| Oracle® Fusion Middleware Oracle Enterprise Data Qualityの使用 12c (12.2.1.2.0) E88274-01 |
|

 前 |
この章では、EDQの拡張機能の概要について説明します。
この章の内容は次のとおりです。
照合が必要な理由
1つ以上のビジネス・アプリケーションからの情報を照合および調整する必要は、様々な場合に発生します。例を示します。
複数のシステムで保持されるデータの調整
システムと情報の重複につながるマージと取得
重複を除去したい新規システムへのデータの移行
信頼された参照セットとの照合によるシステム情報の品質向上が必要であることが認識されている場合
照合が複雑になりうる理由
レコードが相互に一致するかどうかを定義するのは、常に単純なわけではありません。次の2つのレコードを考えてみます。

これらはどのデータベース・フィールドも異なりますが、調査すると、レコードの間には明らかに類似性があります。例を示します。
共通の姓を共有
2番目に番地さえなければ住所は同じ
これらを「同じ」として扱うかどうかの意思決定は、次のような要因に依存します。
情報の使用目的は何か。
意思決定に役立つ他の情報はあるか。
効率的な照合には、ソース・データの高度な完全性と正確性を想定する従来のデータ分析テクニックよりも、はるかに高度なツールが必要です。情報を使用する方法のビジネス・コンテキストが意思決定プロセスに含まれることも要求されます。たとえば、同じ住所に関連付けられた複数の個人を1件の顧客とみなしますか、それとも2件とみなしますか。
EDQで問題を解決する方法
EDQからは、照合が必要な最もよくあるビジネス上の問題に適した照合プロセッサのセットが提供されます。照合プロセッサでは複数の論理段階、および照合に関するユーザーの思考方法に相当する単純な概念が使用されます。
識別子
1フィールドのレベルでの照合ルール記述をユーザーに強制するかわりに、EDQの照合プロセッサは強力な識別子の概念を活用しています。
ユーザーは識別子を使用して、関連するフィールドを実世界のエンティティにマップでき、広範囲の利点を提供できます。
類似の情報が異なるアプリケーションまたはデータベースに保管される場合、識別子をマップして、フィールド間の命名の差異を克服できます。図に示すと次のようになります。
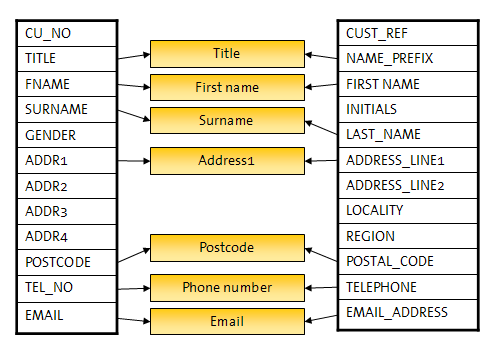
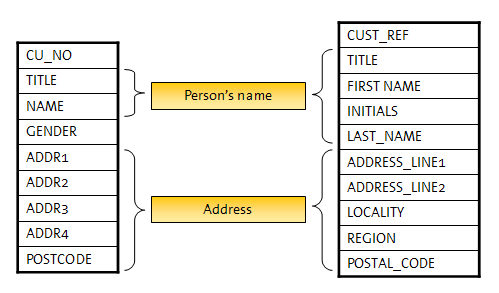
個人の名前など、特定のタイプの識別子では、EDQの拡張性を利用して、新規の識別子タイプ、および関連付けられた比較も導入できます。これらの新規識別子タイプによって、多数のフィールドを単一の識別子にマップし、構造の差異を一度に扱い、その後で無視できます。この場合、照合ルールはフィールド・レベルでなくエンティティ・レベルで動作するので、単純ですが強力です。その結果、構成はより迅速に定義でき、より理解しやすくなります。図に示すと次のようになります。
クラスタ化
クラスタ化とは、照合に必要な部分であり、照合プロセッサがすべてのレコードを他のすべてのレコードと比較しようとしないようにするために、データ・セットをクラスタに分割するために使用されます。
EDQでは、多数の識別子を使用して、同一の照合プロセッサに多数のクラスタを構成できるので、事前にクラスタ・キーが形成されたデータに依存する必要がなくなります。
クラスタ化の詳細は、「クラスタ化概念ガイド」を参照してください。
比較
比較とは、識別子の値を相互に比較し、比較結果を出力する置換可能なアルゴリズムです。出力される結果の性質は、比較に依存します。たとえば、比較の結果は単なるTrue (一致)またはFalse (一致なし)の場合もあれば、一致の強度を示すパーセント値の場合もあります。
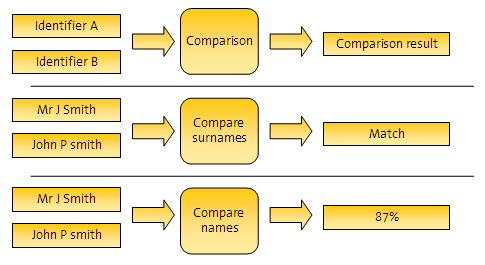
