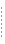このスクリプトでは、e-docs マニュアルの検索に必要な Google 検索の URL を出力します。
このスクリプトでは、e-docs マニュアルに必要なバナーを出力します。
このスクリプトでは、e-docs マニュアルの検索に必要な Google 検索のパラメータを出力します。
このスクリプトでは、e-docs マニュアルに必要な製品のブレッドクラムを出力します。
>
対話管理ガイド > コンテンツ セレクタの作成
対話管理ガイド
読書好き 」として識別されるユーザがログインしたら、コンテンツ セレクタを使用して推薦図書の一覧を表示できます。
コンテンツ管理ガイド 』の「BEA リポジトリへのコンテンツの追加」を参照してください。
読書好き 」は、このタイプのユーザ プロファイルの一例です。
注意 : この章で示す手順は、[パッケージ・エクスプローラー] ビューの data\src フォルダに関係します。data ディレクトリおよび src ディレクトリは、名前が変更されている可能性があります。
タイトル 、作者 、出版日 、ISBN 、出版社の Web サイトへの URL など、多数のプロパティを割り当てることができます。コンテンツ セレクタを使用して、箇条書きのタイトル一覧を表示し、各タイトルを出版社の Web サイトにリンクすることもできます。このリストとリンクは、コンテンツ プロパティのテキスト値のみを使用して作成されます。
ShowProperty サーブレットを使用して、バイナリ プロパティも表示できます (実画像の表示)。詳細については、「プレースホルダ ファイルの作成 」を参照してください。コンテンツ セレクタで表示できるバイナリ コンテンツのタイプは、設定した MIME タイプによって決まります。デフォルトでは、WebLogic Portal はイメージやその他のタイプのファイルを表示するための MIMEがサポートされています。その他のタイプの詳細については、「プレースホルダでのその他の MIME タイプの表示 」を参照してください。
コンテンツ セレクタ ファイル - Workshop for WebLogic で作成するコンテンツ セレクタ ファイルには、次の 2 つの部分が含まれます。
<pz:contentSelector> JSP タグ - この対応するタグは処理を実行し、Workshop for WebLogic でも作成されます。コンテンツ セレクタから返されるコンテンツは、通常ポートレットに表示されます。ユーザがコンテンツ セレクタを含むポートレットまたはポータル デスクトップを表示する場合、コンテンツ セレクタのルールとロジックは、ユーザ プロファイル情報などの一致するプロパティを探します。プロパティがコンテンツ セレクタのルールに一致する場合、コンテンツ セレクタはクエリを実行し、クエリに一致するすべてのコンテンツを取得し、表示します。
ヒント : 開発時にルール ファイルが変更されると、JSP と同じように再ロードされるので、コンテンツ セレクタを使う開発作業は短時間で済みます。ただし、サーバがプロダクション モードのときは、コンテンツ セレクタはアプリケーション内のファイルベースの定義からデータベース内にロードされ、その修正は WebLogic Portal Administration Console で行うことができます。アプリケーションを再デプロイしたり、サーバを再起動したりする必要はありません。
<img> HTML タグのソース パスには、仮想コンテンツ リポジトリのコンテンツ項目のパスを使用します。パスには、バイナリ ファイルを表示するための ShowProperty サーブレットが含まれます。node.getPath() メソッドの node は、<utility:forEachInArray> タグの id 属性に格納された特定のコンテンツ項目です。<utility:forEachInArray> id 属性値が foo の場合、メソッドは foo.getPath() のように表示されます。
