| Oracle® Retail Science Cloud Services Implementation Guide Release 19.1.003.2 F40917-01 |
|

 Previous |
 Next |
| Oracle® Retail Science Cloud Services Implementation Guide Release 19.1.003.2 F40917-01 |
|
Previous |
Next |
Science Innovation Workbench is a workspace that provides read-only access to the application data objects and clean data by using Oracle APEX. This extension is a workspace for advanced analytics users to add new implementations by using Oracle Advanced Analytic (Oracle R/ODM) algorithms that are implemented as SQL/PLSQL functions.
This appendix provides instructions for using the interface.
Open Analytics: understanding why, what, and how.
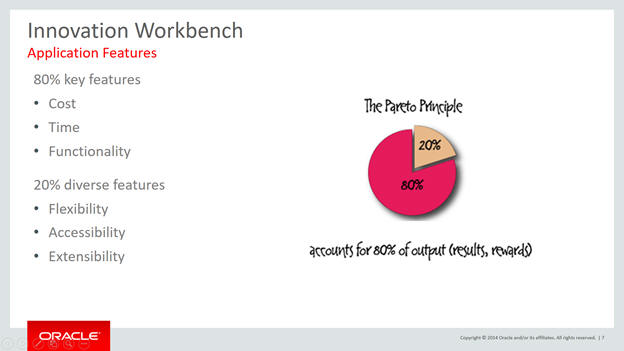
Innovation Workbench helps in extending and delivering 20 percent of these features. It provides tools to learn, discover, and innovate existing application features.
Innovation Workbench helps answer questions such as:
Which customers are likely to leave?
What is customer feedback?
Who are the prospect customers?
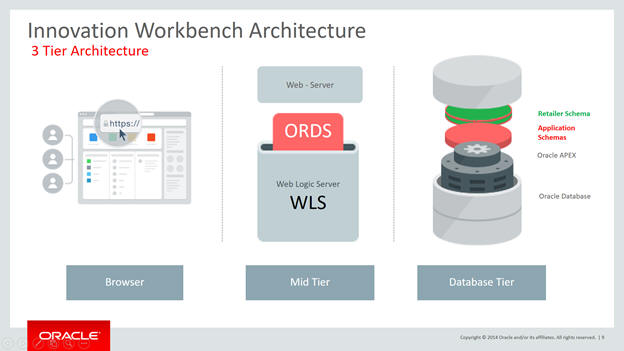
With Innovation Workbench, the following new components are available:
Retailer schema (see green slice in Figure A-4)
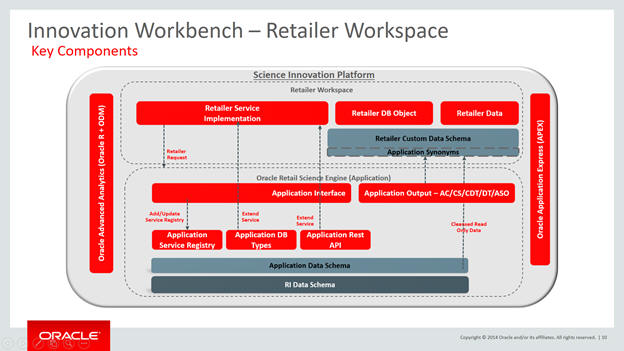
Retailer workspace
SQL Workshop
Application Builder
The Retailer Schema has read-only access to the Application Schema. All permissions are controlled using database permissions.
Roles for the analyst, scientist, developer. and integration are as follows:
Oracle Developer identifies which objects can be accessed.
Administrator manages users.
Retailer Developer uses data shared, extend, explore and mine data.
As part of Innovation Workbench, a retailer developer has the following roles:
Business Analyst, explores data, gains insights
Data Scientist, discovers patterns in data mining using Oracle R/ODM
Developer, develops applications and shares insights via UI and web services
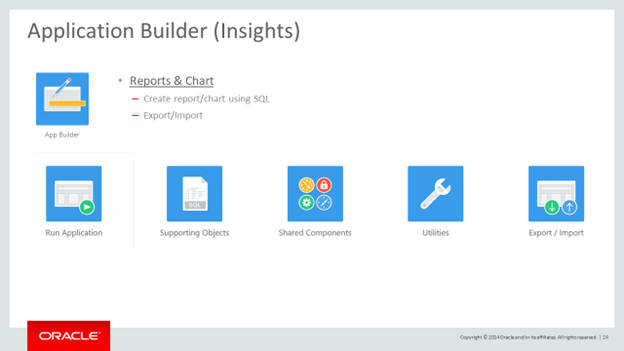
Key components
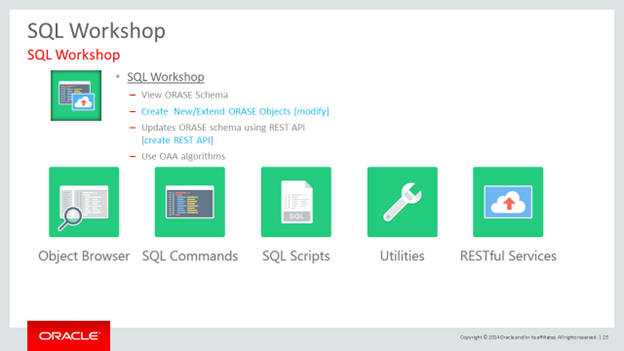
The SQL Workshop provides tools to view and manage database objects.
The Application Builder provides tools to create reports and charts using wizards and page designers.
Figure A-9 Application Builder (Insights)
Login using http:// < url>
Login/Password
This takes you to the application.
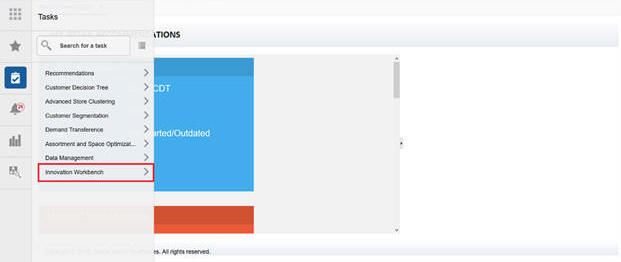
Select Innovation Workbench.
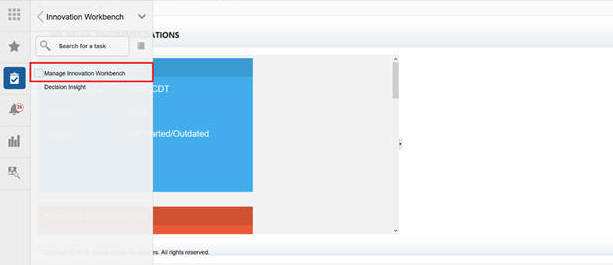
Select Manage Innovation Workbench.
This takes you to Retailer Workspace where you can log in with same login and password credentials.
Retailer Workspace has a dedicated schema and work area to do full stack development.
Dedicated Schema for retailer
Granting and revoking database object privileges
Dedicated service plan and consumer group for retailer workspace
Access to database utilities and scheduling for long-running transactions
SQL Workshop
Application Builder
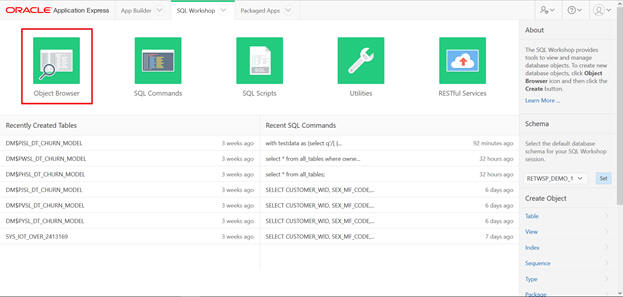
In this exercise you will browse the Application schema objects using SQL Workshop.
Access Read Only
Cleansed
Aggregated
Filtered
Sample
Inputs and Outputs
Figure A-18 SQL Workshop Object Browser Synonym
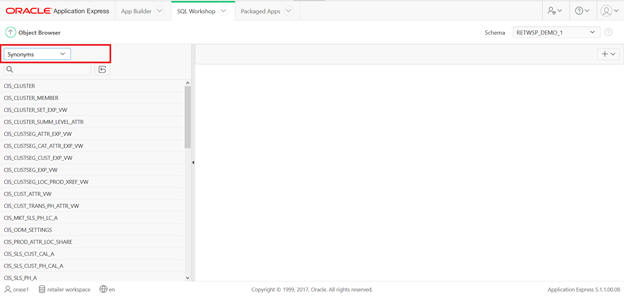
Note that this dedicated schema is only associated with the Application Schema and cannot be extended to any other new schema.
Data
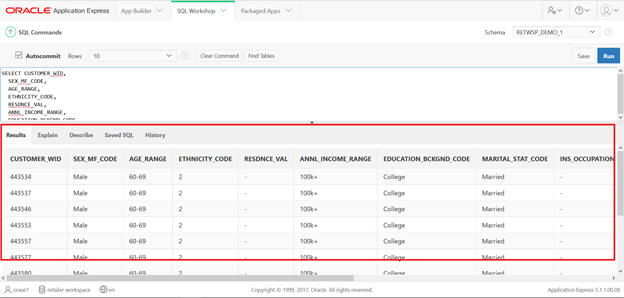
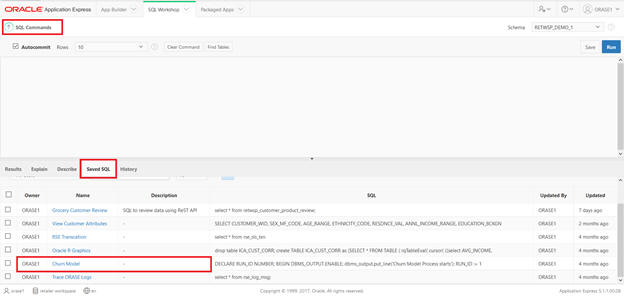
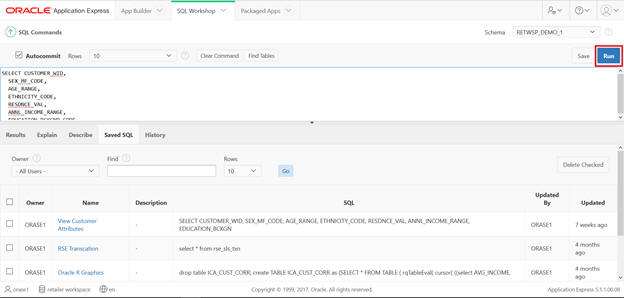
This SQL has been saved, so you can type sql in the command and execute and save it.
