この章では、
フィールドの定義と使用で説明した実行時のマッピング関数を除く、すべてのFML関数およびVIEWS関数について説明します。
COBOLプログラムでは、FML関数を直接使用できません。まず、
FINITというプロシージャを使用して、FMLデータを受信するためにレコードを初期化し、次に
FVSTOFおよび
FVFTOSのプロシージャを使用してCOBOLレコードとFMLバッファ間の変換を行います。これらのプロシージャの詳細は、
『COBOLを使用したOracle Tuxedo ATMIアプリケーションのプログラミング』を参照してください。ここでは、COBOLインタフェースについては説明しません。
FMLとVIEWS: 16ビット・インタフェースと32ビット・インタフェース
FMLは、2種類あります。従来のFMLインタフェースは、フィールド長に16ビットの値を使用し、フィールドを識別する情報を格納します。したがって、FML16と呼ばれます。FML16では、一意のフィールド数は8191、個々のフィールド長は最大64Kバイト、フィールド化バッファの総容量は64Kに制限されます。このインタフェースの定義、型、および関数のプロトタイプは
fml.hに定義され、FML16インタフェースを使用するアプリケーション・プログラムは、このファイルをインクルードする必要があります。各関数は、
-lfmlにあります。
FML32は、フィールド長と識別子に32ビットの値を使用します。約3千万のフィールド、約20億バイトのフィールド長およびバッファ長が使用できます。FML32の定義、型、および関数のプロトタイプは、
fml32.h内にあります。各関数は、
-lfml32にあります。FML32の定義、型、および関数名には、すべて接尾辞「32」が付きます(
MAXFBLEN32、
FBFR32、
FLDID32、
FLDLEN32、
F_OVHD32、
Fchg32、エラー・コード
Ferror32など)。また、環境変数にも接頭辞 “32"が付きます(
FLDTBLDIR32、
FIELDTBLS32、
VIEWFILES32、
VIEWDIR32など)。FML32では、フィールド化バッファのポインタは
「FBFR32 *」型、フィールド長は
FLDLEN32型、フィールドのオカレンス数は
FLDOCC32型です。FML32バッファには、デフォルトで4バイトの調整が必要です。
正しく記述されたFML16アプリケーションは、簡単にFML32インタフェースに変更できます。FML関数の呼出しに使用する変数は、すべて適切なtypedef (
FLDID、
FLDLEN、および
FLDOCC)により定義されている必要があります。FMLの型付きバッファに対して
tpalloc(3c)を呼び出すときは、FMLのかわりに
FMLTYPEで定義する必要があります。アプリケーションのソース・コードに、
fml.hのかわりに
fml32.hを指定し、
fml1632.hを組み込むことで32ビットの関数を使用できるようになります。
fml1632.hには、すべての16ビットの型定義を32ビット版に変換したり、16ビットの関数やマクロを32ビット版に変換するマクロが含まれています。
FML32のフィールド化バッファをFML16のフィールド化バッファに変換する関数や、その逆の変換を行う関数も提供されています。
#include ���fml.h���
#include ���fml32.h���
int
F32to16(FBFR *dest, FBFR32 *src)
int
F16to32(FBFR32 *dest, FBFR *src)
F32to16は、32ビットのFMLバッファを16ビットのFMLバッファに変換します。これは、フィールド対フィールドのバッファの変換を行い、フィールド化バッファの索引を作成することによって行ないます。FLDID32からFLDIDを生成し、フィールド値(
string型および
carray型フィールドではフィールド長も含む)をコピーすると、フィールドは変換されます。
destは、変換後のフィールド化バッファを示すポインタ(宛先バッファ)であり、
srcは、変換元のフィールド化バッファを示すポインタ(ソース・バッファ)です。ソース・バッファは変更されません。
これらの関数は、領域の不足により失敗する可能性があります。操作を完了するには、十分な追加領域を割り当ててから関数を再度発行します。
F16to32は、16ビットのFMLバッファを32ビットのFMLバッファに変換します。この関数は、
fml32ライブラリまたは共有オブジェクトに格納されており、エラーが発生すると
Ferror32が設定されます。
F32to16は、
fmlライブラリまたは共有オブジェクトに格納されており、エラーが発生すると
Ferrorが設定されます。これらの関数を使用するためには、
fml.hおよび
fml32.hの両方をインクルードする必要があることに注意してください。同じファイルに、
fml1632.hをインクルードする必要はありません。
埋め込み型バッファのフィールド型(
FLD_PTR、
FLD_FML32、および
FLD_VIEW32)は、FML32でのみサポートされています。
FLD_PTR型、
FLD_FML32型、
FLD_MBSTRING型、または
FLD_VIEW32型のフィールドを含むバッファを使用すると、
F32to16が失敗し、
FBADFLDエラーが返されます。これらの関数に対して
F16to32を呼び出しても、何も起こりません。
|
注意:
|
以降の項では、16ビットの関数のみ説明し、対応するFML32およびVIEW32関数は説明しません。 |
FML関数のパラメータ仕様をわかりやすくするため、パラメータは、規則的な順序で指定されます。FMLのパラメータは、次の順序で指定されます。
|
1.
|
フィールド化バッファへのポインタが必要な関数の場合( FBFR)、このパラメータを最初に指定します。関数が2つのフィールド化バッファのポインタを使用する場合(転送関数など)、最初に宛先バッファ、次にソース・バッファを指定します。フィールド化バッファのポインタはshort型の範囲内に調整された領域を指す必要があり(そうでない場合 Ferrorが FALIGNERRに設定されてエラーが返されます)、領域はフィールド化バッファである必要があります(そうでない場合 Ferrorが FNOTFLDに設定されてエラーが返されます)。 |
|
2.
|
入出力関数の場合は、最初にストリームに対するポインタを指定し、次にフィールド化バッファに対するポインタを指定します。 |
|
3.
|
フィールド識別子を必要とする関数の場合は、次にフィールド識別子( FLDID型)を指定します( Fnextの場合は、次にフィールド識別子に対するポインタを指定します)。 |
|
4.
|
フィールド・オカレンス( FLDOCC型)を必要とする関数の場合は、次にフィールド・オカレンスを指定します。( Fnextの場合は、次にオカレンス番号に対するポインタを指定します。) |
|
5.
|
フィールド値を受け渡す関数の場合は、次にフィールド値の先頭に対するポインタを指定します。(このポインタは、文字ポインタとして定義しますが、別の型のポインタからキャストすることもできます。) |
|
6.
|
文字配列( carray、 mbstring)型フィールドを処理する関数にフィールド値を渡す場合は、次にフィールドの長さを決定するパラメータ( FLDLEN型)を指定します。フィールド値を検索する関数の場合は、検索対象のバッファの長さに対するポインタを関数に渡す必要があります。このパラメータは、検索対象の値の長さに設定されます。 |
|
7.
|
いくつかの関数では、上記の規則には当てはまらない特別なパラメータが必要です。これらの特別なパラメータは、上記のパラメータの後に指定します。詳細は、各関数の説明部分を参照してください。 |
|
8.
|
以下は、フィールドの型ごとに定義されているNULL値です。 |
|
•
|
carray型または mbstring型の場合はゼロ長の文字列
|
以下の関数を使用すると、プログラムの実行時に問合せフィールド表またはフィールド識別子を照会し、フィールドに関する情報を取得できます。
Fldidは、指定された有効なフィールド名のフィールド識別子を返し、フィールド名/フィールド識別子のマッピング表がない場合は、その表をフィールド表ファイルからロードします。
Fnameは、指定された有効なフィールド識別子のフィールド名を返し、フィールド識別子/フィールド名のマッピング表がない場合は、その表をフィールド表ファイルからロードします。
char *
Fname(FLDID
fieldid)
Fldnoは、指定されたフィールド識別子からフィールド番号を抽出します。
FLDOCC
Fldno(FLDID
fieldid)
Fldtypeは、指定されたフィールド識別子からフィールドの型(
fml.hで定義された整数)を抽出します。
int
Fldtype(FLDID
fieldid)
表6-1
Fldtypeによって返されるフィールドの型
|
|
|
fml.h/fml32.hにおけるフィールドの型名 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ftypeは、フィールド識別子で指定されたフィールドの型名を含む文字列に対するポインタを返します。
char *
Ftype(FLDID
fieldid)
fieldidは、有効なフィールド識別子です。たとえば、次のコードは、
short、
long、
char、
float、
double、
string、
carray、
mbstring、
FLD_PTR、
FLD_FML32または
FLD_VIEW32のいずれか1つの文字列へのポインタを返します。
char *typename
. . .
typename = Ftype(fieldid);
アプリケーションの作成機能の一部として、またはフィールド識別子を再作成するため、型の種類とフィールド番号からフィールド識別子を作成しておくと便利です。
Fmkfldidは、この機能を提供します。
FLDID
Fmkfldid(int
type, FLDID
num)
|
•
|
typeは、有効な型、 つまり整数です。(詳細は、 「Fldtype」を参照してください。)
|
|
•
|
numは、フィールド番号です。(既存のフィールドとの混同を避けるため、未使用のフィールド番号を指定する必要があります。)
|
大半のFML関数では、引数としてフィールド化バッファに対するポインタが必要です。このようなポインタを宣言するには、次の例のように、
typedef宣言をした
FBFRを使用できます。
この節では、変数
fbfrをフィールド化バッファに対するポインタとして使用します。フィールド化バッファ自体は宣言できません。宣言できるのは、フィールド化バッファに対するポインタだけです。
サーバーがFMLバッファが含まれているリクエストを受信すると、そのFMLバッファおよび
FLD_PTRフィールドによって参照される埋込みVIEWまたはバッファ用に領域が割り当てられます。新しいFMLバッファへのポインタがユーザー作成コードに渡されます。サーバー処理の完了時には、メッセージの受信時に割り当てられたすべてのバッファを破棄する必要があります。Oracle Tuxedoでは、FMLバッファおよびすべての従属バッファがチェックされ、参照が検出されるとバッファが削除されます。サーバー・コードを作成するプログラマは、次の状況を認識しておく必要があります。
|
•
|
サーバーによって割り当てられたバッファを参照するようにVIEWまたはポインタ・フィールドを追加、変更、または更新した場合、新たに割り当てられたバッファは、 tpreturn(3c)または tpforward(3c)関数の呼出しによって開始されるクリーンアップ中に削除されます。 |
|
•
|
フィールドを変更、更新、または削除してバッファがFMLバッファによって参照されなくなった場合、ユーザー作成コードで tpfree(3c)関数を使用して明示的にそのバッファを解放する必要があります。バッファが明示的に解放されていない場合、サーバー・プロセスでメモリー・リークが発生します。 |
|
•
|
tpreturn(3c)を呼び出すかわりに、ユーザー記述コードを使用して別のバッファを割り当て、戻すことができます。この場合、 tpreturn()に渡されたFMLバッファは解放されますが、 FLD_PTRフィールドまたは FLD_VIEW32フィールドによって参照されるバッファは解放されません。
|
この項では、フィールド化バッファの領域を確保するための関数について説明します。まず、指定されたバッファがフィールド化バッファであるかどうかを判別するための関数を説明します。
Fielded (または
Fielded32)を使用すると、指定されたバッファがフィールド化されているかどうかをテストできます。
Fielded32は32ビットのFMLと共に使用します。
Fieldedを使用すると、バッファがフィールド化されている場合はtrue (
1)が返されます。バッファがフィールド化されていない場合はfalse (
0)が返されます。この場合、
Ferrorは設定されません。
フィールド化バッファに割り当てるメモリー領域のサイズは、フィールド化バッファに指定できるフィールドの最大数と、すべてのフィールド値に必要な領域の合計サイズによって異なります。
Fneededを使用すると、フィールド化バッファに必要な領域(バイト単位)を判別できます。この関数には引数として、フィールド数とすべてのフィールド値に必要な領域(バイト単位)を指定します。
long
Fneeded(FLDOCC
F, FLDLEN
V)
|
•
|
Vは、フィールド値に必要な領域(バイト単位)です。
|
フィールド値に必要な領域は、各フィールド値が標準的な構造で格納された場合の領域を見積もることにより、算出できます。たとえば、
long型の値が
long型として格納されると、4バイトの領域が必要です。可変長フィールドの場合は、フィールドに必要な領域の平均値を見積もります。
Fneededで算出される領域には、フィールドごとの固定オーバーヘッドが含まれます。つまり、フィールド値に必要な領域には、オーバーヘッド分が加算されます。
Fneededを使用して必要な領域を見積もったら、
malloc(3)を使用して必要なバイト数を割り当て、割り当てたメモリー領域に対するポインタを設定できます。たとえば、次のコードでは、フィールド化バッファに対し、25個のフィールドと300バイトの値を格納できるだけの領域を割り当てています。
#define NF 25
#define NV 300
extern char *malloc;
. . .
if((fbfr = (FBFR *)malloc(Fneeded(NF, NV))) == NULL)
F_error("pgm_name"); /* no space to allocate buffer */
ただし、このコードで割り当てられたメモリー領域は、まだフィールド化バッファではありません。この領域は、
Finitを使用して初期化する必要があります。
Fvneeded関数を使用すると、
VIEWバッファに必要な領域(バイト単位)を判別できます。この関数には、引数として
VIEWの名前に対するポインタを指定します。
long
Fvneeded(char *
subtype)
Fvneeded関数は、
VIEWのサイズをバイト数で返します。
Finitは、割り当てられたメモリー領域をフィールド化バッファとして初期化します。
int
Finit(FBFR *
fbfr, FLDLEN
buflen)
|
•
|
fbfrは、初期化されていないフィールド化バッファを指すポインタです。
|
|
•
|
buflenは、バッファの長さ(バイト単位)です。
|
前述の例で割り当てたメモリー領域を初期化するために
Finitを呼び出す場合は、以下の形式を使用します。
Finit(fbfr, Fneeded(NF, NV));
この呼出しの結果、
fbfrは、初期化された空のフィールド化バッファを指します。
Fneeded(NF, NV)によって割り当てられた最大バイト数から、
fml.hで定義された
F_OVHD分を差し引いたバイト数を、バッファのフィールド領域として使用できます。
|
注意:
|
ただし、 malloc(3) (前の項を参照)への呼出しと Finitへの呼出しでは、同じ値を使用する必要があります。 |
Fneeded、
malloc(3)、および
Finitに対する呼出しは、
Fallocに対する1回の呼出しで置き換えることができます。この関数を使用すると、必要な領域を割り当て、バッファを初期化できます。
FBFR *
Falloc(FLDOCC F, FLDLEN V)
|
•
|
Vは、フィールド値に必要な領域(バイト単位)です。
|
前の3つの項で説明した、
Fneeded、
malloc()、および
Finitと同じ機能を実行する
Fallocへの呼出しは、次のようにコーディングします。
extern FBFR *Falloc;
. . .
if((fbfr = Falloc(NF, NV)) == NULL)
F_error(���pgm_name���); /* couldn't allocate buffer */
Ffreeは、フィールド化バッファとして割り当てられたメモリー領域を解放します。
Ffree32は、
FLD_PTRフィールドのポインタによって参照されるメモリー領域を解放しません。
fbfrは、フィールド化バッファに対するポインタです。次の例を検討してください:
#include <fml.h>
. . .
if(Ffree(fbfr) < 0)
F_error("pgm_name"); /* not fielded buffer */
free(3)より
Ffreeの使用をお薦めします。
free(3)ではフィールド化バッファを無効にできませんが、
Ffreeを使用するとフィールド化バッファを無効にできます。フィールド化バッファの無効化が必要なのは、
malloc(3)が解放されたメモリーをクリアせずに再利用するためです。
free(3)を使用すると、
mallocが無効化されていないフィールド化バッファを戻す可能性があります。
フィールド化バッファの領域を直接確保することもできます。フィールド化バッファは、
short型境界に調整させて開始する必要があります。バッファには、少なくとも
F_OVHD分のバイト(
fml.hで定義)を割り当てる必要があります。割り当てないと、
Finitからエラーが返されます。
以下のコードは、前の項の例と似ていますが、
Fneededはマクロではないため、静的バッファのサイズ指定には使用できません。
/* the first line aligns the buffer */
static short buffer[500/sizeof(short)];
FBFR *fbfr=(FBFR *)buffer;
. . .
Finit(fbfr, 500);
以下のようなコードは入力
しないように注意してください。
FBFR badfbfr;
. . .
