Load Oracle Identity Role Intelligence Data Using Data Ingestion (Day 0)
Introduction
Data ingestion is the process of importing data into the Oracle Identity Role Intelligence (OIRI) database. OIRI uses a Command Line Interface (CLI) tool to fetch and load data from external sources such as the Oracle Identity Governance (OIG) database or flat files.
As part of the data ingestion process, data is loaded into the following tables of the OIRI database:
- USERS
- APPLICATIONS
- ACCOUNTS
- ENTITLEMENTS
- ASSIGNED_ENTS
- ROLES
- ROLE_USER_MSHIP
- ROLE_ENT_COMPOSI
- ROLE_HIERARCHY
- ORGANIZATIONS
You can run the data import process in the following modes:
-
Full
You run data import in full mode when you first install OIRI and want to load all the data from the source to the OIRI database. This is called Day 0 data import. If you run data import in full mode after Day 0, which is referred to as Day N data import, when the OIRI database already contains entity data, the existing data is truncated and new data from the sources is loaded.
-
Incremental
You run data import in incremental mode on Day N, which matches the data in OIRI and the source, and loads only the data that has been added, updated, or deleted in the source after the last data import run.
When you install OIRI, you set the default data ingestion sources. These can include:
- OIG Database
- Flat Files
- OIG Database and Flat Files
Objectives
On completion of this lab, you should be able to load data into the OIRI database using the data ingestion method.
- Update data ingestion configuration
- Perform dry run of the data ingestion and validate the input database
- Perform the data ingestion process
- Review the results
Prerequisites
Before starting this tutorial you must have:
- A running Oracle Identity Role Intelligence container. Instructions on how to download and install the OIRI container can be found in Installing and Configuring Oracle Identity Role Intelligence
- Flat files containing data for loading into the OIRI database. Sample data used in this tutorial can be reviewed in the oiri_ding_etl_samples.zip
- NFS mount location exists that can be used for creating a persistent volume which will be used across the Kubernetes cluster nodes. For the purposes of this tutorial this is assumed to be
/nfs. - The following directories exist (with the same or similar naming):
- DING :
/nfs/ding - OIRI :
/nfs/oiri - LOCAL :
/local/k8s/
- DING :
Configure the Data Ingestion Process
Before running the data ingestion process you should complete the following configuration tasks.
-
Copy the Kubernetes Certificate Authority certificate to the data ingestion directory,
/nfs/ding.cp /etc/kubernetes/pki/ca.crt /nfs/ding/ -
Run the
oiri-dingcontainer. This allows you to issue data ingestion commands and configure data ingestion specific parameters.docker run -d --name ding-cli \ -v /nfs/ding/:/app/ \ -v /nfs/oiri/:/app/oiri \ -v /local/k8s/:/app/k8s \ oiri-ding-12.2.1.4.<TAG> \ tail -f /dev/nullConfirm that the container is running.
docker ps -a | grep ding-cliShould return output similar to:
968676d7db91 oiri-ding-12.2.1.4.<TAG> "tail -f /dev/null" 21 seconds ago Up 14 seconds ding-cli -
Connect to the
ding-clicontainer and verify parameters.Connect to the
ding-clicontainer.docker exec -it ding-cli bashRun the
ding-clicommand to verify the data ingestion configuration.ding-cli --config=/app/data/conf/config.yaml data-ingestion verify /app/data/conf/data-ingestion-config.yamlYou will see output similar to the following.
###### ### # # ##### ##### # ### # # # ## # # # # # # # # # # # # # # # # # # # # # # # # #### ##### # # # # # # # # # # # # # # # # # # ## # # # # # # ###### ### # # ##### ##### ####### ### Verifying Data Ingestion Config. Wallet and DB connections will be validated SUCCESS: Data Ingestion Config is valid. -
Verify that flat files are enabled as a data source.
Connect to the
ding-clicontainer.docker exec -it ding-cli bashView the
data-ingestion-config.yamlfile.view /app/data/conf/data-ingestion-config.yamlLocate the
sourcessection and confirm thatflatFileis enabled and that OIGDB is disabled.sources: oracleIdentityGovernance: enabled: false version: 12.2.1.3 format: jdbc option: url: jdbc:oracle:thin:@oighost@example.com:1522/oimpdb.example.com driver: oracle.jdbc.driver.OracleDriver queryTimeout: 300 fetchSize: 50 flatFile: enabled: true version: 1.0 format: csv option: sep: ',' timestampFormat: yyyy-MM-ddIf flat files are not enabled or OIGDB is enabled as a data source then reset them using the
updateDataIngestionConfig.shscript:./updateDataIngestionConfig.sh --useoigdbforetl false --useflatfileforetl trueYou will see output similar to the following.
INFO: OIG DB as source for ETL is true INFO: Setting up /app/data/conf/config.yaml INFO: Setting up /app/data/conf/data-ingestion-config.yaml INFO: Setting up /app/data/conf/custom-attributes.yaml INFO: Setting up /app/oiri/data/conf/application.yaml INFO: Setting up /app/oiri/data/conf/authenticationConf.yaml INFO: Setting up /app/data/conf/dbconfig.yaml -
Download and copy the sample data to your OIRI environment.
Download the oiri_ding_etl_samples.zip file and copy to a staging directory. Unzip the file.
cd /staging/ unzip oiri_ding_etl_samples.zipYou will see output similar to the following.
