| ドキュメントのダウンロード | サイト マップ | 用語集 | |
|
|||
| BEA ホーム | 製品 | デベロッパ・センタ | support | askBEA |
|
|
||||||||
| e-docs > WebLogic Server > WebLogic XML プログラマーズ ガイド > WebLogic XML Streaming API の使い方 |
|
WebLogic XML プログラマーズ ガイド
|
WebLogic XML Streaming API の使い方
以下の節では、WebLogic XML Streaming API により XML ドキュメントの解析と生成を行う方法について説明します。
WebLogic XML Streaming API の概要
WebLogic XML Streaming API は、XML ドキュメントの解析と生成を簡単に直感的に行える方法を提供します。SAX API に似ていますが、複雑な XML ドキュメントを処理する際の煩雑さの原因になる SAX イベント ハンドラを書く必要はなく、手順の流れに従って XML ドキュメントを処理できます。つまり、Streaming API では、SAX API より解析を綿密に制御できます。
SAX を使用して XML ドキュメントを解析する場合、プログラムでは、イベント発生時に解析をリスンするイベント リスナを作成し、特定のイベントを請求するのではなく、イベントに対して対応する必要があります。一方、Streaming API を使用する場合は、XML ドキュメントを手順の流れに沿って処理すること、特定のタイプのイベント(要素の開始など)を請求すること、要素の属性を繰り返し処理すること、ドキュメントの先頭をスキップすること、任意の時点で処理を停止すること、特定の要素のサブ要素を取得すること、指定どおりに要素をフィルタすることができます。イベントに対応するのではなく、イベントを請求するので、Streaming API を使用する方法は、「プル解析」と呼ばれることもあります。
Streaming API により、オペレーティング システム上の XML ファイル、DOM ツリー、SAX イベントのセットなど、多くのタイプの XML ドキュメントを解析できます。これらの XML ドキュメントをイベントのストリーム、すなわち XMLInputStream、に変換し、このストリームを順に処理して、要素の開始、ドキュメントの終了などのイベントを必要に応じてスタックから取得します。
WebLogic Streaming API は、デフォルト パーサとして WebLogic FastParser を使用します。
Streaming API による XML ドキュメント解析の詳細なサンプルについては、WL_HOME¥samples¥server¥src¥examples¥xml¥orderParser ディレクトリを参照してください。WL_HOME は、最上位 WebLogic Platform ディレクトリです。
次の表で、WebLogic Streaming API の主なインタフェースとクラスについて説明します。
XML ドキュメントの解析 : 一般的手順
以下の手順は、WebLogic XML Streaming API により XML ドキュメントの解析と操作を行う一般的手順について説明したものです。
最初の 2 つの手順は必須です。その後の手順は、XML ファイルをどのように処理するかに応じて実行します。
XML ドキュメント解析の例
以下の節では、XML Streaming API により XML ドキュメントを解析する例を示します。
このプログラムは、XML ファイルを表わす 1 つのパラメータを取り、そのファイルを XML 入力ストリームに変換します。次に、ストリームを繰り返し処理し、XML要素の開始、XML ドキュメントの終了など、各イベントのタイプを判別します。開始要素、終了要素、および要素の本文を形成する文字データの 3 つのタイプのイベントについては、情報がプリントアウトされます。コメントや XML ドキュメントの開始など、その他のタイプのイベントについては、何も行われません。
注意: 太字のコードについては、例の後の節で詳しく説明します。
package examples.xml.stream;
import weblogic.xml.stream.Attribute;
import weblogic.xml.stream.AttributeIterator;
import weblogic.xml.stream.ChangePrefixMapping;
import weblogic.xml.stream.CharacterData;
import weblogic.xml.stream.Comment;
import weblogic.xml.stream.XMLEvent;
import weblogic.xml.stream.EndDocument;
import weblogic.xml.stream.EndElement;
import weblogic.xml.stream.EntityReference;
import weblogic.xml.stream.ProcessingInstruction;
import weblogic.xml.stream.Space;
import weblogic.xml.stream.StartDocument;
import weblogic.xml.stream.StartPrefixMapping;
import weblogic.xml.stream.StartElement;
import weblogic.xml.stream.EndPrefixMapping;
import weblogic.xml.stream.XMLInputStream;
import weblogic.xml.stream.XMLInputStreamFactory;
import weblogic.xml.stream.XMLName;
import weblogic.xml.stream.XMLStreamException;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class ComplexParse {/**
* ストリームでハンドルを取得するためのヘルパー メソッド
* 名前で取得し、ストリームを戻す
* このメソッドは、InputStreamFactory を使用して、
* XMLInputStream のインスタンスを作成する
* @param name 解析するファイル
* @return XMLInputStream 解析するストリーム
*/
public XMLInputStream getStream(String name)
throws XMLStreamException, FileNotFoundException
{
