TM
TM| ドキュメントのダウンロード | サイト マップ | Glossary | TM|
|
|||
| BEA ホーム | 製品 | dev2dev | support | askBEA |
| TM |
|
||||||||
| e-docs > WebLogic ServerTM > WebLogic エンタープライズ JavaBeans プログラマーズ ガイド > WebLogic Server のコンテナ管理による永続性サービス |
|
WebLogic エンタープライズ JavaBeans プログラマーズ ガイド
|
WebLogic Server のコンテナ管理による永続性サービス
以下の節では、WebLogic Server EJB コンテナでサポートされているコンテナ管理による永続性(CMP)機能について説明します。
EJB コンテナは、EJB と WebLogic Server 間の統一的なインタフェースを提供します。コンテナは、EJB の新しいインスタンスを作成し、これらの Bean リソースを管理し、トランザクション、セキュリティ、同時実行性、ネーミングなどの永続性サービスを実行時に提供します。ほとんどの場合、WebLogic Server の旧バージョンの EJB はコンテナで動作します。 ただし、Bean のコードの移行が必要な場合については、『Migration Guide』を、変換ツールの使い方については、DDConverterを参照してください。
WebLogic Server のコンテナ管理による永続性 (CMP) モデルでは、EJB のインスタンス フィールドをデータベースのデータと同期することで、CMP エンティティ Bean の永続性を実行時に自動処理します。
エンティティ Bean では、コンテナ管理による永続性を利用して、エンティティ Bean インスタンスで永続データ アクセスを実行するメソッドが生成されます。生成されたメソッドでは、エンティティ Bean インスタンスと基盤のリソース マネージャの間でデータが転送されます。永続性は実行時にコンテナによって処理されます。コンテナ管理の永続性を利用する利点は、エンティティが格納されるデータ ストアからエンティティ Bean が論理的に独立することです。コンテナでは、論理的な関係と物理的な関係のマッピングが実行時に管理されると同時に、それらの参照整合性が管理されます。
永続フィールドと関係によって、エンティティ Bean の抽象永続性スキーマが構成されます。デプロイメント記述子は、エンティティ Bean でコンテナ管理による永続性が使用されることを示します。また、デプロイメント記述子は、データにアクセスするコンテナへの入力としても使用されます。
WebLogic Server は、エンティティ Bean に永続性サービスを提供します。エンティティ EJB が任意のトランザクション対応またはトランザクション非対応の永続ストレージにその状態を保存する (「Bean 管理による永続性」) ことも、コンテナが EJB の非 transient インスタンス変数を自動的に保存する (「コンテナ管理による永続性」) こともできます。WebLogic Server では、このどちらも選択可能であり、両者を併用することもできます。
EJB がコンテナ管理の永続性を使用する場合、EJB が使用する永続性サービスのタイプを weblogic-ejb-jar.xml デプロイメント ファイルに指定します。 自動永続性サービスのハイレベル定義は、persistence-use 要素に格納されます。persistence-use には、EJB がデプロイ時に使用するサービスが定義されます。
自動永続性サービスは、さらに別のデプロイメント ファイルを使用してそのデプロイメント記述子を指定し、エンティティ EJB ファインダ メソッドを定義します。 たとえば、WebLogic Server RDBMS ベースの永続性サービスは、特定の Bean からデプロイメント記述子とファインダ定義を取得するときに、その Bean の weblogic-cmp-rdbms-jar.xml ファイルを使用します。詳細については、WebLogic Server RDBMS 永続性の使い方で説明します。
サードパーティの永続性サービスでは、他のファイル フォーマットを使用してデプロイメント記述子をコンフィグレーションします。 しかし、ファイルのタイプに関係なく、コンフィグレーション ファイルは weblogic-ejb-jar.xml の persistence-use 要素で参照しなければなりません。
注意: コンテナ管理による永続性 Bean では、接続プールの最大接続数を 1 より大きい値にコンフィグレーションします。WebLogic Server のコンテナ管理による永続性サービスでは、同時に 2 つの接続を取得しなければならない場合があるからです。
EJB で WebLogic Server RDBMS ベースの永続性サービスを使用するには、次の手順に従います。
WebLogic Server のユーティリティ、DDConverter を使用してこのファイルを作成した場合、ファイルの名前は weblogic-cmp-rdbms-jar.xml となります。このファイルをまったく新しく作成する場合は、異なる名前でファイルを保存できます。ただし、weblogic-ejb-jar.xml の persistence-type および persistence-use 要素が適切なファイルを参照していることを確認する必要があります。
weblogic-cmp-rdbms-jar.xml は、WebLogic Server RDBMS ベースの永続性サービスを使用して EJB の永続性デプロイメント記述子を定義します。
各 weblogic-cmp-rdbms-jar.xml ファイルでは、以下の永続性オプションを定義します。
クライアントはファインダ メソッドを使用して、クエリを実行し、クエリ条件を満たすエンティティ Bean の参照を受け取ることができます。この節では、RDBMS 永続性を使用する WebLogic 固有の 1.1 EJB 用のファインダを作成する方法について説明します。コンテナ管理による永続性を利用する 2.0 EJB のファインダ クエリを定義するには、ポータブルなクエリ言語である EJB QL を使用します。 EJB QL の詳細については、EJB 2.0 用 EJB QL の使い方を参照してください。
WebLogic Server では、ファインダを簡単に作成できます。
ejbc は、ejb-jar.xml のクエリを使用して、デプロイメント時にファインダ メソッドの実装を作成します。
RDBMS 永続性用のファインダの主要コンポーネントは以下のとおりです。
以降の節では、WebLogic Server デプロイメント ファイルの XML 要素を使用して EJB ファインダを記述する方法について説明します。
findMethodName() という形式で、ファインダ メソッドのシグネチャを指定します。weblogic-cmp-rdbms-jar.xml に定義されるファインダ メソッドは、EJB オブジェクトの Java コレクションまたは単一オブジェクトを返す必要があります。
注意: 関連付けられている EJB クラスの単一オブジェクトを返す findByPrimaryKey(primkey) メソッドを定義することもできます。
finder-list スタンザは、EJBHome 内の 1 つまたは複数のファインダ メソッド シグネチャを EJB オブジェクトを検索するためのクエリに関連付けます。次に、WebLogic Server RDBMS ベースの永続性を使用した単純な finder-list スタンザの例を示します。
<finder-list>
<finder>
<method-name>findBigAccounts</method-name>
<method-params>
<method-param>double</method-param>
</method-params>
<finder-query><![CDATA[(> balance $0)]]></finder-query>
</finder>
</finder-list>
注意: method-param 要素内に非プリミティブな型を使用する場合には、完全修飾名を指定する必要があります。たとえば、Timestamp ではなく java.sql.Timestamp を使用します。完全修飾名を使用しないと、デプロイメント ユニットのコンパイル時に ejbc でエラー メッセージが生成されます。
finder-query 要素は、RDBMS から EJB オブジェクトをクエリするための WebLogic クエリ言語 (WLQL) 式を定義します。WLQL は、ファインダ パラメータ、EJB 属性、および Java 言語の式に対して標準の演算子セットを使用します。 WLQL の詳細については、EJB 1.1 CMP 用の WebLogic クエリ言語 (WLQL) の使用を参照してください。
注意: finder-query 値のテキストは、常に、XML CDATA 属性を使用して定義してください。CDATA を使用すると、WLQL 文字列中に特殊文字が入っていても、ファインダをコンパイルしたときにエラーが発生しないようになります。
CMP ファインダでは、1 回のデータベース クエリですべての Bean をロードできます。そのため、100 の Bean もデータベースに一度アクセスするだけでロードできます。Bean 管理による永続性 (BMP) ファインダは、データベースに一度アクセスして、ファインダで選択した Bean の主キー値を取得する必要があります。各 Bean にアクセスする場合、通常は Bean がキャッシュされていないとことを想定して、もう一度データベースにアクセスする必要があります。したがって、100 の Bean にアクセスするために、BMP はデータベースに 101 回アクセスします。
EJB 1.1 CMP 用の WebLogic クエリ言語 (WLQL) の使用
EJB 1.1 CMP 用の WebLogic クエリ言語 (WLQL) を使用すると、コンテナ管理による永続性を利用する 1.1 エンティティ EJB をクエリできます。weblogic-cmp-rdbms-jar.xml ファイルでは、各 finder-query スタンザには EJB を返すためのクエリを定義する WLQL 文字列が指定されていなければなりません。EJB 向けの WLQL とそれに対応するデプロイメント ファイル (EJB 1.1 仕様に基づいたもの) を使用します。
注意: 2.0 EJB のクエリについては、EJB 2.0 用 EJB QL の使い方を参照してください。weblogic-ql クエリを使用すると、elb-ql クエリが完全にオーバライドされます。
WLQL 文字列では、比較演算子用に次のプレフィックス表記法を使用します。
(operator operand1 operand2)
追加の WLQL 演算子は、単一のオペランド、テキスト文字列、またはキーワードを受け付けます。
注意: RDBMS カラム名は WLQL のオペランドとして使用できません。 代わりに、weblogic-cmp-rdbms-jar.xml の attribute-map に定義されているとおり、RDBMS カラムにマップされる EJB 属性 (フィールド) を使用します。
次のコード例は、weblogic-cmp-rdbms-jar.xml ファイルから基本的な WLQL 式を使用する部分を抜粋したものです。
public Enumeration findBigAccounts(double balanceGreaterThan)
throws FinderException, RemoteException;
注意: finder-query 値のテキストは、常に、XML CDATA 属性を使用して定義してください。CDATA を使用すると、WLQL 文字列中に特殊文字が入っていても、ファインダをコンパイルしたときにエラーが発生しないようになります。
<finder-query><![CDATA[(& (> balance $0) (! (= accountType 'checking')))]]></finder-query>
