| Oracle® Retail Category Management Implementation Guide Release 14.1.1 E61606-01 |
|

 Previous |
 Next |
| Oracle® Retail Category Management Implementation Guide Release 14.1.1 E61606-01 |
|
Previous |
Next |
This release of Category Management has defined, supported integration processes for exporting data to and importing data from Oracle Retail Advanced Science Engine (ORASE). These integration processes are detailed in this chapter. In addition, there are basic, supported import and export scripts that can be used as a basis for a customer-defined integration with other systems.
This chapter describes the basic Category Management script import and export.
All Category Management import and export-related scripts and files are located in <CM_HOME>/bin.
The export script is used for exporting data from Category Management. The export consists of a single script along with a control file.
Script Name:
exportdata.ksh
Usage:
exportdata.ksh <control-file>
Control File Name:
exportlist.txt
Control File Content and Format
The control file contains a list of measures to be exported and their desired export intersections, separated by a space. The intersections must conform to RPAS standards (four characters per dimension, right padded with underscores if less than length four). For example:
drtynumfacingsv sku_str_week
drtyshelfcapv sku_str_week
drtysqftv sku_str_week
drtystrclustx qrtrclssstr
drtystrcluslbl qrtrclssstr
Output Location and Format
The output files are written to the <CM_MASTERDOMAIN>/output directory. The output file names are the measure names from the control file. The exportMeasure utility is used to export data in CSV (comma-separated values) format. This maintains the consistency of start and width attributes across different applications. See the Oracle Retail Predictive Application Server Administration Guide for the Fusion Client for details on this utility.
Environment Variables
Only CM_HOME needs to be defined prior to running the script. Other required environment variables are set in the <CM_HOME>/bin/environment.ksh script. These may be adjusted to redefine the output directory, and so on.
Log Files
Processing logs for this script are written to the <CM_HOME>/logs/<date_dir>/exportdata.<unique_id> directory. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system-generated string of numbers that is unique in this context.
Inside this folder, the log file is called exportdata.log. Additional folders are created for every invocation of the script.
Error Codes
exportdata.ksh detects several error conditions, as shown in Table 5-1.
The import script is used for importing data to Category Management. The import consists of a single script along with a control file.
Script Name:
importdata.ksh
Usage:
importdata.ksh <control-file>
Control File Name:
importlist.txt
Control File Content and Format
The control file contains a list of measures to be imported. For example:
drtyattrvaltx
drtynumfacingsv
drtynumfacingsv
drtysqftv
Input Location and Format
The input files are expected to be in the <domain>/input directory. The input file names must match the target measure names in Category Management, suffixed with ".csv.ovr". The loadmeasure utility is used to import data in CSV (comma-separated values) format. See the Oracle Retail Predictive Application Server Administration Guide for the Fusion Client for details on this utility.
Environment Variables
Only CM_HOME must be defined prior to running the script. Other required environment variables are set in the <CM_HOME>/bin/environment.ksh script. These may be adjusted to alter entities such as the log level.
Log Files
Processing logs for this script are written to the <CM_HOME>/logs/<date_dir>/importdata.<unique_id> directory. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system generated string of numbers that is unique in this context.
Inside this folder, the log file is called importdata.log. Additional folders are created for every invocation of the script.
Error Codes
importdata.ksh detects several error conditions, as shown in Table 5-2.
Category Management is integrated with the Assortment and Space Optimization module (ASO) of ORASE using Hybrid Storage Architecture (HSA) in near real-time.
In RCM, the interface with ASO is managed using taskflows in the Assortment Planning and Optimization module for ASO at the cluster and store levels. Data is interfaced to ASO in near real-time. After data processing in ASO, ASO results can be imported back into Assortment Planning and Optimization, also in near real-time. Data committed in the workbooks is available in the Oracle DB Server in real-time using HSA and those are interfaced to ASO through the Assortment Planning and Optimization-ASO interface scripts. In the same way, data processed in ASO can be copied back to the RDM tables using the Assortment Planning and Optimization-ASO interface scripts, and later, the data can be imported into the Assortment Planning and Optimization module workbooks through custom menus.
Following are the components of the Assortment Planning and Optimization-ASO integration:
Assortment Planning and Optimization: Module within RCM, with taskflows and custom menus to export and import data to ASO.
HSA/RDM (RPAS Data Mart): Architecture which makes the data stored in RPAS Data Mart available to integrated domains and non-RPAS Oracle DB Servers in near real-time. For more details on HSA, see the HSA Installation section in the Oracle Retail Predictive Application Server Installation Guide and RDM Data Model in the Oracle Retail Predictive Application Server Administration Guide for the Fusion Client.
