| Oracle® Fusion Middleware Oracle Enterprise Data Qualityの管理 12c (12.2.1.2.0) E88275-01 |
|

 前 |
 次 |
この章では、EDQシステムのパフォーマンスを最適化するために使用できるサーバーのプロパティについて、およびそのプロパティの様々な環境での構成方法について説明します。
内容は次のとおりです。
EDQには、システムの様々な側面を構成するために使用される多くのプロパティがあります。これらのうち比較的少数がシステムのパフォーマンス特性の制御に使用されます。
EDQでのパフォーマンス・チューニングは多くの場合CPUコアという言葉で説明されます。この章では、これはRuntime.availableProcessors()メソッドへのコールにより返される、Java仮想マシンによりレポートされるCPUの数のことです。
チューニング制御はdirector.propertiesファイル内のプロパティとして公開されます。このファイルはoedq_local_home構成ディレクトリにあります。
|
注意: ほとんどの場合、これらのプロパティをチューニングする必要はなく、そのデフォルト設定は、できるかぎり多くの使用可能なハードウェアを利用することを目的としています(通常、これは最適なパフォーマンスを得ることに適しています)。通常は、EDQエキスパートから指示があった場合にのみ、これらのプロパティを変更してください。多くの使用例では、これらの設定に16を超える値を指定してもパフォーマンス上のメリットはほとんどないため、そのような設定は、EDQを非常に大規模なサーバーにデプロイする場合に行うことをお薦めします。たとえば、およそ70個の論理CPUが使用可能な単一のExaLogicノードにおいて、それぞれ最大16スレッドが実行される複数のEDQ管理対象サーバー(必要に応じてクラスタ内のもの)は、通常、制約のない単一サーバーより全体的なパフォーマンスに優れています。 |
最も重要なチューニング・プロパティは、次のとおりです。
runtime.threads |
このプロパティは、起動された各バッチ・ジョブに使用されるスレッドの数を決定します。このプロパティのデフォルト値はゼロで、これは使用可能な各CPUコアに対しシステムが1スレッドを開始することを意味します。このプロパティの値にゼロ以外の正の整数を指定して、スレッドの数を明示的に指定できます。たとえば、各バッチ・プロセスに合計で4スレッドを開始する場合は、runtime.threadsを4に設定します。 |
runtime.intervalthreads |
このプロパティは、間隔モードで実行中に各プロセスで使用されるスレッドの数を決定します。これは、同時に処理できるリクエストの数も定義します。デフォルトの動作では、間隔モードで実行中の各プロセスに対し1スレッドが実行します。 |
workunitexecutor. outputThreads |
このプロパティは、データの結果データベースへの書込みに使用されるスレッドの数を決定します。これらのスレッドはシステム全体の結果および出力データのキューにサービスを提供するので、システムで実行しているすべてのプロセスで共有されます。このプロパティのデフォルト値はゼロで、これは使用可能な各CPUコアに対しシステムが1出力を使用することを意味します。このプロパティの値にゼロ以外の正の整数を指定して、出力スレッドの数を明示的に指定できます。たとえば、各バッチ・プロセスに合計で4スレッドを使用する場合は、workunitexecutor.outputThreadsを4に設定します。 |
EDQで提供されるデフォルトのチューニング設定は、バッチ処理で主に使用されるほとんどのシステムで適切です。すべての使用可能なコアを使用するジョブの実行時は、十分なスレッドが開始されます。複数のジョブが開始される場合、オペレーティング・システムはコア間の効率的な共有のために作業をスケジューリングできます。オペレーティング・システムがこれらの種類のワークロードのスケジューリングを実行できるようにするのがベスト・プラクティスです。
本番システムが大量のリアルタイム処理に使用されている場合、リアルタイムのレスポンスがクリティカルでなくなるまで、同時バッチおよびリアルタイム処理に使用しないでください。一般的に、リアルタイム処理のデータを準備するために必要なバッチ・パフォーマンスの部分のみを実行することをお薦めします(たとえば、リアルタイム参照データ照合の参照データの準備など)。
バッチ処理をリアルタイム処理に使用されているシステムで実行する必要がある場合、スケジュールされているメンテナンス期間など、リアルタイム・プロセスが停止しているときにバッチ作業を実行することがベスト・プラクティスです。この場合、runtime.threadsはデフォルト設定が適しています。リアルタイム・サービスが実行している間にバッチ処理を実行する必要がある場合、runtime.threadsの値を、コアの合計数よりも小さく設定します。バッチ・プロセスで開始されるスレッドの数を削減することにより、これらのプロセスが実行時に使用可能なすべてのコアに負荷をかけるのを防ぎます。バッチが実行中に到着するリアルタイム・サービス・リクエストは、CPU時間をめぐってそれと競合することはありません。
