| Oracle® Fusion Middleware Oracle Enterprise Data Qualityの使用 12c (12.2.1.2.0) E88274-01 |
|

 前 |
 次 |
この章では、ディレクタを使用するときに実行する基本的な操作に関する情報を説明します。
この章の内容は、次のとおりです。
スナップショットからのデータを分析するプロセスを追加するには、次のようにします。
メニューから「ファイル - 新規プロセス」を選択するか、
プロジェクト・ブラウザで「プロセス」を右クリックし、「新規プロセス」を選択します。
プロセスで使用するステージング済データ、データ・インタフェースまたはリアルタイム・データ・プロバイダを選択するか、後でプロセスでリーダーを構成する場合は何も選択しません。
|
注意: 分析しているデータをステージングしない、つまりデータをソースから直接ストリームしたい場合もあります。これを行うには、「ステージング済データ」構成を選択し、プロセスのプロセス実行プリファレンスを変更します。 |
プロセスにプロファイリング・プロセッサを直接追加するかどうかを選択します。データを初めて分析している場合はこれが有用なことがあります。
プロセスの「名前」とオプションの「説明」を指定します。
「終了」をクリックします。
接続したデータ・ストアからデータのスナップショットを追加するには、次のようにします。
プロジェクト・ブラウザで「ステージング済データ」を右クリックし、「新規スナップショット」を選択します。
スナップショットの作成元にするデータ・ストアを選択するか、希望するデータ・ストアがリストにない場合は、新規データ・ストアを追加します。
スナップショットする表またはビューを選択します(または、データの新規ビューをスナップショットするSQLを指定できます)。
表またはビューからスナップショットに含める列、およびスナップショットに対するソートとフィルタリングを有効化する方法を選択します。
デフォルトでは、インテリジェント・ソートおよびフィルタの有効化が使用されます。つまり、スナップショットが特定サイズ(システム管理者が設定)未満の場合、いずれかの列を使用してスナップショットに基づく結果をソートおよびフィルタリングできます。スナップショットがそのサイズより大きい場合、スナップショットに基づく結果はどの列順でもソートまたはフィルタリングできませんが、ユーザーが結果ブラウザを使用してこれを行おうとすると、特定の列に対してソートとフィルタリングを有効化するように求められます。
または、インテリジェント・ソートおよびフィルタの有効化をオフに切り替え、ソートとフィルタを有効化する列を手動で選択できます。
インテリジェント・ソートとフィルタの有効化を使用する場合に、超過するとスナップショットのソートとフィルタリングが無効になるデフォルトしきい値は1000万セルです。このため、たとえば50万行と15列のスナップショット(750万セル)ではソートとフィルタリングが有効化されますが、50万行と25列のスナップショット(1250万セル)ではソートとフィルタリングが無効化されます。
|
注意: すべての列を選択することをお薦めします。指定したプロセスで使用する列は、これらのサブセットにできます。 |
オプションで、表またはビューをフィルタして、そのサブセットをスナップショットします(または独自のSQL WHERE句を記述できます)。
オプションで、選択したデータをサンプリングします(たとえば、最初のnレコード、オフセット後の最初のnレコード、100レコードごとに1レコードなど)。