Finit(&badfbfr, Fneeded(NF, NV));
このコードは間違いです。
FBFRの構造体がユーザーのヘッダー・ファイルで定義されていません。したがって、コンパイル時にエラーが発生します。
Fsizeofは、バイト単位でフィールド化バッファのサイズを返します。
fbfrは、フィールド化バッファに対するポインタです。たとえば、次のコードでは、
Fsizeofは、フィールド化バッファの当初の割当て時に
Fneededが返した数と同じ数を返します。
long bytes;
. . .
bytes = Fsizeof(fbfr);
Funusedを使用すると、フィールド化バッファの領域のうち、追加データを格納するために使用できる領域を判別できます。
fbfrは、フィールド化バッファに対するポインタです。次の例を検討してください:
long unused;
. . .
unused = Funused(fbfr);
Funusedは、バッファ内での未使用バイトの
位置は示しません。未使用バイトの
数のみが示されます。
Fusedを使用すると、フィールド化バッファの領域のうち、データおよびオーバーヘッドに使用されている領域を判別できます。
fbfrは、フィールド化バッファに対するポインタです。次の例を検討してください:
long used;
. . .
used = Fused(fbfr);
Fusedは、バッファ内での使用済バイトの
位置は示しません。使用済バイトの
数のみが示されます。
詳細は、
『Oracle Tuxedo ATMI FML関数リファレンス』の
Fused、Fused32(3fml)に関する項を参照してください。
この関数を使用すると、
Fallocを呼び出してすでに領域を割り当てたバッファのサイズを変更できます。
tpalloc(3c)で領域を割り当てた場合は、
tprealloc(3c)を呼び出して領域を再び割り当てます。バッファのサイズ変更機能は、新しいフィールド値を追加したために空き領域が不足した場合などに役立ちます。このような場合は、単に
Freallocを呼び出すだけでバッファのサイズを増やすことができます。また、
Freallocを呼び出してバッファのサイズを小さくすることもできます。
FBFR *
Frealloc(FBFR *
fbfr, FLDOCC
nf, FLDLEN
nv)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
nvは、新しいフィールド値の領域(バイト単位)です。
|
FBFR *newfbfr;
. . .
if((newfbfr = Frealloc(fbfr, NF+5, NV+300)) == NULL)
F_error(���pgm_name���); /* couldn't re-allocate space */
else
fbfr = newfbfr; /* assign new pointer to old */
この例では、アプリケーション側で、すでに割り当てられたフィールド数と値の領域のバイト数を認識している必要があります。
Freallocの引数(および対応する
realloc(3))は絶対値であり、インクリメント値ではありません。領域の割当てを複数回行う必要がある場合、このサンプル・コードは正しく動作しません。
以下の例では、割り当てられた領域をインクリメントする別の方法を示します。
/* define the increment size when buffer out of space */
#define INCR 400
FBFR *newfbfr;
. . .
if((newfbfr = Frealloc(fbfr, 0, Fsizeof(fbfr)+INCR)) == NULL)
F_error(���pgm_name���); /* couldn't re-allocate space */
else
fbfr = newfbfr; /* assign new pointer to old */
この例では、バッファが最後に初期化されたときのフィールド数や値の領域のサイズを知っておく必要はありません。したがって、サイズを増やす最も簡単な方法は、現在のサイズにインクリメント値を加えたサイズを値の領域として使用することです。上の例は、必要に応じて何回でも実行することができます。過去の実行内容や値を覚えておく必要はありません。
Freallocを呼び出した後で
Finitを呼び出す必要はありません。
Freallocに対する呼出しでリクエストした追加の領域が古いバッファと隣接している場合は、上の例の
newfbfrと
fbfrは同一になります。ただし、防御的プログラミングのために、
newfbfrを宣言しておき、新しい値またはNULL値が返されるのを防ぐ必要があります。
Freallocが失敗した場合、
fbfrは再使用しないでください。
|
注意:
|
バッファ・サイズは、現在バッファで使用されているバイト数までしか縮小できません。 |
フィールド化バッファの位置に関する唯一の制約は、フィールド化バッファを
short型境界に調整する必要があることです。それ以外の場合、フィールド化バッファは位置に依存せず、メモリー内で自由に移動できます。
srcがフィールド化バッファを指し、
destがフィールド化バッファを保持できるサイズのストレージ領域を指す場合は、以下のコードを使用してフィールド化バッファを移動できます。
FBFR *
src;
char *
dest;
. . .
memcpy(dest, src, Fsizeof(src));
Cの実行時メモリー管理関数の1つである
memcpyは、指定したバイト数のバッファ(3つ目の引数で指定)を、指定した領域(2つ目の引数で指定)から別の領域(1つ目の引数で指定)に移動します。
memcpyを使用するとフィールド化バッファをコピーできますが、コピー先のバッファは、コピー元と同じになります。たとえば、コピー先の空き領域のバイト数は、コピー元の空き領域のバイト数と同じです。
Fmoveは、
memcpyと同じように動作します。ただし、明示的に長さを指定する必要はありません(自動的に算出されます)。
int
Fmove(char *
dest, FBFR *
src)
|
•
|
srcは、ソース・フィールド化バッファに対するポインタです。
|
たとえば、次のコードでは、
Fmoveは、ソース・バッファがフィールド化バッファかどうかを確認しますが、このバッファの変更は行いません。
FBFR *src;
char *dest;
. . .
if(Fmove(dest,src) < 0)
F_error("pgm_name");
宛先バッファは、フィールド化バッファ(
Fallocで割り当てられたバッファ)でなくてもかまいませんが、
short型境界に調整されている必要があります(FML32では4バイト)。したがって、
Fmoveは、フィールド化バッファをフィールド化バッファ以外のバッファにコピーする必要があるときに、
Fcpyの代替関数として機能します。ただし
Fmoveは、宛先バッファに十分な領域があるかどうかの確認は行いません。
値が
FLD_PTR型の場合、
Fmove32はバッファ・ポインタを転送します。アプリケーション・プログラマは、対応するポインタの移動に応じてバッファの再割り当て、および解放を管理する必要があります。
FLD_PTRフィールドが指すバッファは、
tpalloc(3c)を呼び出して割り当てます。
Fcpyは、あるフィールド化バッファを別のフィールド化バッファで上書きするために使用します。
int
Fcpy(FBFR *
dest, FBFR *
src)
|
•
|
destは、宛先フィールド化バッファに対するポインタです。
|
|
•
|
srcは、ソース・フィールド化バッファに対するポインタです。
|
Fcpyは、上書きされたフィールド化バッファの全体の長さを保持するため、フィールド化バッファのサイズを拡大または縮小する場合に便利です。次の例を検討してください:
FBFR *src, *dest;
. . .
if(Fcpy(dest, src) < 0)
F_error(���pgm_name���);
Fmoveの
destは、初期化されていない領域を指す場合があります。しかし、
Fcpyの
destには、初期化されたフィールド化バッファ(
Fallocで割り当てられる)を指定する必要があります。さらに、
Fcpyは、
destに指定されたバッファが十分な大きさであるかどうかも検証します。
|
注意:
|
フィールド化バッファのサイズを、現在格納されているデータの領域より小さくすることはできません。 |
Fmoveと同様、ソース・バッファは
Fcpyによって変更されません。
値が
FLD_PTR型の場合、
Fcpy32はバッファ・ポインタをコピーします。アプリケーション・プログラマは、対応するポインタがコピーされたときのバッファの再割り当ておよび解放を管理する必要があります。
FLD_PTRフィールドが指すバッファは、
tpalloc(3c)を呼び出して割り当てます。
フィールドへのアクセスおよびフィールドの変更を行う関数
この項では、変換処理を行わずにフィールド型を使用して、フィールド化バッファにアクセスしたり、更新する方法を説明します。フィールド化バッファから、またはフィールド化バッファへのデータ転送時に、データ型を変換する関数の一覧については、
「変換を行う関数」を参照してください。
Faddは、フィールド化バッファに新しいフィールド値を追加します。
int
Fadd(FBFR *
fbfr, FLDID
fieldid, char *
value, FLDLEN
len)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
valueは、新しい値に対するポインタです。上の例は char*型を示していますが、実際に使用するときは、追加する値と同じ型を指定します。後の例を参照してください。
|
|
•
|
FLD_CARRAY型またはFLD_MBSTRING型の場合、lenは値の長さです。
|
バッファ内にフィールド・オカレンスがない場合は、フィールドが追加されます。1つまたは複数のフィールド・オカレンスがすでに存在する場合は、新しいフィールド・オカレンスとして値が追加され、現在指定されている最も大きい番号より1つ大きい番号が割り当てられます。(特定のオカレンスを追加するには、
Fchgを使用します。)
Faddには、フィールド値に対するポインタを指定し、フィールド値自体は指定しません。これは、フィールド値を取得したり、フィールド値を戻すその他の関数でも同じです。
フィールド長が固定されているフィールド型(
short型、
long型、
char型、
float型、
double型)、またはフィールド長を指定できるフィールド型(
string型)の場合、フィールド長を指定する必要ありません。フィールド長は無視されます。フィールド型が文字配列(
FLD_CARRAYまたは
FLD_MBSTRING)の場合は、フィールド長を指定する必要があります。フィールド長は
FLDLEN型で定義されます。たとえば、次のコードは、目的のフィールドのフィールド識別子を取得し、フィールド値をバッファに追加します。
FLDID fieldid, Fldid;
FBFR *fbfr;
. . .
fieldid = Fldid("fieldname");
if(Fadd(fbfr, fieldid, "new value", (FLDLEN)9) < 0)
F_error("pgm_name");
デフォルトでは、文字配列型がネイティブなフィールド型と見なされます。したがって、関数には値の長さを渡す必要があります。追加する値が文字配列以外の場合、
valueの型は、ポインタが指す値の型に応じて変わります。たとえば、次のコードは、long型のフィールド値を追加します。
long lval;
. . .
lval = 123456789;
if(Fadd(fbfr, fieldid, &lval, (FLDLEN)0) < 0)
F_error("pgm_name");
文字配列フィールドの場合、NULLフィールドは、長さ0で表します。文字列フィールドでは、フィールド値の一部としてNULL終了バイトが格納されるので、NULL文字列を格納できます。つまり、NULL終了バイトだけで構成される文字列は、長さ1であると見なされます。これ以外の型(固定長の型)では、アプリケーション・プログラムでNULLと解釈される特殊な値を使用できますが、値のサイズは、実際に渡される値とは関係なく、フィールド型で指定されます(たとえば、
long型の場合は長さ4)。NULL値のアドレスを渡すとエラー(
FEINVAL)が発生します。
ポインタ・フィールドの場合、
Fadd32はポインタ値を格納します。
FLD_PTRフィールドが指すバッファは、
tpalloc(3c)を呼び出して割り当てます。埋め込み型のFML32バッファの場合、
Fadd32は索引を除くすべての
FLD_FML32フィールド値を格納します。
埋め込み型のVIEW32バッファの場合、
Fadd32は
FVIEWFLD型の構造体に対するポインタを格納します。FVIEWFLD型の構造体には、vflags (現在未使用で
0に設定されているフラグ・フィールド)、
vname (VIEW名を含む文字配列)、および
data (C構造体として格納されるVIEWデータに対するポインタ)が含まれています。アプリケーションは、
Fadd32に
vnameと
dataを提供します。
FVIEWFLD構造体は、次のとおりです。
typedef struct {
TM32U vflags; /* flags - currently unused */
char vname[FVIEWNAMESIZE+1]; /* name of view */
char *data; /* pointer to view structure */
} FVIEWFLD;
Fappendは、フィールド化バッファに新しいフィールド値を付加します。
int
Fappend(FBFR *
fbfr, FLDID
fieldid, char *
value, FLDLEN
len)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
valueは、新しい値に対するポインタです。上の例は char*型を示していますが、実際に使用するときは、付加する値と同じ型を指定します。後の例を参照してください。
|
|
•
|
FLD_CARRAY型またはFLD_MBSTRING型の場合、lenは値の長さです。
|
Fappendは、
valueで定義された値を指定した、新しい
fieldidのフィールド・オカレンスを付加し、バッファを付加モードにします。付加モードでは、同じフィールド・セットを含む多数の行で構成された、サイズの大きいバッファが最適化されます。
次の例では、
Fappendを使用して、各行に5つのフィールドがある500行のバッファを作成します。
for (i=0; i 500 ;i++) {
if ((Fappend(fbfr, LONGFLD1, &lval1[i], (FLDLEN)0) < 0) ||
(Fappend(fbfr, LONGFLD2, &lval2[i], (FLDLEN)0) < 0) ||
(Fappend(fbfr, STRFLD1, &str1[i], (FLDLEN)0) < 0) ||
(Fappend(fbfr, STRFLD2, &str2[i], (FLDLEN)0) < 0) ||
(Fappend(fbfr, LONGFLD3, &lval3[i], (FLDLEN)0) < 0)) {
F_error("pgm_name");
break;
}
}
Findex(fbfr, 0);
Fappendには、フィールド値に対するポインタを指定し、フィールド値自体は指定しません。これは、フィールド値を取得したり、フィールド値を戻すその他の関数でも同じです。
フィールド長が固定されているフィールド型(
short型、
long型、
char型、
float型、
double型)、またはフィールド長を指定できるフィールド型(
string型)の場合、フィールド長を指定する必要ありません。フィールド長は無視されます。フィールド型が文字配列(
FLD_CARRAYまたは
FLD_MBSTRING)の場合は、フィールド長を指定する必要があります。フィールド長は
FLDLEN型で定義されます。
デフォルトでは、文字配列型がネイティブなフィールド型と見なされます。したがって、関数には値の長さを渡す必要があります。付加する値が文字配列以外の場合、
valueの型は、ポインタが指す値の型に応じて変わります。
文字配列フィールドの場合、NULLフィールドは、長さ0で表します。文字列フィールドでは、フィールド値の一部としてNULL終了バイトが格納されるので、NULL文字列を格納できます。つまり、NULL終了バイトだけで構成される文字列は、長さ1であると見なされます。これ以外の型(固定長の型)では、アプリケーション・プログラムでNULLと解釈される特殊な値を使用できますが、値のサイズは、実際に渡される値とは関係なく、フィールド型で指定されます(たとえば、
long型の場合は長さ4)。NULL値のアドレスを渡すとエラー(
FEINVAL)が発生します。
Fchgは、バッファ内のフィールド値を変更します。
int
Fchg(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, char *
value, FLDLEN
len)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
valueは、新しい値に対するポインタです。上の例は char *型を示していますが、実際に使用するときは、追加する値と同じ型を指定します( 「Fadd」を参照)。
|
|
•
|
FLD_CARRAY型またはFLD_MBSTRING型の場合、lenは値の長さです。
|
たとえば、次のコードは、
carray型のフィールドを
valueに格納された新しい値に変更します。
FBFR *fbfr;
FLDID fieldid;
FLDOCC oc;
FLDLEN len;
char value[50];
. . .