JVMパラメータはEDQのインストール中に構成する必要があります。詳細は、『Oracle Fusion Middleware Oracle Enterprise Data Qualityのインストールと構成』のEnterprise Data Qualityをサポートするサーバー・パラメータの設定に関する項を参照してください。パフォーマンスを改善するためにこれらのパラメータをインストール後にチューニングする必要が生じた場合、この項の手順に従います。
|
注意: この項のすべての推奨事項はJava HotSpot仮想マシンを使用するEDQインストールに基づきます。実装の性質により、これらの推奨事項は他のJVMにも適用されることがあります。 |
EDQ内でのパフォーマンス・チューニングに関する最も重大なデータベース・チューニング・パラメータはworkunitexecutor.outputThreadsです。このパラメータは、結果データおよびステージング済データの結果データベースへの書込みに使用されるスレッドの数、よってデータベース接続の数を決定します。アプリケーション・サーバーで実行中のすべてのプロセスはこのスレッドのプールを共有するので、特定の環境では処理がI/Oバウンドになるリスクがあります。CPUの使用率と比較して特にI/O集中になっているプロセスがあり、データベース・マシンがEDQアプリケーション・サーバーをホストしているマシンよりもより強力な場合、workunitexecutor.outputThreadsの値を増加することが適切な場合があります。追加のデータベース・スレッドはデータベースへのより多くの接続を使用し、データベースにより多くの負荷をかけます。
特定の状況下では、クライアントのヒープ・サイズの問題が発生することがあります。次に例を示します。
大規模なデータをクライアント側のExcelファイルにエクスポートしようとした場合。
多数のグループがある場合に一致レビューを開いた場合。
EDQでは、クライアントのヒープ・サイズの調整にblueprints.propertiesファイルのプロパティを使用できます。
すべてのJava Web Startクライアント・アプリケーションのデフォルトの最大クライアント・ヒープ領域を2倍にするには、EDQサーバーのlocal構成ディレクトリでblueprints.propertiesファイルを作成(すでに存在する場合は編集)します。EDQ構成ディレクトリの詳細は、Oracle Enterprise Data QualityのインストールのEDQディレクトリの要件に関する項を参照してください。
次の行を追加します。
*.jvm.memory = 512m
|
注意: この値を大きくすると、すべての接続クライアントでヒープ・サイズが512MBに変更されることになります。これに付随して、他のアプリケーションが使用中の場合に、クライアントのパフォーマンスにその影響が及ぶことがあります。 |
特定アプリケーションのヒープ・サイズを調整するには、アスタリスク(*)を次のリストに示すクライアント・アプリケーションのブループリント名に置き換えます。
director - (ディレクタ)
matchreviewoverview - (一致レビュー)
casemanager - (ケース管理)
casemanageradmin - (ケース管理の管理)
opsui - (サーバー・コンソール)
diff - (構成分析)
issues - (問題マネージャ)
たとえば、ディレクタの最大クライアント・ヒープ領域を2倍にするには、次の行を追加します。
director.jvm.memory = 512m
複数のアプリケーションのクライアント・ヒープ領域を2倍にするには、単にこのプロパティを繰り返します。たとえば、ディレクタと一致レビューについては、次のようになります。
director.jvm.memory = 512m
matchreviewoverview.jvm.memory = 512m
パフォーマンスを最大化するために、4つの一般的な技術を使用できます。
この項には、次の項目が含まれます。
インポートしたデータをEDQリポジトリ・データベースにステージングするかわりに(またはそれと同時に)、プロセスに直接ストリームするジョブを開発できます。ジョブで使用できるスレッドがごく少数である場合、そのジョブにデータをストリームすると、データをより迅速に処理できる可能性があります。その理由は、インポートしたデータのステージングをバイパスすると、ジョブのI/O負荷が減少するためです。実際のジョブの技術要件およびビジネス要件と、使用できるリソースに応じて、データをストリームするか、データをステージングしてストリームすることで、パフォーマンスを向上できます。ただし、ジョブで多数のスレッドを使用できる場合、最初からすべてを使用できるようにデータのスナップショットを作成すると、より迅速に実行できる可能性があります。誤解を避けるために言えば、データは、ステージングの有無にかかわらずジョブにストリームできます。ただし、データをストリームしない場合、インポートしたデータのステージングを無効にすることはできません。インポートしたデータをプロセスまたはプロセス・チェーンに対してステージングなしで直接ストリームするジョブは、パイプとして動作し、データ・ストアからレコードを直接読み取り、データ・ターゲットにレコードを書き込みます。
構成
データをプロセスにストリームするには、次のようにします。
ジョブを作成します。
