| Oracle® TimesTen In-Memory Databaseオペレーション・ガイド リリース18.1 E98635-05 |
|


 前 |
 次 |
この章では、TimesTenデータベースの基本オブジェクトの詳細について説明し、SQLを使用してこれらのオブジェクトを管理する方法の簡単な例を示します。SQLの詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』を参照してください。
アプリケーション内からSQLを発行する方法の詳細は、適切なTimesTen開発者ガイドを参照してください。
この章の内容は次のとおりです。
次の項では、TimesTenデータベースの主要なオブジェクトおよび特徴について説明します。
TimesTenデータベースには、次の永続オブジェクトがあります。
表: TimesTenデータベースの主要オブジェクトは、アプリケーション・データを含む表です。詳細は、「表の理解」を参照してください。
マテリアライズド・ビュー: 1つ以上の通常のTimesTen表から選択したデータのサマリーを保持する読取り専用表です。詳細は、「マテリアライズド・ビューの理解」を参照してください。
ビュー: 1つ以上のディテール表と呼ばれる表に基づいた論理表です。ビュー自体にデータは含まれていません。詳細は、「ビューの理解」を参照してください。
索引: 索引は、表に速くアクセスできるように、表の1つ以上の列に対して作成します。詳細は、「索引の理解」を参照してください。
行: 各表は0以上の行で構成されます。行とは、成形された値のリストです。詳細は、「行の理解」を参照してください。
シノニム: データベース・オブジェクトの別名。シノニムは、オブジェクトの名前や所有者を隠すために使用できるため、セキュリティや利便性を目的として頻繁に使用されます。詳細は、「シノニムの理解」を参照してください。
システム表およびシステム・ビューシステム表およびシステム・ビューには、すべての表に関する表などのTimesTenメタデータが含まれます。詳細は、「システム表」および「システム・ビューの理解」を参照してください。
また、準備済のコマンド、カーソル、ロックなどの多くの一時オブジェクトもあります。
TimesTenは、パスワードでユーザー名を認証します。デフォルトではアプリケーションの実行に使用されるログイン名がデータベース内のオブジェクトの所有者になるため、アプリケーションでは、そのアプリケーション専用に1つのUIDを選択する必要があります。接続文字列でUID接続属性を省略すると、TimesTenでは現行のユーザーのログイン名を使用します。TimesTenでは、すべてのユーザー名が大文字に変換されます。SQL文を発行するときは常に、owner.table_nameなどのデータベース・オブジェクトの完全修飾名を使用してください。
ユーザーは、SYSユーザーとしてTimesTenデータベースにアクセスすることはできません。TimesTenは、UID接続属性の値または接続ユーザーのログイン名(UID接続属性の値が存在しない場合)でユーザー名を判別します。ユーザーのログイン名がSYSの場合は、ログイン名が上書きされるようにUID接続を設定します。
TimesTenの表は、共通の書式または構造を持つ行で構成されています。この書式は、表の列で定義します。
次の項では、表とその列およびこれらの管理方法について説明します。
この項の内容は次のとおりです。
表に列を作成する場合、列名の大文字と小文字は区別されます。
各列には、次の値が設定されています。
データ型
NULL値可能、主キーおよび外部キーのプロパティ(オプション)
オプションのデフォルト値
列は、NOT NULLと明示的に宣言しないかぎり、NULL値可能になります。表の列がNULL値可能の場合は、その列にNULL値を保存できます。NULL値可能でない場合は、表のその列の各行にNULL以外の値を設定する必要があります。
TimesTenの列の書式は変更できません。列の追加や削除は可能ですが、列の定義は変更できません。列を追加または削除するには、ALTER TABLE文を使用します。列の定義を変更するには、まずアプリケーションで表を削除し、新しい定義で再作成する必要があります。
表の行のインメモリー・レイアウトは、行への高速アクセスを可能にし、無駄な領域が最小限になるように設計されています。TimesTenでは、表のVARBINARY、NVARCHAR2およびVARCHAR2の各列がインラインまたはアウトラインのいずれかに指定されます。
インライン列は固定長です。表内のすべての固定長列の値は、行単位で保存されます。
(アウトライン列とも呼ばれる)非インライン列は可変長です。データ型がVARCHAR2、NVARCHAR2またはVARBINARYの列には、アウトラインで保存されるものがあります。アウトライン列は、行に近接して保存されるのではなく、行に割り当てられます。TimesTenではデフォルトで、宣言された列の長さが128バイトを超えるVARCHAR2、NVARCHAR2およびVARBINARYの列は、アウトラインで保存されます。さらにすべてのLOBデータ型もアウトラインで保存されます。TimesTenではデフォルトで、宣言された列の長さが128バイト以下の可変長の列は、インラインで保存されます。
インライン列ではなくアウトライン列で実行されるほとんどの処理はわずかに遅くなります。インライン列ではなくアウトライン列を使用する際にパフォーマンスに関して考慮する事項がいくつかあります。
TimesTenは、アウトライン列からデータを行を連続して保存しないため、データへのアクセスは遅くなります。
TimesTenは、より多くのロギング操作を生成するため、データの移入が遅くなります。
TimesTenは、より多くの再利用操作およびロギング操作を実行するため、データの削除が遅くなります。大量の行(100,000以上)を削除する場合は、複数のより小さいDELETE FROM文またはDELETE FIRST句を使用することを検討してください。詳細は、「大量のDELETE文の回避」を参照してください。
行のインライン部分およびアウトライン部分の最大サイズについては、「ttIsql tablesizeコマンドの使用」を参照してください。
表の作成時に、デフォルトの列値を指定できます。指定するデフォルト値は、列のデータ型と互換性がある必要があります。列には、次のいずれかのデフォルト値を指定できます。
NULL(すべてのデータ型の列)
定数値
SYSDATE(DATE列およびTIMESTAMP列)
USER(CHAR列)
CURRENT_USER(CHAR列)
SYSTEM_USER(CHAR列)
CREATE TABLE文のDEFAULT句を使用し、1つ以上の列のデフォルト値を指定しなかった場合、これらの列のデフォルト値は、NULLになります。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE TABLEに関する説明を参照してください。
TimesTenの表は、所有者名および表名によって一意に識別されます。すべての表に所有者が存在します。デフォルトでTimesTenは、表を作成したユーザーを所有者に定義します。TimesTenが作成したシステム表などの表の所有者名は、SYSまたはTTREPです。
表を一意に参照するには、MARY.PAYROLLなどのように表の所有者名と表名をピリオド「.」で区切って指定します。所有者を指定しなかった場合、TimesTenは、コール元のユーザー名の下にある表を検索し、次にユーザー名SYSの下にある表を検索します。
名前は、文字で始まる英数字の値です。名前には、アンダースコアを使用できます。表名の長さは、最大30文字です。所有者名の長さも、最大30文字です。TimesTenでは、すべての表名、列名および所有者名が大文字で表示されます。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』の「名前、ネームスペースおよびパラメータ」に関する説明を参照してください。
アプリケーションは、表にSQL文を介してアクセスします。TimesTen問合せオプティマイザは、表にアクセスする最適な方法を自動的に選択します。既存の索引を使用するか、必要に応じて一時索引を作成してアクセスの高速化します。一時索引の自動作成および自動破棄を行うとパフォーマンスのオーバーヘッドが発生するため、パフォーマンスを向上させるには、頻繁に検索する列に対して、アプリケーションで索引を明示的に作成する必要があります。詳細は、「文のチューニングと索引の使用」を参照してください。オプティマイザ・ヒント(文またはトランザクション・レベル)を使用して、特定のアプリケーションのTimesTen実行計画を調整できます。オプティマイザ・ヒントの詳細は、「オプティマイザ・ヒントを使用して実行計画を変更する」を参照してください。
1つ以上の列に主キーを作成して、それらの列で重複値が拒否されるように設定できます。主キー列は、NOT NULLとして宣言する必要があります。1つの表に設定可能な主キーは1つのみです。TimesTenは、主キーに対して範囲索引を自動的に作成して、主キーに一意性を適用し、主キーを介してアクセス速度を向上します。行を挿入すると、範囲索引をハッシュ索引に変更する場合を除き、主キー列を変更できなくなります。
1つの表に設定可能な主キーは1つのみですが、一意索引を使用すると、一意性に関するプロパティを表に追加できます。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE INDEXに関する説明を参照してください。
|
ノート: 主キー列はNOT NULLである必要がありますが、一意索引はNOT NULLとして宣言された列に対して作成できます。 |
また、表には、別の表の行に対応する行を持つ1つ以上の外部キーを設定できます。外部キーは、他方の表の主キーまたは一意に索引付けされた列に関連付けられています。外部キーは、参照先列に対して範囲索引を使用します。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE TABLEに関する説明を参照してください。