public Enumeration findAllAccounts()
throws FinderException, RemoteException
<finder-query><![CDATA[(like lastName M%)]]></finder-query>
<finder-query><![CDATA[(isNull firstName)]]></finder-query>
<finder-query><![CDATA[WHERE >5000 (orderBy 'id' (> balance 5000))]]></finder-query>
<finder-query><![CDATA[(orderBy 'id desc' (> ))]]></finder-query>
WebLogic Server では、標準WLQL クエリの代わりに SQL 文字列を使用し、 CMP 1.1 ファインダ クエリ用のSQL を記述することができます。SQL 文が CMP 1.1 ファインダ クエリとしてデータベースから値を取り出します。複雑なファインダ クエリが必要とされ WLQL を使えない場合に、SQL を使って CMP 1.1 ファインダ クエリを記述します。
WLQL の詳細については、EJB 1.1 CMP 用の WebLogic クエリ言語 (WLQL) の使用を参照してください。
SQL ファインダ クエリを指定するには、次の手順に従います。
「より大きい (>)」や「より小さい (<)」のシンボルなど、SQL クエリ内で XML パーサを混乱させる可能性のある文字を使用する場合には、必ず、前述の SQL 文の例のように CDATA 形式を使用して SQL クエリを宣言してください。
注意: SQL クエリ内ではベンダ固有の SQL を際限なく使用できます。
EJB クエリ言語 (QL) は、コンテナ管理による永続性を利用する 2.0 エンティティ EJB のファインダ メソッドを定義する移植可能なクエリ言語です。このクエリ言語は SQL に似ており、クエリ内の 1 つまたは複数のエンティティ EJB オブジェクトまたはフィールドを選択する場合に使用します。CMP フィールドはデプロイメント記述子で宣言するので、findByPrimaryKey() 以外のすべてのファインダ メソッドのクエリをデプロイメント記述子で作成できます。findByPrimaryKey は、コンテナによって自動的に処理されます。EJB QL クエリの検索スペースは、ejb-jar.xml (コンテナ管理によるフィールドとその関連データベース カラムの Bean のコレクション) で定義された EJB のスキーマからなります。
デプロイメント記述子では、EJB QL クエリ文字列を使用して、EJB 2.0 のエンティティ Bean の各ファインダ クエリを定義する必要があります。WebLogic Query Language (WLQL) を EJB 2.0 エンティティ Bean で使用することはできません。WLQL は、EJB 1.1 CMP で使用することを想定しています。
以前のバージョンの WebLogic Server を使用したことがあれば、コンテナ管理によるエンティティ EJB ではファインダ メソッド用に WLQL を使用できます。この節では、WLQL の一般的な処理についてのクイック リファレンスを提供します。WLQL の構文と EJB QL の構文の対応については、次の表を参考にしてください。
EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方
WebLogic Server には、標準の EJB QL の拡張であり、SQL に似た WebLogic QL という言語が用意されています。この言語はファインダ式と連携し、RDBMS の EJB オブジェクトのクエリ用に使用されます。query は、weblogic-ql 要素を使用して、weblogic-cmp-rdbms-jar.xml デプロイメント記述子に定義します。
ejb-jar ファイルには、weblogic-cmp-rdbms-jar.xml ファイルの weblogic-ql 要素に対応するクエリ要素が必要です。ただし、weblogic-cmp-rdbms-jar.xml のクエリ要素は、ejb-jar.xml のクエリ要素をオーバライドします。
EJB WebLogic QL upper および lower 拡張機能は、大文字と小文字の違いがある以外は検索式の文字と一致する結果をファインダ メソッドが返せるように、引数の大文字と小文字を変換します。 大文字と小文字の変換は文字列を照合するための一時的なものなので、データベース内に永続しません。 基底のデータベースも、upper および lower 関数をサポートしている必要があります。
upper 関数は、文字列の照合の前に、引数内の文字をすべて大文字に変換します。 クエリ内で大文字で表された式で upper 関数を使用すると、大文字であるか小文字であるかに関係なく、式に一致するすべての項目が返されます。たとえば、次のように入力します。
select name from products where upper(name)='DETERGENT';
lower 関数は、文字列の照合の前に、引数内の文字をすべて小文字に変換します。 クエリ内で小文字で表された式で lower 関数を使用すると、大文字であるか小文字であるかに関係なく、式に一致するすべての項目が返されます。
select type from products where lower(name)='domestic';
注意: upper および lower 拡張機能は、WebLogic Server 7.0 SP03 で追加されました。
EJB WebLogic QL 拡張機能の SELECT DISTINCT では、重複したクエリをフィルタ処理するようデータベースに指示します。SELECT DISTINCT を EJB QL クエリで指定すると、重複した結果をソートするために EJB コンテナのリソースが使用されません。
EJB 2.0 CMP Bean の weblogic-ql 要素の XML スタンザで値を TRUE に設定して sql-select-distinct 要素を指定すると、作成されるデータベース クエリの SQL STATEMENT には DISTINCT 句が含まれます。
sql-select-distinct 要素は weblogic-cmp-rdbms-jar.xml ファイルで指定します。ただし、Oracle データベースでアイソレーション レベルを READ_C0MMITED_FOR_UPDATE に指定してある場合、sql-select-distinct を指定することはできません。Oracle 上では、クエリに sql-select-distinct と READ_C0MMITED_FOR_UPDATE の両方を指定することができないからです。このアイソレーション レベルをセッション Bean などで使用する可能性がある場合、sql-select-distinct 要素を使用しないでください。
WebLogic クエリ言語 (WL QL) の拡張機能である ORDERBY は、ファインダ メソッドと連携して、選択における CMP フィールドの選択順序を指定するキーワードです。
図5-1 id による順序付けを指定する WebLogic QL ORDERBY 拡張機能
ORDERBY
SELECT OBJECT(A) from A for Account.Bean
ORDERBY A.id
注意: ORDERBY は、すべてのソート処理を DBMS に委ねます。このため、取得される結果の順序は、実行中の Bean の基盤となる特定の DBMS によって異なります。
また、次のようにORDERBY に昇順 [ASC] か降順 [DESC] か指定することもできます。
図5-2 id による順序付けを指定する WebLogic QL ORDERBY 拡張機能 (昇順/降順指定)
ORDERBY <field> [ASC|DESC], <field> [ASC|DESC]
SELECT OBJECT(A) from A for Account.Bean, OBJECT(B) from B for Account.Bean
ORDERBY A.id ASC; B.salary DESC
WebLogic Server では、EJB QL のサブクエリの次のような機能をサポートしています。
WebLogic QL とサブクエリの関係は、SQL クエリとサブクエリの関係に似ています。WebLogic QL のサブクエリは、外部 WebLogic QL クエリの WHERE 句内で使用してください。若干の例外はありますが、サブクエリの構文は WebLogic QL クエリのものとほぼ同じです。
WebLogic QL を指定する手順については、EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方を参照してください。この手順に従って、SELECT 文で次の例のようにサブクエリを指定します。
次のクエリは、成績順位をもとに平均以上の生徒を選択しています。
SELECT OBJECT(s) FROM studentBean AS s WHERE s.grade > (SELECT AVG(s2.grade) FROM StudentBean AS s2)
上記クエリの例の中で、サブクエリ、「SELECT AVG(s2.grade) FROM StudentBean AS s2」が EJB QL クエリと同じ構文を備えている点に注意してください。
サブクエリをネストすることもできます。この深さは、基盤データベースのネストの許容範囲によって制限されます。
WebLogic QL クエリでは、メイン クエリとそのすべてのサブクエリの FROM 句で宣言される識別子がユニークでなければなりません。これはつまり、サブクエリの内側で前にローカルに宣言した識別子をそのサブクエリで再び宣言することはできないということです。
たとえば、次の例は無効です。 Employee Bean がクエリとサブクエリの双方で emp として宣言されています。
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp.salary) FROM
EmployeeBean AS emp WHERE employee.state=MA)
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp2.salary) FROM
EmployeeBean AS emp2 WHERE emp2.state=MA)
この例では、サブクエリの Employee Bean がメインクエリの Employee Bean と異なる識別子になるように正しく宣言されています。
WebLogic QL サブクエリの戻り値の型は、次のような各種の型のいずれかになります。
WebLogic Server は、cmp-field で構成されている戻り値の型をサポートしています。サブクエリから返される結果は、1 つの値または値の集合から構成されている可能性があります。cmp-field 型の値を返すサブクエリの例を次に示します。
SELECT emp.salary FROM EmployeeBean AS emp WHERE emp.dept = 'finance'
このサブクエリは、財務部門の従業員の給料すべてを選択しています。
WebLogic Server は、ある cmp-field に対する集約から構成されている戻り値型をサポートしています。集約は必ず1 つの値から構成されるので、ここで返される値も常に 1 つの値になります。cmp-field の集約 (MAX) の型の値を返すサブクエリの例を次に示します。
SELECT MAX(emp.salary) FROM EmployeeBean AS emp WHERE emp.state=MA
このサブクエリは、マサチューセッツで最高額の給料を 1 つだけ選択しています。
集約関数の詳細については、集約関数の使用を参照してください。
WebLogic Server は、単純主キーを持つ 1 つのcmp-bean で構成されている戻り値の型をサポートしています。
