6About Siebel Table Partitioning
About Siebel Table Partitioning
This chapter provides information on partitioning large tables in Siebel Business Applications. Partitioning a DB2 table is not a complicated procedure, but to optimally partition Siebel tables, it is critical that you understand how partitioning works in DB2.
This chapter consists of the following topics:
About Siebel Partitioning
Partitioning table spaces on DB2 allows tables to be spread across multiple physical partitions based on a partitioning key, a set of key value ranges for each partition, and optionally, a partitioning index. Using partitioned table spaces increases the maximum size of a table and improves the manageability of large tables.
Partitioning EIM table spaces by batch number improves EIM performance for batching and parallel processing, and allows distribution of key ranges across multiple data sets.
Any table can be partitioned during the installation or upgrade process. You can define partitioned table spaces and key ranges for Siebel tables during or after installation, based on your business requirements. For a complete list of prepartitioned Siebel tables, see Prepartitioned Siebel Tables.
You can partition tables yourself by following Oracle’s guidelines, or you can take advantage of the default partitioning scheme that Oracle developed, based on customer experience using the Siebel data model with DB2 for z/OS. If you use the Siebel default partitions, you can either accept them as they are, or you can reconfigure them to suit your requirements.
DB2 for z/OS Version 8 introduced a number of new partitioning capabilities. None of these capabilities are required to run Siebel Business Applications, but many of the key features are supported in Siebel releases since 8.0, including the following:
You can specify up to 1296 partitions for tables partitioned on the last 2 bytes of ROW_ID. For further information, see Partitioning for Even Data Distribution. For tables that use any other partitioning key, up to 4096 partitions can be specified.
The current Siebel release supports table-controlled and index-controlled partitioning. If you use table controlled partitioning, you do not have to maintain indexes that are used for partitioning only.
With table-controlled partitioning, clustering is separated from partitioning. The partitioning index is not automatically the clustering index, so data in a partitioned table space does not have to be clustered by the partitioning key. Data can be clustered by partition using a secondary unique index that you choose.
Note: Clustering related records within a partition generally improves performance and is particularly important for tables with non-unique access paths, for example, intersection tables.Partitioning indexes can be defined for indexes if the associated table uses table-controlled partitioning and is not partitioned by ROW_ID. For further information, see Considerations in Partitioning Tables.
About Partitioning Keys
When a table is created on a partitioned table space, the table is assigned a partitioning key that is composed of one or more columns. Value ranges are assigned to each partition based on value ranges within the partitioning key. The value ranges determine which partition a particular row is assigned to.
How key values are specified for each table partition depends on whether the table uses table-controlled or index-controlled partitioning. With index-controlled partitioning, a partitioning index specifies the partitioning key and the key value ranges (limit keys) that determine how data is partitioned. With table-controlled partitioning, the partition key and key value ranges are contained in the table definition, so a partitioning index is not required. In the current release, partitioned tables use table-controlled partitioning by default.
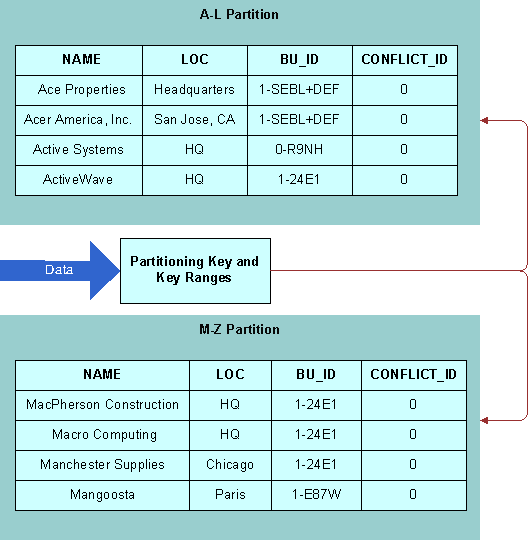
An example of partitioning in shown in the following figure. You can divide a large table such as S_ORG_EXT (which holds a list of new accounts) to store records of names beginning with letters A-L in one partition and records of names beginning with letters M-Z in another partition. In this example, the partitioning key is the Name column and a partitioning index defines the key ranges (A-L; M-Z) for the partitioning column. A key range must be specified for each partition.