TimesTen Scaleoutでは、表は、データベースのデータを分散する方法を定義するために使用するオブジェクトです。TimesTen Scaleoutは、この定義された表の分散スキームに従ってデータの分散を管理します。作成した表は、データベースのすべての要素に存在します。表のデータ行は、データベースの様々な要素に存在します。詳細は、『Oracle TimesTen In-Memory Database Scaleoutユーザーズ・ガイド』の表の処理に関する項を参照してください。
TimesTenのデータベースには、アプリケーションで作成された表のみでなく、システム表も含まれています。システム表には、TimesTenメタデータ(データベース内のすべての表および索引の定義など)およびその他の情報(オプティマイザ計画など)が保存されています。アプリケーションでは、ユーザー表の場合と同様にシステム表を問い合せることができます。アプリケーションは、システム表を直接更新できません。TimesTenのシステム表の詳細は、『Oracle TimesTen In-Memory Databaseシステム表およびビュー・リファレンス』の「システム表およびビュー」の章を参照してください。
|
ノート: TimesTenのシステム表のフォーマットは、TimesTenのリリース間で変更される場合があります。 |
表の作成、破棄または管理を行う処理を実行するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章で、すべてのSQL文の構文とともに説明されています。
この項の内容は次のとおりです。
表を作成するには、SQL文CREATE TABLEを使用します。SQL文の構文については、『Oracle TimesTen In-Memory Database SQLリファレンス』を参照してください。TimesTenでは、表名が大文字に変換されます。
例8-1 表の作成
次のSQL文によって、2つの異なるデータ型のcust_idおよびcust_nameという2つの列を持つcustomerという表が作成されます。
Command> CREATE TABLE customer (cust_id TT_INTEGER, cust_name VARCHAR2(50));
例8-2 ハッシュ索引を持つ表の作成
この例では、cust_id、cust_name、addr、zip、regionの列を持つcustomerという表が作成されます。cust_id列が主キーとして指定されているので、表内の行は「主キー、外部キーおよび一意索引」で説明するとおり、行のCustId値で一意に識別されます。
UNIQUE HASH ON custId PAGES値は、ハッシュ索引に30ページあることを示しています。つまり、この表の予想行数は30 * 256 = 7680です。表の行数がこれより大幅に多くなると、パフォーマンスが低下する場合があり、ハッシュ索引のリサイズが必要になります。ハッシュ索引内のページの詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のALTER TABLEのSET PAGESに関する説明を参照してください。ハッシュ表内のページのサイズを設定する方法の詳細は、ハッシュ索引サイズの適切な設定に関する説明を参照してください。
Command> CREATE TABLE customer (cust_id NUMBER NOT NULL PRIMARY KEY, cust_name CHAR(100) NOT NULL, addr CHAR(100), zip NUMBER, region CHAR(10)) UNIQUE HASH ON (cust_id) PAGES = 30;
TimesTenデータベースのサイズの増加は、最初の接続時に行うことができます。データベースのサイズを変更する必要をなくすには、データベースの最終的なサイズを少なく見積もらないようにする必要があります。表のサイズの見積りには、ttSizeユーティリティを使用します。
次の例は、ttSizeユーティリティによる行数、インライン行のバイト数、表の索引のサイズおよび表の合計サイズの見積りを示します。
% ttSize -tbl pat.tab1 mydb Rows = 2 Total in-line row bytes = 17524 Indexes: Index PAT adds 6282 bytes Total index bytes = 6282 Total = 23806
既存の表のサイズは、ttIsql tablesizeコマンドでも計算できます。詳細は、「ttIsql tablesizeコマンドの使用」を参照してください。
データベース内の1つ以上の表に対してエージング・ポリシーを定義できます。エージング・ポリシーとは、エージングのタイプ、属性および状態(ONまたはOFF)のことです。使用状況ベースまたは時間ベースのいずれかのタイプのエージング・ポリシーを指定できます。使用状況ベースのエージングでは、指定したデータベースの使用範囲内の最低使用頻度(LRU)のデータが削除されます。時間ベースのエージングでは、指定したデータ存続期間およびエージング・プロセスの頻度に基づいてデータが削除されます。指定した表に対して定義できるエージングのタイプは1つのみです。
CREATE TABLE文を使用して、新しい表のエージング・ポリシーを定義できます。既存の表にエージング・ポリシーが定義されていない場合は、ALTER TABLE文を使用してその表にエージング・ポリシーを追加できます。エージング・ポリシーは、エージング・ポリシーを破棄したり、新しいエージング・ポリシーを追加することによって変更できます。
グローバル一時表
マテリアライズド・ビューのディテール表
キャッシュ・グループにエージングを実装することもできます。『Oracle TimesTen Application-Tier Database Cacheユーザーズ・ガイド』のキャッシュ・グループでのエージングの実装に関する説明を参照してください。
|
ノート: TimesTen Scaleout内の表にエージング・ポリシーを指定する機能はサポートされていません。詳細は、『Oracle TimesTen In-Memory Database Scaleoutユーザーズ・ガイド』のTimesTen ScaleoutとTimesTen Classicの比較に関する項を参照してください。 |
この項の内容は次のとおりです。
使用状況ベースのエージングを使用すると、最低使用頻度(LRU)のデータを削除することによって、データベースで使用されるメモリーの量を、指定したしきい値の範囲内で管理できます。
CREATE TABLE文のAGING LRU句を使用して、新しい表のLRUエージングを定義します。エージングの状態がONの場合、エージングは自動的に開始されます。
ttAgingLRUConfig組込みプロシージャをコールして、LRUエージング属性を指定します。属性値は、LRUエージング・ポリシーが含まれているデータベース内のすべての表に適用されます。ttAgingLRUConfig組込みプロシージャをコールしない場合は、属性のデフォルト値が使用されます。
|
ノート: 属性を変更する場合、ttAgingLRUConfig組込みプロシージャを使用するにはユーザーにADMIN権限が必要です。既存の属性を表示する場合、権限は必要ありません。詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』の組込みプロシージャに関する説明を参照してください。 |
次の表に、LRUエージング属性の概要を示します。
| LRUエージング属性 | 説明 |
|---|---|
LowUsageThreshhold |
LRUエージングが非アクティブになるデータベースPermSizeの割合(%)。 |
HighUsageThreshhold |
LRUエージングがアクティブになるデータベースPermSizeの割合(%)。 |
AgingCycle |
エージング・サイクルの間隔(分)。 |
LRUエージング・ポリシーの定義後、AgingCycleに対して新しい値を設定すると、エージングは、その時点での時間および新しいサイクル時間に基づいて実行されます。たとえば、元のエージング・サイクルが15分で、LRUエージングが10分前に実行された場合、エージングは、5分後に再度実行されることになります。ただし、AgingCycleパラメータを30分に変更すると、AgingCycleで変更した値を使用してttAgingLRUConfigプロシージャをコールした時点から30分後にエージングが行われます。
最後のエージング・サイクル以降に行へのアクセスまたは行の参照を行った場合、その行はLRUエージングの対象ではなくなります。行は、次のいずれかの条件に当てはまる場合にアクセスまたは参照されたとみなされます。
行がSELECT文の結果セットを作成するために使用された。
行に、更新フラグまたは削除フラグが設定されている。
行がINSERT SELECT文の結果セットを作成するために使用された。
ALTER TABLE文を使用して、次のタスクを実行できます。
ALTER TABLE文をSET AGING {ON|OFF}句とともに使用して、エージング・ポリシーが定義されている表のエージングの状態を有効または無効にします。
ALTER TABLE文をADD AGING LRU [ON|OFF]句とともに使用して、LRUエージング・ポリシーを既存の表に追加します。
ALTER TABLE文をDROP AGING句とともに使用して、表のエージングを破棄します。
エージングの開始をスケジュールするには、ttAgingScheduleNow組込みプロシージャをコールします。詳細は、「エージング開始のスケジュール」を参照してください。
表のエージングをLRUから時間ベースに変更するには、まず、DROP AGING句とともにALTER TABLE文を使用して表のエージングを破棄します。次に、ADD AGING USE句とともにALTER TABLE文を使用して時間ベースのエージングを追加します。
