


|
|
この章では、 XQuery を使用してデータ サービスを作成するための一連のベスト プラクティスについて説明します。また、データ サービス設計モデルを紹介し、データサービスを階層化して管理、保守容易性、再利用性を最大限に高めるための概念モデルについても説明します。
データ サービスを設計する際には、クエリを保守、管理、および再利用する能力を最大限まで高める必要があります。このための方法の 1 つは、サービスを以下のレベルに分割する階層化設計モデルを採用することです。
図 5-1 はデータ サービス設計モデルを示します。
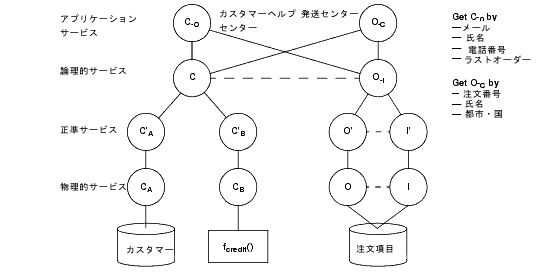
この設計モデルを使用すると、次のような方法でデータ サービスの設計と開発を行うことができます。
この節では、データ サービス設計モデルの各層におけるサービスの設計と開発を行うためのベスト プラクティスについて説明します。表 5-2 ではデータ サービス設計の原則を説明します。
表 5-3 では、データ サービスの設計および開発時に適用する実装ガイドラインについて説明します。
 
|