Assortment Planning and Optimization-ASO Interface: Scripts which call PL/SQL packages to copy data from RDM to ASO staging tables. In the same way, processed data is copied back to RDM tables. Those scripts need to be scheduled to run as cron jobs in regular intervals to integrate with ASO.
ASO: Module of ORASE which does space optimization for the assortments and returns the space optimized results.
After installing RCM, following are the prerequisites for ASO integration using HSA:
Need an Oracle Database Server with Oracle 12c or later installed for installing HSA. It should be the same server where ASO will be installed. It can also be the same server where RCM is installed.
ASO installed on the same Oracle DB Server where HSA will be installed.
Assortment Planning and Optimization-ASO interface packages and scripts should also be installed on the same Oracle DB Server after installing ASO and HSA.
If the Oracle database server is not the same as the RPAS server where RCM is installed, the RPAS server must be installed with the Oracle client software, including SQL Plus and SQL Loader. ORACLE_HOME must be set.
Following tablespaces RSEINT_MDS, tablespace_temp should be created in Oracle DB which is used by RDM.
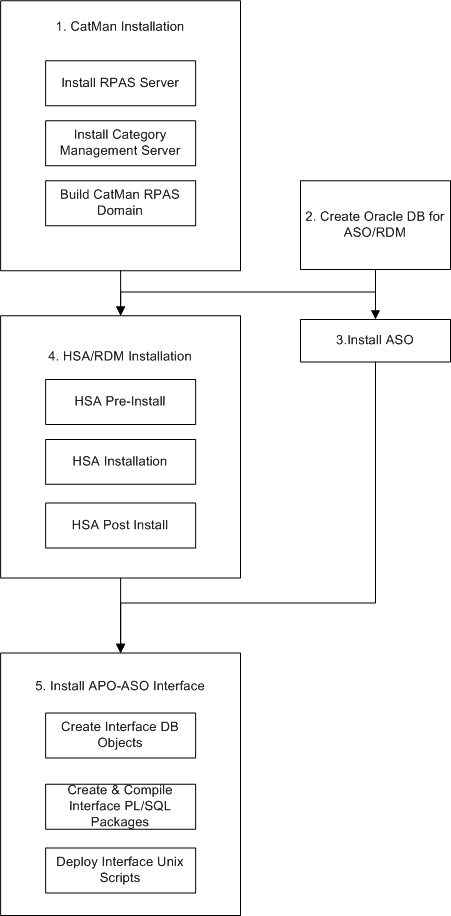
Figure 5-1 shows the steps for the Assortment Planning and Optimization-ASO integration. For a detailed description of the steps, see "Description of Assortment Planning and Optimization-ASO Integration Steps".
To integrate Assortment Planning and Optimization and ASO, perform the following installations:
Install RPAS, the Category Management Server, and Category Management Domain. For more information, see Chapter 3.
Create the Oracle DB for installing the ASO Objects and RDM.
Install ASO on the Oracle DB server. For more information, see the Oracle Retail Advanced Science Engine Installation Guide.
Install HSA on the Oracle DB Server and register it with the RPAS Domain. See "Step 4 - HSA/RDM Installation".
Install the Assortment Planning and Optimization-ASO Interface Objects. See "Step 5 - Assortment Planning and Optimization-ASO Interface Object Installation".
The components needed for HSA installation are available in the
<CM_HOME>/hsa/integration_config directory.
HSA Pre-Installation Steps
To prepare the RPAS Server environment for installing HSA:
Set and export the following variables:
export RDM_PATH
RDM_PATH is the variable where you want to install RDM on the RPAS Server. Typically, it can be $CM_HOME/rdm.
export ORACLE_HOME
ORACLE_HOME is the path where the Oracle Client software is installed on the RPAS Server.
export PATH=$PATH:$ORACLE_HOME/bin:$ORACLE_HOME/lib
Edit the $CM_HOME/hsa/integration_config/schemaInfo.xml file with the Oracle Database Server information in the following tags for the host, port, and service_name parameters.
<tns_parameters>
<protocol>tcp</protocol>
<host>server_name</host>
<port>9999</port>
<server>dedicated</server>
<service_name>db_service_name</service_name>
</tns_parameters>
|
Note: This file is configurable. If tablespace name and space_quota are not provided, it will use the default tablespace and space_quota in the Oracle Database. It needs to be edited based on the size of the implementation, in discussion with the Database Administrator (DBA), for all the newly added schemas in the file. |
For silent installation of RDM, pre-fill the prepareRDM.ksh file which is in the $RPAS_HOME/bin directory. The passwords used for the RDM schemas should be the same as the passwords to be used for creating them in the Oracle DB server. The following example shows sample data for the file.