Archive: oiri_ding_etl_samples.zip creating: oiri_ding_etl_samples/ inflating: oiri_ding_etl_samples/accounts.csv inflating: oiri_ding_etl_samples/applications.csv inflating: oiri_ding_etl_samples/assignedEntitlements.csv inflating: oiri_ding_etl_samples/entitlements.csv inflating: oiri_ding_etl_samples/file_list_data_to_be_deleted.properties inflating: oiri_ding_etl_samples/oig_list_data_to_be_deleted.properties inflating: oiri_ding_etl_samples/roleEntitlementComposition.csv inflating: oiri_ding_etl_samples/roles.csv inflating: oiri_ding_etl_samples/roleUserMembership.csv inflating: oiri_ding_etl_samples/role_hierarchy.csv inflating: oiri_ding_etl_samples/users.csv inflating: oiri_ding_etl_samples/users_with_ca.csv -
Copy sample files to the relevant location for loading into OIRI.
When you install OIRI fixed container locations are created into which you can put flat files containing entity data to be loaded. These locations are as follows.
- /app/data/input/users/
- /app/data/input/applications/
- /app/data/input/entitlements/
- /app/data/input/assignedentitlements/
- /app/data/input/roles/
- /app/data/input/rolehierarchy/
- /app/data/input/roleusermemberships/
- /app/data/input/roleentitlementcompositions/
- /app/data/input/accounts/
Recall that the host directory
/nfs/dingis mapped to the container directory/app/data/. Copy the sample files into the location on your host as directed in the table below, for example:cp /staging/oiri_ding_etl_samples/users.csv /nfs/ding/input/users/Location Sample File /nfs/ding/input/users/ users.csv /nfs/ding/input/applications/ applications.csv /nfs/ding/input/entitlements/ entitlements.csv /nfs/ding/input/assignedentitlements/ assignedEntitlements.csv /nfs/ding/input/roles/ roles.csv /nfs/ding/input/rolehierarchy/ role_hierarchy.csv /nfs/ding/input/roleusermemberships/ roleUserMembership.csv /nfs/ding/input/roleentitlementcompositions/ roleEntitlementComposition.csv /nfs/ding/input/accounts/ accounts.csv Confirm that the sample files can be accessed from within the
oiri-dingcontainer.docker exec -it ding-cli bashls -ltr /app/data/input/*You will see output similar to the following.
/app/data/input/users: total 40 -rwxrwxrwx 1 root root 38909 Apr 21 12:59 users.csv /app/data/input/applications: total 4 -rwxrwxrwx 1 root root 788 Apr 21 13:00 applications.csv /app/data/input/entitlements: total 8 -rwxrwxrwx 1 root root 8055 Apr 21 13:01 entitlements.csv /app/data/input/assignedentitlements: total 104 -rwxrwxrwx 1 root root 105099 Apr 21 13:02 assignedEntitlements.csv /app/data/input/roles: total 4 -rwxrwxrwx 1 root root 3064 Apr 21 13:02 roles.csv /app/data/input/rolehierarchy: total 4 -rwxrwxrwx 1 root root 266 Apr 21 13:03 role_hierarchy.csv /app/data/input/roleusermemberships: total 4 -rwxrwxrwx 1 root root 2631 Apr 21 13:04 roleUserMembership.csv /app/data/input/roleentitlementcompositions: total 12 -rwxrwxrwx 1 root root 10822 Apr 21 13:05 roleEntitlementComposition.csv /app/data/input/accounts: total 12 -rwxrwxrwx 1 root root 10898 Apr 21 13:05 accounts.csv
Perform a Dry Run of the Data Ingestion Process
Before running data ingestion you can perform a dry run to validate if the source data against the OIRI database. This process fetches data from the source, in this case flat files, and validates it against the metadata of the OIRI database. The dry run process will pick up any issues with the input data, for example, user name cannot be more than 50 characters, or duplicate entries are not permitted. A dry run can be executed with the following steps.
-
Connect to the
ding-clicontainer and invoke the dry run.docker exec -it ding-cli bashding-cli --config=/app/data/conf/config.yaml data-ingestion dry-run /app/data/conf/data-ingestion-config.yamlThis will produce a long output, the top and tail of which are shown below.
ding-cli --config=/app/data/conf/config.yaml data-ingestion dry-run /app/data/conf/data-ingestion-config.yaml ###### ### # # ##### ##### # ### # # # ## # # # # # # # # # # # # # # # # # # # # # # # # #### ##### # # # # # # # # # # # # # # # # # # ## # # # # # # ###### ### # # ##### ##### ####### ### Extract and Validate Identity data from given Identity source to OIRI Database. Found driver jar file at : /ding-cli/driver/spark-apps.jar applicationJarLocation /ding-cli/driver/spark-apps.jar Apr 22, 2021 12:18:20 PM org.apache.spark.launcher.OutputRedirector redirect ... Successfully Initiated Extract and Validate Identity data from given Identity source to OIRI Database. INFO: Job submitted successfully. Please check the Spark driver logs for more detailsThis command picks each entity, fetches the data from the flat files, and validates it with the metadata defined in the OIRI database.
-
Review the Dry Run Data Import.
Sign into Identity Role Intelligence UI
In a browser, navigate to the following URL:
http://HOST_NAME:PORT/oiri/ui/v1/consoleFor example:
https://oirihost.example.com:30305/oiri/ui/v1/consoleThe OIRI login screen is displayed.
Enter the credentials for your environment and click Sign in .