注意: 複合主キーを持つ Bean はサポートされていません。複合主キーを持つ Bean をサブクエリの戻り値の型として指定しようとしても、クエリをコンパイルする時点で失敗に終わります。
単純主キーを持つ Bean 型の値を返すサブクエリの例を次に示します。
SELECT OBJECT(emp) FROM EMployeeBean As emp WHERE emp.department.budget>1,000,000
このサブクエリは、$1,000,000 以上の予算がある部門の全従業員のリストを返します。
サブクエリを比較演算子のオペランドとして使用します。 WebLogic QL では、比較演算子 ([NOT]IN、[NOT]EXISTS) および算術演算子 (<、>、<=、>=、=、および ANY や ALL と使用する <>) のオペランドをサブクエリとしてサポートしています。
[NOT] IN 比較演算子は、左側のオペランドが右側のサブクエリ オペランドのメンバーかどうか検査します。
サブクエリが NOT IN オペレータの右側のオペランドとなっている例を次に示します。
SELECT OBJECT(item)
FROM ItemBean AS item
WHERE item.itemId NOT IN
(SELECT oItem2.item.itemID
FROM OrderBean AS orders2, IN(orders2.orderItems)oIttem2
メイン クエリの NOT IN 演算子では、サブクエリによって返された集合の中に含まれていない品目すべてを選択しています。したがって、最終的に、メインクエリが未注文の品目すべてを選択します。
[NOT] EXISTS 比較演算子は、サブクエリ オペランドによって返された集合が空かどうか検査します。
サブクエリが NOT EXISTS オペランドのオペランドとなっている例を次に示します。
SELECT (cust) FROM CustomerBean AS cust
WHERE NOT EXISTS
(SELECT order.cust_num FROM OrderBean AS order
WHERE cust.num=order_num)
これは、相関サブクエリを用いたクエリの一例となっています。 詳細については、相関サブクエリと非相関サブクエリを参照してください。 このクエリは、注文していない顧客をすべて返します。
SELECT (cust) FROM CustomerBean AS cust
WHERE cust.num NOT IN
(SELECT order.cust_um FROM OrderBean AS order
WHERE cust.num=order_num)
右側のサブクエリ オペランドが 1 つの値を返す場合、比較の算術演算子を使用できます。右側のサブクエリが複数の値を返す場合には、サブクエリの前に ANY または ALL 修飾子が必要です。
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered =
(SELECT MAX (subOItem.quantityOrdered)
FROM Order ItemBean AS subOItem
WHERE subOItem,item itemID = ?1)
AND oItem.item.itemId = ?1
特定の品目 ID に対し、サブクエリはその品目の注文の最高数を返します。サブクエリが返している集合が、「=」演算子に必要な 1 つの値となっている点に注意してください。
メイン クエリの「=」演算子では、これと同じ品目 ID に対し、どの注文の注文品目の注文量がサブクエリから返された注文の最高数に等しいかを調べています。最終的に、特定の品目について注文が最高数である OrderBean をクエリが返します。
右側のサブクエリ オペラントが複数の値を返す場合には、算術演算子と ANY または ALL と組み合わせて使用します。
ANY または ALL を使用したサブクエリの例を次に示します。
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered > ALL
(SELECT subOItem.quantityOrdered
FROM OrderBean AS suborder IN (subOrder.orderItems)subOItem
WHERE subOrder,orderId = ?1)
サブクエリは、特定の注文 ID に対し、その注文 ID で注文された各品目の注文数の集合を返します。メイン クエリの「>」ALL 演算子は、各品目の注文数がサブクエリから返された集合内のすべての値を上回っている注文すべてを探しています。最終的にメインクエリは、入力された注文に対して、全品目で注文数を上回っている注文すべてを返します。
サブクエリが複数の値を持つ結果を返す可能性があるため、「>」演算子ではなく、「>」ALL 演算子が使用されている点に注意してください。
<、 >、 <=、>=、=、<> といったすべての算術演算子がこのように使用されます。
WebLogic Server は、相関サブクエリと非相関サブクエリの双方をサポートしています。
非相関サブクエリは、その外部クエリとは独立に評価されます。非相関サブクエリの例を次に示します。
SELECT OBJECT(emp) FROM EmployeeBean AS emp
WHERE emp.salary>
(SELECT AVG(emp2.salary) FROM EmployeeBean AS emp2)
この非相関サブクエリの例では、平均以上の給与の従業員を選択しています。この例では、算術演算子「>」を使用します。
相関サブクエリは、その外部クエリの値がサブクエリでの評価に関与するサブクエリです。相関サブクエリの例を次に示します。
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
この相関サブクエリの例では、最後に出荷された 10 個の注文を選択しています。NOT IN 演算子を使用しています。
注意: 相関クエリでは、非相関クエリより処理オーバーヘッドが大きくなる可能性があることに注意してください。
サブクエリ内で DISTINCT 句を使用すると、そのサブクエリで生成される SQL 内で SQL SELECT DISTINCT を使うことができます。サブクエリでの DISTINCT 句の使い方は、メインクエリでの使い方とは異なります。 メインクエリ内の DISTINCT 句は EJB コンテナによって施されますが、サブクエリ内の DISTINCT 句は生成された SQL の SQL SELECT DISTINCT によって施されます。サブクエリ内に DISTINCT 句が含まれる例を次に示します。
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
この例では、最後に出荷された 10 個の注文を選択しています。
WebLogic Server では、WebLogic QL の集約関数をサポートしています。これらは、WHERE 句のようなクエリの一部ではなく、SELECT 句の対象として使われるのみです。集約関数の振る舞いは SQL 関数と似ています。これらの関数は、クエリの WHERE 条件によって返される Bean の外側で評価されます。
WebLogic QL を指定する手順については、EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方を参照してください。これに従って、次の表のサンプルのように、集約関数を指定した SELECT 文を記述します。
次の手順で、ResultSet として集約関数を返すことができます。
WebLogic Server は、複数カラム クエリの結果を java.sql.ResultSet の形式で返す、 ejbSelect() クエリをサポートしています。この機能を支援するために、WebLogic Serverでは、次のように SELECT 句の対象フィールドをカンマで区切って指定できるようになりました。
SELECT emmp.name, emp.zip FROM EmployeeBean AS emp
このクエリは、従業員の名前と郵便番号の値をカラムとしその数行を含んだ java.sqlResultSet を返します。
WebLogic QL を指定する手順については、EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方を参照してください。 EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方の手順に従って、上記のクエリの例で WebLogic QL を指定したように、ResultSet を指定するクエリを記述します。また、同様にこれに従って、下記の表のサンプルで示すように、集約クエリを指定した SELECT 文を記述します。
EJB QL で作成される ResultSet は、cmp-field の値、または、cmp-field 値の集合だけを返します。 Bean を返すことはできません。
さらに、cmp-field と集約関数を組み合わせた場合、下記のサンプルに示すような強力なクエリを作成できます。
次の行 (Bean) は、各地区の従業員の給与を示しています。
次の SELECT 文のクエリでは、ResultSet、集約関数 (AVG) とともに、GROUP BY 文と ORDER BY 文を使用し、複数カラム クエリの結果を降順ソートを使って取り出します。
SELECT e.location, AVG(e.salary)
FROM Finder EmployeeBean AS e
GROUP BY e.location
ORDER BY 2 DESC
このクエリは、各地区の従業員の平均給与を降順で示します。2 という数字は、ORDERBY ソートを SELECT 文の 2 番目の項目で実行することを意味しています。GROUP BY 句 は、e.location 属性に一致する従業員の平均給与を指定しています。
注意: ResultSet を返すクエリ内で ORDERBY の引数として使用できるのは整数だけです。WebLogic Server では、Bean を返すファインダ、または ejbselect() 内で ORDERBY の引数として整数を使用することはできません。
Query インタフェースには、検索メソッドと実行メソッドがあります。 検索メソッドは、EJBObject を返すという点で標準の EJB メソッドと似ています。 実行メソッドは、個々のフィールドを選択できるという点で、Select 文に似ています。
Query インタフェースの戻り値の型は、切断された ResultSetです。つまり、ResultSet がオープンなデータベース接続を保持していない点を除き、ResultSet の情報にアクセスするのと同じように、返されたオブジェクトの情報にアクセスするということです。
Query インタフェースのプロパティベース メソッドを使用すると、クエリに特有の設定を別の方法で指定できます。 QueryProperties インタフェースは標準の EJB クエリ設定を保持し、WLQueryProperties インタフェースは WebLogic 固有のクエリ設定を保持します。
Query インタフェースは QueryProperties を拡張しますが、実際の Query 実装は WLQueryProperties を拡張したものなので、フィールド グループを設定する図 5-3 の例のように、安全にキャストできます。
図5-3 WLQueryProperties によるフィールド グループの設定
Query query=qh.createQuery(); ((WLQueryProperties) query).setFieldGroupName("myGroup"); Collection results=query.find(ejbql); Query query=qh.createQuery(); Properties props = new Properties(); props.setProperty(WLQueryProperties.GROUP_NAME, "myGroup"); Collection results=query.find(ejbql, props);