Partitioning and the Storage Control Files
Partitioning is defined in the Siebel storage control files. You can use one of the following storage control file templates shipped with your Siebel Business Applications to partition tables:
storage_p.ctl. This template is the database storage layout for the Siebel Schema with partitioning for ASCII encoding.
storage_p_u.ctl. This template is the database storage layout for the Siebel Schema with partitioning for Unicode encoding.
storage_p_e.ctl. This template is the database storage layout for the Siebel Schema with partitioning for EBCDIC encoding.
Storage control files are described in detail in Configuring the Siebel Database Layout.
Each of the partitioning storage control file templates contain the same Siebel-recommended partitioning schema. The templates provide a set of 17 partitioned base tables for the Horizontal product line and a set of 24 partitioned base tables for Siebel Industry Applications. The default partitioning scheme is optimized for online activities from the Siebel Client.
Siebel Business Applications’ partitioning templates provide 10 partitions for each partitioned table. You select the number of partitions for your implementation based on your business needs, and define partitioning keys based on the number of partitions.
If you want to customize the Siebel table-partitioning layout, you can do so by editing the appropriate storage control file template directly. Alternatively, you can use the Siebel Database Storage Configurator (dbconf.xls) to modify the template (recommended). For more information, see Partitioning Tables and Indexes Using the Database Storage Configurator.
Considerations in Partitioning Tables
Careful planning, requirements analysis, and monitoring are necessary to achieve optimal partitioning and optimal performance. If partitioning is not planned and carried out carefully, performance and scalability are adversely affected. Decide which Siebel tables to partition and how to partition them on the basis of table size and usage in your deployment. You can partition any table in accordance with your business requirements; you can select all the tables that provide for partitioning, or you can select a subset of them.
About Choosing a Partitioning Key Column
You can use any column from a Siebel base table as the partitioning key for a Siebel table but you cannot use extension columns you create for partitioning purposes. In deciding which column is most appropriate for partitioning, consider data access and data distribution factors. You also need to determine the number of partitions your implementation requires.
When choosing a partitioning key for a Siebel table, follow all the rules, restrictions, and concerns listed in the IBM DB2 documentation. Factors to consider include data distribution and potential updates of partitioning keys. For example, when partitioning keys are updated, system performance is adversely affected. When choosing partitioning keys, select fields that are seldom updated, when possible. This helps avoid performance problems.
The partitioning key that provides optimum performance and scalability varies according to the type of table being partitioned. For example, if in an organization Contact records are retrieved by LAST_NAME range predicates, for example, LAST_NAME LIKE 'Huang%', then partitioning on the LAST_NAME column is recommended to keep all similar records in one partition, while clustering on the LAST_NAME column ensures the records returned by the query are contiguous.
However, a different approach is required for child tables, especially those in a one-to-many (1:M) relationship with the parent table. If child tables are partitioned, it is recommended that you use the PAR_ROW_ID column for both the partitioning and clustering keys to reduce the input/output steps required to return related child records.
As an alternative to using Siebel table columns as partitioning keys, you can use either the Siebel PARTITION_COLUMN or MEMBER_NAME columns. These columns are used for partitioning purposes only. The PARTITION_COLUMN column is a physical column that is defined in the storage control file, but is not accessed by the Siebel application. It exists to provide a method of ensuring even data distribution across table partitions where none of the table columns are good candidates for partitioning. The column is populated with data using a trigger to generate the partitioning value for each row. For additional information on the role of PARTITION_COLUMN, see Partitioning for Even Data Distribution. For information on the role of the MEMBER_NAME column, see Partitioning Strategies for Special Types of Tables.
About Table-Controlled Partitioning and Using Indexes
It is recommended that you use table-controlled partitioning with Siebel database tables.
In the current Siebel release, partitioned tables use table-controlled partitioning by default. If you use table-controlled partitioning, partitioning is defined at the table level so you do not require a partitioning index. Maintaining indexes that are used for partitioning purposes only is no longer necessary, which reduces storage requirements and allows you to select a secondary index as the clustering index.
About Choosing a Clustering Index
In previous versions of DB2, the partitioning index was automatically the clustering index. In DB2 for z/OS Version 8 and later releases, data can be clustered by any index. Data in a partitioned table space no longer needs to be clustered by the partitioning index, although in many installations, this might be the most efficient option. For example, it is recommended that child tables are partitioned so that all records related by the parent table ROW_ID are contiguous within the same partition and a similar approach is recommended for intersection tables. By choosing the most appropriate clustering index for each of the Siebel-partitioned tables, you can optimize query performance.