|
ノート: LRUエージングを破棄するか、またはコマンドで参照される表にLRUエージングを追加すると、TimesTenによって、コンパイルされているコマンドが無効とマークされます。これらのコマンドは、再コンパイルする必要があります。 |
時間ベースのエージングでは、指定したデータ存続期間およびエージング・プロセスの頻度に基づいてデータが表から削除されます。CREATE TABLE文のAGING USE句を使用して、新しい表の時間ベースのエージング・ポリシーを指定します。ALTER TABLE文のADD AGING USE句を使用して、既存の表に時間ベースのエージング・ポリシーを追加します。
AGING USE句にはColumnName引数があります。ColumnNameは時間ベースのエージングに使用する列名で、タイムスタンプ列とも呼ばれます。タイムスタンプ列は次のように定義する必要があります。
ORA_TIMESTAMP、TT_TIMESTAMP、ORA_DATEまたはTT_DATEデータ型
NOT NULL
使用しているアプリケーションによって、タイムスタンプ列の値が更新されます。いくつかの行でこの列の値が不明な場合に、それらの行がエージングされないようにするには、その列のデフォルト値を大きい値に定義します。タイムスタンプ列に索引を作成すると、エージング・プロセスのパフォーマンスを向上できます。
|
ノート: 列を追加または変更してNOT NULLに定義することはできないため、既存の表で列を追加または変更した後で、その列をタイムスタンプ列として使用することはできません。 |
時間ベースのエージング・ポリシーが含まれている表からタイムスタンプ列を破棄することはできません。
タイムスタンプ列のデータ型がORA_TIMESTAMP、TT_TIMESTAMPまたはORA_DATEである場合は、CREATE TABLE文のLIFETIME句に、日、時間または分単位で存続期間を指定できます。タイムスタンプ列のデータ型がTT_DATEである場合は、日単位で存続期間を指定します。
タイムスタンプ列の値は、SYSDATEから引かれます。結果は、指定した単位(分、時間、日)を使用して切り捨てられ、指定したLIFETIME値と比較されます。結果がLIFETIME値より大きい場合、その行はエージングの候補となります。
CYCLE句を使用して、システムで行を確認し、指定した存続期間を超えたデータを削除する頻度を指定します。CYCLEを指定しない場合、エージングは5分ごとに行われます。CYCLEに0(ゼロ)を指定した場合、エージングは継続して行われます。エージングは、状態がONの場合、自動的に開始されます。
ALTER TABLE文を使用して、次のタスクを実行します。
SET AGING {ON|OFF}句を使用して、時間ベースのエージング・ポリシーが含まれている表のエージングの状態を有効または無効にします。
SET AGING CYCLE句を使用して、時間ベースのエージング・ポリシーが含まれている表のエージング・サイクルを変更します。
SET AGING LIFETIME句を使用して、存続期間を変更します。
ADD AGING USE句を使用して、エージング・ポリシーが含まれていない既存の表に時間ベースのエージングを追加します。
DROP AGING句を使用して、表のエージングを破棄します。
エージングの開始をスケジュールするには、ttAgingScheduleNow組込みプロシージャをコールします。詳細は、「エージング開始のスケジュール」を参照してください。
表のエージング・ポリシーを時間ベースのエージングからLRUエージングに変更するには、まず、表の時間ベースのエージングを破棄します。次に、ADD AGING LRU句とともにALTER TABLE文を使用して、LRUエージングを追加します。
外部キーによって関連付けられている表には、同じエージング・ポリシーを設定する必要があります。
エージング処理をスケジュールするには、ttAgingScheduleNow組込みプロシージャをコールします。実行中のエージング・プロセスが存在しないかぎり、このプロシージャをコールするとすぐにエージング・プロセスは開始されます(存在する場合、そのエージング・プロセスが完了すると開始されます)。
ttAgingScheduleNowをコールすると、状態がONまたはOFFのいずれであるかに関係なく、エージング・プロセスが開始されます。
ttAgingScheduleNowをコールしてもエージングの状態は変わらないため、これをコールした結果としてエージング・プロセスは1回のみ開始されます。ttAgingScheduleNowのコール時にエージングの状態がOFFの場合、エージング・プロセスは開始されますが、プロセスの完了後、エージングは継続されません。エージングを継続するには、ttAgingScheduleNowを再度コールするか、またはエージングの状態をONに変更する必要があります。
エージングの状態がすでにONに設定されている場合は、ttAgingScheduleNowがコールされた時間に基づいて、ttAgingScheduleNowによってエージング・サイクルがリセットされます。
SET AGING OFF句とともにALTER TABLE文を使用してエージングを無効にすると、外部でエージングを制御できます。その後、ttAgingScheduleNowを使用して、目的の時間にエージングを開始します。
ttAgingScheduleNowを使用して、このプロシージャのコール時に個々の表の名前を指定することによって、表のエージングを開始またはリセットします。表名を指定しない場合は、ttAgingScheduleNowによって、エージングが定義されているデータベース内のすべての表のエージングが開始またはリセットされます。
アクティブなスタンバイ・ペアの場合は、アクティブなマスター・データベースにエージングを実装します。エージングの結果として行われる削除は、スタンバイ・マスター・データベースおよび読取り専用サブスクライバにレプリケートされます。スタンバイ・マスター・データベースに対してフェイルオーバーが行われると、エージングは、ロールがACTIVEに変更された後でそのデータベースに対して有効になります。
他のすべてのタイプのレプリケーション・スキームの場合は、ノードごとに個別にエージングを実装します。エージング・ポリシーは、すべてのノードで同じである必要があります。
ホット・スタンバイとして使用されるマルチマスター・レプリケーション・スキームにLRUエージングを実装すると、LRUエージングで予期しない結果が発生する可能性があります。エージングがローカルで行われるため、フェイルオーバー後に必要なデータの一部が失われる場合があります。
ビューとは、1つ以上の表に基づく論理表です。ビュー自体にデータは含まれていません。これは、ディテール表の計算済データを含むマテリアライズド・ビューと区別するために、非マテリアライズド・ビューと呼ばれることもあります。ビューは直接更新できませんが、ディテール表のデータへの変更はただちにビューに反映されます。
ビューは、基本的には、データベースに格納さたSQL文となり、これにより、SQL問合せの結果を表自体として処理できるようにします。TimesTenでは、ビューを問い合せるたびにそのビューの結果が生成されるため、ビューのデータ結果は常に最新です。ビューは、通常の表の問合せと同様に問い合せることができます。
マテリアライズド・ビューを使用すると、負荷の高いSQL操作を事前に計算できます。主に読取り専用データベースの問合せの結果を事前計算し、マテリアライズド・ビューに格納することで、SELECT操作の速度を向上させることができる場合があります。この場合のデメリットは、マテリアライズド・ビューには追加の記憶領域が必要になることです。マテリアライズド・ビューのディテール表に対してDML操作を実行するときには、これらのDML操作はリソースを大量に消費し、マテリアライズド・ビューの行を格納する追加の記憶域が必要になることに注意してください。表に対して使用するマテリアライズド・ビューの数が多すぎると、その表のパフォーマンスが低下することがあります。
ビューの作成、破棄または管理を行う処理を実行するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章で、すべてのSQL文の構文とともに説明されています。
この項の内容は次のとおりです。
ビューを作成するには、SQL文CREATE VIEWを使用します。SQL文の構文については、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章を参照してください。
CREATE VIEW ViewName AS SelectQuery;
これによって、ビューで使用される列がディテール表から選択されます。
たとえば、表t1からビューを作成します。
Command> CREATE VIEW v1 AS SELECT * FROM t1;
次に、表t1に対する集計問合せからビューを作成します。
Command> CREATE VIEW v1 (max1) AS SELECT max(x1) FROM t1;
マテリアライズド・ビューの内容の定義に使用するSELECT問合せは、トップレベルのSQL SELECT文(『Oracle TimesTen In-Memory Database SQLリファレンス』のSQL文に関する項を参照)に似ていますが、次の制限があります。
ビュー定義内のSELECT *問合せは、ビュー作成時に拡張されます。ビューが作成された後に追加された列は、ビューに反映されません。
ビューを作成するSELECT文で、次の句は使用できません。
DISTINCT
FIRST
ORDER BY
引数
一時表
SELECT構文のリストの各式には、一意の名前が必要です。列の別名が定義されていないかぎり、単純にその列の名前が使用されます。ROWIDは式とみなされるため、別名が必要です。
