Policy Management provides High Availability (HA) to all Policy Management cluster configurations. Policy Management accomplishes HA by using two servers per cluster, an active server and a standby server. For georedundancy, a third, spare server provides additional backup support. Servers are continually monitored by the in-memory database. As shown in Figure 1, the active server processes network traffic and is accessible and connected to external devices, clients, gateways, and so forth. Only one server in a cluster can be the active server.
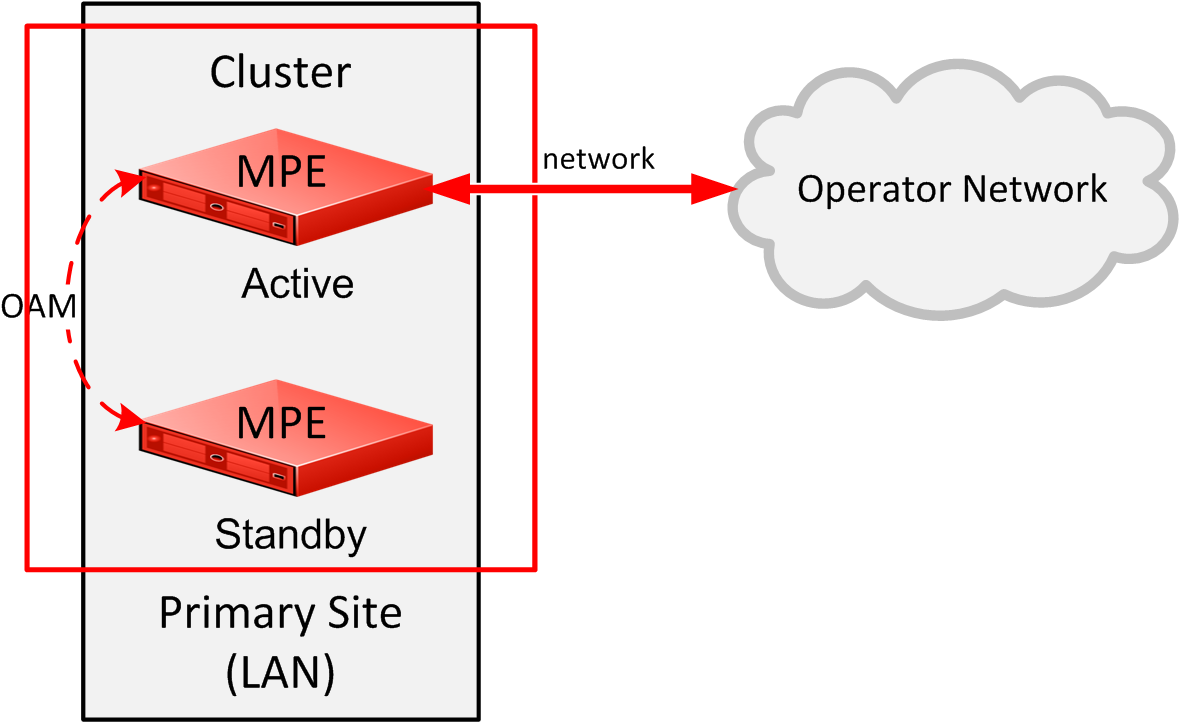
- The active and standby servers communicate using a TCP connection over the Operation, Administration, and Management (OAM) network to replicate current state data, monitor server heartbeats, and merge trace logs and alarms.Note: For georedundancy, a third, spare server is part of the cluster and receives replication data and heartbeats.
- The servers share a virtual IP (VIP) cluster address to support automatic failover. The active server controls the VIP address.
- The standby server does not receive any live traffic load, but holds an up-to-date copy of the active session state data at all times, replicated by High Availability. (This is sometimes called a warm standby.)
- The HA database runtime processes on each server constantly monitor server status using heartbeat signals.
- If the active server fails, indicated by missing a succession of three heartbeats:
- The standby server queries the active server. If the active server fails to respond, the standby server assumes the active state and takes over the VIP address and connections.
- Because it continually receives session state and data updates through replication, the standby server can assume processing of ongoing sessions, so the failover is automatic and transparent to other components.
The terms active and standby denote roles, or states, that the servers assume, and these roles can change based on decisions made by the underlying HA database, automatically and at any time. If necessary, the standby server assumes control and becomes the active server. (For example, this would occur if the active server became unresponsive as determined by lack of a heartbeat signal.) When this happens, the server that was previously the active server assumes the role of the standby server.
When the failed server recovers, it becomes the standby server, and current state data for the cluster is replicated to the server. This behavior is non-revertive; that is, if an active server fails and then recovers, it becomes the standby server, rather than resuming its role as the active server.