In choosing a clustering index, consider both day-to-day online access to the Siebel tables and processes such as EIM, Siebel Remote, Assignment Manager, and Workflow. The recommended clustering index for each of the Siebel-partitioned base tables is shown in the following table.
Only one clustering index can be defined for a table. When you have altered the index to make it clustering, run the REORG utility on the table space and then run RUNSTATS.
About Using Partitioning Indexes
Although the prepartitioned Siebel tables use table-controlled partitioning, you can also define partitioning indexes for Siebel tables that are not partitioned using PARTITION_COLUMN. For information on the role of PARTITION_COLUMN in partitioning tables, see Partitioning for Even Data Distribution.
You might want to define a partitioning index for a Siebel table-controlled partitioned table to improve query performance, if, for example, the table and its associated index are very large. You can partition the index provided it has the same columns and limit keys as the partitioning key values defined for the table.
Partitioning indexes are distinguished from partitioned indexes. A partitioning index must:
Contain all of the columns from the partitioning key, at a minimum
Note: A partitioning index can also contain additional columns, for example, columns required to support optimal clustering or performance enhancement.The columns must be in the same order
The columns must have the same sort order
A partitioned index does not have the same partitioning key values as the key values on the table. Siebel Business Applications do not support partitioned indexes.
Partitioning indexes are defined in the storage control file templates for the prepartitioned Siebel base tables that do not use PARTITION_COLUMN. These tables are:
S_CONTACT
S_OPTY
S_ORG_EXT
EIM_ACCOUNT
EIM_PROD_INT
EIM_OPTY
EIM_CONTACT
EIM_SRV_REQ
EIM_ACTIVITY
EIM_DEFECT
EIM_ASSET
EIM_ACCNT_CUT
EIM_FN_CONTACT1
EIM_FN_ASSET
EIM_FN_ASSET1
EIM_FN_ASSET2
EIM_FN_INSITM1
EIM_FN_INSCLM1
EIM_FN_ORGGRP
EIM_ASSET_AT
EIM_VHCL_SRV
For more information about the Siebel partitioned tables, see Prepartitioned Siebel Tables.
About Table Partitioning Methods
Siebel CRM supports two methods for partitioning tables:
Partitioning Based on Business Data
In this partitioning method, a table is partitioned based on existing columns in the Siebel Schema. For example, S_OPTY is partitioned by columns in the U1 index. In this case, no special action is needed except to define the key ranges and number of partitions.
If multiple organizations are defined in your Siebel application, partitioning on the BU_ID column might be more efficient than using the Siebel-supplied partitioning index. In these cases, clustering on the BU_ID column, then other relevant columns, ensures related records are contiguous within a partition for a given business unit, which optimizes query performance.
If your data analysis reveals that the number of records associated with business units is skewed, so that some business units have few records, it might be appropriate to allocate groups of business units to one partition; in these cases, choose your clustering key column with care.
Partitioning for Even Data Distribution
This partitioning method involves partitioning a table using an additional partitioning column, PARTITION_COLUMN, designed specifically for Siebel partitioning with even data distribution. This column is populated with data using a BEFORE INSERT trigger option to generate the partitioning value for each row.
Most Siebel tables are tied together by the ROW_ID column from a parent table. Columns with an _ID suffix are used to define a parent-child relationship, for example, OU_ID. These columns might seem to be good partitioning candidates because they support the DB2 access path but, in fact, these columns are poor candidates for partitioning because ROW_IDs are generated in sequential order. (An exception is if the values in a column with an _ID suffix identify groups of related records; in this case, the column might be a suitable partitioning key.)
To resolve the limitation caused by the sequential order of ROW_ID, Siebel Business Applications provide a column, PARTITION_COLUMN, which is used only for partitioning purposes. It is a physical column defined in a storage control file, but it is not a part of the Siebel Repository. It is important that you continue to use the name PARTITION_COLUMN if the Siebel application is to recognize this column. You must also define this column as NOT NULL WITH DEFAULT.
A DB2 BEFORE INSERT trigger is used to populate the PARTITION_COLUMN values; it is defined in the Siebel storage control file. This trigger generates a random number between 00 and 10 and uses it to populate PARTITION_COLUMN. The partition limit keys are also numbers between 01 and 10. Rows are assigned to each of the 10 partitions based on the value of PARTITION_COLUMN generated for the row. For example, if the number generated for PARTITION_COLUMN is 6, the row is assigned to the partition with a limit key value of 6. By using a trigger to populate the columns, you can partition tables that do not have good candidate columns for a partitioning key due to their data content. Using a trigger, you can still generate values that distribute the data well.
