| Oracle® Fusion Middleware Oracle Enterprise Data Qualityの使用 12c (12.2.1.2.0) E88274-01 |
|

 前 |
 次 |
この章では、EDQにおいて特定の主要なタスクを実行する方法について説明します。製品の基本をすでに理解している場合、これらは特に有用です。
この章の内容は次のとおりです。
EDQでは、GUIで対話型操作として(プロジェクト・ブラウザでオブジェクトを右クリックして「実行」を選択)、またはスケジュール済ジョブの一部として、次の種類のタスクを実行できます。
タスクには様々な実行オプションが含まれます。詳細は、次のタスクをクリックしてください。
また、ジョブを設定する際に、フェーズの実行前または実行後に実行するようにトリガーを設定することもできます。
ジョブを設定するときに、タスクをいくつかのフェーズに分割できます。これによって、処理順序を制御したり、含まれるタスクの成功または失敗によってジョブの実行方法を変えたい場合に条件付きの実行を使用したりすることができます。
ジョブの一部として「スナップショット」を実行するように構成する際には、1つのオプション「有効」があり、デフォルトで設定されています。
このオプションを無効化すると、ジョブ定義は保持されますが、スナップショットのリフレッシュが一時的に無効になります。たとえば、スナップショットをすでに実行したため、ジョブのタスクのみを後で再実行しようとしている場合に該当します。
ジョブの一部として、またはクイック実行オプションとプロセス実行プリファレンスを使用して、プロセスを実行する際には、様々なオプションを使用できます。
リーダー(処理するレコードのオプション)
プロセス(プロセスによる結果の書込み方法のオプション)
実行モード(リアルタイム・プロセスのオプション)
ライター(プロセスのレコードの書込み方法のオプション)
プロセスのリーダーごとに次のオプションを設定できます。
サンプル
「サンプル」オプションではジョブ固有のサンプリング・オプションを指定できます。たとえば、通常は数百万件のレコードに対して実行されるプロセスがあるとします。ただし、テスト目的などで、ある特定のレコードのみを処理するように特定のジョブを設定したい場合があります。
「サンプリング」の下のオプションを使用して必要なサンプリングを指定し、「サンプル」オプションを使用して有効にします。
使用可能なサンプリング・オプションはリーダーの接続方法によって異なります。
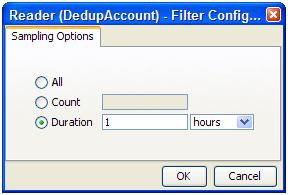
リアルタイム・プロバイダに接続しているリーダーの場合、「カウント」オプションを使用して指定レコード数で終了するようにプロセスを制限できます。または「期間」オプションを使用して期間を制限してプロセスを実行できます。たとえば、リアルタイム・モニタリング・プロセスを1時間のみ実行する方法は、次のとおりです。
ステージング済データ構成に接続しているリーダーの場合、スナップショットの構成に使用できるのと同じサンプリングとフィルタのオプションを使用して、定義済レコード・セットのサンプルのみに対して実行するようにプロセスを制限できます。たとえば、データ・ソースの最初の1000レコードのみを処理するようにプロセスを実行する方法は次のとおりです。
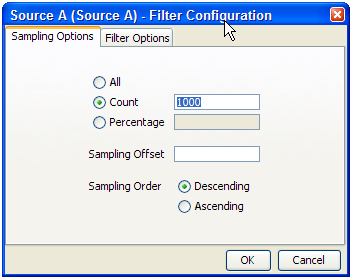
「サンプリング・オプション」のフィールドを次に示します。
すべて - すべてのレコードをサンプリングします。
カウント - n件のレコードをサンプリングします。選択するサンプリング順序に応じて、最初のn件のレコードまたは最後のn件のレコードになります。
パーセンテージ - レコードの合計数のn%をサンプリングします。
サンプリング・オフセット - この数よりも後のレコードに対してサンプリングを実行します。
サンプリングの順序 - 「降順」(最初のレコードから)または「昇順」(最後から)。
|
注意: たとえば、2000件のレコード・セットに対してサンプリング・オフセットに1800が指定されると、「カウント」または「パーセンテージ」フィールドに指定された値にかかわらず200レコードしかサンプリングされません。 |
プロセス実行プリファレンスの一部として、またはジョブの一部として、プロセスを実行するときに次のオプションを使用できます。
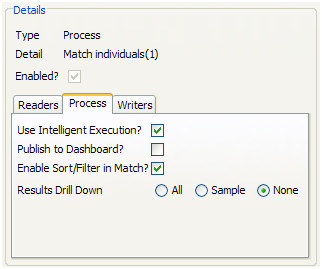
インテリジェント実行を使用?
「インテリジェント実行の使用」は、プロセスの現在の構成に基づく最新結果を得ているプロセッサは、その結果を再生成しないことを意味します。最新結果がないプロセッサは、再実行マーカーによってマークされます。詳細は、Enterprise Data Qualityオンライン・ヘルプのプロセッサの状態に関する項を参照してください。インテリジェント実行はデフォルトで選択されています。プロセス内のリーダーでレコードのサンプリングまたはフィルタを選択した場合は、インテリジェント実行の設定にかかわらずすべてのプロセッサが再実行します。プロセスが異なるセットのレコードに対して実行されるためです。
照合プロセッサでのソート/フィルタを有効化?
このオプションは、プロセスの任意の照合プロセッサに指定されたソート/フィルタ有効化設定(各照合プロセッサの「拡張オプション」)が、プロセス実行の一部として実行されることを意味します。このオプションはデフォルトで選択されます。大容量のデータが一致する場合は、ソート/フィルタ有効化タスクを実行して一致結果の確認を許可すると、長い時間がかかる可能性があるため、このオプションの選択を解除して後に延ばすことをお薦めします。たとえば、一致結果を外部にエクスポートする場合、「ソート/フィルタの有効化」プロセスが実行するのを待たずに、照合プロセスが完了したらすぐにデータのエクスポートを開始できます。照合プロセスの結果を確認する必要がない場合には、設定を完全にオーバーライドすることもできます。
結果のドリル・ダウン
このオプションでは、「結果のドリル・ダウン」の必要なレベルを選択できます。
「すべて」では、プロセスに読み込まれるすべてのレコードにドリルダウンできます。これは少量のデータ(数千件までのレコード)を処理している場合のみ、プロセスに読み込まれたすべてのレコードの処理を確認およびチェックできるようにする際にお薦めします。
「サンプル」はデフォルト・オプションです。これはプロセスの標準的な実行にお薦めします。このオプションを選択すると、プロセスによって生成されるすべてのドリルダウンでレコードのサンプルを使用できるようになります。このオプションでは、ドリルダウンしたときに必ずレコードが表示されて結果を調べることができますが、プロセスによって書き込まれるデータ容量が多くなりすぎることはありません。
「なし」では、プロセスによってメトリックが生成されますが、データにドリルダウンすることはできません。これは、すでに設計とテストが終了したデータ・クレンジング・プロセスを実行する場合など、ソースからターゲットにできるだけ早くプロセスを実行する場合にお薦めします。
ダッシュボードに公開?
このオプションでは、結果をダッシュボードに公開するかどうかを設定します。結果を公開するためには、プロセスの1つ以上の監査プロセッサでダッシュボードの公開をあらかじめ有効にしておく必要があることに注意してください。
必要な実行タイプをサポートするために、EDQでは3種類の実行モードが用意されています。
リアルタイム・プロバイダに接続しているリーダーがプロセスにない場合、プロセスは常に標準モードで実行します。
リアルタイム・プロバイダに接続しているリーダーが少なくとも1つプロセスに含まれる場合、プロセスの実行モードを次の3つのオプションから選択できます。
標準モード
標準モードでは、プロセスはレコードのバッチを完了するまで実行します。レコードのバッチはリーダーの構成によって定義されます。さらに、その他のサンプリング・オプションがプロセス実行プリファレンスまたはジョブ・オプションで設定されることもあります。
準備モード
準備モードが必要なのは、プロセスがリアルタイム・レスポンスを提供する必要がある場合です。ただし、これが可能になるのは、プロセスのリアルタイムでない部分がすでに実行された場合、つまりプロセスの準備が完了した場合のみです。
準備モードが最も使用されるのはリアルタイム参照照合です。この場合、同じプロセスが別のジョブおよび別のモードで実行するようにスケジュールされます。最初のジョブは、プロセスのリアルタイム以外の部分(たとえば、照合用の参照データに対するすべてのクラスタ・キーの作成など)をすべて実行して、リアルタイム・レスポンス実行のためにプロセスを準備します。2番目のジョブはリアルタイム・レスポンス・プロセスとして実行します(おそらく間隔モード)。
間隔モード
間隔モードでは、プロセスが長期間(絶え間なく)実行しますが、処理の結果は間隔ごとに書き込まれます。レコードまたは時間の制限に達すると、1つの間隔が完了して新しい間隔が始まります。レコードと時間両方のしきい値が指定されている場合は、いずれかのしきい値に達すると新しい間隔が始まります。
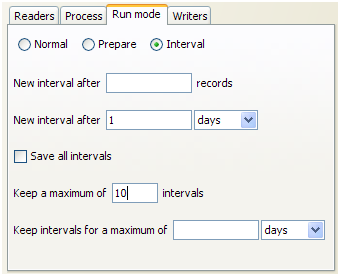
間隔モードのプロセスは長時間実行できるため、結果を保存しておく間隔の数を構成できることが重要です。これは、間隔の数または期間によって定義できます。
たとえば、連続して実行し、毎日新しい間隔が開始するようにリアルタイム・レスポンス・プロセスに次のオプションを設定できます。
間隔モードでの処理結果の参照
プロセスが間隔モードで実行しているとき、完了した間隔の結果を参照できます(間隔を保存するために指定されているオプションに対して古すぎない場合)。
結果ブラウザには単純なドロップダウン選択ボックスがあり、各間隔の開始日時と終了日時が表示されます。デフォルトでは最後に完了した間隔が表示されます。間隔を選択して結果を参照します。

プロセスを開いているときに新しい結果セットが表示可能になると、ステータス・バーに通知が示されます。
その後、ドロップダウン選択ボックスで新しい結果を選択できます。
プロセスのライターごとに次のオプションを設定できます。
データの書込み?
このオプションは、ライターが実行されるかどうかを設定します。つまり、書き込んでデータをステージングするライターの場合、このオプションを選択解除するとステージング済データが書き込まれません。リアルタイム・コンシューマに書き込むライターの場合、このオプションを選択解除するとリアルタイム・レスポンスが書き込まれません。
これは次の2つのケースで役立ちます。
書き込まれたデータをリポジトリにステージングせずに、データを直接エクスポート・ターゲットにストリームする場合、ライターは書き込む属性を選択するためにのみ使用されます。このケースでは、データの書込みオプションの選択を解除し、エクスポート・タスクをジョブ定義のこのプロセスの後に追加します。
ライターを一時的に無効にする場合。たとえば、テストのためにプロセスをリアルタイム実行からバッチ実行に切り替える場合に、リアルタイム・レスポンスを発行するライターを一時的に無効化することがあります。
ソート/フィルタを有効化?
このオプションでは、「ステージング済データ」ライターによって書き込まれたデータのソートとフィルタを有効化するかどうかを設定します。通常、ライターによって書き込まれたステージング済データに対してソートとフィルタを有効にする必要があるのは、ユーザーが結果のソートとフィルタを望む別のプロセスによってデータが読み取られる予定がある場合、またはライターの結果そのもののソートとフィルタを行う必要がある場合です。
このオプションはリアルタイム・コンシューマに接続しているライターには影響しません。
プロジェクトに構成されているすべての外部タスク(ファイルのダウンロードまたは外部実行ファイル)は、同じプロジェクト内のジョブに追加できます。
ジョブの一部として実行するように「外部タスク」を構成する際には、1つのオプション「有効」があります。
エクスポート・オプションの有効化または無効化では、ジョブ定義を維持したままで、データのエクスポートを一時的に有効化または無効化できます。
ジョブの一部として実行するように「エクスポート」を構成するとき、エクスポートを有効化または無効化できます(ジョブ定義を維持したままで、データのエクスポートを一時的に有効化または無効化できます)。また、次のオプションを使用して、ターゲット・データ・ストアにデータを書き込む方法を指定できます。
現在のデータおよび挿入の削除(デフォルト)
EDQでは、ターゲットの表またはファイルの現在のデータすべてを削除し、適用範囲内データをエクスポートに挿入します。たとえば、外部データベースに書き込んでいる場合は、表を切り捨ててデータを挿入します。または、ファイルに書き込んでいる場合は、ファイルを再作成します。
現在のデータに追加
EDQでは、ターゲットの表またはファイルのデータを削除せずに、適用範囲内データをエクスポートに追加します。UTF-16ファイルに追加する場合は、バイト順序マーカーが新しいデータの先頭に書き込まれないように、UTF-16LEまたはUTF-16-BE文字セットを使用してください。
主キーを使用してレコードを置換します
EDQでは、エクスポートの適用範囲データにも存在するレコード(主キーの照合によって判別)をすべてターゲット表から削除し、適用範囲内データを挿入します。
|
注意:
|
ジョブの一部として実行するように「結果ブックのエクスポート」を構成する際には、エクスポートを有効化または無効化する1つのオプションがあります。必要な場合には同じ構成を維持したままで一時的にエクスポートを無効にできます。
トリガーは、処理の特定の時点でEDQが実行できるアクションが具体的に構成されたものです。
ジョブでフェーズの前に実行
ジョブでフェーズの後に実行
詳細は、『Oracle Fusion Middleware Oracle Enterprise Data Qualityの管理』のトリガーの使用に関する項、およびEnterprise Data Qualityオンライン・ヘルプの照合プロセッサの拡張オプションに関する項を参照してください。
この項の内容は次のとおりです。
|
注意:
|
プロジェクト・ブラウザで必要なプロジェクトを展開します。
プロジェクトの「ジョブ」ノードを右クリックして、「新規ジョブ」を選択します。「新規ジョブ」ダイアログが表示されます。
名前と説明(必須の場合)を入力して、「終了」をクリックします。ジョブが作成され、ジョブ・キャンバスに表示されます。
フェーズ・リストで「新規フェーズ」を右クリックし、「構成」を選択します。
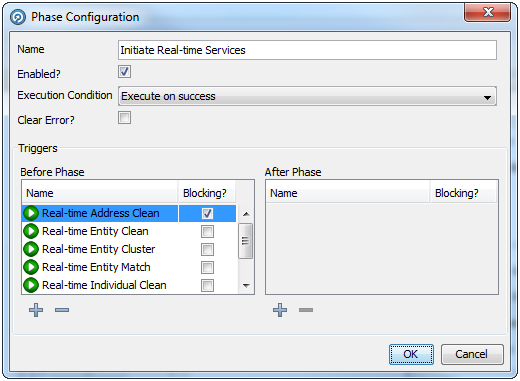
フェーズの名前を入力し、次に示す他のオプションを必要に応じて選択します。
| フィールド | タイプ | 説明 |
|---|---|---|
| 有効 | チェック・ボックス | フェーズを有効化または無効化します。デフォルトの状態では選択されています(有効化)。
注意: 実行プロファイルによって、またはEDQコマンドライン・インタフェースでrunopsjobコマンドを使用して、フェーズのステータスをオーバーライドできます。 |
| 実行条件 | ドロップダウン・リスト | 前のフェーズの成功または失敗に応じてフェーズを実行するように条件設定します。
オプションは次のとおりです。
注意: いずれかのフェーズでエラーが発生すると、「エラーのクリア」ボタンが選択された「関係なく実行」または「失敗で実行」フェーズが初めて実行される場合を除いて、すべての「成功で実行」フェーズが停止します。 |
| エラーのクリア | チェック・ボックス | ジョブのエラー状態をクリアするかそのまま残します。
ジョブ・フェーズでエラーが発生すると、エラー・フラグが適用されます。このオプションを使用してエラー・フラグがクリアされなければ、「成功で実行」に設定された後続のフェーズは実行されません。デフォルトの状態では選択されていません。 |
| トリガー | N/A | フェーズの実行前または実行後にトリガーをアクティブ化するように構成します。詳細は、「ジョブ・トリガーの使用」を参照してください。 |
「OK」をクリックして設定を保存します。
ツール・パレットでタスクをクリックしてドラッグし、必要に応じてタスクの構成とリンクを行います。
さらにフェーズを追加するには、「フェーズ」領域下部のジョブ・フェーズの追加ボタンをクリックします。フェーズを選択し、「フェーズの移動」ボタンを使用してリスト内で上下に動かすと、フェーズの順序を変更できます。フェーズを削除するには「フェーズの削除」ボタンをクリックします。
必要に応じてジョブが構成されたら、「ファイル」 > 「保存」をクリックします。
ジョブを編集するには、プロジェクト・ブラウザでジョブを探し、ダブルクリックするか、右クリックして「編集...」を選択します。
ジョブがジョブ・キャンバスに表示されます。必要に応じてフェーズまたはタスク(あるいは両方)を編集します。
「ファイル」→「保存」をクリックします。
ジョブを削除しても、そのジョブに含まれていたプロセスは削除されません。そのジョブに関連する結果も削除されません。ただし、ジョブに含まれていたいずれかのプロセスが最後に実行されたのがそのジョブだった場合、そのプロセスの最新結果セットは削除されます。これによって、そのプロセス内のプロセッサが最新ではないとマークされます。
ジョブを削除するには次のいずれかを実行します。
プロジェクト・ブラウザでジョブを選択し、[Delete]キーを押します。
ジョブを右クリックし、「削除」を選択します。
現在実行中のジョブは削除できないことに注意してください。
ジョブを作成または編集するときには、右クリック・メニューからアクセスできるその他のオプションがあります。
キャンバスでタスクを選択して右クリックするとメニューが表示されます。次の2通りの場合があります。
有効 - 選択したタスクが有効化されると、このオプションの横にチェックマークが表示されます。必要に応じて選択または選択解除します。
タスクの構成...- このオプションでは「タスクの構成」ダイアログが表示されます。詳細は、「データ・インタフェースを使用するジョブの実行」を参照してください。
削除 - 選択したタスクを削除します。
開く - 選択したタスクをプロセス・キャンバスで開きます。
切取り、コピー、貼付け - これらのオプションを使用して、必要に応じてジョブ・キャンバスでタスクの切取り、コピー、貼付けを行います。
フェーズは右クリック・メニューを使用して制御されます。フェーズの名前変更、削除、無効化、構成、コピー、および貼付けにメニューを使用します。
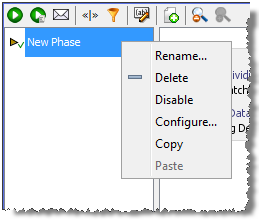
フェーズ・リストの一番下にある、「追加」、「削除」、「上方」および「下方」コントロールを使用します。