ジョブの同じフェーズ内にタスクとしてスナップショットとプロセスの両方を追加し、スナップショットがプロセスに直接接続していることを確認します。
追加で、インポートしたデータのEDQリポジトリへのステージングを無効化するには、次のようにします。
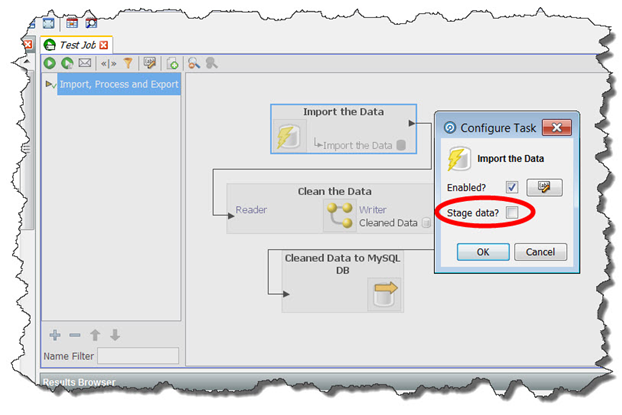
ジョブ内のスナップショットを右クリックして、「タスクの構成」または「コネクタの構成」を選択します。
「タスクの構成」ダイアログ・ボックス内で、「データのステージング」チェック・ボックスを選択解除します。
|
注意: レコード選択基準(スナップショットのフィルタまたはサンプリングのオプション)は、データのストリーム時にも適用されます。 |
エクスポートをストリームするには、次のようにします。
データ・インタフェースに書き込むライターで終了するプロセスを作成します。
同じデータ・インタフェースから読み取るエクスポートを作成します。
ジョブ内で、ジョブの同じフェーズのタスクとしてプロセスおよびエクスポートを追加します。
データ・インタフェースに書き込むプロセスがエクスポートに直接接続していることを確認します。
前述のようにEDQを構成した場合、デフォルトで、データはリポジトリにステージングされません。その理由は、ステージング済データのセットを指し示すデータ・インタフェース出力マッピングを選択していないためです。
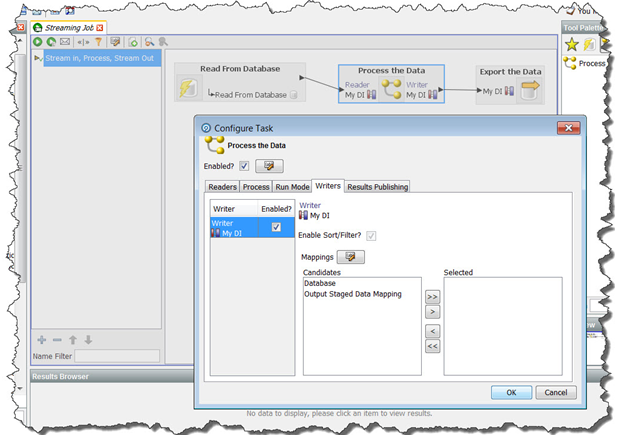
エクスポートするデータのステージングを有効にする場合、次のようにします。
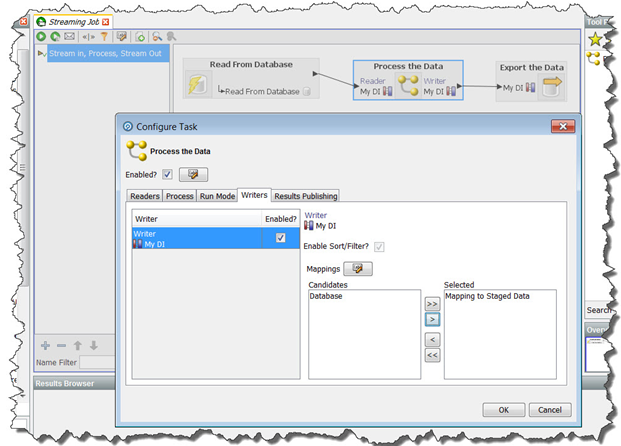
ステージング済データのセットを指し示すデータ・インタフェース・マッピングを作成します。
ジョブ内のプロセスを右クリックして、「タスクの構成」または「コネクタの構成」を選択します。
「タスクの構成」ダイアログで、「ライター」タブに移動します。
ライターの横にある「有効」チェック・ボックスを選択します(デフォルトで選択されています)。
ステージング済データのセットを指し示すデータ・インタフェース・マッピングを選択します。
データをステージングする場合とステージングを無効にする場合
プロセスの設計時には、スナップショットを介してEDQリポジトリにステージングされたデータに対して頻繁にプロセスを実行します。ステージングなしでのジョブへのデータのストリームは、次の場合に適切です。
本番環境に対処する場合。
処理するレコードの数が多い場合。
常にソース・システムから最新のレコードを使用する場合。
ただし、ステージングなしのスナップショットのストリームは、常に最速または最適なオプションであるとはかぎりません。同じデータのセットで複数のプロセスを実行する必要がある場合や、ステージング済データを参照する必要がある場合、ジョブの最初のタスクとしてスナップショットを介してデータをステージングし、その後で依存プロセスを実行する方が効率的です。ジョブに使用可能な多数のスレッドがある場合、すべてのデータを最初にステージングすると、より迅速に実行できる可能性があります。また、スナップショットのソース・システムが有効である場合、状況によっては、ソース・システムに対する影響が最小化されるようにフェーズ単独でスナップショットを実行すると最も効果的です。この場合、ストリームを実行するには、同じジョブ・フェーズ内でスナップショットとプロセスが相互に直接接続される必要があるため、データはプロセスにストリームされません。
誤解を避けるために言えば、プロセスがスナップショットに直接接続されていると、データは、リポジトリにステージングされているかどうかにかかわらず(「データのステージング」チェック・ボックスにより決定)、そのプロセスに常にストリームされます。データをEDQにストリームして同時にステージングもするアプローチは、状況によっては効率的です(データをジョブで後から再度使用する場合など)。
エクスポートのストリーム
ステージング済データのセットのエクスポートが、ステージング済データを書き込むプロセスの後に同じジョブで実行されるように構成されている場合、エクスポートは、レコードがリポジトリにステージングされるかどうかにかかわらず、処理時に常にレコードを書き込みます。ただし、ターゲットのみにデータをストリームするようにステージングを無効化すると、パフォーマンスが多少向上する可能性があります。
次の場合に出力データのステージングを無効にできます。
デプロイされたデータのクレンジング・ジョブが目的の場合。
アプリケーション間で共有される外部ステージング・データベースに書き込む場合。(たとえば、より大規模なETLプロセスの一環としてデータ品質ジョブを実行し、外部ステージング・データベースを使用してEDQとETLツール間でデータを渡す場合など。)
結果の書込みを最小化すると、EDQがプロセスからリポジトリに書き込む結果のドリルダウンのデータ量が減少し、I/Oも節約できます。
EDQの各プロセスは、3つの結果のドリルダウン・モードのいずれかで実行されます。
すべて(プロセスのすべてのレコードがドリルダウンに書き込まれます)
サンプル(レコードのサンプルがドリルダウンの各レベルに書き込まれます)
なし(メトリックのみが書き込まれ、ドリルダウンは使用できません)
「すべて」モードは、すべての処理ポイントのプロセスですべてのレコードが完全にトラッキングされるため、少量のデータに対してのみ使用する必要があります。このモードは、小規模なデータ・セットを処理する場合や、少数のレコードを使用して複雑なプロセスをデバッグする場合に役立ちます。