strcpy(value, "new value");
flen = strlen(value);
if(Fchg(fbfr, fieldid, oc, value, len) < 0)
F_error("pgm_name");
ocが -1の場合、フィールド値が新しいオカレンスとしてバッファに追加されます。
ocが0以上であり、フィールドが見つかった場合、フィールド値は指定された新しい値に変更されます。
ocが0以上であり、フィールドがない場合は、指定されたオカレンスとして値を追加できるまで、NULLオカレンスがバッファに追加されます。たとえば、バッファ上に存在しないフィールドのフィールド・オカレンス3を変更しようとすると、3つのNULLオカレンス(オカレンス0、1および2)が追加され、続いて、フィールド値が指定されたオカレンス3が追加されます。NULL値については、文字列型と文字型の値の場合はNULL文字列
「\0」(長さ1バイト)、long型とshort型のフィールドの場合は
0、float型とdouble型の値の場合は
0.0、文字配列の場合は0長の文字列が使用されます。
新しい値または変更された値は、
valueに格納されます。文字配列(
FLD_CARRAYまたは
FLD_MBSTRING)の場合、長さは
lenで指定されます。その他のフィールド型では、
lenは無視されます。値のポインタがNULLであり、フィールドが見つかった場合、そのフィールドは削除されます。削除対象のフィールド・オカレンスが見つからないと、エラー(
FNOTPRES)と見なされます。
ポインタ・フィールドの場合、
Fchg32にポインタ値が格納されます。
FLD_PTRフィールドが指すバッファは、
tpalloc(3c)を呼び出して割り当てます。埋め込み型のFML32バッファの場合、
Fchg32は、索引を除くすべての
FLD_FML32フィールドの値を格納します。
埋め込み型のVIEW32バッファの場合、
Fchg32は
FVIEWFLD型の構造体に対するポインタを格納します。FVIEWFLD型の構造体には、
vflags (現在未使用で
0に設定されているフラグ・フィールド)、
vname (VIEW名を含む文字配列)、および
data (C構造体として格納されるVIEWデータに対するポインタ)が含まれています。アプリケーションは、
vnameと
dataを
Fchg32に提供します。
FVIEWFLD構造体は、次のとおりです。
typedef struct {
TM32U vflags; /* flags - currently unused */
char vname[FVIEWNAMESIZE+1]; /* name of view */
char *data; /* pointer to view structure */
} FVIEWFLD;
バッファには、変更または追加されたフィールド値を格納できる領域が必要です。空き領域不足の場合、エラー(
FNOSPACE)が返されます。
Fcmpは、2つのフィールド化バッファのフィールド識別子とフィールド値を比較します。
int
Fcmp(FBFR *
fbfr1, FBFR *
fbfr2)
この場合、
fbfr1および
fbfr2はフィールド化バッファを指すポインタです。
この関数は、2つのバッファが同一の場合は
0を返し、以下の条件のいずれかが成立する場合は
-1を返します。
|
•
|
fbfr1フィールドの フィールド識別子が、対応する fbfr2フィールドのフィールド識別子より小さい。
|
|
•
|
fbfr1フィールドの値が、対応する fbfr2フィールドの値より小さい。
|
ポインタと埋め込み型のバッファが等価であるかどうか、次の条件に基づいて判別されます。
|
•
|
ポインタ・フィールドの場合、ポインタ値(アドレス)が同じであれば2つのポインタ・フィールドは同一と見なされます。 |
|
•
|
埋め込み型のFML32バッファの場合、すべてのフィールド・オカレンスと値が同じであれば、2つのフィールドは同一と見なされます。 |
|
•
|
埋め込み型のVIEW32バッファの場合、VIEW名が同じであり、さらに、すべての構造体メンバーのオカレンスと値が同じであれば、2つのフィールドは同一と見なされます。 |
Fcmpは、上記のいずれかの条件の逆がtrueである場合に
1を返します。たとえば、
fbfr2フィールドのフィールド識別子が
fbfr1フィールドの対応するフィールド識別子より小さい場合、
Fcmpは
1を返します。
Fdelは、指定されたフィールド・オカレンスを削除します。
int
Fdel(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
たとえば、次のコードは、指定されたフィールド識別子が示すフィールドの最初のオカレンスを削除します。
FLDOCC occurrence;
. . .
occurrence=0;
if(Fdel(fbfr, fieldid, occurrence) < 0)
F_error("pgm_name");
指定されたフィールドが存在しない場合は
-1が返され、
Ferrorが
FNOTPRESに設定されます。
ポインタ・フィールドの場合、
Fdel32は、参照されるバッファを変更したり、ポインタを解放しないで、
FLD_PTRフィールド・オカレンスを削除します。データ・バッファは、オペークなポインタとして扱われます。
Fdelallは、指定されたフィールドのすべてのオカレンスをバッファから削除します。
int
Fdelall(FBFR *
fbfr, FLDID
fieldid)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
if(Fdelall(fbfr, fieldid) < 0)
F_error("pgm_name"); /* field not present */
フィールドが検出されなかった場合は
-1が返され、
Ferrorが
FNOTPRESに設定されます。
ポインタ・フィールドの場合、
Fdelall32は、参照されるバッファを変更したり、ポインタを解放しないで、
FLD_PTRフィールド・オカレンスを削除します。データ・バッファは、オペークなポインタとして扱われます。
Fdeleteは、フィールド識別子の配列(
fieldid[])にリストされているすべてのフィールドのすべてのオカレンスを削除します。
int
Fdelete(FBFR *
fbfr, FLDID *
fieldid)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、削除対象となるフィールド識別子のリストに対するポインタです。
|
フィールド化バッファが直接更新されます。フィールド識別子の配列は特定の順番になっている必要はありませんが、配列の最後のエントリは、フィールド識別子0 (
BADFLDID)である必要があります。次の例を検討してください:
#include "fldtbl.h"
FBFR *dest;
FLDID fieldid[20];
. . .
fieldid[0] = A; /* field id for field A */
fieldid[1] = D; /* field id for field D */
fieldid[2] = BADFLDID; /* sentinel value */
if(Fdelete(dest, fieldid) < 0)
F_error("pgm_name");
宛先バッファに、A、B、C、Dという4つのフィールドがある場合、上記の例では、フィールドBおよびフィールドCのオカレンスのみを含むバッファが生成されます。
Fdeleteを使用すると、
Fdelallを数回呼び出す場合より効率的にバッファから複数のフィールドを削除できます。
ポインタ・フィールドの場合、
Fdeleteは、参照されるバッファを変更したり、ポインタを解放しないで、
FLD_PTRフィールド・オカレンスを削除します。データ・バッファは、オペークなポインタとして扱われます。
Ffindは、バッファ内の指定されたフィールド・オカレンスの値を検索します。
char *
Ffind(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, FLDLEN *
len)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
上の例では、
Ffindの戻り値として、文字ポインタのデータ型(Cの
char*)が示されています。実際に返されるポインタの型は、ポインタが指す値の型と同じです。
#include "fldtbl.h"
FBFR *fbfr;
FLDLEN len;
char* Ffind, *value;
. . .
if((value=Ffind(fbfr,ZIP,0, &len)) == NULL)
F_error("pgm_name");
フィールドが見つかると、フィールドの長さが
len内に返され(
lenがNULLの場合は、長さは返されない)、フィールドの位置が関数の値として返されます。フィールドが見つからないと、NULLが返され、
Ferrorが
FNOTPRESに設定されます。
Ffindは、フィールドの読取り専用アクセス権を取得する場合に使用できます。
Ffindによって返された値を使用してバッファを変更することはできません。フィールド値は
Faddまたは
Fchg関数のみを使用して変更してください。この関数は、埋込み型のバッファにある指定されたフィールドのオカレンスは調べません。
Ffindからの戻り値は、バッファが変更されない限り有効です。この値は、short型境界では確実に調整されますが、long型またはdouble型の境界では、フィールド型がlong型またはdouble型でも、調整されない場合があります。(値の調整については、この章の後の説明を参照してください。)変数を正しく境界に調整する必要があるプロセッサでは、正しく調整されていない値を参照すると、システム・エラーが発生します。次は、その例です。
long *l1,l2;
FLDLEN length;
char *Ffind;
. . .
if((l1=(long *)Ffind(fbfr, ZIP, 0, &length)) == NULL)
F_error("pgm_name");
else
l2 = *l1;
このコードは、次のように書き直さなければなりません。
if((l1==(long *)Ffind(fbfr, ZIP, 0, &length)) == NULL)
F_error("pgm_name");
else
memcpy(&l2,l1,sizeof(long));
この関数は、フィールド化バッファ内のフィールドの最後のオカレンスを検索し、そのフィールドに対するポインタと、最後のフィールド・オカレンスのオカレンス番号と長さを返します。
char *
Ffindlast(FBFR *
fbfr, FLDID
fieldid, FLDOCC *
oc, FLDLEN *
len)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
ocは、検索対象の最後のフィールド・オカレンスのオカレンス番号に対するポインタです。
|
|
•
|
lenは、検索対象の値の長さに対するポインタです。
|
上の例では、
Ffindlastの戻り値として、文字ポインタのデータ型(Cの
char*)が示されています。実際に返されるポインタの型は、ポインタが指す値の型と同じです。
Ffindlastは、
Ffindと同様に動作します。ただし、フィールド・オカレンスを指定する必要はなく、 関数の戻り値として、最後のフィールド・オカレンスのオカレンス番号と値が返されます。関数の呼出し時にオカレンスにNULLを指定すると、オカレンス番号は返されません。この関数は、埋込み型のバッファにある指定されたフィールドのオカレンスは調べません。
Ffindlastによって返される値は、バッファが変更されない限り有効です。
Ffindoccは、バッファ内の指定したフィールドのオカレンスを調べ、ユーザー指定のフィールド値と一致する最初のフィールド・オカレンスのオカレンス番号を返します。
FLDOCC
Ffindocc(FBFR *
fbfr, FLDID
fieldid, char *
value, FLDLEN
len;)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
valueは、新しい値に対するポインタです。上の例は char *型を示していますが、実際に使用するときは、追加する値と同じ型を指定します( 「Fadd」を参照)。
|
|
•
|
FLD_CARRAY型またはFLD_MBSTRING型の場合、lenは値の長さです。
|
たとえば、次のコードは、
ocを、指定された郵便番号のオカレンスに設定します。
#include "fldtbl.h"
FBFR *fbfr;
FLDOCC oc;
long zipvalue;
. . .
zipvalue = 123456;
if((oc=Ffindocc(fbfr,ZIP,&zipvalue, 0)) < 0)
F_error("pgm_name");
文字列フィールドでは、正規表現がサポートされています。たとえば、次のコードは、
ocを「J」で始まる
NAMEのオカレンスに設定します。
#include "fldtbl.h"
FBFR *fbfr;
FLDOCC oc;
char *name;
. . .
name = "J.*"
if ((oc = Ffindocc(fbfr, NAME, name, 1)) < 0)
F_error("pgm_name");
|
注意:
|
ただし、文字列上でのパターン照合を可能にするには、 Ffindoccの4番目の引数を0以外にする必要があります。この引数が0の場合、単純な文字列比較が実行されます。フィールド値が見つからない場合は、 -1が返されます。 |
上方互換性のため、接頭辞としてアクセント記号(
^)、また接尾辞としてドル記号(
$)が正規表現に暗黙的に追加されます。したがって、前の例にある正規表現は、実際には
「^(J.*)$」として解釈されます。正規表現は、フィールド内の文字列値全体と一致しなければなりません。
Fgetは、値が変更されたときに、フィールド化バッファのフィールドを検索するために使用されます。
int
Fget(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, char *
loc, FLDLEN *maxlen)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
locは、フィールド値のコピー先バッファに対するポインタです。
|
|
•
|
maxlenは、関数が呼び出されたときにソース・バッファの長さを参照し、フィールドの長さを戻すポインタです。
|
呼出し側プログラムは、
Fgetにプライベート・バッファに対するポインタとプライベート・バッファの長さを提供します。
maxlenをNULLとして指定すると、宛先バッファはフィールド値を格納できるだけのサイズを持つと想定され、バッファの長さは返されません。
Fgetは、指定したフィールドがバッファ内に存在しない場合(
FNOTPRES)、または宛先バッファが小さすぎる場合(
FNOSPACE)、エラーを返します。たとえば、次のコードは、郵便番号を取得します(文字配列または文字列として格納されていると仮定)。
FLDLEN len;
char value[100];
. . .
len=sizeof(value);
if(Fget(fbfr, ZIP, 0, value, &len) < 0)
F_error("pgm_name");
郵便番号が
long型として格納されている場合は、次のコードで郵便番号を取得できます。
FLDLEN len;
long value;
. . .
len = sizeof(value);
if(Fget(fbfr, ZIP, 0, value, &len) < 0)
F_error("pgm_name");
Fgetallocは、
Fgetと同じく、バッファ・フィールドを検索し、そのコピーを作成します。ただし、フィールドの領域は、
malloc(3)への呼出しによって取得します。
char *
Fgetalloc(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, FLDLEN *
extralen)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
extralenは、取得する長さに対するポインタ(関数の呼出し時)、または取得した実際の長さに対するポインタ(関数の復帰時)です。
|
上記の例では、
Fgetallocの戻り値として、文字ポインタのデータ型(Cの
char*)が示されています。実際に返されるポインタの型は、ポインタが指す値の型と同じです。
Fgetallocが成功すると、正しく境界に調整されたバッファ・フィールドのコピーに対する有効なポインタが返されます。失敗すると、NULLが返されます。
malloc(3)が失敗すると、
Fgetallocからエラーが返され、
Ferrorが
FMALLOCに設定されます。
Fgetallocの最後のパラメータには、予備の領域を指定します。たとえば、空き領域が不足した場合に、フィールド化バッファに値を再度指定する代わりに、取得済の領域を拡張する場合に取得する領域です。成功すると、割り当てられたバッファの長さが
extralenに返されます。次の例を検討してください:
FLDLEN extralen;
FBFR *fieldbfr
char *Fgetalloc;
. . .
extralen = 0;
if (fieldbfr = (FBFR *)Fgetalloc(fbfr, ZIP, 0, &extralen) == NULL)
F_error("pgm_name");
Fgetallocで取得した領域を
freeで解放する処理は、呼出し側プログラムの役割です。
Fgetlastは、値の変更時にフィールド化バッファからフィールドの最後のオカレンスを検索するために使用します。
int
Fgetlast(FBFR *
fbfr, FLDID
fieldid, FLDOCC *
oc, char *
loc, FLDLEN *
maxlen)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
ocは、最後のフィールド・オカレンスのオカレンス番号に対するポインタです。
|
|
•
|
locは、フィールド値のコピー先バッファに対するポインタです。
|
|
•
|
maxlenは、関数が呼び出されたときにソース・バッファの長さを参照し、フィールドの長さを戻すポインタです。
|
呼出し側プログラムは、
Fgetlastにプライベート・バッファに対するポインタとブライペート・バッファの長さを提供します。
Fgetlastは、
Fgetと同様に動作します。ただし、フィールド・オカレンスを指定する必要はなく、 関数の戻り値として、最後のフィールド・オカレンスのオカレンス番号と値が返されます。ただし、
occにNULLを指定して関数を呼び出すと、オカレンス番号は返されません。
Fnextは、指定されたフィールド・オカレンスの次のフィールドをバッファ内で検索します。
int
Fnext(FBFR *
fbfr, FLDID *
fieldid, FLDOCC *
oc, char *
value, FLDLEN *
len)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、フィールド識別子に対するポインタです。
|
|
•
|
valueは、次のフィールドに含まれる値と同じ型のポインタです。
|
|
•
|
lenは、 *valueの指す長さに対するポインタです。
|
バッファ内の最初のフィールドを取得するには、
fieldidに
FIRSTFLDIDを代入します。フィールド識別子と最初のフィールド・オカレンスのオカレンス番号が対応するパラメータ内に返されます。フィールドがNULLでない場合は、フィールド値が
valueポインタでアドレス指定されたメモリー位置にコピーされます。
lenパラメータを使用すると、フィールド値を格納できるだけの領域が
valueに割り当てられているかどうかを判別できます。十分な領域が割り当てられていない場合は、
Ferrorが
FNOSPACEに設定されます。値の長さが
lenパラメータ内に返されます。ただし、フィールドの値がNULLでない場合、
lenパラメータは、
valueに現在割り当てられている領域の長さも含んでいると見なします。
取り出されるフィールドが埋め込み型のVIEW32バッファのときは、
valueパラメータは
FVIEWFLD構造体を指します。
Fnext関数は、構造体の
vnameフィールドと
dataフィールドを設定します。
FVIEWFLD構造体は、次のとおりです。
typedef struct {
TM32U vflags; /* flags - currently unused */
char vname[FVIEWNAMESIZE+1]; /* name of view */
char *data; /* pointer to view structure */
} FVIEWFLD;
フィールド値がNULLの場合は、
valueパラメータと
lengthパラメータは変更されません。
フィールドがそれ以上見つからない場合は、
Fnextは
0を返し(バッファの終わり)、
fieldid、
occurrence、
valueは変更されません。
valueパラメータがNULLでない場合、
lengthパラメータもNULLでないと見なされます。
以下の例は、バッファ内のすべてのフィールド・オカレンスを読み取ります。
FLDID fieldid;
FLDOCC occurrence;
char *value[100];
FLDLEN len;
. . .
for(fieldid=FIRSTFLDID,len=sizeof(value);
Fnext(fbfr,&fieldid,&occurrence,value,&len) > 0;
len=sizeof(value)) {
/* code for each field occurrence */
}
Fnumは、指定されたバッファに含まれているフィールド数を返します。エラーの場合は
-1を返します。
fbfrは、フィールド化バッファに対するポインタです。たとえば、次のコードは、指定されたバッファ内のフィールド数を出力します。
if((cnt=Fnum(fbfr)) < 0)
F_error("pgm_name");
else
fprintf(stdout,"%d fields in buffer\n",cnt);
FLD_FML32および
FLD_VIEW32フィールドは、格納するフィールド数に関係なく、単一フィールドとしてカウントされます。
Foccurは、バッファ内の指定されたフィールドのオカレンス数を返します。
FLDOCC
Foccur(FBFR *
fbfr, FLDID
fieldid)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
埋め込み型のFML32バッファ内でのフィールドのオカレンスはカウントされません。
フィールド・オカレンスがバッファ内にない場合は0が返され、エラーの場合は
-1が返されます。たとえば、次のコードは、指定されたバッファ内のフィールド
ZIPのオカレンス数を出力します。
FLDOCC cnt;
. . .