オプションで、データなし正規化を実行します。詳細は、Enterprise Data Qualityオンライン・ヘルプのデータなし処理に関する項を参照してください。
スナップショットに「名前」を付け、ただちに実行するかどうかを選択します。
「終了」をクリックして、スナップショットの追加を確定します。
スナップショットが作成され、プロジェクト・ブラウザに表示されます。即座に実行(右クリックして「"スナップショット"の実行」)、またはプロセスで使用して後で実行できます。スナップショットの「ストリーム」もできます。つまり、処理するレコードをデータ・ストアから直接、つまりリポジトリにコピーせずに選択する方法としても使用できます。
次のステップは、たとえばスナップショット内のデータをプロファイリングするプロセスの追加です。
データの検証または変換のためにプロセッサで使用する参照データのセットを追加するには、次のようにします。
プロジェクト・ブラウザで「参照データ」を右クリックし、「新規参照データ」を選択します。
参照データをステージング済データまたは外部データへのルックアップにするか、データの新規セットでなく既存の参照データ・セットへの代替ルックアップにするには、「新規ルックアップ...」を選択します。
または、結果ブラウザでデータを使用して参照データを作成するために、なんらかのデータ値を選択し、右クリックして「参照データの作成」を選択します。たとえば、頻度プロファイラの結果から、結果タブを選択します。使用する値を選択し、右クリックして「参照データの作成」を選択します。
|
注意: 通常のWindowsのShift選択オプションおよびControl選択オプションを使用して、データを選択できます。使用する値を選択しようとするとき、ドリルダウンしないように注意してください。または、結果ブラウザで指定した列に対するロードされたデータをすべて選択するために、上部で列をControl選択します(たとえば、上のスクリーンショットでの「値」列)。Escapeを押すと、選択したデータの選択がすべて解除されます。 |
新規参照データ(既存参照データへの新規ルックアップではなく)を追加する場合、参照データで必要な列を定義します。たとえば、値の単純なリストについては、単一の列を定義します。参照データ・エディタで一意制約を追加し、重複エントリを作成できないようにするには、列で「一意」オプションを選択します。
データのルックアップを実行するときに使用する列を1つまたは複数選択します。
ルックアップから値を返すときに使用する列を1つまたは複数選択します。
オプションで、特定のタイプ(正規表現のリストなど)の参照データを作成している場合、作成する参照データのカテゴリを選択します。
参照データに「名前」(たとえば「有効な敬称」)、およびオプションの「説明」(たとえば「顧客表から作成」)を指定し、データを今編集するかどうかを選択します。
データを今編集するように選択する場合、参照データ・エディタを使用して参照データのエントリを追加または削除します。
「OK」をクリックして終了します。
プロジェクト・ブラウザでプロジェクトの下に参照データ・セットが表示され、プロセッサ、たとえばリスト・チェックで使用できます。
結果に基づいて問題を追加(たとえば、関心があるアイテムのタグ付けや、フォローアップする別ユーザーのアクションの作成)するには、次のようにします。
結果ブラウザでデータを右クリックし、「問題の作成...」を選択します。