「サンプル」モードは、ドリルダウンごとに限定された数のレコードが書き込まれるため、大量のデータに向いています。システム管理者は、ドリルダウンごとに書き込むレコードの数(デフォルトでは1000個のレコード)を設定できます。「サンプル」モードは、ディレクタのユーザー・インタフェースから対話的にプロセスを実行する場合のデフォルトです。
「なし」モードは、ユーザーが結果との対話を必要としない本番環境で実行されるテスト済プロセスのパフォーマンスを最大化する場合に使用する必要があります。「なし」は、ジョブ内でプロセスを実行する場合のデフォルトです。
プロセスの実行時に結果のドリルダウン・モードを変更するには、「実行プリファレンス」画面を使用するか、ジョブを作成してからプロセス・タスクをダブルクリックしてそれを構成します。
たとえば、次のプロセスは、ジョブを介して本番環境にデプロイする場合にドリルダウン結果を書き込まないように構成されています(これは、ジョブ内でプロセスを実行する場合のデフォルトです)。
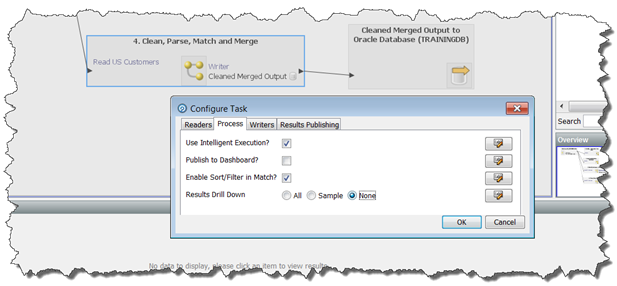
実行ラベルの影響
サーバー・コンソールのユーザー・インタフェースまたはコマンドラインから実行ラベル付きで実行されるジョブでは、結果のドリルダウンは生成されないことに注意してください。
大量のデータを処理する場合、ユーザーが結果ブラウザでデータをソートおよびフィルタできるようにスナップショットとステージング済データを索引付けする際に、時間がかかる可能性があります。多くの場合、このソートおよびフィルタ機能は不要であるか、少量のデータ・サンプルを処理する場合にのみ必要です。
システムでは、少量のデータ・セットを処理する場合にソートとフィルタを有効にし、大量のデータ・セットに対してはソートとフィルタを無効にするインテリジェント・ソートおよびフィルタが適用されます。ただし、少量のデータ・セットを複数処理する際に最大限のスループットを実現する場合などには、これらの設定をオーバーライドできます。
スナップショットのソート/フィルタ・オプション
スナップショット作成時のデフォルト設定では、「インテリジェント・ソート/フィルタリングの使用」オプションが選択されており、システムでは、スナップショットのサイズに基づいてソートとフィルタを有効にするかどうかを決定します。
ただし、ユーザーが結果ブラウザでスナップショットに基づく結果をソートまたはフィルタする必要がない場合、またはユーザーが必要となった時点でのみソートまたはフィルタを有効にする場合、スナップショットを追加または編集するときにそのソートとフィルタを無効にできます。
これを行うには、スナップショットを編集し、3番目の画面(「列選択」)で「インテリジェント・ソート/フィルタリングの使用」オプションの選択を解除して、「ソート/フィルタ」列のすべての列を選択解除したままにします。
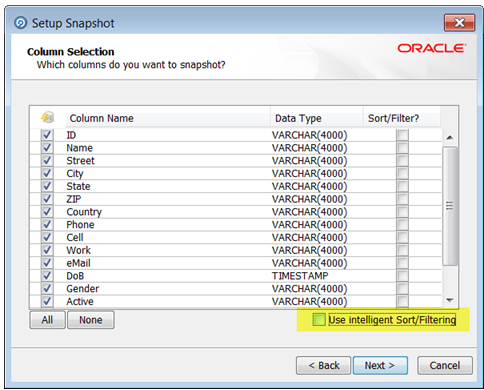
または、ソートとフィルタが、使用可能な列の部分選択のみで必要であることがわかっている場合、チェック・ボックスを使用して適切な列を選択します。パフォーマンスを向上するには、ルックアップと戻りプロセッサによりルックアップ列として使用されるすべての列に索引を作成する必要があることに注意してください。ソートとフィルタを無効にすると、ソートとフィルタを有効にする追加タスクがスキップされるため、スナップショットの合計処理時間が短縮されます。ユーザーが、有効になっていない列に基づいて結果をソートまたはフィルタしようとすると、その時点でそれを有効にするためのオプションが提示されます。
ステージング済データのソート/フィルタ・オプション
ステージング済データがプロセスによって書き込まれる場合、サーバーは、デフォルトでデータのソートまたはフィルタを有効にしません。そのため、デフォルト設定はパフォーマンスのために最適化されています。
書き込まれたステージング済データのソートまたはフィルタを有効にする必要がある場合(たとえば、書き込まれたステージング済データが、対話的なデータ・ドリルダウンを必要とする別のプロセスによって読み取られるため)、ステージング済データの定義を編集してこれを有効にし、インテリジェント・ソート/フィルタ・オプションを適用するか(ソートとフィルタを有効にするかどうかは、ステージング済データ表のサイズに基づいて決定されます)、または選択した列を対象として有効にできます(次を参照してください)。
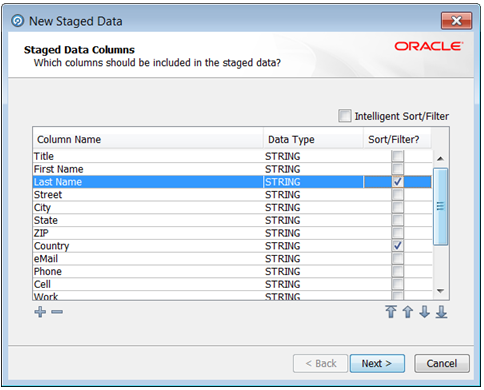
照合プロセッサのソート/フィルタ・オプション
照合の出力に対して、ソート/フィルタ有効化オプションを設定することが可能です。
|
注意: これは、一致レビューUIを使用して照合処理の結果を確認する場合にのみ有効にする必要があります。 |
次のプロセッサは、作業の前に処理対象のデータをすべてEDQリポジトリに書き込む必要があるため、リソースを集中的に使用します。
クイック統計プロファイラ
レコード重複プロファイラ
重複チェック
すべての照合プロセッサ
グループとマージ
フレーズ・プロファイラ
データ・ストリームのマージ
|
注意: このプロセッサは、個々のリーダーからレコードをマージする場合にのみ使用する必要があります。同じリーダーの複数のパスを接続する場合に使用する必要はありません。 |