一致ルール
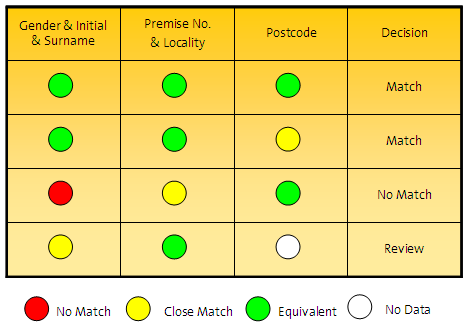
一致ルールは、比較結果をそのビジネス上の重要性に従って解釈する方法を提供します。比較結果を解釈するために、順序付けしたルールをいくつでも構成できます。各ルールから3つの決定のいずれかを導出できます。
一致
一致なし
レビュー – 一致を確認または拒否するには手動レビューが必要
一致ルールを使用してすべての比較にわたるルール表が生成され、たとえば次のような一致演算の決定が行われます。
事前構築された照合プロセスの使用
EDQは、データや特定の照合要件にあわせて最適化されておらず、変更するのがより困難な事前作成済の照合プロセスに頼らずに、新規の照合プロセスをより迅速かつ容易に作成できるように設計されています。
しかし、場合によっては、EDQでの照合の動作方法を学習するため、また初期結果を迅速に提供する目的でデータにおける重複のレベルを示すために、照合テンプレートを使用できます。
構成可能性および拡張性
EDQには高度に構成可能かつチューニング可能な照合アルゴリズムのライブラリがあり、ユーザーは照合プロセスを調整して、保有するデータで可能なかぎり最善の結果を達成できます。
さらに、EDQでは新規照合アルゴリズムとアプローチを定義できます。「最善の」照合機能は、示される問題と照合されるデータの性質に完全に依存します。照合プロセスのすべてのキー要素では、拡張したコンポーネントを使用できます。例を示します。
レコードを識別するために使用するもの
レコードを比較する方法
比較の品質を向上させるためにデータを変換および操作する方法
構成可能性と拡張性を組み合せることで、必ず最適なソリューションを最短の時間でデプロイできます。
照合拡張をアプリケーションに追加する詳細は、Enterprise Data Qualityオンライン・ヘルプのEDQの拡張に関する項を参照してください。
主な機能
EDQの照合の主な機能には、次のものがあります。
あらゆるタイプのデータの照合
照合プロセスの構成によるガイダンス
ユーザー定義可能なデータ識別、比較および一致ルール
ビジネス・ルールに基づく照合
照合およびマージ決定用のマルチユーザー手動レビュー機能
新規データが表示されるときに手動決定を再び表示
照合プロセスからの出力の生成を自動化
構成可能な照合ライブラリにより、大半の要件に対応するフレキシブルな照合機能を提供
拡張可能な照合ライブラリにより、最適な照合アルゴリズムをデプロイ可能
一致決定のインポートとエクスポートが可能
レビュー・アクティビティ(決定とレビュー・コメント)の完全な監査証跡を提供
クラスタ化とは、照合の必須要素であり、高速な照合結果を生成するために必要です。データ・セットの「最初の切分け」を高度な処理能力を駆使して行い、システム・パフォーマンスの観点からは実現不可能な、すべての単一レコードの相互比較プロセスの照合プロセッサでの実行を回避します。
クラスタ化はリアルタイム照合にも不可欠であり、EDQがシステム内のすべてのレコードの同期されたコピーを保持しなくても、新規レコードをそのシステムに存在するレコードと照合できるようになります。
クラスタ
EDQでの照合は、すべてのレコードの相互比較を試行せず、クラスタ化プロセスによって作成されるクラスタ内で行われます。
クラスタ化ではデータ・セットにあるいずれのレコードの比較も試行しません。かわりに、1レコードずつの照合に使用する識別子の値を1つ以上操作して、データ・セットのクラスタを作成します。共通の操作された値(クラスタ・キー)を持つレコードが同じクラスタに属するようになり、照合で相互に比較されます。異なるクラスタにあるレコード間での比較は行われず、単一のレコードを含むクラスタは照合で使用されません。
「文字列から配列を作成」変換を使用して、スペースで区切られた名前識別子からのすべての値をクラスタ化する、名前列に対する単一クラスタを次に図示します。