|
注意: 問題は作成された場所である特定のプロセスとプロセッサにリンクされるので、別ユーザーが関連データを素早く検索できます。 |
問題の「説明」を追加します。
オプションで、問題を自分または別ユーザーに割り当て、必要な「アクション」(ある場合)を指定します。
「保存」をクリックして問題を保存します。
問題が追加され、問題マネージャから使用可能です。問題が別ユーザーに割り当てられた場合、そのユーザーがログオンすると、ただちに未解決の問題について通知されます。
プロジェクト計画を添付、またプロジェクト・ユーザーの間でなんらかの主要な情報を共有するためにノートをプロジェクトに追加するには、次のようにします。
プロジェクト・ブラウザで「ノート」を右クリックし、「新規ノート」を選択します。
ノートに「タイトル」を指定します。
詳細をノートに追加します(または、必要なのがタイトルと1つ以上の添付ファイルのみの場合は、空白のままにします)。
ファイル・システムを参照して、添付ファイルをノートに追加します(または示された領域にファイルをドラッグ・アンド・ドロップします)。
「保存」をクリックします。
ノートが作成され、プロジェクト・ブラウザに表示されます。
EDQにはデータを処理するためのプロセッサのライブラリが備わっています。
プロセッサをプロセスに追加するには、次のようにします。
プロセスがキャンバス上で開いていることを確認します。
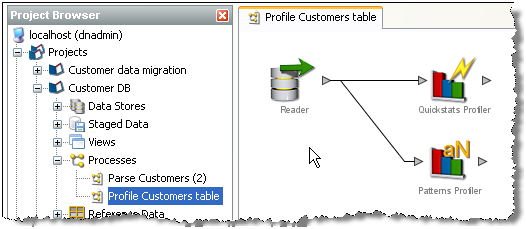
リーダーをダブルクリックして、ステージング済データ(スナップショットなど)、ビューまたはリアルタイム・データ・プロバイダからデータを読み込むように構成します。
読み込むデータ、およびプロセスに関連するデータの属性を選択します。
プロセッサをクリックしてキャンバスにドラッグして、プロセッサをツール・パレットに追加します。
矢印を結合して、プロセッサをリーダーからのデータに接続します。
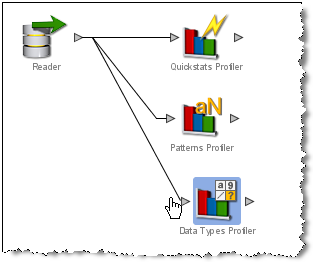
プロセッサの入力属性を選択して、プロセッサを構成します。
青い矢印アイコンは、最新バージョンの属性が入力として使用されることを意味します。変換プロセッサが使用された場合、このことは特に重要です。
|
注意:
|
使用するプロセッサのセットを接続したら、ツールバーの高速実行プロセス・ボタンをクリックして、プロセスを実行し、結果を確認します。
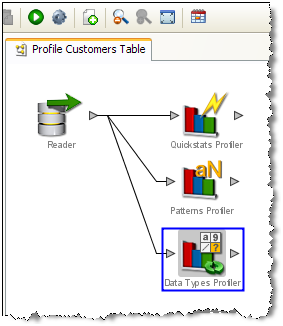
キャンバスの背景が青色に変化し、プロセスが実行中であることが示されます。(また、プロジェクト・ブラウザのプロセス・アイコンが緑色になり、同じホストに接続した他のユーザーが、そのプロセスが実行中であることを確認できます。)。
|
注意: プロセスはロックされ、実行中には編集できません。 |
プロセスが終了したら、シェードした背景では表示されなくなり、キャンバスでプロセッサをクリックし、プロセッサの結果を結果ブラウザで表示して、各プロセッサの結果を参照できます。
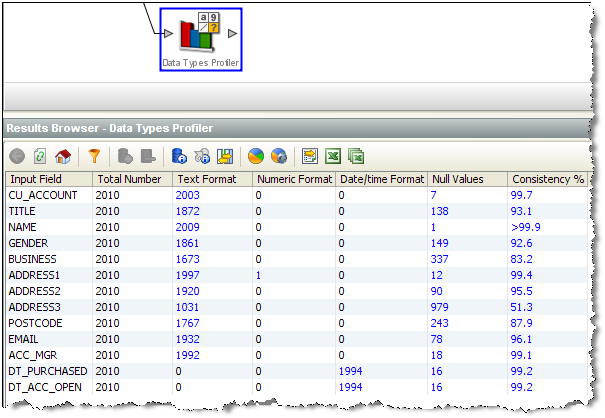
メトリックをドリルダウンし、メトリックに関連するデータを表示します。
プロセスの作成に成功したら、データの検証と変換のための参照データの作成を開始できるようになります。
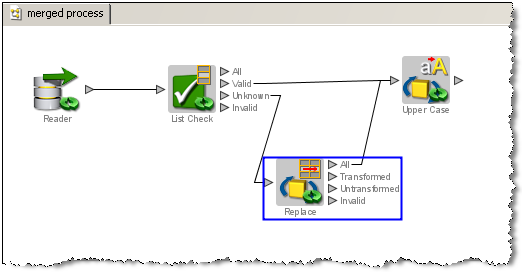