if((cnt=Foccur(fbfr,ZIP)) < 0)
F_error("pgm_name");
else
fprintf(stdout,"Field ZIP occurs %d times in buffer\n",cnt);
Fpresは、指定フィールド・オカレンスが存在する場合にtrue (1)を返します。それ以外の場合は、false (0)を返します。
int
Fpres(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
たとえば、次のコードは、
fbfrが指すフィールド化バッファ内にフィールド
ZIPが存在する場合、trueを返します。
Fpresは、埋込み型のバッファ内で指定されたフィールドのオカレンスをチェックしません。
Fvalsは、
string値の場合は
Ffindと同じように動作しますが、値に対するポインタを必ず返します。
Fvallは、
long型および
short型の値の場合は、
Ffindと同じように動作しますが、実際のフィールド値を、値に対するポインタのかわりに
long型で返します。
char*
Fvals(FBFR *fbfr,FLDID fieldid,FLDOCC oc)
char*
Fvall(FBFR *fbfr,FLDID fieldid,FLDOCC oc)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
Fvalsの場合、指定されたフィールド・オカレンスが見つからないと、NULL文字列
\0を返します。この関数は、戻り値をチェックせずにフィールドの値を別の関数に渡すのに役立ちます。ただし、この関数は、
string型のフィールドの場合のみ有効であり、ほかのフィールド型の場合は、自動的にNULL文字列を返します(つまり、変換は行われません)。
Fvallの場合、指定されたフィールド・オカレンスが見つからないと、0を返します。この関数は、戻り値をチェックせずにフィールドの値を別の関数に渡すのに役立ちます。ただし、この関数は、
long型と
short型のフィールドの場合のみ有効であり、ほかのフィールド型の場合は、自動的に0を返します(つまり、変換は行われません)。
この項では、バッファ内の個々のフィールドではなく、フィールド化バッファ全体にアクセスし、内容を更新する関数を説明します。これらの関数では、最大3つのパラメータしか使用されません。
|
•
|
destは、宛先フィールド化バッファに対するポインタです。
|
|
•
|
srcは、ソース・フィールド化バッファに対するポインタです。
|
|
•
|
fieldidは、フィールド識別子またはフィールド識別子の配列です。
|
Fconcatは、ソース・バッファのフィールドを、既存の宛先バッファのフィールドに追加します。
int
Fconcat(FBFR *
dest, FBFR *
src)
宛先バッファ内のオカレンスは保持されます。つまり、このオカレンスは変更されません。新しいオカレンス、つまり、ソース・バッファから取得されたオカレンスには、宛先フィールドの既存のオカレンス番号より大きい番号が設定され、宛先バッファに追加されます。フィールドは、フィールド識別子の順序で保持されます。
FBFR *src, *dest;
. . .
if(Fconcat(dest,src) < 0)
F_error("pgm_name");
destに2つのフィールド(A、B)と2つのオカレンスを持つフィールドCがあり、
srcに3つのフィールド(A、C、D)があるとします。この結果、
destには、2つのオカレンスを持つフィールドA (宛先のフィールドAとソースのフィールドA)、フィールドB、3つのオカレンスを持つフィールドC (
destの2つのオカレンスと
srcのオカレンス)、およびフィールドDが設定されます。
新しいフィールドを格納できるだけの領域がない場合(
FNOSPACEが返された場合)、この処理は失敗し、宛先バッファは変更されません。
Fjoinは、フィールド識別子とオカレンスの組合せに基づき、2つのフィールド化バッファを結合します。
int
Fjoin(FBFR *
dest, FBFR *
src)
フィールド識別子とオカレンスの組合せが一致するフィールド間では、宛先バッファの値がソース・バッファの値で更新されます。ソース・バッファ内に、対応するフィールド識別子とオカレンスの組合せがない場合、宛先バッファのフィールドは削除されます。宛先バッファ内に、対応するフィールド識別子とオカレンスの組合せがない場合、ソース・バッファ内のフィールドは、宛先バッファに追加されません。次の例を参照してください。
if(Fjoin(dest,src) < 0)
F_error("pgm_name");
前述の例で使用した入力バッファを使用すると、ソース・フィールド値Aとソース・フィールド値Cを持つ宛先バッファが生成されます。新しい値が古い値より大きい場合は、この関数は領域の不足のために失敗することがあります(
FNOSPACE)。その場合、宛先バッファは変更されていると予測されます。ただし、この事態が発生した場合、
Frealloc関数と
Fjoin関数を繰り返し使用すると、宛先バッファを再割当てできます(宛先バッファが部分的に更新されてしまった場合でも、これらの関数を繰り返し使用すると、正しい結果が得られます)。
バッファの結合によってポインタ・フィールド(
FLD_PTR)が削除されると、ポインタが参照するメモリー領域は、変更も解放もされません。
Fojoinは、
Fjoinと似ていますが、ソース・バッファ内に対応するフィールド識別子とオカレンスの組合せがない宛先バッファのフィールドの削除は行いません。
int
Fojoin(FBFR *
dest, FBFR *
src)
宛先バッファ内に対応するフィールド識別子とオカレンスの組合せがないソース・バッファ内のフィールドは、宛先バッファに追加されません。次の例を検討してください:
if(Fojoin(dest,src) < 0)
F_error("pgm_name");
前記の例で使用した入力バッファを使用すると、この呼出しの結果の
destには、ソース・フィールド値A、宛先フィールド値B、ソース・フィールド値Cが含まれます。
Fjoinの場合のように、この関数は、領域の不足のために失敗する場合があり(
FNOSPACE)、その場合は、領域をさらに割り当てた後で関数を再発行すると、処理を完了できます。
バッファの結合によってポインタ・フィールド(
FLD_PTR)が削除されると、ポインタが参照するメモリー領域は、変更も解放もされません。
Fprojは、目的のフィールドのみが保存されるように、バッファの適切な箇所を更新します。(つまり、結果として、指定されたフィールドのプロジェクションが行われます。)バッファの更新によってポインタ・フィールド(
FLD_PTR)が削除されると、ポインタが参照するメモリー領域は、変更も解放もされません。
int
Fproj(FBFR *
fbfr, FLDID *
fieldid)
これらのフィールドは、この関数に渡されるフィールド識別子の配列で指定されます。更新は、フィールド化バッファ内で直接実行されます。次の例を検討してください:
#include "fldtbl.h"
FBFR *fbfr;
FLDID fieldid[20];
. . .
fieldid[0] = A; /* field id for field A */
fieldid[1] = D; /* field id for field D */
fieldid[2] = BADFLDID; /* sentinel value */
if(Fproj(fbfr, fieldid) < 0)
F_error("pgm_name");
バッファにA、B、Cの各フィールドがある場合は、上記の例の結果として、フィールドAとフィールドDのオカレンスのみを含むバッファが生成されます。ただし、フィールド識別子の配列内のエントリは、特定の順序で並べる必要はありませんが、フィールド識別子0 (
BADFLDID)がフィールド識別子の配列の最後の値でなければなりません。
Fprojcpyは
Fprojと似ていますが、目的のフィールドは宛先バッファに配置されます。バッファの更新によってポインタ・フィールド(
FLD_PTR)が削除されると、ポインタが参照するメモリー領域は、変更も解放もされません。
int
Fprojcpy(FBFR *
dest, FBFR *
src, FLDID *
fieldid)
まず、宛先バッファ内のすべてのフィールドが削除され、ソース・バッファでのプロジェクションの結果が宛先バッファにコピーされます。上記の例を使って、次のコードではプロジェクションの結果が宛先バッファに格納されます。
if(Fprojcpy(dest, src, fieldid) < 0)
F_error("pgm_name");
フィールド識別子の配列内のエントリは、再配置される場合があります。つまり、フィールド識別子の配列は、それらのエントリが番号順になっていないとソートされます。
Fupdateは、ソース・バッファ内のフィールド値で宛先バッファを更新します。
int
Fupdate(FBFR *
dest, FBFR *
src)
フィールド識別子とオカレンスの組合せが一致するフィールドの場合、フィールド値は、ソース・バッファ内の値によって宛先バッファ内で更新されます(
Fjoinと同じ)。ソース・バッファに対応するフィールドがない宛先バッファのフィールドは、変更されません(
Fojoinと同じ)。宛先バッファに対応するフィールドのないソース・バッファのフィールドは、宛先バッファに追加されます(
Fconcatと同じ)。次の例を検討してください:
if(Fupdate(dest,src) < 0)
F_error("pgm_name");
srcバッファにフィールドA、C、Dという3つのフィールドがあり、
destバッファにフィールドA、Bという2つのフィールドと、フィールドCの2つのオカレンスがある場合、結果はソース・フィールドA、宛先フィールドB、ソース・フィールドC、2つ目の宛先フィールドC、およびソース・フィールドDになります。
ポインタの場合、
Fupdate32にポインタ値が格納されます。
FLD_PTRフィールドが指すバッファは、
tpalloc(3c)を呼び出して割り当てます。埋め込み型のFML32バッファの場合、
Fupdate32は、索引を除くすべての
FLD_FML32フィールドの値を格納します。
埋め込み型のVIEW32バッファの場合、
Fupdate32は
FVIEWFLD型の構造体に対するポインタを格納します。FVIEWFLD型の構造体には、
vflags (現在未使用で
0に設定されているフラグ・フィールド)、
vname (VIEW名を含む文字配列)、および
data (C構造体として格納されるVIEWデータに対するポインタ)が含まれています。アプリケーションは、
Fupdate32に
vnameおよび
dataを提供します。
FVIEWFLD構造体は、次のとおりです。
typedef struct {
TM32U vflags; /* flags - currently unused */
char vname[FVIEWNAMESIZE+1]; /* name of view */
char *data; /* pointer to view structure */
} FVIEWFLD;
この関数は、指定されたVIEW記述を使用して、フィールド化バッファからC構造体へデータを転送します。
int
Fvftos(FBFR *
fbfr, char *
cstruct, char *
view)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
viewは、VIEW記述名の文字列に対するポインタです。
|
指定されたVIEWが見つからない場合、
Fvftosから
-1が返され、
Ferrorが
FBADVIEWに設定されます。
フィールド化バッファからC構造体へのデータ転送時には、以下の規則が適用されます。
|
•
|
C構造体のメンバーにマッピングされていないフィールド化バッファのフィールドは無視されます。 |
|
•
|
フィールド化バッファ内には存在しなくても、VIEW記述には記述されており、構造体メンバーにマッピングされているフィールドの場合は、対応するNULL値がメンバー内にコピーされます。 |
|
•
|
フィールド化バッファのフィールドが string型または carray型のデータを含む場合は、最大でマッピング先の構造体メンバーのサイズまで文字がコピーされます(それ以上のマッピング元の値は切り捨てられます)。マッピング元の値がマッピング先の構造体メンバーよりも短い場合は、メンバー値の残りにNULL文字(0)が埋め込まれます。string型の値は、値を切り捨てても、必ずNULL文字で終了します。 |
|
•
|
バッファ内のフィールドのオカレンス数がマッピング先の構造体メンバーの数と等価の場合は、フィールド化データがC構造体にコピーされます。 |
|
•
|
バッファ内のフィールドのオカレンス数がマッピング先の構造体メンバーの数より多い場合は、フィールド化データは無視されます。 |
|
•
|
バッファ内のフィールドのオカレンス数がマッピング先の構造体メンバーの数より少ない場合は、余分なメンバーには対応するNULL値が割り当てられます。 |
たとえば、次のコードは、
string1を
cust.action[0]に格納し、
abcを
cust.bug[0]に格納します。
cust構造体内のほかのすべてのメンバーにはNULL値を格納します。
#include <stdio.h>
#include "fml.h"
#include "custdb.flds.h"
#include "custdb.h"
struct custdb cust;
FBFR *fbfr;
. . .
fbfr = Falloc(800,1000);
Fvinit((char *)&cust,"custdb"); /* initialize cust */
str = "string1";
Fadd(fbfr,ACTION,str,(FLDLEN)8);
str = "abc";
Fadd(fbfr,BUG_CURS,str,(FLDLEN)4);
Fvftos(fbfr,(char *)&cust,"custdb");
. . .
この関数は、指定されたVIEW記述を使用して、C構造体からフィールド化バッファへデータを転送します。
int
Fvstof(FBFR *
fbfr, char *
cstruct, int
mode, char *
view)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
modeは、 FUPDATE、 FJOIN、 FOJOIN、または FCONCATのいずれかです。
|
|
•
|
viewは、VIEW記述名の文字列に対するポインタです。
|
指定されたVIEWが見つからない場合、
Fvstofから
-1が返され、
Ferrorが
FBADVIEWに設定されます。
|
注意:
|
NULL値は、構造体メンバーからフィールド化バッファに転送されません。つまり、構造体からフィールドへの転送時には、構造体メンバーに対して定義されたデフォルト設定またはユーザー指定のNULL値が構造体メンバーに含まれていると、そのメンバーは無視されます。 |
Fvnullは、C構造体内のオカレンスにそのフィールド用のNULL値が含まれているかどうかを判別します。
int
Fvnull(char *
cstruct, char *
cname, FLDOCC
oc, char *
view)
|
•
|
cnameは、構造体メンバーの名前に対するポインタです。
|
|
•
|
viewは、VIEW記述名の文字列に対するポインタです。
|
この関数は、適切なNULL値でC構造体内のすべての要素を初期化します。
int
Fvsinit(char *
cstruct, char *
view)
|
•
|
viewは、VIEW記述名の文字列に対するポインタです。
|
この関数は、実行時にフラグ・オプションを変更します。
int
Fvopt(char *
cname, int
option, char *
view)
|
•
|
viewは、VIEW記述名の文字列に対するポインタです。
|
以下は、
optionパラメータに指定できる値の一覧です。
フィールド化バッファからC構造体への一方向マッピングを指定します。VIEW記述の
Sオプションと同じように機能します。
C構造体からフィールド化バッファへの一方向マッピングを指定します。VIEW記述の
Fオプションと同じように機能します。
C構造体とフィールド化バッファの間の双方向マッピングを指定します。
指定されたメンバーのマッピングを無効にします。VIEW記述の
Nオプションと同じように機能します。
VIEW記述への変更は永久に保持されるわけではありません。変更内容の有効期間は、別のVIEW記述に対してアクセスが行われるときまでです。
この関数は、C構造体の個々のメンバーを、適切なNULL値に初期化します。この関数は、viewfile内で
Cフラグが使用されていると、要素のACMを0に設定します。viewfile内で
Lフラグが使用されていると、要素のALMを対応するNULL値の長さに設定します。
int
Fvselinit(char *
cstruct, char *
cname, char *
view)
|
•
|
cnameは、構造体メンバーの名前に対するポインタです。
|
|
•
|
viewは、VIEW記述名の文字列に対するポインタです。
|
この項では、次のトピックですべてのRECORD関数について説明します。COBOLプログラムでは、RECORD関数を直接使用できません。
RECORD関数は、RECORDバッファと呼ばれる記憶構造を定義および操作するために使用されます。RECORDバッファは、COBOLコピーブックへのアクセスを提供します。
RECORD記述は、COBOLコピーブックから
cpy2recordを使用してバイナリ形式で作成および格納され、Cプログラムで使用できます。
RECORDFILESおよび
RECORDDIR環境変数を使用してRECORD構造体を処理するために、実行時にRECORD記述ファイルが使用されます。
RECORDFILESには、所定のアプリケーション・プログラム用のRECORD記述ファイルをカンマで区切ってリストします。フル・パス名で指定したファイルは、そのまま使用されます。相対パス名で指定したファイルは、
RECORDDIRで指定したディレクトリのリストから検索されます。
RECORDDIRには、相対ファイル名を指定したRECORD記述ファイルを検索するために使用する、コロンで区切ったディレクトリのリストを指定します。
RECORDバッファのポインタは
RECORD *型で、
tpalloc ("
RECORD"、
subtype、
size)は、
RECORD *型のポインタを返します。レコード名(
subtype)の最大長は32バイトで、レコード名の長さが16を超える場合、
tptypes (
char *ptr、
char *type、
char *subtype)は、
RECORD *ポインタが完全な長さのレコード名の最初をポイントする場合に、最初の16バイトのサブタイプを移入します。
ほとんどのRECORD関数は、1つまたは複数の戻り値を返します。エラーの条件は、エラーの他には考えられない戻り値で示されます。エラーの場合はこれは通常-1です。エラー・タイプは、外部整数
Ferror32でも使用可能になります。
Ferror32は、正常呼出しではクリアされないので、エラーが示された後でのみテストします。
標準エラー出力にメッセージを生成するために、
F_error32()関数があります。これは1つのパラメータ(文字列)を取り、引数の文字列にコロンと空白を付けて出力し、改行文字の後にエラー・メッセージを出力します。表示されるエラー・メッセージは、エラー発生時に設定された
Ferror32内の現在のエラー番号に対して定義されているメッセージです。
メッセージ・カタログからエラー・メッセージのテキストを検索するには、Fstrerror32()を使用できます。これらは、userlogへの引数として使用できるポインタを返します。
エラー・コードのうち、RECORD関数で生成できるものについては、マニュアルのRECORDの項目で説明しています。
Rinit()関数は、割り当てられたRECORDバッファを初期化します。
Rinit(RECORD *rec, char *data, int len, int flags)
次の表は、
Rinit()関数の引数を示しています。
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
リクエストのデータ部分のアドレスを含むポインタ。 dataがNULLである場合、 recは0に初期化されます。 dataがNULLでなく lenが0より大きい場合、データ長 lenはデータから recのデータ・セクションにコピーされます。また、 dataがNULLでなく lenが0の場合は、 recのサイズに応じて、データが recのデータ・セクションにコピーされます。 |
|
|
dataで参照されるバッファ内のリクエスト・データの長さ。
|
|
|
フラグ・オプション(文字セットおよびエンディアン、float型)。 flagsでは0個以上のフラグを論理和とすることが可能です。次に、有効な flagsの一覧を示します。 このフラグが設定されると、 dataで文字エンコーディングがEBCDIC形式であることを示します。 このフラグが設定されると、 dataで文字エンコーディングがASCII形式であることを示します。 このフラグが設定されると、データがビッグ・エンディアンであることを示します。 このフラグが設定されると、データがリトル・エンディアンであることを示します。 このフラグが設定されると、データがメインフレームfloatであることを示します。このフラグが設定されると、 TPENC_BIG_ENDIANもシステムで設定されます。 文字セットを指定しない場合、デフォルト値( TPENC_ASCII)が使用され、エンディアンが指定されていない場合は、実行中のプラットフォームのエンディアンが使用されます。float型が設定されていない場合、デフォルトのfloat型はIEEE floatです。 |
この関数は、エラー発生時に-1を戻し、
Ferror32を設定してエラー条件を示します。
無効な引数が指定されています(たとえば、
flagsが無効である場合など)。
recのサイズが小さすぎてリクエスト・データを格納できません。
Rget()関数はRECORDバッファから1項目またはレコード全体を取得します。RECORDのソース・データは自動的に宛て先データの型に変換されます。
Rget(RECORD *rec, char *name, char *data, int datatype, int *len, int flags)
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
取得される項目の名前。 nameがNULLであるか、その長さが0である場合、レコード全体が取得されます。グループ名はサポートされません。名前は完全修飾名です。項目がグループの下にある場合、 nameは groupname.itemnameである必要があります。例: group1.name1は、 group1の name1を参照します。
表内の要素を参照するには、添字を使用する必要があります。添字のない表名は使用できます(添字は0から始まります)。例: 10 table1 occurs 10 times.