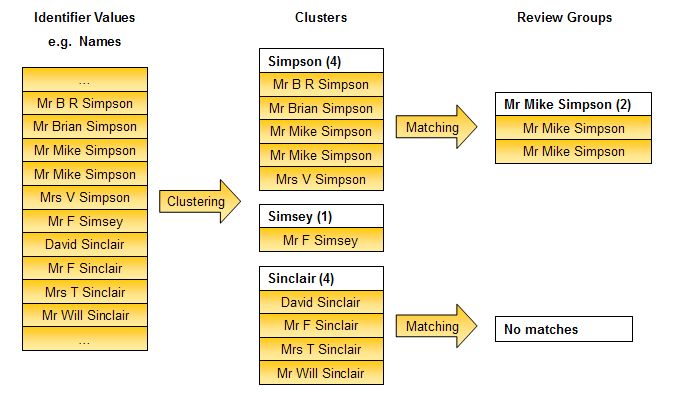
したがって、クラスタ化のプロセスは照合プロセスのパフォーマンスと機能にとって重要です。作成されるクラスタが大きすぎると、照合で行われる比較が多すぎ、実行が低速になることがあります。一方、クラスタが小さすぎると、クラスタ化できない類似の値が存在することになり、一致する可能性があるレコードをみのがす可能性があります。
必要な照合に応じて、クラスタ化でわずかに異なるレコードに対して共通のクラスタ・キーを生成できる必要があります。たとえば、「Oracle」および「Oracle Ltd」のような識別子の値を持つレコードが同じクラスタに属し、相互に比較可能になるのが望ましいことです。
複数のクラスタ
EDQでは複数のクラスタの使用がサポートされます。指定のデータ・セットに対して、識別子の値がわずかに異なる一致が存在する可能性があるため、単一の識別子の値を使用したクラスタ化は不十分なことがよくあります。たとえば、姓フィールドのデータの一部にスペル・ミスがあることがわかっている場合、変換がない姓クラスタは信頼できず、soundexまたはmetaphone変換を追加すると、クラスタが大きくなりすぎる可能性があります。この場合、追加のクラスタが必要になる場合があります。別のクラスタを別の識別子に対して構成すると、完全に新規のクラスタが作成され、それらに対して同じ照合プロセスが実行されます。たとえば、郵便番号の最初の3桁をクラスタ化することを選択し、CB4の郵便番号を持つすべてのレコードが照合目的で単一クラスタに属するようにできます。
異なる変換を含む異なるクラスタ化構成を使用して、同じ識別子を2度クラスタ化することもできます。これを行うには、同じ識別子に対するクラスタを2つ作成し、識別子の値に対して動作する異なる変換を構成します。
クラスタが多いほど、照合で一致が検出される可能性が高くなります。それでも、照合のパフォーマンスを損なわないようにするため、クラスタは少なめに使用してください。存在するクラスタが多いほど、照合で比較する必要があるレコードが多くなります。
複合クラスタ
複合クラスタによって、複数の識別子を使用してデータ・セットをクラスタに分割するさらにわかりやすく効率的な方法が提供されます。この場合、各識別子の異なる部分が結合され、単一のクラスタ・キーとなり、照合するレコードをグループ化するために使用されます。たとえば、顧客を照合する場合、姓識別子と郵便番号識別子の組合せを使用して、次のクラスタを構成するとします。
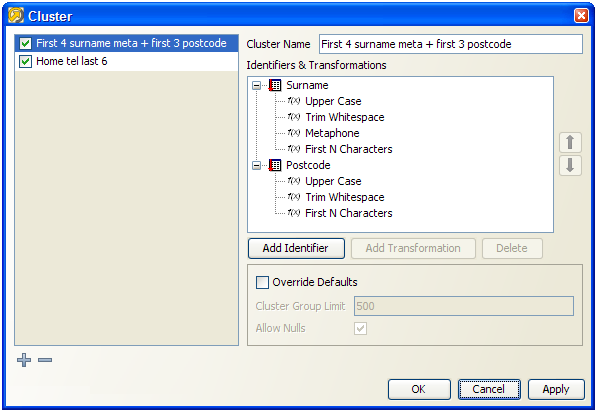
したがって、照合プロセスで各レコードについて、姓識別子の値が変換され(大文字に変換、すべての空白を削除、metaphone値を生成、および最初の4文字に切捨て)、次に郵便番号識別子からの変換値(大文字に変換、すべての空白を削除、および最初の3文字に切捨て)と連結します。
変換後の識別子の値の連結は構成されず、自動的に行われます。
そのため、前述のクラスタ構成を使用して、クラスタ・キーが次のように生成されます。
| 姓 | 郵便番号 | クラスタ・キー |
|---|---|---|
| Matthews | CB13 7AG | M0SCB1 |
| Foster | CB4 1YG | FSTRCB4 |
| JONES | SW11 3QB | JNSSW1 |
| Jones | sw11 3qb | JNSSW1 |
つまり、最後2つのレコードは同じクラスタになり、一致の可能性があるため相互に比較されますが、他の2つのレコードとは比較されません。
クラスタ化における変換
クラスタ化における変換により、本質的には同じ値の間にあるスペース、大文字と小文字、スペルおよび他の差異を正規化し、識別子の値が同一ではなく単なる類似であるレコードのクラスタを作成できます。