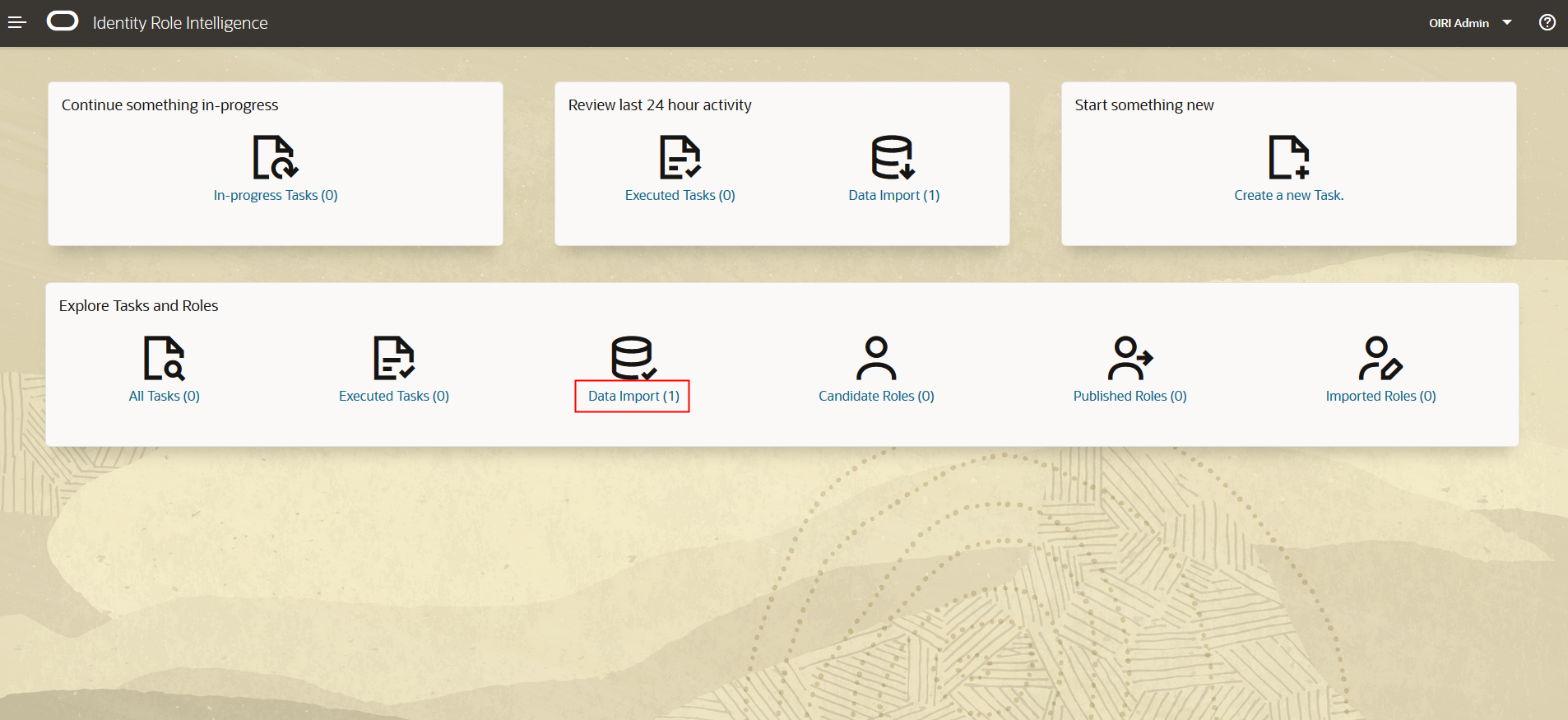
In the OIRI UI Home screen select Data Import.
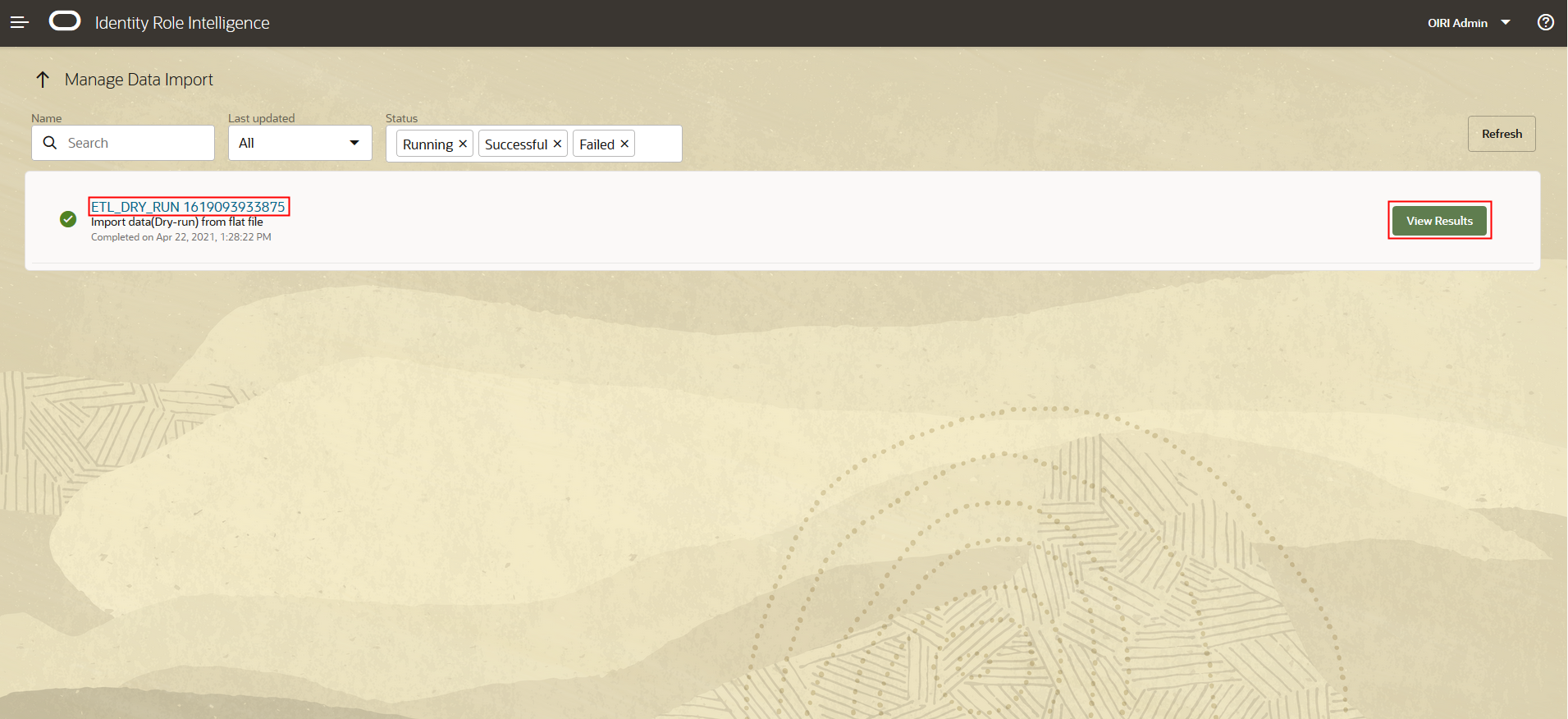
In the Manage Data Import screen you can search for the dry run import task that you want to review. When you have identified the task, select View Task or click on the task name.