table1[4].name1は、 table1の5番目の要素の name1であることを示します。
|
|
|
|
|
|
データのデータ型。有効な datatypeのリストについては、 表6-10を参照してください。レコード全体が取得されると、データ型は無視されます(0に設定できます)。 |
|
|
アプリケーション・データ領域の長さ。入出力パラメータとして使用されます。入力パラメータの場合、 dataの長さを示し、出力パラメータの場合は、取得されたデータの長さを示します。関数がコールされるときに lenがNULLである場合、項目のデータ領域が項目値を収容できる大きさであると想定され、その長さは返されません。 |
|
|
flagsはデータ形式を示します。 Rget()の flagsは、 Rinit()の flagsと同じです。形式はレコード全体に適用されます。
|
マルチスレッドのアプリケーション中のスレッドは、
TPINVALIDCONTEXTを含め、どのコンテキスト状態で実行していても、
Rget()の呼出しを発行できます。
無効な引数が指定されています(たとえば、NULLデータ・パラメータが指定されています)。
lenに指定されているデータ領域の大きさは、フィールド値を保持するのに十分な大きさではありません。
RECORD名の検索中にプログラムで
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが見つかりません。
RECORD名の検索中に
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが破壊されているか、RECORDファイルではありません。
Rset()関数は項目またはレコード全体をRECORDバッファに設定します。
Rset(RECORD *rec, char *name, char *data, int datatype, int len, int flags)
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
設定される項目またはレコード全体の名前。 nameがNULLまたはその長さが0である場合、レコード全体が設定されます。 |
|
|
|
|
|
項目のデータ型。有効なデータ型のリストについては、 表6-10を参照してください。レコード全体が設定されると、 datatypeは無視されます(0に設定できます)。 |
|
|
データで参照されるバッファ内のアプリケーション・データの長さ。データで参照されるオブジェクトの長さはその datatypeから算出され(たとえば、 C_FLOAT型の値が sizeof(float)の長さの場合、オブジェクトは C_SHORT、 C_LONG、 C_CHAR、 C_FLOAT、 C_DOUBLE、 C_INT、 C_DECIMAL、 C_UINT、 C_ULONG、 C_LLONGおよび C_USHORTです)、 lenは無視されます。 |
|
|
flagsはデータ形式を示します。 Rset()の flagsは、 Rinit()の flagsと同じです。形式はレコード全体に適用されます。
|
マルチスレッドのアプリケーション中のスレッドは、
TPINVALIDCONTEXTを含め、どのコンテキスト状態で実行していても、
Rset()のコールを発行できます。
無効な引数が指定されています(たとえば、NULLデータ・パラメータが指定されているか、データが
recの想定よりも短いです)。
RECORD名の検索中にプログラムで
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが見つかりません。
RECORD名の検索中に
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが破壊されているか、RECORDファイルではありません。
Frneeded()関数はRECORDバッファに対して割り当てる必要があるスペースを決定するために使用されます。
RECORDバッファに必要なスペースは、コピーブック・レコード・サイズと同じです。レコード・サイズがすでにわかっている場合、
tpalloc()で使用できます。そうでない場合は、
Frneeded()を使用してレコード・サイズを取得します。取得したら、希望のRECORDバッファに割り当てることができます。次のコードは、レコードを含めるのに十分なスペースをRECORDバッファに割り当てる例です。
struct RECORD *rec = (struct RECORD *)tpalloc("RECORD", "myrecord", Frneeded("myrecord"));
次の表は、
Frneeded()関数の引数を示しています。
正常終了の場合、
Frneeded()は、RECORDバッファに対して割り当てる必要があるスペースを返しますこの関数は、エラー発生時に-1を戻し、
Ferror32を設定してエラー条件を示します。
RECORD記述が見つからないか、取得できません。
Fvftor32()関数はフィールド化バッファからRECORDバッファにデータを転送します。
Fvftor32(FBFR32 *fbfr, RECORD *rec, char *name, long flags)
次の表は、
Fvftor32()関数の引数を示しています。
|
|
|
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
転送されるグループ・アイテムまたはレコード全体の名前。 nameが NULLであるか、その長さが0である場合、レコード全体が取得されます。 |
|
|
|
フィールドは、フィールド化バッファからRECORDのメンバー記述子に基づくRECORDバッファにコピーされます。フィールド化バッファのフィールドは、対応するバッファがRECORDにない場合、無視されます。RECORDで指定されたメンバーに対応するフィールドがフィールド化バッファにない場合、メンバーにNULL値がコピーされます。
複数のオカレンスをRECORDに格納するには、構造体メンバーは配列(COBOLでは
OCCURS)である必要があります。バッファに存在するオカレンスの数が、配列にある要素数よりも少ない場合は、余分の要素スロットにはNULL値が割り当てられます。一方、バッファの配列にある要素数よりもオカレンスの数の方が多い場合は、余分なオカレンスは無視されます。
Fvftor32()は32ビットFMLで使用されます。FML32バッファ内のサブFML32は、RECORDバッファ内の対応するグループに変換されます。
無効な引数が指定されています(たとえば、NULLデータ・パラメータが指定されています)。
フィールド化バッファが境界付けされていないことを示します。バッファが適切に境界付けされて開始されていません。
バッファがフィールド化されていないことを示します。バッファがフィールド化されていないか、または
Finit()で初期化されていません。
フィールド化バッファにスペースがないことを示します。フィールド値は、フィールド化バッファで追加あるいは変更されますが、バッファには、十分な領域が残っていません。
mallocに失敗したことを示します。CARRAY (またはMBSTRING)あるいは文字列の値から変換するときに、
malloc()を使用した領域の動的な割当てが失敗します。
Fvrtof32()関数はRECORDバッファからフィールド化構造にデータを転送します。
Fvrtof32()は、32ビットのFMLで使用します。RECORDバッファ内のグループは、FML32バッファ内のサブFMLに変換されます。
Fvrtof32(FBFR32 *fbfr, RECORD *rec, char *name, int mode, long flags)
次の表は、
Fvrtof32()関数の引数を示しています。
|
|
|
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
転送されるグループ・アイテムまたはレコード全体の名前。 nameが NULLであるか、その長さが0である場合、レコード全体が取得されます。 |
|
|
次の値を指定できます。 FUPDATE/FOJOIN/FJOIN/FCONCAT
|
•
|
FUPDATEは、RECORDバッファ内の値で宛先バッファを更新します。フィールドID/オカレンスと一致するフィールドの場合は、フィールド値はソース・バッファの値を使って宛先バッファで更新されます。ソース・バッファに、一致するフィールドを持たない宛先バッファのフィールドはそのままです。宛先バッファに、一致するフィールドを持たないソース・バッファのフィールドが、宛先バッファに追加されます。
|
|
•
|
FJOINは、一致するfieldid/オカレンスに基づいてレコード・バッファとフィールド化バッファを結合します。フィールドID/オカレンスと一致するフィールドの場合は、フィールド値はソース・バッファの値を使って宛先バッファで更新されます。ソース・バッファ内に、対応するfieldidとオカレンスの組合せがない場合、宛先バッファのフィールドは削除されます。バッファを組み込むことにより FLD_PTRフィールドが削除されても、ポインタによって参照されるメモリー領域は変更または解放されません。
|
|
•
|
FOJOINは、 FJOINに似ていますが、宛先バッファ fbfrのフィールドに、ソース・バッファ recに対応するfieldid/オカレンスがない場合でも、そのフィールドは削除されません。対応するフィールド識別子/オカレンスを宛先バッファに持たないソース・バッファにあるフィールドは、宛先バッファに追加されません。バッファを組み込むことにより FLD_PTRフィールドが削除されても、ポインタによって参照されるメモリー領域は変更または解放されません。
|
|
•
|
FCONCATは、ソースRECORDバッファのフィールドを、既存の宛先バッファのフィールドに追加します。宛先バッファにあるオカレンスは維持され、ソース・バッファの新しいオカレンスは、フィールドに対して比較的大きなオカレンス番号で追加されます。
|
|
|
|
|
無効な引数が指定されています(たとえば、NULLデータ・パラメータが指定されています)。
フィールド化バッファが境界付けされていないことを示します。バッファが適切に境界付けされて開始されていません。
バッファがフィールド化されていないことを示します。バッファがフィールド化されていないか、または
Finit()で初期化されていません。
フィールド化バッファにスペースがないことを示します。フィールド値は、フィールド化バッファで追加あるいは変更されますが、バッファには、十分な領域が残っていません。
mallocに失敗したことを示します。CARRAY (またはMBSTRING)あるいは文字列の値から変換するときに、
malloc()を使用した領域の動的な割当てが失敗します。
Fvrtos32()関数はRECORDバッファからC構造にデータを転送します。
Fvrtos32(RECORD *rec, char *name, char *cstruct, char *view, long flags)
次の表は、
Fvrtos32()関数の引数を示しています。
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
転送されるグループ・アイテムまたはレコード全体の名前。 nameが NULLであるか、その長さが0である場合、レコード全体が取得されます。 |
|
|
|
|
|
コンパイルされたVIEW記述の名前を指すポインタ。RECORDおよびVIEWは、グループ・アイテムの名前から同形である必要があります。 |
|
|
|
アイテムは、RECORDバッファからviewのメンバー記述子
cnameに基づく構造体にコピーされます。指定されたグループ/レコードとC構造体の両方に名前が存在するアイテムのみが、RECORDバッファからC構造体にコピーされます。必要に応じて変換が実行されます。
構造体内のアイテムの複数のオカレンスについて、メンバーは、C言語またはCOBOLの
OCCURS句により配列として宣言されます。アイテムの1オカレンスに対して1つの配列の要素が使用されます。配列のサイズは、バッファ内のアイテム・オカレンスの最大数を反映します。
RECORDバッファとC構造体またはCOBOLレコード間のデータ転送時に、受信側の配列に存在する要素の数がソース配列内のオカレンスの数より多い場合、余分な要素は変更されません。ソース・バッファ内のオカレンスの数が配列内の要素の数より多い場合は、ソース・バッファ内の余分なオカレンスは無視されます。
無効な引数が指定されています(たとえば、NULLデータ・パラメータが指定されています)。
VIEWDIRまたはVIEWFILESで指定されたファイルにviewnameが見つかりません。
viewnameの検索中にプログラムで
VIEWDIRまたは
VIEWFILESで指定したファイルの1つが見つかりません。
VIEWDIRまたはVIEWFILESで指定されたファイルにviewnameが見つかりません。
viewnameの検索中に
VIEWDIRまたは
VIEWFILESで指定したファイルの1つが壊れているか、
viewfileではありません。
RECORD名の検索中にプログラムで
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが見つかりません。
RECORD名の検索中に
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが破壊されているか、RECORDファイルではありません。
Fvstor32()関数はC構造体からRECORDバッファにデータを転送します。
Fvstor32(RECORD *rec, char *name, char *cstruct, char *view, long flags)
次の表は、
Fvrtos32()関数の引数を示しています。
|
|
|
|
|
RECORDバッファを指すポインタ。このポインタは、 tpalloc()の以前の呼出しで割り当てられた型付きバッファを参照する必要があります。 |
|
|
転送されるグループ・アイテムまたはレコード全体の名前。 nameが NULLであるか、その長さが0である場合、レコード全体が取得されます。 |
|
|
|
|
|
コンパイルされたVIEW記述の名前を指すポインタ。RECORDおよびVIEWは、グループ・アイテムの名前から同形である必要があります。 |
|
|
|
アイテムは、構造体からviewのメンバー記述子
cnameに基づくRECORDバッファにコピーされます。指定されたグループ/レコードとC構造体の両方に名前が存在するアイテムのみが、構造体からRECORDバッファにコピーされます。必要に応じて変換が実行されます。
構造体内のアイテムの複数のオカレンスについて、メンバーは、C言語またはCOBOLの
OCCURS句により配列として宣言されます。アイテムの1オカレンスに対して1つの配列の要素が使用されます。配列のサイズは、バッファ内のアイテム・オカレンスの最大数を反映します。
無効な引数が指定されています(たとえば、NULLデータ・パラメータが指定されています)。
VIEWDIRまたはVIEWFILESで指定されたファイルにviewnameが見つかりません。
viewnameの検索中にプログラムで
VIEWDIRまたは
VIEWFILESで指定したファイルの1つが見つかりません。
VIEWDIRまたはVIEWFILESで指定されたファイルにviewnameが見つかりません。
viewnameの検索中に
VIEWDIRまたは
VIEWFILESで指定したファイルの1つが壊れているか、viewfileではありません。
RECORD名の検索中にプログラムで
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが見つかりません。
RECORD名の検索中に
RECORDDIRまたは
RECORDFILESで指定したファイルの1つが破壊されているか、RECORDファイルではありません。
RECORDバッファのデータは常に元の形式 - COBOL内部表現です。
Rget()が使用される場合、データはC言語で自動的に宛先データの型に変換されます。
Rset()が使用される場合は、データはC言語からCOBOL内部表現に自動的に変換されます。
次の表は、
Rget()または
Rset() (またはその両方)でサポートされるデータ型を示しています。
|
|
|
|
|
|
|
|
S9(1-4), S9(5-9), S9(10-18) 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S9(10)からS9(18)、COMPまたはCOMP-5またはバイナリ |
|
|
|
|
9(10)から9(18)、COMPまたはCOMP-5またはバイナリ |
|
|
|
|
S9(5)からS9(9)、COMPまたはCOMP-5またはバイナリ |
|
|
|
|
S9(5)からS9(9)、COMPまたはCOMP-5またはバイナリ |
|
|
|
|
S9(1)からS9(4)、COMPまたはCOMP-5またはバイナリ |
|
|
|
|
9(1)から9(4)、COMPまたはCOMP-5またはバイナリ |
|
|
|
|
S9(2*m-(n+1))V9(n)、COMP-3またはPACKED-DECIMAL |
COBOL内部10進数およびC dec_t型の変換 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
•
|
C_STRING、 C_CHAR: EBCDICおよびASCII変換
|
|
|
•
|
1 バイナリ整数型には C_SHORT、 C_USHORT、 C_INT、 C_UINT、 C_LONG、 C_ULONGが含まれます。
|
|
•
|
2 ターゲットのサイズがsrcのサイズより大きい場合、ターゲットの残りは0として設定されます。それ以外の場合は、srcの内容が切り捨てられ、tgtにコピーされます。
|
|
•
|
3 外部変数のサイズがrecのサイズより大きい場合、 Rget()が呼び出されるときに、外部変数の残りが0として設定されます。 Rset()が呼び出される場合は、外部変数のrec->rsizeの長さのみがrecにコピーされます。外部変数のサイズがrecのサイズより小さい場合、 Rget()が呼び出されるときに、recの引数lenでポイントされる長さが外部のrecにコピーされます。 Rset()が呼び出される場合は、recの残りが' 'として設定されます(recのencがebcdicである場合は0x40です)。
|
|
•
|
4 数値フィールドのみがサポートされ、Zoned Decimalはサポートされていません。
|
FMLでは、フィールド化バッファの読取りまたは書込み時にデータ変換を実行する一連のルーチンが用意されています。
一般に、これらのルーチンは、対応する非変換関数と同じように動作します。ただし、バッファへの書込み時にはユーザー型からネイティブ型へ変換を行い、バッファからの読取り時にはネイティブ型からユーザー型への変換を行います。
フィールドのネイティブ型は、そのフィールド表エントリ内でそのフィールドに対して指定され、そのフィールド識別子内でエンコードされたデータ型です。(ただし、上記の規則に対する唯一の例外として
CFfindoccがあります。この関数は、読取り操作を行いますが、ユーザー型からネイティブ型に変換を行ってから
Ffindoccを呼び出します。)これらの関数の名前は、接頭辞「C」が付いた、対応する非変換FML関数と同じです。
変換関数でサポートされていないフィールドの型は、ポインタ(
FLD_PTR)、埋込み型のFML32バッファ(
FLD_FML32)、および埋込み型のVIEW32バッファ(
FLD_VIEW32)です。FML32変換関数の実行中にこれらのフィールド型のいずれかが出現すると、
Ferrorが
FEBADOPに設定されます。
CFaddは、バッファにユーザー指定の項目を追加して、バッファ内に新しいフィールド・オカレンスを生成します。
int
CFadd(FBFR *
fbfr, FLDID
fieldid, char *
value, FLDLEN
len, int
type)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、追加するフィールドのフィールド識別子です。
|
|
•
|
FLD_CARRAY型の場合、lenは値の長さです。
|
フィールドを追加する前に、データ項目は、ユーザー指定の型からフィールドをフィールド化バッファに格納される型としてフィールド表内で指定された型に変換されます。ソースが
FLD_CARRAY型(文字配列)である場合は、len引数を配列の長さに設定する必要があります。次の例を検討してください:
if(CFadd(fbfr,ZIP,"12345",(FLDLEN)0,FLD_STRING) < 0)
F_error("pgm_name");
上記の例では、
ZIP (郵便番号)フィールドがlong型整数としてフィールド化バッファ内に格納されている場合は、「12345」がlong型整数の表現に変換されてから、その表現が
fbfrの指すフィールド化バッファに追加されます(ただし、フィールド値の長さは、関数が決定できるので0に指定されています。この長さは、
FLD_CARRAY型の場合のみ必要です)。以下の例は、同じ値をフィールド化バッファに格納しますが、その値をstring型としてではなくlong型として表現して格納します。
long zipval;
. . .