たとえば、Name識別子ではクラスタ化のときにMetaphone変換またはSoundex変換のいずれかを使用し、類似する音の名前を同じクラスタに含めることができます。これにより、データにスペル・ミスが含まれる可能性がある場合でも照合が可能になります。たとえば、姓識別子に対するSoundex変換を使用すると、「Fairgrieve」および「Fairgreive」という姓が同じクラスタに属するようになり、可能性がある重複がレコードに含まれるかどうかが照合で比較されます。
識別子に対して有効な変換は、識別子のタイプに依存して変化します(たとえば、文字列用には番号用とは異なる変換があります)。
たとえば、文字列識別子に使用可能な変換の一部は次のとおりです。
文字列から配列を作成 (デリミタを使用して、値を個別の各単語に分割し、各単語の値によってグループ化します。たとえば、スペース・デリミタを使用する場合、「JOHN」と「SMITH」が値「JOHN SMITH」から分割されます)。
最初のN文字 (値の最初の数文字を選択します。たとえば、「MATTHEWS」からは「MATT」です)。
イニシャルの生成 (識別子の値からイニシャルを生成します。たとえば、「Internal Business Machines」からは「IBM」です)。
EDQには大半の要件に応える変換のライブラリが備わっています。カスタム変換のシステムへの追加もできます。
変換のオプションにより、識別子の値変換方法を変更できます。使用可能なオプションは変換ごとに異なります。
たとえば、「最初のN文字」変換には次のオプションを構成できます。
文字数 (選択する文字数)
無視する文字 (選択前にスキップする文字数)
クラスタ化の使用
「最善の」クラスタ化設定は、照合で使用するデータ、および照合プロセスの要件に依存します。
多くの識別子を指定のエンティティに使用する場合でも、クラスタは1つか2つの識別子にのみ使用するのが最適です。たとえば、人々を姓およびほぼ正確な誕生日(たとえば生年)によりグループとしてクラスタ化する場合でも、名と郵便番号のクラスタは作成せずに、これらの属性を照合プロセスで使用します。
再び、このことはソース・データ、特に各属性のデータの品質と完全性に依存します。正確な照合結果を得るには、クラスタ機能で使用する属性には高い品質が要求されます。なかでもデータは完全かつ正しいものである必要があります。照合前に監査プロセッサと変換プロセッサを使用して、クラスタ化が望ましい属性に高品質のデータが移入されていることを確認できます。
まずきわめて単純なクラスタ化構成から開始するのが一般的であり(たとえば、人々を照合するとき、姓属性の最初の5文字を使用し、大文字に変換してレコードをグループ化)、クラスタも最初はかなり大きなものになります(多くのグループでは数百件のレコード)。照合プロセスがさらに開発され、おそらくはサンプルでなく完全なデータ・セットに適用された後、パフォーマンスを向上させるためにクラスタ化の構成をより繊細にできます(たとえば、姓属性の最初の5文字に郵便番号属性の最初の4文字を続けて使用し、レコードをグループ化)。これには、クラスタが小さくなり、実行する必要がある比較の総数が減少するという効果があります。
複数の識別子を照合し、いくつかのキー識別子に空白やnullが含まれる場合、大きいグループを持つ単一クラスタよりも複数のクラスタを使用するほうが一般的により適切です。
|
注意: すべてのユーザー指定クラスタ化変換が適用された後、クラスタ化エンジンが終了する前に、すべてのデータなし(空白)文字は常にクラスタ・キーから削除されます。たとえば、「文字列から配列を作成」変換を使用して、データをスペースで分割する場合、値「Jim<space><carriage return>Jones」と「Jim<space>Jones」のどちらからも、クラスタ値「Jim」と「Jones」が作成されます。前者からクラスタ値「<carriage return>Jones」は作成されません。この目的は、ユーザーがクラスタ化のときデータにある様々な形の空白をどう処理するかを常に考慮する必要をなくすことです。 |