動的クエリを使用すると、各自のアプリケーション コードでプログラム的にクエリを作成したり実行できるようになります。たとえば、クエリを使ってRDBMS に対して EJB オブジェクトの情報を要求できます。この機能は、 EJB 2.0 CMP Bean でのみ利用できます。動的クエリの使用には、次のような利点があります。
次のコード例では、動的クエリをどのように実行するかを示します。
InitialContext ic=new InitialContext();
FooHome fh=(FooHome)ic.lookup("fooHome");
QueryHome qh=(QueryHome)fh;
Sring ejbql="SELECT OBJECT(e)FROM EmployeeBean e WHERE e.name='rob'"
Query query=qh.createQuery();
query.setMaxElements(10)
Collection results=query.find(ejbql);
WebLogic Server は、INDEX の使い方に関するヒントを Oracle Query オプティマイザに渡すことを可能にする EJB QL 拡張機能をサポートしています。この拡張機能を使用すると、データベース エンジンにヒントを提供できます。たとえば、検索先のデータベースが ORACLE_SELECT_HINT によって恩恵を受けることがわかっている場合は、ANY 文字列値を取り、その文字列値をデータベースに対するヒントとして SQL SELECT 文の後に挿入する ORACLE_SELECT_HINT 句を定義します。
このオプションを使用するには、この機能を使用するクエリを weblogic-ql 要素で宣言します。この要素は、weblogic-cmp-rdbms-jar.xml ファイルに入っています。weblogic-ql 要素では、EJB-QL に対する WebLogic 固有の拡張機能を含むクエリを指定します。
WebLogic QL のキーワードおよび使い方は次のとおりです。
SELECT OBJECT(a) FROM BeanA AS a WHERE a.field > 2 ORDERBY a.field SELECT_HINT '/*+ INDEX_ASC(myindex) */'
この文は、Oracle のオプティマイザ ヒントを使用して次の SQL を生成します。
SELECT /*+ INDEX_ASC(myindex) */ column1 FROM .... (etc)
WebLogic QL ORACLE_SELECT_HINT 句では、単一引用符で囲まれた部分 (' ') が SQL SELECT の後に挿入されます。クエリ作成者は、引用符内のデータを Oracle データベースが確実に認識できるものにする必要があります。
WebLogic Server では、コンテナ管理によるフィールドの読み出しおよび修正にコンテナ生成のアクセサ メソッドを使用します。 それらのメソッドの名前は get または set で始まり、ejb-jar.xml で定義されている永続フィールドの実際の名前を使用します。 これらのメソッドは、public、protected、および abstract として宣言されます。
Oracle DBMS の BLOB および CLOB DBMS カラムのサポート
WebLogic Server は、Oracle Binary Large Object (BLOB) および Character Large Object (CLOB) DBMS カラムを EJB CMP でサポートしています。BLOB および CLOB は、大きなオブジェクトを効率的に保存したり、検索したりするためのデータ型です。CLOB は文字オブジェクトで、BLOB は大きなバイト配列に変換される画像などのバイナリまたはシリアライズ可能オブジェクトです。
BLOB および CLOB は、文字列変数である OracleBlob または OracleClob の値を BLOB または CLOB カラムにマップします。 WebLogic Server では、BLOB をバイト配列またはシリアライズ可能なオブジェクトにマップし、CLOB をデータ型 java.lang.string にマップします。現時点では、char 配列を CLOB カラムにマップすることはできません。
BLOB/CLOB サポートを有効にするには次の手順に従います。
BLOB/CLOB オブジェクトのサイズが大きいため、BLOB または CLOB を使用すると、パフォーマンスが低下する場合があります。
次の XML コードは、weblogic-cmp-rdbms-jar-xml ファイルの dbms-column 要素を使用して BLOB オブジェクトを指定する方法を示しています。
<field-map>
<cmp-field>photo</cmp-field>
<dbms-column>PICTURE</dbms-column>
<dbms_column-type>OracleBlob</dbms-column-type>
</field-map>
OracleBlob にマップされた cmp-fields のシリアライゼーションの制御
デフォルトでは WebLogic Server は、OracleBlob にマップされている byte[] 型の cmp-field を、書き込むときにシリアライズし、読み込むときにデシリアライズします。
別のプログラムによってデータベースに直接書き込まれた BLOB を読み込むときにエラーが発生する場合があります。コンテナはデータがシリアライズされていると判断するからです。
データがシリアライズされていないことを指定するには、次のフラグを使用して EJB をコンパイルします。
java -Dweblogic.byteArrayIsSerializedToOracleBlob=false weblogic.ejbc std_ejb.jar ejb.jar
次の XML コードは、weblogic-cmp-rdbms-jar-xml ファイルの dbms-column 要素を使用して CLOB オブジェクトを指定する方法を示しています。
<field-map>
<cmp-field>description</cmp-field>
<dbms-column>product_description</dbms-column>
<dbms_column-type>OracleClob</dbms-column-type>
</field-map>
WebLogic Server での EJB 1.1 CMP の調整更新
コンテナ管理 EJB が読み書きされるときに、コンテナは get および set コールバックを受け取るので、EJB のコンテナ管理による永続性 (CMP) は、自動的に調整更新をサポートします。EJB 1.1 CMP Bean を調整すると、パフォーマンスの向上に役立ちます。
WebLogic Server は、EJB 1.1 CMP の調整更新をサポートするようになりました。ejbStore が呼び出されると、EJB コンテナはコンテナ管理フィールドがトランザクションで変更されたかどうかを自動的に判定します。変更されたフィールドだけがデータベースに書き込まれます。変更されたフィールドがない場合、データベースは更新されません。
以前のバージョンの WebLogic Server では、CMP 1.1 Bean が変更されたかどうかをコンテナに通知する isModified メソッドを記述することができました。 isModified は現在も WebLogic Server でサポートされていますが、isModified メソッドを使用しないで、更新されたフィールドをコンテナに判定させることをお勧めします。
この機能は EJB 2.0 CMP に対してデフォルトで有効です。EJB CMP 1.1 の調整更新を有効にするには、weblogic-cmp-rdbms-jar.xml ファイルの次のデプロイメント記述子要素を true に設定します。
<enable-tuned-updates>true</enable-tuned-updates>
CMP の調整更新を無効にするには、このデプロイメント記述子要素を次のように設定します。
<enable-tuned-updates>false</enable-tuned-updates>
この場合、ejbStore は常にすべてのフィールドをデータベースに書き込みます。
CMP 2.0 エンティティ Bean 向けに最適化されたデータベース更新
CMP 2.0 エンティティ Bean の場合、setXXX() メソッドでは、変更されていないプリミティブの値と、変更不能なフィールドの値をデータベースに書き込みません。 この最適化により、特に大量のデータベース トランザクションを伴うアプリケーションにおいて、パフォーマンスが向上します。
トランザクションによる更新内容は、トランザクションで発行されたクエリ、ファインダ、および ejbSelect の結果に反映させる必要があります。この要件に従うとパフォーマンスが低下する場合があるので、新しいオプションにより、Bean に関するクエリを実行する前にキャッシュをフラッシュするように指定することができます。
このオプションが無効の場合 (デフォルト設定)、現在のトランザクションの結果はクエリに反映されません。このオプションを有効にした場合、コンテナはキャッシュされているトランザクションの変更をすべてデータベースに書き込んでから新しいクエリを実行します。この方法により、変更が結果に表示されます。
このオプションを有効にするには、weblogic-cmp-rdbms-jar.xml ファイルで include-updates 要素を true に設定します。
図5-6 トランザクションの結果をクエリに反映するための指定
<weblogic-query>
<query-method>
<method-name>findBigAccounts</method_name>
<method-params>
<method-param>double</method-param>
</method-params>
</query-method>
<weblogic-ql>WHERE BALANCE>10000 ORDERBY NAME</weblogic-ql>
<include-updates>true</include-updates>
</weblogic-query>
デフォルトは false で、この設定は最大限のパフォーマンスを実現します。キャッシュされているトランザクションに対して行われる更新はクエリの結果に反映され、変更はデータベースには書き込まれず、クエリの結果に変更は見られません。
この機能を使用するかどうかは、データを最新かつ一貫性のあるものにしておくことよりもパフォーマンスを重視するかどうかで判断します。
主キーとは、エンティティ Bean をそのホーム内でユニークに識別するオブジェクトです。コンテナでは、エンティティ Bean の主キーを操作できなければなりません。個々のエンティティ Bean クラスは、その主キーに対して別のクラスを定義できますが、複数のエンティティ Bean クラスが同じ主キー クラスを使用できます。主キーは、エンティティ Bean のデプロイメント記述子で指定されます。コンテナ管理の永続性を利用するエンティティ Bean の主キー クラスを指定するには、エンティティ Bean クラスの 1 つまたは複数のフィールドに主キーをマップします。
すべてのエンティティ オブジェクトはそのホーム内で一意な ID を持ちます。2 つのエンティティ オブジェクトのホームと主キーが共通する場合、両者は同一のものと見なされます。クライアントはエンティティ オブジェクトのリモート インタフェースへの参照に対して getPrimaryKey() メソッドを呼び出して、そのホーム内でのエンティティ オブジェクトの ID を調べることができます。参照と関連付けられたオブジェクト ID は、参照が有効な間は変化しません。したがって getPrimaryKey() メソッドは、同じエンティティ オブジェクトの参照に対して呼び出されたときは常に同じ値を返します。エンティティ オブジェクトの主キーを知っているクライアントは、Bean のホーム インタフェースの findByPrimaryKey(key) メソッドを呼び出すことによって、エンティティ オブジェクトへの参照を取得することができます。