SELECT FOR UPDATEまたはSELECT FOR INSERT文はビューに対しては使用できません。
特定のTimesTen問合せ制限は、非マテリアライズド・ビューの作成時に確認されません。これらの制限に違反しているビューの作成が可能な場合がありますが、その後、実行した文でこのビューが参照されると、エラーが戻されます。
ビューがSELECT文のFROM句で参照されると、ビューの名前は、その定義によってSQLコンパイル時に導出表に置き換えられます。導出表の内容は、実体化と呼ばれますが、この実体化は一時的なもので、SQL文の存続期間中にのみ存在します。たとえば、ビューと参照しているSELECTの両方で集計が指定されている場合、ビューは、その結果がSELECTの他の表と結合される前にマテリアライズ化されます。
ビューは、DROP TABLE文では破棄できません。DROP VIEW文を使用する必要があります。
ビューは、ALTER TABLE文では変更できません。
ビューの参照は、ディテール表の破棄または変更が原因で失敗する可能性があります。
次の項では、マテリアライズド・ビューとその管理方法について説明します。
マテリアライズド・ビューとは、1つ以上の通常のTimesTen表から選択したデータのサマリーを保持する読取り専用表です。マテリアライズド・ビューの結果セットを作成するために問い合される通常のTimesTen表は、ディテール表と呼ばれます。
|
ノート: マテリアライズド・ビューは、キャッシュ・テーブルではサポートされません。 |
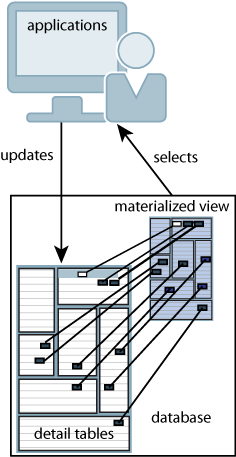
図8-1に、ディテール表から作成されたマテリアライズド・ビューを示します。アプリケーションで、ディテール表の更新およびマテリアライズド・ビューからのデータの選択を行うことができます。
同期マテリアライズド・ビューでは、ディテール表のトランザクション時に、ディテール表の結果セット・データが更新されます。ディテール表でデータが更新されるたびに、結果セットが更新されます。このため、マテリアライズド・ビューとディテール表が非同期になることはありません。ただし、パフォーマンスに影響を与える可能性があります。1つのトランザクション(ユーザー・トランザクション)で、ディテール表とマテリアライズド・ビューの両方の更新が実行されます。
TimesTen Scaleoutでは、マテリアライズド・ビューによりデータ行を分散するための2番目のメカニズムが提供されます。また、TimesTen Scaleoutのマテリアライズド・ビューは、複数要素へのアクセス(ブロードキャスト)を削減または排除するグローバル索引として役立ちます。TimesTen Scaleoutでのマテリアライズド・ビューの使用方法の詳細は、『Oracle TimesTen In-Memory Database Scaleoutユーザーズ・ガイド』のマテリアライズド・ビューの理解に関する項を参照してください。
この項の内容は次のとおりです。
マテリアライズド・ビューを作成するには、SQL文CREATE MATERIALIZED VIEWを使用します。
|
ノート: マテリアライズド・ビューを作成するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章で、SQLの構文とともに説明されています。所有者が、マテリアライズド・ビューが作成されるディテール表に対する権限を取り消すと、そのマテリアライズド・ビューは無効になります。『Oracle TimesTen In-Memory Databaseセキュリティ・ガイド』のマテリアライズド・ビューのオブジェクト権限に関する項を参照してください。 |
マテリアライズド・ビューの作成時に、「主キー、外部キーおよび一意索引」の表の場合と同様の方法で、主キーおよびハッシュ表のサイズを指定できます。
マテリアライズド・ビューの例では、次の2つの表を使用します。
Command> CREATE TABLE customer (cust_id INT NOT NULL, cus_name CHAR(100) NOT NULL, addr CHAR(100), zip INT, region CHAR(10), PRIMARY KEY (cust_id)); CREATE TABLE book_order (order_id INT NOT NULL, cust_id INT NOT NULL, book CHAR(100), PRIMARY KEY (order_id), FOREIGN KEY (cust_id) REFERENCES customer(cust_id));
次の項では、マテリアライズド・ビューの作成の詳細および例を示します。
同期マテリアライズド・ビューは、ディテール表が更新されるたびに自動的に更新されます。同期マテリアライズド・ビューは、CREATE MATERIALIZED VIEW文を使用して作成できます。
次のように入力すると、sample_mvという同期マテリアライズド・ビューが作成されます。このマテリアライズド・ビューによって、前述のcustomerおよびbook_orderディテール表の選択した列から結果セットが生成されます。
Command> CREATE MATERIALIZED VIEW sample_mv AS SELECT customer.cust_id, cust_name, order_id, book FROM customer, book_order WHERE customer.cust_id=book_order.cust_id;
マテリアライズド・ビューを削除するには、DROP VIEW文を発行します。
次の文では、sample_mvマテリアライズド・ビューが削除されます。
Command> DROP VIEW sample_mv;
SQL文の構文については、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章を参照してください。
マテリアライズド・ビューは、読取り専用表であるため、直接には更新できません。つまり、マテリアライズド・ビューは、INSERT文、DELETE文またはUPDATE文で更新できず、レプリケーション、XLAまたはキャッシュ・エージェントでも更新できません。
たとえば、マテリアライズド・ビューの行を更新しようとすると、次のエラーが戻されます。
805: Update view table directly has not been implemented
マテリアライズド・ビューのその他の実装についてよく理解している読者にとっては一般的ですが、TimesTenのマテリアライズド・ビューには、次の特性があります。
ディテール表はレプリケートできますが、マテリアライズド・ビューはレプリケートできません。
マテリアライズド・ビューおよびそのディテール表のいずれも、キャッシュ・グループの一部にはできません。
表または別のマテリアライズド・ビューを参照する外部キーを作成できません。通常の表は、外部キーを使用して、マテリアライズド・ビューを参照できません。
マテリアライズド・ビューを破棄するには、DROP VIEW文を使用する必要があります。
マテリアライズド・ビューを変更することはできません。DROP VIEW 文で破棄してから、CREATE MATERIALIZED VIEW文で新しいマテリアライズド・ビューを作成する必要があります。
マテリアライズド・ビューは、アプリケーションで明示的に作成する必要があります。
TimesTenの問合せオプティマイザが、ディテール表に対する問合せをリライトしてマテリアライズド・ビューを参照することはありません。マテリアライズド・ビューを使用する場合は、アプリケーションの問合せでビューを直接参照する必要があります。
マテリアライズド・ビューの作成に使用するSQLにはいくつかの制限があります。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE MATERIALIZED VIEWに関する説明を参照してください。
更新される表をマテリアライズド・ビューで参照していると、UPDATE、INSERTおよびDELETE操作のパフォーマンスに影響することがあります。パフォーマンスへの影響は、次のような多数の要因に応じて異なります。
マテリアライズド・ビューの性質: ディテール表の数、外部結合または集計の使用の有無。
ディテール表およびマテリアライズド・ビューに存在する索引のタイプ。
変更の影響を受けるマテリアライズド・ビュー行の数。
マテリアライズド・ビューは、問合せ結果の最新の永続コピーです。マテリアライズド・ビューを最新の状態に保つには、マテリアライズド・ビューのディテール表の変更時に、TimesTenでマテリアライズド・ビュー・メンテナンスを実行する必要があります。たとえば、表T1、T2およびT3から選択するVという名前のマテリアライズド・ビューがあり、常にT1に挿入するか、T2を更新するか、T3から削除する場合、TimesTenはマテリアライズド・ビュー・メンテナンスを実行します。
マテリアライズド・ビュー・メンテナンスの実行には、通常のデータベース処理と同様に適切な索引が必要です。索引がない場合、マテリアライズド・ビュー・メンテナンスのパフォーマンスは低くなります。
ディテール表に対する更新文、挿入文、削除文のすべての処理には実行計画が存在します(「TimesTen問合せオプティマイザ」を参照)。たとえば、T1の行を更新すると、実行計画の第1段階が開始されます。マテリアライズド・ビューVが更新された後、第2段階でT1が更新されます。
マテリアライズド・ビュー・メンテナンスを高速に行うには、次の手順を実行して、ディテール表を更新するすべての処理の計画を評価する必要があります。
ディテール表に対して頻繁に実行される更新文や削除文でのすべてのWHERE句を調べます。索引キーを使用する句に注目してください。たとえば、次の処理が、アプリケーションの処理時間の95%を占めているとします。
UPDATE T1 set A=A+1 WHERE K1=? AND K2=? DELETE FROMT2 WHERE K3=?