次のプロセッサは、レコード単位で動作しますが、同様にリソースを集中的に使用します。
解析
|
注意: この解析プロセッサのパフォーマンスは、その構成に大きく依存し、高速にも低速にもなります。 |
住所の検証
これらのリソース集中型プロセッサを1つ以上使用する必要のある状況が明らかに存在します。たとえば、重複除外プロセスでは、照合プロセッサが必要です。ただし、最適なパフォーマンスが要求される場合は、可能なかぎりその使用を避けてください。解析および住所の検証の各照合プロセッサをチューニングする方法の具体的なガイダンスは、次の項を参照してください。
解析と照合の場合、各プロセッサには多くの処理ステージがあるため、個々のプロセッサによって大量の作業が実行されます。このような場合、プロセッサ・レベルでパフォーマンスを最適化するためのオプションを使用できます。
データを解析または照合する際にパフォーマンスを最大化する方法の詳細は、次の項を参照してください。
解析と照合は、両方とも本質的にリソース集中型であり、実行に時間がかかる可能性があります。この理由から、解析および照合プロセッサは、独自のプロセスに配置する(または、ごく少数の他のプロセッサとともに使用する)ことをお薦めします。これにより、処理を分離してそのパフォーマンスを正確に測定できるため、チューニングが容易になります。
デフォルトでは、解析プロセッサは「解析とプロファイル」モードで動作します。この場合、パーサーによって「トークン・チェック」および「未分類のトークン」結果ビューが出力されるため、構成の際に便利です。これらは、解析ルールを定義する場合に役立ちます。ただし、本番環境では、解析プロセッサによって最大限のパフォーマンスが要求される場合、「解析とプロファイル」モードではなく「解析」モードで実行する必要があります。パーサーの実行モードを変更するには、その「拡張オプション」リンクをクリックし、「オプション」ダイアログ・ボックスで実行モードを設定します。
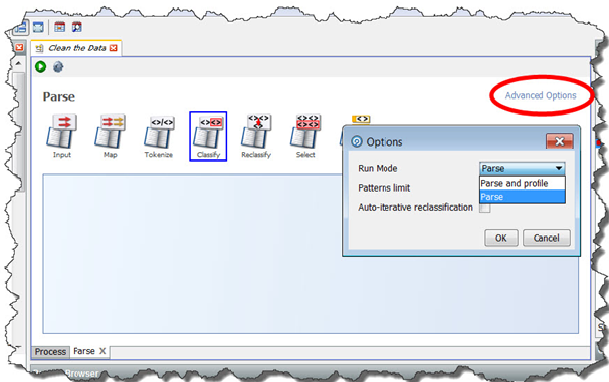
解析プロセッサからメトリックとデータの出力のみが要求される場合にさらにパフォーマンスを向上するには、パーサーを含むプロセスをドリルダウンなしで実行できます(前述の「結果の書込みの最小化」を参照)。
解析の構成を繰り返し設計する際に高速なドリルダウンが必要な場合、通常は、少量のデータを処理するのが最適です。解析プロセッサの構成によって、指定した入力レコードの様々なパターンが複数生成される場合(たとえば、多くの分類および再分類ルールがある場合)、結果を変更することなく「パターン制限」オプションを使用して生成されるパターンの数を削減する(たとえば8にする)ことで、パフォーマンスが向上する可能性があります。このオプションを変更する場合、変更の前後で解析結果の変動をテストする必要があります。
次の方法を使用して、照合のパフォーマンスを最大化できる可能性があります。
照合のパフォーマンスは、照合プロセッサの構成に大きく依存しており、さらにその構成は照合プロセスに関連するデータの特性に依存します。適切な構成の最も重要な要素は、照合プロセッサのクラスタ化の構成です。
一般的には、できるかぎり多くの潜在的な一致を検出しながら、一致する可能性の低いレコード間での冗長な比較を実行しないようにして、その両者の間でバランスを取ることになります。適切なバランスを見つけるには、トライアル・アンド・エラーが必要で、たとえば、(クラスタ・キーで使用する識別子の文字を少なくするなどして)クラスタを拡張した場合、(クラスタ・キーで使用する識別子の文字を多くするなどして)クラスタを縮小した場合、またはクラスタの追加や削除を行った場合でそれぞれの一致統計の違いを評価します。
次の2つの一般的なガイドラインが役に立ちます。
適切に移入された多数の識別子を持つデータ(住所に加え電子メール・アドレスや電話番号といった連絡先の詳細を含む顧客データなど)を処理する場合、単一のクラスタを拡張するのではなく複数のクラスタを使用して、100万のレコードごとに最大サイズが20となるクラスタと、一部の識別子のカウンタの希薄化を目標としてください。
少数の識別子を持つデータを処理する場合(たとえば、名前とおおよその場所に基づいて個人やエンティティの照合のみを行う場合)、必然的に拡張されたクラスタを使用することになります。この場合、使用可能なデータを使用してクラスタを圧縮できるように、できるかぎり実際に保持している識別子で入力データを標準化、拡張および訂正することを目標としてください。この場合、可能であれば最大サイズが約500レコードとなるクラスタを引き続き目標とします(クラスタ内のすべてのレコードをクラスタ内の他のすべてのレコードと比較する必要があるため、500レコードの単一クラスタでは、500 x 499 = 249500回の比較が実行されることに留意してください)。
デフォルトでは、ユーザー・レビューに使用できるように、すべての照合結果でソート、フィルタおよび検索が有効になっています。ただし、大規模なデータ・セットでは、ソート、フィルタおよび検索を有効にするために必要な索引作成プロセスは、非常に時間がかかることがあり、一定の場合には不要なこともあります。
一致レビュー・アプリケーションを使用して照合の結果を確認する機能を必要とせず、結果ブラウザでの照合の出力をソートまたはフィルタする必要がない場合、ソートとフィルタを無効にしてパフォーマンスを向上してください。たとえば、照合の結果を外部に書き込んで確認したり、本番環境へのデプロイ時に照合を完全に自動化できます。