クラスタ化プロセスのレビュー
EDQでは、照合で使用するクラスタをレビューして、必要なレベルの粒度で必ず作成されるようにできます。
これは、照合プロセッサがクラスタ化構成を使用して実行されたときに作成されるクラスタのビューを使用することで可能になります。結果ブラウザには、生成されたクラスタのビューがクラスタ・キーとともに表示されます。
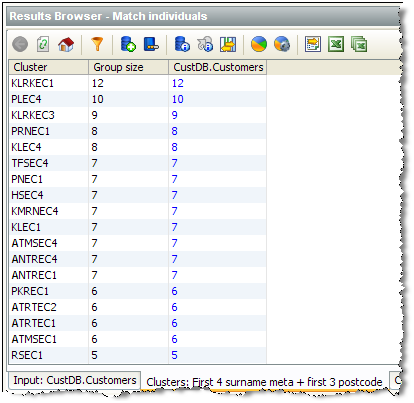
クラスタの分割が推奨されない類似のグループを把握するために、クラスタ・キーの値を使用してクラスタのリストをソートできます。
ドリルダウンすることで、各入力データ・セットから各クラスタ内部の構成レコードを知ることができます。たとえば、前述のクラスタ・キー「KLRKEC3」を持つ顧客データ・セットからの9件のレコードは次のとおりです。
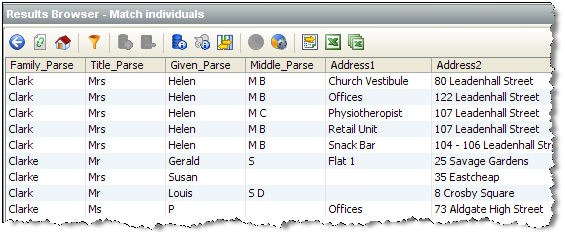
この方法で、エキスパート・ユーザーはクラスタ化プロセスを調査およびチューニングし、最適な結果を最速の時間で生成できます。たとえば、クラスタが大きすぎ、照合パフォーマンスが損なわれる場合、追加のクラスタを作成するか、クラスタ構成をより厳格にできます。一方、可能性がある一致が異なるクラスタにあることをユーザーが認識できれば、クラスタを拡張するためにクラスタ化オプションを変更する必要が生じる可能性があります。
|
注意: クラスタ化方針によっては、大きいクラスタが作成されます。たとえば、識別子に多数のnull値が存在し、クラスタ・キーがNULLである大きいクラスタが作成される場合、これが当てはまることが多くなります。構成可能なレコード数より多いレコードがクラスタに含まれるか、実行される比較が多数になる場合、クラスタをスキップして照合エンジンのパフォーマンスを節約できます。クラスタのデフォルト最大サイズはレコード500件であり、各クラスタで実行する比較の最大数の制限もできます。これらのオプションを変更するには、Enterprise Data Qualityオンライン・ヘルプの照合プロセッサの拡張オプションに関する項を参照してください。 |
EDQでは異なる2種類のリアルタイム照合が利用できます。
リアルタイム重複防止は、動的に変化するデータ(たとえば、アプリケーションの動作データ)に対する照合が目的です。
リアルタイム参照照合は、ゆっくりと変化するデータ(たとえば、参照リスト)に対する照合が目的です。
この項は、EDQでリアルタイム照合が動作する方法の一般的なガイドです。
|
注意: EDQをリアルタイム重複防止またはデータ・クレンジング、あるいはその両方のためにOracle Siebel UCMまたはCRMとともに使用する場合は、Oracleからこの目的で標準のコネクタが提供されます。 |
リアルタイム重複防止
EDQのリアルタイム重複防止機能では、照合するデータは動的であり、定期的に変更されることを想定しています(たとえば、広範囲で使用されるCRMシステムの顧客データ)。この理由で、EDQでは作業データはコピーされません。かわりに、EDQクラスタ生成プロセスを使用して生成されたキー値を使用して、ソース・システムでデータが索引付けされます。
リアルタイム重複防止は、クラスタ化、そして照合という2段階で発生します。
クラスタ化
クラスタ化段階では、EDQは新規レコードをリアルタイム・インタフェースで受け取り、リアルタイム実行向けに有効化されたプロセスを使用して、クラスタ・キーを割り当てます。ライターを使用して、レコードのクラスタ・キーを返します。次にソース・システムがこのメッセージを受信して、事前入力された表を使用して候補レコードを選択し、クラスタ・キーの1つを駆動レコードと共有するすべてのレコードのセットをEDQにフィードバックします。