フェーズの編集と構成の詳細は、前述の「ジョブの作成」、および「ジョブ・トリガーの使用」も参照してください。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
ジョブ・トリガーは他のジョブを開始または中断するために使用されます。デフォルトでは次の2種類のトリガーが用意されています。
「ジョブの実行」トリガー: ジョブを開始するために使用されます。
「Webサービスの停止」トリガー: リアルタイム・プロセスを停止するために使用されます。
管理者はJMSメッセージの送信やWebサービスの呼出しなど他のトリガーを構成できます。これらは「フェーズ構成」ダイアログを使用して構成され、その例を次にあげます。
トリガーはフェーズの前または後に設定できます。前のトリガーはフェーズ名の上の青色矢印で示され、後のトリガーはフェーズ名の下の赤色矢印で示されます。たとえば、次の画像ではトリガーの前後のフェーズを示します。

トリガーをブロック・トリガーとして指定することもできます。ブロック・トリガーは、トリガーされたタスクが完了するまで、後続のトリガーまたはフェーズの開始を防ぎます。
対象のフェーズを右クリックし、「構成」を選択します。「フェーズ構成」ダイアログが表示されます。
「トリガー」領域で、必要に応じて「フェーズ前」または「フェーズ後」リストの下の「トリガーの追加」ボタンをクリックします。「トリガーの選択」ダイアログが表示されます。
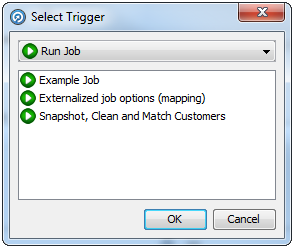
ドロップダウン・フィールドでトリガーの種類を選択します。
リスト領域で特定のトリガーを選択します。
「OK」をクリックします。
必要な場合は、トリガーの横の「ブロック中」チェックボックスを選択します。
必要に応じて他のトリガーを設定します。
すべてのトリガーが設定されたら、「OK」をクリックします。
対象のフェーズを右クリックし、「構成」を選択します。
「フェーズ構成」ダイアログで、削除対象のトリガーを見つけてクリックします。
選択したトリガーのリストの下にある「トリガーの削除」ボタンをクリックします。トリガーが削除されます。
「OK」をクリックして変更を保存します。ただし、トリガーの削除でエラーが発生した場合は「取消」をクリックします。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
ジョブが実行を完了するたびに、1ユーザー、特定の複数ユーザーまたはユーザー・グループ全体に電子メールの通知を送信するようにジョブを構成できます。これにより、EDQユーザーはEDQにログオンしなくてもスケジュール済ジョブのステータスをモニターできます。
また、電子メールが送信されるのは、有効なSMTPサーバーの詳細がoedq_local_homeディレクトリのnotification/smtpサブフォルダにあるmail.propertiesファイルに指定されている場合のみです。同じSMTPサーバー詳細が問題の通知にも使用されます。詳細は、Enterprise Data Qualityサーバーの管理を参照してください。
デフォルト通知テンプレート(default.txt)はEDQのconfig/notification/jobsディレクトリにあります。追加のテンプレートを構成するには、このファイルをコピーして同じディレクトリに貼り付け、名前を変更して、内容を必要に応じて変更します。新しいファイルの名前は「電子メール通知構成」ダイアログの「通知テンプレート」フィールドに表示されます。
ジョブを開き、ジョブ・キャンバスのツールバーの「通知の構成」ボタンをクリックします。「電子メール通知構成」ダイアログが表示されます。
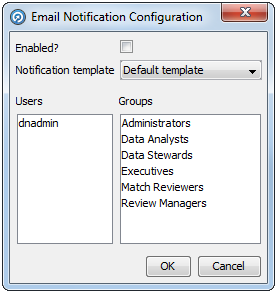
「有効」ボックスを選択します。
ドロップダウン・リストから通知テンプレートを選択します。
通知を送信するユーザーとグループをクリックして選択します。ユーザーまたはグループ(あるいは両方)を複数選択する場合は、[Ctrl]キーを押したままでクリックします。
「OK」をクリックします。
|
注意: 有効な電子メール・アドレスを持つユーザーのみが電子メールを受信します。EDQの内部で管理されるユーザーについては、有効な電子メール・アドレスをユーザー管理で構成する必要があります。EDQの外部、たとえばWebLogicや外部LDAPシステムで管理されるユーザーについては、有効なmail属性を構成する必要があります。 |
デフォルトの通知には、次のようにジョブの各フェーズで実行されたすべてのタスクのサマリー情報が含まれます。
スナップショット・タスク
通知には、ジョブの実行でのスナップショット・タスクのステータスが表示されます。ステータスには、次のものがあります。
STREAMED - プロセスが実行されるときに、データをプロセスに直接送ってステージングすることにより、スナップショットのパフォーマンスが最適化されました
FINISHED - スナップショットが独立タスクとして完了するまで実行しました
CANCELLED - スナップショット・タスク中にユーザーによってジョブが取り消されました
WARNING - スナップショット完了まで実行しましたが、1つ以上の警告が生成されました(たとえば、スナップショットがデータ・ソースのデータを切り捨てる必要がありました)
ERROR - エラーのためにスナップショットが完了できませんでした
スナップショット・タスクがFINISHEDステータスの場合、スナップショットされたレコード数が表示されます。
処理中に検出された警告とエラーの詳細が含まれます。
プロセス・タスク
通知には、ジョブの実行でのプロセス・タスクのステータスが表示されます。ステータスには、次のものがあります。
FINISHED - プロセスが完了するまで実行しました
CANCELLED - プロセス・タスク中にユーザーによってジョブが取り消されました
WARNING - プロセス完了まで実行しましたが、1つ以上の警告が生成されました
ERROR - エラーのためにプロセスが完了できませんでした
プロセスが正しい数のレコードに対して実行されたことを確認するために、プロセス・タスクのリーダーとライターごとにレコード数が含まれます。処理中に検出された警告とエラーの詳細が含まれます。これには警告の生成プロセッサによって生成された警告またはエラーが含まれる場合があることに注意してください。
エクスポート・タスク
通知には、ジョブの実行でのエクスポート・タスクのステータスが表示されます。ステータスには、次のものがあります。
STREAMED - プロセスからのデータを直接実行してデータ・ターゲットに書き込むことにより、エクスポートのパフォーマンスが最適化されました
FINISHED - エクスポートが独立タスクとして完了するまで実行しました
CANCELLED - エクスポート・タスク中にユーザーによってジョブが取り消されました
ERROR - エラーのためにエクスポートが完了できませんでした
エクスポート・タスクがFINISHEDステータスの場合、エクスポートされたレコード数が表示されます。
処理中に検出されたエラーの詳細が含まれます。
結果ブックのエクスポート・タスク
通知には、ジョブの実行での結果ブックのエクスポート・タスクのステータスが表示されます。ステータスには、次のものがあります。
FINISHED - 結果ブックのエクスポートが完了するまで実行されました
CANCELLED - 結果ブックのエクスポート・タスク中にユーザーによってジョブが取り消されました
ERROR - エラーのために結果ブックのエクスポートが完了できませんでした
処理中に検出されたエラーの詳細が含まれます。
外部タスク
通知には、ジョブの実行での外部タスクのステータスが表示されます。ステータスには、次のものがあります。
FINISHED - 外部タスクが完了するまで実行しました
CANCELLED - 外部タスク中にユーザーによってジョブが取り消されました
ERROR - エラーのために外部タスクが完了できませんでした
処理中に検出されたエラーの詳細が含まれます。
電子メール通知
次のスクリーンショットでは、デフォルトの電子メール・テンプレートを使用する通知電子メールの例を示します。
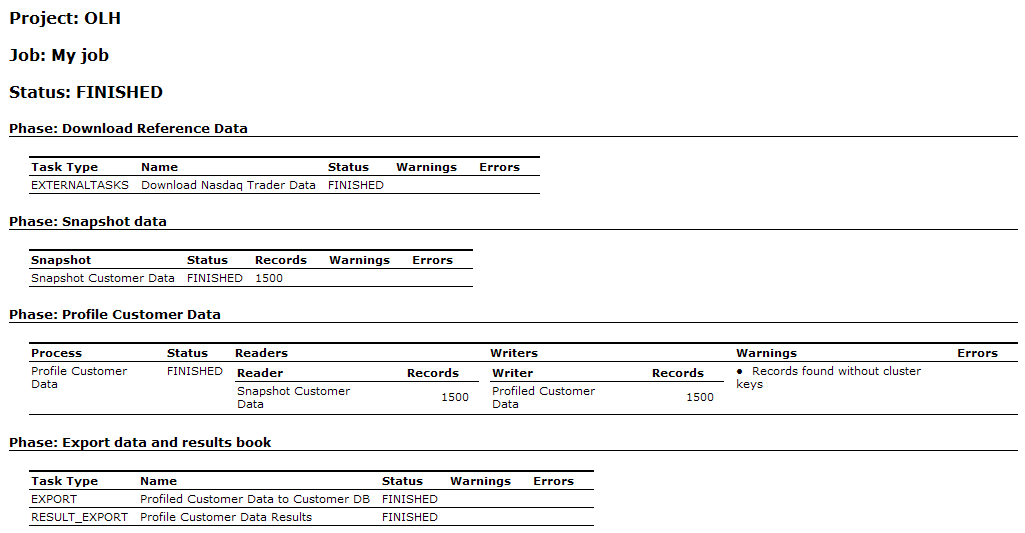
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
この項では、ジョブのパフォーマンスを最適化するために使用できるEDQの各種のパフォーマンス・チューニング・オプションについて説明します。
すべてのタイプのプロセスに適用でき、EDQにおけるパフォーマンスを最大化するために使用できる一般的なテクニックが4つあります。
各テクニックの詳細は、次の見出しをクリックしてください。
EDQでデータをストリームするためのオプションを使用して、データを読み取るときや書き込むときにEDQリポジトリ・データベースでデータをステージングするタスクを回避できます。
完全にストリームされたプロセスまたはジョブはパイプとして動作し、いずれのレコードもEDQリポジトリに書き込まず、レコードをデータ・ストアから直接読み取り、レコードをデータ・ターゲットに書き込みます。
スナップショットのストリーミング
プロセスを実行するとき、スナップショットの実行を完全に回避して、データをスナップショット経由でデータ・ストアからプロセスに直接ストリームするのが適切な場合があります。たとえば、プロセスを設計するときには、データのスナップショットを使用できますが、プロセスを本番でデプロイするときには、常にソース・システムからの最新セットのレコードを使用し、ユーザーに結果のドリルダウンを求めないことが判明しているため、データをリポジトリにコピーするステップを回避するとします。
データをプロセスにストリーム(したがってEDQリポジトリでデータをステージングするプロセスを回避)するには、ジョブを作成し、スナップショットとプロセスを両方ともタスクとして追加します。次にスナップショット・タスクとプロセスの間にあるステージング済データ表をクリックして無効化します。プロセスはデータをソース・システムから直接ストリームします。スナップショットの一部として構成された選択パラメータもすべて適用されます。
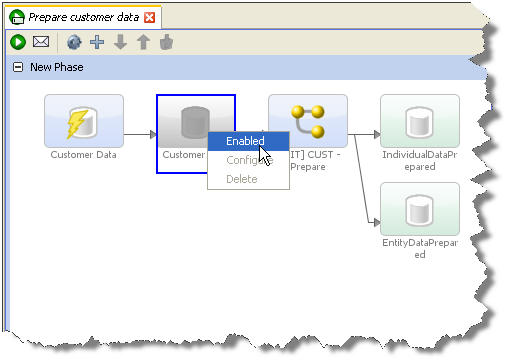
データをストリームするときには、レコード選択基準(スナップショット・フィルタリングまたはサンプリング・オプション)はすべて適用されます。また、スナップショットのデータ・ストアがクライアント側にある場合、サーバーからアクセスできないので、ストリーミング・オプションは使用不可能になります。
ただし、スナップショットのストリーミングが常に「最速」または最善のオプションとはかぎりません。同じデータのセットに対して複数のプロセスを実行する必要がある場合、ジョブの最初のタスクとしてデータをスナップショットし、次に依存するプロセスを実行するほうが効率的な場合があります。スナップショットのソース・システムがライブの場合、スナップショットを個別のタスクとして(独自のフェーズで)実行し、ソース・システムへの影響を最小化するのが通常は最適です。
エクスポートのストリーミング
データをデータ・ストアに書き込むときにもデータをストリームできます。ステージング済データのセットのエクスポートが、同じジョブでステージング済データ表を書き込むプロセスの後で実行されるように構成されている場合、エクスポートでは常にレコードが処理されながら書き込まれるため(レコードがリポジトリのステージング済データ表にも書き込まれるかどうかにかかわらず)、ここでのパフォーマンス向上率は減少します。
しかし、データをリポジトリに書き込む必要がないことが判明している場合(データを外部に書き込むことのみ必要)、このステップを回避して、パフォーマンスをわずかに改善できます。これが該当するケースとしては、データ・クレンジング・プロセスがデプロイされる場合や、アプリケーション間で共有される外部ステージング・データベースに書き込んでいる場合、たとえば外部ステージング・データベースを使用してデータをEDQとETLツールの間で受け渡し、大きなETLプロセスの一部としてデータ品質ジョブを実行する場合があります。
エクスポートをストリームするには、ジョブを作成し、データを書き込むプロセスをタスクとして追加し、データを外部に書き込むエクスポートを別タスクとして追加します。次にプロセスとエクスポート・タスクの間にあるステージング済のデータを無効化します。これにより、プロセスが出力データを外部ターゲットに直接書き込みます。
|
注意: データ・インタフェースに書き込むライターをプロセスで構成し、データ・インタフェースからエクスポート・ターゲットにマップするエクスポート・タスクを構成して、エクスポート・ターゲットへのデータのストリーミングも可能です。 |
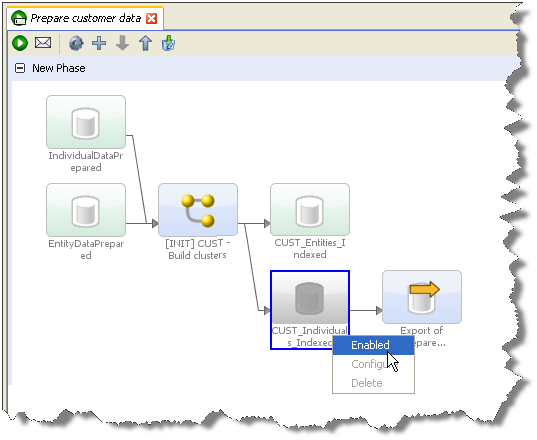
クライアント側のデータ・ストアへのエクスポートをタスクとして使用し、ジョブの一部として実行することはできません。データ・ストアに接続するためにクライアントを使用するので、EDQディレクタ・クライアントから手動で実行する必要があります。
最小化された結果書込みとは、EDQによってプロセスからリポジトリに書き込まれる結果ドリルダウンデータの量にかかわる異なる種類の「ストリーミング」です。
EDQの各プロセスは、3つの結果ドリルダウン・モードのうちいずれかで実行されます。
すべて(プロセスの全レコードがドリルダウンで書き込まれます)
サンプル(レコードのサンプルがドリルダウンの各レベルで書き込まれます)
なし(メトリックのみ書き込まれます - ドリルダウンは使用不可能)
プロセス内でどの処理ポイントでもすべてのレコードを必ず完全にトラッキングできるのを確認するために、「すべて」モードを使用するのは、データが小量の場合のみにしてください。小さいデータ・セットを処理するときや、少数のレコードを使用して複雑なプロセスをデバッグするときに、このモードが有用です。
「サンプル」モードは大量のデータに適しており、必ずドリルダウンのたびに限定された数のレコードが書き込まれます。システム管理者はドリルダウンごとに書き込むレコード数を設定でき、デフォルトではこの値は1000件です。「サンプル」モードがデフォルトです。
本番で実行され、ユーザーが結果にかかわる必要がないテスト対象プロセスのパフォーマンスを最大化するには、「なし」モードを使用してください。
プロセスを実行するときに「結果のドリル・ダウン」モードを変更するには、プロセス実行のプリファレンス画面を使用するか、ジョブを作成して、プロセス・タスクをクリックして構成します。
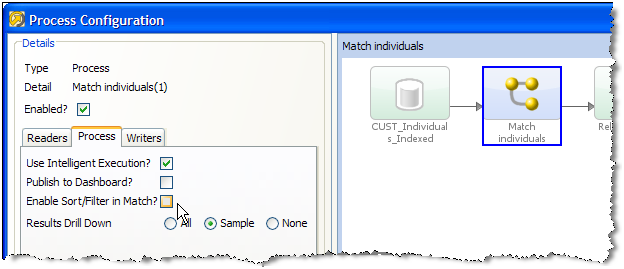
たとえば、次のプロセスは、本番でデプロイされるときにドリルダウン結果を書き込まないように変更されます。
大量のデータを使用する場合、ユーザーがデータを結果ブラウザでソートおよびフィルタリングできるようにするために、スナップショットと書き込まれたステージング済データを索引付けするには、長時間かかる場合があります。多くの場合、このソートおよびフィルタリング機能は必要にならないか、少数のデータ・サンプルを使用する場合のみ必要になります。
インテリジェント・ソートおよびフィルタリング有効化が適用されるので、小量のデータ・セットを使用するときはソートおよびフィルタリングが有効化されますが、大量のデータ・セットに対してはソートおよびフィルタリングが無効化されます。しかし、これらの設定をオーバーライドして、たとえば、小さなデータ・セットを複数使用する際に最大のスループットを実現できます。
スナップショットのソートおよびフィルタ・オプション
スナップショット作成のデフォルト設定は、「インテリジェント・ソート/フィルタリング・オプションの使用」であり、ソートおよびフィルタリングを有効化するかどうかは、スナップショットのサイズに基づいて決定されます。詳細は、「スナップショットの追加」を参照してください。
しかし、ユーザーが結果ブラウザでスナップショットに基づいた結果をソートまたはフィルタリングする必要がないことが判明している場合や、ユーザーが必要に応じてソートまたはフィルタリングを有効化するようにしたい場合は、スナップショットを追加または編集するときに、ソートおよびフィルタリングを無効化できます。
これを行うには、スナップショットを編集し、3番目の画面(「列選択」)で「インテリジェント・ソート/フィルタの使用」オプションの選択を解除し、「ソート/フィルタ」列ですべての列の選択を解除したままにします。
また、使用可能な列の下位選択に対してのみ、ソートおよびフィルタリングが必要になると判明している場合は、チェック・ボックスを使用して、該当する列を選択します。
ソートおよびフィルタリングを無効化すると、ソートおよびフィルタリング有効化のための追加タスクがスキップされるので、スナップショットの合計処理時間が短縮されます。
有効化されていない列に基づいてユーザーが結果をソートまたはフィルタリングしようとすると、その時点で有効化するためのオプションがユーザーに提示されます。
ステージング済データのソートおよびフィルタ・オプション
ステージング済データがプロセスによって書き込まれるとき、デフォルトではデータのソートまたはフィルタリングは有効化されません。したがって、デフォルト設定はパフォーマンスについて最大化されています。
たとえば、対話的なデータ・ドリルダウンを必要とする別プロセスが、書き込まれたステージング済データを読取り中であることが原因で、書き込まれたステージング済データに対してソートまたはフィルタリングを有効化する必要がある場合、ステージング済データ定義を編集してこれを有効化し、インテリジェント・ソート/フィルタリング・オプションを適用するか(ステージング済データ表のサイズに基づきソートおよびフィルタリングを有効化するかどうかで決定)、または選択した列に対して有効化するために対応する「ソート/フィルタ」チェック・ボックスを選択できます。
照合プロセッサの「ソート/フィルタ」オプション
照合の出力に対してソート/フィルタ有効化オプションを設定できます。「照合パフォーマンス・オプション」を参照してください。
解析と照合の場合、各プロセッサに処理段階が多数あるので、個別のプロセッサによって大量の作業が実行されます。このような場合、パフォーマンスをプロセッサのレベルで最適化するためのオプションが使用可能です。
データを解析または照合するときにパフォーマンスを最大化する方法の詳細は、次の見出しをクリックしてください。
解析プロセッサ側で最大のパフォーマンスが要求される場合、解析プロセッサを「解析とプロファイル」モードでなく「解析」モードで実行してください。解析結果の分類済および未分類トークンを調査する必要がない、構成が完了している解析プロセッサについては、このことが特に当てはまります。パーサーのモードはパーサーの拡張オプションで設定されます。
解析プロセッサからメトリックとデータ出力のみ要求される、さらに優れたパフォーマンスを得るには、ドリルダウンを使用せずにパーサーを含むプロセスを実行できます。前述の「最小化された結果書込み」を参照してください。
解析構成を対話的に設計し、高速なドリルダウンが必要な場合、小量のデータを使用するのが一般に最善です。データが大量の場合は、Oracle結果リポジトリを使用するとドリルダウンのパフォーマンスが著しく向上します。
以下のテクニックを使用して、照合パフォーマンスを最大化できます。
最適化されたクラスタ化
照合のパフォーマンスは、照合プロセッサの構成に依存して大幅に変化し、照合プロセッサの構成は、照合プロセスにかかわるデータの特性に依存します。正しく動作する構成の最も重要な側面は、照合プロセッサにおけるクラスタ化の構成です。
一般に、可能なかぎり多数の可能性がある一致が見つかるようにすることと、(一致しないであろうレコード間の)冗長な比較が実行されないようにすることの間で取るべきバランスがあります。適切なバランスを見つけるにはなんらかの試行錯誤、たとえば、(クラスタ・キー内の識別子の使用文字数削減などによる)クラスタの拡張、(クラスタ・キー内の識別子の使用文字数増加などによる)クラスタの収縮、またはクラスタを追加または削除する場合の一致統計の差異の評価が必要になる場合があります。
次の2つのガイドラインが有用な場合があります。
住所や他の連絡先詳細、たとえば電子メール・アドレスと電話番号を持つ顧客データなど、適切に移入された多数の識別子を含むデータを使用する場合、100万件のレコードごとに最大サイズ20のクラスタを目標にし、いくつかの識別子では希薄性に対処するために、単一クラスタを拡張するよりも複数のクラスタを使用してください。
少数の識別子を持つデータを使用する場合、たとえば、個人またはエンティティを名前とおよその場所に基づいてのみ照合できる場合、クラスタの拡張が不可避な場合があります。この場合、使用可能なデータによるクラスタの緊密化を可能にするために、使用する識別子の入力データを標準化、拡張、および修正することを心がけてください。大量のデータの場合、少数のクラスタが著しく大きくなることがあります。たとえば、Oracle Watchlist Screeningでは、許可リストと照合してスクリーニングするときに使用するクラスタ化方法の一部について、700万のクラスタ比較限度が使用されます。この場合も、可能なら最大サイズが約500レコードのクラスタを目標にしてください(クラスタ内のどのレコードも、クラスタ内の他のどのレコードとも比較することが必要になるので、500レコードの単一クラスタの場合、500 x 499 = 249500回の比較が実行されます)。
作業をクラスタ化する方法とデータの設定を最適化する方法の詳細は、「クラスタ化概念ガイド」を参照してください。
照合プロセッサのソート/フィルタ・オプションの無効化
デフォルトでは、すべての照合結果をユーザー・レビューで必ず使用可能にするため、ソート、フィルタリングおよび検索は有効化されます。しかし、大きなデータ・セットでは、ソート、フィルタリングおよび検索を有効化するために必要な索引付けのプロセスは非常に時間がかかり、場合によっては不要なこともあります。
レビュー・アプリケーションを使用して照合の結果をレビューする機能が必要でなく、結果ブラウザで照合の出力をソートまたはフィルタできなくてもよい場合、パフォーマンス向上のためにソートとフィルタリングを無効化してください。たとえば、照合の結果を外部で書き込んでレビューする場合や、照合を本番でデプロイする場合に完全に自動化する場合があります。
ソートとフィルタリングを有効化または無効化するための設定は、プロセッサの「拡張オプション」から使用可能な個別の照合プロセッサ・レベルでも(詳細は、Enterprise Data Qualityオンライン・ヘルプのマッチ・プロセッサの詳細オプションに関する項にある照合プロセッサのソート/フィルタ・オプションを参照)、プロセスまたはジョブ・レベルのオーバーライドとしても可能です。
プロセス内のすべての照合プロセッサに対する個別の設定をオーバーライドし、照合結果のソート、フィルタリングおよびレビューを無効化するには、ジョブ構成、またはプロセス実行プリファレンスで、照合プロセッサの「ソート/フィルタの有効化」オプションの選択を解除します。
出力の最小化
照合プロセッサは最大3種類の出力を書き出せます。
照合(またはアラート)グループ(照合プロセッサの決定どおりにレコードを照合レコードのセットにまとめます。照合プロセッサで一致レビューが使用される場合は一致グループが発生しますが、ケース管理が使用される場合はアラート・グループが発生します。)
関係(一致するレコード間のリンク)
マージ済出力(一致するレコードの各セットからマージされたマスター・レコード)
デフォルトでは、使用可能なすべての出力タイプが書き込まれます。(マージ済出力をリンク・プロセッサから書き込むことはできません。)
しかし、使用可能な出力がすべてプロセスに必要とはかぎりません。たとえば、一致するレコードのセットを識別するのみの場合は、マージ済出力の無効化が妥当です。
いずれかの出力を無効化しても、ユーザーによる照合プロセッサの結果のレビューに影響はありません。
一致(またはアラート・)グループ出力を無効化するには、次のようにします。
照合プロセッサをキャンバスで開き、「一致」サブプロセッサを開きます。
上部の「一致グループ(またはアラート・グループ)」タブを選択します。
「一致グループ・レポートの生成」または「アラート・グループ・レポートの生成」オプションの選択を解除します。
または、関連があるか関連がないレコードのグループを出力するのみだと判明している場合は、画面の同じ部分にある他のチェック・ボックスを使用します。
関係出力を無効化するには、次のようにします。
照合プロセッサをキャンバスで開き、「一致」サブプロセッサを開きます。
上部の「関係」タブを選択します。
「関係レポートの生成」オプションの選択を解除します。
または、いくつかの関係(レビュー関係のみ、または特定のルールにより生成された関係のみなど)のみ出力すると判明している場合は、画面の同じ部分にある他のチェック・ボックスを使用します。
マージ済出力を無効化するには、次のようにします。
照合プロセッサをキャンバスで開き、「マージ」サブプロセッサを開きます。
「マージ済出力の生成」オプションの選択を解除します。
または、関連があるレコードからのマージ済出力レコードのみか、関連がないレコードのみを出力すると判明している場合は、画面の同じ部分にある他のチェック・ボックスを使用します。
入力のストリーミング
バッチ照合プロセスでは、レコードを効率的に比較するために、EDQリポジトリにあるデータのコピーが必要です。
プロセス内のリーダーと照合プロセッサの間でデータが変換されることがあり、照合プロセスで使用するスナップショットがリフレッシュされても照合結果をレビューできるようにするため、照合プロセッサは作業の基礎となるデータ(リアルタイム入力以外)のスナップショットを独自に生成します。大きなデータ・セットの場合、これには時間がかかることがあります。
したがって、照合プロセスで最新のソース・データを使用する場合、スナップショットをストリームすることをお薦めします。その方が、最初にスナップショットを実行してからデータを照合プロセッサにフィードし、その照合プロセッサが独自の内部スナップショットを生成する(事実上データを2回コピー)よりも効率的です。前述の「スナップショットのストリーミング」を参照してください。
リアルタイム照合プロセスの参照データのキャッシュ
参照データをEDQサーバー上にキャッシュするように照合プロセッサを構成でき、場合によっては照合プロセスが高速になります。照合プロセッサの「拡張オプション」で、リアルタイム照合プロセッサにおける参照データのキャッシュを有効化できます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
EDQでは監査プロセッサと解析プロセッサの結果をWebベースのアプリケーション(ダッシュボード)に公開でき、データ品質は定期的にチェックされるので、データの所有者、またはデータ品質プロジェクトの関係者がデータ品質をモニターできます。
結果はプロセス実行時にオプションで公開されます。このオプションを使用するときに監査プロセッサが結果を公開するように設定するには、それに対応したプロセッサの構成が必要です。
これを行うには、次の手順を実行します。
キャンバスでプロセッサをダブルクリックして、プロセッサの構成ダイアログを表示します
「ダッシュボード」タブを選択します(注意: 解析では、入力サブプロセッサの内部にあります)。
プロセッサの結果を公開するオプションを選択します。
メトリックの名前を選択すると、ダッシュボードに表示されます。
プロセッサの結果をダッシュボード向けに解釈する方法、つまり各結果を成功、警告、失敗のいずれとして解釈するかを選択します。
ダッシュボードに結果を公開するように構成されたプロセッサがプロセスに1つ以上含まれると、公開プロセスをプロセス実行の一部として実行できます。
プロセスの結果をダッシュボードに公開するには、次のようにします。
ツールバーからプロセス実行のプリファレンスボタンをクリックします。
「プロセス」タブで、「ダッシュボードに公開」オプションを選択します。
保存して実行ボタンをクリックして、プロセスを実行します。
プロセスの実行が完了すると、構成された結果がダッシュボードに公開され、ユーザーが参照できます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
ディレクタ内に設定されたほとんどのオブジェクトは構成ファイルにパッケージ化でき、ディレクタ・クライアント・アプリケーションを使用して構成ファイルを別のEDQサーバーにインポートできます。
このため、異なるネットワーク上のユーザー間で作業を共有でき、構成をファイル領域にバックアップする方法を提供します。
次のオブジェクトをパッケージ化できます。
プロジェクト全体
個別プロセス
参照データ・セット(すべての種類)
ノート
データ・ストア
ステージング済データ構成
データ・インタフェース
エクスポート構成
ジョブ構成
結果ブック構成
外部タスク定義
Webサービス
公開されたプロセッサ
|
注意: 特定のサーバー・ユーザーに関連付けられているので、問題はエクスポートおよびインポートできず、サーバー間でのドラッグ・アンド・ドロップによる単なるコピーもできません。 |
オブジェクトをパッケージ化するには、プロジェクト・ブラウザで選択し、右クリックし、「パッケージ..」を選択します。
たとえば、サーバー上のすべての構成をパッケージ化するには、ツリーにある「サーバー」を選択し、サーバー上のすべてのプロジェクトをパッケージ化するには、「プロジェクト」親ノードを選択し、同じ方法で「パッケージ」を選択します。
その後、ディレクタ・パッケージ・ファイル(拡張子 .dxi)をファイル・システムに保存できます。パッケージ・ファイルとは、パッケージ化するために選択されたオブジェクトをすべて含む構造化ファイルです。たとえば、プロジェクトをパッケージ化すると、その補助オブジェクトすべて(データ・ストア、スナップショット構成、データ・インタフェース、プロセス、参照データ、ノートおよびエクスポート構成)がファイルに含まれます。
|
注意: 一致決定は、関連がある照合プロセッサを含むプロセスとともにパッケージ化されます。同様に、プロセス全体をプロジェクトまたはサーバー間でコピー・アンド・ペーストすると、関連がある一致決定がコピーされます。ただし、個別の照合プロセッサをプロセス間でコピー・アンド・ペーストした場合は、元のプロセスに対して作成されたいずれの一致決定も、照合プロセッサの構成の一部だとみなされないので、コピーされません。 |
複数のオブジェクトをパッケージできると有用な場合がよくあります。たとえば、大きなプロジェクト内の単一プロセス、およびプロセス実行に必要な参照データのすべてをパッケージ化します。
フィルタを適用する方法には次の3通りがあります。
オブジェクトを名前でフィルタリングするには、プロジェクト・ブラウザの下部にあるクイック・キーワードNameFilterオプションを使用します
プロジェクト・ブラウザをフィルタリングして単一のプロジェクトを表示するには(他のオブジェクトをすべて非表示)、プロジェクトを右クリックし、「選択したプロジェクトのみを表示」を選択します。
オブジェクト(プロセスやジョブなど)をフィルタリングし、その関連オブジェクトを表示するには、オブジェクトを右クリックし、「依存関係フィルタ」を選択し、「選択したアイテムによって使用されているアイテム」(選択したオブジェクトによって使用される他のオブジェクト、たとえば選択したプロセスによって使用される参照データを表示)、または「選択したアイテムを使用しているアイテム」(選択したオブジェクトを使用するオブジェクト、たとえば選択したプロセスを使用するいずれかのジョブ)のいずれかを選択します。
フィルタがプロジェクト・ブラウザに適用されているときはいつでも、フィルタがアクティブであることを示すボックスがタスク・ウィンドウのすぐ上に表示されます。たとえば、次のスクリーンショットには、「解析例」プロセスによって使用されるオブジェクトのみが表示されるようにサーバーがフィルタリングされていることを示すインジケータが示されます。