zipval = 12345;
if(CFadd(fbfr,ZIP,&zipval,(FLDLEN)0,FLD_LONG) < 0)
F_error("pgm_name");
ただし、Cでは構造体&12345Lを使用できないので、まず、値を変数に格納する必要があります。
CFaddは、成功すると
1を返し、エラーになると
-1を返します(
Ferrorは、適宜に設定されます)。
CFchgは、
CFaddと同じように動作しますが、指定された値の変換後、フィールド値を変更します。
int
CFchg(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, char *
value, FLDLEN
len, int
type)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、変更するフィールドのフィールド識別子です。
|
|
•
|
FLD_CARRAY型の場合、lenは値の長さです。
|
たとえば、次のコードは、フィールド
ZIPの最初のオカレンス(オカレンス0)を指定された値に変更し、必要に応じて変換を行います。
FLDOCC occurrence;
long zipval;
. . .
zipval = 12345;
occurrence = 0;
if(CFchg(fbfr,ZIP,occurrence,&zipval,(FLDLEN)0,FLD_LONG) < 0)
F_error("pgm_name");
指定されたオカレンスが見つからないと、指定されたオカレンスとして値を追加できるまで、NULLオカレンスがバッファに追加されます。
CFgetは、
Fgetと同様に変換を行います。異なる点は、変換された値がユーザー提供のバッファにコピーされることです。
int
CFget(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, char *
buf, FLDLEN *
len, int
type)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、検索するフィールドのフィールド識別子です。
|
|
•
|
bufは、変換後のコピー先バッファに対するポインタです。
|
|
•
|
FLD_CARRAY型の場合、lenは値の長さです。
|
前の例を使って、次のコードは、バッファに格納されたばかりの値(どのような形式の値でも可)にアクセスして、その値を元のlong型整数に戻します。
FLDLEN len;
. . .
len=sizeof(zipval);
if(CFget(fbfr,ZIP,occurrence,&zipval,&len,FLD_LONG) < 0)
F_error("pgm_name");
長さのポインタがNULLの場合は、検索および変換した値の長さは返されません。
CFgetallocは、
Fgetallocと同じように動作します。ただし、戻り値(変換後の値)に対して
mallocを使用して割り当てた領域は、
freeを使用して解放する必要があります。
char *
CFgetalloc(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, int
type, FLDLEN *
extralen)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、変換するフィールドのフィールド識別子です。
|
|
•
|
extralenは、関数の呼出し時には追加の割当て量に対するポインタであり、関数の復帰時には割り当てられた総領域のサイズに対するポインタです。
|
上記の例では、
CFgetallocの戻り値として文字ポインタのデータ型(Cの
char*)が示されています。実際に返されるポインタの型は、ポインタが指す値の型と同じです。
以下のコードを使用すると、すでに格納されている値を自動的に割り当てられた領域に取り込むことができます。
char *value;
FLDLEN extra;
. . .
extra = 25;
if((value=CFgetalloc(fbfr,ZIP,0,FLD_LONG,&extra)) == NULL)
F_error("pgm_name");
関数呼出しに値
extraを指定した場合、関数は、取り出した値に十分な領域に加えて、さらに25バイトを割り当てます。割り当てられた領域の総量が、この変数に返されます。
CFfindは、検索対象のフィールドの値を変換し、その値に対するポインタを返します。
char *
CFfind(FBFR *
fbfr, FLDID
fieldid, FLDOCC
oc, FLDLEN
len, int
type)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、検索するフィールドのフィールド識別子です。
|
上記の例では、
CFfindの戻り値として、文字ポインタのデータ型(Cの
char*)が示されています。実際に返されるポインタの型は、ポインタが指す値の型と同じです。
この関数が戻すポインタは、
Ffindの場合と同じく、読取り専用と見なされます。たとえば、次のコードは、
ZIPフィールドの最初のオカレンスの値を含む
long型に対するポインタを返します。
char *CFfind;
FLDLEN len;
long *value;
. . .
if((value=(long *)CFfind(fbfr,ZIP,occurrence,&len,FLD_LONG))== NULL)
F_error("pgm_name");
長さに対するポインタがNULLの場合、検出された値の長さは返されません。この関数の戻り値は、
Ffindの場合と異なり、対応するユーザー指定の型の境界に正しく調整されます。
|
注意:
|
CFfindが戻すポインタは、次のバッファ操作(破壊的でない操作も含む)が実行されるまで有効です。これは、変換後の値が1つのプライベート・バッファに保存されているためです。一方、 Ffindの戻り値の場合は、次にバッファが変更されるまで有効です。
|
CFfindoccは、バッファの指定されたフィールドのオカレンスを調べ、フィールド識別子の型に変換されたユーザー指定のフィールド値と一致する最初のフィールド・オカレンスのオカレンス番号を返します。
FLDOCC
CFfindocc(FBFR *
fbfr, FLDID
fieldid, char *
value, FLDLEN
len, int
type)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
fieldidは、検索するフィールドのフィールド識別子です。
|
|
•
|
valueは、対応する未変換の値に対するポインタです。
|
たとえば、次のコードは、文字列を
fieldid ZIPの型(通常は
long型)に変換し、
ocを指定された郵便番号のオカレンスに設定します。
#include "fldtbl.h"
FBFR *fbfr;
FLDOCC oc;
char zipvalue[20];
. . .
strcpy(zipvalue,"123456");
if((oc=CFfindocc(fbfr,ZIP,zipvalue,0,FLD_STRING)) < 0)
F_error("pgm_name");
フィールド値が見つからない場合は、
-1が返されます。
|
注意:
|
CFfindoccは、ユーザー指定の値をネイティブ・フィールド型に変換してから、フィールド値を検証するため、正規表現は、ユーザー指定の型とネイティブ・フィールド型が両方とも FLD_STRINGである場合のみ機能します。したがって、 CFfindoccには、正規表現に関するユーティリティがありません。
|
ユーザー指定の型
FLD_STRINGへの変換およびFLD_STRINGからの変換を処理するために、以下の関数が提供されています。
これらの関数は、対応する非文字列用の関数を呼び出し、
FLD_STRINGの
型と0の
lenを提供します。ただし、
Ffindsによって返されるポインタの有効期間は、
CFfindに記述される場合と同一になります。
これらの関数の説明については、
『Oracle Tuxedo ATMI FML関数リファレンス』を参照してください。
CFadd、
CFchg、
CFget、
CFgetalloc、
CFfindの各関数は、
Ftypcvtを使用して、適切なデータ変換を行います。
Ftypcvt32関数は、フィールド型
FLD_PTR、
FLD_FML32、および
FLD_VIEW32では失敗します。
Ftypcvtの使用方法は、次のとおりです。この形式は、パラメータの順序に関する規則に準拠しません。
char *
Ftypcvt(FLDLEN *
tolen, int
totype, char *
fromval, int
fromtype, FLDLEN
fromlen)
|
•
|
tolenは、変換後の値の長さに対するポインタです。
|
|
•
|
fromvalは、変換前の値に対するポインタです。
|
|
•
|
fromlenは、変換前の型が FLD_CARRAYである場合の変換前の値の長さです。
|
Ftypcvtは、
fromlenで指定された長さの
fromtype型の
*fromvalの値(
fromtypeが
FLD_CARRAYの場合。それ以外の場合、
fromlenは
fromtypeから算出される)を、
totype型の値に変換します。
Ftypcvtが成功すると、変換後の値に対するポインタが返され、
*tolenに変換後の長さが設定されます。失敗すると、
FtypcvtからNULLが返されます。
CFchg関数を使用した次の例を参照してください。
CFchg(fbfr,fieldid,oc,value,len,type)
FBFR *fbfr; /* fielded buffer */
FLDID fieldid; /* field to be changed */
FLDOCC oc; /* occurrence of field to be changed */
char *value; /* location of new value */
FLDLEN len; /* length of new value */
int type; /* type of new value */
{
char *convloc; /* location of post-conversion value */
FLDLEN convlen; /* length of post-conversion value */
extern char *Ftypcvt;
/* convert value to fielded buffer type */
if((convloc = Ftypcvt(&convlen,FLDTYPE(fieldid),value,type,len)) == NULL)
return(-1);
if(Fchg(fbfr,fieldid,oc,convloc,convlen) < 0)
return(-1);
return(1);
}
Ftypcvtを直接呼び出して、フィールド化バッファを変更せずにフィールド値を変換することができます。
以下は、変換時の規則の一覧です。
oldvalは、変換対象のデータ項目に対するポインタを表し、
newvalは変換後の値に対するポインタを表します。
|
•
|
変換前と変換後の型が同一である場合、 *newvalと *oldvalは同一です。 |
|
•
|
変換前と変換後の型が数値型( long型、 short型、 float型、または double型)である場合は、Cの代入演算子で正しい型変換を行います。たとえば、次のコードによって short型は float型に変換されます。 |
*((float *)newval) = *((short *) oldval)
|
•
|
数値型から文字列型へ変換する場合は、適切な sprintfを使用します。たとえば、次のコードによって short型は string型に変換されます。 |
sprintf(newval,"%d",*((short *)oldval))
|
•
|
文字列型から数値型へ変換する場合は、適切な関数(たとえば、 atof、 atol)を使用し、その結果を型変換のために代入します。たとえば、次のように指定します。 |
*((float *)newval) = atof(oldval)
|
•
|
char型から任意の数値型へ変換するか、または数値型から char型へ変換する場合、 char型は、「短い short型」と見なされます。たとえば、次のコードによって char型は float型に変換されます。
|
*((float *)newval) = *((char *)oldval)
shortを
charに変換する場合、次の例のようにします。
*((char *)newval) = *((short *)oldval)
|
•
|
charは、NULL文字を追加することによって stringに変換されます。この場合の charは、「より短い short」ではありません。もしそうであれば、それを shortに変換し、次に sprintfを介して shortを stringに変換することで、割当てが行われます。同じ意味で、 stringは、 stringの最初の文字をその文字に割り当てることにより、 charに変換されます。
|
|
•
|
carray型は、任意のシーケンスのバイトを格納するために使用されます。この意味で、それは任意のユーザー・データ型をエンコードできます。ただし、 carray型の場合は、以下の規則に従います。
|
|
•
|
carray型は、 carray型にNULLバイトを付加することによって string型に変換されます。このため、 stringから後続のNULLのオーバーヘッドを差し引いたものを格納したい場合は、 carray型を使用できます。(ただし、フィールドは、フィールド化バッファ内でshort型の範囲内に調整されるので、必ず領域を節約できるとは限りません。) stringは、その終了NULLバイトを削除することによって carray型に変換されます。
|
|
•
|
carray型が数値型に変換される場合、まず string型に変換され、次にその string型が数値型に変換されます。同様に、数値型が carray型に変換される場合も、まず string型に変換され、その後、 string型が carray型に変換されます。
|
|
•
|
配列の最初の文字を charに代入すると、 carray型は char型に変換されます。同様に、 char型を carray型に変換する場合は、文字を配列の最初のバイトとして代入し、配列の長さを1に設定します。 |
ただし、長さ1の
carray型と
char型は、以下の点で異なります。
|
•
|
char型には、関連する fieldidのオーバーヘッド分が含まれますが、 carray型には、関連する fieldidのほか、長さコードが含まれます。
|
|
•
|
carray型を数値型に変換する場合は、 string型にしてから atoiを呼び出します。 charを型変換すると、数値になります。たとえば、ASCII値「1」(10進数では49)の char型は、値49の short型に変換されます。長さ1の carray型(単一バイトのASCII値「1」を持つ)は、値1の short型に変換されます。同様に、 char型の「a」(10進数では97)は、値97の short型に変換されます。 carray型の「a」は、( atoi (「 a」)が0を生成するので)値0の short型に変換されます。
|
|
•
|
dec_t型を別の型に変換したり、またはその逆処理を行う場合、 decimal(3c)で説明されている変換関数( _gp_deccvasc、 _gp_deccvdbl、 _gp_deccvflt、 _gp_deccvint、 _gp_deccvlong、 _gp_dectoasc、 _gp_dectodbl、 _gp_dectoflt、 _gp_dectoint、および _gp_dectolong)を使用します。
|
次の表は、この項で示した変換規則をまとめたものです。
次の表は、前の表で使用されているエントリの説明です。
|
|
|
|
|
srcと destが同じ型です。変換の必要はありません。
|
|
|
Cの代入演算子を使用した型変換によって、変換が行われます。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NULL終了バイトを削除することによって変換が行われます。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ユーザー指定の型
FLD_MBSTRINGのデータのコード・セットのエンコーディング変換を処理するために、以下の関数が提供されています。
これらの関数では、
FLD_MBSTRINGフィールドのエンコーディング名とマルチバイト・データ情報の準備、
FLD_MBSTRINGフィールドからのエンコーディング名とマルチバイト・データ情報の抽出、および
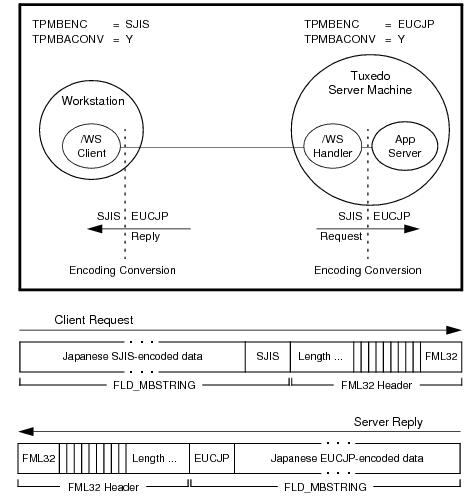
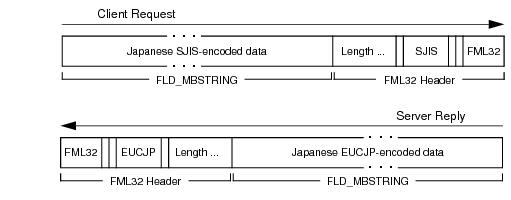
FLD_MBSTRINGフィールドにあるマルチバイト文字から名前付きターゲット・エンコーディングへの変換を行います。次の図は、エンコーディング変換がどのように行われるかを例示しています。
上図の例に示すように、
FLD_MBSTRINGフィールドは、ユーザー・データのコード・セット
文字エンコーディングまたは単に
エンコーディングを識別する情報を保持できます。この例では、クライアントのリクエストの
FLD_MBSTRINGフィールドは、Shift-JIS (SJIS)エンコーディングで表される日本語ユーザー・データを保持し、サーバーの応答の
FLD_MBSTRINGフィールドは、Extended UNIX Code (EUC)エンコーディングで表される日本語ユーザー・データを保持しています。マルチバイト文字エンコーディング機能では、環境変数
TPMBENCと
TPMBACONVを読み込んで、ソースのエンコーディング、ターゲットのエンコーディング、および自動エンコーディング変換の状態(有効または無効)を判別します。
次の図に示すように、FML32型付きバッファは、それ自体でユーザー・データの文字エンコーディングを識別する情報を保持できます。
FML32型付きバッファで保持する
FLD_MBSTRINGフィールド数が多い場合、グローバル・エンコーディングを使用すると、
FLD_MBSTRINGフィールドごとに文字エンコーディング名を追加するよりも、FML32バッファによるマルチバイト・ユーザー・データのトランスポート効率が向上します。
Fmbpack32()関数を使用すると、アプリケーション開発者は、
Fmbpack32()で作成された
FLD_MBSTRINGフィールドごとに、グローバル・エンコーディングを行うか個別のエンコーディングを行うかを選択できます。グローバル・エンコーディングで使用できる名前は、各FML32バッファにつき1つだけです。