The View Results screen is displayed which shows the imports for each of the entities specified in the flat files.
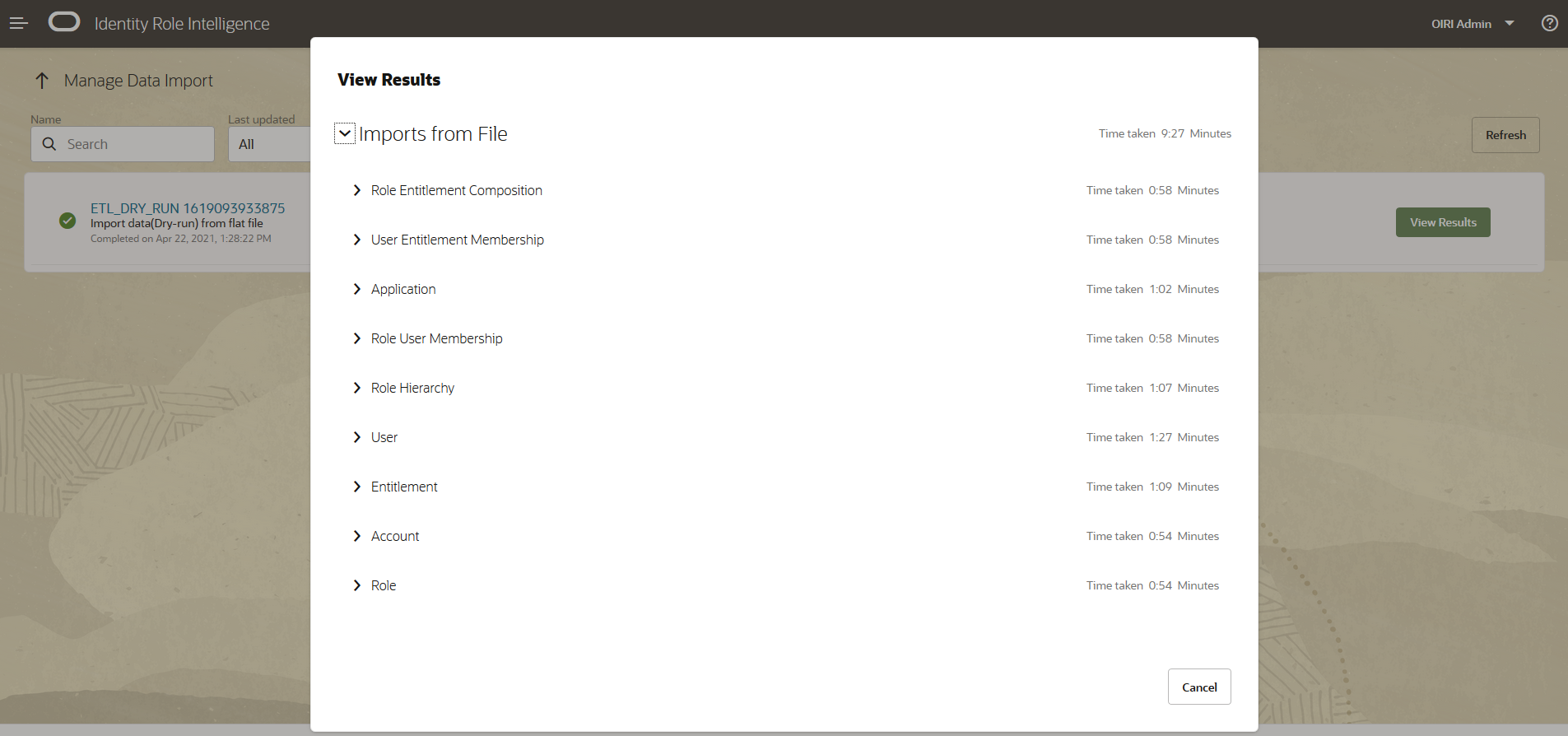
From here you can drill down into the details of the specific entities, as with the example below which shows the details for the User entity.