エンティティ Bean クラスでは、主キーを 1 つの CMP フィールドにマップできます。ejb-jar.xml ファイルのデプロイメント記述子、primkey-field 要素を使用して、主キーであるコンテナ管理フィールドを指定します。prim-key-class 要素は、主キー フィールドのクラスでなければなりません。
1 つまたは複数の CMP フィールドをラップする主キー クラス
主キー クラスを 1 つまたは複数のフィールドにマップすることができます。主キー クラスは public でなければならず、パラメータを付けない public コンストラクタを持たなければなりません。ejb-jar.xml ファイルのデプロイメント記述子、prim-key-class 要素を使用して、エンティティ Bean の主キー クラスの名前を指定します。このデプロイメント記述子要素にはクラス名だけを指定できます。主キー クラス内のすべてのフィールドは public として宣言する必要があります。クラス内のフィールドは、ejb-jar.xml ファイルの主キー フィールドと同じ名前を持たなければなりません。
エンティティ Bean が無名主キークラスを使用する場合、EJB をサブクラス化し java.lang.Integer 型の cmp-field をそのサブクラスに追加する必要があります。そのフィールドの自動主キー生成を有効にし、コンテナがフィールドの値を自動的に埋め、そのフィールドを weblogic-cmp-rdbms-jar.xml デプロイメント記述子のデータベース カラムにマップできるようにします。
最終的に、ejb-jar.xml ファイルを更新して元の EJB クラスではなく EJB サブクラスを指定するようにし、その Bean を WebLogic Server にデプロイします。
元の EJB を無名主キー クラスとともに使用した場合、デプロイメント時にWebLogic Server から次のエラー メッセージが表示されます。
EJB の ejb_name では、「不明な主キー クラス (<prim-key-class> == java.lang.Object)」をデプロイメント時に (java.lang.Object 以外のオブジェクトとして) 指定する必要があります。
WebLogic Server で主キーを使用する場合のヒントをいくつか挙げておきます。
WebLogic Server では、データベース カラムを cmp-field と cmr-field に同時にマップすることができます。その場合、cmp-field は読み込み専用となります。cmp-field が主キー フィールドの場合、cmp-field に対して setXXX メソッドを使うことによって create() メソッドが呼び出されたときにフィールドの値が設定されるように指定します。
WebLogic Server は、コンテナ管理による永続性 (CMP) 用の自動主キー生成機能をサポートしています。
注意: この機能は EJB CMP 2.0 コンテナに対してのみサポートされており、EJB CMP 1.1 に対する自動主キー生成機能はサポートされていません。1.1 Bean の場合は、Bean 管理による永続性 (BMP) を使用する必要があります。
生成されるキーのサポートは以下の 2 つの方法で提供されます。
このオプションでは、コンテナはすべてのキー生成を基底のデータベースに委ねます。この機能を有効にするには、サポートされている DBMS の名前と、データベースで必要な場合にはジェネレータ名を指定します。CMP コードは、この機能を実装するすべての細部を処理します。
この機能の詳細については、Oracle 用主キー サポートの指定と Microsoft SQL Server 用主キー サポートの指定を参照してください。
注意: Oracle のテーブルの作成手順については、Oracle データベースのマニュアルを参照してください。
weblogic-cmp-rdbms-jar.xml ファイルで key_cache_size 要素を設定して、データベースの SELECT および UPDATE によって一度に取得する主キー値の数を指定します。key_cache_size のデフォルト値は 1 です。データベース アクセスを最小限に抑えてパフォーマンスを向上するために、BEA ではこの要素には値 >1 を設定することを推奨しています。 この機能の詳細については、主キーの命名済シーケンス テーブル サポートの指定を参照してください。
現時点では、WebLogic Server は、Oracle および Microsoft SQL Server 向けの DBMS 主キー生成サポートだけを提供します。ただし、命名済シーケンス テーブルは、サポートされている他のデータベースで使用できます。また、この機能は単純 (非複合) 主キーで使用することを想定したものです。
Bean の抽象「get」および「set」メソッドでは、以下の 2 つの型のいずれかとしてフィールドを宣言できます。
Oracle データベース用の主キー生成サポートでは、Oracle の SEQUENCE 機能が使用されます。この機能は、Oracle データベース内の Sequence エンティティと連携して一意の主キーを生成します。Oracle SEQUENCE は、新しい数値が必要な場合に呼び出されます。
SEQUENCE がデータベース内に作成されたら、XML デプロイメント記述子で自動キー生成を指定します。weblogic-cmp-rdbms-jar.xml ファイルで、次のように自動キー生成を指定します。
<automatic-key-generation>
<generator-type>ORACLE</generator-type>
<generator_name>test_sequence</generator-name>
<key-cache-size>10</key-cache-size>
</automatic-key-generation>
generator-name 要素で、使用する ORACLE SEQUENCE の名前を指定します。ORACLE SEQUENCE が SEQUENCE INCREMENT 値を付けて作成した場合は、key-cache-size を指定しなければなりません。この値は、Oracle SEQUENCE INCREMENT 値と一致する必要があります。これら 2 つの値が一致しない場合、重複キーの問題が発生する可能性が高くなります。
警告: Oracle では、ジェネレータ タイプ USER_DESIGNATED_TABLE を使用しないでください。使用すると、次の例外が発生する可能性があります。
javax.ejb.EJBException: nested exception is:java.sql.SQLException: Automatic Key Generation Error: attempted to UPDATE or QUERY NAMED SEQUENCE TABLE NAMED_SEQUENCE_TABLE, but encountered SQLException java.sql.SQLException:ORA-08177: can't serialize access for this transaction.
USER_DESIGNATED_TABLE モードは、TX ISOLATION LEVEL を SERIALIZABLE に設定します。Oracle では、これによって問題が発生する可能性があります。
代わりに、AutoKey オプション ORACLE を使用します。
Microsoft SQL Server 用主キー サポートの指定
Microsoft SQL Server データベース用の主キー生成サポートでは、SQL Server の IDENTITY カラムが使用されます。Bean が作成され、新しい行がデータベース テーブルに挿入されると、SQL Server は、IDENTITY カラムとして指定されたカラムに、次の主キー値を自動的に挿入します。
注意: Microsoft SQL Server のテーブルの作成手順については、Microsoft SQL Server データベースのマニュアルを参照してください。
IDENTITY がデータベース テーブル内に作成されたら、XML デプロイメント記述子で自動キー生成を指定します。weblogic-cmp-rdbms-jar.xml ファイルで、次のように自動キー生成を指定します。
<automatic-key-generation>
<generator-type>SQL_SERVER</generator-type>
</automatic-key-generation>
generator-type 要素では、主キーの生成方法を指定します。
サポートされていないデータベース向けの主キー生成サポートでは、Named SEQUENCE TABLE を使用してキー値を保持します。テーブルには、整数の SEQUENCE INT である単一カラムを持つ単一行を含める必要があります。このカラムは、現在のシーケンス値を保持します。
注意: テーブルの作成手順については、各データベース製品のマニュアルを参照してください。
命名済シーケンス テーブル サポートを利用する場合、その基盤データベースがトランザクション アイソレーション レベル、TRANSACTION_SERIALIZABLE をサポートしているか確かめます。weblogic-ejb.xml ファイルの isolation-level 要素にこのオプションを指定します。TRANSACTION_SERIALIZABLE オプションは、あるトランザクションを複数回同時に実行することが、そのトランザクションを順番に複数回実行した場合と同じ結果になることを仕様とします。データベースで トランザクション アイソレーション レベル、TRANSACTION_SERIALIZABLE がサポートされていなければ、命名済シーケンス テーブル サポートを使用できません。
注意: 基盤データベースでどのような型のアイソレーション レベルがサポートされているかについては、そのデータベースのドキュメントを参照してください。 アイソレーション レベルの設定の詳細については、EJB デプロイメント記述子の指定と編集を参照してください。
NAMED_SEQUENCE_TABLE がデータベース内に作成されたら、次の例のように、weblogic-cmp-rdbms-jar.xml ファイル内の XML デプロイメント記述子を使用して自動キー生成を指定します。
図5-9 命名済シーケンス テーブル用の自動キー生成サポートの指定
<automatic-key-generation>
<generator-type>NAMED_SEQUENCE_TABLE</generator-type>
<generator_name>MY_SEQUENCE_TABLE_NAME</generator-name>
<key-cache-size>100</key-cache-size>
</automatic-key-generation>
generator-name 要素によって、使用する SEQUENCE TABLE の名前を指定します。key-cache-size を使用すると、1 回の DBMS 呼び出しでコンテナが取得するキーの数を示すキー キャッシュのサイズをオプションで指定することもできます。
パフォーマンスを向上するために、BEA ではこの値を >1 (1 より大きい) に設定することを推奨しています。この設定により、次のキー値を取得するためのデータベースの呼び出し回数を減らすことができます。
また、NAMED SEQUENCE テーブルは Bean のタイプごとに作成することをお勧めします。異なるタイプの Bean が NAMED SEQUENCE テーブルを共有しないようにしてください。こうすることで、キー テーブルの競合の発生を防ぎます。
EJB 2.0 CMP Bean における複数のテーブル マッピングを使用すると、1 つの EJB をあるデータベース内の複数の DBMS テーブルにマップできるようになります。その EJBの weblogic-cmp-rdbms-xml ファイルで、複数の DBMS テーブルとカラムを、EJB とこれのフィールドにマップすることによって、この機能をコンフィグレーションします。マッピングには次のタイプが含まれます。