The EIM tables and some of the prepartitioned base tables do not use PARTITION_COLUMN. For information on partitioning EIM tables, see EIM Tables and Partitioning.
When partitioning a nonpartitioned Siebel table, or when customizing a prepartitioned table, you need to assess whether PARTITION_COLUMN is the most appropriate partitioning key for the specific table. To improve query performance, ensure the partitioning key you use keeps related records together within each partition.
Example of Partitioning the S_ADDR_ORG Table
You can use the Siebel-selected partitioned tables exactly as they are shipped. You can also customize the Siebel partitioned tables, or partition other Siebel schema base tables. For information on customizing the partitioned tables or partitioning nonpartitioned tables, see Partitioning Tables and Indexes Using the Database Storage Configurator.
This topic gives one example of how to partition a table and a table space. The example definitions in this topic reflect a partitioning scenario for the S_ADDR_ORG table, which resides in the H0401504 partitioned table space. The Siebel partitioning template used for this scenario is the storage_p_e.ctl storage control file.
In a storage control file, the partitioned table space is defined with two types of storage control file objects: Tablespace and Tspart (table space partitions). The storage control file objects related to partitioning are:
Tablespace
Tspart (table space partitions)
Table
PartitionBase (defines the partitioning key for table-controlled partitioned tables)
PartitionPart (defines the key value ranges used for partitioning data for table-controlled partitioned tables)
IndexBase (base definition of a partitioning index)
IndexPart (index partitions)
A table definition always includes the same options, whether the corresponding table space is partitioned or not. However, the table space, partition and index objects include different options, depending on whether the table space is partitioned or nonpartitioned.
Example of a Table Object Definition
The following is an example object definition for table S_ADDR_ORG:
[Object 6855] Type = Table Name = S_ADDR_ORG Database = D0059504 Tablespace = H0401504 Partitions = 10 Clobs = No
Example of a Table Space Definition
The definition for Tablespace object H0401000 follows:
[Object 3643] Type = Tablespace Name = H0401504 Database = D0059504 LockSize = Page Bufferpool = BP16K1 Define = No Partitions = 10 Lockpart = Yes
You can easily identify a partitioned table space by reviewing the Partitions option in the Tablespace object in the storage control file. If the Partitions option is greater than zero, then the table space is partitioned and requires additional objects, such as Tableparts (Tspart) and partition or index objects. The number of Tspart objects is equal to the number of partitions.
Example of Definitions for Table Space Partitions
The example for the Tablespace object in Example of a Table Space Definition specifies 10 partitions; therefore, ten Tspart objects must be defined, as shown in the following example for objects 3644 through 3653).
[Object 3644] Type = Tspart Name = H0401504 PartNum = 1 ... [Object 3653] Type = Tspart Name = H0401504 PartNum = 10
Example of the DDL for the Partitioned Table Space
The storage control file definitions for the partitioned table space in the previous example result in the following output DDL statements:
CREATE TABLESPACE H0401504 IN D0059504 USING STOGROUP SYSDEFLT PRIQTY 48 SECQTY 1440 FREEPAGE 0 PCTFREE 17 LOCKPART YES DEFINE NO NUMPARTS 10 ( PART 1 USING STOGROUP SYSDEFLT , PART 2 USING STOGROUP SYSDEFLT , PART 3 USING STOGROUP SYSDEFLT , PART 4 USING STOGROUP SYSDEFLT , PART 5 USING STOGROUP SYSDEFLT , PART 6 USING STOGROUP SYSDEFLT , PART 7 USING STOGROUP SYSDEFLT , PART 8 USING STOGROUP SYSDEFLT , PART 9 USING STOGROUP SYSDEFLT , PART 10 USING STOGROUP SYSDEFLT ) BUFFERPOOL BP16K1 LOCKSIZE PAGE LOCKMAX 0 COMPRESS YES
Example of a Partition Definition
If you use the table S_ADDR_ORG, the column OU_ID appears to be a good candidate for a partitioning key. However, OU_ID contains data in the Siebel row ID format and row IDs are generated in ascending order. Instead a trigger is used to generate a random number between 00 and 10 and this number is stored in a new physical PARTITION_COLUMN. This column is defined in the storage control file for S_ADDR_ORG.