次にサーバーを右クリックし、「パッケージ..」を選択して、表示されるオブジェクトをパッケージ化できます。これにより、表示されたオブジェクトのみがパッケージ化されます。
フィルタをクリアするには、インジケータ・ボックスにある「x」をクリックします。
パッケージ化の前にフィルタリングされたビューからいくつかのオブジェクトを特に除外する場合があります。たとえば、いくつかのサンプル・データを含むスナップショットへのマッピングがあるデータ・インタフェースからデータを読み取るプロセスを作成したとします。プロセスを他のデータのセットに対して再利用するためにパッケージ化するとき、プロセスとそのデータ・インタフェースは公開しますが、スナップショットとデータ・ストアは除外しようとします。スナップショットとデータ・ストアをフィルタから除外するには、スナップショットを右クリックし、フィルタから除外を選択します。プロセスへのデータ・ストアの関係はスナップショットを経由するので、データ・ストアも除外されます。パッケージ化では常に表示されるオブジェクトのみがパッケージ化されるので、スナップショットとデータ・ストアはパッケージに含まれません。
ディレクタ・パッケージ・ファイルを開くには、他のオブジェクトが選択されていないプロジェクト・ブラウザにある空白の領域を右クリックして「パッケージ・ファイルを開く...」を選択するか、「ファイル」メニューから「パッケージ・ファイルを開く...」を選択します。次に開く.dxiファイルを検索します。
すると、パッケージ・ファイルはプロジェクトと同じように、ディレクタ・プロジェクト・ブラウザ内で開いて表示されます。パッケージ・ファイル内のオブジェクトはファイルから直接表示または変更できませんが、プロジェクト・ブラウザでドラッグ・アンド・ドロップ、またはコピー・アンド・ペーストによってEDQホストのサーバーにコピーできます。
個別のオブジェクトをパッケージからインポートするか、ファイル内のノードを選択してプロジェクト・リストの適切なレベルにドラッグして、複数のオブジェクトをインポートできます。これにより、パッケージ内部のプロジェクトの内容全体を既存のプロジェクトにマージしたり、(たとえば)すべての参照データ・セットまたはプロセスのみにマージしたりできます。
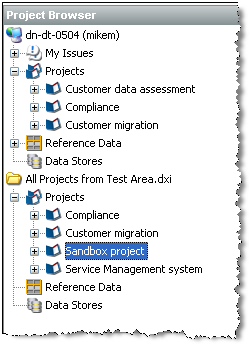
たとえば、次のスクリーンショットでは、すべてテスト・システムからエクスポートされた多数のプロジェクトがある開いたパッケージ・ファイルが示されます。プロジェクトをパッケージ・ファイルからサーバーにドラッグして、新しいサーバーにドラッグ・アンド・ドロップします。
複数のオブジェクトをパッケージ・ファイルからインポートして、ターゲットの場所に既存のオブジェクトとの名前の競合がある場合、競合解決画面が表示され、インポートするオブジェクトの名前を変更するか、オブジェクトを無視するか(したがって同じ名前の既存のオブジェクトを使用)、既存のオブジェクトをパッケージ・ファイルのオブジェクトで上書きできます。名前の競合がある各オブジェクトに対して異なるアクションを選択できます。
単一のオブジェクトをインポートしており、名前の競合がある場合、既存のオブジェクトを上書きできず、インポートを取り消すか、インポートしているオブジェクトの名前を変更する必要があります。
パッケージ・ファイルから必要なすべてのオブジェクトのコピーを完了したら、パッケージ・ファイルを右クリックして、「パッケージ・ファイルを閉じる」を選択して、パッケージ・ファイルを閉じることができます。
各クライアント・セッションが終了するとき、開いたパッケージ・ファイルは自動的に切断されます。
たとえば大量の参照データがパッケージに含まれる場合、パッケージ・ファイルのいくつかがとても大きくなることがあります。大きいパッケージ・ファイルを使用する場合、サーバーのファイル用ランディングエリアにファイルをコピーして、DXIファイルをサーバーから開くほうが高速です。パッケージ・ファイルからのオブジェクトのコピーはこれでかなり高速になります。
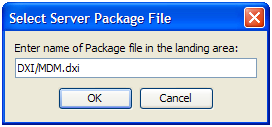
この方法でパッケージ・ファイルを開くには、まずDXIファイルをサーバーのランディングエリアにコピーします。次にディレクトリ・クライアントを使用して、プロジェクト・ブラウザでサーバーを右クリックし、「サーバー・パッケージ・ファイルを開く..」を選択します。
次にファイルの名前をダイアログに入力する必要があります。ファイルがランディングエリアのサブフォルダに格納されない場合、これを名前に含めることが必要になります。たとえば、ランディングエリアのDXIサブフォルダに保持されたMDM.dxiという名前のファイルを開く方法は、次のとおりです。
オブジェクトを同じネットワーク上のEDQサーバー間でコピーするには、オブジェクトをファイルにパッケージ化しなくてもこれを行うことができます。
オブジェクト(プロジェクトなど)を2つの接続したEDQサーバー間でコピーするには、各サーバーに接続し、一方のサーバーから他方のサーバーにオブジェクトをドラッグ・アンド・ドロップします。
|
注意: 別のサーバーに接続するには、「ファイル」メニューの「新規サーバー...」を選択します。クライアントを使用してEDQに接続するためのデフォルト・ポートは9002です。 |
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください。
EDQではリポジトリ・データベースを使用して、処理中に生成される結果とデータが格納されます。すべての結果データは、別個のデータベースに内部で保持される格納済の構成を使用して再生成できるという意味で、一時的です。
結果リポジトリ・データベースのサイズを管理するために、特定のセットのステージング済データ(スナップショットまたは書き込まれたステージング済データ)、特定のプロセス、特定のジョブの結果、または特定のプロジェクトのすべての結果をパージできます。
たとえば、古いプロジェクトの結果をサーバーからパージしても、プロジェクトの構成を格納しておけば、プロジェクトのプロセスを将来再び実行可能にできます。
なお、プロジェクト、プロセス、ジョブ、またはステージング済データ・セットを削除すると、そのプロジェクト、プロセス、ジョブ、またはステージング済データのセットに対する結果は自動的にパージされます。このため、必要な場合はプロジェクト構成をパッケージ化し、パッケージのインポートをテストしてから、サーバーから削除できます。すると、必要な場合は後の日付で構成をアーカイブから復元できます。
特定のスナップショット、書き込まれたステージング済データのセット、プロセス、ジョブ、またはプロジェクトの結果をパージする方法は次のとおりです。
プロジェクト・ブラウザでオブジェクトを右クリックします。パージ・オプションが表示されます。
適切なパージ・オプションを選択します。
パージする大量のデータがある場合、タスクの詳細が「タスク」ウィンドウに表示される場合があります。
|
注意:
|
一致決定データは残りの結果データとともにパージされません。一致決定は、照合の出力が処理された方法を記録する監査証跡の一部として保持されます。
たとえば開発プロセス中に一致決定のデータを削除する必要がある場合は、次の方法を使用してください。
関連する照合プロセッサを開きます。
「手動決定の削除」をクリックします。
すべての一致決定データを完全に削除するには「OK」をクリックし、メイン画面に戻るには「取消」をクリックします。
|
注意: 一致決定のパージがただちに行われます。ただし、照合プロセスが再実行されるまで、これは一致結果に表示されません。プロセスのこの最終段階で関係が更新され、関係に対して格納された決定がもう存在しないという事実が反映されます。 |
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
プロセッサ・ライブラリで使用可能な一連のデータ品質プロセッサに加え、EDQでは特定のデータ品質機能用に独自のプロセッサを作成および共有できます。
プロセッサを作成するには2つの方法があります。
外部開発環境を使用して、新規プロセッサを記述 - 詳細は、Enterprise Data Qualityオンライン・ヘルプのEDQの拡張に関する項を参照してください
EDQを使用してプロセッサを作成 - 詳細は、この項を参照してください
EDQでは、順番に使用される一連のベース(または「メンバー」)プロセッサの組合せを使用して、単一の機能用に単一のプロセッサを作成できます。
なお、次のプロセッサを新しく作成するプロセッサに含めることはできません。
解析
一致
グループとマージ
データ・セットのマージ
ただし、構成を再利用するために、前述のプロセッサの単一構成されたプロセッサ・インスタンスも公開できます。
プロセッサ作成の例
TitleおよびForename属性を基準とし、個人のGender値を導出する再利用可能な「性別の追加」プロセッサの作成を例としてあげます。これを行うには、複数のメンバー・プロセッサを使用する必要があります。しかし、他のユーザーがプロセッサを使用するときは、ユーザーが単一のプロセッサを構成し、TitleおよびForename属性を入力し(ただしこれらはデータ・セットで名前を指定)、2つの参照データ・セットを選択するのみにします。1つはTitle値をGender値にマップし、もう1つはForename値をGender値にマップします。最後に、プロセッサから3つの出力属性(TitleGender、NameGenderおよびBestGender)を取得します。
これを行うには、まず必要なメンバー・プロセッサを構成する必要があります(または、プロセッサを作成する基礎となる既存のプロセスがある場合もあります)。たとえば、次のスクリーンショットでは、Gender属性を追加するために5つのプロセッサを使用するのが次のように示されます。
GenderをTitleから導出します(マップから拡張)。
Forenameを分割します(文字列から配列を作成)。
最初のForenameを取得します(配列の要素を選択)。
GenderをForenameから導出します(マップから拡張)。
マージして最善のGenderを作成します(属性をマージ)。