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
XMLInputStream stream = factory.newInputStream(new FileInputStream(name));
return stream;
}
/**
* 要素の開始、ドキュメントの終了など、
* イベントのタイプを識別する
* イベントのタイプが START_ELEMENT, END_ELEMENT または
* CHARACTER_DATA である場合、メソッドは該当する情報を
* プリントアウトする。そうでない場合、何もしない
* @param event 解析された XML イベント
*/
public void parse(XMLEvent event)
throws XMLStreamException
{
switch(event.getType()) {
case XMLEvent.START_ELEMENT:
StartElement startElement = (StartElement) event;
System.out.print("<" + startElement.getName().getQualifiedName() );
AttributeIterator attributes = startElement.getAttributesAndNamespaces();
while(attributes.hasNext()){
Attribute attribute = attributes.next();
System.out.print(" " + attribute.getName().getQualifiedName() +
"='" + attribute.getValue() + "'");
}
System.out.print(">");
break;
case XMLEvent.END_ELEMENT:
System.out.print("</" + event.getName().getQualifiedName() +">");
break;
case XMLEvent.SPACE:
case XMLEvent.CHARACTER_DATA:
CharacterData characterData = (CharacterData) event;
System.out.print(characterData.getContent());
break;
case XMLEvent.COMMENT:
// コメントを出力
break;
case XMLEvent.PROCESSING_INSTRUCTION:
// ProcessingInstruction を出力
break;
case XMLEvent.START_DOCUMENT:
// StartDocument を出力
break;
case XMLEvent.END_DOCUMENT:
// EndDocument を出力
break;
case XMLEvent.START_PREFIX_MAPPING:
// StartPrefixMapping を出力
break;
case XMLEvent.END_PREFIX_MAPPING:
// EndPrefixMapping を出力
break;
case XMLEvent.CHANGE_PREFIX_MAPPING:
// ChangePrefixMapping を出力
break;
case XMLEvent.ENTITY_REFERENCE:
// EntityReference を出力
break;
case XMLEvent.NULL_ELEMENT:
throw new XMLStreamException("Attempt to write a null event.");
default:
throw new XMLStreamException("Attempt to write unknown event
["+event.getType()+"]");
}
}
/**
* ストリーム全体を繰り返し処理するヘルパー メソッド
* @param name 解析するファイル
*/
public void parse(XMLInputStream stream)
throws XMLStreamException
{
while(stream.hasNext()) {
XMLEvent event = stream.next();
parse(event);
}
stream.close();
}
/** メイン メソッド。XML 入力ストリームに変換される
* XML ファイルを表わす 1 つの引数を取る
*/
public static void main(String args[])
throws Exception
{
ComplexParse complexParse= new ComplexParse();
complexParse.parse(complexParse.getStream(args[0]));
}
}
XML 入力ストリームの取得
XML Streaming API により、XML ファイル DOM ツリー、SAX イベントなど、さまざまなオブジェクトをイベントのストリームに変換できます。
次の例で、XML ファイルからイベントのストリームを変換する方法を示します。
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
XMLInputStream stream = factory.newInputStream(new FileInputStream(name));
まず、XMLInputStreamFactory の新しいインスタンスを作成し、次に、このファクトリを使用して、name 変数で参照される XML ファイルから新しい XMLInputStream を作成します。
次の例では、DOM ツリーからストリームを作成する方法を示します。
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setValidating(false);
dbf.setNamespaceAware(true);
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(new java.io.File(file));
XMLInputStream stream = XMLInputStreamFactory.newInstance().newInputStream(doc);
バッファされた XML 入力ストリームの取得
XMLInputStream オブジェクトの繰り返し処理を終了した後は、このストリームに再度アクセスすることはできません。ただし、再度ストリームを処理する必要がある場合、たとえば、ストリームを別のアプリケーションに送信したり、別の方法で再度繰り返し処理したりする場合は、XMLInputStream オブジェクトではなく、BufferedXMLInputStream オブジェクトを使用できます。