プロセッサの入力属性を選択するとき、一部の属性ではあいまいな最新バージョンが存在する可能性があります。属性が2つの異なるパスに存在し、片方または両方のパスで変換された場合は、必ずこのような状態になります。この場合、最上位レベルの属性(または最新バージョン)がグレー表示され、選択不可能になります。この場合、属性を展開し、可能性があるすべてのバージョンを表示して、使用する属性の特定バージョンを選択する必要があります。
たとえば、次の大文字プロセッサが2つの異なるプロセッサによる2つの入力パスを使用して構成されたとします。置換プロセッサによってtitle属性が変換されます。
大文字プロセッサの構成は次のように表示され、title属性の最新バージョンがグレー表示されて、このバージョンがあいまいなので使用できないことが示されます。この場合、title属性の下にリストされた特定の属性の1つを選択する必要があります。
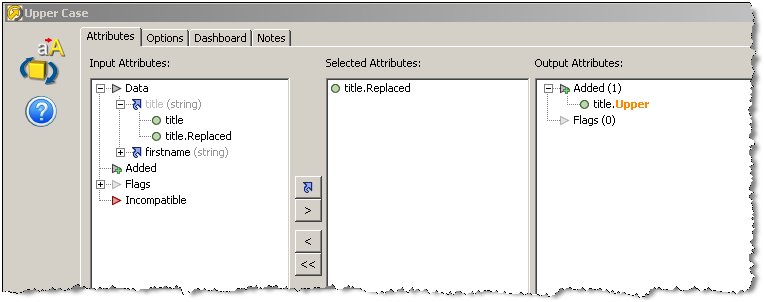
属性マージ・プロセッサは個別の処理パスを結合するために使用することが多いので、属性マージ・プロセッサを構成中にこのシナリオが普通に発生します。
固定幅テキスト・ファイルに接続する新規データ・ストアを定義するとき、新規データ・ストア・ウィザードから、ファイルのデータ・フィールドの名前とサイズを定義するように求められます。
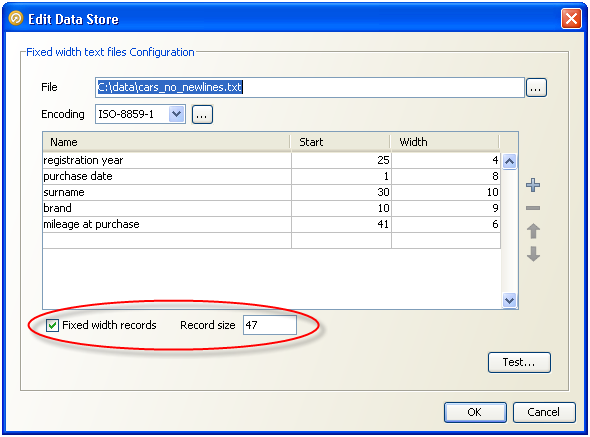
固定幅テキスト・ファイルのデータは行と列に配置され、1行当たり1エントリです。文字数で指定される各列の固定幅から、列に含めることができるデータの最大量が決定されます。ファイルのフィールドを区切るためのデリミタは使用されません。かわりに、データ量が少ない場合は空白を使用して割当てスペースを埋め、指定の列の先頭を常に行頭からのオフセットとして指定できるようにします。次のファイル・スニペットでは、多くのフラットなファイルに共通の特性を示します。車とその所有者に関する情報が含まれますが、ファイルの列に見出しがなく、データの意味に関する情報がありません。さらに、データは読みやすくするために各列の間に1文字分の空白を付加してレイアウトされています。
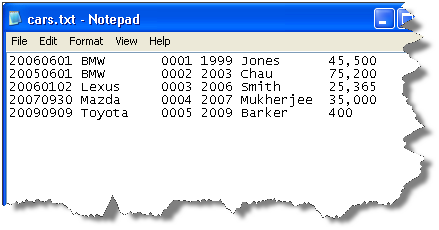
固定幅テキスト・ファイルのデータを正しく解析するために、そのファイルの暗黙的な列サイズをEDQに通知する必要があります。これは新規データ・ストア・ウィザードで行われ、必要に応じて後でデータ・ストア設定の一部として編集できます。
固定幅テキスト・ファイルのデータ・ストア構成画面を初めて表示するときの列の表は空です。次のスクリーンショットでは、サンプル・ファイルの数列にマッピング情報を移入してあります。
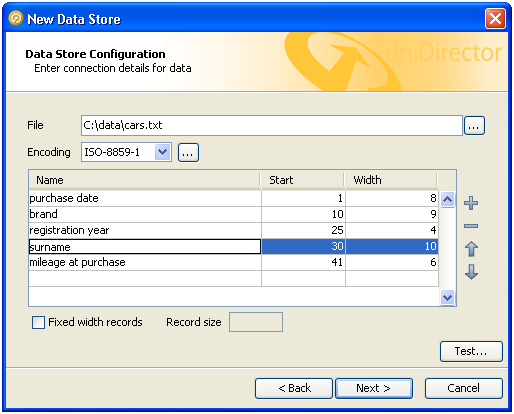
各列はその開始位置と幅の文字数によってEDQに向けて記述されます。各列には名前も割り当てられ、データ・スナップショットやダウンストリーム処理でデータを識別できるように使用されます。名前はデータ・ストアが定義されるときにユーザーが定義するものであり、ダウンストリームで最も使用しやすくするために説明的な内容にしてください。
データ列の位置は開始点と幅で定義されます。行の先頭文字は位置がゼロではなく1であることにも注意してください。各列の幅と開始点を提供すると、EDQではある列が次の列の先頭まで続くと想定されないので、結果は次のようになります。
列の間の単一スペースなど、読みやすくするためにファイルに含まれたいずれのスペースも、自動的に無視できます。