これらを使用してプロセッサを作成するには、キャンバス上ですべて選択し、右クリックし、「プロセッサの作成」を選択します。
これにより、ただちに単一のプロセッサがキャンバス上で作成され、プロセッサ設計ビューが表示されるので、単一のプロセッサが動作する方法を設定できます。
プロセッサ設計ビューから、プロセッサの次の側面を設定できます(ただし、多くの場合、デフォルト設定を使用できます)。
プロセッサに必要な入力は、ベース・プロセッサの構成から自動的に計算されます。多くのベース・プロセッサで同じ構成済の入力属性が使用される場合、新規プロセッサ用の入力属性が1つのみ作成されます。
ただし、必要に応じて、プロセッサ設計ビューでプロセッサに必要な入力または名前を変更でき、または入力をオプションにできます。これを行うには、キャンバスの上部にある「プロセッサ設定」アイコンをクリックしてから、「入力」タブを選択します。

前述の場合は、ベース・プロセッサの構成で使用された個別属性の名前だったTitleとForenamesという2つの入力属性が作成されます。
ユーザーがこれらの属性の1つの外部ラベルをForenamesからForenameに変更して、ラベルをより一般的にし、Forenameの入力をオプションにすることを選択します。
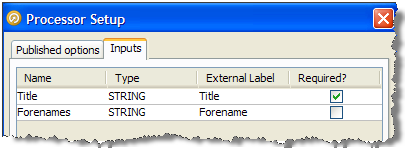
入力属性がオプションであり、プロセッサのユーザーが属性を入力属性にマップしない場合、属性値はプロセッサのロジックでnullとして扱われます。
|
注意: この画面で入力属性それぞれの名前を変更もでき、名前はプロセッサの設計内部でのみ変更されます(現在の使用でソース・データ・セットからの実際の入力属性が異なる場合でも、プロセッサが破損しません)。これが使用可能な場合、メンバー・プロセッサの構成が新規プロセッサの構成と一致しますが、作成されたプロセッサの動作には差異が発生しません。 |
プロセッサ設計ページでは、作成しているプロセッサに対して公開するメンバー・プロセッサのオプションを選択できます。この例では、ユーザーがTitleおよびForname値をGender値にマップするための固有な参照データ・セットを選択できるようにします(たとえば、プロセッサを新しい国のデータに対して使用する可能性があり、提供されたForenameからGenderへのマップが適切でなくなるため)。
オプションを公開するには、プロセッサ設計ページでメンバー・プロセッサを開き、「オプション」タブを選択し、ウィンドウ下部の「公開オプションを表示します」ボックスを選択します。
次に、どのオプションを公開するか選択できます。オプションを公開しないと、オプションはその構成値に設定され、新規プロセッサのユーザーはオプションを変更できなくなります(ユーザーがプロセッサ定義を編集する権限を持つ場合を除く)。
オプションを公開するには2つの方法があります。
新規として公開 - 作成しているプロセッサの新規オプションとしてオプションが公開されます。
既存の公開されたオプション(ある場合)を使用 - 単一の公開されたオプションを多くのメンバー・プロセッサ間で共有できます。たとえば、プロセッサのユーザーは大文字と小文字を無視するための単一オプションを指定でき、このオプションは複数のメンバー・プロセッサに適用されます。
|
注意: 参照データを使用するオプションを公開しないと、参照データは内部で新規プロセッサの構成の一部としてパッケージ化されます。これは、プロセッサのエンド・ユーザーが参照データ・セットを変更しないようにする場合に有用です。 |
この例では、最初のメンバー・プロセッサ(GenderをTitleから導出)を開き、Title値をGender値にマップするために使用する参照データ・セットを指定するオプションを(新規として)公開するように選択します。
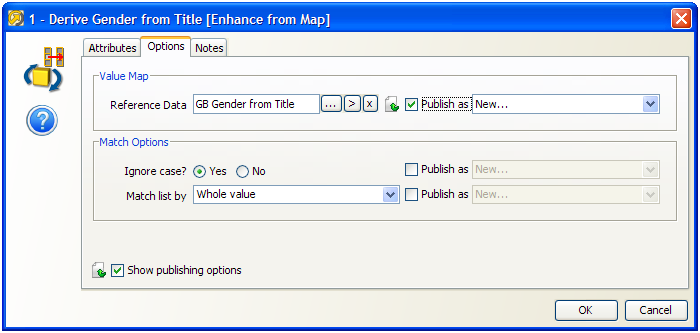
前述では、照合オプションは公開オプションとして公開されていないので、プロセッサのユーザーはこれらを変更できません。
次に、4番目のプロセッサ(GenderをForenameから導出)でForename値をGender値にマップするために使用する参照データ・セットを指定するオプションを公開するために同じプロセスを実行します。
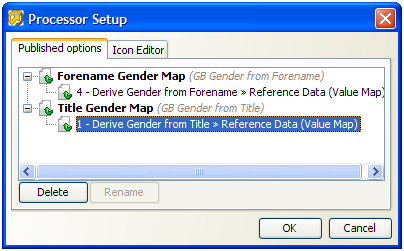
公開するオプションを選択したら、これらに新規プロセッサ上でどのようにラベルを付けるかを選択できます。
これを行うには、キャンバス上部の「プロセッサ設定」ボタンをクリックし、オプション名を変更します。たとえば、前述で公開した2つのオプションにTitle GenderマップおよびForename Genderマップというラベルを付けます。
新規プロセッサの出力属性は、いずれか1つ(しかし1つのみ)のメンバー・プロセッサの出力属性に設定されます。
デフォルトでは、作成されたプロセッサの出力属性には、一連のうち最後のメンバー・プロセッサが使用されます。異なるメンバー・プロセッサを出力属性に使用するには、そのメンバー・プロセッサをクリックし、ツールバーの「出力」アイコンを選択します。
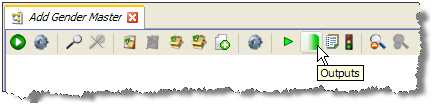
出力に使用されるメンバー・プロセッサには、出力側に緑色のシェーディングが付きます。
|
注意: 結果ビューに表示される属性は、常に新規プロセッサの出力属性として公開されます。場合によっては、メンバー・プロセッサをプロファイルに追加したり、公開する出力属性をチェックし、結果プロセッサとして設定して(次を参照)、新規プロセッサで必要な出力属性のみ表示される(たとえば変換プロセッサへの入力属性は表示されない)ことを確認することが必要です。また、結果ビューが必要でなければ設定解除できます。この場合、公開される出力属性は常に出力プロセッサの属性のみになります。 |
新規プロセッサの結果ビューは、いずれか1つ(しかし1つのみ)のメンバー・プロセッサの結果ビューに設定されます。
デフォルトでは、作成されたプロセッサの結果には、連番が最後のメンバー・プロセッサが使用されます。異なるメンバー・プロセッサを結果ビューに使用するには、そのメンバー・プロセッサをクリックし、ツールバーの「結果」アイコンを選択します。
結果に使用されるメンバー・プロセッサには、オーバーレイ・アイコンが付きます。

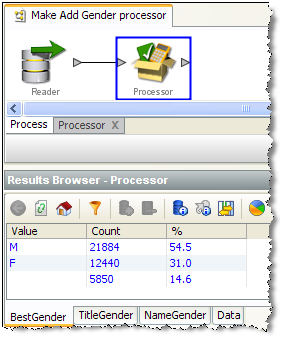
場合によっては、結果ビューを提供する目的で特にメンバー・プロセッサを追加します。この例では、新規プロセッサのユーザーが「性別の追加」プロセッサの動作の内訳を表示できるようにするために、3つの出力属性(TitleGender、ForenameGenderおよびBestGender)の頻度プロファイラを追加します。これを行うには、プロセッサ設計ビューで頻度プロファイラを追加し、3つの属性を入力として選択し、結果プロセッサとして選択し、実行します。
プロセッサ設計ビューを終了すると、頻度プロファイラの結果が新規プロセッサに結果として使用されているのがわかります。
新規プロセッサの出力フィルタは、いずれか1つ(そして1つのみ)のメンバー・プロセッサの出力フィルタに設定されます。
デフォルトでは、作成されたプロセッサの出力フィルタには、番号が最後のメンバー・プロセッサが使用されます。異なるメンバー・プロセッサを使用するには、そのメンバー・プロセッサをクリックし、ツールバーの「フィルタ」ボタンを選択します。

選択した出力フィルタはプロセッサ設計ビューで緑色になり、新規プロセッサ上で公開されることが示されます。

新規プロセッサのダッシュボード公開オプションは、いずれか1つ(そして1つのみ)のメンバー・プロセッサのダッシュボード公開オプションに設定されます。
新規プロセッサからの結果をダッシュボードに公開する必要がある場合、監査プロセッサをメンバー・プロセッサの1つにする必要があります。
メンバー・プロセッサをダッシュボード・プロセッサとして選択するには、そのメンバー・プロセッサをクリックし、ツールバーの「ダッシュボード」アイコンを選択します。