通常は、レコード当たりのキー値を多数生成することが推奨されます。これはバッチ照合の場合も同様です。
照合
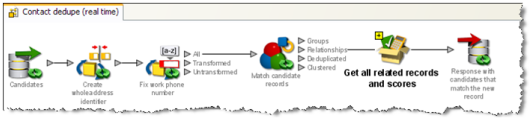
照合段階では、EDQはクラスタ・キーを入力レコードと共有するレコードを含むメッセージを受信します。次に、単一入力に対する動作レコードとして示されたすべてのレコードとともに照合プロセッサを使用して、これらの候補一致レコードから新規レコードへの確実な一致と可能性がある一致を選択し、一致のソートに使用できるスコアを割り当てます。その後、照合結果がリアルタイム・インタフェースで返され、このレスポンスが外部で処理され、システムを更新する方法が決定されます。可能性があるレスポンスとしては、新規(重複)レコードの拒否、新規レコードとその重複レコードのマージ、または新規レコードの追加、ただし重複レコードへのリンクを含めることがあります。
リアルタイム照合プロセスの例を次に示します。
リアルタイム参照照合
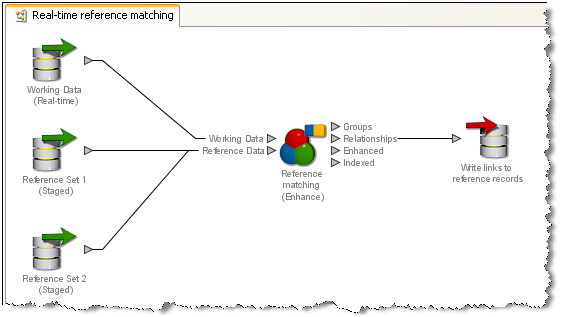
EDQのリアルタイム参照照合の実装では、新規レコードが1つ以上の参照セットと照合されます。参照セットのデータは動的でないと想定されます。つまり、定期的に更新されますが、複数ユーザーによって均一にアクセスおよび更新されるわけではありません(たとえば、CRMデータでなくウォッチ・リスト)。参照照合は単一段階のプロセスです。動作するリアルタイム・ソースから受け取るレコードは、1つ以上のステージング済ソースからの参照レコードのスナップショットに対して照合されます。次に、プロセスに対するライターが、照合プロセッサの出力を呼出し元システムに返します。返される出力は、照合プロセッサからのどの形の出力でもかまいません。新規レコードを参照セットにリンクするのみの場合、関係出力に書き戻せます。照合する参照データからのデータをマージして、新規レコードを拡張する場合、照合プロセッサでマージ・ルールを使用して、マージ済(または拡張済)データ出力を書き戻せます。
|
注意: リアルタイム照合プロセスの参照データは、必要に応じてEDQサーバー上のメモリーにキャッシュし、問合せができます。詳細は、Enterprise Data Qualityオンライン・ヘルプのリアルタイム・プロセスの参照レコードのキャッシュに関する項を参照してください。 |
次の例では、参照レコードへのリンクが書き込まれます。
リアルタイム参照照合用のプロセスの準備
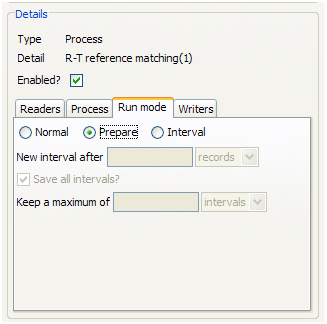
リアルタイム参照照合プロセスを正しく実行するには、まず準備モードで実行する必要があります。これにより、受信するレコードを参照セットと高速で比較し、レスポンスを発行できます。プロセスを準備モードで実行すると、参照データ・セットのクラスタ・キーがすべて生成されたことが確認されます。
プロセスを準備モードで実行するには、ジョブを設定し、関連するプロセスをタスクとして追加します。プロセスをクリックし、構成の詳細を設定します。「実行モード」タブをクリックし、「準備」を選択します。
参照データの再準備
リアルタイム照合では、参照データのキャッシュおよび準備されたコピーが使用されます。つまり、参照データが更新されるとき、スナップショットを再実行し、データを再準備する前は、更新を照合プロセスに伝播できません。
参照データの再準備には、次の作業が必要です。
リアルタイム照合プロセスの停止。
参照データのスナップショットのリフレッシュ。
準備モードでのリアルタイム照合プロセスの実行。
リアルタイム・プロセスの再起動。
トリガーは他のジョブを開始および停止でき、前述のすべてのフェーズを含むジョブを作成するために使用できます。ジョブの停止、再準備および再起動は次のようになります。