For tables that use table-controlled partitioning, you must define two types of objects in the storage control file: PartitionBase and PartitionPart. These objects specify the partitioning key column and partition value ranges. An example definition for each is shown.
PartitionBase Definition
The example for object 9401 contains a DB2 BEFORE INSERT trigger to populate PARTITION_COLUMN. This is always defined by the SpecialCol keyword in a PartitionBase section. The syntax for the trigger implements the column PARTITION_COLUMN to S_ADDR_ORG as CHAR(2) NOT NULL with default of a space. It also implements a trigger to populate the partitioning column.
[Object 9401] Type = PartitionBase Name = S_ADDR_ORG Partitions = 10 SpecialCol = PARTITION_COLUMN WCHAR(2) NOTNULL DEFAULT ' ' Function = BEGIN ATOMIC SET N.PARTITION_COLUMN = RIGHT(DIGITS(INT(MOD(RAND()* 9991, 10)) + 1), 2); END Column 1 = PARTITION_COLUMN ASC
The performance overhead of using a trigger is measured as a percentage of the inserts. Performance overhead depends on several factors, including row length and the number of indexes in the table.
Triggers that use the S_PARTY partitioned table space, 10 partitions, 14 columns, and 443 bytes with 8 indexes, have demonstrated a performance overhead of less than 1% for each insert.
PartitionPart Definition
In the example for object 9401, the PartitionBase section defines ten (10) partitions. Therefore, it requires ten PartitionPart objects. These are illustrated in the example for objects 9402 through 9411:
[Object 9402] Type = PartitionPart Name = S_ADDR_ORG PartNum = 1 LimitKey = '01' ... [Object 9411] Type = PartitionPart Name = S_ADDR_ORG PartNum = 10 LimitKey = MAXVALUE
Siebel Business Applications provide generic values for the partitioning keys. Review these LimitKey values in the PartitionPart object and change them to suit the special requirements of your implementation.
Example of the DDL for a Partitioned Table
The storage control file definitions for the partitioned table in the previous example result in the following output DDL statements:
CREATE TABLE CQ10L007.S_ADDR_ORG ( "ACTIVE_FLG" CHAR(1) DEFAULT 'Y' NOT NULL,
"ADDR" VARCHAR(200),
"ADDR_LINE_2" VARCHAR(100),
"ADDR_LINE_3" VARCHAR(100),
"ADDR_NAME" VARCHAR(100) DEFAULT 'x' NOT NULL,
"ADDR_NUM" VARCHAR(30),
"ADDR_TYPE_CD" VARCHAR(30),
"ALIGNMENT_FLG" CHAR(1) DEFAULT 'N' NOT NULL,
"BL_ADDR_FLG" CHAR(1) DEFAULT 'Y' NOT NULL,
"BU_ID" VARCHAR(15),
"CITY" VARCHAR(50),
"COMMENTS" VARCHAR(255),
"CONFLICT_ID" VARCHAR(15) DEFAULT '0' NOT NULL,
"COUNTRY" VARCHAR(30),
"COUNTY" VARCHAR(50),
"CREATED" TIMESTAMP DEFAULT NOT NULL,
"CREATED_BY" VARCHAR(15) NOT NULL,
"DB_LAST_UPD" TIMESTAMP,
"DB_LAST_UPD_SRC" VARCHAR(50),
"DCKING_NUM" NUMERIC(22, 7) DEFAULT 0,
"DFLT_SHIP_PRIO_CD" VARCHAR(30),
"DISA_CLEANSE_FLG" CHAR(1) DEFAULT 'N' NOT NULL,
"EMAIL_ADDR" VARCHAR(100),
"FAX_PH_NUM" VARCHAR(40),
"INTEGRATION2_ID" VARCHAR(30),
"INTEGRATION3_ID" VARCHAR(30),
"INTEGRATION_ID" VARCHAR(30),
"LAST_UPD" TIMESTAMP DEFAULT NOT NULL,
"LAST_UPD_BY" VARCHAR(15) NOT NULL,
"LATITUDE" NUMERIC(22, 7),
"LONGITUDE" NUMERIC(22, 7),
"MAIN_ADDR_FLG" CHAR(1) DEFAULT 'Y' NOT NULL,
"MODIFICATION_NUM" NUMERIC(10, 0) DEFAULT 0 NOT NULL,
"NAME_LOCK_FLG" CHAR(1) DEFAULT 'N' NOT NULL,
"OU_ID" VARCHAR(15) NOT NULL,
"PARTITION_COLUMN" CHAR(2) DEFAULT ' ' NOT NULL,
"PH_NUM" VARCHAR(40),
"PROVINCE" VARCHAR(50),
"ROW_ID" VARCHAR(15) NOT NULL,