バッファされた XML 入力ストリームを作成するには、XMLInputStreamFactory クラスの newBufferedInputStream() メソッドを使用します。以下に例を示します。
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
BufferedXMLInputStream bufstream =
factory.newBufferedInputStream(factory.newInputStream(new
FileInputStream(name)));
BufferedXMLInputStream オブジェクトの mark() メソッドと reset() メソッドにより、ストリームの特定のスポットをマークし、ストリームの処理を続け、マークしたスポットに戻るようにストリームをリセットできます。詳細については、バッファされた XML 入力ストリームのマーキングとリセットを参照してください。
XML ストリームのフィルタリング
XML ストリームのフィルタリングとは、指定したタイプのオブジェクトのみの入ったストリームを作成することです。たとえば、開始要素、終了要素、および XML 要素の本文をマークアップする文字データのみの入ったストリームを作成できます。別の例では、指定した名前を持つ要素のみがストリームに出現するように XML ストリームをフィルタリングすることもできます。
XML ストリームをフィルタするには、XMLInputStreamFactory.newInputStream() メソッドに対する 2 番目のパラメータとしてフィルタ クラスを指定します。フィルタ クラスに対するパラメータとして XML ストリームに入れるイベントを指定します。次の例では、TypeFilter クラスにより、結果の XML ストリームに XML の開始要素と終了要素、および文字データのみを入れるように指定する方法を示します。
import weblogic.xml.stream.util.TypeFilter;
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
XMLInputStream stream = factory.newInputStream(new FileInputStream(name),
new TypeFilter(XMLEvent.START_ELEMENT |
XMLEvent.END_ELEMENT |
XMLEvent.CHARACTER_DATA));
次の表で、WebLogic XML Streaming API に用意されているフィルタについて説明します。これらは、weblogic.xml.stream.util パッケージの一部です。
カスタム フィルタの作成
API に入っているフィルタがニーズに合わない場合は、独自のフィルタを作成することもできます。
package my.filters;
import weblogic.xml.stream.XMLName;
import weblogic.xml.stream.ElementFilter;
import weblogic.xml.stream.events.NullEvent;
public class SuperDooperFilter implements ElementFilter {protected String name;
public SuperDooperFilter(String name)
{
this.name = name;
}
public boolean accept(XMLEvent e) {
if (name.equals(e.getName().getLocalName()))
return true;
return false;
}
}import my.filters.SuperDooperFilter
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
XMLInputStream stream = factory.newInputStream(new FileInputStream(name),
new SuperDooperFilter(param));
ストリームの繰り返し処理
イベントのストリームが完成した後、次の手順は、XMLInputStream.next() メソッドと XMLInputStream.hasNext() メソッドにより、イベントのストリームを手順に沿って処理することです。以下に例を示します。
while(stream.hasNext()) {
XMLEvent event = stream.next();
System.out.print(event);
}特定の XMLEvent タイプの判別
XMLInputStream.next() メソッドは、タイプ XMLEvent のオブジェクトを返します。XMLEvent には、このイベントが、XML ドキュメントの開始、要素の終了、エンティティ参照などのどれであるかをさらに分類するサブインタフェースがあります。XMLEvent インタフェースには、対応するフィールド、すなわち定数、ならびに実際のイベントを識別するために使用できるメソッドのセットも入っています。次の図に、XMLEvent インタフェースとそのサブインタフェースの階層を示します。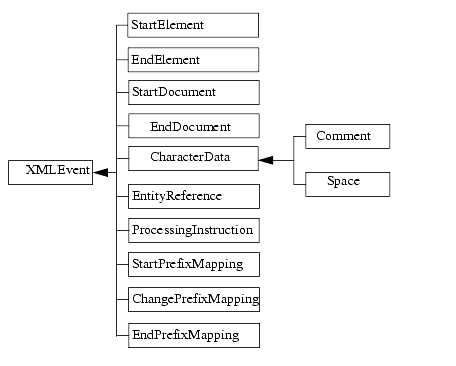
次の表に、XML ストリームの解析時に特定のイベントを識別するために使用できる XMLEvent クラスのサブクラスとフィールドをリストします。
次の例では、Java case 文を使用して、XMLInputStream.next() メソッドにより返されたイベントのタイプを判別する方法を示します。簡単にするため、この例では、見つかったイベントをそのままプリントします。イベントをさらに処理する方法は、その後の節で示します。
switch(event.getType()) {
case XMLEvent.START_ELEMENT:
// 要素の開始
System.out.println ("Start Element¥n");
break;case XMLEvent.END_ELEMENT:
// 要素の終了
System.out.println ("End Element¥n");
break;
case XMLEvent.PROCESSING_INSTRUCTION:
// 処理指示
System.out.println ("Processing instruction¥n");
break;
case XMLEvent.SPACE:
// ホワイトスペース
System.out.println ("White space¥n");
break;
case XMLEvent.CHARACTER_DATA:
// 文字データ
System.out.println ("Character data¥n");
break;
case XMLEvent.COMMENT:
// コメント
System.out.println ("Comment¥n");
break;
case XMLEvent.START_DOCUMENT:
// XML ドキュメントの開始
System.out.println ("Start Document¥n");
break;
case XMLEvent.END_DOCUMENT:
// XML ドキュメントの終了
System.out.println ("End Document¥n");
break;
case XMLEvent.START_PREFIX_MAPPING:
// プレフィックス マッピング スコープの開始
System.out.println ("Start prefix mapping¥n");
break;
case XMLEvent.END_PREFIX_MAPPING:
// プレフィックス マッピング スコープの終了
System.out.println ("End prefix mapping¥n");
break;
case XMLEvent.CHANGE_PREFIX_MAPPING:
// プレフィックス マッピングがネームスペースを変更
System.out.println ("Change prefix mapping¥n");
break;
case XMLEvent.ENTITY_REFERENCE:
// エンティティ参照
System.out.println ("Entity reference¥n");
break;
default:
throw new XMLStreamException("Attempt to parse unknown event
[" + event.getType() + "]");
}要素の属性の取得
XML ドキュメントの要素の属性を取得するには、まず、XMLInputStream.next() メソッドにより返された XMLEvent オブジェクトを StartElement オブジェクトに対してキャストする必要があります。
要素が何個の属性を持っているか分からないため、まず、属性のリスト全体を入れる AttributeIterator オブジェクトを作成してから、属性がなくなるまでリストを繰り返し処理します。次の例で、ストリームの繰り返し処理に示した switch 文の START_ELEMENT case の一部としてこれを行う方法を示します。
case XMLEvent.START_ELEMENT:
StartElement startElement = (StartElement) event;
System.out.print("<" + startElement.getName().getQualifiedName() );
AttributeIterator attributes = startElement.getAttributesAndNamespaces();
while(attributes.hasNext()){
Attribute attribute = attributes.next();
System.out.print(" " + attribute.getName().getQualifiedName() +
"='" + attribute.getValue() + "'");
}
System.out.print(">");
break;
この例では、まず、返されたXMLEvent を StartElement にキャストすることにより、StartElement オブジェクトを作成します。次に、StartElement.getAttributesAndNamespaces() メソッドを使用して AttributeIterator オブジェクトを作成し、AttributeIterator.hasNext() メソッドを使用して属性を繰り返し処理します。Attribute それぞれについて、Attributes.getName().getQualifiedName() メソッドと Attribute.getValue() メソッドを使用し、属性の名前と値を返します。
getNamespace() メソッドと getAttributes() メソッドにより、ネームスペースまたは属性のみを返すこともできます。
ストリームの位置決め
次の表で、ストリームの特定の位置までスキップするために使用できる XMLInputStream インタフェースのメソッドについて説明します。
次の例では、入力ストリームを繰り返し処理する基本コードを修正し、XML 要素の本文の文字データをスキップする方法を示します。
while(stream.hasNext()) {
XMLEvent peek = stream.peek();
if (peek.getType() == XMLEvent.CHARACTER_DATA ) {
stream.skip();
continue;
}
XMLEvent event = stream.next();
parse(event);
}この例は、XMLInputStream.peek() メソッドを使用してストリーム上の次のイベントを判別する方法を示しています。イベントのタイプが XMLEvent.CHARACTER_DATA である場合、そのイベントはスキップされ、次のイベントに進みます。
サブストリームの取得
すべてのサブ要素も含め、次の要素のコピーを取得するには、XMLInputStream.getSubStream() メソッドを使用します。getSubstream() メソッドは、XMLInputStream オブジェクトを返します。親ストリーム(または getSubStream() を呼び出したストリーム)での位置は移動しません。親ストリームでは、getSubStream() で取得した要素をスキップしたい場合、skipElement() メソッドを使用します。
getSubStream() メソッドは、検出された START_ELEMENT イベントと END_ELEMENT イベントの数を記録し、その数が等しくなると(すなわち、完全な次の要素が見つかると)停止して、結果のサブストリームを XMLInputStream オブジェクトとして返します。
たとえば、XML Streaming API を使用して以下の XML ドキュメントを解析するとします。ただし、<content> タグと </content> タグに囲まれたサブストリームのみを対象にします。
<book>
<title>The History of the World</title>
<author>Juliet Shackell</author>
<publisher>CrazyDays Publishing</publisher>
<content>