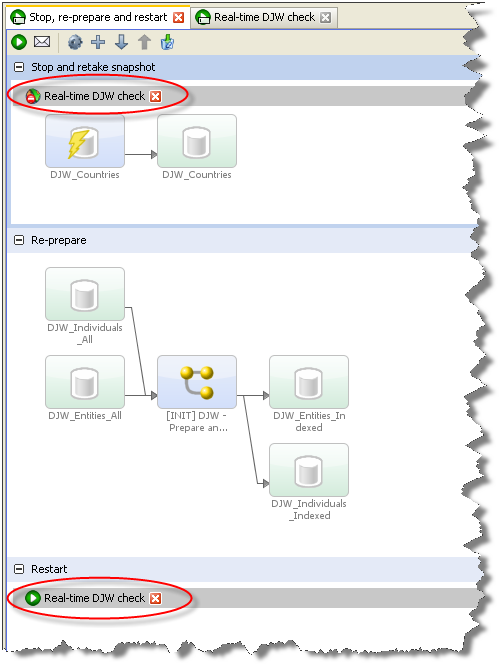
このジョブは3つのフェーズから構成されます。1番目では、リアルタイム照合プロセスが停止し、参照データ・スナップショットが再実行されます。2番目では、照合プロセスが準備モードで実行されます。3番目では、リアルタイム照合プロセスが間隔モードで再起動されます。
トリガーはフェーズの開始時または終了時に実行するように構成されるので、2番目のフェーズの終了時に再起動トリガーを置いたり、停止トリガーを1番目のフェーズの開始時に置くことができます。ただし、再起動トリガーを固有のフェーズに置くと、再準備フェーズが成功した場合のみ再起動フェーズが実行されるように構成できます。詳細は、Enterprise Data Qualityの管理のジョブ・トリガーの使用に関する項を参照してください。
リアルタイム照合の有効化
リアルタイム照合を有効化するには、照合プロセッサを含むプロセスを構成し、単一の(照合プロセッサへの)作業入力のみを使用します。
リアルタイム・プロセスは間隔モードで実行できます。間隔モードでは、プロセスは連続的に実行され、その結果を結果データベースに定期的な間隔で書き込みます。「実行オプション」を参照してください。
リアルタイム・プロセスは正常モードで実行できますが、この場合は次のようになります。
プロセスから結果が書き込まれるのは、プロセスが取り消された場合のみです(結果を保持するオプションを選択)。
|
注意: 多くの場合、すべての結果は外部、たとえばログ・ファイルで永続化できるので、書込みに要件はありません。 |
プロセスを準備する必要がある場合、準備は最初に行われるので、準備が完了するまでプロセスはレスポンスやリクエストを生成できません。
JMSまたはWebサービスを使用して外部システムと通信するように、リアルタイム・コンシューマとプロバイダのインタフェースも構成する必要があります。
|
注意: Webサービスを経由するリアルタイム参照照合の場合、EDQのWebサービス機能を使用して、リアルタイム・コンシューマとプロバイダのインタフェースを自動的に生成できます。EDQ顧客データ・サービス・パックを使用している場合、事前構成されたWebサービスが提供されます。 |
解析が必要な理由
目的に適合するデータの重要な側面は、データが見つかる構造です。構造そのものがデータの必要性に適していないことがよくあります。例を示します。
データ取得システムに、独自の用途がある情報向けの独自のフィールドがないため、多数の情報の個別部分を単一のフリー・テキスト・フィールドに入力する、明白な場所がない情報のために誤ったフィールドを使用したりする(たとえば、会社情報を個別の連絡先フィールドに入力)、などのユーザー独自の回避策が蔓延している場合があります。
異なるデータ構造を使用して、このようなデータを新規システムに移動する必要があります。
重複をデータから削除する必要がありますが、データ構造が原因で、重複の識別と削除が困難です(たとえば、建物番号などの主要な住所識別子が住所の他の部分と分けられていません)。
または、データの構造に問題がなくても、構造の用途が十分に管理されていない場合や、エラーの対象になる場合があります。例を示します。
ユーザーは必要な情報をすべて収集するようにトレーニングされていないため、連絡先を入力するときに名前フィールドに実名を入力せずに、「ハンドル」を入力するなどの問題が発生します。
アプリケーションでフィールドが非論理的な順序で表示されるため、ユーザーがデータを誤ったフィールドに入力します
ユーザーが同じエンティティを表す複数のレコードに不正確なデータを入力したり、正確なデータを誤ったフィールドに入力するなど、検出しにくい方法で重複レコードを入力します。