この場合、注目するキーは(K1、K2)およびK3です。
ビューでこれらのすべてのキー列が選択されていることを確認します。この例では、K1、K2およびK3がマテリアライズド・ビューで選択されている必要があります。
これらの各キーに対して、マテリアライズド・ビューの索引を作成します。この例では、(V.K1、V.K2)に対する索引およびV.K3に対する索引の2つの索引がビューに必要です。これらの索引が一意である必要はありません。この例では、ビューの列の名前は表の列の名前と同じですが、別の名前を指定することもできます。
この方法では、ディテール表を更新すると、対応するビューの更新にWHERE句が使用されます。これによって、メンテナンスは1つのバッチで行われ、パフォーマンスが向上します。
ただし、前述の方法を使用できない場合があります。たとえば、アプリケーションにディテール表を更新するメソッドが多数存在することがあります。その場合、アプリケーションがビューで非常に多数の項目を選択したり、マテリアライズド・ビューに対して非常に多数の索引を作成することになり、予想以上の領域または処理能力が使用される可能性があります。次に示す別の方法を行います。
マテリアライズド・ビューのFROM句に指定されている各表(ディテール表)で、UPDATE文、INSERT文およびCREATE VIEW文によって頻繁に変更されている表を確認します。たとえば、マテリアライズド・ビューのFROM句に表T1、T2、T3、T4およびT5があり、その中でT2とT3のみが頻繁に変更されているとします。
マテリアライズド・ビューでこれらの表のrowidが選択されることを確認してください。この例では、マテリアライズド・ビューでT2.rowidおよびT3.rowidが選択されている必要があります。
これらの各rowid列に対してマテリアライズド・ビューの索引を作成します。この例では、列の名前はT2rowidおよびT3rowidで、索引はV.T2rowidおよびV.T3rowidに対して作成されます。
この方法では、バッチ単位ではなく、行単位でマテリアライズド・ビュー・メンテナンスが行われます。ただし、マテリアライズド・ビューとそのディテール表の間では行が非常に効率的に照合されるため、高速でメンテナンスされます。通常、最初の方法ほど高速ではありませんが、有効な方法です。
索引は、表の検索のパフォーマンスを大幅に向上させる補助的なデータ構造です。索引アドバイザを使用すると、特定のSQLワークロードに対して索引を推奨できます。詳細は、「索引アドバイザを使用した索引の推奨」を参照してください。
問合せの実行を高速化するために、索引は問合せオプティマイザによって自動的に使用されます。問合せオプティマイザの詳細は、「TimesTen問合せオプティマイザ」を参照してください。
索引は、表の各行で、索引を設定した列に一意の値を指定することによって一意なものとして指定できます。一意索引は、NULL値可能の列に対しても作成できます。SQL標準に従って、複数のnull値を一意索引に使用でき、一意索引により、同じ値セットを持つ複数の行を指定できます。
TimesTen Scaleoutでは、分散キーのすべての列が含まれていない索引アクセスには、複数要素へのアクセス(すべての要素にわたるブロードキャスト)が必要になります。ブロードキャストを回避し、索引アクセスを最適化する方法の詳細は、『Oracle TimesTen In-Memory Database Scaleoutユーザーズ・ガイド』の索引の理解に関する項を参照してください。
TimesTenでは、データ値をソートする場合、NULL値はNULL以外のすべての値より大きい値とみなされます。NULL値の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のNULL値に関する説明を参照してください。
索引の作成、破棄または変更を行う処理を実行するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章で、すべてのSQL文の構文とともに説明されています。
次の項では、索引の管理方法について説明します。
TimesTenでは、表への高速アクセスが可能になる次の3つのタイプの索引があります。表に最大500の範囲またはハッシュ索引を作成できます。
範囲索引: 範囲索引は、特定の範囲内の列値を持つ行を検索する場合に有効です。範囲索引は、表の1つ以上の列に対して作成できます。
範囲索引と等価結合は一致検索および範囲検索(以上、以下など)で使用できます。あるフィールドに主キーを設定してFIELD > 10かどうかを確認する場合、主キー索引では検索は効率的に行われず、別の索引の方が効率的です。
範囲索引の作成方法の詳細については、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE INDEXに関する説明を参照してください。
ハッシュ索引: ハッシュ索引は、一致検索の実行に便利です。ハッシュ索引は次のいずれかの方法で作成されます。
CREATE INDEX文を使用すると、表またはマテリアライズド・ビューの1つ以上の列にハッシュ索引または一意のハッシュ索引を作成できます。
CREATE TABLE... UNIQUE HASH ON文を使用すると、表の作成時に表の主キーに一意のハッシュ索引を作成できます。
ハッシュ索引作成の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』で、CREATE INDEXおよびCREATE TABLEに関する説明を参照してください。ハッシュ索引を作成する方法の例は、例8-4を参照してください。ハッシュ表のサイズを設定する方法の詳細は、「ハッシュ索引サイズの適切な設定」を参照してください。
|
ノート: 完全一致検索の場合、ハッシュ索引は範囲索引よりも高速になりますが、範囲索引より多くの領域が必要となります。ハッシュ索引は値自体の参照にのみ使用できます。SQL問合せで値の範囲が返される場合は、ハッシュ索引を使用できません。また、ハッシュ索引は、表スキャンによって取得される値のソートには効果がありません。範囲索引はインメモリー・データ管理に最適化されており、列の値に基づく効率的なソートが可能です。 TimesTenでは、問合せの実行を高速化する問合せの処理中に一時ハッシュ索引または一時範囲索引が自動的に作成されることがあります。 |
|
ノート: または、データに高速にアクセスするために、RowIDによる検索を実行することもできます。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のROWIDデータ型に関する説明を参照してください。 |
索引を作成するには、SQL文CREATE INDEXを発行します。TimesTenでは、索引名は大文字に変換されます。
TimesTen Scaleoutで索引を作成すると、分散マップ内のすべての要素の索引が作成されます。TimesTen Scaleoutは、各要素の索引に、その要素に格納されている行を移入します。
索引には所有者が存在します。索引の所有者は、基礎となる表を作成したユーザーです。TimesTenによって作成される索引(システム表の索引など)のユーザー名はSYSですが、レプリケーション表の索引のユーザー名はTTREPになります。
|
ノート: LOB列には索引を作成できません。 |
例8-4 索引の作成
次の文では、表customerの列cust_idに索引ixidが作成されます。
Command> CREATE INDEX ixid ON customer (cust_id);
次の文では、表作成の一部としてcustomer表に一意のハッシュ索引が作成されます。
Command> CREATE TABLE customer (cust_id NUMBER NOT NULL PRIMARY KEY, cust_name CHAR(100) NOT NULL, addr CHAR(100), zip NUMBER, region CHAR(10)) UNIQUE HASH ON (cust_id) PAGES = 30;
次の文では、顧客名について、customer表に一意でないハッシュ索引が作成されます。
Command> CREATE HASH INDEX custname_idx ON customer(cust_name);
各種の索引とその作成方法に関するその他の例については、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE INDEXに関する説明およびALTER TABLEに関する説明を参照してください。
ALTER TABLE文を使用して主キー制約を追加(または変更)し、範囲索引またはハッシュ索引の使用を指定できます。
|
ノート: CREATE INDEX文で作成した索引の場合、索引を変更してハッシュ索引から範囲索引へ、または範囲索引からハッシュ索引へ変換することはできません。 |
ALTER TABLE文のUSE RANGE INDEX句を使用すると、ハッシュ索引のかわりに範囲索引が使用されるように主キー制約を変更できます。ALTER TABLE文のUSE HASH INDEXを使用すると、範囲索引のかわりにハッシュ索引が使用されるように主キー制約を変更できます。詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のALTER TABLEに関する説明を参照してください。
索引を一意に参照するには、アプリケーションで所有者および名前の両方を指定する必要があります。アプリケーションで所有者を指定しなかった場合、TimesTenは、コール元のユーザー名の下にある索引を検索し、次にユーザー名SYSの下にある索引を検索します。
