拡張プレディクション: 特徴量エンジニアリングおよび特徴選択により予測精度が向上
拡張プレディクションでは、予測を実行する前にデータに対して特徴量エンジニアリングおよび特徴選択を実行できるようになり、予測精度が向上します。 拡張プレディクションを定義する場合、管理者は「データ準備」ページの「自動特徴量エンジニアリングおよび選択の有効化」で新しいオプションを選択できます。 このオプションは、デフォルトで選択されています。
適用対象: FreeForm、Planning
特徴量エンジニアリングとは、既存の特徴量を変換したり、モデル・パフォーマンスを向上させるために新しい特徴量を作成することで、機械学習のデータを準備するプロセスです。 自動特徴量エンジニアリングは、このプロセスを加速し、精度を向上させてより優れたモデルを実現します。
特徴量エンジニアリングがなければ、すべてのドライバーはそのまま扱われます。 特徴量エンジニアリングでは、追加情報が特徴量から導出されるため、より正確な予測が可能になります。 次のタイプの変換が適用されます。
- 時間ベースの特徴量。 たとえば、特定の曜日には影響がありますか。
- ラグ効果。 たとえば、6月のマーケティング支出が8月の販売量に及ぼす影響など、ビジネス・ドライバがターゲットに及ぼすラグ効果は何ですか。
- 変換の集計。 たとえば、ローリング平均値が単一のデータ・ポイントではなくビジネス・ドライバに与える影響は何ですか。
特徴量エンジニアリングが完了すると、自動特徴選択によってすべてのドライバ(元のドライバと変換されたドライバ)がレビューされ、最も重要な特徴量の上位15個以下が選択されます。 これらの上位特徴量は、モデルの生成および予測に使用されます。
「予測の説明」画面で特徴量エンジニアリングおよび特徴選択の影響を確認できます: 「予測の詳細」予測値を含むフォームで、予測データを含むセルを右クリックし、「予測の説明」を選択します。 「特徴量の重要度」タブおよび「予測分析」タブで、予測の詳細を確認します。
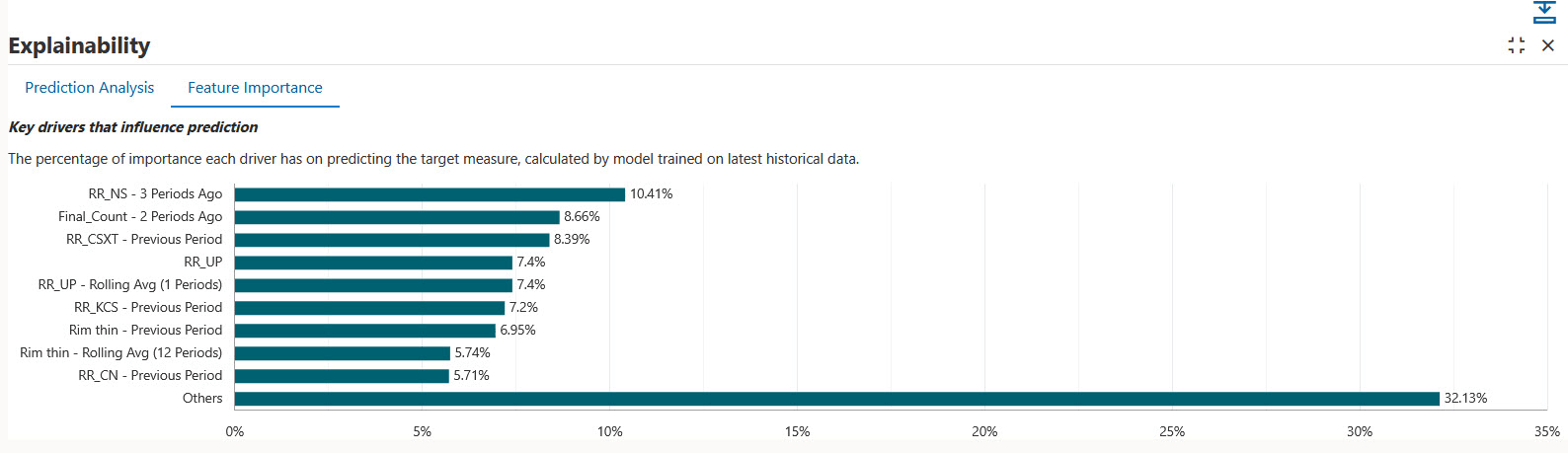
特徴量の重要度に対する特徴量エンジニアリングの影響
ビジネス上の利点:
- 特徴量エンジニアリングは、入力された特徴量と出力変数の間の隠れた関係を検索します。 適切に設計された特徴量により、モデルがより関連性の高い情報を取得できるため、モデルのパフォーマンスが向上し、予測が改善されます。
- 特徴選択、予測の正確性に影響を与える最も関連性の高いビジネス・ドライバを特定し、オーバーフィッティングを回避するために「ノイジー」または影響の少ない変数をフィルタリングします。 また、複雑さと処理時間を短縮することでパフォーマンスが向上します。 予測力に基づいて特徴量をランク付けすることで、説明可能性をサポートします。
ヒントと考慮事項
- デフォルトでは、「自動特徴量エンジニアリングおよび選択の有効化」が選択されています。
- 「自動特徴量エンジニアリングおよび選択の有効化」を選択すると、予測の実行に必要な時間が長くなります。
主なリソース
- FreeForm
- FreeFormの管理
- FreeFormの操作
- Planning
- Planningの管理
- Planningの操作