# Path to the RDM repository directory
RDM_PATH=$CM_HOME/rdm
# Path to schema info file
SCHM_INFO=$CM_HOME/hsa/integration_config/schemaInfo.xml
# Flag to confirm file paths ("Y" or "N")
PATH_CONFIRM=Y
# Flag to overwrite RDM directory ("Y" or "N")
RDM_OVERWRITE=Y
# Flag to overwrite the wallet ("Y" or "N")
WALLET_OVERWRITE=Y
# Password for the Wallet
WALLET_PWD=password01
# Path to the Oracle server CA certificate file
#CA_PATH=
# Passwords for working schemas
RPAS_DATA_MART_PWD=password01
RPAS_PATCH_PWD=password01
RPAS_BATCH_PWD=password01
RPAS_DIMLOAD_PWD=password01
RPAS_FACTLOAD_PWD=password01
RPAS_HIERMGR_PWD=password01
RPAS_WKBK_PWD=password01
RPAS_ETL_PWD=password01
Run the prepareRDM.ksh script to create the RDM directory structure and generate the prepareSchemas.sql script which is used to create schemas in the Oracle DB server. It generates the script in the $RDM_PATH/scripts directory.
Go to the RDM_PATH/scripts directory and run the SQL script, @prepareSchemas.sql, on the schema where you want to install HSA. In the following example, ETSUSER schema is used to create the HSA schemas and roles. A user with the DBA privilege should run the script to create the schemas and roles.
cd $RDM_PATH/scripts
sqlplus ETSUSER/<pwd>@<server>:<port>/<service_name> @prepareSchemas.sql
HSA Installation Step
To install HSA, use the standard rpasInstall command to install RDM on the RPAS Server using the following two commands to generate and install:
rpasInstall -buildRDM -genScript -integrationCfg $CM_HOME/hsa/integration_config/integration.xml -partitionInfo $CM_HOME/hsa/integration_config/partitioninfo.xml -log buildRDM_genscript.log -rdm $RDM_PATH
rpasInstall -buildRDM -fromScript -rdm $RDM_PATH -log buildRDM_fromscript.log
HSA Post-Installation Steps
After installing HSA:
After the successful installation of RDM, the dimension data should be loaded into the RDM tables. Run the load_rdm_dim.ksh script which creates the dimension file that needs to be loaded into the RDM tables.
Note: This script should also be scheduled to run on the daily/weekly batch based on the frequency of changes to hierarchy data.
.$CM_HOME/bin/load_rdm_dim.ksh
Run the following command to register the Category Management domain with HSA. After registration, both the RPAS domain and HSA are linked.
rdmMgr -rdm $RDM_PATH -register -d $CM_HOME/domain/catman -name catman
To install the Assortment Planning and Optimization-ASO interface objects:
If the Oracle DB Server is different from the RPAS Server, ftp and copy the contents of $CM_HOME/hsa/apo_aso_interface to a directory to be used as the home directory for the interface, for example, INTF_HOME.
To grant access to all ASO Objects in the ASO schema for RPAS_ETL_USER, run the SQL script, @direct_aso_grants.sql, present in the $INTF_HOME/db/grants directory on the ASO schema.
To grant access to the RDM Objects in the RPAS_DATA_MART schema for RPAS_ETL_USER, run the SQL script, @direct_rdm_grants.sql, present in the $INTF_HOME/db/grants on the RDM Schema.
To create the Assortment Planning and Optimization-ASO Interface DB objects and compile the PL/SQL packages in the RPAS_ETL_USER schema, run the SQL Script, @create_all.sql, present in the $INTF_HOME directory.
Edit the following environment variables used in the interface scripts in scripts/lib/int.env:
INTF_HOME
For example: export INTF_HOME="home/apo_aso_interface"
INTF_DB_BATCH_USER
For example: export INTF_DB_BATCH_USER="RPAS_ETL_USER/<pwd>@<service_name>"
Schedule the following three scripts as cron jobs to run after the scheduled interval (for example, 10 to 15 minutes) to copy data from the RDM tables into the ASO Staging table and vice versa. This scheduling should be in-sync with the ASO script which copies data from the ASO Staging table to the final ASO tables.
aso_apo_interface.ksh: Copies processed data from the ASO Staging table to the RDM tables used by Assortment Planning and Optimization.
apo_aso_interface.ksh: Copies exported data from Assortment Planning and Optimization in the RDM tables to the ASO Staging table.