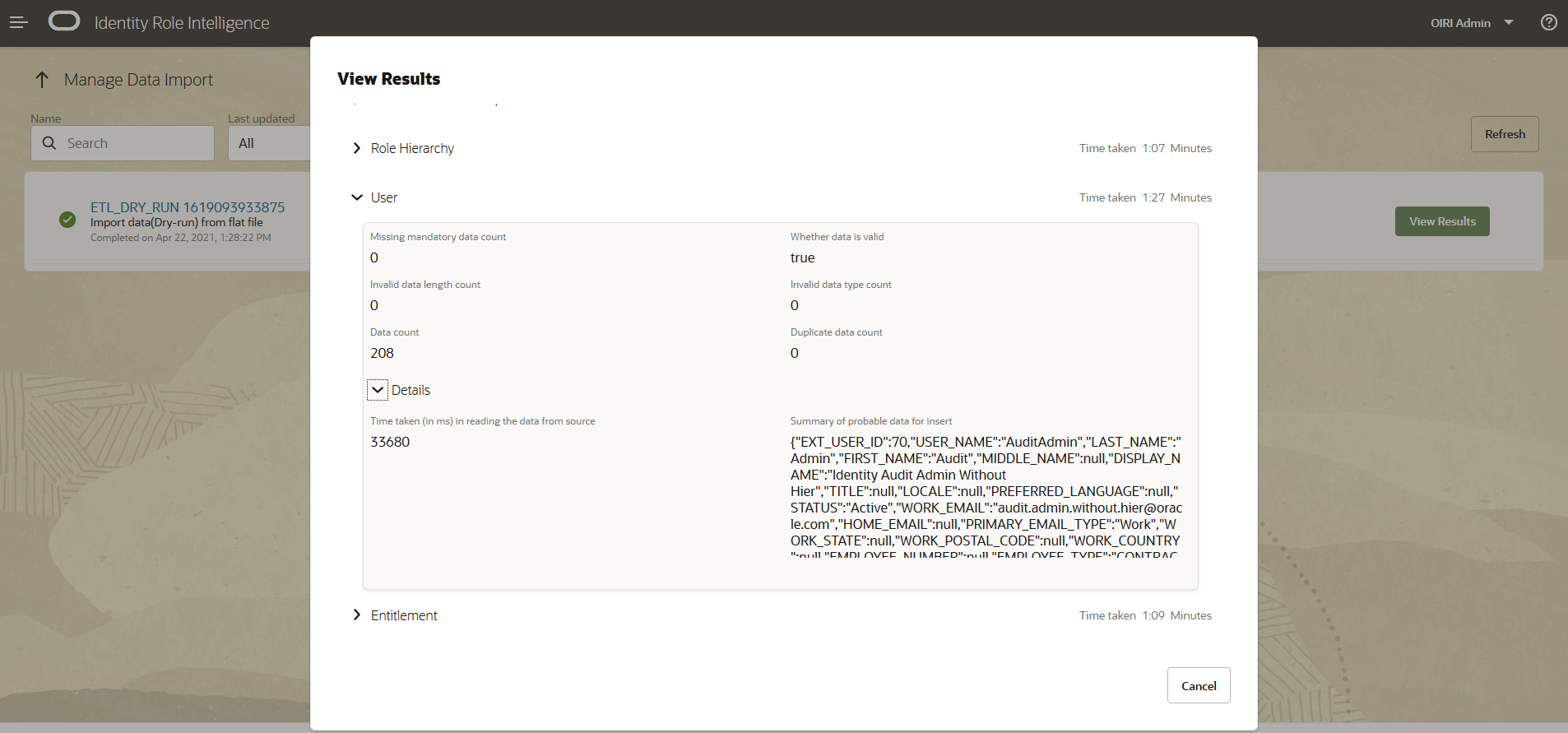
If you have errors in the source data, for example duplicate entries, then these will be flagged in the dry run results. In the example below, you can see that the Users entity has a duplicate entry for
EXT_USER_ID 70.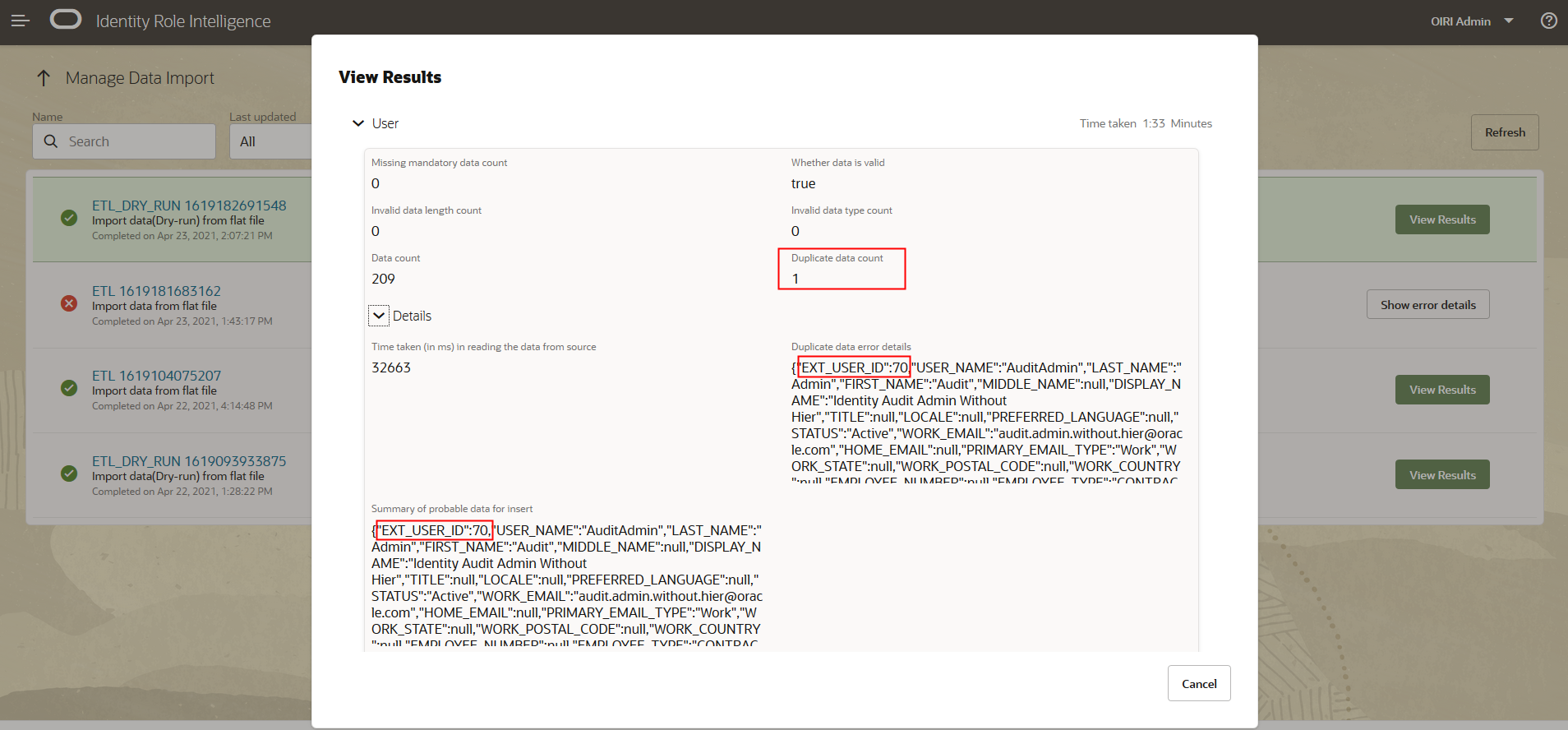
If the issue is not corrected in the source data, the subsequent data load will fail. In the case of the duplicate user entry, you will see a failed Spark pod as shown below. Interrogation of the pod logs shows that the duplicate causes a unique constraint error in the OIRI database.
Note: to access the pod information and logs you need to connect to the
oiri-clicontainer which haskubectlconfigured.docker exec -it oiri-cli bashkubectl get pods -n dingYou will see output similar to the following.
NAME READY STATUS RESTARTS AGE oiri-ding-8337ee78f9845138-driver 0/1 Completed 0 25h oiri-ding-b70d9f78febf73ea-driver 0/1 Error 0 85m oiri-ding-baa5ce78fa1f4b2f-driver 0/1 Completed 0 22h oiri-ding-c9a54178fecedd1a-driver 0/1 Completed 0 68m spark-history-server-74799bd496-fznrr 1/1 Running 0 8dFor the driver pod that is in error, return the logs.
[oiri@oiri-cli scripts] kubectl logs oiri-ding-b70d9f78febf73ea-driver -n ding ... Caused by: java.sql.BatchUpdateException: ORA-00001: unique constraint (OII_OIRI.USERS_PK) violated at oracle.jdbc.driver.OraclePreparedStatement.executeLargeBatch(OraclePreparedStatement.java:9711) at oracle.jdbc.driver.T4CPreparedStatement.executeLargeBatch(T4CPreparedStatement.java:1447) at oracle.jdbc.driver.OraclePreparedStatement.executeBatch(OraclePreparedStatement.java:9487) at oracle.jdbc.driver.OracleStatementWrapper.executeBatch(OracleStatementWrapper.java:237) at oracle.oiri.apps.tasks.dal.impl.UserDataAccess.lambda$loadDataset$eefa0bc6$1(UserDataAccess.java:847) ... 