すると、プロセッサに信号アイコンが付き、ダッシュボード・プロセッサであることが示されます。

|
注意: 新規プロセッサを使用するときに一貫性がある結果を得るために、通常は、結果ビュー、出力フィルタおよびダッシュボード公開のオプションには同じメンバー・プロセッサを使用することをお薦めします。これは特に、データをチェックするために設計されたプロセッサを設計するときに当てはまります。 |
カスタム・アイコンを他者が使用できるように公開する前に、新規プロセッサに追加する場合があります。これを行うには、単にプロセッサ(プロセッサ設計ビューの外側)をダブルクリックし、アイコンとグループ・タブを選択します。
詳細は、「プロセッサ・アイコンのカスタマイズ」を参照してください。
新規プロセッサの設計とテストを終了したら、次のステップは他者が使用できるように公開することです。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください
構成された単一のプロセッサを他のユーザーがデータ品質プロジェクトに対して使用するために、ツール・パレットに公開できます。
次の種類のプロセッサはその構成を他のデータ・セットに対して容易に使用できるので、公開するのはとりわけ有用です。
照合プロセッサ(すべての構成が識別子に基づく)
解析プロセッサ(すべての構成がマップされた属性に基づく)
EDQで作成されたプロセッサ(設定が設定入力に基づく)
公開されたプロセッサは、ツール・パレットでもプロセスで使用するために表示され、プロジェクト・ブラウザでも表示されるので、他のEDQインスタンスへのインポート用にパッケージ化できます。
|
注意: プロセッサのアイコンは公開前にカスタマイズできます。これにより、プロセッサをツール・パレットで新規ファミリに公開もできます。 |
構成されたプロセッサを公開するには、次の手順を使用します。
プロセッサを右クリックし、「公開プロセッサ」を選択します。次のダイアログが表示されます。
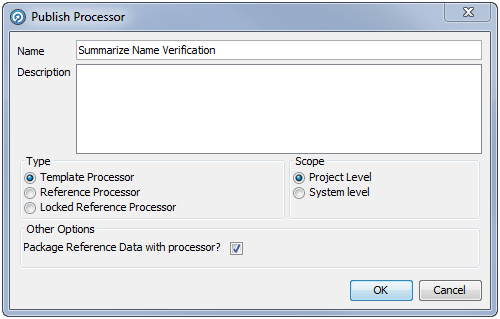
「名前」フィールドで、ツール・パレットに表示されるプロセッサの名前を入力します。
必要な場合は、詳細を「説明」フィールドに入力します。
公開されたプロセッサのタイプを「テンプレート・プロセッサ」、「参照プロセッサ」、または「ロックされた参照プロセッサ」から選択します。
範囲: 「プロジェクト・レベル」(プロセッサは現在のプロジェクトでのみ使用可能)または「システム・レベル」(プロセッサはシステム上のすべてのプロジェクトで使用可能)を選択します。
この公開されたプロセッサに関連付けられた参照データをパッケージ化するには、「参照データをプロセッサとパッケージ化しますか。」チェック・ボックスを選択します。
|
注意: 公開されたプロセッサに対して外部化したオプションでは、常に参照データを使用可能にする必要があります(プロジェクトまたはシステムのレベル)。公開されたプロセッサ上で外部化されないオプションは、その参照データとして公開されたプロセッサを提供するか(このオプションを選択したときのデフォルト動作)、参照データを使用可能にするように要求できます。たとえば、標準のシステム・レベルの参照データ・セットを使用するためです。 |
公開されたプロセッサは、通常のプロセッサと同じ方法で編集できますが、変更したら再公開する必要があります。
公開されたテンプレート・プロセッサを編集および公開すると、オリジナルといずれかのインスタンスの間に実際のリンクがないので、影響を受けるのはそのプロセッサの後続のインスタンスのみです。
公開された参照プロセッサまたはロックされた参照プロセッサを再構成すると、プロセスのインスタンスのすべてが必要に応じて変更されます。ただし、オリジナルを再公開するときにプロセッサのインスタンスが使用中の場合、次のダイアログが表示されます。
プロセッサのユーザーがプロセッサの動作の意図を理解できるように、プロセッサを公開する前にオンライン・ヘルプを添付できます。
公開されたプロセッサの主要なヘルプ・ページとして動作するindex.htm (またはindex.html)という名前のファイルを含むzipファイルとして、オンライン・ヘルプを添付する必要があります。他のhtmlページや画像もzipファイルに含め、主要なヘルプ・ページに埋め込みでき、またそこからのリンクもできます。この設計の目的は、いずれのHTMLエディタでもヘルプ・ページを設計でき、index.htmという名前のHTMLファイルとして保存でき、従属ファイルとともにzip圧縮できることです。
これを行うには、公開されたプロセッサを右クリックし、「ヘルプの添付」を選択します。これにより、ファイルを検索および選択するために使用するファイル参照ダイアログが開きます。
|
注意: 「ヘルプの格納場所の設定」オプションの用途は、ヘルプ・ファイル(複数可)をプロセッサに添付するのでなく、ヘルプ・ファイルのパスを指定することです。このオプションは、ソリューション開発でのみ使用してください。 |
プロセッサにヘルプが添付されている場合、ユーザーはプロセッサを選択してF1を押し、ヘルプにアクセスできます。公開されたプロセッサのヘルプ・ファイルは、製品とともに出荷される標準のEDQオンライン・ヘルプと統合されないので、その索引にリストされず、検索で見つかりません。
同様の目的で公開されたプロセッサのコレクションを、ツール・パレットでファミリに公開できます。たとえば、特定のタイプのデータを使用するために複数のプロセッサを作成し、すべてをその固有ファミリに公開します。
これを行うには、公開前に各プロセッサのファミリ・アイコンをカスタマイズし、同じファミリに公開するすべてのプロセッサに対して同じアイコンを選択する必要があります。プロセッサを公開すると、ファミリ・アイコンがツール・パレットで表示され、公開され、そのファミリ・アイコンを使用するすべてのプロセッサがそのファミリに表示されます。ファミリの名前はファミリ・アイコンの名前と同じになります。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
公開されたプロセッサは、次に示すように個別プロジェクトのレベルかシステムのレベルのいずれかにあります。
公開されたプロセッサには3つのタイプがあります。
テンプレート - これらのプロセッサは必要に応じて再構成できます。
参照 - これらのプロセッサはその構成をオリジナルのプロセッサから継承します。これらを再構成できるのは、適切な権限を持つユーザーのみです。プロセッサ・アイコンの左上の隅にある緑色のボックスによって識別されます。
ロックされた参照 - これらのプロセッサも構成をオリジナルのプロセッサから継承しますが、標準の参照プロセッサと異なり、このリンクは削除できません。プロセッサ・アイコンの左上の隅にある赤色のボックスによって識別されます。
これらのプロセッサは他のプロセッサと同じ方法で使用でき、プロジェクト・ブラウザまたはツール・パレットから、クリックしてプロジェクト・キャンバスにドラッグして追加します。
詳細は、Enterprise Data Qualityオンライン・ヘルプの公開されたプロセッサに関する項を参照してください。
公開されたプロセッサの作成と使用は、次の権限によって制御されます。
公開済プロセッサ: 追加 - ユーザーはプロセッサを公開できます。
公開済プロセッサ: 変更 - この権限を「公開済プロセッサ: 追加」権限と組み合せると、ユーザーが既存の公開されたプロセッサを上書きできます。
公開済プロセッサ: 削除 - ユーザーは公開されたプロセッサを削除できます。
参照プロセッサへのリンクの削除 - ユーザーは公開された参照プロセッサをロック解除できます。詳細は、次の項を参照してください。
ユーザーに「参照プロセッサへのリンクの削除」権限がある場合、公開された参照プロセッサをロック解除できます。これを行うには、次の手順を実行します。
プロセッサを右クリックします。
「参照プロセッサへのリンクの削除」を選択します。次のダイアログが表示されます。
「OK」をクリックして確定します。プロセッサのインスタンスは参照プロセッサから切断されるので、オリジナルのプロセッサが更新されても更新されません。
詳細は、「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください。
複雑なプロセスの作成中や、既存のプロセスを再表示するときは、プロセスがどう設定されたかを調査し、エラーがあればエラーを調査することがよく望まれます。
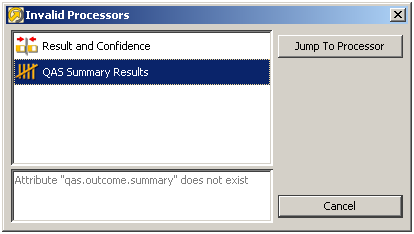
多数のプロセッサがキャンバスに存在する場合、「無効なプロセッサの検索」(キャンバスを右クリック)を使用して、問題の発見を支援できます。このオプションを使用できるのは、そのキャンバスにある1つ以上のプロセッサにエラーがある場合のみです。
これにより表示されるダイアログに、キャンバスに接続した無効なプロセッサがすべて表示されます。エラーの詳細は、選択すると、各プロセッサに対してリストされます。「プロセッサにジャンプ」オプションにより、ユーザーはキャンバス上で選択された無効なプロセッサに移動するので、問題をプロセッサ構成から調査および修正できます。
プロセッサへの入力として使用される属性をリストするために、そのプロセッサの上で右クリックし、「入力属性検索」を選択できます。
使用されるアイコンから、属性が属性の最新バージョンか、それとも定義された属性なのかが示されます。
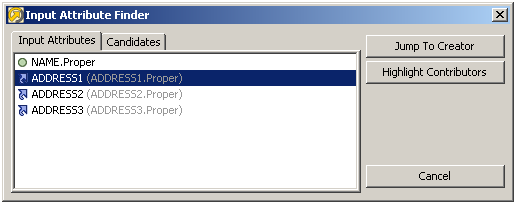
次の2つのオプションがあります。
作成者にジャンプ - 選択した属性を作成したプロセッサに移動します。
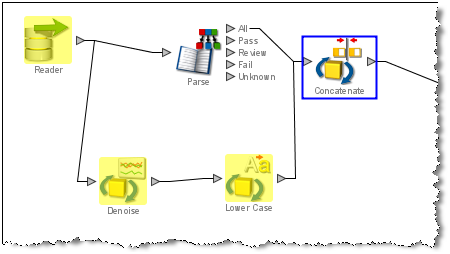
コントリビュータのハイライト表示 - 選択した入力属性の値に影響を及ぼしたすべてのプロセッサ(関連がある場合はリーダーを含む)がハイライト表示されます。影響を及ぼしたプロセッサは黄色でハイライト表示されます。次の例では、連結プロセッサの入力属性の1つの作成に影響を及ぼしたパスを判定するため、その属性を検索しました。
候補
入力属性検索の「候補」タブでは、プロセッサ構成に存在するいずれの属性に対しても、同じ機能を実行できます。属性はプロセッサ構成で入力として使用される必要があるとはかぎりません。
このアクションを行うと、「コントリビュータのハイライト表示」オプションで行われたハイライトがすべてクリアされます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
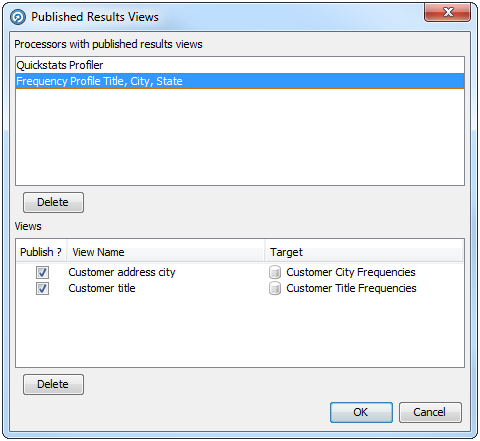
プロセスを実行する前にプロセス実行の結果をプレビューでき、特定の結果ビューを無効化または削除できます。これは、「公開された結果ビュー」ダイアログで行われます。
ダイアログを開くには、次のいずれかを行います。
「プロセス」ツールバーの「公開された結果ビュー」ボタンをクリックします。