The ASO script which copies data from the ASO Staging table to the final ASO tables.
|
Note: This script is part of the ASO installer and not part of Assortment Planning and Optimization. For more information, see the Oracle Retail Advanced Science Engine Implementation Guide. |
Schedule the apo_purge.ksh script to run in daily or weekly batch. It is used to purge data from the RDM tables for finalized assortment sets.
RCM and ORASE are integrated with an exchange of data. This section describes the RCM exports which ORASE can receive, as well as, the ORASE exports which RCM can receive.
ORASE exports several data files which can be imported into RCM. Following are lists of the files:
Attribute Information:
Product Attributes Hierarchy - attr.csv.dat. This hierarchy load file contains the Product Attributes definition.
Loaded Attribute Value ID - drtyattrvaltx.csv.ovr. This measure load file contains the SKU-Product Attributes mapping.
Demand Transference Files:
Assortment Elasticity - drtyassrtelasv.csv.ovr. This measure load file contains the Assortment Category Elasticity Parameters.
Attribute Weights and Functional Fit - drtyattrwgtv.csv.ovr. This measure load file contains both Category-Attribute Weights and Category-Attribute Functional Fit.
Similarities - drtysiminv.csv.ovr. This measure load file contains the SKU Similarities Parameters.
Cluster Information:
Store Clusters - rsestrclst.csv. This measure load file contains Store Cluster Name and Store Cluster Label data.
Consumer Decision Trees:
CDTs - *.xml. Any number of consumer decision tree (CDT) files in XML format.
This section describes the transformation in the RCM to ORASE integration.
Transformation between ORASE and RPAS Format
The format used by RPAS and ORASE for categories and attributes is not the same. The ORASE format is to add a class prefix before the attribute name ID, attribute value ID, and category ID, but the RPAS format does not utilize this prefix. Table 5-3 describes differences, by way of example, between the two formats.
Table 5-3 Transformation Matrix
| RPAS Format | ORASE Format | |
|---|---|---|
|
Attribute Name ID |
brandtier |
CLS~1000~10000~brandtier |
|
Attribute Value ID |
brandtier~national_mainstream |
CLS~1000~10000~brandtier~national_mainstream |
|
Category ID |
1000_10000 |
CLS~1000~10000 |
In the table, ORASE format, the class prefix used is "CLS~1000~10000." This is a concatenation of a text string CLS denoting class, in addition to the department ID 1000, and the class ID 10000. RPAS does not utilize this prefix. In addition, when concatenating the department and class IDs together to form the class position ID, RPAS uses an underscore rather than tilde separator.
The RCM import and export scripts described in the following sections contain code which can be utilized to transform between these formats.
The flat-file data exported from ORASE and imported into RCM is transformed using a script.
Script Name
rcm_t_data_orase.ksh
Usage
rcm_t_data_orase.ksh -f <file> -d <delimiter> [-a <field1,field2,…>] -c <field1,field2,…>
<file> is the path and file name of the file to be transformed. The script will look for the file in the path specified.
<delimeter> is the delimiter used to separate fields in the input file.
<fieldx>, when used after the -a option, indicates a field containing attribute name or attribute value IDs to be transformed. If multiple fields contain data needing transformation, specify them in comma-separated format. For example "-a 1,2,3".
<fieldx>, when used after the -c option, indicates a field containing category name IDs to be transformed. If multiple fields contain data needing transformation, specify them in comma-separated format. For example "-c 4,5".
Notes
This script may be called from the command line.
Additionally, this script is invoked from within other integration scripts when called with the -r option. Specifically, import_rse_attributes.ksh, described in "Attributes Data Import Script", when called with the -r option, will call rcm_t_data_orase.ksh to transform the attribute ID fields of the attribute hierarchy and SKU-attribute map before loading the data into the RCM domain. The script import_rse_clusters.ksh, described in "Clustering Data Import Script", when called with the -r option, will call rcm_t_data_orase.ksh to transform the category ID field before loading the data into the RCM domain. The script import_rse_dt.ksh, described in "Demand Transference Data Import Script", when called with the -r option, will call rcm_t_data_orase.ksh to transform the assortment elasticity category ID field and attribute weights and functional fit category and attribute name ID fields before loading into the RCM domain. Each of these three scripts use a delimiter of the comma character ("-d ,").