Figure A-20 SQL Workshop SQL Command Save SQL
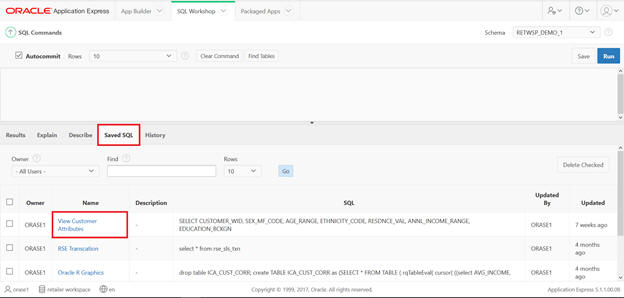
Figure A-21 SQL Workshop SQL Command Saved SQL View Customer Attributes
Using this you can do the following:
Upload Scripts
Create Scripts
Edit Scripts
Load data
Use ETL feeds
Use system feeds whereever possible. If the application feed is not available, then ReST objects can be used.
Data can be loaded to the retailer schema using the ReST API in JSON format. These must be batched from the client end while uploading data into application.
SQL Workshop ' SQL Command
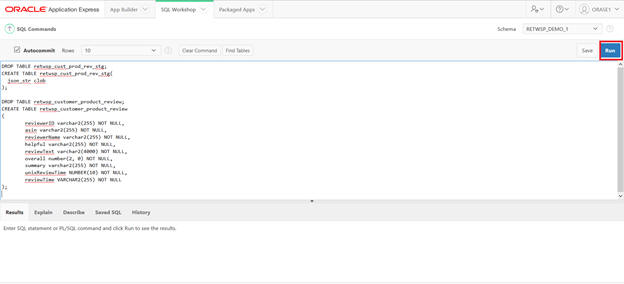
Create table that will hold Customer Reviews
DROP TABLE retwsp_cust_prod_rev_stg;
CREATE TABLE retwsp_cust_prod_rev_stg(
json_str clob
);
DROP SEQUENCE retwsp_cust_prod_rev_seq CREATE SEQUENCE retwsp_cust_prod_rev_seq START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE; reviewerID varchar2(255) NOT NULL,
DROP TABLE retwsp_customer_product_review;
CREATE TABLE retwsp_customer_product_review
(
reviewid NUMBER NOT NULL,
reviewerID varchar2(255) NOT NULL,
asin varchar2(255) NOT NULL,
reviewerName varchar2(255) NOT NULL,
helpful varchar2(255) NOT NULL,
reviewText varchar2(4000) NOT NULL,
overall number(2, 0) NOT NULL,
summary varchar2(255) NOT NULL,
unixReviewTime NUMBER(10) NOT NULL,
reviewTime VARCHAR2(255) NOT NULL
);
Copy and paste the above content and click Run.
Create ReST API, which allows you to load customer reviews in the above table.
Click Create.
Here is the code to populate the JSON data to the relational table.
Declare
customer_review_lblob blob;
customer_review_cblob clob;
begin
customer_review_lblob := :body;
customer_review_cblob := wwv_flow_utilities.blob_to_clob(customer_review_lblob);
-- insert into stage table
insert into retwsp_cust_prod_rev_stg values (customer_review_cblob);
-- move to target table
insert into retwsp_customer_product_review (reviewid, reviewerID, asin, reviewerName, helpful, reviewText, overall, summary, unixReviewTime, reviewTime)
with review_data
as (select json_str from retwsp_cust_prod_rev_stg)
select retwsp_cust_prod_rev_seq.nextval, j.*
from review_data rd,
json_table(rd.json_str, '$[*]'
columns (reviewerID varchar2 path '$.reviewerID'
,asin varchar2 path '$.asin'
,reviewerName varchar2 path '$.reviewerName'
,helpful number path '$.helpful'
,reviewText varchar2 path '$.reviewText'
,overall number path '$.overall'
,summary varchar2 path '$.summary'
,unixReviewTime number path '$.unixReviewTime'
,reviewTime varchar2 path '$.reviewTime'
)
) j;
delete from RETWSP_TMP_CUST_PROD_RW;
commit;
end;
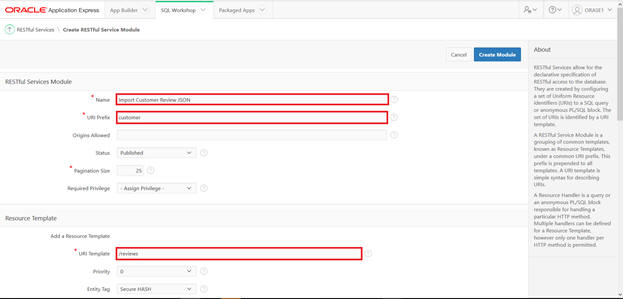
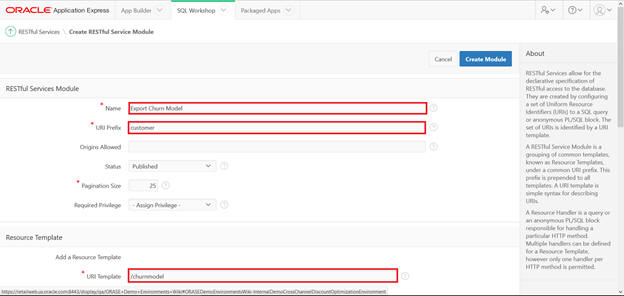
Provide the essential elements, including name, URI prefix, and template.
Select the method. In this case it is POST, since the data is getting updated.
Populate the name for the RESTful Services Module. URI Prefix as customer and URI Template/reviews. The / is required.
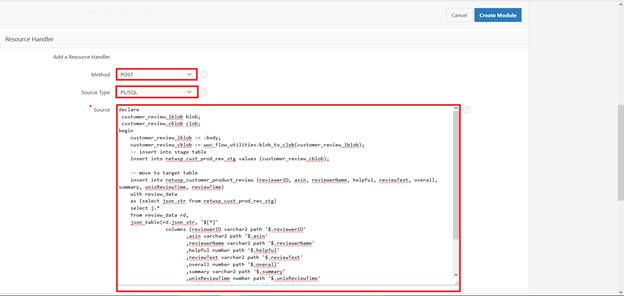
Add resource handler method - POST and source type - PL/SQL
Declare
customer_review_lblob blob;
customer_review_cblob clob;
begin
customer_review_lblob := :body;
customer_review_cblob := wwv_flow_utilities.blob_to_clob(customer_review_lblob);
-- insert into stage table
insert into retwsp_cust_prod_rev_stg values (customer_review_cblob);
-- move to target table
insert into retwsp_customer_product_review (reviewid, reviewerID, asin, reviewerName, helpful, reviewText, overall, summary, unixReviewTime, reviewTime)
with review_data
as (select json_str from retwsp_cust_prod_rev_stg)
select retwsp_cust_prod_rev_seq.nextval, j.*
from review_data rd,
json_table(rd.json_str, '$[*]'
columns (reviewerID varchar2 path '$.reviewerID'
,asin varchar2 path '$.asin'
,reviewerName varchar2 path '$.reviewerName'
,helpful number path '$.helpful'
,reviewText varchar2 path '$.reviewText'
,overall number path '$.overall'
,summary varchar2 path '$.summary'
,unixReviewTime number path '$.unixReviewTime'
,reviewTime varchar2 path '$.reviewTime'
)
) j;
delete from retwsp_cust_prod_rev_stg;
commit;
end;
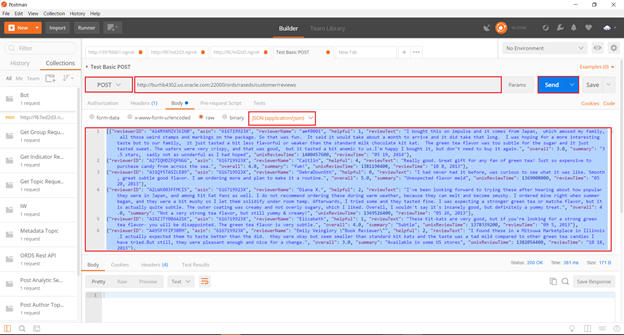
Post customer reviews using following the data http://<url>
This posting can be done using POSTMaN or any ReST Client (such as java application posting data into Retailer Schema)This step requires PostMan or a client that will push reviews. Download and Install PostMan. If it cannot be installed, go to the next step.https://www.getpostman.com/apps
Select * from retwsp_customer_product_review;
These methods must be used judiciously, with smaller datasets.
Prepare Data
Key components that can be used for refining data are Create Train and Test dataset.
The followings SQL shows how stratified split is used to preserve the categorical target distribution in the resulting training and test dataset.
Key items below are:
target column. It must be categorical type.
case id column. It must contain unique numbers that identify the rows.
input data set. {percent of training dataset} - percent of training dataset. For example, if you want to split 60% of input dataset into a training dataset, use the value 60. The test dataset will contain 100%-60% = 40% of the input dataset. The training and test dataset are mutually exclusive.
Train Datsasets
create or replace view retwsp_rf_cust_attr_test_vw as (SELECT v1.* FROM ( -- randomly divide members of the population into subgroups based on target classes SELECT a.*, row_number() OVER (partition by EDUCATION_BCKGND_CODE ORDER BY ORA_HASH(CUSTOMER_WID)) "_partition_caseid" FROM retwsp_rf_cust_attr_vw a) v1, ( -- get the count of subgroups based on target classes SELECT EDUCATION_BCKGND_CODE, COUNT(*) "_partition_target_cnt" FROM retwsp_rf_cust_attr_vw GROUP BY EDUCATION_BCKGND_CODE) v2 WHERE v1.EDUCATION_BCKGND_CODE = v2.EDUCATION_BCKGND_CODE -- random sample subgroups based on target classes in respect to the sample size AND ORA_HASH(v1."_partition_caseid", v2."_partition_target_cnt"-1, 0) <= (v2."_partition_target_cnt" * 60 / 100));
Test Datasets
create or replace view retwsp_rf_cust_attr_test_vw as (SELECT v1.* FROM ( -- randomly divide members of the population into subgroups based on target classes SELECT a.*, row_number() OVER (partition by EDUCATION_BCKGND_CODE ORDER BY ORA_HASH(CUSTOMER_WID)) "_partition_caseid" FROM retwsp_rf_cust_attr_vw a) v1, ( -- get the count of subgroups based on target classes SELECT EDUCATION_BCKGND_CODE, COUNT(*) "_partition_target_cnt" FROM retwsp_rf_cust_attr_vw GROUP BY EDUCATION_BCKGND_CODE) v2 WHERE v1.EDUCATION_BCKGND_CODE = v2.EDUCATION_BCKGND_CODE -- random sample subgroups based on target classes in respect to the sample size AND ORA_HASH(v1."_partition_caseid", v2."_partition_target_cnt"-1, 0) <= (v2."_partition_target_cnt" * 40 / 100));
Now we have customer reviews we will review, build text to find document frequencies, and display them in charts. We will further extract key text for each review.