エンコーディングの変換機能により、基底のTuxedoシステム・ソフトウェアでは、着信
FLD_MBSTRINGフィールドのエンコーディング表現を、受信プロセスが実行されているマシンでサポートされているエンコーディング表現に変換できます。この変換は文字コード・セット間の変換でも言語の翻訳でもなく、同じ言語の異なる文字エンコーディング間の変換です。
この関数は、FML32型付きバッファに入力された
FLD_MBSTRINGフィールドのエンコーディング名およびマルチバイト・データ情報を準備します。
Fmbpack32()は、
FLD_MBSTRINGフィールドがFML32 APIでFML32バッファに追加される前に使用します。
この関数の詳細は、
『Oracle Tuxedo ATMI FML関数リファレンス』の
Fmbpack32(3fml)に関する項を参照してください。
この関数は、FML32型付きバッファ内の
FLD_MBSTRINGフィールドからエンコーディング名およびマルチバイト・データ情報を抽出します。
Fmbunpack32()は、
FLD_MBSTRINGフィールドがFML32 API (
Ffind32()、
Fget32()、など)でFML32バッファから抽出された後に使用します。
この関数の詳細は、
『Oracle Tuxedo ATMI FML関数リファレンス』の
Fmbunpack32(3fml)に関する項を参照してください。
この関数は、FML32型付きバッファにある
FLD_MBSTRINGフィールドのマルチバイト文字を、名前付きターゲット・エンコーディングに変換します。具体的には、
tpconvfmb32()は、
FLD_MBSTRINGフィールドで指定されたソースのエンコーディング名を、
target_encodingで定義されたターゲットのエンコーディング名と
比較し、エンコーディング名が異なる場合に
tpconvfmb32()は、
FLD_MBSTRINGフィールドのデータをターゲットのエンコーディングに変換します。
この関数は、VIEW32型付きバッファにある
MBSTRINGフィールドのマルチバイト文字を、名前付きターゲット・エンコーディングに変換します。具体的には、
tpconvvmb32()は、
MBSTRINGフィールドで指定されたソースのエンコーディング名と
target_encodingで定義されたターゲットのエンコーディング名を比較し、エンコーディング名が異なる場合に
tpconvvmb32()は、
MBSTRINGフィールドのデータをターゲットのエンコーディングに変換します。
フィールド化バッファを
Finitまたは
Fallocで初期化すると、自動的に索引が設定されます。この索引により、フィールド化バッファへのアクセスが促進されますが、プログラマ側からは索引処理が見えません。フィールド化バッファにフィールドを追加したり、削除すると、索引が自動的に更新されます。
ただし、記憶装置に長期に渡ってフィールド化バッファを格納したり、協調動作するプロセス間でフィールド化バッファを転送する場合は、フィールド化バッファの受信時に、索引を削除したり、再生成して領域を節約できます。ここで説明する関数は、このような索引操作を実行します。
この関数は、バッファの索引が占有する領域を返します。
fbfrは、フィールド化バッファに対するポインタです。
この関数を使用すると、バッファの索引のサイズを判別し、索引を削除した方が時間や領域を節約できるかどうかを判別できます。
Findexを使用すると、索引が設定されていないフィールド化バッファに索引を設定できます。
int
Findex(FBFR *
fbfr. FLDOCC
intvl)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
Findexの2つ目の引数は、バッファの索引付けの間隔を指定します。0を指定すると、
FSTDXINT値(
fml.hで定義)が使用されます。間隔1を指定すると、すべてのフィールドに索引が設定されます。
索引付けの間隔を増やしてバッファの索引を再設定すると、ユーザー・データ用のバッファの空き領域を増やすことができます。ただし、処理時間の高速化と空き領域の確保を一度に両方実現することはできません。一般的に、索引の数を減らす、つまり索引の間隔を大きくすると、フィールドの検索に時間がかかります。ほとんどの操作では、空き領域が少なくなると、まず、すべての索引が削除されます。それができない場合は、エラー・メッセージが返されます。
索引の削除後に、フィールド化バッファを変更していない場合は、この関数を
Findexのかわりに使用できます。
int
Frstrindex(FBFR *
fbfr, FLDOCC
numidx)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
numidxは、 Funindex関数の戻り値です。
|
Funindexは、フィールド化バッファの索引を削除し、削除前のバッファ内の索引数を返します。
FLDOCC
Funindex(FBFR *
fbfr)
fbfrは、フィールド化バッファに対するポインタです。
索引を設定しないでフィールド化バッファを送信する例
索引を設定しないでフィールド化バッファを送信するには、次の手順に従います。
|
2.
|
送信するバイト数(バッファの先頭の最上位バイトの数)を取得します。 |
num_to_send = Fused(fbfr);
transmit(fbfr,num_to_send);
索引の削除は受信側のプロセス以外で行われ、さらにファイルで送信されなかったため、受信側のプロセスは
Frstrindexを呼び出せません。
|
注意:
|
Funindexを呼び出しても、索引が占有していたメモリー領域は解放されません。 Funindexは、ディスク上の領域を節約したり、バッファを別プロセスに送信するときに領域を節約するだけです。フィールド化バッファと索引を別プロセスに送信し、これらの関数を使用しないこともできます。
|
この項では、標準入出力またはファイルのストリームに対して、フィールド化バッファの入力や出力を行うための関数を説明します。
I/O関数の
Freadおよび
Fwriteは、標準I/Oライブラリを操作します。
int Fread(FBFR *fbfr, FILE *iop)
int Fwrite(FBFR *fbfr, FILE *iop)
入出力先のストリームは、
FILE型のポインタ引数によって決定されます。この引数は、通常の標準I/Oライブラリ関数を使用して設定しなければなりません。
以下のように
Fwriteを使用すると、フィールド化バッファを標準I/Oストリームに書き込むことができます。
if (Fwrite(fbfr, iop) < 0)
F_error("pgm_name");
以下のように
Freadを使用すると、
Fwriteを書き込んだバッファを読み取ることができます。
if(Fread(fbfr, iop) < 0)
F_error("pgm_name");
fbfrが指すフィールド化バッファの内容は、読み込まれたフィールド化バッファの内容で置き換えられますが、フィールド化バッファの容量(バッファ・サイズ)は変更されません。
Fwriteは、バッファの索引を削除し、
Fusedから返されたフィールド化バッファの使用済の部分のみを書き込みます。
Freadは、
Findexを呼び出すことによってバッファの索引を復元します。バッファの索引付けには、
Fwriteで書き込まれた時と同じ索引付けの間隔が使用されます。
Fread32は、
FLD_PTR型のフィールドを無視します。
以下のようにチェックサムを算出して、I/Oの妥当性をチェックできます。
long chk;
. . .
chk = Fchksum(fbfr);
Fchksumを呼び出し、フィールド化バッファと共にチェックサムの値を書き出し、入力時にその値をチェックする処置は、ユーザーの責任です。
Fwriteは、チェックサムの自動的な書込みは行いません。ポインタ・フィールド(
FLD_PTR)の場合は、ポインタまたはポインタが参照するポインタではなく、チェックサムの計算に使用するポインタ・フィールド名が含まれます。
Fprintは、フィールド化バッファをテキスト形式で標準出力に出力します。
fbfrは、フィールド化バッファに対するポインタです。
Ffprintは、
Fprintとよく似ていますが、次の例のように、テキストを指定された出力ストリームに出力します。
Ffprint(FBFR *
fbfr, FILE *
iop)
|
•
|
fbfrは、フィールド化バッファを指すポインタです。
|
|
•
|
iopは、出力ストリームへの FILE型ポインタです。
|
これらの各出力関数は、フィールド・オカレンスごとに、フィールド名とフィールド値をタブで区切って出力し、改行文字を追加します。
Fnameは、フィールド名を決定するために使用されます。フィールド名が決定できない場合、フィールド識別子が出力されます。文字列または文字配列のフィールド値内の表示不能な文字は、バックスラッシュとその後に続く2文字からなる16進値で表現されます。テキスト内に現れるバックスラッシュは、もう1つバックスラッシュを使用するとエスケープされます。バッファの出力が完了すると空白行が出力されます。
値が
FLD_PTR型の場合、
Fprint32はフィールド名またはフィールド識別子と16進法のポインタ値を出力します。この関数はポインタ情報を出力しますが、
Fextread32関数はフィールド型
FLD_PTRを無視します。値が
FLD_FML32型の場合、
Fprint32は、ネストの各レベルの先頭にタブを付けてFML32バッファを再帰的に出力します。値が
FLD_VIEW32型の場合、この関数は、VIEW32フィールド名と構造体メンバー名/値の対を出力します。
Fextreadを使用すると、フィールド化バッファを、その出力形式、つまり
Fprintの出力から作成できます(
Fprintで出力された16進値が正しく解釈されます)。
int
Fextread(FBFR *
fbfr, FILE *
iop)
Fextreadは、
Fprintの出力形式で、フィールド名とフィールド識別子の組合せの前指定する、次のオプション・フラグを受け付けます。
|
|
|
|
|
|
|
|
|
|
|
あるフィールドを別のフィールドに割り当てる必要があります |
|
|
|
フラグが指定されていない場合、デフォルトでは、
Faddによりフィールドが追加されます。
複数行にわたってフィールド値を指定するには、2行目以降の行頭にタブを入力します。このタブは無視されます。単一の空白行は、バッファの終了を示します。連続した複数の空白行を指定すると、NULLバッファが生成されます。埋め込み型のバッファに対して
Fextreadを実行すると、ネスト状のFML32バッファ(
FLD_FML32)とVIEW32フィールド(
FLD_VIEW32)が生成されます。
Fextread32は、
FLD_PTR型のフィールドを無視します。
エラーが発生すると、
-1が返され、
Ferrorが適宜設定されます。ファイルの終わりに達しても空白行が現れないと、
Ferrorに
FSYNTAXが設定されます。
この項では、式の「変数」にフィールド化バッファまたはVIEWのフィールドの値であるようなブール式を評価する関数について説明します。これらの関数を使用すると、以下の処理を行うことができます。
|
•
|
ブール式を、評価に適したコンパクトな形式にコンパイルします。 |
|
•
|
フィールド化バッファまたはVIEWと照合してブール式を評価し、trueまたはfalseを返します。 |
式を効率的な評価に適した簡潔な形式にコンパイルする関数が使用されます。2番目の関数により、コンパイルされた形式がフィールド化バッファと照合して評価され、trueまたはfalseの結果が返されます。
ここでは、ブール式のコンパイル用関数で受け付ける式と、式の評価方法を詳しく説明します。
以下のC言語の標準演算子はサポートされていません。
|
•
|
ビット単位のorおよびand演算子: ||および&& |
|
•
|
前置または後置のインクリメント演算子(++)およびデクリメント演算子(--) |
次の表は、ブール式で受け付けられるBackus-Naur Form定義の一覧です。
|
|
|
|
|
<boolean> || <logical and> | <logical and> |
|
|
<logical and> && <xor expr> | <xor expr> |
|
|
<xor expr> ^ <equality expr> | <equality expr> |
|
|
<equality expr> <eq op> <relational expr> | <relational expr> |
|
|
|
|
|
<relational expr> <rel op> <additive expr> | <additive expr> |
|
|
|
|
|
<additive expr> <add op> <multiplicative expr> | <multiplicative expr> |
|
|
|
|
|
<multiplicative expr> <mult op> <unary expr> | <unary expr> |
|
|
|
|
|
<unary op> <primary expr> | <primary expr> |
|
|
|
|
|
( <boolean> ) | <unsigned constant> | <field ref> |
|
|
<unsigned number> | <string> |
|
|
<unsigned float> | <unsigned int> |
|
|
' <character> {<character>. . .} ' |
|
|
<field name> | <field name>[<field occurrence>] |
|
|
|
|
|
|
論理式で許可される変数は、フィールド参照のみです。フィールド名の指定方法には、いくつかの規則があります。たとえば、フィールド名は、英字と数字で構成し、先頭には英字を指定しなければなりません。アンダースコア(
_)は、英字と見なされます。長い変数名をアンダースコアで区切り、読みやすい名前に変えることができます。フィールド名には、最大30文字を指定できます。予約語はありません。
フィールド化バッファを評価するため、論理式で参照されるフィールドは、フィールド表に存在していなければなりません。したがって、
FMLおよびVIEWSの環境設定で説明したように、環境変数の
FLDTBLDIRと
FIELDTBLSを設定してから、ブール式をコンパイルする関数を使用してください。論理式で使用できるフィールド型は、FMLフィールドで使用できる型と同じです。つまり、
short型、
long型、
float型、
double型、
char型、
string型、および
carray型を使用できます。フィールド型は、フィールド名と共にフィールド表に格納されています。したがって、フィールド型は常に判別できます。
VIEWを評価するため、ブール式で参照されるフィールドは、関連付けられたフィールド化バッファ名ではなく、VIEW内にC構造体要素名として存在していなければなりません。したがって、
FMLおよびVIEWSの環境設定で説明したように、環境変数の
VIEWDIRと
VIEWFILESを設定してから、ブール式をコンパイルする関数を使用してください。ブール式で使用できるフィールド型は、FMLフィールドで使用できる型と同じで、
short型、
long型、
float型、
double型、
char型、
string型、
carray型に加え、
int型および
dec_t型を使用できます。フィールド型は、フィールド名と共にVIEW定義に格納されています。したがって、フィールド型は常に判別できます。
文字列は、一重引用符で囲まれた文字の集まりです。エスケープ・シーケンスでエスケープした文字は、その文字のASCIIコードで置き換えることができます。エスケープ・シーケンスは、バックスラッシュと2桁の16進数で構成されます。この規則は、
\xで始める16進のエスケープ・シーケンスを使用するC言語規則とは異なります。
例として、
helloと
hell\\6fを比較します。
oの16進数コードは
6fなので、これらは等価の文字列です。
8進のエスケープ・シーケンスや
\nなどのエスケープ・シーケンスはサポートされていません。
定数として、C言語の場合と同じく、整数と浮動小数点値が受け付けられます。(8進および16進の定数は認識されません。)整数は、
long型として処理され、浮動小数点値は、
double型として処理されます。(
dec_t型の10進定数はサポートされていません。)
ブール式を評価するため、ブール式のコンパイラによって以下の変換が行われます。
|
•
|
short型および int型の値を long型に変換します。
|
|
•
|
float型および decimal型の値を double型に変換します。
|
|
•
|
フィールド内の引用符で囲まれていない文字列を数値と比較するため、文字列を数値に変換します。 |
|
•
|
引用符で囲まれた constantの文字列を数値と比較するため、数値を文字列に変換してから、字句単位で比較します。 |
|
•
|
long型と double型を比較するため、 long型を double型に変換します。
|
ブール式は基本式から構成され、次のものを使用できます。
|
•
|
field name[constant] - フィールド名と定数添字
|
|
•
|
field name[?] - フィールド名と「 ?」添字
|
フィールド名またはフィールド名と後続の添字は、基本式です。添字は、参照対象のフィールド・オカレンスを指定します。添字としては、整定数または
? (任意のオカレンスを示す)のいずれかを使用します。添字は、式と見なされません。フィールド名に添字が付いていないと、フィールド・オカレンスは0と見なされます。
フィールド名参照が、算術演算子、単項演算子、代入演算子、または関係演算子なしで示されると、フィールドが存在する場合はlong型整数の1、フィールドが存在しない場合は0となります。この方法を使用して、フィールド型に関係なく、フィールド化バッファ内にフィールドが存在するかどうかをテストできます。(間接演算子(
*)は存在しません。)
定数は基本式です。定数の型は、
long型、
double型、
carray型のいずれかです。
かっこで囲んだ式は、型と値が、かっこで囲まない場合の式の型と値に等しい基本式です。かっこを使用すると、演算子の優先度を変更できます。次の節を参照してください。
次の表に、ブール式の演算子を優先順位の高いものから降順に示します。
同じ演算子型に分類される演算子は、優先度が同じです。次の項では、各演算子を詳しく説明します。C言語では、かっこを使用して、演算子の優先度をオーバーライドできます。
単項演算子を含む式は、右から左にグループ化されます。
+
expression
-
expression
~
expression
!