This script will transform the specified fields from ORASE format to RPAS format as detailed in Table 5-3.
Log Files
Processing logs for this script, when called from the command line, are written to the <CM_HOME>/logs/<date_dir>/rcm_t_data_orase.<unique_id> directory. If invoked from within another import script, the log for this script will be one level deeper from the calling script. For example, <CM_HOME>/logs/<date_dir>/<calling script>.<unique_id>/rcm_t_data_orase.<unique_id>. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system-generated string of numbers that is unique in this context.
Inside this folder, the log file is called rcm_t_data_orase.log. Additional folders are created for every invocation of the script.
Error Codes
rcm_t_data_orase.ksh detects the following error condition, as shown in Table 5-4.
The CDT files exported from ORASE and imported into RCM are transformed using a script.
Script Name
rcm_t_cdt_orase.ksh
Usage
rcm_t_cdt_orase.ksh -f <cdtfile>
<cdtfile> is the path and file name of the file to be transformed. The script will look for the file in the path specified.
Notes
This script may be called from the command line. However, it is also invoked from within the processcdts.ksh script when called with the -r option.
This script will transform the <cdt> tag's category element, from ORASE format to RPAS format according to Table 5-3. It will also transform all <attribute> tags' name and value elements, from ORASE format to RPAS format according to Table 5-3.
Log Files
Processing logs for this script, when called from the command line, are written to the <CM_HOME>/logs/<date_dir>/rcm_t_cdt_orase.<unique_id> directory. If invoked from within another import script, the log for this script will be one level deeper from the calling script. For example, <CM_HOME>/logs/<date_dir>/<calling script>.<unique_id>/rcm_t_cdt_orase.<unique_id>. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system-generated string of numbers that is unique in this context.
Inside this folder, the log file is called rcm_t_cdt_orase.log. Additional folders are created for every invocation of the script.
Error Codes
rcm_t_cdt_orase.ksh detects several error conditions, as shown in Table 5-5.
The flat-file data exported from ORASE and imported into RCM is transformed using a script.
Script Name
orase_t_data_rcm.ksh
Usage
orase_t_data_rcm.ksh -f <file> -d <delimiter> [-n <field1,field2,…>] [-v <field1,field2,…>] [-c <field1,field2,…>]
<file> is the path and file name of the file to be transformed. The script looks for the file in the path specified.
<delimeter> is the delimiter used to separate fields in the input file. If the delimeter needed is the pipe character ("|"), specify "-f PIPE".
<fieldx>, when used after the -n option, indicates a field containing attribute name IDs to be transformed. If multiple fields contain data needing transformation, specify then in comma-separated format. For example, "-n 1,2,3".
<fieldx>, when used after -v option, indicates a field containing attribute value IDs to be transformed. If multiple fields contain data needing transformation, specify then in comma-separated format. For example, "-v 1,2,3".
<fieldx>, when used after -c option, indicates a field containing category name IDs to be transformed. If multiple fields contain data needing transformation, specify them in comma-separated format. For example, "-c 4,5".
Notes
Since -n, -v, and -c are optional, if none are specified, the script will exit gracefully with nothing to do.
If -n is specified but -v is not, the script will exit, as an attribute name field is required to correctly prefix the -n field.
This script may be called from the command line.
This script will transform the specified fields from RPAS format to ORASE format as detailed in Table 5-3.
Log Files
Processing logs for this script, when called from the command line, are written to the <CM_HOME>/logs/<date_dir>/orase_t_data_rcm.<unique_id> directory. If invoked from within another script, for example, export_so.ksh, the log for this script will be one level deeper from the calling script. For example, <CM_HOME>/logs/<date_dir>/export_so.<unique_id>/orase_t_data_rcm.<unique_id>. Here:
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system-generated string of numbers that is unique in this context.
Inside this folder, the log file is called orase_t_data_rcm.log. Additional folders are created for every invocation of the script.
Error Codes
orase_t_data_rcm.ksh detects several error conditions, as shown in Table 5-6.
Table 5-6 Error Codes for orase_t_data_rcm.ksh
| Error Code | Abort Required? | Error Description |
|---|---|---|
|
1 |
Yes |
Incorrect usage, or failure in one of the following commands or command-line utilities: exportMeasure, awk, sort, exportHier, head, rm, touch, mv. |
|
15 |
Yes |
Delimiter not specified, or attribute name field specified with -n but no attribute value field specified with -v. |
The attributes import script is used for importing attributes hierarchy and measure data into Category Management. The data is expected to be generated by ORASE. The import consists of a single script.