TimesTen索引を破棄するには、SQL文DROP INDEXを発行します。TimesTen Scaleoutの索引を削除すると、すべての要素の索引が削除されます。
|
ノート: 表を破棄すると、その表のすべての索引が自動的に破棄されます。 |
TimesTenデータベースのサイズの増加は、最初の接続時に行うことができます。任意の索引を含むデータベースのサイズの見積りには、ttSizeユーティリティを使用します。データベースのサイズを正確に見積ると、後でデータベースのサイズを変更する必要性を減らすために役立ちます。
次の例は、ttSizeユーティリティによる行数、インライン行のバイト数、表の索引のサイズおよび表の合計サイズの見積りを示します。
% ttSize -tbl pat.tab1 mydb Rows = 2 Total in-line row bytes = 17524 Indexes: Index PAT adds 6282 bytes Total index bytes = 6282 Total = 23806
適切な索引セットを使用すると、問合せパフォーマンスが向上します。索引アドバイザを使用すると、特定のSQLワークロードのパフォーマンスを向上させるための索引を推奨できます。索引アドバイザは、読取り集中型の複雑な問合せを対象としています。書込み集中型のワークロードには、索引アドバイザの使用はお薦めしません。
索引アドバイザは、SQLワークロードを評価し、結合、単一表スキャン、およびORDER BYまたはGROUP BY操作のパフォーマンスを向上させることができる索引を推奨します。索引アドバイザは、マテリアライズド・ビュー用の実表やキャッシュ・グループ内の表など、特定の目的に使用する表を区別しません。SQLワークロードの問合せで表が使用されるかぎり、索引アドバイザはその表について索引を推奨することができます。
索引アドバイザは、推奨される索引ごとにCREATE文を生成し、発行する文を選択できます。索引アドバイザは次の索引を推奨できるため、データベース管理者は、新しい索引に推奨された各CREATE文を適用する前に見直す必要があります。
既存の索引の複製になっている索引。
SQLワークロード時に作成および削除される表、または表の列の索引。ただし、表、または表の列を作成するDDLの後で、かつ、その削除の前で、SQLワークロードで推奨される索引にCREATE文を追加できます。
データが一意でないデータ・セット用の一意な索引など、作成することができない索引。この場合は、この推奨を無視する必要があります。
索引作成オプションでは、UNIQUEまたは一意でない索引のいずれかとして索引を作成できます。索引アドバイザはどちらの索引タイプも推奨しています。推奨される両方の索引が同じ名前ため、それらの索引のうちの1つのみを作成できます。オプティマイザは、指定されたワークロードにはUNIQUE索引が適していると考えますが、一意でない索引を作成することも選択できます。列に一意の値のみが含まれている場合は、UNIQUE索引の作成を検討してください。列に一意でない値が含まれている場合は、一意でない索引の作成を検討してください。
索引アドバイザは、次のことに対応していません。
メモリー使用率を最適化しません。
メンテナンスのコストを考慮しません。
有用でない場合は既存の索引を削除するということは推奨しません。
グローバル一時表用の索引は推奨しません。
推奨されるステップでは、次のように索引アドバイザを使用します。
索引アドバイザを実行するには、オプションで次の手順を実行する必要があります。
索引アドバイザは問合せ計画に依存するため、索引アドバイザを有効にしてワークロードを実行する前に、SQLワークロードに使用する関連オプティマイザ・ヒントを設定します。オプティマイザ・ヒントの詳細については、「オプティマイザ・ヒントを使用して実行計画を変更する」を参照してください。
SQLワークロードに含まれている表の統計を更新し、取得時に文を強制して再準備させます。これにより、データ収集の最新の統計が提供され、最新の統計に基づいて文が再準備されます。
SQLワークロードに含まれている表の統計を、組込みプロシージャttOptUpdateStats、ttOptEstimateStatsまたはttOptSetTblStatsのうちの1つで更新します。組込みプロシージャでは、invalidateパラメータを1に設定して、示されている表を参照しているすべてのコマンドを無効にし、再実行時に自動的に再準備されるようにこれらのコマンドを強制します。これにより、統計は確実に最新状態になります。
ttOptUpdateStats組込みプロシージャは、表のすべての統計を完全に更新します。ただし、これには時間がかかります。
ttOptEstimateStatsは、示された表のわずかな割合の行に基づいて統計を評価します。
ttOptSetTblStatsは、ユーザーによって指定された既知の値に統計を設定します。
|
ノート: 組込みプロシージャの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』のttOptUpdateStatsに関する項、ttOptEstimateStatsに関する項およびttOptSetTblStatsに関する項を参照してください。 |
次の例は、これらの表のうちの10%の行のランダム・サンプルを評価することで、現行のユーザー用のすべての表の統計を推定します。また、これらの表を参照する、すでに準備されたすべてのコマンドを無効にします。
Command> call ttOptEstimateStats ( '', 1, '10 PERCENT' );
次のようにして、ttIndexAdviceCaptureStartおよびttIndexAdviceCaptureEnd組込みプロシージャをコールして、索引アドバイザが索引推奨項目を生成するために必要な情報を取得します。
ttIndexAdviceCaptureStart組込みプロシージャをコールして、索引情報を収集するプロセスを開始します。
SQLワークロードを実行します。
ttIndexAdviceCaptureEnd組込みプロシージャをコールして、索引情報収集プロセスを終了します。
ttIndexAdviceCaptureStart組込みプロシージャをコールしてデータ収集プロセスを開始する場合、次のものを指定します。
captureLevelパラメータでは、収集する索引情報を現行の接続向けまたはデータベース全体向けのいずれにするかを指定します。独立した接続に対して競合することなく、複数の接続レベルの取得を同時に実行できます。データベースレベルの取得は、接続レベルの取得と並行して実行できます。データベースレベルの取得と接続レベルの取得の間には競合がないため、データベースレベルの取得を開始したときにすでに進行中の未処理の接続レベルの取得は、目的どおりに完了します。ただし、最初のデータベースレベルの取得が引き続き有効な場合にデータベースレベルの取得の2番目のリクエストを開始すると、エラーが返されます。また、最初の接続レベルの取得が引き続き有効な場合に同じ接続から接続レベルの取得の2番目のリクエストが開始されるときも、エラーが返されます。
データベースレベルの取得用にttIndexAdviceCaptureStartを起動すると、すでに進行中の未処理の接続レベルの取得は完了します。
captureModeパラメータには、次のいずれかのシナリオでデータ収集を実行することを指定します。
SQLワークロードの現行の実行を使用して索引情報の収集を実行します。
索引情報の収集は、SQLワークロードの現行の実行の基盤にするのではなく、既存の計算済の統計および問合せ計画の分析の基盤にします。このシナリオでは、SQL文は準備されますが、実行はされません。このモードは、接続レベルの取得でのみ実行できます。
取得を完了するには、ttIndexAdviceCaptureEnd組込みプロシージャをコールすることで、同じ接続からの有効な接続レベルの取得、または有効なデータベースレベルの取得は終了します。データベースレベルの取得の完了には、ADMIN権限が必要です。
取得中に接続が失敗すると、次のことが起きます。
取得が接続レベルの取得の場合、取得は終了し、関連するすべてのリソースは解放されます。
取得がデータベースレベルの取得の場合、ADMIN権限を持った別のユーザーが接続してttIndexAdviceCaptureEnd組込みプロシージャを起動し、データベースレベルの取得を終了するまで、取得は続行されます。
取得中に一時領域が一杯になると、有効な取得は終了し、取得中に収集されたデータは保存されます。
|
ノート: 取得後にttIndexAdviceCaptureDropを実行して一時領域を解放します。ttIndexAdviceCaptureDropの詳細については、「索引アドバイザ用に収集したデータを破棄してデータをファイナライズする」を参照してください。 |
次の例では、SQLワークロードの現行の実行に対応した接続レベルにおける索引アドバイザ用の収集を開始します。
Command> call ttIndexAdviceCaptureStart(0,0);
次の例では、接続レベルの取得用の収集を終了します。
Command> call ttIndexAdviceCaptureEnd(0);
|
ノート: 組込みプロシージャの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』の「ttIndexAdviceCaptureStart」および「ttIndexAdviceCaptureEnd」を参照してください。 |