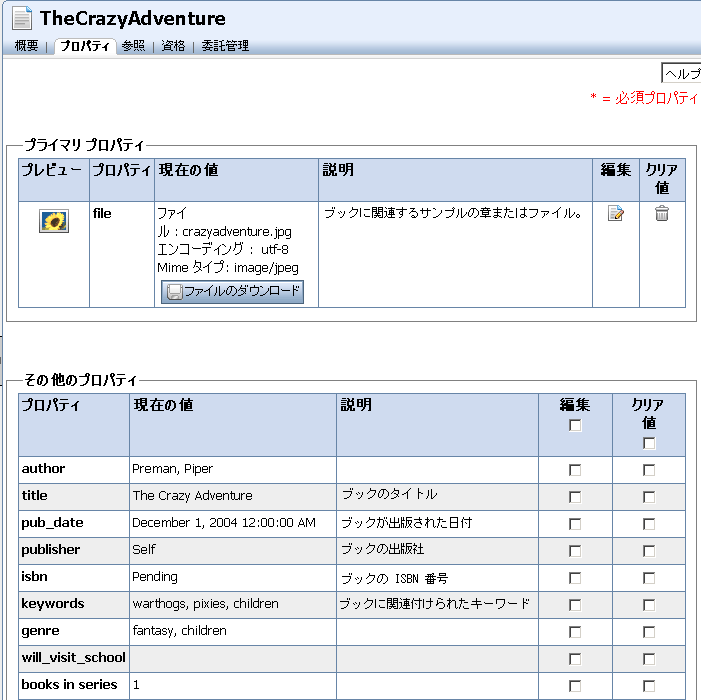
実行|サーバーで実行 ] を選択して WebLogic Server を起動します。WebLogic Server をコンフィグレーションする手順については、『ポータル開発ガイド 』を参照してください。 <data>\src\contentselectors\GlobalContentSelectors フォルダを右クリックし、[新規 |コンテンツ セレクタ ] を選択します。 図 6-1 で示すように、[ファイル名 ] フィールドにファイル拡張子 .sel を使用してコンテンツ セレクタの名前を入力します。
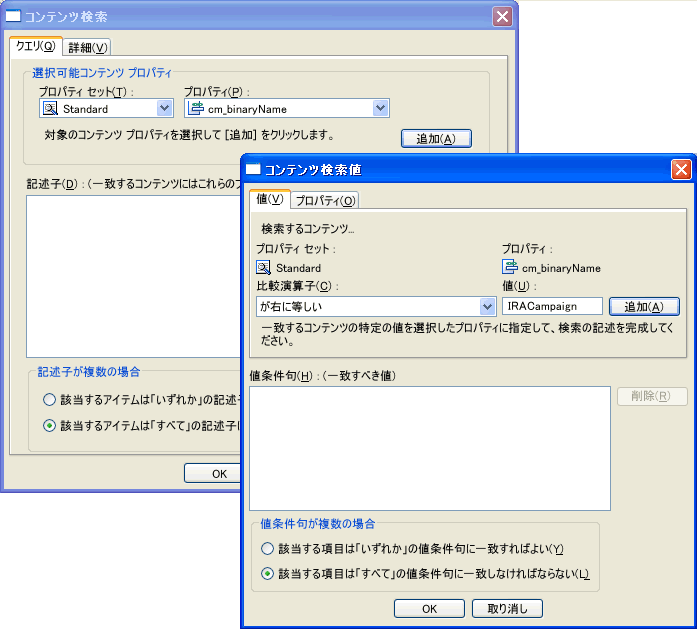
終了 ] をクリックします。 コンテンツ セレクタ エディタが表示されます。 プロパティー ] タブを選択して、コンテンツ セレクタの説明を変更します。 パレット ] タブを選択して、コンテンツ セレクタの実行条件となる [選択可能な条件] を表示します。条件を選択すると、エディタ ウィンドウの上部に対応するリンクが表示されます。 空のコンテンツ検索 ] リンクをクリックして、クエリを定義します。これを行うには、WebLogic Portal Administration Console で設定された BEA の仮想コンテンツ リポジトリに接続されている必要があります。 詳細 ] タブ)、またはグラフィカル モード ([クエリ ] タブ) で定義できます。
詳細モード - [コンテンツ検索] ウィンドウで [詳細 ] タブを選択し、「条件式を使用するコンテンツ クエリの構築 」の手順に従ってクエリを作成します。[詳細 ] タブでは、クエリのコンテキスト エラーを強調表示するためのコードのカラー表示を行うことができます。既存のクエリを [詳細 ] タブに貼り付けて再利用することができます。 グラフィカル モード - [クエリ ] タブで、次の手順を実行して、コンテンツ プロパティ、比較演算子、および値を選択し、コンテンツ項目を取得して、コンテンツ クエリを構築します。
クエリ ] タブを選択します。 追加 ] をクリックします。非公開のコンテンツを取得するデフォルト プロパティ セットの 1 つは標準バージョンです。標準バージョンのプロパティを使用して、コンテンツの検索範囲を絞ります。たとえば、cm_latestVersion プロパティを選択すると、最新バージョンのグラフィックのみを取得します。
注意 : 選択するプロパティは、ユーザ プロファイルまたはセッション プロパティなどのプロパティ セット プロパティではなく、システム コンテンツ プロパティです。
追加 ] をクリックします。[コンテンツ検索] ウィンドウにクエリ記述子が追加されます。 記述子が複数の場合 ] 領域で、適切なオプションを設定できます。 OK ] をクリックして、クエリを検索に追加します。 コンテンツ プレビュー ] タブをクリックして、クエリによって取得されるコンテンツをプレビューできます。[ユーザ プロファイル] プロパティから値を使用するようにクエリを定義した場合、取得されたコンテンツはユーザごとに異なるため、[プレビュー ユーザ ] フィールドに既存のユーザのユーザ名を入力して、そのユーザに対して取得されるコンテンツを確認する必要があります。デフォルトでは、公開済みコンテンツをプレビューします。公開されていないコンテンツをプレビューするには、[Controls whether this will preview unpublished or published content ] をクリックし、詳細を表示します。
コンテンツ管理ガイド 』の「BEA リポジトリへのコンテンツの追加」を参照してください。