これらの問題はすべて低品質のデータの原因となり、多くの場合はビジネスへの損失をもたらします。したがって、データにこれらの問題があるのかを分析でき、必要な箇所では解決できることが、ビジネスにとって重要です。
EDQパーサー
EDQ解析プロセッサは、データ品質プロセスの開発者が特定のタイプのデータ、たとえば名前データ、住所データまたは製品説明の理解と変換のためにパッケージ化されたパーサーを作成するために使用するように設計されています。しかし、どのタイプのデータにも固有なのは、デフォルト・ルールがない一般的なパーサーです。データ固有ルールを作成してデータそのものを分析し、解析構成を設定できます。
用語
解析とは、データ品質の領域でも、コンピューティング一般でも、頻繁に使用される用語です。単なる「データの分解」から、精巧な人工知能を使用してコンピュータが人の言葉を「理解」できるようになる自然言語解析(NLP)全体まで、広い意味を持ちます。多くの他の用語も解析に関連して頻繁に使用されます。これらも解析と同様、異なるコンテキストでわずかに異なる意味になることがあります。このため、EDQでは解析およびその関連用語をどういう意味で使用しているのかを定義することが重要です。
次の用語と定義に注意してください。
| 用語 | 定義 |
|---|---|
| 解析 | EDQにおける解析とは、どのタイプのデータもひとまとめに理解および検証し、必要に応じてその構造を用途にあわせて改善するために、ユーザー指定のビジネス・ルールと人工知能を適用することとして定義されます。 |
| トークン | トークンとは、ルールを使用する解析プロセッサによって単位として認識されるデータです。指定のデータ値は1つ以上のトークンから構成できます。
トークンを認識するには、データの構文分析または意味分析のいずれかを使用できます。 |
| トークン化 | データを最初に構文分析し、ルールを使用してデータを最小単位(基本のトークン)に分割します。基本のトークンにはそれぞれ、一連の英字を表すために使用する<A>などのタグが付きます。 |
| 基本のトークン | トークン化で認識される初期トークン。一連の基本のトークンを後で組み合せて、分類または再分類で新たなトークンにできます。 |
| 分類 | データを意味的に分析し、基本のトークンまたは一連の基本のトークンに意味を割り当てます。各分類には、「建物」などのタグ、およびあいまいなデータに対する最適な理解を選択するときに使用する分類レベル(「有効」または「可能性のあるもの」)があります。 |
| トークン・チェック | 特定のタイプのトークンの有無をチェックするために、属性に対して適用される分類ルールのセット。 |
| 再分類 | オプションの追加分類ステップであり、一連の分類されたトークンと未分類(基本の)トークンを単一の新規トークンとして再分類できます。 |
| トークン・パターン | 単一属性において、または複数属性にわたり、トークン・タグのパターンを使用するデータの文字列の説明。
文字列データはいくつもの異なるトークン・パターンを使用して表せます。 |
| 選択 | レコードに多くの説明(またはトークン・パターン)が考えられる場合、解析プロセッサが調整可能なアルゴリズムを使用してデータの「最適な」説明を選択しようとするプロセス。 |
| 解決 | 結果(成功、レビューまたは失敗)およびオプションのコメントがある指定の選択された説明(トークン・パターン)を使用するレコードのカテゴリ化。解決では選択したトークン・パターンに基づくルールを使用して、レコードを新規出力構造に解決もできます。 |
EDQ解析プロセッサのサマリー
次の図で、EDQ解析プロセッサの動作方法のサマリーを示します。
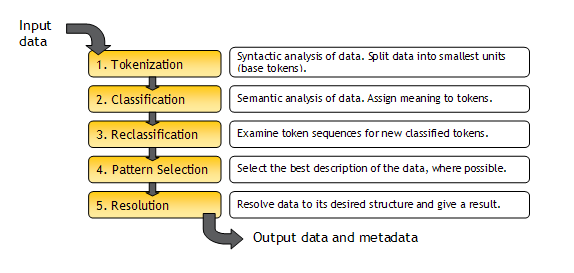
EDQ解析プロセッサを構成する方法の完全な説明は、Enterprise Data Qualityオンライン・ヘルプのEDQ解析プロセッサに関するヘルプ・ページを参照してください。