This script can be found under SQLWorkshop ' SQL Scripts [Text Mining Feature Extraction]
-------------------------------------------------------------Build Text and Token --------------------------------------------
DECLARE
v_policy_name VARCHAR2(4000);
v_lexer_name VARCHAR2(4000);
BEGIN
v_policy_name := 'RETWSP_POLICY';
v_lexer_name := 'RETWSP_LEXER';
ctx_ddl.drop_preference(v_lexer_name);
ctx_ddl.drop_policy(
policy_name => v_policy_name
);
ctx_ddl.create_preference(
v_lexer_name,
'BASIC_LEXER'
);
ctx_ddl.create_policy(
policy_name => v_policy_name,
lexer => v_lexer_name,
stoplist => 'CTXSYS.DEFAULT_STOPLIST'
);
END;
/
DROP TABLE retwsp_feature;
CREATE TABLE retwsp_feature
AS
SELECT
'REVIEWTEXT' "COLUMN_NAME",
token,
value,
rank,
count
FROM
(
SELECT
token,
value,
RANK() OVER(
ORDER BY value ASC
) rank,
count
FROM
(
SELECT
column_value token,
ln(n / COUNT(*) ) value,
COUNT(*) count
FROM
(
SELECT
t2.column_value,
t1.n
FROM
(
SELECT
COUNT(*) OVER() n,
ROWNUM rn,
odmr_engine_text.dm_policy_tokens(
'RETWSP_POLICY',
reviewtext
) nt
FROM
retwsp_customer_product_review
) t1,
TABLE ( t1.nt ) t2
GROUP BY
t2.column_value,
t1.rn,
t1.n
)
GROUP BY
column_value,
n
)
)
WHERE
rank <= 3000;
SELECT
*
FROM
retwsp_feature;
create table retwsp_review_df as
SELECT
*
FROM
(
SELECT
nested_result.attribute_name,
COUNT(nested_result.attribute_name) count_val
FROM
(
WITH
/* Start of sql for node: RETWSP_CUSTOMER_PRODUCT_REVIEW */ "N$10001" AS (
SELECT /*+ inline */
"RETWSP_CUSTOMER_PRODUCT_REVIEW"."ASIN",
"RETWSP_CUSTOMER_PRODUCT_REVIEW"."REVIEWERID",
"RETWSP_CUSTOMER_PRODUCT_REVIEW"."OVERALL",
"RETWSP_CUSTOMER_PRODUCT_REVIEW"."REVIEWTEXT"
FROM
"RETWSP_DEMO_1"."RETWSP_CUSTOMER_PRODUCT_REVIEW"
)
/* End of sql for node: RETWSP_CUSTOMER_PRODUCT_REVIEW */,
/* Start of sql for node: Build Text */ "N$10002" AS (
SELECT /*+ inline */
"REVIEWERID",
"ASIN",
"OVERALL",
odmr_engine_text.dm_text_token_features(
'RETWSP_POLICY',
"REVIEWTEXT",
'RETWSP_FEATURE',
NULL,
50,
'IDF'
) "REVIEWTEXT_TOK"
FROM
"N$10001"
)
/* End of sql for node: Build Text */ SELECT
*
FROM
"N$10002"
) output_result,
TABLE ( output_result.reviewtext_tok ) nested_result
GROUP BY
nested_result.attribute_name
)
ORDER BY count_val DESC;
select * from retwsp_review_df;
-------------------------------------------------------------Feature Extraction and Feature Comparison --------------------------------------------
-- Create the settings table
DROP TABLE RETWSP_ESA_settings;
CREATE TABLE RETWSP_ESA_settings (
setting_name VARCHAR2(30),
setting_value VARCHAR2(30));
DECLARE ---------- sub-block begins
already_exists EXCEPTION;
PRAGMA EXCEPTION_INIT(already_exists, -00955);
v_stmt VARCHAR2(4000);
v_param_name VARCHAR2(100);
v_param_value VARCHAR2(100);
BEGIN
dbms_output.put_line('Start Populate settings table' || dbms_data_mining.algo_name);
dbms_output.put_line('Start Populate settings table' || dbms_data_mining.algo_nonnegative_matrix_factor);
v_param_name := dbms_data_mining.algo_name;
v_param_value := dbms_data_mining.ALGO_NONNEGATIVE_MATRIX_FACTOR;
v_stmt := 'INSERT INTO RETWSP_ESA_settings (setting_name, setting_value) VALUES (''' || v_param_name || ''',''' || v_param_value || ''')';
dbms_output.put_line('Start Populate settings table v_stmt --' || v_stmt);
EXECUTE IMMEDIATE v_stmt;
v_param_name := dbms_data_mining.prep_auto;
v_param_value := dbms_data_mining.prep_auto_on;
v_stmt := 'INSERT INTO RETWSP_ESA_settings (setting_name, setting_value) VALUES (''' || v_param_name || ''',''' || v_param_value || ''')';
dbms_output.put_line('Start Populate settings table v_stmt --' || v_stmt);
EXECUTE IMMEDIATE v_stmt;
EXCEPTION
WHEN already_exists THEN
dbms_output.put_line('Exception not found');
END; ------------- sub-block ends
/
create view RETWSP_CUST_PROD_REVIEW_VW as (select reviewid, reviewtext from RETWSP_CUSTOMER_PRODUCT_REVIEW);
DECLARE
v_xlst dbms_data_mining_transform.TRANSFORM_LIST;
v_policy_name VARCHAR2(130) := 'RETWSP_POLICY';
v_model_name varchar2(50) := 'RETWSP_ESA_MODEL';
BEGIN
v_xlst := dbms_data_mining_transform.TRANSFORM_LIST();
DBMS_DATA_MINING_TRANSFORM.SET_TRANSFORM(v_xlst, 'REVIEWTEXT', NULL, 'REVIEWTEXT', NULL, 'TEXT(POLICY_NAME:'||v_policy_name||')(MAX_FEATURES:3000)(MIN_DOCUMENTS:1)(TOKEN_TYPE:NORMAL)');
DBMS_DATA_MINING.DROP_MODEL(v_model_name, TRUE);
DBMS_DATA_MINING.CREATE_MODEL(
model_name => v_model_name,
mining_function => DBMS_DATA_MINING.FEATURE_EXTRACTION,
data_table_name => 'RETWSP_CUST_PROD_REVIEW_VW',
case_id_column_name => 'REVIEWID',
settings_table_name => 'RETWSP_ESA_SETTINGS',
xform_list => v_xlst);
END;
/
------------------
-- List top (largest) 3 features that represent are represented in each review.
-- Explain the attributes which most impact those features.
-- This can be used in UI to display all key features in each review.
select REPLACE(xt.attr_name,'"REVIEWTEXT".',''), xt.attr_value, xt.attr_weight, xt.attr_rank
from (SELECT S.feature_id fid, value val,
FEATURE_DETAILS(RETWSP_ESA_MODEL, S.feature_id, 5 using T.*) det
FROM
(SELECT v.*, FEATURE_SET(RETWSP_ESA_MODEL, 3 USING *) fset
FROM RETWSP_CUSTOMER_PRODUCT_REVIEW v
WHERE reviewid = 1) T,
TABLE(T.fset) S
order by val desc) X, XMLTABLE('/Details'
PASSING X.DET
COLUMNS
"ALGORITHM" VARCHAR2(30) PATH '@algorithm',
"FEATURE" VARCHAR2(30) PATH '@feature',
RECORDS XMLTYPE PATH '/Details') R,
XMLTABLE ('/Details/Attribute'
PASSING R.RECORDS
COLUMNS
"ATTR_NAME" VARCHAR2(30) PATH '@name',
"ATTR_VALUE" VARCHAR2(120) PATH '@actualValue',
"ATTR_WEIGHT" VARCHAR2(10) PATH '@weight',
"ATTR_RANK" VARCHAR2(10) PATH '@rank'
) XT
ORDER BY ATTR_RANK;
To display the prepared data in UI for end user to review, complete the following:
Select Application Builder to create the UI.
Click Create.
Select Create Page.
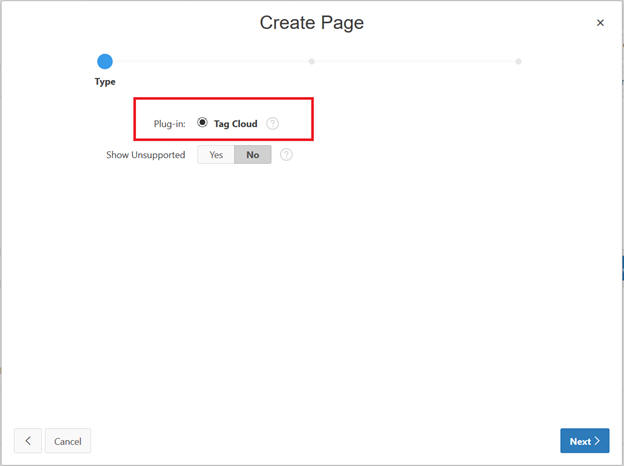
Select Plugin and click Next.
Select Type.
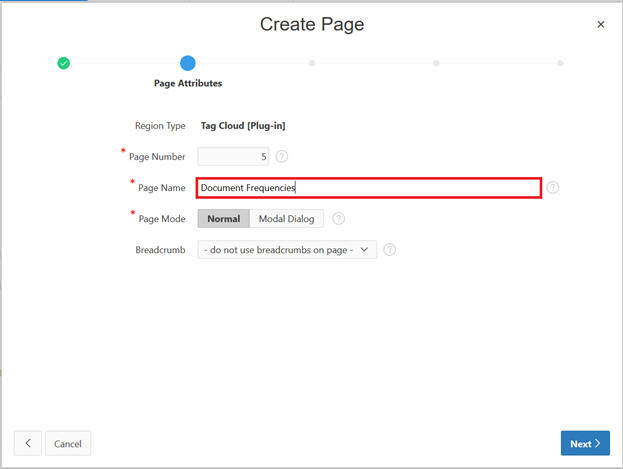
Populate Page Name and click Next.