<chapter title='Just a Speck of Dust'>
<synopsis>The world as a speck of dust</synopsis>
<para>Once the world was just a speck of dust...</para>
</chapter>
<chapter title='Life Appears'>
<synopsis>Move over dust, here comes life.</synopsis>
<para>Happily, the dust got a companion: life...</para>
</chapter>
</content>
</book>
次のコード(抜粋)は、<content> 開始要素タグをスキップし、サブストリームを取得し、独立した ComplexParse オブジェクトを使用してそのサブストリームを解析する方法を示しています。
if (stream.skip( ElementFactory.createXMLName("content")))
{
ComplexParse complexParse = new ComplexParse();
complexParse.parse(stream.getSubStream());
}前の XML ドキュメントでこのメソッドを呼び出すと、以下の出力が得られます。
<content>
<chapter title='Just a Speck of Dust'>
<synopsis>The world as a speck of dust</synopsis>
<para>Once the world was just a speck of dust...</para>
</chapter>
<chapter title='Life Appears'>
<synopsis>Move over dust, here comes life.</synopsis>
<para>Happily, the dust got a companion: life...</para>
</chapter>
</content>
バッファされた XML 入力ストリームのマーキングとリセット
BufferedXMLInputStream オブジェクトを使用する場合、mark() メソッドと reset() メソッドにより、ストリームの特定のスポットをマークし、ストリームの処理を続けた後、マークしたスポットに戻るようにストリームをリセットできます。この 2 つのメソッドは、最初に繰り返し処理をした後で、ストリームをさらに操作したい場合に便利です。
注意: バッファされたストリームをマーキングせずに読み取った場合、直前に読み取ったものにアクセスすることはできません。つまり、ストリームはバッファされるだけであり、自動的にストリームを再読み取りできることを意味するわけではありません。まずストリームをマークしておく必要があります。
次の例で、BufferedXMLInputStream オブジェクトの一般的な使い方を示します。
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
BufferedXMLInputStream bufstream =
factory.newBufferedInputStream(factory.newInputStream(new
FileInputStream(name)));
// ストリームの開始をマーク
bufstream.mark();
// ストリームをローカルに処理
bufferedParse.parse(bufstream);
// ストリームをマークにリセット
bufstream.reset();
// 別のアプリケーションにストリームを送信
ComplexParse complexParse = new ComplexParse();
complexParse.parse(bufstream);
入力ストリームのクローズ
プログラミング慣行として、XML 入力ストリームでの作業終了時に入力ストリームを明示的にクローズします。入力ストリームをクローズするには、XMLInputStream.close() メソッドを使用します。以下に例を示します。
// 入力ストリームのクローズ
input.close();
新しい XML ドキュメントの生成 : 一般的手順
次の手順では、WebLogic XML Streaming API により新しい XML ドキュメントを生成する一般的手順について説明します。
最初の 2 つの手順は必須です。その後の手順は、XML ファイルをどのように生成するかに応じて実行します。
XML ドキュメント生成の例
以下の節では、XML Streaming API により XML ドキュメントを生成する例を示します。
このプログラムでは、まず、PrintWriter オブジェクトに基づいて出力ストリームを作成し、次に、その出力ストリームに要素を追加して、プログラムのコメントに説明されているように、単純な XML 発注書を作成します。また、別の XML ファイルに基づく入力ストリームを出力ストリームに追加する方法も示します。
注意: サンプルの後の節に、さらに詳しい説明があります。
package examples.xml.stream;
import weblogic.xml.stream.XMLInputStream;
import weblogic.xml.stream.XMLOutputStream;
import weblogic.xml.stream.XMLInputStreamFactory;
import weblogic.xml.stream.XMLName;
import weblogic.xml.stream.XMLEvent;
import weblogic.xml.stream.StartElement;
import weblogic.xml.stream.EndElement;
import weblogic.xml.stream.Attribute;
import weblogic.xml.stream.ElementFactory;
import weblogic.xml.stream.XMLStreamException;
import weblogic.xml.stream.XMLOutputStreamFactory;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.PrintWriter;
/**
* 次のような非常に単純な発注書を
* プリントアウトするプログラム
*
* <purchase_order>
* <name>Juliet Shackell</name>
* <item id="1234" quantity="2">Fabulous Chair</item>
* <!-- this is a comment-->
* <another_file>