ファイル|保存 ] を選択して、コンテンツ セレクタ ファイルを保存します。 <pz:contentSelector> タグを追加します。<pz:contentSelector> タグを使用して、テキスト コンテンツ (HTML ファイルなどのテキスト バイナリを含む) および非テキスト バイナリ (グラフィック) を表示する方法の詳細については、「JSP タグを使用するコンテンツ セレクタ ファイルの表示 」を参照してください。
ヒント : コンテンツ セレクタでは、画像などのバイナリ コンテンツを表示できます。詳細については、『コンテンツ管理ガイド 』を参照してください。
図 6-3 は、classic.sel というコンテンツ セレクタ ファイルを示します。コンテンツ セレクタをトリガする条件は、Americas という値を持つプロパティ セット SalesRegion を持つユーザです。取得するコンテンツは、名前に IRACampaign を含む任意のバイナリ ファイル コンテンツです。
ヒント : ライブラリ サービス (バージョン管理およびワークフロー ステータスなど) が BEA リポジトリで有効の場合、コンテンツ項目が廃棄済みステータスになっていない限り、システム プロパティは常にクエリできる ようになります。公開コンテンツと非公開コンテンツの両方を検索することができます。コンテンツ タイプに基づいてコンテンツを取得する場合は、コンテンツ クエリで cm_objectClass システム プロパティを使用する必要があります。クエリがシステム プロパティだけを使用する場合、クエリは廃棄されていないシステム プロパティに一致するすべてのコンテンツ項目を取得します。
<property><comparator><value> の 3 つの部分があります。
true の場合、一致するすべてのコンテンツ項目が取得されます。
employee_type == 'manager'
このクエリは、BEA 仮想コンテンツ リポジトリから、厳密に一致する (==) 文字列
manager を含む
employee_type というプロパティを持つコンテンツ項目を取得する。
and (&&) および or (||) ロジックを使用する複数の句で構成されます。次に例を示します。
(genre == 'rock' || genre == 'alternative') &&
このクエリは、
rock または (||)
alternative の正確な値を持つ
genre プロパティのコンテンツ項目と
2 より大きい
platinum_records プロパティ値の持つ (&&) コンテンツ項目を取得する。括弧は、クエリの 1 つのセクションと次のセクションを区切り、評価の順番を制御する。
(genre=='rock' || genre=='country') && artist=='dead'
このクエリは、
rock または
country の正確な値を持つ
genre プロパティのコンテンツ項目と値が
dead の
artist プロパティ値を持つコンテンツ項目を取得する。
and (&&) および or (||) ロジックを使用して評価されます。
ヒント : 開発サーバが稼動している状態で、Workshop for WebLogic でテスト プレースホルダまたはコンテンツ セレクタを作成し、[コンテンツ検索] ウィンドウの [詳細 ] タブを使用して、クエリを構築します。取得したコンテンツは [コンテンツ プレビュー ] タブで表示されます。userProperty() フォーマットを使用してクエリの値を取得する場合は、[コンテンツ プレビュー ] タブの [プレビュー ユーザ ] フィールドにユーザ名を入力して、そのユーザの値を取得し、取得したコンテンツ項目を表示する必要があります。
表 6-1 を参照してください。
types というセットに格納されます。たとえば、Book というタイプを作成し、title 、author 、pub_date 、isbn などのプロパティを追加することができます。
com.bea.content.expression.Search クラスにもリストされ、表 6-1 に表示される項目を含みます。