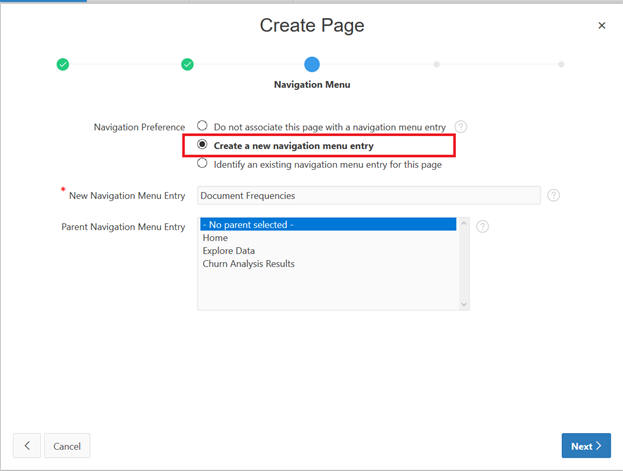
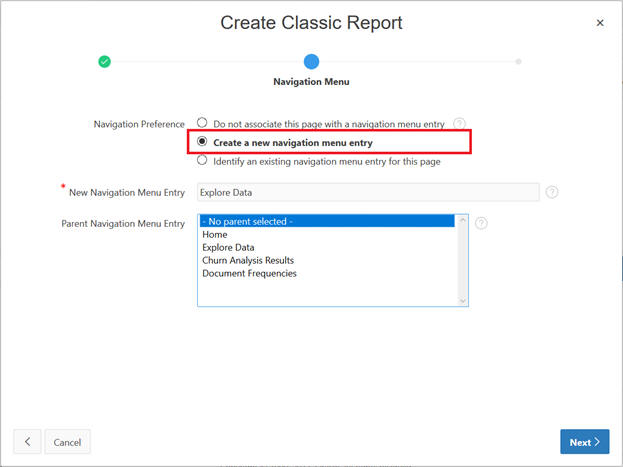
Select the Navigation Menu entries and click Next.
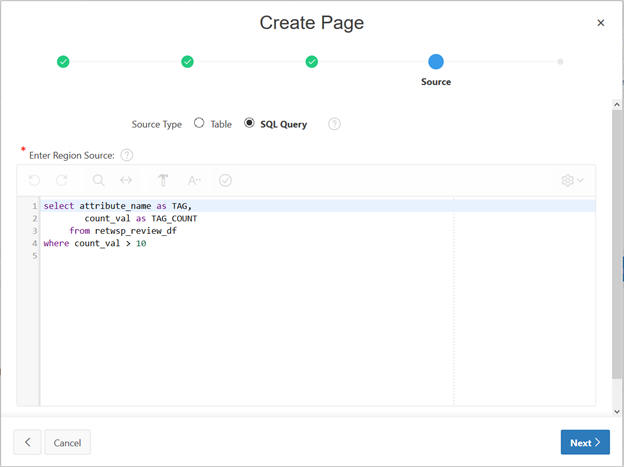
Click Next and populate SQL to build the chart.
select attribute_name as TAG,
count_val as TAG_COUNT
from retwsp_review_df
where count_val > 30
order by attribute_name;
You see the Page Designer. Click Save and Run icon.
Log in with username/password.
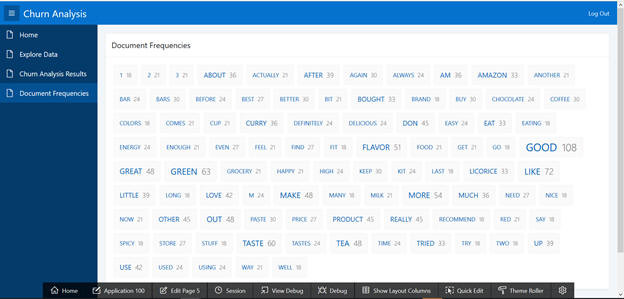
The just designed screen is displayed, with the following content.
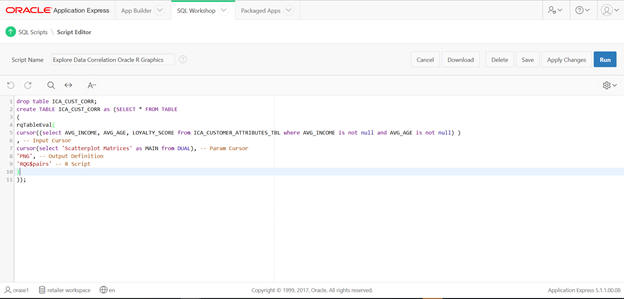
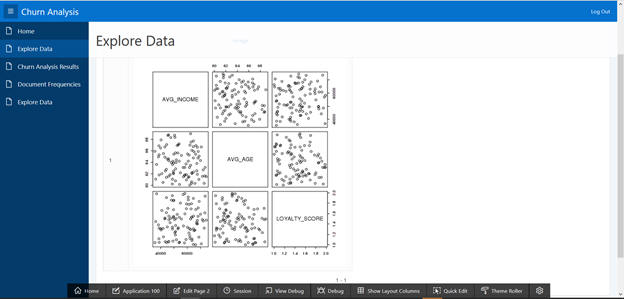
Oracle R graphic can be used to illustrate the correlation between customer attributes.
Navigate from SQLWorkshop ' SQL Scripts.
Review the content of the SQL and execute it. This creates a table that has a scatter plot matrix image blob stored as an output.
drop table ICA_CUST_CORR; create TABLE ICA_CUST_CORR as (SELECT * FROM TABLE ( rqTableEval( cursor((select AVG_INCOME, AVG_AGE, LOYALTY_SCORE from ICA_CUSTOMER_ATTRIBUTES_TBL where AVG_INCOME is not null and AVG_AGE is not null) ) , -- Input Cursor cursor(select 'Scatterplot Matrices' as MAIN from DUAL), -- Param Cursor 'PNG', -- Output Definition 'RQG$pairs' -- R Script ) ));
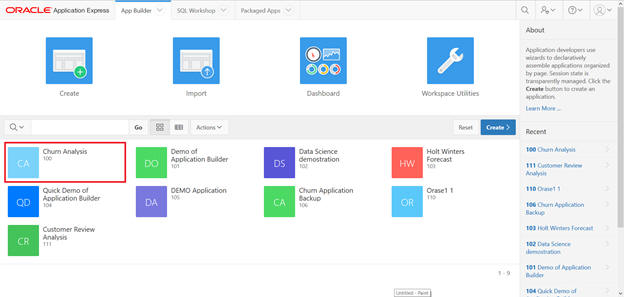
Create a new page in Churn Analysis.
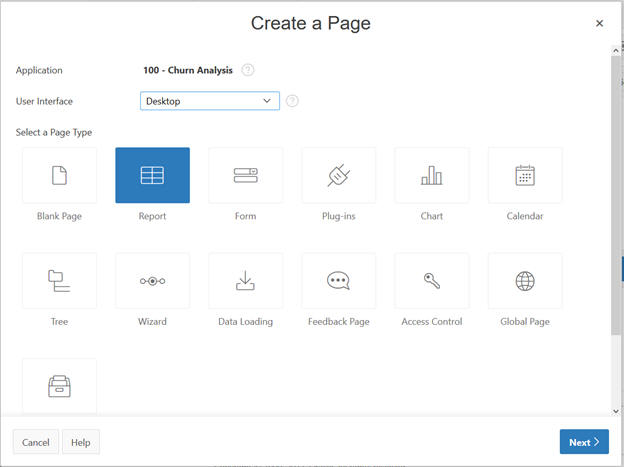
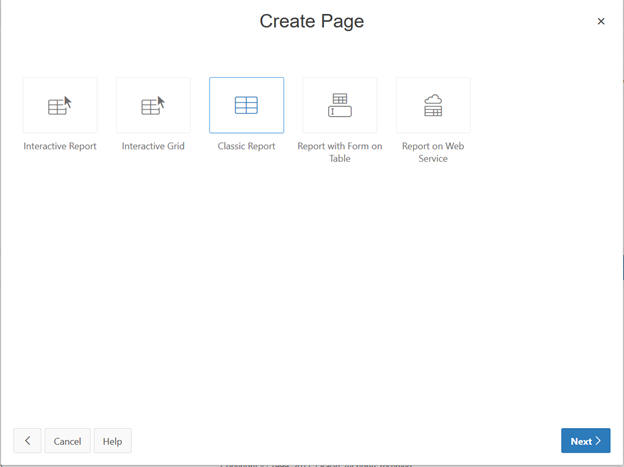
Select Report from the Options and click Next.
Select Classic Report.
Input the page name and click Next.
Figure A-49 Classic Report Page Attributes
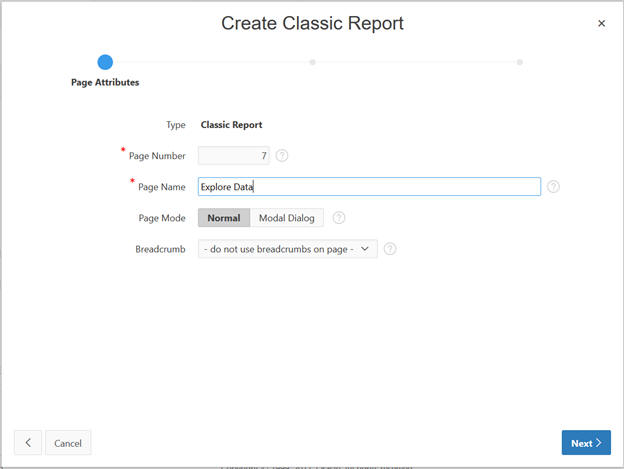
Figure A-50 Classic Report Navigation Menu
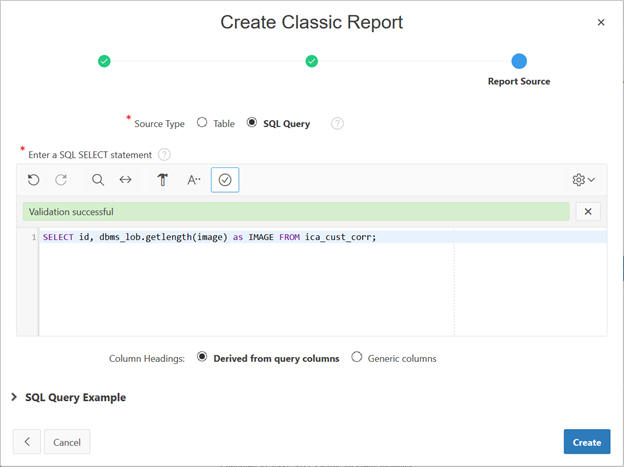
Select Next to display the input query screen.
SELECT id, dbms_lob.getlength(image) as IMAGE FROM ica_cust_corr;
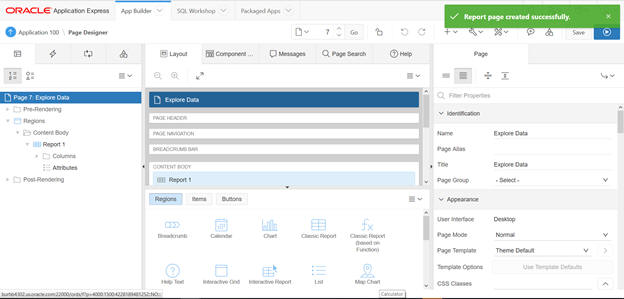
Click Create to display the Page Designer.