Script Name:
import_rse_attributes.ksh
Usage:
import_rse_attributes.ksh [-r]
The -r option indicates that attribute name IDs and attribute value IDs contained in the processed files should be transformed from ORASE format to RPAS format by removing the Class Prefix.
Input Files
The files imported by this script are:
Product Attributes Hierarchy file: attr.csv.dat
SKU-Attribute Map file: drtyattrvaltx.csv.ovr
Input Location and Format
The input files are expected to be in the <domain>/input directory.
The Product Attributes Hierarchy file, attr.csv.dat, is described in Chapter 3. The SKU-Attribute Map file is described in "SKU-Attributes Map File".
File Name:
drtyattrvaltx.csv.ovr
File format:
comma-separated values file
Fields:
SKU, Product Attribute Name, Product Attribute Value
The following table describes the fields in this file.
| Field | Description |
|---|---|
| SKU | SKU ID in the Product Hierarchy |
| Product Attribute Name | Product Attribute Name Position ID |
| Product Attribute Value | Product Attribute Value Position ID |
Example:
"1234615","formatsize","12_oz" "1234615","manufacturingprocess","non_organic" "1234615","pl","npl" "1234615","roast","light_roast" "1234615","segment","de_caffeinated"
|
Note: The Attribute Name and Attribute Value fields must be the position names (such as non_organic), not the position labels (such as, Non Organic). |
Algorithm
If the -r option is specified, the rcm_t_data_orase.ksh script is called to remove prefixes from the attribute name and attribute value ID fields. It calls RPAS loadHier to load the Product Attributes hierarchy file, converts the SKU-Attributes map contents to lower case, and calls RPAS loadmeasure to load the SKU-Attributes map file.
Environment Variables
Only CM_HOME must be defined prior to running the script. Other required environment variables are set in the <CM_HOME>/bin/environment.ksh script. These may be adjusted to alter entities such as the log level.
Log Files
Processing logs for this script are written to the <CM_HOME>/logs/<date_dir>/import_rse_attributes.<unique_id> directory. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system generated string of numbers that is unique in this context.
Inside this folder, the log file is called import_rse_attributes.log. Additional folders are created for every invocation of the script.
Error Codes
import_rse_attributes .ksh detects several error conditions, as shown in Table 5-7.
The clustering import script is used for importing store to store cluster mapping data into Category Management. The store to store cluster mapping is stored in two measures which are loaded into Dynamic Hierarchy Dimensions for selected Category Management workbooks. The data is expected to be generated by ORASE. The import consists of a single script.
Script Name:
import_rse_clusters.ksh
Usage:
import_rse_clusters.ksh [-r]
The -r option indicates that category IDs contained in the processed file should be transformed from ORASE format to RPAS format by removing the Class Prefix and changing the separator of the category ID from ~ to _.
Input Files
The file imported by this script is:
Store to Store Cluster map file: rsestrclst.csv
Input Location and Format
The input file is expected to be in the <domain>/input directory.
The map file is described in "Store to Store Cluster Map File".
Output Effect
The input file is split into two entities, one holding the store cluster position and the other holding the store cluster labels. Each is then loaded into the RPAS measures DRTYStrClusTx and DRTYStrClusLbl.
File Name:
rsestrclst.csv
File format:
comma-separated values file
Fields:
Effective Start Date, Effective End Date, Category, Store, Store Cluster Position, Store Cluster Label
The following table describes the fields in this file.
| Field | Description |
|---|---|
| Effective Start Date | Effective Start Date in dayYYYYMMDD format |
| Effective End Date | Effective End Date in dayYYYYMMDD format |
| Category | Category ID in the Product Hierarchy |
| Store | Store ID in the Location Hierarchy |
| Store Cluster Position | Store Cluster Position ID |
| Store Cluster Label | Store Cluster Position Label |
Example:
"day20121221","day20131219","10000","4","200","Cluster Set 1" "day20121221","day20131219","10000","2","200","Cluster Set 1" "day20121221","day20131219","20000","2","205","Cluster Set 1" "day20121221","day20131219","20000","3","205","Cluster Set 1" "day20121221","day20131219","40000","148","218","Cluster Set 4" "day20121221","day20131219","40000","149","218","Cluster Set 4"
Algorithm:
If the -r option is specified, the rcm_t_data_orase.ksh script is called to remove prefixes from the category ID field.