複数のテーブル マッピングを有効にするには、次のことが必要になります。
これまでは、1 つの EJB を 1 つのテーブル、あるいは、フィールドやカラムの 1 リストに関連付けていました。現在は、EJB がマップするテーブルの数の分だけ、フィールドやカラムの一連のセットを 1 つの EJB にマップさせることができます。
1 つの Bean での複数のテーブル マッピングには次のような制限があります。
ある 1 つのエンティティ Bean にマップする複数のテーブルの主キー間に、参照一貫性制約を課してはなりません。この場合、Bean 削除時に実行時エラーになる可能性があります。
関係の中の Bean の 1 つが複数のテーブルにマップする場合の CMR の指定については、複数のテーブルにマップされる EJB の CMR の指定を参照してください。
テーブルがまだ作成されていない場合には、XML デプロイメント記述子ファイルおよび Bean クラスの記述に基づいて、WebLogic Server がテーブルを自動的に作成するよう指定できます。JAR ファイル内の関係に結合が含まれている場合、テーブルはすべての Bean および関係の結合テーブルに対して作成されます。この機能を明示的に有効にするには、JAR ファイルのすべての Bean に対して、RDBMS のデプロイメントごとのデプロイメント記述子でこの機能を定義します。
自動テーブル生成を有効にした場合、WebLogic Server は weblogic-cmp-rdbms-jar.xml 内の database-type 要素の値を調べ、そのデータベースのテーブルを作成するのに必要になる正確な構文とデータ型変換について判断します。WebLogic Server バージョン 7.0 では、以下のデータベースおよびベンダにおけるベンダ固有の CREATE TABLE 構文とデータ型変換を使用します。
これら以外のすべてのデータベース システムの場合、WebLogic Server では基本的構文と次の表に示すデータ型変換を使用し、最適な方法で新しいテーブルを作成します。
表5-1 Java の汎用的フィールドと DBMS カラムの型の変換
デプロイメント ファイルの記述に基づいてフィールドをデータベース内の適切なカラムの型にマップできない場合、CREATE TABLE は失敗し、エラーが送出されるので、テーブルを手動で作成する必要があります。
プロダクション環境では自動テーブル作成を使用しないことをお勧めします。この機能は、設計および試作品の開発段階での使用が適しています。プロダクション環境では、外部キーの制約の宣言など、より正確なテーブル スキーマ定義を使用する必要があります。
コンテナ管理による関係 (CMR) は 2 つのエンティティ EJB 間で定義する関係であり、データベースのテーブル間の関係に似ています。 同じ処理タスクに関与する 2 つの EJB 間で CMR を定義すると、アプリケーションは以下の機能を利用することができます。
この節では、WebLogic Server の CMR の特長と制限について説明します。 CMR のコンフィグレーション手順については、コンテナ管理による関係の定義を参照してください。
同じ .jar にパッケージ化され、データが同じデータベースに格納される 2 つの WebLogic Server エンティティ Bean 間で関係を定義できます。 同じ関係に参加するエンティティは、同じデータソースにマップされる必要があります。 WebLogic Server は、異なるデータソースにマップされたエンティティ Bean 間の関係をサポートしていません。 コンテナ管理による関係に参加する各 Bean の抽象スキーマは、同じ ejb-jar.xml ファイルで定義する必要があります。
注意: EJB 2.1 仕様では、エンティティ Bean にローカル インタフェースがない場合、そのエンティティ Bean が参加できる唯一の CMR は一方向 (当該エンティティ Bean から別のエンティティ Bean) の CMR であるとされています。
ただし、WebLogic Server ではリモート インタフェースのみのエンティティ Bean に以下のことが許可されます。
この機能は EJB 2.1 では規定されていないので、リモート インタフェースのみを持ち、双方向の関係に参加しているか一方向の関係の対象であるエンティティ Bean は、他のアプリケーション サーバに移植できない場合もあります。
エンティティ Bean は、別のエンティティ Bean と 1 対 1、1 対多、または多対多の関係を持つことができます。
CMR は、1 対 1 、1 対多、または多対多のどれであるかに関係なく、一方向と双方向のどちらにもなります。 CMR の方向は、関係の片側の Bean がもう一方の側の Bean からアクセス可能かどうかを決定します。
一方向の CMR は一方通行です。「従属」側の Bean は、関係のもう一方の Bean を意識しません。 カスケード削除などの CMR 関連の機能は、従属 Bean にのみ適用できます。 たとえば、EJB1 から EJB2 の一方向の CMR でカスケード削除がコンフィグレーションされている場合、EJB1 を削除すると EJB2 も削除されますが、EJB2 を削除しても EJB1 は削除されません。
注意: カスケード削除機能にとって、関係のカーディナリティは重要な要素です。たとえ関係が双方向であっても、カスケード削除は関係の「多」側からはサポートされません。
双方向の関係は両側通行です。関係の各 Bean が他方の Bean を意識します。 CMR 関連の機能は、両方向でサポートされます。 たとえば、EJB1 と EJB2 の双方向の CMR でカスケード削除がコンフィグレーションされている場合、CMR のいずれかの Bean を削除すると他方の Bean も削除されます。
関係に参加している Bean インスタンスが削除されると、コンテナは自動的にその関係を削除します。 たとえば、従業員と部署の関係がある場合には、従業員を削除すると、コンテナは従業員と部署の関係も削除します。
CMR の定義では、関係とそのカーディナリティおよび方向を ejb-jar.xml で指定します。 weblogic-cmp-jar.xml では、関係のデータベース マッピングの細目を定義し、リレーションシップ キャッシングを有効にします。 それらの手順は、以下の節で説明します。
コンテナ管理による関係は、ejb-jar.xml の ejb-relation スタンザで定義します。 図 5-10 は、2 つのエンティティ EJB (TeacherEJB と StudentEJB) の関係の ejb-relation スタンザを示しています。
ejb-relation スタンザでは、関係のそれぞれの側の ejb-relationship-role を指定します。 ロール スタンザでは、関係に対する各 Bean の認識を指定します。
図5-10 ejb-jar.xml における 1 対多で双方向の CMR
<ejb-relation>
<ejb-relation-name>TeacherEJB-StudentEJB</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>teacher-has-student
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>TeacherEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>teacher</cmr-field-name>
</cmr-field>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>student-has-teacher
</ejb-relationship-role-name>
<multiplicity>Many</multiplicity>
<relationship-role-source>
<ejb-name>StudentEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>student</cmr-field-name>
<cmr-field-type>java.util.Collection
<cmr-field>
</ejb-relationship-role>
関係のそれぞれの側のカーディナリティは、ejb-relationship-role スタンザの <multiplicity> 要素で指定します。
図 5-10 では、関係 TeacherEJB-StudentEJB のカーディナリティは 1 対多です。そのカーディナリティは、TeacherEJB 側で multiplicity を one に設定し、StudentEJB 側では Many に設定することで指定されています。
図 5-11 の CMR のカーディナリティは 1 対 1 です。この関係では、両方のロール スタンザで multiplicity が one に設定されています。
図5-11 ejb-jar.xml における 1 対 1 で一方向の CMR
<ejb-relation>
<ejb-relation-name>MentorEJB-StudentEJB</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>mentor-has-student
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>MentorEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>mentorID</cmr-field-name>
</cmr-field>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>student-has-mentor
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>StudentEJB</ejb-name>
</relationship-role-source>
</ejb-relationship-role>
関係の片側で <multiplicity> が Many に設定されていて、その <cmr-field> がコレクションである場合は、<cmr-field-type> を java.util.Collection として指定する必要があります (図 5-10 の関係の StudentEJB 側を参照)。 cmr-field が単一値のオブジェクトである場合は、cmr-field-type を指定する必要はありません。
表 5-2 は、関係の各 Bean の cmr-field の内容を、その関係のカーディナリティに基づいて示しています。
CMR の方向は、関係のそれぞれの側の ejb-relationship-role スタンザで cmr-field を設定する、またはしないことでコンフィグレーションします。
双方向の CMR では、関係の両側の ejb-relationship-role スタンザに cmr-field 要素があります (図 5-10 を参照)。
一方向の関係の場合は、関係の片方のロール スタンザにのみ cmr-field があります。 起点側の EJB の ejb-relationship-role には cmr-field がありますが、対象側 Bean のロール スタンザにはありません。 図 5-11 では、MentorEJB から StudentEJB の一方向の関係が指定されています。StudentEJB の ejb-relationship-role スタンザには、cmr-field 要素がありません。
ejb-jar.xml で定義された各 CMR は、weblogic-cmp-jar.xml の weblogic-rdbms-relation スタンザでも定義する必要があります。 weblogic-rdbms-relation は関係を識別し、関係の片側または両側について relationship-role-map スタンザを格納します。このスタンザは、関係に参加している Bean 間のデータベースレベルの関係をマップします。