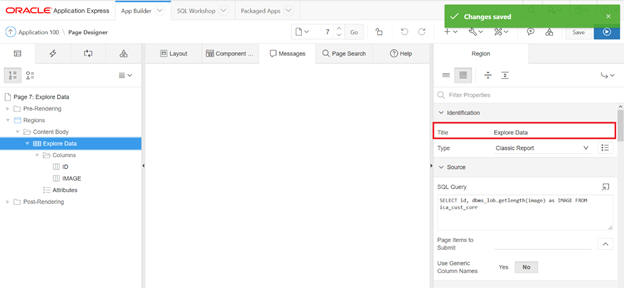
Change the title.
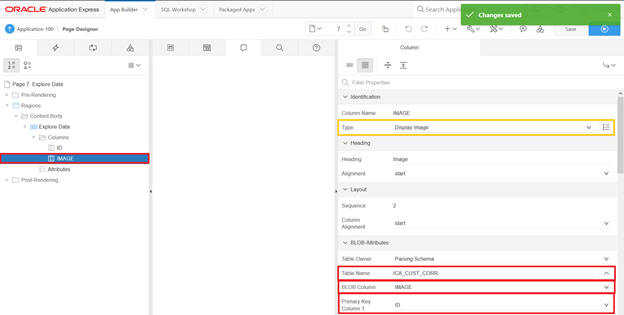
Select Column Image in the left panel, and in the right panel change the values for the image column.
Select type - Display Image
Select Table Name ica_custom_corr
Blob Column as IMAGE
Primary Key Column as ID
Save and Run
The screen displays the Scatter Plot Matrix.
Innovate Science
Oracle R
Oracle Data Mining
Collaborate
Full stack development
R Graphics, Chart, Report
Share and Deliver
Gain Insight
Visualize and Share
Open Web Service
View SQL Workshop Object Browser.
Select Packages and Specification.
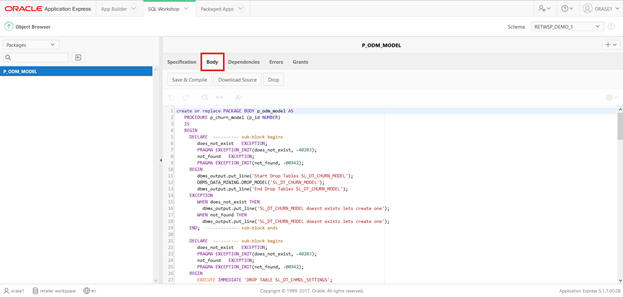
Select the body that creates a classification model using the Decision Tree algorithm.
Key considerations in the code are
Note the default classification algorithm in ODM is Naive Bayes. In order to override, create and populate a settings table to be used as input to the model.
Examples of other possible settings are:
(dbms_data_mining.tree_impurity_metric, 'TREE_IMPURITY_ENTROPY')
(dbms_data_mining.tree_term_max_depth, 5)
(dbms_data_mining.tree_term_minrec_split, 5)
(dbms_data_mining.tree_term_minpct_split, 2)
(dbms_data_mining.tree_term_minrec_node, 5)
(dbms_data_mining.tree_term_minpct_node, 0.05)
A cost matrix is used to influence the weighting of mis-classification during model creation and scoring.
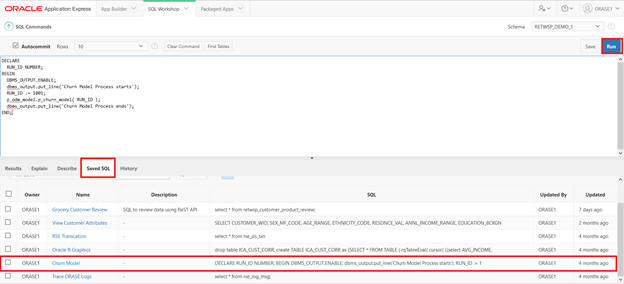
Execute the procedure via SQL Command.
Execute Churn Model analysis and view the results.
Here are the results.
SELECT
dbms_data_mining.get_model_details_xml('SL_DT_CHURN_MODEL')
AS DT_DETAILSFROM dual;
Results of the XML is as follows, next step will be to parse the XML and
<PMML version="2.1">
<Header copyright="Copyright (c) 2004, Oracle Corporation. All rights reserved."/>
<DataDictionary numberOfFields="4">
<DataField name="AGE_RANGE" optype="categorical"/>
<DataField name="ANNL_INCOME_RANGE" optype="categorical"/>
<DataField name="CHURN_SCORE" optype="categorical"/>
<DataField name="PARTY_TYPE_CODE" optype="categorical"/>
</DataDictionary>
<TreeModel modelName="SL_DT_CHURN_MODEL" functionName="classification" splitCharacteristic="binarySplit">
<Extension name="buildSettings">
<Setting name="TREE_IMPURITY_METRIC" value="TREE_IMPURITY_GINI"/>
<Setting name="TREE_TERM_MAX_DEPTH" value="7"/>
<Setting name="TREE_TERM_MINPCT_NODE" value=".05"/>
<Setting name="TREE_TERM_MINPCT_SPLIT" value=".1"/>
<Setting name="TREE_TERM_MINREC_NODE" value="10"/>
<Setting name="TREE_TERM_MINREC_SPLIT" value="20"/>
<costMatrix>
<costElement>
<actualValue>0</actualValue>
<predictedValue>0</predictedValue>
<cost>0</cost>
</costElement>
<costElement>
<actualValue>0</actualValue>
<predictedValue>1</predictedValue>
<cost>1</cost>
</costElement>
<costElement>
<actualValue>0</actualValue>
<predictedValue>2</predictedValue>
<cost>2</cost>
</costElement>
<costElement>
<actualValue>0</actualValue>
<predictedValue>3</predictedValue>
<cost>3</cost>
</costElement>
<costElement>
<actualValue>1</actualValue>
<predictedValue>0</predictedValue>
<cost>1</cost>
</costElement>
<costElement>
<actualValue>1</actualValue>
<predictedValue>1</predictedValue>
<cost>0</cost>
</costElement>
<costElement>
<actualValue>1</actualValue>
<predictedValue>2</predictedValue>
<cost>2</cost>
</costElement>
<costElement>
<actualValue>1</actualValue>
<predictedValue>3</predictedValue>
<cost>3</cost>
</costElement>
<costElement>
<actualValue>2</actualValue>
<predictedValue>0</predictedValue>
<cost>3</cost>
</costElement>
<costElement>
<actualValue>2</actualValue>
<predictedValue>1</predictedValue>
<cost>2</cost>
</costElement>
<costElement>
<actualValue>2</actualValue>
<predictedValue>2</predictedValue>
<cost>0</cost>
</costElement>
<costElement>
<actualValue>2</actualValue>
<predictedValue>3</predictedValue>
<cost>1</cost>
</costElement>
<costElement>
<actualValue>3</actualValue>
<predictedValue>0</predictedValue>
<cost>3</cost>
</costElement>
<costElement>
<actualValue>3</actualValue>
<predictedValue>1</predictedValue>
<cost>2</cost>
</costElement>
<costElement>
<actualValue>3</actualValue>
<predictedValue>2</predictedValue>
<cost>1</cost>
</costElement>
<costElement>
<actualValue>3</actualValue>
<predictedValue>3</predictedValue>
<cost>0</cost>
</costElement>
</costMatrix>
</Extension>
<MiningSchema>
<MiningField name="AGE_RANGE" usageType="active"/>
<MiningField name="ANNL_INCOME_RANGE" usageType="active"/>
<MiningField name="CHURN_SCORE" usageType="predicted"/>
<MiningField name="PARTY_TYPE_CODE" usageType="active"/>
</MiningSchema>
<Node id="0" score="2" recordCount="100427">
<True/>
<ScoreDistribution value="2" recordCount="46479"/>
<ScoreDistribution value="1" recordCount="32131"/>
<ScoreDistribution value="3" recordCount="13794"/>
<ScoreDistribution value="0" recordCount="8023"/>
<Node id="1" score="2" recordCount="71604">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"20-29" "40-49" "50-59" "70-79" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="ANNL_INCOME_RANGE" booleanOperator="isIn">
<Array type="string">"0k-39k" "40k-59k" "80k-99k" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="46479"/>
<ScoreDistribution value="3" recordCount="13794"/>
<ScoreDistribution value="1" recordCount="11331"/>
<Node id="2" score="2" recordCount="43586">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"40-49" "70-79" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="PARTY_TYPE_CODE" booleanOperator="isIn">
<Array type="string">"Cautious Spender" "Mainstream Shoppers" "Money and Brains" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="29792"/>
<ScoreDistribution value="3" recordCount="13794"/>
<Node id="5" score="2" recordCount="41577">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"40-49" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="ANNL_INCOME_RANGE" booleanOperator="isIn">
<Array type="string">"0k-39k" "40k-59k" "60k-79k" "80k-99k" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="27783"/>
<ScoreDistribution value="3" recordCount="13794"/>
</Node>
<Node id="6" score="2" recordCount="2009">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"70-79" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="ANNL_INCOME_RANGE" booleanOperator="isIn">
<Array type="string">"100k+" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="2009"/>
</Node>
</Node>
<Node id="3" score="2" recordCount="28018">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"20-29" "50-59" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="PARTY_TYPE_CODE" booleanOperator="isIn">
<Array type="string">"Livin Large" "Value Seeker" "Young Professional" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="16687"/>
<ScoreDistribution value="1" recordCount="11331"/>
<Node id="7" score="2" recordCount="15567">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"20-29" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="ANNL_INCOME_RANGE" booleanOperator="isIn">
<Array type="string">"0k-39k" "80k-99k" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="10398"/>
<ScoreDistribution value="1" recordCount="5169"/>
</Node>
<Node id="8" score="2" recordCount="12451">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"50-59" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="ANNL_INCOME_RANGE" booleanOperator="isIn">
<Array type="string">"100k+" "40k-59k" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="2" recordCount="6289"/>
<ScoreDistribution value="1" recordCount="6162"/>
</Node>
</Node>
</Node>
<Node id="4" score="1" recordCount="28823">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"30-39" "60-69" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="ANNL_INCOME_RANGE" booleanOperator="isIn">
<Array type="string">"100k+" "60k-79k" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="1" recordCount="20800"/>
<ScoreDistribution value="0" recordCount="8023"/>
<Node id="9" score="1" recordCount="16772">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"60-69" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="PARTY_TYPE_CODE" booleanOperator="isIn">
<Array type="string">"Livin Large" "Value Seeker" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="1" recordCount="16772"/>
</Node>
<Node id="10" score="0" recordCount="12051">
<CompoundPredicate booleanOperator="surrogate">
<SimpleSetPredicate field="AGE_RANGE" booleanOperator="isIn">
<Array type="string">"30-39" </Array>
</SimpleSetPredicate>
<SimpleSetPredicate field="PARTY_TYPE_CODE" booleanOperator="isIn">
<Array type="string">"Mainstream Shoppers" "Young Professional" </Array>
</SimpleSetPredicate>
</CompoundPredicate>
<ScoreDistribution value="0" recordCount="8023"/>
<ScoreDistribution value="1" recordCount="4028"/>
</Node>
</Node>
</Node>
</TreeModel>
</PMML>
Parse XML and insert data into a table <RETWSP_TREE_CHURN_RULES> using SQL.