During processing of the script, the end date is discarded. The remaining data is loaded into two temporary measures with an intersection of day/clss/str. When loading at day, if multiple rows of data for the same intersection exist, the last one will trump the earlier data.
Once the data is loaded into the two temporary measures at day, mace is invoked to aggregate the data into measures at qrtr/clss/str. During aggregation, if multiple records at day roll up to the same quarter, the data for the first row is retained.
Final result of the load is that the quarter, class, store, and store cluster position are written to the store cluster position measure, DRTYStrClusTx. The quarter, class, store, and store cluster label are written to the store cluster label measure, DRTYStrClusLbl.
These measures then become the load files for the Dynamic Hierarchy Dimension positions in the Assortment Planning workbook.
Environment Variables
Only CM_HOME must be defined prior to running the script. Other required environment variables are set in the <CM_HOME>/bin/environment.ksh script. These may be adjusted to alter entities such as the log level.
Log Files
Processing logs for this script are written to the <CM_HOME>/logs/<date_dir>/import_rse_clusters.<unique_id> directory. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system generated string of numbers that is unique in this context.
Inside this folder, the log file is called import_rse_clusters.log. Additional folders are created for every invocation of the script.
Error Codes
import_rse_clusters.ksh detects the following error condition, as shown in Table 5-8.
Placeholder SKUs are created using standard DPM functionality. The Formalize Placeholder script is used to formalize the placeholder SKUs with actual SKUs from the MDM system. The Placeholder-Formalized SKU Mapping file should be provided by MDM system either on a daily or weekly basis before the formalized SKU data flow through the product hierarchy file. Only after formalization, the MDM solution should send the formalized SKUs in a normal hierarchy file. This script uses the standard RPAS informalPositionMgr and renamePositions utilities to formalize and rename the placeholder position with the actual SKU position in both the PROD and PROR hierarchies.
Script Name:
formalize_ph.ksh
Usage:
formalize_ph.ksh
Input Files
The file imported by this script is:
Placeholder - Formalized SKU Map File: formalize_ph.csv.dat
Input Location and Format
The input file is expected to be in the $CM_BATCH directory. The file is described in "Placeholder - Formalized SKU Map File".
Output Effect
Placeholder SKUs are formalized and renamed with the Formalized SKU information in both the PROD and PROR hierarchies.
File Name:
formalize_ph.csv.dat
File format:
comma-separated values file
Fields:
Placeholder SKU, Formalized SKU
The following table describes the fields in this file.
| Field | Description |
|---|---|
| Placeholder SKU | Placeholder SKU ID |
| Formalized SKU | Formalized SKU ID |
Example:
dpm1,1234615 dpm2,1234616 dpm3,1234617
The Demand Transference import script is used for importing the data required for Category Management to utilize the ORASE calculations. The data is expected to be generated by ORASE. The import consists of a single script.
Script Name:
import_rse_dt.ksh
Usage:
import_rse_dt.ksh [-r]
The -r option indicates that category IDs contained in the Elasticity and Weights/Functional Fit file should be transformed from ORASE format to RPAS format by removing the Class Prefix and changing the separator of the category ID from ~ to _. Also, the attribute name ID field in Weights/Functional Fit will be transformed from ORASE format to RPAS format by removing the prefix from the Attribute Name ID field.
Input Files
The files imported by this script are:
Similarities file: drtysiminv.csv.ovr
Elasticity file: drtyassrtelasv.csv.ovr
Weights and Functional Fit file: drtyattrwgtv.csv.ovr
Input Location and Format
The input files are expected to be in the <domain>/input directory.
The input files are described below.
Output Effect
The Similarities and Elasticity files are loaded straight into the RPAS measures DRTYSimInV and DRTYAssrtElasV. The Weights and Functional Fit file is loaded into two RPAS measures DRTYAttrWgtV and DRTYFuncFitB
Algorithm:
The script invokes the importdata.ksh with a control file of import_dt.txt, containing the DT data to be imported. The three data files are loaded into four measures.
The first two files are loaded into RPAS Measures DRTYSimInV and DRTYAssrtElasV.
The third data file is loaded into two measures by loading the first, second, third, fourth, and fifth fields into the Weights measure DRTYAttrWgtV, and the first, second, third, fourth, and sixth fields into the Loaded Functional Fit measure DRHDFuncFitB. It will then run a rule group to aggregate out the Trading Area and Consumer Segment dimensions in the Loaded Functional Fit data (with intersection clss/tdar/csd/atn) to the final measure DRTYFuncFitB used in the calculations (with intersection clss/atn).