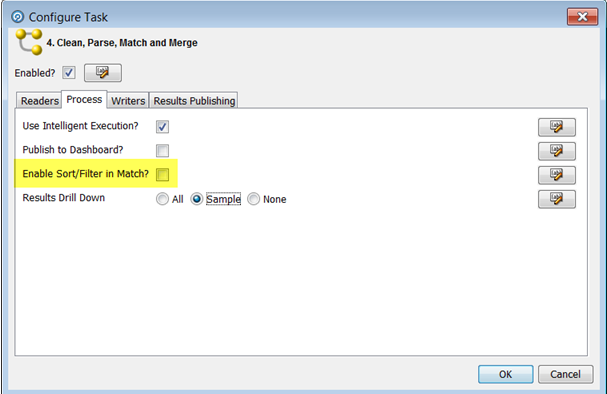
ソートとフィルタを有効化または無効化する設定は、プロセッサの「拡張オプション」で設定できる個々の照合プロセッサ・レベルでも(詳細は照合プロセッサのソート/フィルタ・オプションを参照)、プロセスまたはジョブ・レベルのオーバーライドとしても使用可能です。
プロセスのすべての照合プロセッサで個々の設定をオーバーライドし、照合結果のソート、フィルタおよびレビューを無効にするには、ジョブ構成またはプロセス実行プリファレンスの照合プロセッサのソート/フィルタを有効化するオプションを選択解除します。
|
注意: 「照合でのソート/フィルタを有効化?」は、ジョブにプロセスが含まれる場合、デフォルトで無効になっています。 |
照合プロセッサは、最大3つのタイプの出力を書き出すことができます。
一致(またはアラート)グループ(照合プロセッサによって決定される一致レコードのセットに編成されたレコード。照合プロセッサで一致レビューを使用する場合は一致グループが生成され、ケース管理を使用する場合はアラート・グループが生成されます。)
関係(一致レコード間のリンク)
マージ済出力(一致レコードの各セットからマージされたマスター・レコード)
デフォルトでは、すべての使用可能な出力タイプが書き込まれます。(マージ済出力は、リンク・プロセッサから書き込むことはできません。)
ただし、プロセスでは、すべての使用可能な出力が必要なわけではありません。たとえば、一致レコードのセットのみを識別する場合、マージ済出力は無効にする必要があります。
出力のいずれかを無効にしても、ユーザーが照合プロセッサの結果を確認する機能に影響はありません。
一致(またはアラート)グループの出力を無効にする手順:
キャンバスで照合プロセッサを開き、照合サブプロセッサを開きます。
一番上の「一致グループ」または「アラート・グループ」タブを選択します。
「一致グループ・レポートの生成」または「アラート・グループ・レポートの生成」オプションの選択を解除します。
または、関連レコードまたは関連のないレコードのグループのみを意図的に出力する場合、画面の同じ部分にある他のチェック・ボックスを使用します。
関係の出力を無効にする手順:
キャンバスで照合プロセッサを開き、照合サブプロセッサを開きます。
一番上の「関係」タブを選択します。
「関係レポートの生成」オプションの選択を解除します。
または、一部の関係のみ(たとえば、レビュー関係のみ、または一定のルールにより生成された関係のみ)を意図的に出力する場合、画面の同じ部分にある他のチェック・ボックスを使用します。
マージ済出力を無効にする手順:
キャンバスで照合プロセッサを開き、マージ・サブプロセッサを開きます。
「マージ済出力の生成」オプションの選択を解除します。
または、関連レコードのマージ済出力レコードや、関連のないレコードのみを意図的に出力する場合、画面の同じ部分にある他のチェック・ボックスを使用します。
バッチ照合プロセスでは、効率的にレコードを比較するためにEDQリポジトリにデータのコピーが必要です。
データは、リーダーとプロセスの照合プロセッサとの間で変換される可能性があり、照合プロセスで使用されるスナップショットがリフレッシュされた場合に照合結果を確認できる機能を維持するため、照合プロセッサでは、常に作業対象となるデータ(リアルタイム入力のものを除く)の独自のスナップショットが生成されます。大規模なデータ・セットでは、これに時間がかかる可能性があります。
そのため、照合プロセスで最新のソース・データを使用する場合、最初にスナップショットを実行してからデータを照合プロセッサにフィードするより、スナップショットをストリームして、独自の内部スナップショットを生成することをお薦めします(効率的にデータを2回コピーできます)。前述のスナップショットのストリームの説明を参照してください。
EDQの住所の検証プロセッサは、Enterprise Data Quality住所検証サーバー(EDQ AV)へのパイプです。EDQ AVは、各入力レコードを、そのグローバル・ナレッジ・リポジトリの該当する国で存在するすべての住所に対して照合します。この操作は、本質的にリソース集中型であり、実行に時間がかかります。この理由から、住所の検証プロセッサは、独自のプロセスに配置するか、ごく少数の他のプロセッサとともに使用することをお薦めします。これにより、処理を分離してそのパフォーマンスを正確に測定できるため、チューニングが容易になります。EDQ住所検証サーバーは、EDQアプリケーション・サーバーのJavaヒープの外部に相当量のメモリーを必要とします。住所の検証のパフォーマンスは、使用可能なメモリーが不十分であると影響を受ける可能性があります。EDQアプリケーション・サーバーのJavaヒープのチューニングの詳細は、アプリケーション・サーバーのチューニングの説明を参照してください。キャッシュ・オプションをチューニングすることで、住所の検証のパフォーマンスを調整できます。これらのパラメータは、住所の検証プロセッサの「オプション」タブで使用できるそのプロセッサの「追加オプション」フィールドを使用して制御できます。調整に役立つ2つのパラメータは、次のとおりです。
ReferenceDatasetCacheSize