Create table RETWSP_TREE_CHURN_RULES as
WITH X as
(SELECT * FROM
XMLTable('for $n in /PMML/TreeModel//Node
let $rf :=
if (count($n/CompoundPredicate) > 0) then
$n/CompoundPredicate/*[1]/@field
else
if (count($n/SimplePredicate) > 0) then
$n/SimplePredicate/@field
else
$n/SimpleSetPredicate/@field
let $ro :=
if (count($n/CompoundPredicate) > 0) then
if ($n/CompoundPredicate/*[1] instance of
element(SimplePredicate)) then
$n/CompoundPredicate/*[1]/@operator
else if ($n/CompoundPredicate/*[1] instance of
element(SimpleSetPredicate)) then
("in")
else ()
else
if (count($n/SimplePredicate) > 0) then
$n/SimplePredicate/@operator
else if (count($n/SimpleSetPredicate) > 0) then
("in")
else ()
let $rv :=
if (count($n/CompoundPredicate) > 0) then
if ($n/CompoundPredicate/*[1] instance of
element(SimplePredicate)) then
$n/CompoundPredicate/*[1]/@value
else
$n/CompoundPredicate/*[1]/Array/text()
else
if (count($n/SimplePredicate) > 0) then
$n/SimplePredicate/@value
else
$n/SimpleSetPredicate/Array/text()
let $sf :=
if (count($n/CompoundPredicate) > 0) then
$n/CompoundPredicate/*[2]/@field
else ()
let $so :=
if (count($n/CompoundPredicate) > 0) then
if ($n/CompoundPredicate/*[2] instance of
element(SimplePredicate)) then
$n/CompoundPredicate/*[2]/@operator
else if ($n/CompoundPredicate/*[2] instance of
element(SimpleSetPredicate)) then
("in")
else ()
else ()
let $sv :=
if (count($n/CompoundPredicate) > 0) then
if ($n/CompoundPredicate/*[2] instance of
element(SimplePredicate)) then
$n/CompoundPredicate/*[2]/@value
else
$n/CompoundPredicate/*[2]/Array/text()
else ()
return
<pred id="{$n/../@id}"
score="{$n/@score}"
rec="{$n/@recordCount}"
cid="{$n/@id}"
rf="{$rf}"
ro="{$ro}"
rv="{$rv}"
sf="{$sf}"
so="{$so}"
sv="{$sv}"
/>'
passing dbms_data_mining.get_model_details_xml('SL_DT_CHURN_MODEL')
COLUMNS
parent_node_id NUMBER PATH '/pred/@id',
child_node_id NUMBER PATH '/pred/@cid',
rec NUMBER PATH '/pred/@rec',
score VARCHAR2(4000) PATH '/pred/@score',
rule_field VARCHAR2(4000) PATH '/pred/@rf',
rule_op VARCHAR2(20) PATH '/pred/@ro',
rule_value VARCHAR2(4000) PATH '/pred/@rv',
surr_field VARCHAR2(4000) PATH '/pred/@sf',
surr_op VARCHAR2(20) PATH '/pred/@so',
surr_value VARCHAR2(4000) PATH '/pred/@sv'))
select pid parent_node, nid node, rec record_count,
score prediction, rule_pred local_rule, surr_pred local_surrogate,
rtrim(replace(full_rule,'$O$D$M$'),' AND') full_simple_rule from (
select row_number() over (partition by nid order by rn desc) rn,
pid, nid, rec, score, rule_pred, surr_pred, full_rule from (
select rn, pid, nid, rec, score, rule_pred, surr_pred,
sys_connect_by_path(pred, '$O$D$M$') full_rule from (
select row_number() over (partition by nid order by rid) rn,
pid, nid, rec, score, rule_pred, surr_pred,
nvl2(pred,pred || ' AND ',null) pred from(
select rid, pid, nid, rec, score, rule_pred, surr_pred,
decode(rn, 1, pred, null) pred from (
select rid, nid, rec, score, pid, rule_pred, surr_pred,
nvl2(root_op, '(' || root_field || ' ' || root_op || ' ' || root_value || ')', null) pred,
row_number() over (partition by nid, root_field, root_op order by rid desc) rn from (
SELECT
connect_by_root(parent_node_id) rid,
child_node_id nid,
rec, score,
connect_by_root(rule_field) root_field,
connect_by_root(rule_op) root_op,
connect_by_root(rule_value) root_value,
nvl2(rule_op, '(' || rule_field || ' ' || rule_op || ' ' || rule_value || ')', null) rule_pred,
nvl2(surr_op, '(' || surr_field || ' ' || surr_op || ' ' || surr_value || ')', null) surr_pred,
parent_node_id pid
FROM (
SELECT parent_node_id, child_node_id, rec, score, rule_field, surr_field, rule_op, surr_op,
replace(replace(rule_value,'" "', ''', '''),'"', '''') rule_value,
replace(replace(surr_value,'" "', ''', '''),'"', '''') surr_value
FROM (
SELECT parent_node_id, child_node_id, rec, score, rule_field, surr_field,
decode(rule_op,'lessOrEqual','<=','greaterThan','>',rule_op) rule_op,
decode(rule_op,'in','('||rule_value||')',rule_value) rule_value,
decode(surr_op,'lessOrEqual','<=','greaterThan','>',surr_op) surr_op,
decode(surr_op,'in','('||surr_value||')',surr_value) surr_value
FROM X)
)
CONNECT BY PRIOR child_node_id = parent_node_id
)
)
)
)
CONNECT BY PRIOR rn = rn - 1
AND PRIOR nid = nid
START WITH rn = 1
)
)
where rn = 1;
This sql is also listed in SQL Scripts.
Save the churn rules by creating table RETWSP_TREE_CHURN_RULES as (<sql above>).
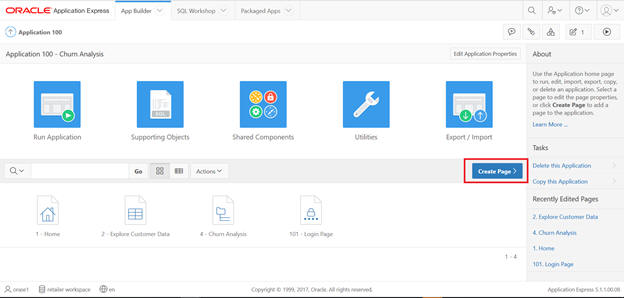
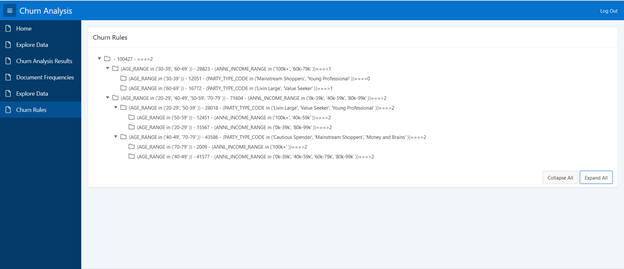
Create an application to display these rules.
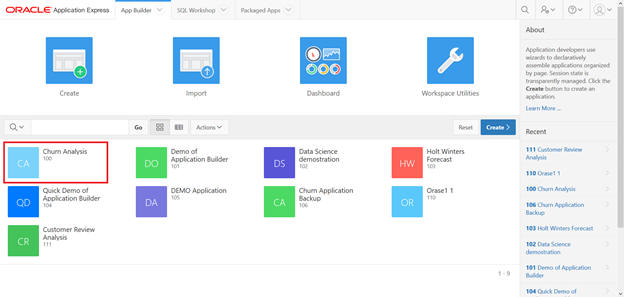
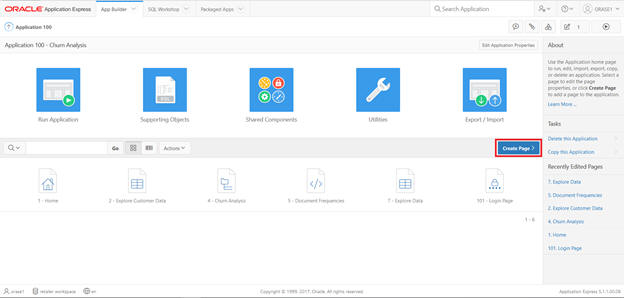
Select Churn Analysis from App Builder.
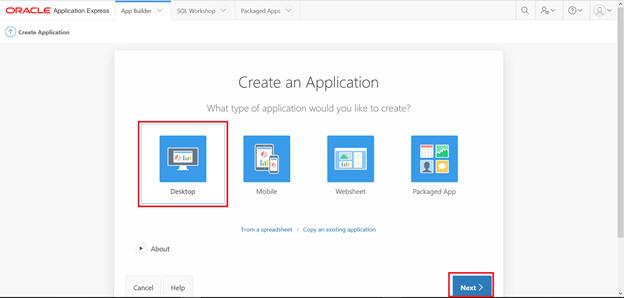
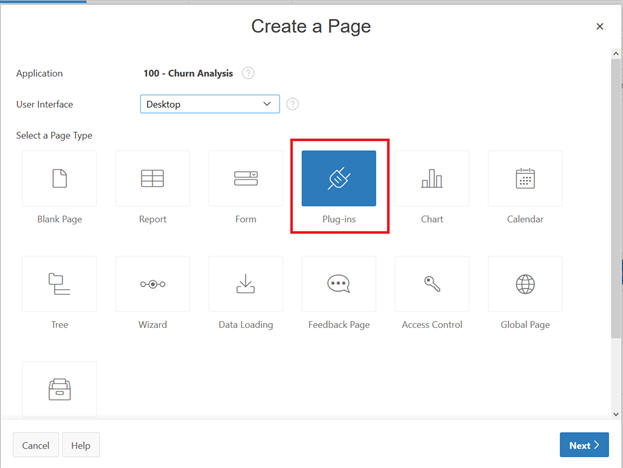
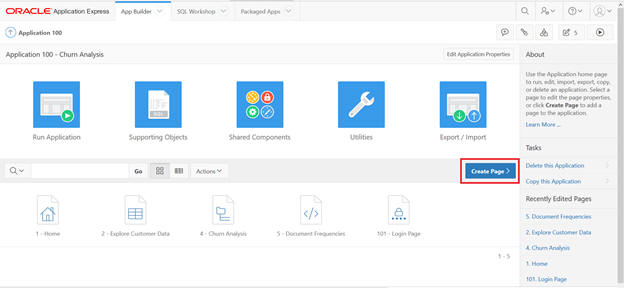
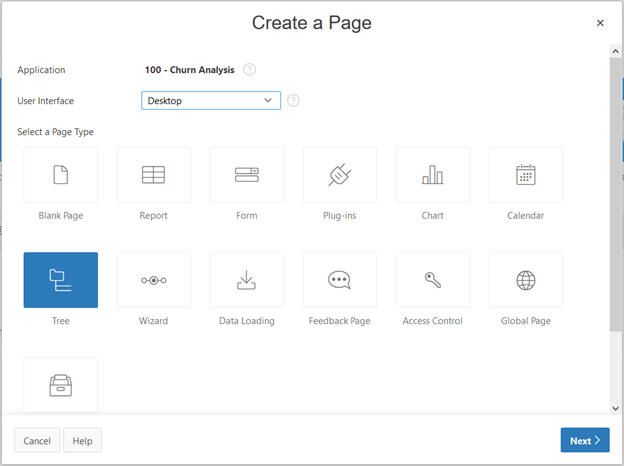
Create a page.