コンテンツ項目のユニークな ID。コンテンツ項目のユニークな ID を参照するには、Administration Console でコンテンツ項目を選択し、説明を表示する。
コンテンツ項目の作成日。コンテンツ項目の作成日情報を表示するには、Administration Console でコンテンツ フォルダを選択し、[
概要 ] タブを選択する。
コンテンツ項目の作成者。コンテンツ項目の作成者情報を表示するには、Administration Console でコンテンツ フォルダを選択し、[
概要 ] タブを選択する。
コンテンツ項目の最終変更日。コンテンツ項目の変更日情報を表示するには、Administration Console でコンテンツ フォルダを選択し、[
概要 ] タブを選択する。
Administration Console に表示するコンテンツ項目名。
仮想コンテンツ リポジトリのコンテンツ項目へのパス。
/BEARepository/ juvenilebooks/ TheCrazyAdventure など。
Node.type == Node.HIERARCHY
コンテンツ項目ではなく、コンテンツ フォルダを識別する。コンテンツ フォルダにはコンテンツ項目と子コンテンツ フォルダを含めることができる。このプロパティをクエリに使用する場合は、
true または
false のブール値で比較する。
Node.type == Node.CONTENT
コンテンツ フォルダではなく、コンテンツ項目を識別する。コンテンツ項目には、関連付けられたタイプのプロパティが含まれる。このプロパティをクエリに使用する場合は、
true または
false のブール値で比較する。
コンテンツ項目に関連付けられたコンテンツ タイプ。コンテンツ項目のタイプ情報を参照するには、Administration Console で [
タイプ ] タブを選択し、[
概要 ] タブを選択する。
特定のオブジェクト クラスのすべてのインスタンスとそのすべての子を検索する。
特定の値を持つプロパティのメタデータ検索。このプロパティはワイルドカード検索に類似する。
コンテンツ項目のバイナリ プロパティの MIME タイプ。
image/jpeg など。コンテンツ項目の MIME タイプを表示するには、Administration Console でコンテンツ項目を選択し、[
プライマリ プロパティ データ型 ] フィールドを調べる。
BinaryValue. size (ノード プロパティの場合)
コンテンツ項目のバイナリ値のサイズ。コンテンツ項目のバイナリ値のサイズを表示するには、Administration Console でコンテンツ項目を選択し、[
プロパティ ] タブを選択して、[
ファイルのダウンロード ] をクリックする。[
保存 ] をクリックし、表示されたバイナリ ファイルを右クリックして、ファイル プロパティを表示する。
このプロパティをクエリで使用する場合は、バイナリ サイズをバイト単位で指定する。
BinaryValue. name (ノード プロパティの場合)
コンテンツ項目のバイナリ値のファイル名。コンテンツ項目のバイナリ値の名前を参照するには、Administration Console でコンテンツ項目を選択し、[
概要 ] タブで [
名前 ] の値を表示する。
ノードが割り当てられているユーザ。
cm_assignedToUser = `joe' など。
ノードがチェックアウトされた場合。たとえば、
cm_checkedOut = false。
コンテンツの最新のバージョン
cm_latestVersion = true など。
ノードが割り当てられているロール。
cm_role = `Admin' など。
コンテンツのバージョン番号値は String です。たとえば、
cm_version = `5' となります。
バージョンの変更を説明するテキスト。たとえば、
cm_versionComment = Includes updates from Marketing.