For the similarities and elasticity data, the Effective Start and End date fields are ignored.
Control File Name:
importlist_dt.txt
Control File Content and Format
The control file contains a list of measures to be imported from ORASE for Demand Transference. The contents are:
drtysiminv
drtyassrtelasv
drtyattrwgtv,drhdfuncfitb
Environment Variables
Only CM_HOME must be defined prior to running the script. Other required environment variables are set in the <CM_HOME>/bin/environment.ksh script. These may be adjusted to alter entities such as the log level.
Log Files
Processing logs for this script are written to the <CM_HOME>/logs/<date_dir>/import_rse_dt.<unique_id> directory. Here,
<date_dir> is a directory with a name corresponding to the date the script was run, in the format YYYY-MM-DD.
<unique_id> is a system generated string of numbers that is unique in this context.
Inside this folder, the log file is called import_rse_dt.log. Additional folders are created for every invocation of the script.
Error Codes
import_rse_dt.ksh detects the following error condition, as shown in Table 5-9.
Table 5-9 Error Codes for import_rse_dt.ksh
| Error Code | Abort Required? | Error Description |
|---|---|---|
|
1 |
Yes |
Failure in the call to impordata.ksh or in one of the following commands: loadmeasure, mace, or other Unix shell commands. |
File Name:
drtysiminv.csv.ovr
File format:
comma-separated values file
Fields:
SKU, Trading Area, Consumer Segment, Similar SKU, Similarity, Effective Start Date, Effective End Date
The following table describes the fields in this file.
| Field | Description |
|---|---|
| SKU | SKU ID in the Product Hierarchy |
| Trading Area | Trading Area ID in the Location Hierarchy |
| Consumer Segment | Consumer Segment ID in the Consumer Segment Hierarchy |
| Similar SKU | SKU ID in the Product Hierarchy |
| Similarity | Number indicating the similarity between the two SKUs |
| Effective Start Date | Date in YYYY-MM-DD format indicating effective start date of the similarity |
| Effective End Date | Date in YYYY-MM-DD format indicating effective end date of the similarity |
Example:
"1235719","2","s3","1236880",".4779967","2013-11-10","" "1235719","2","s6","1235572",".6059371","2013-11-10","" "1235719","2","s1","1235854",".8803831","2013-11-10","" "1235719","2","s7","1234615",".4367552","2013-11-10","" "1235719","2","s3","1234753",".4779967","2013-11-10","" "1235719","2","s3","1234828",".4779967","2013-11-10",""
File Name:
drtyassrtelasv.csv.ovr
File format:
comma-separated values file
Fields:
Category ID, Trading Area, Consumer Segment, Assortment Elasticity, Effective Start Date, Effective End Date
The following table describes the fields in this file.
| Field | Description |
|---|---|
| Category ID | Category ID in the Product Hierarchy |
| Trading Area | Trading Area ID in the Location Hierarchy |
| Consumer Segment | Consumer Segment ID in the Consumer Segment Hierarchy |
| Assortment Elasticity | Number representing the Category Elasticity |
| Effective Start Date | Date in YYYY-MM-DD format indicating effective start date of the similarity |
| Effective End Date | Date in YYYY-MM-DD format indicating effective end date of the similarity |
Example:
"10000","3","s6","-.4476855","2013-11-10","" "10000","100","s4","-.4954495","2013-11-10","" "10000","1","s3","-.2911932","2013-11-10","" "10000","4","s6","-.3327132","2013-11-10","" "10000","4","s1","-.3327132","2013-11-10","" "10000","100","s6","-.4954495","2013-11-10",""
File Name:
drtyattrwgtv.csv.ovr
File format:
comma-separated values file
Fields:
Category ID, Trading Area, Consumer Segment, Attribute Name, Weight, Functional Fit
The following table describes the fields in this file.
| Field | Description |
|---|---|
| Category ID | Category ID in the Product Hierarchy |
| Trading Area | Trading Area ID in the Location Hierarchy |
| Consumer Segment | Consumer Segment ID in the Consumer Segment Hierarchy |
| Attribute Name | Attribute Name in the Attribute Hierarchy |
| Weight | Normalized weight for the attribute |
| Functional Fit | Boolean where 0 indicates regular attribute and 1 indicates the weight is disregarded |
Example:
"10000","2","s6","pl",".1820273","0" "10000","2","s6","roast",".0641755","0" "10000","2","s6","segment",".1054169","0" "10000","2","s6","brandtier",".0554414","0" "10000","2","s4","tradetype",".1427163","0"