「プロセス」でプロセッサを右クリックして、メニューで「公開された結果ビュー」を選択します。
このダイアログは、2つの領域に分かれています。
公開された結果ビューを持つプロセッサ - プロセスにおいて公開されたビューを持つすべてのプロセッサをリストします。
ビュー - 「公開された結果ビューを持つプロセッサ」領域で現在選択されたプロセッサのビューをリストします。
「公開」チェック・ボックスを選択または選択解除して、公開されたビューを選択または選択解除できます。あるいは、ビューを選択して「削除」をクリックして、これらを削除できます。
ビューを誤って削除した場合、ダイアログの右下の隅で「取消」をクリックして、ビューを復元します。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
EDQ結果ブラウザは使用しやすいように設計されています。一般に、EDQプロセスにおけるいずれかのプロセッサをクリックして、そのサマリー・ビューの1つ以上を結果ブラウザで表示できます。
結果ブラウザには、上部のボタンで使用できる各種の簡単なオプションがあります。ボタンの上にカーソルを置けば機能が表示されます。
ただし、結果ブラウザには、あまり知られていない機能が他にもいくつかあります。
参照するプロセッサをEDQで変更しても結果を参照できるため、特定のプロセッサからの結果を含む新規ウィンドウを開くのは多くの場合有用です。たとえば、2つの結果ブラウザのウィンドウを開き、左右に並べて表示して、結果のセット2つを比較したい場合がこれに該当します。
新規の結果ブラウザを開くには、プロセス内のプロセッサを右クリックし、「結果を新規ウィンドウに表示」を選択します。
プロジェクト・ブラウザの右クリック・メニューから、ステージング済データ(スナップショット、またはプロセスから書き込まれたデータ)を表示するための同じオプションが存在します。
ときどき、結果ブラウザに見慣れない文字が表示されたり、全部表示するのが難しい非常に長いフィールドが出現することがあります。
たとえば、Unicode対応データストアからのデータを処理する場合、EDQクライアントにデータを画面上に正しく表示するための一部のフォントがインストールされていないことがあります(データはEDQサーバーによって正しく処理されます)。
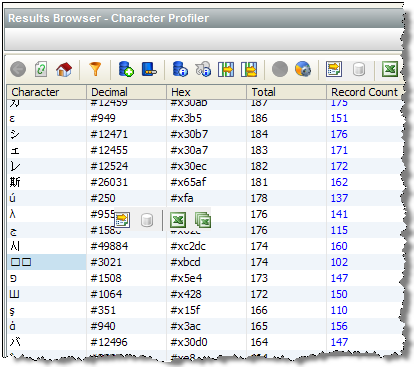
この場合、文字または見慣れない文字を含む文字列を右クリックして「文字の表示」オプションを選択し、文字を調査すると便利です。たとえば、次のスクリーンショットでは、文字を正しく表示するために必要なフォントがクライアントにインストールされていない場合に、マルチバイト文字が選択されたUnicodeデータを「文字プロファイラ」プロセッサが処理する様子を示します。このため、文字は2つの制御文字として表示されます。
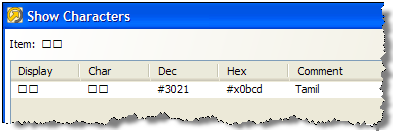
文字を右クリックして「文字の表示」オプションを使用すると、Unicode仕様の文字の文字範囲が表示されます。前述の場合、文字はタミル文字の範囲内です。
「文字の表示」オプションは、結果ブラウザに全部表示するのが難しい非常に長いフィールド(説明など)で作業する場合にも便利です。
たとえば、次のスクリーンショットでは、車の広告から取得されたいくつかのサンプル・データが示されます。
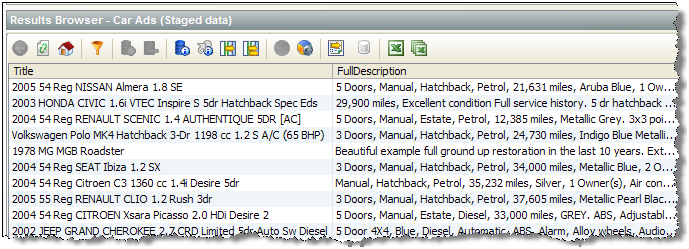
完全列幅ボタンを押すと、列の幅が広がり完全なデータが表示されますが、この場合、画面幅に表示するにはデータが多すぎます。詳細な説明フィールドを折り返されたテキストとして表示するには、表示する行を右クリックして「文字の表示」オプションを使用します。次に、画面右上の矢印をクリックして各値をテキスト領域に表示したり、画面下部の矢印を使用してレコードの間をスクロールできます。
結果ブラウザで列ヘッダーをクリックすると、その列でデータがソートされます。ただし、列ヘッダーを[Ctrl]+クリック([Ctrl]キーを押しながらヘッダーをクリック)すると、結果ブラウザのその列に表示されている(ロードされた)データすべてを選択できます。これは、ロードされたすべての行をコピーしたり、それらを使用して右クリック・オプションで参照データを作成または追加する場合などに便利です。デフォルトでは、結果ブラウザでは100個のレコードしかロードされないため、列ヘッダーを選択する前に「データをすべてロード」ボタンを使用できます。
同じ方法で複数の列ヘッダーを選択できます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
イベント・ログは、EDQサーバーで実行したすべてのジョブおよびタスクの完全な履歴を提供します。
デフォルトでは、すべてのタイプの最近完了したイベントがログに表示されます。ただし、複数の基準を使用してイベントをフィルタリングし、確認する必要があるイベントを表示できます。最上位レベルのビューに表示される列を変更して、イベント・ログをカスタマイズすることもできます。イベントをダブルクリックすると、入手可能な詳細情報が表示されます。
表示されたイベントのビューは、必要に応じて任意の列でソートできます。ただし、デフォルトでは古いイベントは表示されないため、イベントが表示されるように、ソートする前にフィルタを適用する必要があります。
ジョブ、タスクまたはシステム・タスクが開始または終了すると、イベント・ログにイベントが追加されます。
タスクは、ジョブの一部として、またはディレクタUIを使用して個別に開始されます。
次のタイプのタスクがログ記録されます。
プロセス
スナップショット
エクスポート
結果のエクスポート
外部タスク
ファイルのダウンロード
次のタイプのシステム・タスクがログ記録されます。
OFB - 参照用に最適化することを意味するシステム・タスクであり、データを索引付けしてデータをソートおよびフィルタリングできるようにすることで、書き出された結果を結果ブラウザで参照するために最適化します。OFBタスクは通常、スナップショットまたはプロセス・タスクが実行された直後に実行されますが、EDQクライアントを使用して手動で開始することもできます。それには、一連のステージング済データを右クリックして「ソート/フィルタの有効化」を選択するか、最適化されていない列でソートまたはフィルタリングを試みて、ただちに最適化を選択します。
DASHBOARD - 結果をダッシュボードに公開するシステム・タスク。これは、プロセス・タスクが実行された直後に、「ダッシュボードに公開」オプションをオンにして実行されます。
ディレクタUIが複数のサーバーに接続されている場合、左上隅の「サーバー」ドロップダウン・フィールドを使用してサーバー間を切り替えることができます。
サーバー・コンソールUIが複数のサーバーに接続されている場合、ウィンドウ上部のタブ・リストで必要なサーバーを選択します。
クイック・フィルタ
クイック・フィルタ・オプションは、「イベント・タイプ」、「ステータス」および「タスク・タイプ」でのフィルタリングに使用できます。イベントをフィルタリングするには、フィルタに含める値を選択し(複数の項目を選択するには、[Ctrl]キーを押しながら選択)、画面左下にある「フィルタの実行」ボタンをクリックします。
例を示します。
フリー・テキスト・フィルタ(先行検索)
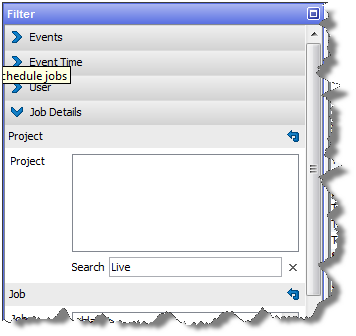
詳細なフリー・テキスト・フィルタ・オプションは、「プロジェクト名」、「ジョブ名」、「タスク名」および「ユーザー名」でのフィルタリングに使用できます。これらはフリー・テキストであるため、フィールドに名前の一部を入力できます。これらの任意のフィールドに名前の一部を入力すると、オブジェクトにその名前の一部が含まれる場合は、そのオブジェクトが表示されます(一致では大文字と小文字が区別されます)。たとえば、ライブ・システムで稼働しているすべてのプロジェクトに「Live」という語を含む名前を指定する命名規則を使用する場合、ライブ・システムのすべてのイベントを次のように表示できます。
|
注意: 「プロジェクト名」列は、デフォルトでは表示されません。表示されるようにビューを変更するには、左側にある「列の選択」ボタンをクリックして「プロジェクト名」ボックスを選択します。 |
日付/時間フィルタ
画面右側にあるフィルタの最終設定で、イベントのリストを日時でフィルタリングできます。特定の日付を簡単に指定できるように、日付ピッカーが用意されています。イベント・ログにアクセスしている際は、最新のイベントのみが表示されますが、必要に応じて、フィルタを適用して古いイベントを表示できます。
|
注意: イベントがEDQによって履歴から削除されることはありませんが、リポジトリに保存されているため、リポジトリ・データベースに構成されているカスタム・データベースレベルのアーカイブまたは削除ポリシーの影響を受けることがあります。 |
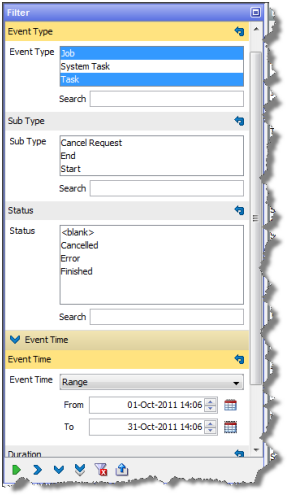
イベントは、開始時刻または終了時刻(あるいはその両方)でフィルタリングできます。たとえば、2008年11月に完了したすべてのジョブおよびタスク(システム・タスクではない)を表示するには、フィルタを次のように適用します。
列の選択
イベント・ログに表示される列のセットを変更するには、「イベント・ログ」領域の左上にある「列の選択」ボタンをクリックします。「列選択」ダイアログが表示されます。必要に応じて列を選択または選択解除し、「OK」をクリックして保存するか、「取消」をクリックして変更を破棄します。または、「デフォルト」をクリックしてデフォルト設定を復元します。
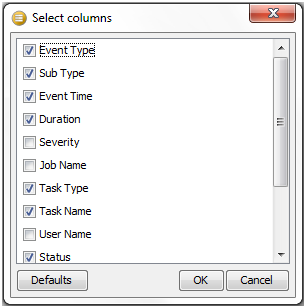
「重大度」はめったに使用されない列で、現在、正常に完了したタスクまたはジョブは50に設定され、エラーまたは警告が発生したタスクまたはジョブは100に設定されています。
イベントを開く
ダブルクリックしてイベントを開くと、入手可能な詳細が表示されます。
タスクを開くと、タスクの実行時に生成されたメッセージを示すタスク・ログが表示されます。
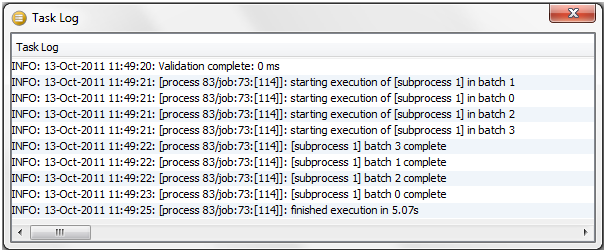
|
注意: メッセージはINFO、WARNINGまたはSEVEREに分類されます。INFOメッセージは情報提供を目的としており、問題を示すものではありません。WARNINGメッセージは、プロセス構成(またはデータ)で問題が発生していることを示すために生成されますが、これによってタスクがエラーになることはありません。SEVEREメッセージは、タスクのエラーに対して生成されます。 |
ジョブでは、ジョブに対して通知電子メールが構成されている場合、ジョブの完了イベントを開くと、Webブラウザに通知電子メールが表示されます。通知が設定されていないジョブには、詳細情報は保持されません。
イベント・ログからのデータのエクスポート
イベント・ログの表示可能データは、CSVファイルにエクスポートできます。これは、Oracleサポートに連絡した際に、サーバー上で何が実行されているかの詳細を要求された場合に便利です。
イベントの現在のビューをエクスポートするには、「CSVにエクスポート」をクリックします。これにより、CSVファイルを書き込むクライアントでブラウザが起動します。ファイルに名前を付けて「エクスポート」をクリックし、ファイルに書き込みます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください
EDQにおける照合の主な原則の1つは、一致と出力の決定をすべて自動的に行えるわけではないということです。可能性のある複数の一致を同じものとみなせるかどうかや、そのマージ済出力がどうなるかを(必要に応じて)判定する最も高速で効率的な方法は、多くの場合、一致するレコードに手動で目を通し、手動の決定を行うことです。
EDQには、照合結果をレビューするための2つの異なるアプリケーション(「一致レビュー」と「ケース管理」)が用意されています。レビュー・アプリケーションは照合プロセッサ構成の一部として選択され、結果を生成する方法を決定します。したがって、特定のいずれのプロセッサについても、2つのアプリケーションは相互に排他的です。レビュー・アプリケーションを選択すると、照合プロセッサで使用できるオプションの一部も変更されます。
照合プロセッサの構成をいつでも変更し、レビュー・アプリケーション間で切替え可能ですが、いずれの結果もプロセッサを再起動後に新規アプリケーションから使用可能になります。
使用するレビュー・アプリケーションは、照合プロセッサのプロセス・ダウンストリームの要件と、次の項で詳細に説明する各レビュー・アプリケーションの強みに基づいて選択してください。
「一致レビュー」アプリケーションは、構成が不要な軽量のレビュー・アプリケーションです。照合結果とマージ結果の手動レビュー、実行間の手動一致決定の永続性、および手動一致決定のインポートとエクスポートがサポートされます。プロセッサの実行間で主要な情報が変更されると、その関係に対して前に保存された一致決定は無効化され、関係は再レビューのために作成されます。
「一致レビュー」アプリケーションは、少数のレビューアが同じビジネス単位でレビュー作業を共有する場合の導入に向いています。レビュー作業のグループ配分や割当てはサポートされず、基本的なレビュー管理機能が提供されます。
「ケース管理」アプリケーションでは、照合レビューへのカスタマイズ可能なワークフロー指向のアプローチが実現します。ケース管理では、関連するレビュー・タスク(アラート)がグループ化されてケースになります。ケースとアラートはどちらも複数の状態で存在でき、相互間の許可されている遷移を伴います。ケース管理ではタイムアウトや他の構成可能属性に基づくアラートの自動エスカレーションもサポートされます。
ケース管理では、作業を個別ユーザーやユーザーのグループに割り当てることや、一致レビューで提供されるよりも高度なレビュー管理機能がサポートされます。
ケース管理は使用する照合プロセッサのそれぞれに対して明示的に有効化する必要があり、ケースとアラートの生成をサポートするには追加の構成が必要です。
ケース管理ではマージ・レビューはサポートされません。
ケース管理システムの詳細は、Enterprise Data Qualityオンライン・ヘルプのケース管理の使用に関する項を参照してください。
EDQの機能を使用して、決定データをインポートし、照合プロセッサ内で可能性がある一致に適用できます。
決定のインポートは1度のみのアクティビティの場合もあり、照合プロセスの一部として進行中の場合もあります。たとえば、異なるアプリケーションから照合プロセスをEDQに移行している場合、前の決定すべてを移行の一部として含めるのが望ましいことです。あるいは、レビュー・プロセスを外部で実行する場合、決定インポートを日常的に使用して、外部決定をEDQに戻します。
別プロセスやEDQのインスタンス、たとえば同じデータに対して動作する別照合プロセスからエクスポートされた一致決定もインポートできます。
EDQのすべての一致決定は一致する可能性があるレコードのペアを参照します。したがって、インポートされた決定を適用するには、照合プロセッサによって「レビュー」ルールを使用して作成された関係に照合できる必要があります。プロセッサで確定一致として識別されたか、またはまったく一致しないレコードのペアの決定をインポートすると、決定は適用されませんが、適用されないのは、レコードのレビュー関係が作成されるように照合ロジックが変更されておらず、変更されるまでの間に限られます。
決定をインポートし、さらにケース管理(または一致レビュー)を使用して手動決定を作成できます。関係に対するいずれの手動決定よりも後の日付/時間の決定がインポートされると、最新の決定として扱われます。手動決定と厳密に同じ日付/時間の決定がインポートされると、手動決定はインポートされた決定より優先されます。
このヘルプの項の残りでは、一致決定のインポートを1ステップずつ案内します。
一致決定をインポートするには、リーダーを使用してインポートされた決定のデータを読み取り、データを照合プロセッサの決定入力ポートに接続します。
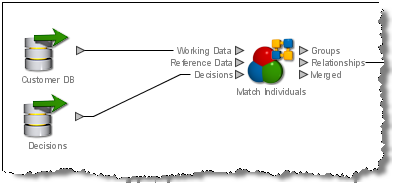
|
注意: 「グループとマージ」では可能性がある一致に対する手動決定が許可されないので、決定入力ポートはありません。 |
このデータには、EDQ照合プロセスで対応する関係と照合するために必要な関係の識別情報すべて(つまり、関係内の両方のレコードに対する照合プロセッサの構成可能な決定キーに含まれる各属性の属性)、および決定、レビュー・ユーザーおよび日付/時間のためのフィールドが含まれる必要があります。可能性がある一致をレビューするときに作成されたコメントもインポートできます。
決定データのセットを照合プロセッサに接続している場合(前述参照)、照合プロセッサを開くと追加のサブプロセッサが表示されます。
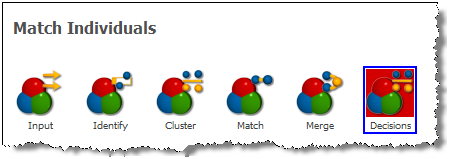
「決定」サブプロセッサをダブルクリックして、決定データを照合プロセスにマップします。
最初のタブでは、接続した決定データにあるフィールドを、ユーザー名や日付/時間などの詳細とともに、インポートする実際の決定およびコメント値に設定できます。
次のスクリーンショットでは、一致決定データをインポートするための正しい構成の例を示します。
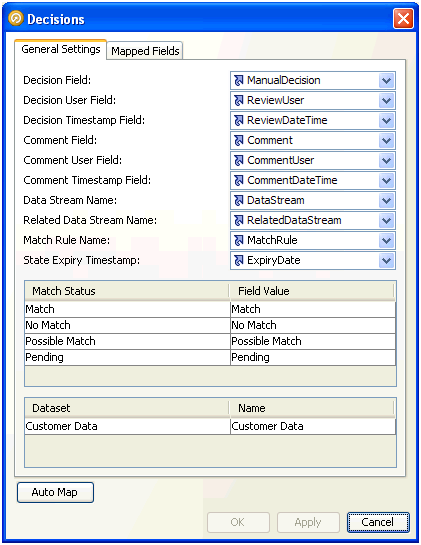
前述のスクリーンショットの最初のセクションでは、インポートされた決定データにおける、決定データを取得するために使用される属性が示されます。すべてのコメント・フィールドはオプションです。「自動マップ」ボタンを押すと、これらのフィールドのデフォルト名を検索して、フィールドを自動的にマップしようとします。フィールドのデフォルト名は、EDQで照合プロセッサから関係を書き出すときに作成された名前なので、次のとおりです。
| 決定フィールド | デフォルト(自動)名 |
|---|---|
| 決定フィールド | RuleDecision |
| 決定ユーザー・フィールド | ReviewedBy |
| 決定タイムスタンプ・フィールド | ReviewDate |
| コメント・フィールド | Comment |
| コメント・ユーザー・フィールド | CommentBy |
| コメント・タイムスタンプ・フィールド | CommentDate |
| データ・ストリーム名 | DataStreamName |
| 関連データ・ストリーム名 | RelatedDataStreamName |
| 一致ルール名 | MatchRule |
| 状態の有効期限タイムスタンプ | ExpiryDate |
つまり、レビューする関係を生成した同じ照合プロセッサに決定データをインポートして戻す場合、「自動マップ」を使用して、すべての決定フィールドを自動的にマップできます。
|
注意: 「状態の有効期限タイムスタンプ」フィールドが表示されるのは、ケース管理を使用してレビューを扱うプロセッサの場合のみです。 |
最初のタブの2番目のセクションでは、構成された決定フィールド(前述の例ではManualDecision)の実際の決定値、そしてこれらがEDQに認識される決定値にマップされる方法を指定できます。前述の場合、フィールド値はEDQで使用されるフィールド値と同じで、「一致」、「一致なし」、「可能性がある一致」および「保留中」です。
3番目のセクションでは、一致プロセッサにより使用されるデータ・ストリームに対して予想される名前の値を指定できます。複数のデータ・セットがある照合プロセッサの場合、インポートされた各決定を正しいデータ・ストリームからの正しいレコードと照合するため、このことは特に重要です。前述の場合、照合プロセッサは単一のデータ・ストリームに対して動作する「重複除外」プロセッサです。つまり、すべてのレコード(各関係の両方のレコード)が同じデータ・ストリーム(「顧客データ」)に由来します。「顧客データ」という名前を前述で指定すると、インポートするすべての決定データは、DataStream属性とRelatedDataStream属性のどちらでも、値が「顧客データ」の必要があります。
次に、「決定」サブプロセッサの「マップ済フィールド」タブを使用して、インポートされた決定データのフィールドを一致関係の必要なフィールドにマップします。可能性のある一致を、一致レビューとケース管理のどちらを使用して処理しているかに応じて、このマッピングの要件は異なります。
一致レビューを使用中の場合、マッピングする必要があるのは、照合データにおける「決定キー」フィールドに相当する決定データ・フィールドのみです。参照しやすくするために、これらのフィールドはマッピング・タブでは赤色で強調表示されます。
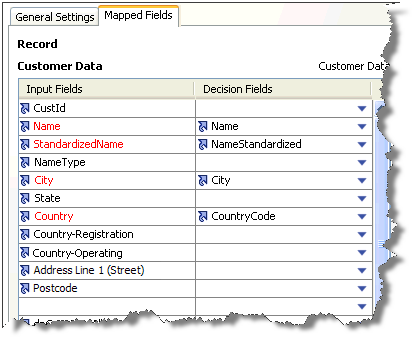
ケース管理を使用する場合、すべてのアクティブなデータ・フィールドをマップする必要があります。この場合、ハイライト表示は使用されません。
次のスクリーンショットでは、決定データの属性を単純な重複除外照合プロセッサの決定キーに構成する例を示します。
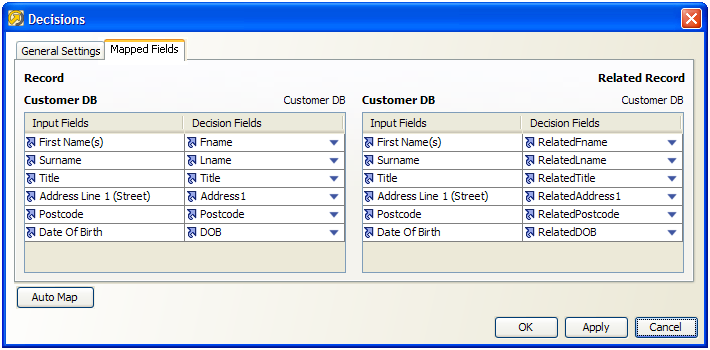
決定データには、関係の両方のレコードの属性(この場合はレコードと関連レコード)が必要です。
「決定」サブプロセッサを正しく構成したら、「OK」ボタンをクリックして、構成を保存できます。その後、照合プロセスを実行して、一致決定をインポートできます。
決定のインポートを1回かぎりで実行している場合は、決定が正しくインポートされたことをチェックしてから、決定データのリーダーを削除します。
照合プロセスの定期的な実行の一部として決定のインポートを続行する場合は、決定データのリーダーを接続したままにしてください。スナップショットを再実行するか、データを照合プロセスに直接ストリームして、EDQにおける他のデータ・ソースと同じ方法で決定データをリフレッシュできます。決定がすでにインポートされた場合、たとえ決定データに存在しても、再インポートされません。
インポートされた決定は、EDQを使用して行われた決定と同じように扱われるので、ケース管理(または一致レビュー・アプリケーション)で表示され、照合プロセッサの「レビュー・ステータス」サマリーも影響を受けます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください
EDQで行われるすべての関係レビュー・アクティビティ(手動一致決定とレビュー・コメント)は、レビューのベースとなった照合プロセッサから書き出せます。次のいずれかの理由で有用な場合があります。
レビュー・アクティビティの完全な監査証跡を保管するため
一致決定を別プロセス(たとえば、同じデータに対して動作する新規照合プロセス)にインポートするためのエクスポートするため
レビュー・アクティビティに対するデータ分析を有効化するため
手動一致決定とレビュー・コメントは、各照合プロセッサからの「決定」出力フィルタに対して照合プロセスから書き出されます。
データは照合プロセッサのデータ・ビューで直接表示でき、データをステージングするためのライターなど、いずれのダウンストリーム・プロセッサにも接続できます。
すべての決定とコメントを「決定」出力に書き込むレビュー・アクティビティを行った後は、照合プロセッサを再実行する必要があります。
また、照合プロセッサ経由でケース管理決定のエクスポートはできません。かわりにワークフローとケース・ソース用の「ケース管理の管理」内にあるインポートとエクスポートのオプションを使用する必要があります。
次のスクリーンショットでは、ライターを使用して書き出された決定データ出力の例を示します。
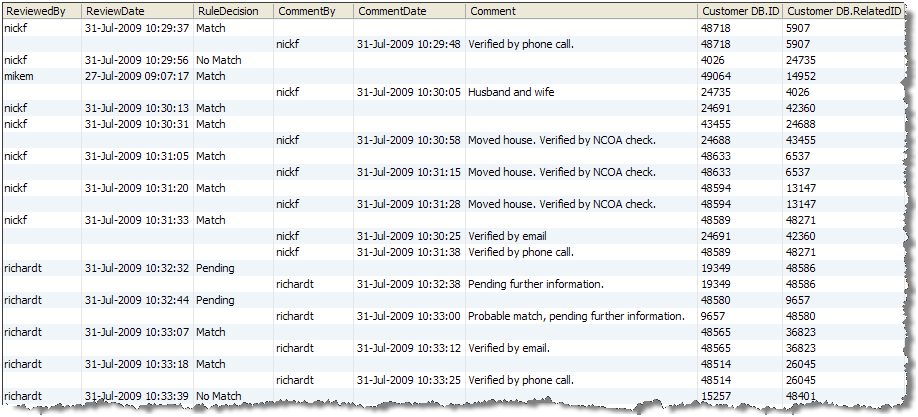
結果またはコメントが適用されるデータの監査証跡を常に完全なものとするため、決定やコメントの時点のすべての関係データは決定またはコメント・レコードにコピーされます。前述のように、手動一致決定およびコメント用に格納されたデータは少々異なりますが、レビュー・コメントは一致決定に関係する可能性があるので、これらはまとめて出力されます。
必要な場合、RuleDecision属性に対して「データなしチェック」を実行するなどして、コメントおよび決定レコードをダウンストリーム処理で分割できます。この属性に「データなし」が含まれるすべてのレコードはレビュー・コメントであり、この属性にデータが含まれるすべてのレコードは手動一致決定です。
書き込まれた決定は、永続的な外部データ・ストアにエクスポート、別プロセスで処理、また必要があれば同じデータに対して動作する別照合プロセスにインポートできます。「一致決定のインポート」を参照してください。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください
内部でディレクタ・アプリケーションを使用して最初に構成される多くの構成設定を公開し、実行時にEDQサーバー・コンソールのユーザー・アプリケーションのユーザーか、コマンドライン・インタフェースを使用してEDQジョブを呼び出す外部アプリケーションのいずれかによってオーバーライドできます。
これにより、EDQと統合されるサード・パーティ・アプリケーションのユーザーが自分の要件にあわせてジョブ・パラメータを変更できます。たとえば、ユーザーが複数の異なるソース・ファイルに対して標準EDQジョブを使用し、ジョブの各実行の結果を個別に格納するために使用する実行ラベルとともに、入力ファイル名を実行時にオプションとして指定するとします。
ジョブ・フェーズは自動的に外部化されます。つまり、ディレクタのユーザーは何も構成しなくても、実行時に実行プロファイルを使用してフェーズを有効化または無効化できます。
オプションを外部化できる他のポイントは次のとおりです。詳細は、各ポイントをクリックしてください。
スナップショットの外部化(サーバー側のみ)
エクスポートの外部化(サーバー側のみ)
プロセッサ・オプションを外部化するには2つの段階があります。
外部化するプロセッサ・オプションを選択します。
外部化されたオプションに意味がわかりやすい名前をプロセス・レベルで付けます。
外部化されたプロセッサ・オプションはプロセス・レベルで構成されるので、プロセス内のすべての他のプロセッサから使用可能です。
プロセス内で外部化されたオプションには一意の名前が必要です。ただし、他のプロセスで外部化されたオプションと同じ名前を使用できます。
2番目の段階はオプションですが、外部化されたオプションを容易に識別できるようにするため、意味がわかりやすい名前を設定することをお薦めします。
「キャンバス」領域で、必要なプロセッサをダブルクリックします。「プロセッサ構成」ダイアログが表示されます。
「オプション」タブを選択します。
ダイアログの右下にある「外部化オプションの表示」ボタンをクリックします。各オプションの横に「外部化」ボタンが表示されます。
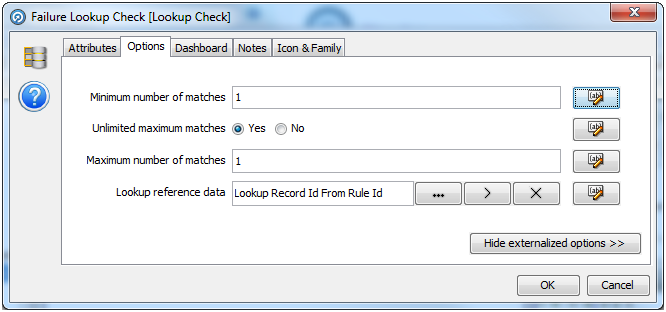
外部化する必要がある各オプションに対して次の操作を行います。
「外部化」ボタンをクリックします。「外部化」ダイアログが表示されます。
ダイアログにあるボックスを選択します。デフォルトのラベルが割り当てられます。
必要な場合はラベルを編集するか、(使用可能な場合)ドロップダウン・リストから別ラベルを選択します。
「OK」をクリックします。
外部化すると、各オプションの横にあるボタンに緑色のマークが付き、オプションが外部化されていることを示します。
すべてのオプションを必要に応じて外部化したら、「OK」をクリックして保存するか、「取消」をクリックして破棄します。
外部化されたプロセッサ・オプションはプロセス・レベルで使用(ジョブでオーバーライド)されます。
プロセスの外部化されたプロセッサ・オプションにはそれぞれデフォルト名があります。次の手順を使用して、異なる名前を割り当てます。
関連するプロセッサを右クリックし、「外部化」を選択します。「プロセス外部化」ダイアログが表示されます。プロセスで使用可能な外部化されたオプションがすべて表示されます。
「外部化の有効化」チェック・ボックスが選択されていることを確認します。
ダイアログの上部領域にある必要なオプションをクリックします。下部領域にはオプションのリンク先であるプロセッサが示され、キャンバス内でプロセッサに直接リンクできます。
「名前変更」をクリックします。
「OK」をクリックして保存するか、「取消」lをクリックして破棄します。
|
注意: 外部化されたオプションに付けた名前は、実行プロファイルかコマンドラインから、この種のオーバーライド・オプションの構文を使用して、オプション値をオーバーライドするときに使用する必要があります。外部化されたオプション値のオーバーライドの例を含むこの構文の完全なガイドは、EDQインストレーションのoedq_local_home/runprofilesディレクトリで提供されるtemplate.propertiesファイルにある指示を参照してください。 |
各照合プロセッサのサブプロセッサウィンドウに「外部化」オプションが表示されます。このウィンドウを開くには、キャンバス上で照合プロセッサをダブルクリックします。
照合プロセッサを外部化すると、次の設定を実行時に動的に変更できます。
有効化または無効化するクラスタ
各クラスタのクラスタ制限
各クラスタのクラスタ比較制限
有効化または無効化する一致ルール
一致ルールを実行する順序
各一致ルールと関連付けられた優先度のスコア
各ルールと関連付けられた決定
照合プロセッサ・オプションを外部化するには2つの段階があります。
外部化する照合プロセッサ・オプションの選択
プロセス・レベルでの外部化された照合プロセッサ・オプションの構成
|
注意: 2番目の段階はオプションですが、外部化されたオプションに意味がわかりやすい名前を必ず付けることをお薦めします。 |
サブプロセッサ・ウィンドウの「外部化」をクリックします。外部化ダイアログが表示されます。
リストされた一致プロパティの横にあるチェック・ボックスを使用して、外部化するプロパティを選択します。
「OK」をクリックして受け入れるか、「閉じる」lをクリックして破棄します。
外部化されたオプションには、一般的なデフォルト名があります。次の手順を使用して、異なる名前を割り当てます。
関連するプロセッサを右クリックし、「外部化」を選択します。「プロセス外部化」ダイアログが表示されます。外部化された照合プロセッサ・オプションを含め、プロセスで使用可能な外部化されたオプションがすべて表示されます。
「外部化の有効化」チェック・ボックスが選択されていることを確認します。
ダイアログの上部領域にある必要なオプションをクリックします。下部領域には発生源となったプロセッサの名前が示され、キャンバス内でそのプロセッサに直接リンクできます。
「名前変更」をクリックします。
「名前変更」ダイアログで新しい名前を入力します。
「OK」をクリックして保存するか、「取消」lをクリックして破棄します。
ジョブ内のタスクには、外部化できる設定がいくつも含まれています。
タスクの設定を外部化する手順は、次のとおりです。
タスクを右クリックして「タスクの構成」を選択します。
対象の設定の横にある「外部化」ボタンをクリックします。
「外部化」ポップアップ内のチェック・ボックスを選択します。
設定のデフォルト名が表示されます。これは必要に応じて編集できます。
「OK」をクリックします。
この後、これらの設定は「ジョブ外部化」ダイアログで管理できます。このダイアログを開くには、ジョブ・キャンバスのツールバーの「ジョブ外部化」ボタンをクリックします。
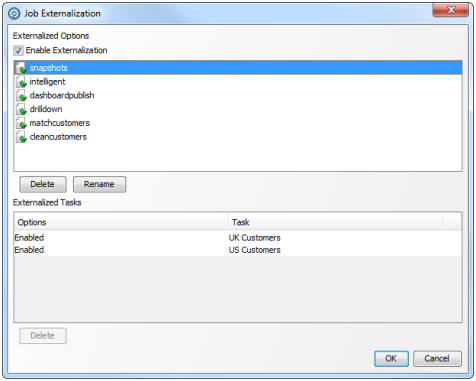
ジョブの外部化は、「外部化の有効化」ボックスを選択または選択解除して有効と無効を切り替えることができます。
「外部化されたオプション」領域に外部化に対応するオプションが表示されます。
オプションを削除するには、そのオプションを選択して、「削除」(「外部化されたオプション」領域の下)をクリックします。
オプションの名前を変更するには、そのオプションを選択して、「名前変更」をクリックします。「名前変更」ポップアップで名前を編集し、「OK」をクリックします。
「外部化されたタスク」領域では、選択されたオプションはそれが関連付けられているタスクの横に表示されます。1つのオプションが複数のタスクに関連付けられている場合は、タスクそれぞれに対して1回表示されます。前述の例のダイアログでは、「有効」オプションがUK顧客のタスクとUS顧客のタスクに関連付けられています。
オプションとタスクの関連付けを解除するには、この領域でオプションを選択して「削除」をクリックします。
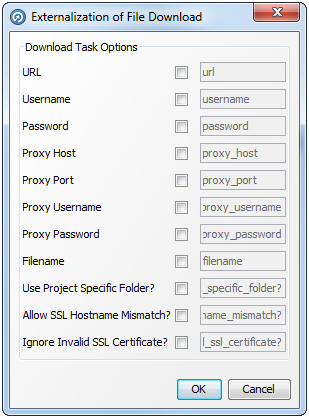
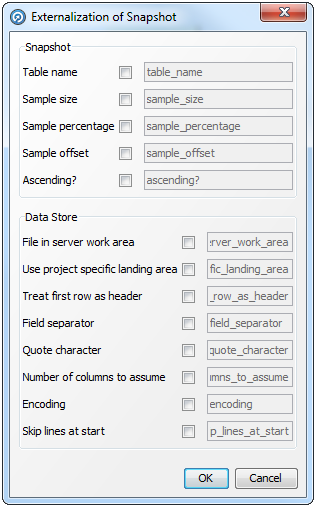
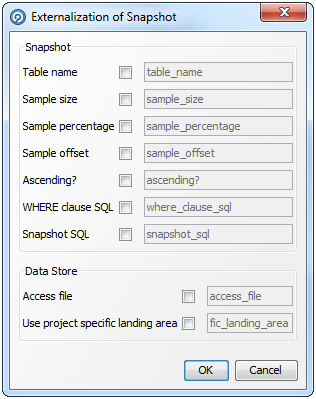
サーバー側のデータ・ストアに由来するスナップショットのみ外部化できます。スナップショットを外部化すると、外部ユーザーがスナップショットそのものの設定(表名、サンプルのサイズ、SQLのWHERE句など)をオーバーライドできるのみでなく、スナップショットの読出し元であるデータ・ストアのオプション(たとえば、ファイル名やデータベース接続の詳細)もオーバーライドできます。
次の手順を実行します。
プロジェクト・ブラウザで必要なスナップショットを右クリックします。
「外部化...」を選択します。「スナップショットの外部化」ダイアログが表示されます。「スナップショット」オプションも「データ・ストア」オプションも使用可能です。
対応するボックスをチェックして、オプションを選択します。右側のフィールドが有効になります。
必要な場合、このフィールドにオプションのカスタム名を入力します。
「OK」をクリックして変更を保存するか、「取消」lをクリックして破棄します。
すべての外部化ダイアログの右にあるフィールドには、それぞれの外部化属性に使用されるデフォルト名が含まれます。これはいずれかのサード・パーティのツールまたはファイルにある外部化された属性を参照するために使用するラベルです。
いずれかのフィールド名を変更するには、左にあるボックスを選択し、必要に応じてフィールドを編集します。
|
注意: 属性名にスペースを使用するのは回避してください。 |
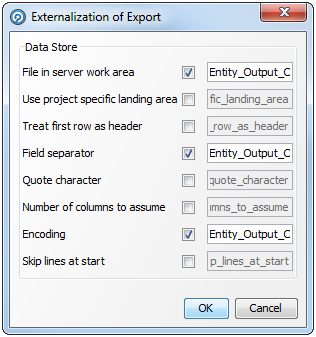
データ・ストアがファイルまたはデータベースのどちらであるかに依存して、このダイアログのフィールドは変化します。
デリミタ付きテキスト・ファイルの例
Accessデータベースの例
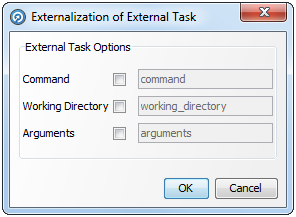
外部タスクを外部化するには、プロジェクト・ブラウザにあるタスクを右クリックして、「外部化」を選択します。
必要に応じてオプションを選択および編集します。「OK」をクリックして保存するか、「取消」lをクリックして破棄します。
すべての外部化ダイアログの右にあるフィールドには、それぞれの外部化属性に使用されるデフォルト名が含まれます。これはいずれかのサード・パーティのツールまたはファイルにある外部化された属性を参照するために使用するラベルです。
いずれかのフィールド名を変更するには、左にあるボックスを選択し、必要に応じてフィールドを編集します。
|
注意: 属性名にスペースを使用するのは回避してください。 |
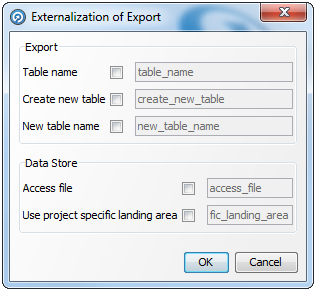
エクスポートを外部化するには、プロジェクト・ブラウザにあるエクスポートを右クリックして、「外部化」を選択します。
必要に応じてオプションを選択および編集します。「OK」をクリックして保存するか、「取消」lをクリックして破棄します。
すべての外部化ダイアログの右にあるフィールドには、それぞれの外部化属性に使用されるデフォルト名が含まれます。これはいずれかのサード・パーティのツールまたはファイルにある外部化された属性を参照するために使用するラベルです。
いずれかのフィールド名を変更するには、左にあるボックスを選択し、必要に応じてフィールドを編集します。
|
注意: 属性名にスペースを使用するのは回避してください。 |
エクスポートを外部化すると、外部ユーザーがエクスポートそのものの設定(書き込む表名など)をオーバーライドできるのみでなく、エクスポートの書込み先であるデータ・ストアのオプション(たとえば、ファイル名やデータベース接続の詳細)もオーバーライドできます。
|
注意: ステージング済データ属性をターゲット・データベース列にマップする構成は外部化できません。さらに、エクスポートで新規表が作成されるように設定せず、書込み先のターゲット表を実行時に動的に変更するには、ターゲット表の構造はエクスポート定義で使用する構造と厳密に同じであり、列とデータ型が同じである必要があります。 |
この項の内容は次のとおりです。
プロジェクト・ブラウザで「データ・インタフェース」ノードを右クリックし、「新規データ・インタフェース」を選択します。「データ・インタフェース」ダイアログが表示されます。
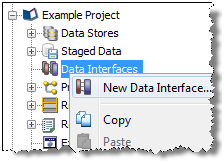
データ・インタフェースで必要な属性を追加するか、コピーした属性のリストを貼り付けます。
ステージング済データまたは参照データからデータ・インタフェースを作成するには、次のようにします。
プロジェクト・ブラウザでオブジェクトを右クリックし、「データ・インタフェース・マッピングの作成」を選択します。「新規データ・インタフェース・マッピング」ダイアログが表示されます。
「新規データ・インタフェース」をクリックして、ステージング済データまたは参照データの属性とデータ型を選択されたインタフェースを作成します。
プロジェクト・ブラウザでデータ・インタフェースを右クリックします。
「編集...」を選択します。「データ・インタフェース属性」ダイアログが表示されます。
必要に応じて属性を編集します。「終了」をクリックして保存するか、「取消」lをクリックして破棄します。
データをプロセスまたはジョブの内部または外部に「バインド」可能にするには、データ・インタフェースが必要です。
マッピングを作成するには、次のいずれかを行います。
データ・インタフェースを右クリックして、「マッピング」を選択して、「新規データ・インタフェース・マッピング」ダイアログの「+」ボタンをクリックして、新規マッピングウィザードを開始します。
ステージング済データまたは参照データ・セットを右クリックして、「データ・インタフェース・マッピングの作成」を選択して、「新規データ・インタフェース・マッピング」ダイアログで必要なデータ・インタフェースをクリックします。
|
注意: データ・ソースはそのタイプに応じて、入力データと出力データのいずれかとしてマップされます。
|
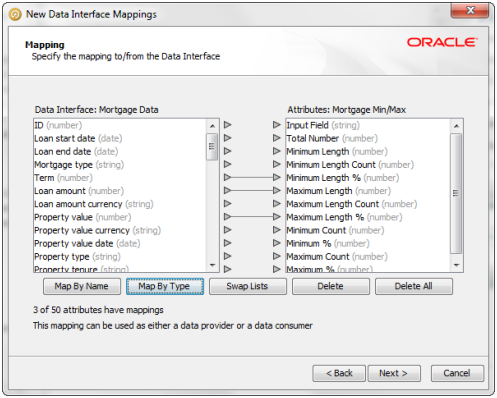
データ・インタフェース・マッピング・ウィザード
データ・ソースまたはデータ・ターゲットを選択すると、「新規データ・インタフェース・マッピング」ダイアログに「マッピング」領域が表示されます。
|
注意:
|
データ・インタフェースを右クリックして、「削除」を選択します。次のダイアログが表示されます。
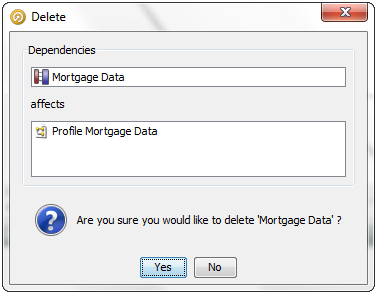
削除ダイアログには、削除の影響を受けるリンクされたオブジェクト、または依存オブジェクトがあれば表示されます。
「はい」をクリックして続行するか、「いいえ」をクリックして取り消します。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
データ・インタフェースを含むプロセスを、スタンドアロン・プロセスとしてか、ジョブの一部として実行する場合、ユーザーはデータ・インタフェースによってデータが読み取られるか書き込まれる方法を構成する必要があります。
|
注意: データ・インタフェースはプロセス内のリーダーまたはライターで使用されます。したがって、データ・インタフェースを実装する方法に依存して、構成中に使用できるマッピングは変化します。 |
データ・インタフェースを含むプロセスをジョブに追加すると、プロセスは次の例のように表示されます。
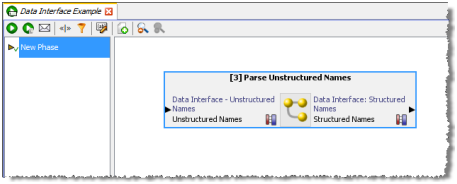
ジョブを実行するには、ジョブ内のどのデータ・インタフェースも構成する必要があります。
各データ・インタフェースを構成するには、次のようにします。
データ・インタフェースをダブルクリックします。「タスクの構成」ダイアログが表示されます。
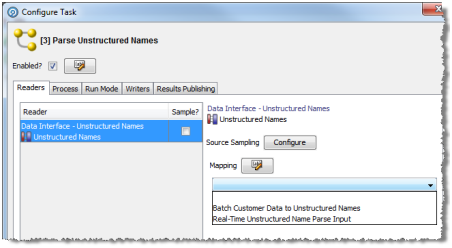
ドロップダウン・フィールドで必要なマッピングを選択します。
|
注意: 1つのライターにはマッピングを複数構成できますが(たとえば、2つの異なるステージング済データ・セットにデータを書き込む)、1つのリーダーには単一のマッピングのみ構成できます。 |
「OK」をクリックして保存するか、「取消」lをクリックして破棄します。
ジョブ内の各データ・インタフェースにデータ・インタフェース・マッピングを指定しておくと、マッピングおよびマッピングでバインドされるオブジェクトがジョブ内に表示されます。これで、ジョブを実行できるようになります。後述の「例 - 2つのデータ・インタフェースを含むジョブ」を参照してください。
データ・インタフェースを含むプロセスの一方をリーダーとして構成し、一方をライターとして構成すると、2つ以上のプロセスをリンクできます。
次の例のように両方のプロセスをジョブに追加します。
最初のプロセスから2番目のプロセスへのコネクタをクリックおよびドラッグします。プロセスがリンクします。
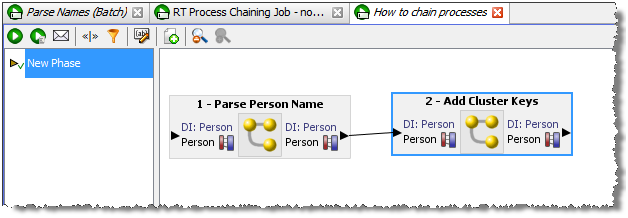
リアルタイム・ジョブ内でデータ・ストリームがEDQで扱われる方法が原因で、プロセスのチェーンを作成する方法には制限があります。
リクエストからレスポンスへのプロセス・チェーン内で1つのみのデータ・ストリームが維持される場合、EDQではレスポンスをリクエストにあわせて調整でき、リアルタイム・サービスは予想どおりに動作します。
しかし、データ・ストリームが分割され、次にプロセス・チェーンのさらに先でマージされると、EDQではレスポンスをリクエストにあわせて調整できなくなります。したがって、送信された最初のWebサービス・リクエストが原因で、ジョブは失敗します。生成されるエラーおよびログ・メッセージには、次のテキスト「"ws"パケットの送信に失敗しました: このリクエストに一致するレスポンスが見つかりませんでした」が含まれます。
このようなチェーンの例を次のスクリーンショットで示します。
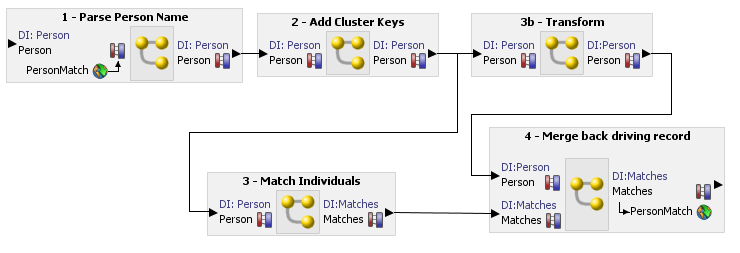
このジョブの例では、データ・インタフェースからの読取りとデータ・インタフェースへの書込みをどちらも行うプロセスが使用されます。ユーザーがマッピングを選択した結果、プロセスはリアルタイムで実行でき、さらにそのリアルタイム・レスポンスがステージング済データに記録されます。
最初にジョブを作成し、プロセスをキャンバスにドラッグします。