title <comparator> <value> のように指定します。ただし、プロパティ名にスペース、二重引用符、またはダッシュ記号が含まれる場合は、プロパティ名を toProperty() 内に囲む必要があります。たとえば、toProperty('Favorite Author') <comparator> <value> のように指定します。
title プロパティを持つ book タイプと article タイプを使用する場合、cm_objectClass プロパティを使用して、book タイプ内の特定の title を持つコンテンツ項目を取得することができます。
likeignorecase '*Adventure' && cm_objectClass = 'books' のように指定します。
表 6-2 に、クエリで使用できる比較演算子を示します。
単値のプロパティ (リストに含まれる単値を含む) が入力した大文字と小文字を区別する値 (ブール値、日付と時刻、数値、文字列値) と厳密に等しいかどうかをチェックする。たとえば、
genre == 'fantasy' は、
genre プロパティの値として、大文字と小文字を区別する
fantasy を持つコンテンツ項目を取得する。
単値のプロパティ (リストに含まれる単値を含む) が入力した大文字と小文字を区別する値 (ブール値、日付と時刻、数値、文字列値) と厳密に等しくないことをチェックする。たとえば、
genre != 'mystery' は、
genre プロパティの値として、大文字と小文字を区別する
mystery を持たないコンテンツ項目を取得する。
単値のプロパティが、指定した値 (日付または時刻、および数値) より大きいかどうかをチェックする。たとえば、
pub_date > toDate('MM-dd-yyyy', `01-01-2000') は、
January 1, 2006 以降の値に設定した
pub_date プロパティ セットを持つコンテンツ項目を取得する。
単値のプロパティが、指定した値 (日付または時刻、および数値) より小さいかどうかをチェックする。たとえば、
books in series < 3。プロパティ名にスペースが含まれているので、
toProperty('books in series') < 3 のように
toProperty() を使用して、
3 より小さい books in series プロパティ値を持つコンテンツ項目を取得します。
単値のプロパティが、指定した値 (日付または時刻、および数値) より大きいかまたは等しいことをチェックする。たとえば、
toProperty('books in series') >= 3 は、3 より大きいかまたは等しい
books in series プロパティ値を持つコンテンツ項目を取得する。サンプル コンテンツ項目のプロパティ値は、
1。
単値のプロパティが、指定した値 (日付または時刻、および数値) より小さいかまたは等しいことをチェックする。たとえば、
toProperty('books in series') <= 3 は、3 より小さいかまたは等しい
books in series プロパティ値を持つコンテンツ項目を取得する。
単値のプロパティが、入力した大文字と小文字を区別する値に類似しているかどうかをチェックする。ワイルドカード文字 * (1 つまたは複数の文字) または ? (1 文字) を使用できる。たとえば、
author like 'P?nm*' は、大文字と小文字を区別する Penman、Panmen、または
P と
n の間に別の 1 文字を持ち、
m の後に任意の 1 つ以上の文字を持つ author プロパティのコンテンツ項目を取得する。
注意 : 末尾にアスタリスク (*) を指定しない場合、プロパティ値の名前 Penman の後にはさらにテキストが続くため、コンテンツ項目は取得されない。
単値のプロパティが、入力した値に類似しているかどうかをチェックする。ワイルドカード文字 * と ? を使用できる。大文字と小文字は区別されない。たとえば、
author likeignorecase 'pen*' は、
penman、
Penman、
Penfield など、
pen で始まる任意の組合せの author プロパティの値を持つコンテンツ項目を取得する。
多値のプロパティが、指定した単値 (日付または時刻、数値、および文字列値) と厳密に等しい単値を含むかどうかをチェックする。一部の実装では、この比較演算子は単値のプロパティに対しても使用できる。たとえば、
genre contains 'fantasy' は、厳密に
fantasy と等しい
genre プロパティ値を含むコンテンツを取得する。
多値のプロパティが、指定した値 (日付または時刻、数値、および文字列値) と厳密に等しい値をすべて含むかどうかをチェックする。たとえば、
genre containsall ('fantasy', 'children') は、
fantasy および
children という
genre プロパティ値を含むコンテンツを取得する。一部の実装では、この比較演算子は単値のプロパティに対しても使用できる。
多値のプロパティが、指定した値 (日付または時刻、数値、および文字列値) と厳密に等しい任意の値を含むかどうかをチェックする。たとえば、
genre containsany ('fantasy', 'children', 'scifi') は、
fantasy、
children、または
scifi という
genre プロパティ値を含むコンテンツを取得する。一部の実装では、この比較演算子は単値のプロパティに対しても使用できる。
単値のプロパティが、入力した値のいずれかを含むどうかをチェックする。入力した値が使用可能な値 (単値) のリストではない場合、