13 more 21/04/23 12:43:17 INFO ShutdownHookManager: Shutdown hook called
Perform the Data Ingestion Process
Once you have reviewed the dry run, and corrected any errors, you can run the data import using the following steps.
-
Connect to the
oiri-dingcontainer and invoke the data ingestion process.docker exec -it ding-cli bashding-cli --config=/app/data/conf/config.yaml data-ingestion start /app/data/conf/data-ingestion-config.yamlThis will produce a long output, the top and tail of which are shown below.
ding-cli --config=/app/data/conf/config.yaml data-ingestion start /app/data/conf/data-ingestion-config.yaml ###### ### # # ##### ##### # ### # # # ## # # # # # # # # # # # # # # # # # # # # # # # # #### ##### # # # # # # # # # # # # # # # # # # ## # # # # # # ###### ### # # ##### ##### ####### ### Extract Transform Load Identity data from given Identity source to OIRI Database. Found driver jar file at : /ding-cli/driver/spark-apps.jar applicationJarLocation /ding-cli/driver/spark-apps.jar ... INFO: 21/04/22 15:17:52 INFO ShutdownHookManager: Deleting directory /tmp/spark-212ade80-69d0-47fe-9e23-2b80a50bfc03 INFO: Job submitted successfully. Please check the Spark driver logs for more details -
Review the Data Import.
When you sign into Identity Role Intelligence UI, you will notice that the number of data loads has incremented by 1.