weblogic-rdbms-relation の relation-name は、ejb-jar.xml の CMR の ejb-relation-name と同じでなければなりません。
1 対 1 と 1 対多の関係の場合、relationship-role-map は関係の片側のみで定義します。
1 対 1 の関係では、一方の Bean の外部キーがもう一方の Bean の主キーにマップされます。
図 5-12 は、MentorEJB と StudentEJB の 1 対 1 の関係の weblogic-rdbms-relation スタンザです。その <ejb-relation> は、図 5-11 で示されています。
図5-12 1 対 1 の CMR の weblogic-cmp-jar.xml
<weblogic-rdbms-relation>
<relation-name>MentorEJB-StudentEJB</relation-name>
<weblogic-relationship-role>
<relationship-role-name>
mentor-has-student
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>student</foreign-key-column>
<key-column>StudentID/key-column>
</column-map>
<relationship-role-map>
</weblogic-relationship-role>
1 対多の関係では常に、ある Bean の外部キーが別の Bean の主キーにマップされます。 1 対多の関係では、外部キーが常に、関係の「多」サイドの Bean に関連付けられます。
図 5-13 は、TeacherEJB と StudentEJB の 1 対多の関係の weblogic-rdbms-relation スタンザです。その <ejb-relation> は、図 5-10 で示されています。
図5-13 1 対多の CMR の weblogic-rdbms-relation
<weblogic-rdbms-relation>
<relation-name>TeacherEJB-StudentEJB</relation-name>
<weblogic-relationship-role>
<relationship-role-name>
teacher-has-student
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>student</foreign-key-column>
<key-column>StudentID/key-column>
</column-map>
<relationship-role-map>
</weblogic-relationship-role>
多対多の関係では、関係のそれぞれの側で weblogic-relationship-role スタンザを指定します。 そのマッピングには、結合テーブルが関わります。 結合テーブルの各行には、関係に関与するエンティティの主キーに対応する 2 つの外部キーが格納されます。 関係の方向は、関係のデータベース マッピングの指定方法に影響しません。
図 5-14 は、2 人の従業員の関係 friends の weblogic-rdbms-relation スタンザを示しています。
FRIENDS 結合テーブルには、first-friend-id および second-friend-id という 2 つのカラムがあります。各カラムには、他の従業員の友人である特定の従業員を示す外部キーが格納されています。 従業員テーブルの主キー カラムは id です。 この例では、従業員 Bean が 1 つのテーブルにマップされています。 従業員 Bean が複数のテーブルにマップされている場合、主キー カラムを格納するテーブルを relation-role-map で指定する必要があります。 例については、複数のテーブルにマップされる EJB の CMR の指定を参照してください。
図5-14 多対多の CMR の weblogic-rdbms-relation
<weblogic-rdbms-relation>
<relation-name>friends</relation-name>
<table-name>FRIENDS</table-name>
<weblogic-relationship-role>
<relationship-role-name>first-friend
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>first-friend-id</foreign-key-column>
<key-column>id</key-column>
</column-map
</relationship-role-map>
<weblogic-relationship-role>
<weblogic-relationship-role>
<relationship-role-name>second-friend</relationship-role-
name>
<relationship-role-map>
<column-map>
<foreign-key-column>second-friend-id</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
関係に関与する CMP Bean は、複数の DBMS テーブルにマップできます。
関係のどの Bean も複数のテーブルにマップされない場合は、使用されるテーブルが暗黙的に了解されるので、foreign-key-table 要素と primary-key-table 要素は省略することができます。
図 5-15 は、1 対 1 の関係の外部キー側の Bean (Fk_Bean) が 2 つのテーブル (Fk_BeanTable_1 と Fk_BeanTable_2) にマップされる CMR の relationship-role-map です。
関係の外部キー カラム (Fk_column_1 と Fk_column_2) は、Fk_BeanTable_2 に配置されます。 主キー側の Bean (Pk_Bean) は、主キー カラム Pk_table_pkColumn_1 と Pk_table_pkColumn_2 のある 1 つのテーブルにマップされます。
外部キー カラムを持つテーブルは、<foreign-key-table> 要素で指定します。
図5-15 1 対 1 の CMR (1 つの Bean が複数のテーブルにマップされる)
<relationship-role-map
<foreign-key-table>Fk_BeanTable_2</foreign-key-table>
<column-map>
<foreign-key-column>Fk_column_1</foreign-key-column>
<key-column>Pk_table_pkColumn_1</key-column>
</column-map>
<column-map>
<foreign-key-column>Fk_column_2</foreign-key-column>
<key-column>Pk_table_pkColumn_2</key-column>
</column-map>
</relationship-role-map>
リレーションシップ キャッシングでは、関係する複数 Bean をキャッシュにロードし、それらに結合クエリを発行してクエリの発行回数を削減することによって、エンティティ Bean のパフォーマンスが高められます。
たとえば、次のような関係のエンティティ Bean があるとします。
accountBean および addressBean の EJB コード (1 対 1 の関係を持つ) を検討します。
Account acct = acctHome.findByPrimaryKey("103243");
Address addr = acct.getAddress();
リレーションシップ キャッシングが行われなければ、コードの 1 行目で accountBean をロードする SQL クエリが発行され、2 行目で addressBean をロードする SQL クエリが発行されます。これにより、データベースには 2 つのクエリが生じます。
リレーションシップ キャッシングが行われると、accountBean と addressBean の双方をロードする 1 つのクエリがコードの 1 行目で発行されるため、パフォーマンスは向上するはずです。したがって、特定のファインダ メソッドを実行した後に関連する Bean にアクセスすることがわかっている場合は、リレーションシップ キャッシング機能を通じてファインダ メソッドに通知しておくことをお勧めします。
リレーションシップ キャッシングは、weblogic-cmp-jar.xml で以下のスタンザを使用して指定します。
注意: weblogic-ejb-jar.xml ファイル上で 、ある関係が指定されている Bean (たとえば、上記の XML コード例では customerBean) の finders-load-bean 要素が False に設定されていないことを確かめます。このようにしなければ、リレーションシップ キャッシングが有効になりません。 finder-load-bean 要素のデフォルトは True です。
図5-16 weblogic-cmp-jar.xml の relationship-caching
<relationship-caching>
<caching-name>cacheMoreBeans</caching-name>
<caching-element>
<cmr-field>accounts</cmr-field>
</caching-element>
</relationship-caching>
図5-17 weblogic-cmp-jar.xml の weblogic-query
<weblogic-query>
<query-method>
<method-name>findBigAccounts</method-name>
<method-params>
<method-param>java.lang.String</method-param>
<method-param>java.lang.Integer</method-param>
</method-params>
</query-method>
<caching-name>cacheMoreBeans</caching-name>
</weblogic-query>
ネストされた caching-element を使用すると、複数レベルの関連 Bean をロードすることができます。現在は、指定できる caching-element の数に制限はありません。 しかし、caching-element のレベルをあまり多く設定しすぎると、そのトランザクションのパフォーマンスに影響すると考えられます。
リレーションシップ キャッシングでは結合クエリを使用し、結合クエリではおそらく結果を ResultSet 内のテーブルに複写するため、指定した caching-element 要素の数が ResultSet に複写される結果の数に直に影響してきます。 1 対多関係では、relationship-caching 要素であまり多くの caching-element デプロイメント記述子を指定しないでください。caching-element デプロイメント記述子の数に対して複写される結果の数が乗算される可能性があります。
リレーションシップ キャッシングの機能には次のような制限があります。
カスケード削除メカニズムは、エンティティ Bean オブジェクトを削除する場合に使用します。カスケード削除を特定の関係に対して指定した場合、エンティティ オブジェクトの有効期間は他方のエンティティ オブジェクトに依存します。1 対 1 関係と 1 対多関係に対してはカスケード削除を指定できますが、多対多関係に対しては指定できません。cascade delete() メソッドは WebLogic Server の削除機能を使用し、database cascade delete() メソッドでは、基盤データベースに組み込まれているカスケード削除のサポートを使用するよう WebLogic Server に指示します。