in は
= または
== と同じとなる (日付または時刻、数値、および文字列値)。たとえば、
isbn in ('pending', 'not_available') は、
pending または
not_available という
isbn プロパティ値を含むコンテンツを取得する。
title というプロパティを持つ book というコンテンツ タイプを使用する場合、book タイプに関連付けられるすべてのコンテンツ項目は title フィールドを持ちます。各 title 値はユニークであるため、クエリでユニークな値を入力して、特定のコンテンツ項目を取得したり、比較演算子を使用して、特定のコンテンツ項目を無視することができます。
クエリ内にハード コーディングした値 - ハード コーディングした値を使用して、クエリの予測性を向上させます。ハード コーディングした値を使用して、取得する特定のコンテンツを正確に指定することができます。 ユーザ プロファイルまたはプロパティ セットのその他のタイプからの値の取得 (セッションおよびリクエスト) - ユーザ プロファイル、セッション、またはリクエストのプロパティ セットから値を読み込む場合、個々の指定したユーザ プロファイル、セッション、またはリクエストのプロパティの値がプログラムによってクエリに挿入されます。これにより、現在のユーザのプリファレンスまたは現在のセッションまたはリクエストに基づいて、パーソナライズされたクエリを作成することができます。 author であるクエリでは、ユーザの FavoriteAuthor プロファイルのプロパティを取得してクエリに値を入力し、それによりクエリがユーザの好みの作者に関連するコンテンツを取得できるようにできます。
'pending' のように指定します。 "The Crazy Adventure" のように二重引用符で囲まれている場合、'\"The Crazy Adventure\"' のように値を入力します。タイトルが単一引用符で囲まれている場合、title = '\'The Crazy Adventure\'' のように値を値を入力します。 "\u6565" など)、8 進数 ("\7"、"\65"、"\377" など)、および標準 Java エスケープ シーケンス ("\n"、"\r"、"\b" など) を文字列で使用できる。 true または false キーワードのいずれかである (引用符なしの小文字)。 toDate('formatStr', 'dateStr') 形式で表されます。ここで、formatStr は使用する日付と時刻形式 ('MM/dd/yyyy' など)、dateStr は入力する実際の日付と時刻 ('01/01/2006' など) を示します。formatStr は有効な java.text.SimpleDateFormat 文字列でなければなりません。formatStr を省略する場合、toDate() は 'MM/dd/yyyy HH:mm:ss z' 形式で入力する日付と時刻を使用します (ここで、z は MDT などのタイムゾーンを示します)。たとえば、toDate('12/01/2004 06:00:00 MDT') のように指定します。formatStr で使用する形式で入力します。たとえば、日付値だけの場合、toDate('MM/dd/yyyy', '12/01/2004') のように指定します。また、'MM-yyyy' のように、月と年だけを指定することもできます。now キーワードを使用して、実行時に式が解析される時刻を指定します。
<type>Property(<propertyset>, <propertyname>) 形式を使用する。ここで、タイプは user 、request 、または session です。たとえば、userProperty('userpreferences', 'FavoriteAuthor') のように指定します。 and (&& ) ロジックおよび or (|| ) ロジックによって結合し、数式と同様に括弧を使用して評価の順番を制御することにより、複数の独立したクエリ句を組み合わせることができます。これにより、複雑なクエリを作成することができます。また、括弧で囲まれたグループの前に感嘆符を使用して、複雑なクエリに not ロジック (! ) を含めることもできます。
コンテンツ管理ガイド 』を参照してください
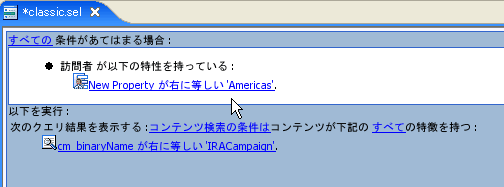
図 6-4 は、BEA の仮想コンテンツ リポジトリに格納されたブックのプロパティ セットを示します。
表 6-3 のクエリの例は、サンプル コンテンツ項目のプロパティを使用し、各クエリのサンプルの説明は、クエリがコンテンツ項目を取得するかどうかを示します。
genre プロパティの値として、大文字と小文字を区別する
fantasy を持つコンテンツ項目を取得する。
will_visit_schools == true
true に設定された
will_visit_schools プロパティを持つコンテンツ項目を取得する。
true は単一引用符で囲まない。また、
true は小文字を使用する。
genre プロパティの値として、大文字と小文字を区別しない
mystery を持つコンテンツ項目を取得する。
pub_date > toDate('MM-dd-yyyy', '01-01-2005')
January 1, 2005 以降の値に設定された
pub_date プロパティを持つコンテンツ項目を取得する。
プロパティ名にスペースが含まれるため、次の例に示すように
toProperty() を使用する必要がある。
toProperty('books in series') < 3