ReferencePageCacheSize
使用可能なオプションの詳細は、Loqateのサポート・サイト(https://www.loqate.com/support/options/)を参照してください
これらのパラメータを調整する前に、Loqateサポートのアドバイスを検索してください。
住所の検証のキャッシング・パラメータを調整することに加え、住所をスクリーニングする国ごとに異なるEDQプロセスを作成すると、住所の検証のパフォーマンスを大幅に向上できます。
詳細は、次を参照してください。
EDQの照合プロセッサは、本質的に非常に効率的で、多くの自動最適化を行います。ただし、構成が不十分であると、パフォーマンスに重大な影響を与える可能性があります。照合プロセスの実行に長い時間がかかる場合、そのクラスタ構成が原因である可能性があります(大規模なクラスタが多すぎると、通常、比較の回数も多くなり、結果として照合が遅くなります)。
よくある誤解は、同じリーダーの複数のパスを結合する場合、データ・ストリームのマージ・プロセッサが必要であるというものです。これは間違っています。異なるリーダーの完全に異なっているデータ・ストリームを結合する場合はデータ・ストリームのマージ・プロセッサを使用する必要がありますが、通常のどのEDQプロセッサでも、同じリーダーの複数のパスを結合して、結合したすべてのパスのすべての個別レコードを処理できます。
非常に大規模で複雑な単一プロセスのパフォーマンス問題の原因を特定することは、非常に困難です。かわりに、個別の操作に対して個別のモジュール・プロセスを作成し、それらをデータ・インタフェースで結合してください。このアプローチを採用すると、各プロセスの実行時間を簡単に把握できるため、診断がずっと容易になります。さらに、プロセスのサイズが小さくなるほど、その理解および管理が簡単になるというメリットも加わります。
スクリプト・プロセッサの使用が必要なこともありますが、その場合、ほぼすべての状況で、コンパイルされたJavaコードを使用するコア・プロセッサを実行するよりパフォーマンスが低下します。本当に必要な場合を除き、スクリプト・プロセッサは使用しないでください。
EDQの監査および変換プロセッサは、一度に1つのレコードを処理します。これらは、その処理をすべてメモリー内で実行することや、アプリケーション・サーバーが保持している範囲で任意にCPU性能をスケーリングすることができます。一方で、EDQの照合プロセッサは、データのセットを処理できます。(これは、一部のプロファイリング・プロセッサにも当てはまります。詳細は、前述のリソース集中型プロセッサのリストを参照してください。)データ・セットのレコードの類似度を評価するために、照合プロセッサは、これらのデータ・セットをEDQリポジトリ・データベースに書き込みます。このI/Oオーバーヘッドは、照合プロセッサに必要です(レコード重複プロファイラ、クイック統計プロファイラ、レコード重複チェック・プロセッサおよびフレーズ・プロファイラでも同様です)。いくつかのシナリオでは、照合プロセッサが絶対に必要です。たとえば、次の場合は照合プロセッサを使用する必要があります。
大規模なデータ・セットであいまい一致を識別する場合。
複数のフィールドを使用して一致を識別する場合。
可能性がある一致を確認する必要がある場合。
ただし、単一のフィールドが完全に一致するレコードを単純に戻す必要がある場合、ルックアップと戻りプロセッサの方が、照合プロセッサより迅速に実行できる可能性があります。
効率的なプロセスの設計以外では、EDQ自体の広範なチューニングは必要ありません。変更できる有益なパラメータはごく少数で、ほとんどの場合、それらはデフォルト値のままに設定しておくことができます。(詳細は、『Oracle Fusion Middleware Oracle Enterprise Data Qualityの管理』を参照してください)。ただし、EDQはエコシステム内に存在します。物理的なハードウェアおよびネットワーク・インフラストラクチャ以外で、このエコシステムの最も重要な部分は、EDQが実行されるプラットフォーム(特にアプリケーション・サーバーとデータベース・リポジトリ)です。ほとんどのパフォーマンス問題の原因は、最適化されていないプロセスおよびジョブ構成であり、それらを解決するためにプラットフォームをチューニングする必要はありません。ただし、一定の場合、いくつかの単純なプラットフォーム最適化の手順によって、パフォーマンスが向上する可能性があります。プラットフォームのチューニングを検討する前に注意してもらいたいことは、新しいEDQインストールを構成する場合、システムを通じてテスト・データの実際のロードを実行して、設定を完了する前にその結果を確認する必要があるということです。
アプリケーション・サーバーの最大Javaヒープ・サイズをチューニングすると、パフォーマンスが向上する可能性があります。最大Javaヒープ・サイズをチューニングする場合、次の点に注意してください。
プロセッサ・コア(とそれに対応するスレッド)の数を増やすほど、Javaヒープに割り当てるメモリー量を増加する必要があります。最適なパフォーマンスを得るには、ランタイム・スレッドごとに2GBのメモリーを割り当てることをお薦めします。(EDQでは、検出された論理CPUごとに1つのランタイム・スレッドが使用されることに注意してください)。
ほとんどの場合、8GBの設定で十分です。
|