ファイルのすべての列にマッピングを定義する必要はありません。必要でない列が存在する場合、データ・ストア構成の列定義から簡単に省略できます。たとえば、ファイルの3番目の列はマッピングに含めませんでしたが、前後の列の境界が厳格に定義されているので、データ・セットに余分なデータは含まれません。
列をファイル内と同じ順序で指定する必要はありません。ここで指定した列は、データ・ソースから作成されるどのスナップショットにも反映されます。
列の表の右側にあるボタンを使用して、レコードを追加または削除、また選択したレコードをリスト内の上下に移動できます。
データのセットを処理するために新規データ・ストアに接続するには、次のようにします。
プロジェクト・ブラウザでプロジェクト内部の「データ・ストア」を右クリックし、「新規データ・ストア」を選択します。
接続先にするカテゴリ、つまり「データベース」、「テキスト・ファイル」、「XMLファイル」、「MS Officeファイル」、または「その他」(JDBCまたはODBCを使用して接続の詳細を指定する場合)を選択します。
データにどこからアクセスするかを、サーバーまたはクライアントから選択します。
接続先にするデータ・ストアのタイプを選択します(たとえば、データベースの場合は、Oracle、SQL Server、MS Accessなど、データベースのタイプ)。
データへの接続の詳細を指定します。たとえば、次のようになります。
クライアント側アクセス・データベースの場合、ローカルなファイル・システムの.mdbファイルを参照します。
クライアント側テキスト・ファイルの場合、ローカルなファイル・システムのテキスト・ファイルを含むディレクトリを参照します。固定幅 テキスト・ファイルの場合、ファイルに存在するフィールドも定義する必要があります。
サーバー側ファイル(Access、テキスト、ExcelまたはXML)の場合、ファイルの名前をサーバー・ランディング領域に存在する(または存在するようになる)形で、ファイルの接尾辞を含めて入力します。プロジェクト固有のランディング領域を使用して、異なるプロジェクトのデータを強制的に孤立させることができます。管理者はこの機能を使用する必要があるプロジェクトのランディング領域を設定することが必要になります。再び、固定幅テキスト・ファイルの場合、ファイルに存在するフィールドも定義する必要があります。
データベースの場合、「データベース・ホスト」、「ポート番号」(デフォルト・ポート番号を使用しない場合)、「データベース名」、「ユーザー名」、「パスワード」および「スキーマ」(ユーザーのデフォルト・スキーマと異なる場合)を指定します。
JNDI接続を介してアクセスするデータベースの場合、「JNDI名」を指定します。
ODBCブリッジ・コネクタを介してアクセスできる他のいずれかのタイプのデータの場合、ODBC DSN、「JDBC URL」、「ユーザー名」および「パスワード」を指定します。
JDBCを介してアクセスできる「その他」のタイプのデータの場合、「ドライバ・クラス名」、「JDBC URL」、「ユーザー名」および「パスワード」を指定します。
新規データ・ストアへの接続をチェックするには、「テスト」ボタンを使用します。まだ存在しないファイルへの接続詳細を指定できます(EDQにおけるエクスポート・タスクによって作成されるファイルなど)。
|
注意: 非ネイティブ・タイプのデータ・ソースを接続するには、JDBC接続の知識がある程度必要です。 |