この機能を有効にするには、Bean コードを再コンパイルしてデプロイメント記述子の変更を有効にする必要があります。
カスケード削除を有効にするには、以下の 2 つの方法のいずれかに従います。
cascade delete() メソッドでは、WebLogic Server を使用してオブジェクトを削除します。削除したエンティティに関連するエンティティ Bean に対して cascade delete 要素が指定されている場合、カスケード削除が行われ、関連するエンティティ Bean もすべて削除されます。
カスケード削除を指定するには、ejb-jar.xml デプロイメント記述子要素の cascade-delete 要素を使用します。これはデフォルト メソッドです。データベースの設定には変更を加えません。WebLogic Server は、カスケード削除が行われる場合に削除対象のエンティティ オブジェクトをキャッシュします。
カスケード削除を指定するには、ejb-jar.xml ファイルの cascade-delete 要素を使用します。
<ejb-relation>
<ejb-relation-name>Customer-Account</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>Account-Has-Customer
</ejb-relationship-role-name>
<multiplicity>one</multiplicity>
<cascade-delete/>
</ejb-relationship-role>
</ejb-relation>
注意: この cascade delete() メソッドは、ejb-relation 要素に含まれる一方の ejb-relationship-role 要素に対してのみ指定できます。この場合、同じ ejb-relation 要素の他方の ejb-relationship-role 要素に値が one の multiplicity 属性が指定されている必要があります。
database cascade delete() メソッドを使用すると、アプリケーションはデータベースに組み込まれているカスケード削除のサポートを利用できるので、パフォーマンスの向上を見込めます。db-cascade-delete 要素を weblogic-cmp-rdbms-jar.xml ファイルにまだ指定していない場合、データベースのカスケード削除機能を有効にしないでください。 有効にすると、データベースで不正な結果が生成されます。
weblogic-cmp-rdbms-jar.xml ファイルのdb-cascade-delete 要素では、基盤となる DBMS の組み込みカスケード削除機能をカスケード削除処理で使用するよう指定します。この機能はデフォルトでは無効になっているので、EJB コンテナは Bean ごとに SQL DELETE 文を発行してカスケード削除に関連する Bean を削除します。
db-cascade-delete 要素を weblogic-cmp-rdbms-jar.xml に指定する場合、cascade-delete 要素を ejb-jar.xml に指定する必要があります。
db-cascade-delete を有効にすると、データベース テーブルの追加設定が必要になります。たとえば、dept がデータベースで削除された場合、Oracle データベース テーブルの次の設定によって、すべての従業員がカスケード削除されます。
図5-19 カスケード削除用の Oracle テーブルの設定
CREATE TABLE dept
(deptno NUMBER(2) CONSTRAINT pk_dept PRIMARY KEY,
dname VARCHAR2(9) );
CREATE TABLE emp
(empno NUMBER(4) PRIMARY KEY,
ename VARCHAR2(10),
deptno NUMBER(2) CONSTRAINT fk_deptno
REFERENCES dept(deptno)
ON DELETE CASCADE );
WebLogic Server は、セッション Bean およびエンティティ Bean 用のローカル インタフェースをサポートしています。ローカル インタフェースを使用すると、エンタープライズ JavaBean は、同じ EJB コンテナ内で別のセマンティクスと実行コンテキストを使用して動作できます。通常、EJB は同じ EJB 内にあり、同じ Java 仮想マシン (JVM) 内で動作します。このようにして、EJB は通信にネットワークを使用せず、Java Remote Method Invocation-Internet Inter-ORB Protocol (RMI-IIOP) 接続によるオーバーヘッドの発生を防ぎます。
EJB とコンテナ管理による永続性の関係は、EJB のローカル インタフェースに基づいています。関係に関わる EJB には、ローカル インタフェースが必要です。ローカル インタフェース オブジェクトは、軽量の永続的オブジェクトです。これらのオブジェクトを使用すると、リモート オブジェクトを使用するよりも完成度の高いコーディングが可能になります。ローカル インタフェースも参照渡しです。ゲッターはローカル インタフェースに含まれています。
以前のバージョンの WebLogic Server では、リモート インタフェースに基づいて関係を指定できます。しかし、新しいコードでは、リモート インタフェースを使用する CMP の関係を使用しないことをお勧めします。
EJB コンテナを使用すると、ローカル クライアントが JNDI 経由でローカル ホーム インタフェースにアクセスできるようになります。ローカル インタフェースを参照するには、ローカルの JNDI 名が必要です。エンティティ Bean のローカル ホスト インタフェースを実装するオブジェクトは、EJBLocalHome オブジェクトと呼ばれます。weblogic-ejb-jar.xml ファイルの jndi-name、または local-jndi-name を指定できます。 デプロイメント記述子を指定する手順の詳細については、EJB デプロイメント記述子の指定と編集を参照してください。
WebLogic Server の以前のバージョンでは、リモート インタフェースを返すために ejbSelect メソッドが使用されていました。現在では、クエリの結果をローカルまたはリモートのどちらのオブジェクトにマップするかを示す ejb-jar.xml ファイルの result-type-mapping 要素を指定します。
セッション Bean またはエンティティ Bean のローカル クライアントは、セッション Bean、エンティティ Bean、メッセージ駆動型 Bean など別の EJB です。ローカル クライアントは、同じ EAR ファイルに含まれており、かつその EAR ファイルがリモートでない限り、サーブレットでもかまいません。ローカル Bean のクライアントは、EAR またはスタンドアロン JAR の一部でなければなりません。
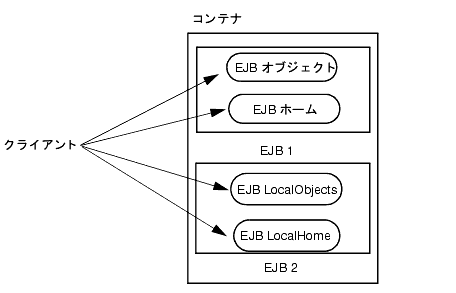
ローカル クライアントは、Bean のローカル インタフェースとローカル ホーム インタフェースを介してセッション Bean またはエンティティ Bean にアクセスします。コンテナは、Bean のローカル インタフェースとローカル ホーム インタフェースを実装するクラスを提供します。これらのインタフェースを実装するオブジェクトは、ローカル Java オブジェクトです。次の図は、ローカル クライアントとローカル インタフェースを持つコンテナを示しています。
図5-20 ローカル クライアントとローカル インタフェース
WebLogic Server は、EJB 間でローカルの関係と一方向のリモート関係の両方をサポートしています。EJB が同じサーバ上にあり、同じ JAR ファイルを構成している場合、EJB はローカルの関係を持ちます。EJB が同じサーバ上にない場合、関係はリモートでなければなりません。ローカル Bean の関係では、その関係を実装するキーが複合キーである場合は複数カラムのマッピングを指定します。リモート Bean の場合は、リモート Bean の主キーが不明であるため、単一の column-map だけが指定されます。ロールが group-name だけを指定している場合、column-map は指定されません。関係がリモートの場合は group-name は指定されません。
ローカル インタフェースを格納するために、コンテナの構造が変更され、以下のものが追加されています。
コンテナ管理による永続性では、グループを使用して、エンティティ Bean の特定の永続的な属性を指定します。field-group は、Bean の cmp-field と CMR-field のサブセットを表します。Bean 内の関連フィールドを、障害のあったグループにまとめて 1 つのユニットとしてメモリ内に入れることができます。グループをクエリまたは関係に関連付けることができます。それによって、クエリを実行するか、または関係に従った結果として Bean がロードされたときに、グループ内の指定フィールドのみがロードされます。
指定したグループを持たないクエリと関係に対して、「default」という特殊なグループを使用します。デフォルトでは、default グループには、Bean のすべての CMP-field と、Bean の永続的な状態に外部キーを追加するすべての CMR-field が格納されます。
フィールドは複数のグループに関連付けられている場合があります。この場合、フィールドに対して getXXX() メソッドを実行すると、そのフィールドを含む最初のグループで障害が発生します。
フィールド グループは、weblogic-rdbms-cmp-jar.xml ファイルで次のように指定します。
<weblogic-rdbms-bean>
<ejb-name>XXXBean</ejb-name>
<field-group>
<group-name>medical-data</group-name>
<cmp-field>insurance</cmp-field>
<cmr-field>doctors</cmr-fields>
</field-group>
</weblogic-rdbms-bean>
フィールド グループは、フィールドのサブセットにアクセスする必要があるときに使用します。
WebLogic Server では、EJB 2.0 仕様で定義されている EJB リンクを完全にサポートしています。アプリケーション コンポーネント内で EJB 参照を宣言し、これを同じ J2EE アプリケーション内で宣言されたエンタープライズ Bean にリンクさせることができます。
<ejb-link>../products/product.jar#ProductEJB</ejb-link>
デプロイメント記述子を指定する手順については、EJB デプロイメント記述子の指定と編集を参照してください。
次の表は、WebLogic Server で使用される CMP フィールドの Java データ型と、それに対応する標準 SQL データ型の Oracle 拡張を示しています。
SQL CHAR データ型は、CMP フィールドにマップされるデータベース カラムには使用しないでください。このことは、主キーの一部であるフィールドで特に重要です。なぜなら、JDBC ドライバによって返されるパディングの空白は、等しいかどうかの比較を不適切に失敗させるからです。SQL CHAR の代わりに、SQL VARCHAR データ型を使用してください。
byte[] 型の CMP フィールドは、equals() メソッドと hashCode() メソッドを備えるユーザ定義の主キー クラスでラップされていない限り主キーとしては使用できません。なぜなら、byte[] クラスには実質的な equals および hashCode が備わっていないからです。
|

|

|