次に入力データ・インタフェースと出力データ・インタフェースをダブルクリックして、マッピングを選択します。
入力データ・インタフェースには、データ・インタフェースにマップされたWebサービス入力を選択します。
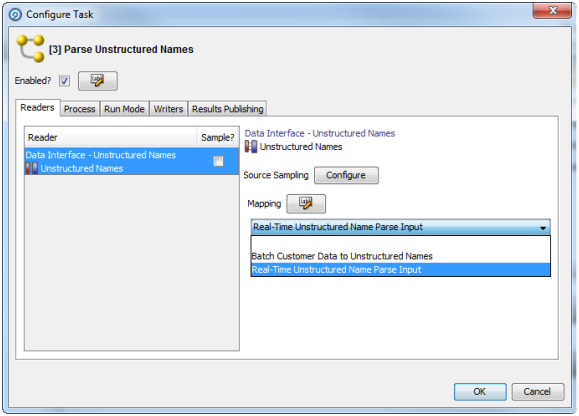
出力データ・インタフェースには、次のダイアログを使用して、「バッチ」(ステージング済データ)マッピングと「リアルタイム」(Webサービス出力)マッピングを両方とも選択します。
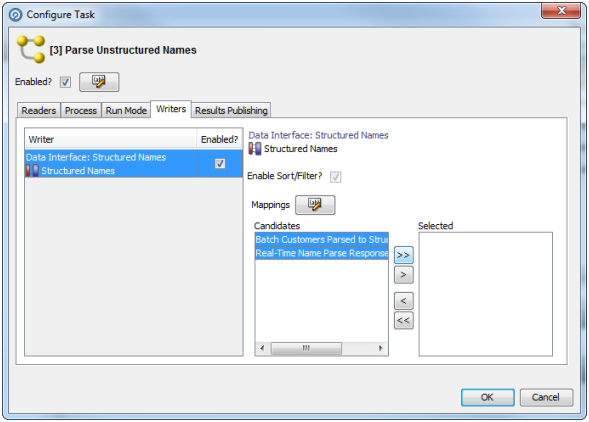
「OK」をクリックして保存します。ジョブが次のように表示され、実行またはスケジュールできます。
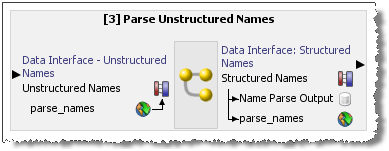
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
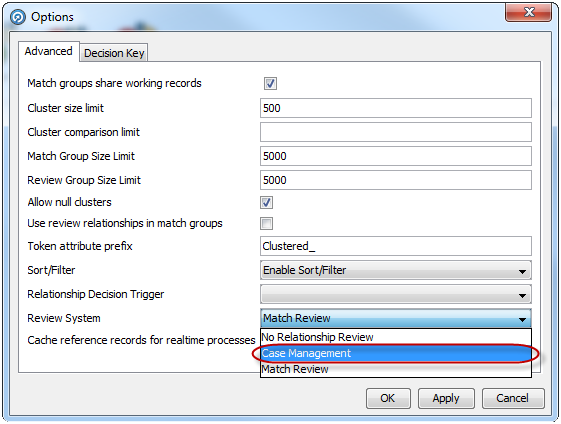
ケース管理は照合プロセッサの「拡張オプション」ダイアログで有効化されます。プロセッサのケース管理を有効化するには、プロセッサを開き、「拡張オプション」リンクをクリックします。