ttIndexAdviceCaptureInfoGet組込みプロシージャをコールして、索引アドバイザ用のデータ収集概要情報を取得します。
ttIndexAdviceCaptureOutput組込みプロシージャをコールして、索引推奨項目を取得します。
|
ノート: これらの組込みプロシージャは、データ収集概要および索引アドバイザの推奨を取得します。目的のデータのいずれか、または両方を実行します。 |
DBAが索引推奨項目の作成文を評価した後で、目的の索引作成推奨項目を適用します。
ttIndexAdviceCaptureInfoGet組込みプロシージャは、索引アドバイザ用に収集されたデータに関する情報を取得します。接続レベルの取得とデータベース・レベルの取得のどちらでも、1行のみが返されます。
|
ノート: データベースレベルの取得による行は、ADMIN権限を持っているユーザーにのみ返されます。 |
ttIndexAdviceCaptureInfoGet組込みプロシージャがデータを取得するのは、次の場合です。
データの取得が開始されて、終了していない場合。
前の取得が開始されて停止されていて、データが削除されていない場合。
|
ノート: 進行している取得がないか、データが存在していない場合、行は返されません。 |
返される行には、次の情報が含まれています。
取得の状態: 取得が完了すると0が返されます。取得が引き続き進行中の場合は1が返されます。
該当する場合は接続識別子。
この取得に設定されている取得レベルおよびモード。
取得間隔の間に準備されて実行された文の数。
取得が開始されて停止された時刻。
次に、363の準備済の文および369の実行済の文について完了した接続レベルの取得に関する取得情報を示します。
Command> call ttIndexAdviceCaptureInfoGet(); < 0, 1, 0, 0, 363, 369, 2012-07-27 11:44:08.136833, 2012-07-27 12:07:35.410993 > 1 row found.
|
ノート: この組込みプロシージャの詳細および構文は、『Oracle TimesTen In-Memory Databaseリファレンス』の「ttIndexAdviceCaptureInfoGet」を参照してください。 |
ttIndexAdviceCaptureOutput組込みプロシージャは、指定したレベル(接続レベルまたはデータベースレベル)で最後に記録された取得から索引推奨項目のリストを取得します。リストには、推奨索引ごとにCREATE文が含まれています。
接続レベルの取得について索引推奨項目をリクエストするには、取得を開始した同じ接続内でcaptureLevelを0に設定したttIndexAdviceCaptureOutputを実行します。データベースレベルの取得の場合、ユーザーがADMIN権限を持っている接続でcaptureLevelを1に設定したttIndexAdviceCaptureOutputを実行します。
返される行には、次のものが含まれています。
stmtCount - 実行されるSQLワークロードを加速するために索引が役立つ回数。
createStmt - 推奨索引を作成するために使用できる実行可能文。これらの文のすべてのデータベース・オブジェクト名は完全に修飾されます。
次の例は、HR.PURCHASE表でPURCHASE_i1という索引に対応したCREATE文を示しています。この索引は、このSQLワークロードに対して4回役立ちます。
CALL ttIndexAdviceCaptureOutput(); < 4, create index PURCHASE_i1 on HR.PURCHASE(AMOUNT); > 1 row found.
|
ノート: この組込みプロシージャの詳細および構文は、『Oracle TimesTen In-Memory Databaseリファレンス』の「ttIndexAdviceCaptureOutput」を参照してください。 |
DBAによって承認された新しい索引に対してCREATE文を適用した後、索引アドバイザ用に収集した取得データを破棄できます。ttIndexAdviceCaptureDrop組込みプロシージャは、接続レベルまたはデータベースレベルの取得にできる、指定したcaptureLevel用に収集された既存のデータを削除します。
Call ttIndexAdviceCaptureDrop(0);
接続レベルとデータベースレベルの両方の取得を削除するには、この組込みプロシージャを2回コールする必要があります。同じレベルで取得が進行中の間は、この組込みプロシージャを起動することはできません。
|
ノート: この組込みプロシージャの詳細および構文は、『Oracle TimesTen In-Memory Databaseリファレンス』の「ttIndexAdviceCaptureDrop」を参照してください。 |
「索引アドバイザを実行するための準備」と「索引推奨項目およびデータ収集情報の取得」に記載されたステップを、SQLワークロードが索引推奨項目をそれ以上表示せずに実行されるまで繰り返すことができます。新しい索引が適用された表の統計を更新し続けることができ、新しい索引が推奨されるかどうかを確認するために索引アドバイザを再実行できます。
次に、SQLワークロード用のデータ収集フロー、および索引アドバイザの組込みプロシージャによって提供される索引アドバイスを示します。
Command> call ttOptUpdateStats(); Command> call ttIndexAdviceCaptureStart(); Command> SELECT employee_id, first_name, last_name FROM employees; < 100, Steven, King > < 101, Neena, Kochhar > < 102, Lex, De Haan > < 103, Alexander, Hunold > < 104, Bruce, Ernst > ... < 204, Hermann, Baer > < 205, Shelley, Higgins > < 206, William, Gietz > 107 rows found. Command> SELECT MAX(salary) AS MAX_SALARY FROM employees WHERE employees.hire_date > '2000-01-01 00:00:00'; < 10500 > 1 row found. Command> SELECT employee_id, job_id FROM job_history WHERE (employee_id, job_id) NOT IN (SELECT employee_id, job_id FROM employees); < 101, AC_ACCOUNT > < 101, AC_MGR > < 102, IT_PROG > < 114, ST_CLERK > < 122, ST_CLERK > < 176, SA_MAN > < 200, AC_ACCOUNT > < 201, MK_REP > 8 rows found. Command> WITH dept_costs AS (SELECT department_name, SUM(salary) dept_total FROM employees e, departments d WHERE e.department_id = d.department_id GROUP BY department_name), avg_cost AS (SELECT SUM(dept_total)/COUNT(*) avg FROM dept_costs) SELECT * FROM dept_costs WHERE dept_total > (SELECT avg FROM avg_cost) ORDER BY department_name; < Sales, 304500 > < Shipping, 156400 > 2 rows found. Command> call ttIndexAdviceCaptureEnd(); Command> call ttIndexAdviceCaptureInfoGet(); < 0, 1, 0, 0, 9, 6, 2012-07-27 11:44:08.136833, 2012-07-27 12:07:35.410993 > 1 row found. Command> call ttIndexAdviceCaptureOutput(); < 1, create index EMPLOYEES_i1 on HR.EMPLOYEES(SALARY); > < 1, create index EMPLOYEES_i2 on HR.EMPLOYEES(HIRE_DATE); > 2 rows found. Command> call ttIndexAdviceCaptureDrop();
行は、TimesTenデータを保存するために使用されます。TimesTenでは、行内のフィールドに対して次に示すいくつかのデータ型がサポートされています。
1バイト、2バイト、4バイト、8バイトの整数。
4バイトおよび8バイトの浮動小数点数。
ASCIIおよびUnicodeの固定長または可変長の文字列。
固定長および可変長のバイナリ・データ。
固定長の固定小数点数。
hh:mi:ss [AM|am|PM|pm]で表現した時間。
yyyy-mm-ddで表現した日付。
yyyy-mm-dd hh:mi:ss:ffffffで表現したタイムスタンプ。
これらのデータ型の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』のデータ型に関する項を参照してください。