3 より少ない
books in series プロパティの値を持つコンテンツ項目を取得する。
toProperty('books in series') >= 3
3 より大きいかまたは等しい
books in series プロパティの値を持つコンテンツ項目を取得する。サンプル コンテンツ項目のプロパティ値は、
1。
toProperty('books in series') <= 3
3 より小さいかまたは等しい
books in series プロパティの値を持つコンテンツ項目を取得する。
大文字と小文字を区別する Penman、Panmen、または
P と
n の間に別の 1 文字を持ち、
m の後に任意の 1 つ以上の文字を持つ
author プロパティのコンテンツ項目を取得する。末尾にアスタリスク (
*) を使用しない場合、プロパティ値の名前 Penman の後にはさらにテキストが続くため、コンテンツ項目は取得されない場合がある。
author likeignorecase 'pen*'
penman、Penman、Penfield など、
pen で始まる任意の組合せの author プロパティの値を持つコンテンツ項目を取得する。
厳密に
fantasy である
genre 値を含むコンテンツを取得する。
contains 比較演算子はワイルドカード文字を許容しない。
genre containsall ('fantasy', 'children')
fantasy および
children という
genre プロパティ値を含むコンテンツを取得する。
genre containsall ('fantasy', 'children', 'scifi')
fantasy、
children、および
scifi という
genre プロパティ値を含むコンテンツを取得する。サンプル コンテンツ項目には、
fantasy と
children が含まれるが、
scifi は含まれない。
genre containsany ('fantasy', 'children', 'scifi')
fantasy、
children、または
scifi という
genre プロパティ値を含むコンテンツを取得する。
isbn in ('pending', 'not_available')
pending または
not_available のいずれかの
isbn プロパティ値を含むコンテンツを取得する。
toProperty('books in series') >= 3 &&
January 2005 以後に発行された
trilogy の一部であるブックを取得する。
(genre contains 'children' || keywords like '*children*') && will_visit_schools == true
children に設定されているか、またはキーワード値に
*children* を持ち、作者が学校を訪問できる
genre 値を持つブックを取得する。
((genre contains 'children' || keywords like '*children*') && will_visit_schools == true) && isbn != 'pending'
children に設定されているか、またはキーワード値に
*children* を持ち、作者が学校を訪問できる
genre 値を持つブックと
pending に等しくない (つまり、ブックがまだ発行されていない)
isbn 値を持つブックを取得する。括弧によるネストは評価の順番を制御する。
(title likeignorecase '*adventure' || genre contains 'fantasy') && (pub_date >= toDate('MM-yyyy', '01-2005') || isbn == 'pending')
title に
*adventure を含むか、
genre に
fantasy を含み、
pub_date が
January 2005 以後であるか、または
isbn が
pending のまま (まだ発行されていない) のブックを取得する。
(genre containsany userProperty('userpreferences', 'BookGenre') && (keywords likeignorecase '*pixies')) ||
ユーザ プロファイルのプロパティを読み込み、特定のプロパティ値を使用して、クエリに値を入力する。取得されたコンテンツがユーザ プリファレンスに基づいているので、クエリはパーソナライズされたコンテンツを提供する。
たとえば、現在のユーザが
mystery に設定された
BookGenre プロパティを使用し、
FavoriteAuthor が
Penman、
Piper に設定されている場合、クエリがサンプル コンテンツを返す。
BookGenre 値が最初の句に一致しない場合でも、2 番目の
or (
||) 句の
FavoriteAuthor が一致する。
プロパティ コントロールまたは
setProperty JSP タグを使用して、ユーザ プロパティ セットおよびプロパティを (Workshop for WebLogic でプロパティ セットを作成するのではなく) プログラムで使用して設定する場合、
userProperty() をクエリで使用できる。
その他の便利なクエリ (サンプル コンテンツに関係しない)
language == userProperty('userpreferences', 'userPreferredLang')
この方法を使用して、プロパティ セットに格納されたユーザの言語プリファレンス
(userPreferredLang) に基づいて、各ユーザに適切な言語のコンテンツを提供できる。また、
