初回トレーニングに生成AIを利用
選択したタクソノミに基づいてカテゴリを予測するための初期トレーニング・セットを生成します。 GenAIは、ビジネス・トランザクションおよびカテゴリ摘要のテキスト・データを使用して、費用カテゴリを予測します。 各カテゴリの上位3つの予測をレビューし、これらの予測を使用して、将来の分類のためのトレーニング・データを最終決定します。
Oracle Fusion Spend Classificationでは、教師あり学習モデルを使用してビジネス・トランザクションを分類します。 これらの学習モデルは、様々なカテゴリにまたがる高品質のトレーニング・データを使用してトレーニングする必要があります。 いくつかの分類方法がすでにある場合、またはSpend Classificationを使用してデータを分類する際に既存のタクソノミの使用を予定している場合は、アップロード準備が整っているトレーニング・データがすでに存在している可能性があります。 しかし、新しいタクソノミを使用してシステムをトレーニングする必要がある場合や、分類および分析ジャーニの開始当初である場合は、トレーニング・データを最初から準備するのに非常に時間を要する可能性があります。
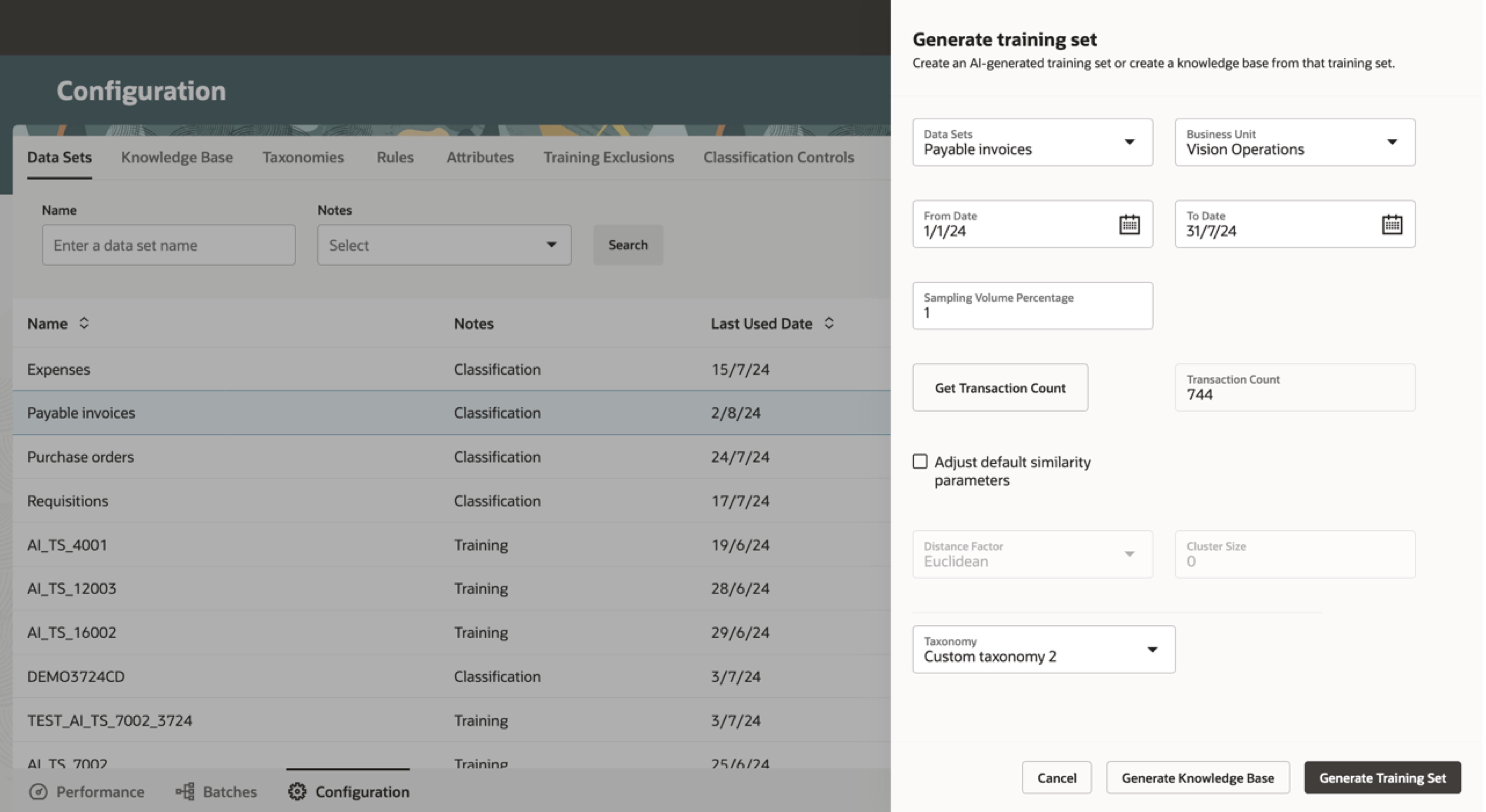
トレーニング・セットの生成
GenAIを使用してサンプル・トレーニング・セットの予測を提供できるようになりました。 GenAIにより、各費用レコードの上位3つの予測が提供されるため、これらをレビューしてトレーニング・セット・データの確定に使用できます。 GenAIでは、請求書などのビジネス・トランザクションの摘要ベースの列が使用され、各カテゴリに割り当てられた摘要が読み取られます。 次に、GenAIで各トランザクションの初期予測が算出されます。 この予測には、トランザクション摘要、品目摘要、明細摘要などの摘要ベースの列が使用されます。
使用するタクソノミを決定したら、トレーニング・セットの生成を開始できます。 各費用レコードの上位3つの予測が表示されます。 これらをレビューし、最適な予測を選択して次のステップに移行することもできます。 あるいは、GenAIで最適な予測を決定し、ナレッジ・ベースの準備を継続できます。ナレッジ・ベースは、トレーニングまたは例を使用して将来の請求書を分類するAIモデルです。 このデフォルトのナレッジ・ベースを使用して、ある期間の請求書を分類し、分類の品質を確認できます。
このアプローチにより、初期トレーニングのために複数の請求書を手動で分類しようとして費やす時間と労力を削減できます。 エンドツーエンドのサイクルが大幅に高速化されます。
これらの機能のデモを次に示します:
有効化のステップ
この機能を有効にするために何もする必要はありません。
ヒントと考慮事項
この新しいAI支援機能は、通常の費用分類フローに組み込まれており、特別な権限は必要ありません。