データ・ストアに「名前」を指定し、「終了」をクリックします。
新規データ・ストアが構成され、プロジェクト・ブラウザに表示されます。
または、データ・ストアをプロジェクト間で共有する場合、前述と同じ方法でシステム・レベル(特定のプロジェクトの外側)で作成できます。
次のステップでは、データ・ストアからのデータのスナップショットを追加します。
1つ以上の特定のデータのセットに対して作業するためのプロジェクトを作成するには、次のようにします。
メニューから「ファイル - 新規プロジェクト」を選択するか、
プロジェクト・ブラウザで「プロジェクト」を右クリックし、「新規プロジェクト」を選択します。
ウィザードのステップに従い、プロジェクトに「名前」とオプションの「説明」を指定します。
新規プロジェクトに必要なユーザー権限を割り当てます。デフォルトでは、すべてのユーザー・グループがプロジェクトにアクセスできます。
新規プロジェクトが作成され、プロジェクト・ブラウザに表示されます。
プロジェクトにノートを追加し、プロジェクト・ユーザー間で共有できます。詳細は、「プロジェクト・ノートの追加」を参照してください。
そうでない場合は、次のステップは「データ・ストアへの接続」です。
準備済エクスポートには、ステージング済データからのデータ、および結果ブックからのデータという、2つのデータ・ソースがあります。
|
注意: 結果ブラウザから直接Excelへの非定型エクスポートも作成できます。 |
ライター・プロセッサを使用してステージング済データ表を作成したら、これをデータ・ストアに書き込むエクスポートを作成できます。その後、エクスポートを手動で実行、またはステージング済データ表を生成するプロセスが実行されるときに実行できます。
ステージング済データ表のエクスポートを設定するには、次のようにします。
プロジェクト・ブラウザで「エクスポート」を右クリックし、「新規エクスポート...」を選択します。
必要なステージング済データ表を選択します。
必要なデータ・ストアを選択します。
データ・ストアの表がエクスポート中に作成されない場合、データ・ストアで必要な表を選択します。
|
注意: デフォルトではこの表の内容が上書きされます。詳細は、後述の「エクスポート・オプション」を参照してください。 |
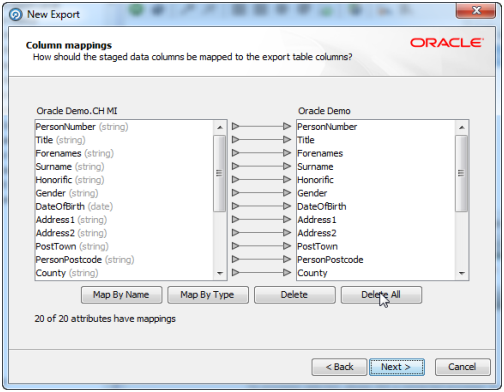
必要に応じて、ステージング済データ表の列をターゲット表の列にマップします。
|
注意: 「自動」ボタンをクリックすると、列が表示順に自動的にマップされます。 |
マッピングが完了したら、「次」をクリックして、(必要に応じて)エクスポートのデフォルト「名前」を変更します(デフォルト名はステージング済データ表とデータ・ストアの名前から構成されます)。
エクスポートをただちに実行するか、後で(たとえば、ジョブまたはプロセスのスケジュール済実行の一部として)実行するために構成を保存します。
エクスポート・タスクによって、エクスポートされるデータのソースと形、およびエクスポートのターゲット(出力テキスト・ファイル、データのマップ先であるデータベースに既存の表、またはデータベースの新規表など)が定義されます。
ユーザーはエクスポート・タスクをジョブに追加するときに、エクスポートの動作方法を選択します。
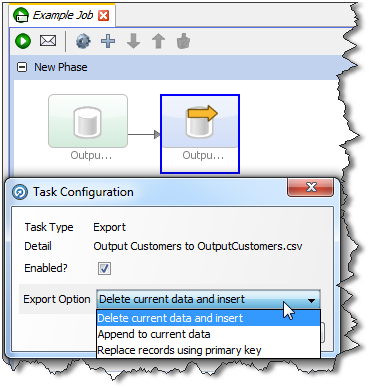
オプションは次のとおりです。