"SHIP_ADDR_FLG" CHAR(1) DEFAULT 'Y' NOT NULL,
"STATE" VARCHAR(10),
"TRNSPRT_ZONE_CD" VARCHAR(30),
"ZIPCODE" VARCHAR(30)) IN D0059504.H0401504
PARTITION BY (PARTITION_COLUMN ASC)(
PARTITION 1 ENDING AT ('01') ,
PARTITION 2 ENDING AT ('02') ,
PARTITION 3 ENDING AT ('03') ,
PARTITION 4 ENDING AT ('04') ,
PARTITION 5 ENDING AT ('05') ,
PARTITION 6 ENDING AT ('06') ,
PARTITION 7 ENDING AT ('07') ,
PARTITION 8 ENDING AT ('08') ,
PARTITION 9 ENDING AT ('09') ,
PARTITION 10 ENDING AT (MAXVALUE) )
/
CREATE TRIGGER CQ10L007.PTH0401 NO CASCADE BEFORE INSERT ON CQ10L007.S_ADDR_ORG
REFERENCING NEW AS N FOR EACH ROW MODE DB2SQL BEGIN ATOMIC SET N.PARTITION_COLUMN =
RIGHT(DIGITS(INT(MOD(RAND()* 9991, 10)) + 1), 2); END
/
CREATE UNIQUE INDEX CQ10L007.S_ADDR_ORG_U1 ON CQ10L007.S_ADDR_ORG ("ADDR_NAME",
"OU_ID", "CONFLICT_ID") USING STOGROUP SYSDEFLT PRIQTY 48 SECQTY 1440 PCTFREE 17
DEFINE NO CLUSTER BUFFERPOOL BP2
/
The trigger name, PTH0401, is based on a number assigned to the S_ADDR_ORG table within the Siebel Repository. The S_ADDR_ORG table is defined in table space H0401504. The trigger name and the table space name are both based on the number assigned to the S_ADDR_ORG table and stored in the table Group Code in the Siebel Repository.
The table is partitioned on the PARTITION_COLUMN column, which is populated by the trigger PTH0401. The index S_ADDR_ORG_U1 is defined with the CLUSTER parameter so it becomes the clustering index; that is, rows within each partition are clustered according to the key of S_ADDR_ORG_U1.
Schedule routine REORGs of the table space and index space regularly to sustain clustering order. Running REORGs regularly accommodates insert activity and reclaims PCTFREE and FREEPAGE definitions.
When you are defining key ranges, remember that EBCDIC sorting order differs to Unicode and ASCII sorting orders. Numeric characters precede alphabetical characters in ASCII and Unicode, but the opposite applies in EBCDIC.
Partitioning Strategies for Special Types of Tables
This topic explains the special considerations you must take into account when partitioning tables that support specific Siebel business processes, such as Siebel Remote, Siebel Assignment Manager, Siebel Workflow, and Siebel Enterprise Integration Manager (EIM).
The following topics describe partitioning considerations for specific tables:
Siebel Remote Transaction Logging Tables
This topic explains the special considerations you must take into account when partitioning tables that support Siebel Remote.
Siebel Remote uses the S_DOCK_TXN_LOG table for transaction logging. All user changes on the Siebel Server are logged in this table. Changes are then routed to mobile users according to their responsibilities and user privileges.
To reduce the performance impact on the coupling facility in such a data sharing environment, avoid giving multiple members ReadWrite access to the same partition. You can do this by partitioning the table S_DOCK_TXN_LOG by the MEMBER_NAME column. The MEMBER_NAME column is populated by the CURRENT MEMBER special register, thereby ensuring that all write processes associated with the member affect only one partition.
Partitioning by MEMBER_NAME is not the default for the S_DOCK_TXN_LOG table, because such partitioning is only required for a data sharing environment. Therefore, the names of the data sharing members are not known by the Siebel application.