expression
単項プラス演算子は、オペランドに有効ではありません。認識はされても、無視されます。単項マイナース演算子の結果は、そのオペランドの否定です。通常の算術変換が実行されます。符号なしのものは、FMLには存在しないので、この演算子には問題がありません。
論理否定演算子の結果は、オペランドの値が0の場合は1であり、オペランドの値が0以外の場合は0となります。結果は
long型になります。
補数演算子の結果は、オペランドの補数です。結果は
long型になります。
倍数に関する演算子の
*、
/ 、
%は、左から右にグループ化されます。通常の算術変換が実行されます。
expression *
expression
expression /
expression
expression %
expression
2項演算子
*は、乗算を示します。
*演算子は、連想型であり、同一レベルで数回の乗算を行う式は、コンパイラで再配置できます。
2項演算子
/は、除算を示します。正の整数が除算されると、切捨ては0に向かって行われますが、オペランドのいずれかが負の場合は、切捨ての形式は、マシンによって異なります。
2項演算子
%は、最初の式を次の式で除算した結果の剰余を返します。通常の算術変換が実行されます。オペランドには、
float型や
double型を使用してはなりません。
加法に関する演算子の
+と
-は、左から右にグループ化されます。通常の算術変換が実行されます。
expression +
expression
expression -
expression
+演算子は、オペランドの和を返します。
+演算子は連想型であり、同一レベルで数回の加算を行う式は、コンパイラで再配置できます。オペランドが両方とも
stringである必要はありません。一方のオペランドが
string文字列の場合、そのオペランドはもう一方のオペランドの算術型に変換されます。
-演算子は、オペランドの差を返します。通常の算術変換が実行されます。オペランドが両方とも
stringである必要はありません。一方のオペランドが
string文字列の場合、そのオペランドはもう一方のオペランドの算術型に変換されます。
expression ==
expression
expression !=
expression
expression %%
expression
expression !%
expression
== (等価)、
!= (非等価)の各演算子は、指定された関係がfalseの場合は0を返し、trueの場合は1を返します。結果は
long型になります。通常の算術変換が実行されます。
%%演算子の場合は、2つ目の式は、最初の式と照合するために使用する正規表現です。2つ目の式(正規表現)は、引用符で囲まれた文字列でなければなりません。最初の式は、FMLフィールド名であっても、引用符で囲まれた文字列であってもかまいません。この演算子は、最初の式が2番目の式(正規表現)と完全に一致する場合に1を返します。その他すべての場合、この演算子は0を返します。
!%演算子は、
正規表現と一視しない演算子です。この演算子は、
%%演算子と同じオペランドをとりますが、まったく反対の結果を生じます。
%%と
!%の関係は、
==と
!=の関係と同じです。
使用可能な正規表現については、
『Oracle Tuxedo ATMI C言語関数リファレンス』の
tpsubscribe(3c)リファレンス・ページを参照してください。
expression <
expression
expression >
expression
expression <=
expression
expression >=
expression
<(より小さい)、
>(より大きい)、
<=(以下)、
>=(以上)の各演算子は、指定された関係がfalseであれば0を返し、trueであれば1を返します。結果は
long型になります。通常の算術変換が実行されます。
ビット単位の排他論理和が返されます。結果は、必ず
long型です。
&&演算子は、左から右にグループ化されます。この演算子は、両方のオペランドが0でない場合は1を返し、どちらかが0の場合は0を返します。
&&演算子は、必ず左から右へ評価を行います。ただし、最初のオペランドが0の場合、2つ目のオペランドを評価しないということは
保証されないため、この点でC言語とは異なります。オペランドの型は同一でなくてもかまいません。結果は、必ず
long型です。
どちらかのオペランドが0でない場合は
1を返し、それ以外の場合は
0を返します。
||演算子は、左から右への評価が保証されます。ただし、最初のオペランドが0でない場合、2つ目のオペランドが評価されないことは保証されず、この点でC言語と異なります。オペランドの型は同一である必要はなく、結果は常に
long型です。
以下のフィールド表は、ブール式のサンプルで使用するフィールドを定義しています。
EMPID 200 carray
SEX 201 char
AGE 202 short
DEPT 203 long
SALARY 204 float
NAME 205 string
ブール式は必ずtrueまたはfalseと評価します。次の条件が両方ともtrueであれば、次の例はtrueです。
|
•
|
EMPIDのフィールド・オカレンス2が存在し、その値が文字「123」で始まります。
|
|
•
|
AGEフィールド(オカレンス0)が存在し、その値が32未満です。 |
"EMPID[2] %% '123.*' && AGE < 32"
この例では、
EMPIDの添字として整定数を使用しています。以下の例では、
?添字を使用しています。
この式は、
PETSが存在し、その任意のオカレンスが文字「dog」を含む場合は、trueとなります。
ここでは、引数としてブール式をとる各種の関数について説明します。
Fboolcoは、ブール式をコンパイルし、評価ツリーに対するポインタを返します。
char *
Fboolco(char *expression)
*expressionはコンパイル対象の式に対するポインタです。
FLD_PTR、
FLD_FML32、または
FLD_VIEW32のフィールド・タイプが使用されると、この関数は異常終了します。これらのフィールド・タイプの1つが指定されると、
Ferrorに
FEBADOPが設定されます。
Fvboolcoは、VIEWのブール式をコンパイルし、評価ツリーに対するポインタを返します。
char *
Fvboolco(char *expression, char *viewname)
*expressionはコンパイル対象の式に対するポインタで、
*viewnameはフィールドを評価するVIEW名に対するポインタです。
評価ツリーを保持するには、
malloc(3)を使用して領域を割り当てます。たとえば、次の例は、「J」で始まり「n」で終了する
FIRSTNAMEフィールド(たとえば、「John」、「Joan」など)がバッファ内に存在し、かつ、
SEX(性別)フィールドが「M」に設定されているかどうかをチェックするブール式をコンパイルします。
#include "<stdio.h>"
#include "fml.h"
extern char *Fboolco;
char *tree;
. . .
if((tree=Fboolco("FIRSTNAME %% 'J.*n' && SEX == 'M'")) == NULL)
F_error("pgm_name");
tree配列の最初の文字は、最下位バイトを形成します。次の文字は、最上位バイトを形成します。それぞれ、全体の配列の長さをバイト数で指定する符号なし型(16ビット)です。この値は、複写あるいは配列の操作に役立ちます。
Fboolcoが生成する評価ツリーは、次の各項で説明する、ブール式を処理する関数によって使用されるため、式を毎回再コンパイルする必要はありません。
ブール式を使用する必要がなくなった時に評価ツリーに割り当てられた領域を解放するには、
free(3)を使用してください。必要がなくなった評価ツリーを解放せずに多くのブール式をコンパイルすると、プログラムのデータ領域がなくなってしまう恐れがあります。
Fboolprは、指定されたファイルにコンパイルされた式を出力します。コンパイルされた式は、構文解析された(評価ツリーで示された)ようにコンパイルされ、全体にかっこが付きます。
void
Fboolpr(char *tree, FILE *iop)
|
•
|
*treeは、 Fboolcoによって以前にコンパイルされたブール式ツリーに対するポインタです。
|
|
•
|
*iopは、出力ファイルへの FILE型ポインタです。
|
Fvboolprは、指定されたファイルにコンパイルされた式を出力します。
void
Fvboolpr(char *tree, FILE *iop, char *viewname)
|
•
|
*treeは、 Fvboolcoを使用して以前にコンパイルしたブール式ツリーに対するポインタです。
|
|
•
|
*iopは、出力ファイルへの FILE型ポインタです。
|
|
•
|
*viewnameは、フィールドが使用されているVIEWの名前です。
|
上記でコンパイルされた式で
Fboolprを実行すると、以下の結果が出力されます:
(((FIRSTNAME[0]) %% ('J.*n')) && ((SEX[0]) == ('M')))
FboolevとFfloatev、およびFvboolevとFvfloatev
これらの関数は、両方とも、フィールド化バッファと照合してブール式を評価します。
int Fboolev(FBFR *fbfr,char *tree)
double Ffloatev(FBFR *fbfr,char *tree)
|
•
|
fbfrは、 Fboolcoによって生成された評価ツリーが参照するフィールド化バッファです。
|
|
•
|
treeは、 fbfrが指すフィールド化バッファを参照する評価ツリーへのポインタです。
|
int
Fvboolev(FBFR *
fbfr,char *
tree,char *
viewname)
double
Fvfloatev(FBFR *
fbfr,char *
tree,char *
viewname)
Fboolevは、フィールド化バッファが評価ツリーで指定されたブール式の条件と一致する場合はtrue (1)を返します。この関数は、フィールド化バッファあるいは評価ツリーのいずれも変更しません。上記の例のコンパイルされた評価ツリーを使用すると、「Buffer selected」と出力されます。
#include <stdio.h>
#include "fml.h"
#include "fldtbl.h"
FBFR *fbfr;
. . .
Fchg(fbfr,FIRSTNAME,0,"John",0);
Fchg(fbfr,SEX,0,"M",0);
if(Fboolev(fbfr,tree) > 0)
fprintf(stderr,"Buffer selected\n");
else
fprintf(stderr,"Buffer not selected\n");
Ffloatevおよび
Ffloatev32は、
Fboolevと同様に動作しますが、式の値を
double型として返します。たとえば、次のコードでは、「6.6」と出力されます。
#include <stdio.h>
#include "fml.h"
FBFR *fbfr;
. . .
main() {
char *Fboolco;
char *tree;
double Ffloatev;
if (tree=Fboolco("3.3+3.3")) {
printf("%lf",Ffloatev(fbfr,tree));
}
}
Fboolevを上記の例の
Ffloatevの位置で使用した場合、1が出力されます。
VIEWを、ターゲット・レコード形式に変換したり、その逆の処理を行うことができます。デフォルトのターゲット・レコード形式は、IBM System/370 COBOLレコードの形式です。
Fvstot、Fvftos、およびFcodeset
long
Fvstot(char *cstruct, char *trecord, long treclen, char *viewname)
long
Fvttos(char *cstruct, char *trecord, char *viewname)
int
Fcodeset(char *translation_table)
Fvstot関数は、データをC構造体からターゲット・レコード・タイプに転送します。
Fvttos関数は、データをターゲット・レコードからC構造体に転送します。
trecordはターゲット・レコードへのポインタです。
cstructはC構造体へのポインタです。
viewnameは、コンパイルされたVIEW記述の名前へのポインタです。
VIEWDIR環境変数および
VIEWFILES環境変数を使用してコンパイルされたVIEW記述があるディレクトリとファイルが検索されます。
FMLバッファを、ターゲット・レコードに変換するには、次の手順に従います。
|
1.
|
Fvftosを呼び出してFMLバッファをC構造体に変換します。
|
|
2.
|
Fvstotを呼び出してターゲット・レコードに変換します。
|
ターゲット・レコードを、FMLバッファに変換するには、次の手順に従います。
|
2.
|
Fvstofを呼び出してその構造体をFMLバッファに変換します。
|
デフォルトのターゲットは、IBM/370 COBOLレコードのターゲットです。デフォルトのデータ変換は、以下の表に基づいて行われます。
IBM/370のレコードでは、フィールド間のフィルタ・バイトはありません。ビューに対応するデータ構造の一部をなすデータ・アイテムに対しては、COBOL SYNC項は指定することはできません。整数フィールドは、変換を実行するマシン上の整数のサイズに応じて4バイトまたは2バイトの整数に変換されます。IBM/370フォーマットへの変換、またはIBM/370フォーマットからの変換を行う場合、ビューの文字列フィールドはNULLで終了している必要があります。
carrayフィールドのデータは変更されずに渡されます。データの変換は行われません。
パック10進数は、IBM/370環境では1バイトにパッキングされた2桁の10進数として存在し、下位の1/2バイトは符号を格納するために使用されます。パッキングされた10進数の長さは1 - 16バイトで、1 - 31桁の数字と1つの符号のストレージ領域があります。パッキングされた10進数は、Cの構造体では
dec_tというフィールド・タイプを利用することによってサポートされます。
dec_tフィールドは、カンマで区切られた2つの数字で構成されたサイズに定義されています。カンマの左側の数字は、10進数が占有する総バイト数です。右側の数値は、小数点以下の桁数です。変換には、次の公式が使用されます。
dec_t(
m, n) <=> S9(2*
m-(
n+1))V9(
n)COMP-3
10進数と他のデータ型(
int型、
long型、
string型、
double型、
float型など)間の変換には、
decimal(3c)で説明されている関数を使用できます。
実行時には、
Fcodesetを呼び出すことにより、別の文字変換表を使用することができます。
translation_tableは、512バイトのバイナリ・データを指している必要があります。最初の256バイトのデータは、ASCIIからEBCDICへの変換表として解釈されます。残りの256バイトのデータはEBCDICからASCIIへの変換表として解釈されます。512バイトより後ろのデータは無視されます。ポインタがNULLのときは、デフォルトの変換表が使用されます。