BDD supports many different cluster configurations, although most will contain nodes similar to the following.
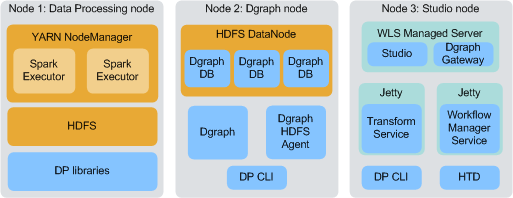
The diagram above depicts the three basic types of BDD nodes. Note that
it doesn't include nodes in your Hadoop cluster that BDD requires but doesn't
run on, like those running ZooKeeper and your Hadoop cluster manager.
- Node 1 is running BDD Data Processing libraries, along with the YARN NodeManager service, Spark on YARN, and HDFS, which DP requires to function. A typical production cluster would contain multiple Data Processing nodes. Oracle recommends at least three to maintain high availability.
- Node 2 is running the Dgraph, the Dgraph HDFS Agent, the DP CLI, and the Hadoop HDFS DataNode service, which is required because the Dgraph databases are stored on HDFS. (Note that the Dgraph databases could also be stored on an NFS (network file system), in which case HDFS would not be required on Dgraph nodes. For more information, see The Dgraph databases. ) A typical production cluster would contain multiple such nodes to ensure high availability of the Dgraph.
- Node 3 is running Studio and the Dgraph Gateway inside a WebLogic Managed Server; the Transform Service and Workflow Manager Service, each inside a Jetty container; the DP CLI; and the Hive Table Detector. A typical cluster would contain one or more Studio nodes, depending on the number of end users making concurrent queries. Note that in a cluster with multiple Studio nodes, the Workflow Manager Service and Hive Table Detector would each be installed on only one of them.
As previously mentioned, you aren't bound to the configurations described above. You can co-locate different BDD and Hadoop components on the same node, and your cluster can contain any number of each type of node. More information on cluster configuration and component co-location is available in the Installation Guide.
Furthermore, you can add and remove Dgraph and Data Processing nodes as needed post-install. For instructions, see Adding and Removing BDD Nodes. You can also add and remove non-BDD nodes from your Hadoop cluster without impacting BDD.
