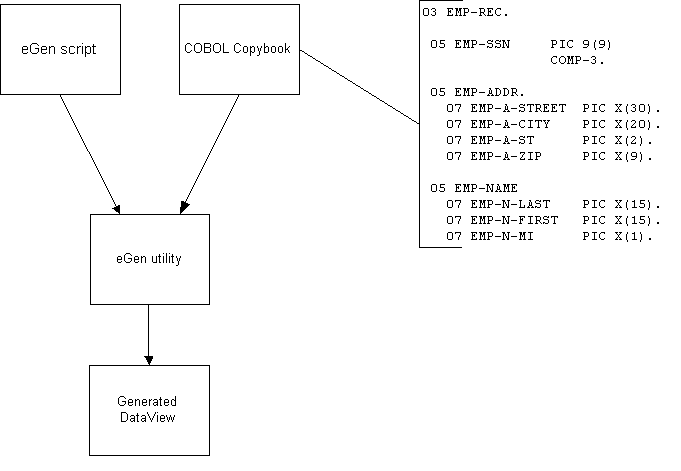
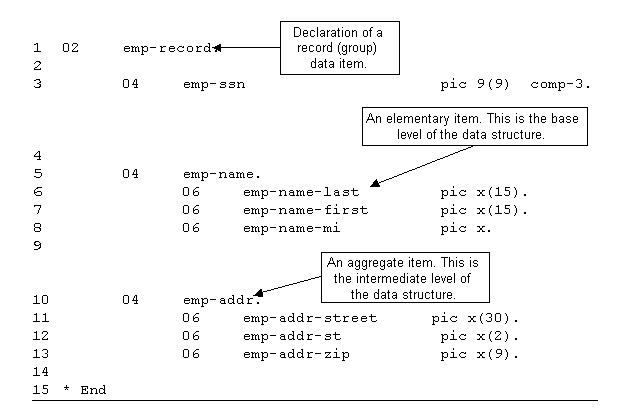
|
|

|

|

|

|