「拡張オプション」ダイアログで、「レビュー・システム」ドロップダウン・フィールドの「ケース管理」を選択します。
|
注意: ケース管理を選択すると、「一致グループでレビュー関係を使用」チェック・ボックスの選択が解除され、「決定キー」タブが「ケース・ソース」タブに置換されます。 |
ケース管理をこのプロセッサで使用できるようにするには、さらに構成が必要です。
「ケース・ソース」タブを使用して、プロセッサのケース・ソースを構成します。
入力データ・ストリームをケース・ソースで定義されたデータ・ソースにマップします。
これらのステップを完了すると、照合プロセッサに関連付けられた一致レビュー・リンクも無効化されます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlの「Enterprise Data Qualityの理解」およびEnterprise Data Qualityオンライン・ヘルプを参照してください
EDQは3つの主要なタイプのプロセス実行をサポートするように設計されています。
しかし、プロセスを想定された実行モードに依存せずに設計し、タイプ間で容易に切り替える自由を保持するために、実行オプションはプロセスまたはジョブ・レベルで構成されます。
プロセスから必要な結果が生成されるかどうかをテストするには通常はデータのセットが必要なので、プロセスは通常の場合、たとえ最終的にはリアルタイム・プロセスとしてデプロイされるとしても、最初はバッチ・プロセスとして設計されます。
バッチ・プロセスには次の特性があります。
データをステージング済データ構成(スナップショットなど)から読み取ります。
リアルタイム・レスポンス・プロセスには適していない重複チェックを含め、プロセッサ・ライブラリにあるどのプロセッサも含めることができます。
結果は書き込まれないか、ステージング済データ表、または外部データベースやファイル(あるいはその両方)に書き込まれます。
標準モードで実行されます。つまり、バッチが完全に処理されたとき、プロセスが完了します。
リアルタイム・レスポンス・プロセスは、データ入力の時点でデータ品質を保護するために対話式サービスとして呼び出されるように設計されます。リアルタイム・レスポンス・プロセスは、データのチェック、クリーニングおよび照合を含め、実質的にどのデータ品質処理も実行できます。プロファイリングはリアルタイム・レスポンス・プロセスでは通常は使用されません。
リアルタイム・レスポンス・プロセスには次の特性があります。
リアルタイム・プロバイダ(Webサービスのインバウンド・インタフェースなど)からデータを読み取ります。
|
注意: リアルタイム・レスポンス・プロセスにはステージング済データ構成(スナップショットなど)に接続したリーダーを含めることもできます。たとえばリアルタイム参照照合時で、この場合はリクエストを処理する前にプロセスを準備モードで実行する必要があります。 |
リアルタイム・コンシューマ(Webサービスのアウトバウンド・インタフェースなど)にデータを書き込みます。
|
注意: リアルタイム・レスポンス・プロセスには、ステージング済データ構成に接続したライターを含め、たとえば、処理されたすべてのレコードとそのレスポンスの完全な監査証跡を書き込むこともできます。いずれの間隔設定にもかかわらず、プロセスが停止するまで、これらのライターからは何の結果も書き込まれません。 |
多くは標準モードで実行され、結果は書き出されませんが、間隔モードで実行できるので、プロセスが連続実行中に結果を書き出すことができます。
重複チェックなど、リアルタイム・レスポンス処理に適していないプロセッサを含めないでください。
|
注意: リアルタイム・レスポンス処理に適さないプロセッサがリアルタイム・プロセスに含まれる場合、メッセージの最初のレコードを受信したときに例外が発生します。各プロセッサのサポートされる実行タイプは、プロセッサのヘルプ・ページにリストされています。 |
リアルタイム・レスポンス・プロセスではバッチ・プロセスと同じロジックの多くまたはすべてを使用できます。
リアルタイム・レスポンス・プロセスは、データ入力の時点でデータ品質をチェックするように設計されますが、呼出し元アプリケーションにレスポンスを返さないので、ソース・システムでデータを変更するユーザーに余計な負荷がかかりません。レスポンスを返す必要がないので、EDQプロセスが可能な動作に対する制限は少なくなります。たとえば、モニタリング・プロセスが実行される期間にすべてのレコードに対して動作するプロファイリング・プロセッサを含めることができます。
リアルタイム・モニタリング・プロセスには次の特性があります。
リアルタイム・プロバイダ(Webサービスのインバウンド・インタフェースなど)からデータを読み取ります。
リアルタイム・レスポンス・プロセスには適していない重複チェックを含め、プロセッサ・ライブラリにあるどのプロセッサも含めることができます。
|
注意: バッチ全体を処理するように設計されたため、リアルタイム・レスポンス・プロセスに適さないプロセッサがリアルタイム・モニタリング・プロセスに含まれる場合、そのプロセスを間隔モードでなく標準モードで実行してください。各プロセッサのサポートされる実行タイプは、プロセッサのヘルプ・ページにリストされています。 |
結果は書き込まれないか、ステージング済データ表、または外部データベースやファイル(あるいはその両方)に書き込まれます。
プロセスが停止するか、構成された時間またはレコードしきい値に到達すると、プロセスは完了します。
標準モード(制限された期間、または制限されたレコード数を処理)または間隔モードのいずれかで実行できます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください
EDQでは、すべてのプロセッサ・インスタンスのアイコンをカスタマイズできます。これは、特殊な目的を持つ可能性のある構成済プロセッサを、基礎となる汎用プロセッサと区別するための1つの方法です。たとえば、「ルックアップ・チェック」プロセッサで特定の購入済または無料で使用可能な参照データ・セットとデータをチェックする場合、プロセス内でその参照データをグラフィカルに示すと便利です。
プロセッサ・アイコンのカスタマイズも、新しいプロセッサの作成および公開時に便利です。プロセッサが公開されている場合、ツール・パレットからプロセッサを使用する際、そのカスタマイズ済アイコンがデフォルトのアイコンになります。
プロセッサ・アイコンをカスタマイズする手順は、次のとおりです。
キャンバスでプロセッサをダブルクリックします
「アイコンとファミリ」タブを選択します
プロセッサ・アイコン(イメージの右上に表示される)を変更するには、画面の左側を使用します。
ファミリ・アイコンを変更するには画面の右側を使用します(プロセッサを公開すると、これが選択したグループに公開されます。あるいは、存在していない場合は新しいファミリが作成されます)
プロセッサ・アイコンとファミリ・アイコンどちらの場合も、ダイアログが開いてサーバーのイメージ・ライブラリが表示されます。既存のイメージを選択するか、新しいイメージを作成できます。
新しいイメージを追加する場合は、ダイアログが表示され、イメージの参照(またはドラッグ・アンド・ドロップ)、サイズ変更、名前や説明(オプション)の入力を行うことができます。
サーバー上でイメージが作成されるとサーバーのイメージ・ライブラリに追加され、アイコンをカスタマイズする際にいつでも使用できるようになります。サーバー上のイメージ・ライブラリにアクセスするには、プロジェクト・ブラウザでサーバーを右クリックして「イメージ...」を選択します。
詳細は、Enterprise Data Qualityオンライン・ヘルプを参照してください。
ケース管理およびケース管理の管理アプリケーションは、デフォルトではEDQ Launchpadに公開されます。しかし、存在しない場合は、Launchpadに追加し、ユーザー・グループを割り当てる必要があります。
詳細は、Enterprise Data Qualityオンライン・ヘルプLaunchpad構成とアプリケーション権限に関する項を参照してください。
EDQではプロセッサの最上位レベルの結果ビューをステージング済データに公開(または「書込み」)できます。
|
注意: ここでの「最上位」とは、結果の最初のサマリー・ビューという意味です。最上位結果ビューをドリルダウンしてアクセスする中間結果ビューは公開できません。データ・ビューもこの方法では公開できません。プロセス内のデータはライターを使用して書き込まれます。 |
結果ビューをステージング済データに公開することには、3つの目的があります。
結果ビューをターゲット・データ・ストアにエクスポート
結果ビューを後続処理(たとえばルックアップ)に使用
サーバー・コンソールUIのユーザーが選択したプロセス結果を表示するのを許可
公開された結果ビューは、プロセス実行時にステージング済データに書き込まれます。
結果ビューがステージング済データに書き込まれるように設定するには、次のようにします。
キャンバスでプロセッサを選択し、プロセッサの結果を結果ブラウザで表示します。
 をクリックして、結果ビューをステージング済データに公開します。すると、結果の公開ダイアログが表示されます。
をクリックして、結果ビューをステージング済データに公開します。すると、結果の公開ダイアログが表示されます。
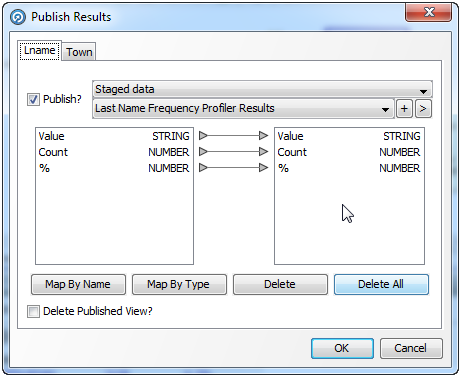
このダイアログを使用して、次のことができます。
書込み先にするステージング済データ・セットの名前を指定または変更
ステージング済データ・セットの属性を変更して、左側に表示された一般的な結果ビューの名前と異なる属性の名前を使用
書き出さない属性が結果ビューにある場合、属性をステージング済データ・セットから削除
構成を失わずに結果ビューの公開のオンまたはオフを切替え
前述の頻度プロファイラの例が示すように、プロセッサから複数の最上位レベル結果ビューが出力される場合、結果の公開ダイアログには各ビューに1つずつ、複数のタブが表示されます。いずれかまたはすべてのプロセッサ・ビューの公開を選択できます。
1つ以上の結果ビューをステージング済データに書き込むように構成された、公開が現在有効であるプロセス内のプロセッサは、次に示すように、キャンバスのオーバーレイ・アイコンを使用して示されます。
|
注意: 結果ビューの書込み先であるステージング済データ・セットが削除または名前変更されると、インジケータは赤色になり、エラーが示されます。これは、プロセッサの構成がエラー、つまりプロセッサが実行できない場合と同じように扱われます。 |
ステージング済結果ビューとサーバー・コンソールUI
デフォルトでは、サーバー・コンソールUI (またはコマンドライン・インタフェースからrunopsjobコマンドを使用)でジョブの実行中にスナップショットまたはステージングされるすべてのデータは、適切な権限を持つユーザーがサーバー・コンソールの結果ブラウザで表示できます。これには、ジョブで実行されるプロセスでステージングすることを選択したどの結果ビューも含まれます。
ただし、実行プロファイルのオーバーライド設定を使用して、サーバー・コンソールUIで特定のステージング済データ・セットが表示されるかどうかをオーバーライドできます。
詳細は、http://docs.oracle.com/middleware/12212/edq/index.htmlのEnterprise Data Qualityオンライン・ヘルプを参照してください