To specify MEMBER_NAME as the partitioning key, create a PartitionBase object for the table in the storage control file using the syntax in the following example:
[Object 8837] Type = PartitionBase Name = S_DOCK_TXN_LOG Partitions = 10 Column 1 = MEMBER_NAME
Turning Off Transaction Logging
If you do not have mobile users or if you intend to use your mobile users for extract only, it is recommended that you turn off transaction logging to improve performance.
To turn off transaction logging
Navigate to the Administration - Siebel Remote screen, and then the Remote System Preferences view.
In the Remote System Preferences form, clear the Enable Transaction Logging check box.
S_ESCL_REQ and S_ESCL_LOG Tables
The tables S_ESCL_REQ and S_ESCL_LOG, which are used by Assignment Manager and Siebel Business Process Designer, tend to grow very large. S_ESCL_REQ is processed based on the GROUP_ID, whereas S_ESCL_LOG is processed by RULE_ID.
You can partition these tables in one of the following ways:
Hard-code the actual values for GROUP_ID and RULE_ID.
This approach is recommended when the number of groups is static. You can define additional partitions to accommodate new values that are unknown at creation time. To use this option, first define the groups and then extract the GROUP_ID values you want to use for partitioning.
Add the PARTITION_COLUMN and a trigger to populate the column.
The number of partitions you define should ensure that data from multiple groups goes into multiple partitions. Start with 36 partitions, because this is the base number for the Siebel row ID.
EIM Tables and Partitioning
To speed up Enterprise Integration Manager (EIM) load and reduce I/O (input and output) contention, spread partitions for EIM tables across the entire I/O subsystem.
It is recommended that you partition EIM tables based on their U1 indexes, that is, the IF_ROW_BATCH_NUM and ROW_ID columns. This method of partitioning allows an EIM batch input to be assigned to one partition, thereby allowing multiple EIM batches to be run in parallel.
The sample storage control files shipped with Siebel Business Applications contain partitioning for a number of EIM tables based on their IF_ROW_BATCH_NUM column; these are the tables that are recommended for partitioning. You can accept this recommended partitioning approach or use the Database Storage Configurator to perform your own custom partitioning of EIM tables.
To compute the optimal number of partitions for an EIM table, divide the number of rows in the EIM table by the number of parallel processes you intend to run. The result is the approximate number of partitions you need to create for the table.
Example of Using a Non-U1 Partitioning Index
Although the recommended partitioning key for EIM tables is usually the U1 index (IF_ROW_BATCH_NUM and ROW_ID), in some cases, you might need to consider a different partitioning key.
The following examples illustrate how you might partition the EIM tables that are used to populate the S_ORG_EXT and S_OPTY target base tables. Using the columns shown ensures that the data is physically clustered based on the clustering index keys of the target tables.
EIM_ACCOUNT IF_ROW_BATCH_NUM ASC, NAME ASC, ACCNT_BI ASC, LOC ASC
EIM_OPTY IF_ROW_BATCH_NUM ASC, OPTY_NAME ASC
For information on using the Database Storage Configurator to perform your own custom partitioning of EIM tables, see Modifying a Storage Control File Using the Database Storage Configurator.
Prepartitioned Siebel Tables
Siebel Business Applications provide the partitioned tables shown in the following.in the storage control file templates. The database tables listed represent partitioned Core product tables; seven exceptions are identified as Siebel Industry Applications (SIA) product tables.
For each table in the following table, the partitioning key columns for the table are listed, as is the recommended clustering index for the table. A partitioning index is defined for three of the partitioned tables (S_CONTACT, S_OPTY and S_ORG_EXT); the name of the index is listed for these tables.
When determining the partitioning strategy for your implementation, you must assess whether the partitioning key columns and recommended clustering indexes specified for the prepartitioned tables are appropriate for your environment. For example, in assessing the most appropriate partitioning column to use for intersection tables, take into account the relationship of candidate partitioning columns to their respective parent tables. Additionally, if multiple organizations are defined in your Siebel application, the BU_ID column might be the most appropriate partitioning column for a table. For information on customizing partitioned tables, see Changing the Number of Table Space Partitions.