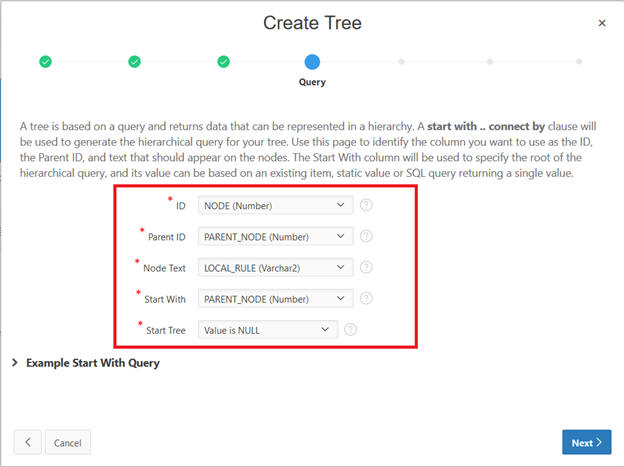
Select the Tree to display.
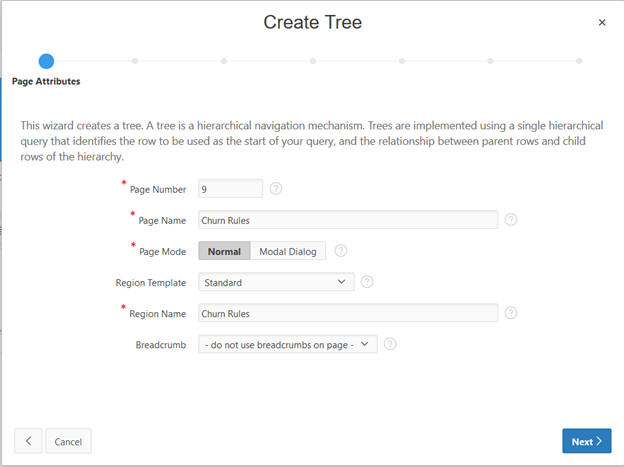
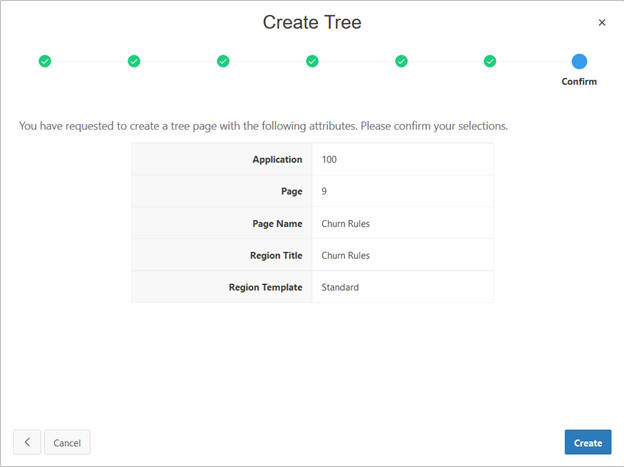
Populate Page Name as Churn Rules and click Next.
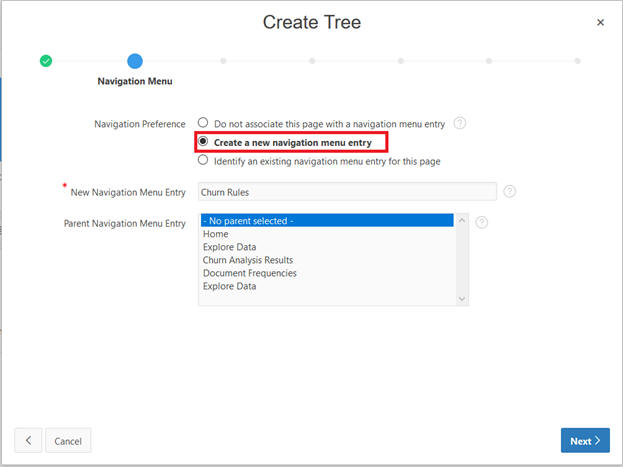
Select Create a new navigation menu entry.
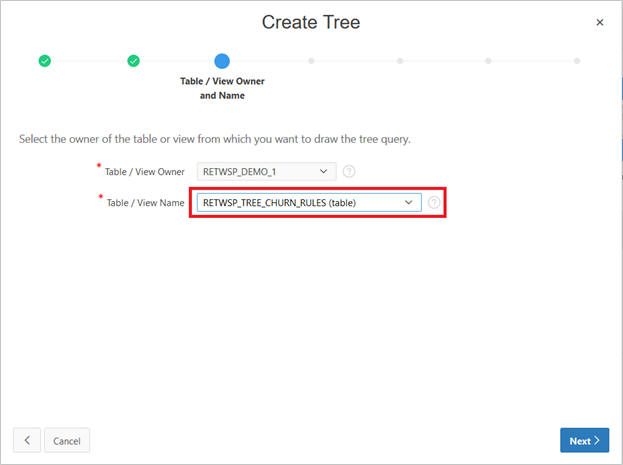
Select RETWSP_TREE_CHURN_RULES from Table/View name list.
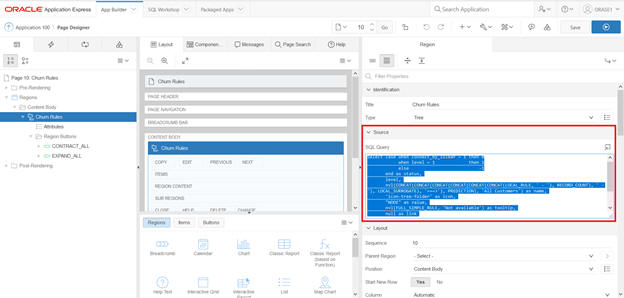
You see Page Designer.
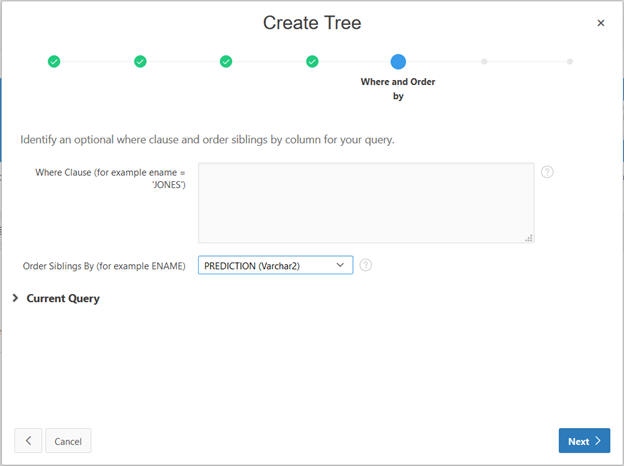
Replace the following query to better format and execute the run.
select case when connect_by_isleaf = 1 then 0
when level = 1 then 1
else -1
end as status,
level,
nvl(CONCAT(CONCAT(CONCAT(CONCAT(CONCAT(CONCAT(LOCAL_RULE, ' - '), RECORD_COUNT), ' - '), LOCAL_SURROGATE), '===>'), PREDICTION), 'All Customers') as name,
'icon-tree-folder' as icon,
"NODE" as value,
nvl(FULL_SIMPLE_RULE, 'Not available') as tooltip,
null as link
from "#OWNER#"."RETWSP_TREE_CHURN_RULES"
start with "PARENT_NODE" is null
connect by prior "NODE" = "PARENT_NODE"
order siblings by "RECORD_COUNT"
Run a new window
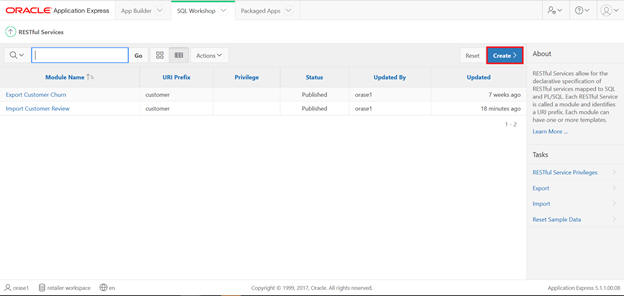
View RESTful Services
Create ReST API, which you can use to load customer reviews in the above table.
Click Create.
Populate with Name, URI Prefix, and URI Template.
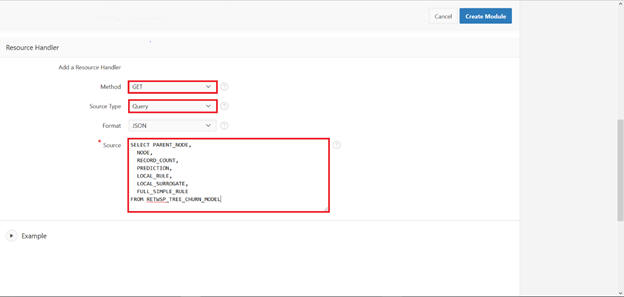
Select GET and populate the SQL as:
SELECT PARENT_NODE, NODE, RECORD_COUNT, PREDICTION, LOCAL_RULE, LOCAL_SURROGATE, FULL_SIMPLE_RULE FROM RETWSP_TREE_CHURN_MODEL
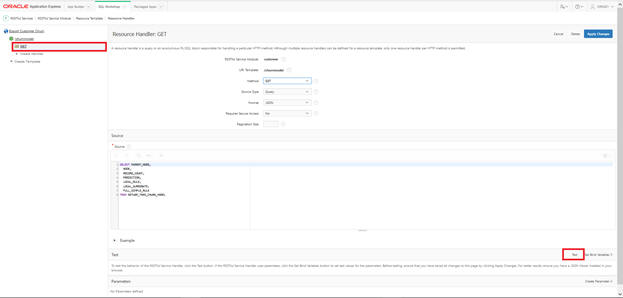
Select GET and then click Test.