行の挿入または削除を行う処理を実行するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス』の「SQL文」の章で、すべてのSQL文の構文とともに説明されています。
次の項では、行の管理方法について説明します。
行を挿入するには、INSERTまたはINSERT SELECTを発行します。また、ttBulkCpユーティリティ使用することもできます。
例8-6 行の表への挿入
表customerに行を挿入するには、次のように入力します。
Command> INSERT INTO customer VALUES(23125, 'John Smith';
|
ノート: 表に複数の行を挿入する場合は、コードに準備済のコマンドおよびパラメータを使用するとより効率的です。バルク・ロードの終了後、索引を作成してください。 |
シノニムとは、データベース・オブジェクトの別名のことです。シノニムは、オブジェクトの名前や所有者を隠すために使用できるため、セキュリティや利便性を目的として頻繁に使用されます。また、シノニムでSQL文を簡略化できます。シノニムによって独立性が実現するため、シノニムがどのオブジェクトを参照するかにかかわらず、変更なしでアプリケーションの動作が可能になります。シノニムはDML文の他、一部のDDLやTimesTen Cache文で使用できます。
シノニムは、次の2つのクラスに分類されます。
プライベート・シノニム: プライベート・シノニムは、特定のユーザーが所有し、特定のユーザーのスキーマ内に存在します。プライベート・シノニムは、表名、ビュー名、順序名など他のオブジェクト名と同じネームスペースを共有します。したがって、プライベート・シノニムの名前は、同じスキーマ内の表名やビュー名と同じにすることはできません。
パブリック・シノニム: パブリック・シノニムは、すべてのユーザーが所有され、データベースの各ユーザーからアクセスできます。パブリック・シノニムには、すべてのユーザーがアクセスでき、どのユーザー・スキーマにも属しません。したがって、パブリック・シノニムの名前は、プライベート・シノニム名や表名と同じにすることができます。
シノニムを作成して使用するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Databaseセキュリティ・ガイド』のシノニムのオブジェクト権限に関する項を参照してください。
シノニムを作成した後は、次のビューを使用して表示できます。
SYS.ALL_SYNONYMS: 現行のユーザーがアクセスできるシノニムを表示します。詳細は、『Oracle TimesTen In-Memory Databaseシステム表およびビュー・リファレンス』のSYS.ALL_SYNONYMSに関する説明を参照してください。
SYS.DBA_SYNONYMS: データベース内のすべてのシノニムを表示します。詳細は、『Oracle TimesTen In-Memory Databaseシステム表およびビュー・リファレンス』のSYS.DBA_SYNONYMSに関する説明を参照してください。
SYS.USER_SYNONYMS: 現行のユーザーが所有しているシノニムを表示します。詳細は、『Oracle TimesTen In-Memory Databaseシステム表およびビュー・リファレンス』のSYS.USER_SYNONYMSに関する説明を参照してください。
シノニムは、CREATE SYNONYM文を使用して作成します。既存のシノニム廃棄せずに定義を変更するには、CREATE OR REPLACE SYNONYM文を使用します。CREATE SYNONYM文およびCREATE OR REPLACE SYNONYM文では、シノニム名およびシノニムが作成されるスキーマ名を指定します。スキーマを省略すると、シノニムはユーザーのスキーマに作成されます。ただし、パブリック・シノニムを作成する場合、スキーマ名はPUBLICネームスペースで定義されるため、指定しません。
CREATE SYNONYM文またはCREATE OR REPLACE SYNONYM文を発行するには、適切な権限を持っている必要があります。権限の詳細は、『Oracle TimesTen In-Memory Databaseセキュリティ・ガイド』のシノニムのオブジェクト権限に関する項を参照してください。
シノニムのオブジェクト・タイプ: CREATE SYNONYM文およびCREATE OR REPLACE SYNONYM文では、特定のオブジェクトの別名を定義します。オブジェクト・タイプは、表、ビュー、シノニム、順序、PL/SQLストアド・プロシージャ、PL/SQL関数、PL/SQLパッケージ、マテリアライズド・ビューまたはキャッシュ・グループのいずれかです。
|
ノート: サポートされていないオブジェクト・タイプのシノニムを作成しても、そのシノニムは使用できない可能性があります。 |
ネーミングについての考慮事項: プライベート・シノニムは、表名など他のすべてのオブジェクト名と同じネームスペースを共有します。したがって、プライベート・シノニムの名前は、同じスキーマ内の表名や他のオブジェクト名と同じにすることはできません。
パブリック・シノニムには、すべてのユーザーがアクセスでき、特定のスキーマには属しません。したがって、パブリック・シノニムの名前は、プライベート・シノニム名や他のオブジェクト名と同じにすることができます。ただし、SYSスキーマのオブジェクトと同じ名前を持つパブリック・シノニムは作成できません。
次の例では、jobs表に対するプライベート・シノニムsynjobsを作成します。jobs表とsynjobsシノニムの両方にSELECT文を発行して、synjobsからの選択と、jobs表からの選択が同じ結果になることを示します。最後に、作成したプライベート・シノニムを表示するため、例ではSYS.USER_SYNONYMS表に対してSELECT文を実行しています。
Command> CREATE SYNONYM synjobs FOR jobs; Synonym created. Command> SELECT FIRST 2 * FROM jobs; < AC_ACCOUNT, Public Accountant, 4200, 9000 > < AC_MGR, Accounting Manager, 8200, 16000 > 2 rows found. Command> SELECT FIRST 2 * FROM synjobs; < AC_ACCOUNT, Public Accountant, 4200, 9000 > < AC_MGR, Accounting Manager, 8200, 16000 > 2 rows found. Command> SELECT * FROM sys.user_synonyms; < SYNJOBS, TTUSER, JOBS, <NULL> > 1 row found.
シノニムの作成および置換の詳細、例および規則については、『Oracle TimesTen In-Memory Database SQLリファレンス』のCREATE SYNONYMに関する説明を参照してください。
DROP SYNONYM文を使用して、データベースから既存のシノニムを削除します。ユーザーが所有するすべてのオブジェクト(シノニムを含む)を削除しないかぎり、そのユーザーを削除することはできません。
次の例では、パブリック・シノニムpubempを削除しています。
Command> DROP PUBLIC SYNONYM pubemp; Synonym dropped.
パブリック・シノニム、または他のユーザー・スキーマ内のプライベート・シノニムを削除するには、適切な権限が必要です。シノニムの作成および置換の詳細、例および規則については、『Oracle TimesTen In-Memory Database SQLリファレンス』のDROP SYNONYMに関する説明の項を参照してください。
シノニムまたはオブジェクトが新規作成または削除されると、一部のSQL問合せやDDL文の中が無効化されたり、再コンパイルされる場合があります。SQL問合せおよびDDL文の無効化や再コンパイルの動作を次に示します。
パブリック・シノニムに依存するすべてのSQL問合せは、次のいずれかのオブジェクトと同じ名前のプライベート・シノニムが作成されると無効化されます。
プライベート・シノニム
表
ビュー
順序
マテリアライズド・ビュー
キャッシュ・グループ
プロシージャ、関数およびパッケージを含むPL/SQLオブジェクト
プライベート・オブジェクトまたはスキーマ・オブジェクトに依存するすべてのSQL問合せは、プライベート・オブジェクトまたはスキーマ・オブジェクトが削除されると無効化されます。
データベースに関するメタデータ情報を取得するために問い合せることができるローカル(V$)またはグローバル(GV$)システム・ビューがいくつかあります。
TimesTen Scaleoutの場合:
V$ビューには、アプリケーションが接続されている要素のデータが含まれます。
GV$ビューには、データベースのすべての要素のV$ビューの内容が含まれます。
TimesTen Classicの場合:
V$ビューには、アプリケーションが接続されているデータベースのデータの行が含まれています。
GV$ビューには、対応するV$ビューと同じ内容が含まれています。
また、TimesTen組込みプロシージャに基づいた問合せ可能なビューもいくつかあります。詳細は、『Oracle TimesTen In-Memory Databaseシステム表およびビュー・リファレンス』のシステム表およびビューに関する項を参照してください。