注意: EDQカスタマ・データ・サービス・パック(CDS)では、集中的にメモリーを使用する必要があり、状況によっては8GBを超える量が必要です。 |
サーバーのメモリー全体からJavaヒープに多く割り当てすぎると、Javaヒープ以外のメモリーを必要とするアプリケーション(たとえば、EDQ住所検証サーバー)を実行するための余分なメモリーが不足するため、パフォーマンス問題が発生する可能性があります。各スレッドでもJavaヒープ以外のメモリーを必要とするため、EDQが多くのスレッドにアクセスする場合、Javaヒープ以外のメモリーに対する必要性も増大します。一般的には、サーバーのメモリー全体の3分の2を超えてJavaヒープに割り当てないようにします。
アプリケーション・サーバーのチューニングの詳細は、『Oracle Fusion Middleware Oracle Enterprise Data Qualityの管理』を参照してください。
EDQでは、照合などの特定の操作を効率的に実行するために最適なデータベースI/Oが必要とされますが、データベースのチューニング方法は、固有の使用例や環境に応じて異なります。ただし、いくつかの一般的なアドバイスを提供することは可能です。データベース管理者の注意点は次のとおりです。
EDQに十分な表領域を割り当てていることを確認します。(表領域のサイズおよび他のデータベース設定のガイドラインは、『Oracle Fusion Middleware Oracle Enterprise Data Qualityのインストールと構成』を参照してください。)
データベースのI/Oパフォーマンスをチューニングするには、経験的なアプローチを採用します。
EDQのインストレーション・ガイド(および適切な項へのリンク)に従って、PGA、SGA、プロセスとセッションなどの重要な設定を指定します。
WebLogicでは、構成済のデータソースによって、データベースに対する接続の最大数を制御することにも注意してください。多くのスレッドが実行される大規模システムでは、状況により、(EDQプロセスによりデータの書込みと読取りが行われる)結果データベースに対する最大接続数をデフォルト値の200から調整する必要があります。ほぼすべての使用例で、500の値で十分です。
アーカイブ(REDO)・ロギングは、リソースを消費します。一定の状況で、サーバー上のすべてのEDQ処理が完全にステートレスで、サービスを失うことなくサーバーを自動的に再プロビジョニングできる場合、パフォーマンスを向上するためにデータベースのアーカイブ・ロギングをオフにすることが適切です。または、これが不可能である場合、個別のディスクにREDOログ・ファイルをマウントすることで、パフォーマンスを向上できる可能性があります。
EDQでは、検出された論理CPU (またはコア)ごとに1つのランタイム・スレッドが作成されます。これは、可能な場合、パラレル・スレッド間で処理を分割します。一般的に、コアが追加されるとプロセスの実行時間は短縮されます。ただし、Java仮想マシン(JVM)で使用できるコアが一定数に達した後は、追加コアごとの処理時間の短縮は、ごくわずかとなる傾向があります(処理能力の増大が、競合の増加によって相殺されるためです)。これは、システムの他の部分(ファイルやデータベースを対象とする読取りと書込みなど)が最適化されていても同様です。典型的なバッチ処理では、JVMに追加されるコアごとの実行時間の短縮は、JVMで使用されるコアの合計数が16を超えるとごくわずかとなります。
ジョブの実行に使用されるプロセス・スレッドの数は、使用可能なコアの数に自動的に設定され、通常は変更できません。ただし、EDQが16より多くのコアを持つサーバーにインストールされており、そこで負荷の高いバッチ処理ワークロードを実行している場合、EDQで使用されるスレッドの数を手動で16に設定できます。その理由は、スレッドの数が多すぎると、スレッドが自身の作業を終了したときに、リソースの競合が発生する可能性があるためです。
スレッドの数を手動で設定するには、EDQインスタンスのoedq.local.homeフォルダにあるdirector.propertiesファイルの次のパラメータを変更します。
runtime.threads = 16
runtime.indexingthreads = 16
workunitexecutor.outputThreads = 16
EDQが16より多くのコアを持つサーバーにインストールされている場合、別の管理対象サーバーを追加してスケーリングできます。すべての管理対象サーバーは、同じWebLogicクラスタ内に配置する必要がありますが、それぞれ個別のJava仮想マシン内で実行されます。別の管理対象サーバーを追加する方法の詳細は、『Oracle® Fusion Middleware Oracle Enterprise Data Qualityの理解』の高可用性に関する項を参照してください。単一のEDQバッチ・ジョブは、常に単一の管理対象サーバー上で実行されるため、管理対象サーバーを追加しても、必ずしも個々のジョブがより高速に実行されるわけではありません。複数の管理対象サーバーを用意するメリットは、異なるジョブを異なる管理対象サーバーで同時に実行できるようになることです。
データベース・サーバーは、EDQが実行されているアプリケーション・サーバーから遠く離れた場所に配置できますが、高速なネットワークで接続する必要があります。