Data is displayed in the window and any request to this end point http:/<url> will return the data shown in Figure A-79 in JSON format.
This exercise illustrates how to add a link to the application Task Navigation.
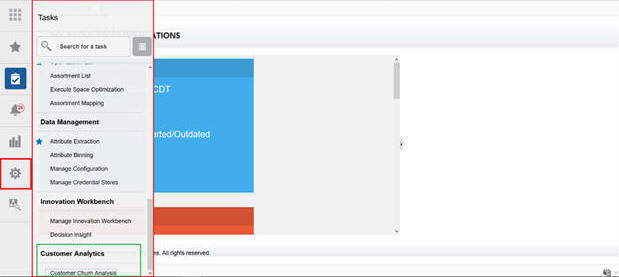
As an INSIGHT_APPLICATION_ADMINISTATOR, you can add a new task to the Tasks.
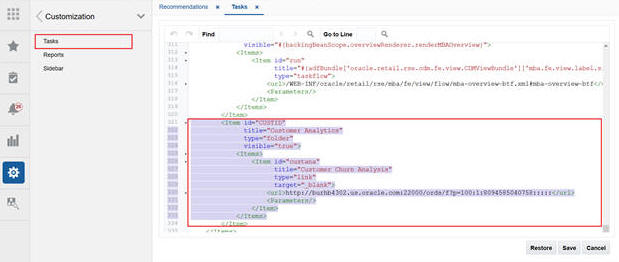
Click Customization.
The Content Area displays Navigation XML. At the end of the XML, add the following content (see Customer Analytics). Update the highlighted contents.
<Item id="CUSTID" title="Customer Analytics" type="folder" visible="true"> <Items> <Item id="custana" title="Customer Churn Analysis" type="link" target="_blank"> <url>http://<url>/ords/f?p=100:1:8094585040758:::::</url> <Parameters/> </Item> </Items> </Item>
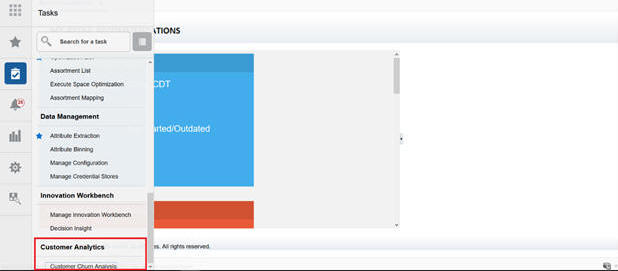
Click Save. Log out and then log back in. You should see:
Click the Customer Churn Analysis link system. A new tab is launched in the browser for the end user.
None of the tables in Retailer Workspace Schema are accessible in the Application Schema.
Executing queries in the Application Schema will result in an error. Until and unless access is provided, the user will not be able to access object/data in another schema.
describe retwsp_demo_1.p_churn_model; ERROR: ORA-04043: object retwsp_demo_1.p_churn_model does not exist select * from RETWSP_TREE_CHURN_RULES; ORA-00942: table or view does not exist 00942. 00000 - "table or view does not exist" *Cause: *Action: Error at Line: 1 Column: 15
Long running jobs must be executed under RETAILER_WORKSPACE_JOBS. These are executed in resource groups dedicated to the retailer schema.
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'retwsp_churn_model', job_type => 'STORED_PROCEDURE', job_action => 'retwsp.pkg_customer_analytics.proc_churn_model', start_date => '01-JAN-17 07.00.00 PM US/Pacific', repeat_interval => 'FREQ=YEARLY; BYDATE=0331,0630,0930,1231; ', end_date => '31-DEC-17 07.00.00 PM US/Pacific', job_class => 'RETAILER_WORKSPACE_JOBS', comments => 'Retailer workspace churn model job'); END; /
ORASE provides functionality to load data files from a customer site sent via Secure FTP, from which all other daily interface files are sent. A zip file, which can contain any number of files, can be provided, along with the specifications about the files to be loaded. (These files are referred to as context files here.) Once the data has been sent, a process is invoked from the Process Orchestration and Monitoring (POM) application to initiate loading the data into the appropriate tables inside the Innovation Workbench. Once the data load is complete, a zip will be sent to the outbound SFTP server to provide the data load logs, which will indicate whether or not there were any rejected records.
The following are the prerequisites for performing a data load:
The table must exist inside the Innovation Workbench.
A zip file named ORASE_IW_DATA.zip must be created. It must contain the data to be loaded and the context files that describe details about the data load.
After ORASE_IW_DATA.zip has been sent to the SFTP server, then a ORASE_IW_DATA.zip.complete file must be sent as well. This triggers the receipt of the data file by the application server. These two files must both be provided. The .zip must be sent first, followed by the .zip.complete file. Note that these filenames are case sensitive.
The ZIP file must contain a pair of files for each table to be loaded, a .dat file and a .ctx file.The data file can have any name, with the .dat extension. The context file must match the name of the data file, but with the .ctx extension. If a data file is provided without a .ctx file, then the data file will be ignored.
For example, to load a table called STG_WKLY_SLS, you require a file called STG_WKLY_SLS.dat to hold the data to be loaded and a file called STG_WKLY_SLS.dat.ctx to describe the details regarding the load.
No support exists for directory names inside the zip file, so if they are provided they will be ignored. For example, you cannot send directory1/STG_WKLY_SLS.dat and directory2/STG_WKLY_SLS.dat because they will end up overriding each other when the zip is extracted.
Although you can provide multiple files to be loaded in a single zip, none of them can be for the same table as another load. The load truncates the data in the table to be loaded, so if the same table is targeted by multiple files, then only the latest file will be loaded. Because this data is truncated prior to each load, you should follow a pattern in which these tables are the staging tables to be used to then populate data in other tables. In this way, the data is verified, which allow for the merging of data, via updates or inserts. This is not be possible if you loaded directly to your final table.
The .ctx file provide options for including details that describe the data load. These details are similar to the options used by SQL*Loader, so refer to documentation about the SQL*Loader for any additional details about concepts noted here.
Here is an example of a context file.
#TABLE#SLS_WKLY_SLS# #DELIMITER#|# #COLUMN#WEEK_DATE#DATE(10) "YYYY-MM-DD"# #COLUMN#PRODUCT_KEY# #COLUMN#LOCATION_KEY_FILLER#BOUNDFILLER# #COLUMN#SLS_AMT# #COLUMN#LOCATION_ID#"some_db_package.lookup_location_id(:LOCATION_KEY_FILLER)"# #COLUMN#LOAD_DATE#"sysdate"#
In the above example contextual file:
The #TABLE## line is required in order to specify the name of the table to be loaded.
The #DELIMITER## line is optional, and if not provided, then a | will be considered the default value.
The table to be loaded will be loaded via a Direct Path load (for efficiency sake). It will truncate the table prior to loading the table. This means that you cannot provide multiple files in a single transmission for the same table.
The columns can be wrapped in " " if necessary.
The data in the file must be provided as CHARACTERSET AL32UTF8.
For the column specifications, the columns must be listed in the order in which they appear in the file.The format is #COLUMN#THE_COLUMN_NAME#Any special load instructions#
Note that for Date columns, you must provide a proper date specification with the format that you are providing the data in.The example above for WEEK_DATE illustrates how to specify the date in a YYYY-MM-DD format.
For numeric columns, you do not normally require any additional load instructions.
If you are providing data that must be used as a BOUND FILLER during the load of another column, then you must specify BOUNDFILLER, just like you would in SQL*Loader.
The LOCATION_ID example above illustrates how you can refer to a FILLER column, which is then used as a parameter to a function, which then returns the actual value to load to the column.
If you want an value such as the system date/time to be loaded, then you can specify "sysdate" as shown above for LOAD_DATE column.
When you are populating columns that are loaded via a special expression (such as LOCATION_ID and LOAD_DATE above), be sure to provide them last in the context file.
When loading data character data, it maybe be necessary to specify the column like this: CHAR(50). This is commonly required by SQL*Loader when advanced character sets are used.
The examples shown above for LOCATION_KEY_FILLER and LOCATION_ID are not usual/simple use cases, but are supported. For a better understanding of how that works, refer to the documentation for SQL*Loader.
When the data load is complete, a zip file named ORASE_IW_DATA_extract.zip will be pushed to the SFTP server and it will contain the log and bad files for the data load.
In order to invoke the load process, you must use the POM application to invoke the following adhoc process:
RSE_LOAD_IW_FILES_ADHOC.
This controls the execution of all these steps. Once the load has been completed, you should be able to use the data as necessary inside the Innovation Workbench. See "Process Orchestration and Monitoring" for additional details.
You can export data that has been created within the Innovation Workbench workspace. You first configure the table to be exported, using the formatting described in Table A-1.A process is then executed that exports the table data to a text file.The data is then gathered into a zip file, and the zip file is moved to the SFTP server for retrieval.
Using the Data Management menu option (described in Oracle Retail Science Cloud Services User Guide), you can manage the tables to be exported. Once in the screen, select the table RSE_CUSTOM_EXP_CFG. Then, add rows and make adjustments to existing rows as required in order to define the tables to be exported.
Table A-1 Export Table Formatting
| Column Name | Data Type | Example | Comments |
|---|---|---|---|
|
TABLE_NAME |
Character(30) |
IW_RESULTS_TABLE |
The name of the table to be exported. |
|
FILE_NAME |
Character(80) |
iw_results_table.csv |
The name of the file to be created, excluding any directory names. |
|
DESCR |
Character(255) |
Results table of XYZ Calculation |
Any description to describe the table. |
|
COL_DELIMITER |
Character(1) |
, (comma) |
The character to use as a delimiter between columns. |
|
COL_HEADING_FLG |
Character(1) |
Y |
A Y/N value to indicate if the export should include a heading row (Y) that contains the names of the columns, or not (N). |
|
DATE_FORMAT |
Character(30) |
yyyy-MM-dd HH:mm:ss |
The format to use for any date columns. This format must be a valid format for Java date handling. |
|
ENABLE_FLG |
Character(1) |
Y |
A flag to indicate if this table should be exported (Y) or not (N) This flag can be used to temporarily disable an export, without the need to remove it completely. |
In order to begin the export process, you must use the POM application to invoke the following AdHoc process:
RSE_IW_EXPORT_FILES_ADHOC / job: RSE_IW_EXPORT_FILES_ADHOC_JOB.
This process controls the execution of the steps to export the data. Once the export has been completed, a zip file named ORASE_IW_EXPORT_extract.zip is created. All files will be named according to the names specified in the RSE_CUSTOM_EXP_CFG table. See "Process Orchestration and Monitoring" for additional details on how to execute a Standalone/AdHoc process.