sessionProperty() を使用して、セッションから言語プリファレンスを取得するか、または
requestProperty('DefaultRequestPropertySet', 'Locale') を使用して、
en-US などのユーザのロケール文字列を返すことができる。
((UserAge <= 35 && colors contains 'red' ||
このクエリは、
!(
colors contains 'black') 句に示すように、
not ロジックを使用する。
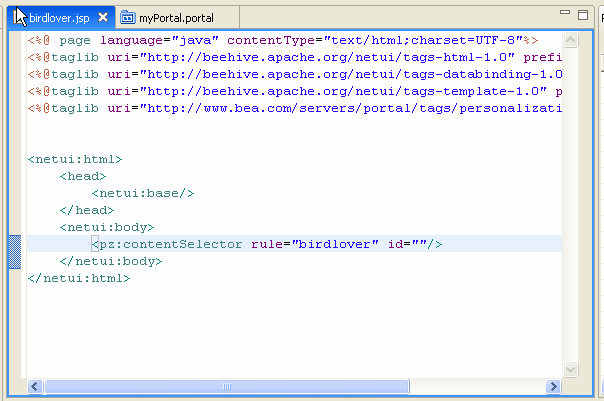
コンテンツ セレクタ ファイルの作成 」を参照)、<pz:contentSelector> JSP タグを使用してコンテンツを表示する必要があります。図 6-3 に示すように、以下の JSP タグは classic コンテンツ セレクタを使用します。
rule 属性 - コンテンツ セレクタ ファイルの名前 (ファイル拡張子なし) を含みます。この属性は、使用するパーソナライゼーション ルールとクエリを JSP タグに指定します。 id 属性 - コンテンツ セレクタがクエリを実行すると、コンテンツは仮想コンテンツ リポジトリからコンテンツ プロパティの配列として取得されます。id 属性は、JSP タグを設定する際に String として入力し、配列を保持するコンテナの役割を果たします。この時点で、他の JSP タグを使用して、配列の処理およびコンテンツの表示を行う必要があります。プロパティの配列を処理してコンテンツを表示する方法については、「プレースホルダでのその他の MIME タイプの表示 」を参照してください。 <pz:contentSelector> タグに設定できる属性があります。クラスの詳細については、「JSP Tag Javadoc
rule および id 属性が自動的に読み込まれ、タグ ライブラリの include 文が自動的に追加されます。コード リスト 6-1 に示すように、その他の JSP と HTML タグも自動的に追加されます。
コード リスト 6-1 他の JSP タグと HTML タグが含まれた JSP ファイル
表 6-4 では、コンテンツ セレクタで使用できる JSP タグを説明します。
配列にコンテンツが実際に含まれているかどうかをチェックする。
コンテンツ項目を箇条書きで表示するためのコンテナを提供する。
配列の各コンテンツ項目を分離し、配列内のすべての項目を処理するまで繰り返す。項目ごとに
<li> 項目を指定する。
<utility:forEachInArray> から各コンテンツ項目を取り出し、表示されるコンテンツ プロパティを指定する。
コード リスト 6-2 に、パーソナライズされたコンテンツに対して複数のコンテンツ セレクタを使用する方法を示します。
コード リスト 6-2 複数のコンテンツ セレクタでの <pz:contentSelector> JSP タグの使用
<pz:div> JSP タグは、インライン HTML パーソナライゼーションを提供できます。インライン コンテンツのセットを JSP に挿入し、このタグでラップできます。このタグは rule 属性を使用します。この属性には既存のユーザ セグメント名を指定できます。該当するユーザ セグメントのメンバーだけがインライン コンテンツを表示できます。たとえば、Workshop for WebLogic で、任意のユーザを bookfan ユーザ プロファイルのプロパティ セットの値が true であるメンバーにする bookfanUserSegment.seg というユーザ セグメントを作成しました。以下のサンプル コードは、この方法を示しています。
<pz:div> タグは、ほぼ同じレベルのパーソナライゼーションを提供します。相違点は、コンテンツ セレクタでは仮想コンテンツ リポジトリからコンテンツを取得しますが、<pz:div> タグでは JSP 内にインライン コンテンツが含まれることです。
ヒント : コンテンツ セレクタでは、画像などのバイナリ コンテンツを表示できます。詳細については、『コンテンツ管理ガイド 』を参照してください。
注意 : この章で示す手順は、[パッケージ・エクスプローラー] ビューの data\src フォルダに関係します。data ディレクトリおよび src ディレクトリは、名前が変更されている可能性があります。
<data>\src\contentselectors\GlobalContentSelectors フォルダにあるコンテンツ セレクタ ファイルを開きます。 クエリ ] リンクをクリックします。 削除 ] をクリックします。 OK ] をクリックします。
<data>\src\contentselectors\GlobalContentSelector フォルダにあるコンテンツ セレクタ ファイルを開きます。 削除 ] を選択します。 はい ] をクリックして削除を続行します。
ヒント : 削除したコンテンツ セレクタを参照している <pz:contentSelector> タグが JSP 内にある場合は、すべて削除する必要があります。
Workshop for WebLogic - 開発者は Workshop for WebLogic を使用してコンテンツ セレクタの条件とクエリを変更できます。詳細については、「コンテンツ セレクタの変更 」を参照してください。 Administration Console - ポータル管理者は Administration Console を使用してコンテンツ セレクタのプロパティまたは説明を編集できます。詳細については、「コンテンツ セレクタの変更 」を参照してください。