現在のデータおよび挿入の削除(デフォルト): ターゲットの表またはファイルにある現在のデータすべてがEDQにより削除され、適用範囲内データがエクスポートに挿入されます。たとえば、外部データベースに書き込んでいる場合は、表を切り捨ててデータを挿入します。または、ファイルに書き込んでいる場合は、ファイルを再作成します。
現在のデータに追加: ターゲットの表またはファイルのデータが削除されずに、適用範囲内データがエクスポートに追加されます。UTF-16ファイルに追加する場合は、バイト順序マーカーが新しいデータの先頭に書き込まれないように、UTF-16LEまたはUTF-16-BE文字セットを使用してください。
主キーを使用してレコードを置換します: エクスポートの適用範囲データにも存在するレコード(主キーの照合によって判別)がすべてターゲット表から削除され、次に適用範囲内データが挿入されます。
|
注意:
|
結果ブックも手動で、またはスケジュール済ジョブの一部として、データ・ストアにエクスポートできます。
|
注意: 結果ブックのエクスポートでは、常に「現在のデータおよび挿入の削除」操作が実行されます。 |
結果ブックのエクスポートを設定するには、次のようにします。
プロジェクト・ブラウザで「エクスポート」を右クリックし、「新しい結果ブックのエクスポート...」を選択します。
結果ブックを選択します。
エクスポートする結果ページ、およびエクスポートする行数を選択します。値を入力しないと、すべてのレコードがエクスポートされます。
エクスポート先のデータ・ストアを選択します。
|
注意: データベースに書き込む場合、結果ブックのエクスポートでは常に「現在のデータおよび挿入の削除」操作が行われるので、表が存在しない場合は作成され(結果ページの名前に相当)、同名の表がある場合は上書きされます。 |
「準備済エクスポートの実行」も参照してください。
ステージング済データ表または結果ブックの準備済エクスポートを実行する方法は2通りあります。
エクスポートを手動で実行
エクスポートをジョブの一部として実行
プロジェクト・ブラウザの名前付きエクスポート構成を右クリックして、「実行」を選択します。
エクスポート・プロセスがただちに実行され、プロジェクト・ブラウザでその進行状況を監視できます。
|
注意: クライアント側のデータ・ストアにエクスポートする場合、エクスポートは手動で実行する必要があります。 |
サーバー側データ・ストアにエクスポートする場合、大きいジョブの一部としてエクスポートを実行でき、そのジョブを将来のなんらかの時点で実行するようにスケジュールできます。
プロジェクト・ブラウザで「ジョブ構成」を右クリックし、「新規ジョブ」を選択します。
「ジョブ構成」ダイアログが表示されます。ジョブのデフォルト名をわかりやすい名前に変更します。
ツール・パレットが変化し、ジョブで実行できるタスクのリストが表示されることに注意してください。
エクスポート・タスクをツール・パレットからドラッグ・アンド・ドロップし、ジョブに追加します。
ジョブには他のタスク、たとえばスナップショットの再実行、プロセスの実行および外部ジョブを含めることもできます。詳細は、Enterprise Data Qualityオンライン・ヘルプのジョブに関する項を参照してください。
選択する各エクスポート・タスクについて、エクスポートを実行する方法を定義します。その他のオプションを使用して、エクスポートを無効化できます。
「実行」をクリックして、ジョブをただちに実行するか、「スケジュール」をクリックして、ジョブを後の日時で実行するようにスケジュールします。