Table Prepartitioned Siebel Tables with Physical Columns
| Table | Partitioning Key Columns | Recommended Clustering Index |
|---|---|---|
|
|
S_ACT_EMP_M1 |
|
|
|
|
|
|
Siebel Industry Applications (SIA) table |
|
|
|
|
S_ASSET_U1 (ASSET_NUM, PROD_ID, REV_NUM, BU_ID, CONFLICT_ID) |
|
|
|
|
|
|
|
|
|
A partitioning index, S_CONTACT_M12, is defined for this table. |
Note: If multiple organizations are defined in your Siebel application, the BU_ID column might be a more effective partitioning key than the LAST_NAME column. In this case, cluster on the S_CONTACT_M14 index (BU_ID, LAST_NAME, FST_NAME, PRIV_FLG).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A partitioning index, S_OPTY_U1, is defined for this table. |
Note: If multiple organizations are defined in your Siebel application, the BU_ID column might be a more effective partitioning key than the NAME column. In this case, cluster on the BU_ID, NAME columns.
|
|
|
|
Note: If your Siebel application is configured to use My Views to access the S_OPTY_POSTN table by the POSITION_ID column, cluster on the S_POSTN_CON_M12 index.
|
A partitioning index, S_ORG_EXT_U1, is defined for this table. |
|
|
|
|
|
|
|
|
|
|
Note: If the
S_POSTN_CON table is not implemented as partitioned, cluster on either the POSTN_ID or the CON_ID column, depending on the one-to-many relationship of each column to its parent table.
|
|
|
|
|
|
|
Partitioning Tables and Indexes Using the Database Storage Configurator
You can use the Database Storage Configurator file (dbconf.xls) to partition tables or customize the prepartitioned tables after you have worked out a partitioning scheme.
The following sections describe how to partition a nonpartitioned table and how to customize a partitioned table. Partitioning is carried out at the table level; however, you must also adjust the related table space and partitioning key values.
Partitioning a Table
The following procedure describes how to partition a nonpartitioned table in a table space.
To partition a table
Launch the Database Storage Configurator, and import the storage control file you want to amend.
For information on this task, see Modifying a Storage Control File Using the Database Storage Configurator.
Click Structures, Table, and then select the table you want to partition.
Click the Partition Table button.
You are prompted to specify the number of partitions you want to define for the table. Enter the appropriate number and click OK.
Click the Structures tab, and then TBL Partition Base; enter values for the following fields:
SpecialCol.
Function
Column 1
In the Column 1 field, enter the name of the column to be used to partition the table.
Enter values for the SpecialCol and Function fields if you are partitioning the table using PARTITION_COLUMN. For information on specifying values for these fields, see Example of Partitioning the S_ADDR_ORG Table.
Save the values you entered by stepping off the cell but keep your cursor in the same row.
Click the Show Partition Parts button.
Enter LimitKey values for each partition you created for the table. As you step off each cell, the value is saved.
Select the Structures tab, and then the Tablespace tab, and locate the table space associated with the table you have partitioned.
The table space is automatically marked as partitioned.
Select the table space and click the Show TSPARTS button.
You can specify values for any of the Tsparts fields or leave them empty to accept the default values. For information on the default values, see Default Objects in Storage Control Files.
Make any other edits needed to the template you are using and follow the steps under Modifying a Storage Control File Using the Database Storage Configurator to verify and save your changes.
Changing the Number of Table Space Partitions
The following procedure describes how to increase or decrease the number of partitions for a partitioned table in a given table space.
To change the number of table space partitions
Launch the Database Storage Configurator, and import the storage control file you want to amend as described in Modifying a Storage Control File Using the Database Storage Configurator.
Click Structures, and then Table, and locate the name of the table space associated with the table for which you want to change the number of partitions.
Click Structures, and then Tablespace, and locate the appropriate table space.
Change the value in the Partitions column as appropriate. Save the new value by stepping off the cell but keep your cursor in the same row.
Click Show TSPARTs.
If you have changed the number of partitions to a lower value, a message appears indicating that there are additional table space partitions for this table. Review and delete the additional partitions.
If you have increased the number of partitions for a table space, you receive a message indicating that the partitions have been created.
Click Structures, TBL Partition Base, and locate the table you are amending.
In the Partitions column, update the number of partitions to match the number of table space partitions you entered previously, then step off the cell to save the value but keep your cursor on the same row.
Click Show Partition Parts.
If you decreased the number of partitions, review and delete the additional Partition Part definitions.
If you increased the number of partitions, review the values in the LimitKey column, and update them appropriately.
Note: When using Excel, you must type the first quote as two single quotes. Excel saves it as a single quote when you step off the cell. If you only enter a single quote, Excel does not save it.
Make any other edits needed to the template you are using and follow the steps under Modifying a Storage Control File Using the Database Storage Configurator to verify and save your changes.