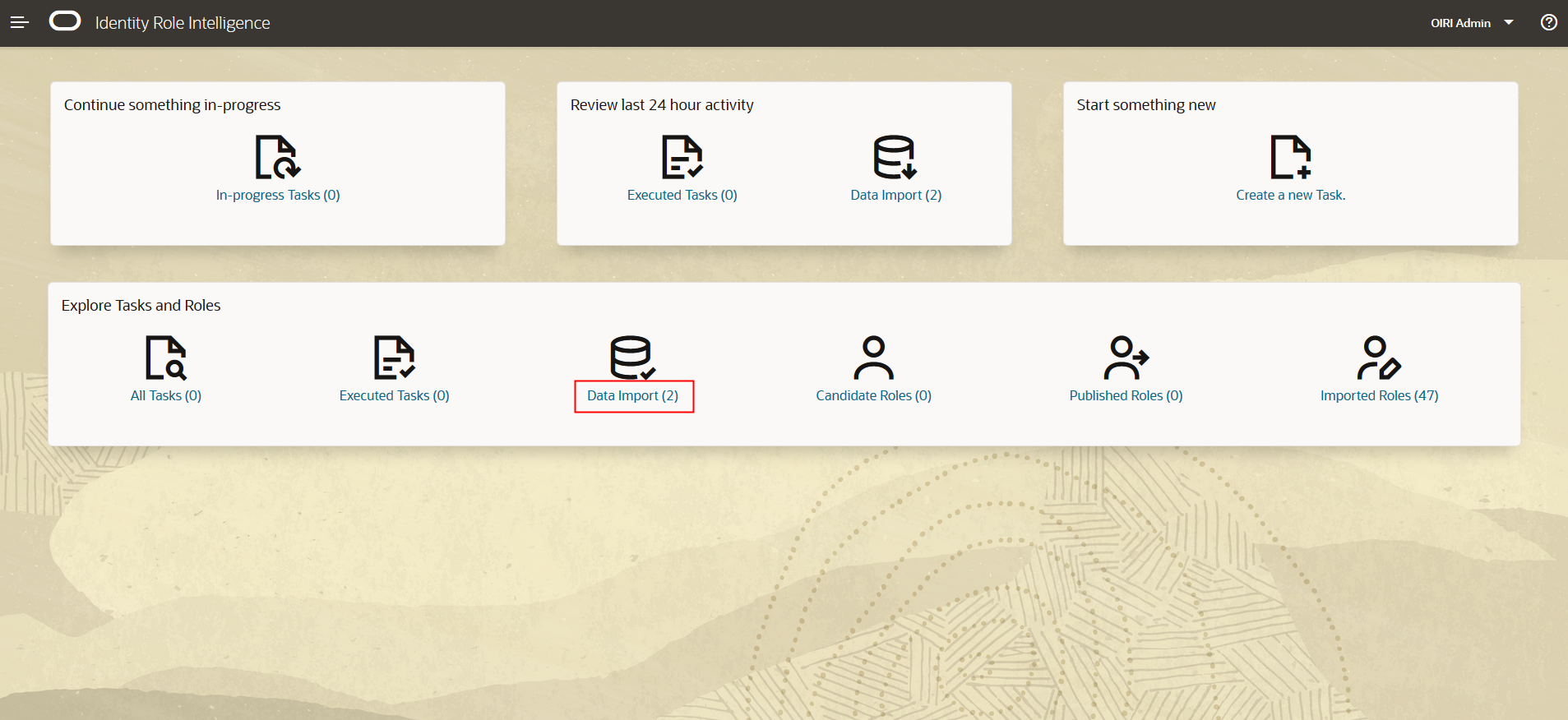
Select the data load and review the import in the same way as you did for the dry run.
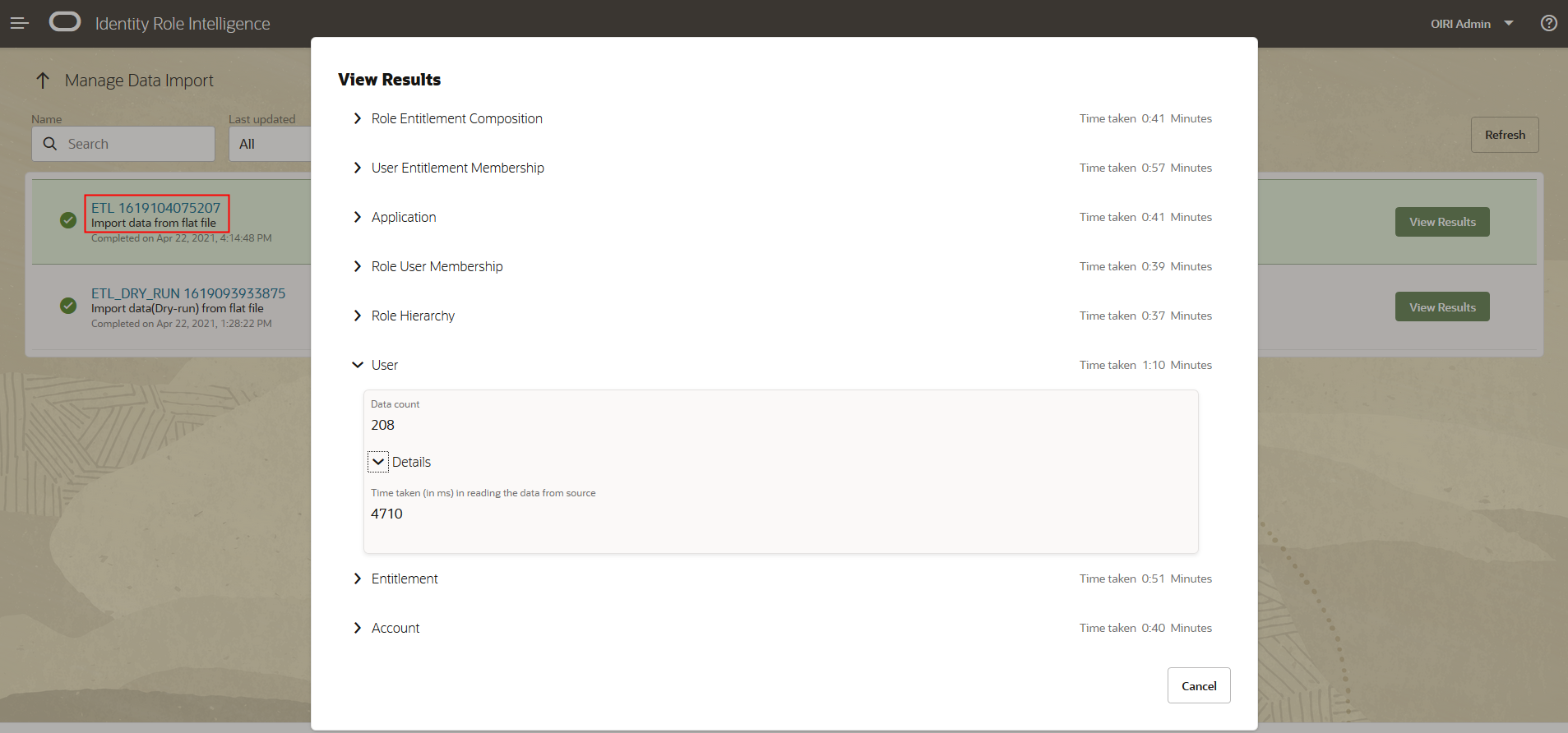
The row count shows that 208 users have been added to the OIRI database. This can be confirmed by connecting to the OIRI database and selecting information from the
userstable. Notice that 208 rows are returned. Also, that the value of theUSER_IDcolumn has been prefixed with ‘F’ to indicate that it was loaded from a flat file. OIG loaded data will be prefixed with ‘G’.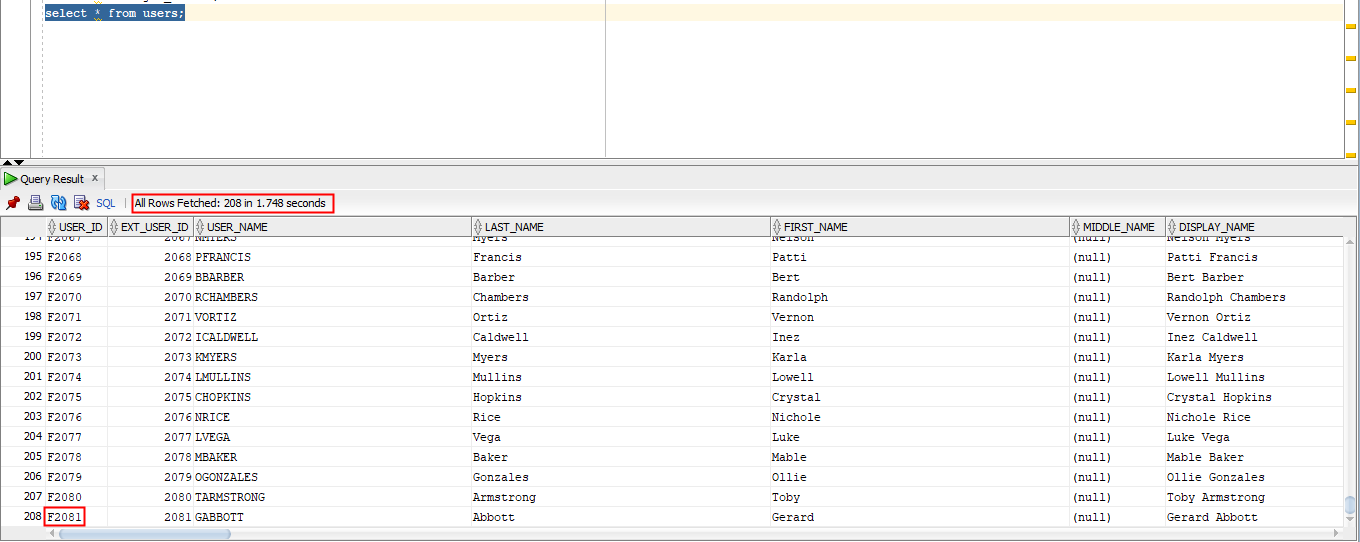
Related Links
Provide links to additional resources. This section is optional; delete if not needed.
Acknowledgements
- Authors - Mike Howlett
- Contributors - Anup Gautam, Gaurav Kumar, Rishi Agarwal, Tanmay Garg
More Learning Resources
Explore other labs on docs.oracle.com/learn or access more free learning content on the Oracle Learning YouTube channel. Additionally, visit education.oracle.com/learning-explorer to become an Oracle Learning Explorer.
For product documentation, visit Oracle Help Center.
Load Oracle Identity Role Intelligence Data Using Data Ingestion (Day 0)
F41671-02
May 2021
Copyright © 2021, Oracle and/or its affiliates.
This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited.
The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing.
If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable:
U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government.
This software or hardware is developed for general use in a variety of information management applications. It is not developed or intended for use in any inherently dangerous applications, including applications that may create a risk of personal injury. If you use this software or hardware in dangerous applications, then you shall be responsible to take all appropriate fail-safe, backup, redundancy, and other measures to ensure its safe use. Oracle Corporation and its affiliates disclaim any liability for any damages caused by use of this software or hardware in dangerous applications.
Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
Intel and Intel Xeon are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. AMD, Opteron, the AMD logo, and the AMD Opteron logo are trademarks or registered trademarks of Advanced Micro Devices. UNIX is a registered trademark of The Open Group.
This software or hardware and documentation may provide access to or information about content, products, and services from third parties. Oracle Corporation and its affiliates are not responsible for and expressly disclaim all warranties of any kind with respect to third-party content, products, and services unless otherwise set forth in an applicable agreement between you and Oracle. Oracle Corporation and its affiliates will not be responsible for any loss, costs, or damages incurred due to your access to or use of third-party content, products, or services, except as set forth in an applicable agreement between you and Oracle.