* This comes from another file called "another_file.xml"
* </another_file>
* </purchase_order>
*
* 上の XML ファイルで、<another_file> 要素は、実際には
* 別の XML ファイルであり、そのファイルからプログラムに引数が渡され、
* XMLInputStream に変換された後、出力ストリームに追加される
*/
public class PrintPurchaseOrder {
/**
* ストリームでハンドルを取得するためのヘルパー メソッド
* 名前で取得し、ストリームを戻す
* このメソッドは、InputStreamFactory を使用して、
* XMLInputStream のインスタンスを作成する
* @param name 解析するファイル
* @return XMLInputStream 解析するストリーム
*/
public XMLInputStream getInputStream(String name)
throws XMLStreamException, FileNotFoundException
{
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
XMLInputStream stream = factory.newInputStream(new FileInputStream(name));
return stream;
}
public static void main(String args[])
throws Exception
{
PrintPurchaseOrder printer = new PrintPurchaseOrder();
//
// 出力ストリームを作成する
//
XMLOutputStreamFactory factory = XMLOutputStreamFactory.newInstance();
XMLOutputStream output = factory.newOutputStream(new
PrintWriter(System.out,true));
// <purchase_order> ルート要素を追加する
output.add(ElementFactory.createStartElement("purchase_order"));
output.add(ElementFactory.createCharacterData("¥n"));
// <name> 要素を追加する
output.add(ElementFactory.createStartElement("name"));
output.add(ElementFactory.createCharacterData("Juliet Shackell"));
output.add(ElementFactory.createEndElement("name"));
output.add(ElementFactory.createCharacterData("¥n"));
// ID属性および数量属性の入った <item> 要素を追加する
output.add(ElementFactory.createStartElement("item"));
output.add(ElementFactory.createAttribute("id","1234"));
output.add(ElementFactory.createAttribute("quantity","2"));
output.add(ElementFactory.createCharacterData("Fabulous Chair"));
output.add(ElementFactory.createEndElement("item"));
output.add(ElementFactory.createCharacterData("¥n"));
// コメントを追加する
output.add("<!-- this is a comment-->");
output.add(ElementFactory.createCharacterData("¥n"));
// 各 XML ファイル引数から入力ストリームを作成し、それを出力に追加する
for (int i=0; i < args.length; i++)
//
// 入力ストリームを取得し、それを出力ストリームに追加する
//
output.add(printer.getInputStream(args[i]));
// 最後に、"purchase_order" ルート要素を終了する
output.add(ElementFactory.createEndElement("purchase_order"));
//
// 結果を画面に出力する
//
output.flush();
// 出力ストリームをクローズする
output.close();
}
}
上のプログラムは、次の出力を生成します。
<purchase_order>
<name>Juliet Shackell</name>
<item id="1234" quantity="2">Fabulous Chair</item>
<!-- this is a comment-->
<another_file>
This is from another file.
</another_file>
</purchase_order>
XML 出力ストリームの作成
WebLogic XML Streaming API により XML ドキュメントを生成する最初の手順の 1 つは、構築されるドキュメントを入れるための出力ストリームを作成することです。XML 出力ストリームの作成方法は、入力ストリームの作成方法と似ています。まず、XMLOutputStreamFactory のインスタンスを作成し、次に XMLOutputStreamFactory.newOutputStream() メソッドで出力ストリームを作成します。以下に例を示します。
XMLOutputStreamFactory factory = XMLOutputStreamFactory.newInstance();
XMLOutputStream output = factory.newOutputStream(new
PrintWriter(System.out,true));
次の例では、DOM ツリーに基づいて XMLOutputStream を作成する方法を示します。
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setValidating(false);
dbf.setNamespaceAware(true);
Document doc = dbf.newDocumentBuilder().newDocument();
XMLOutputStream out =
XMLOutputStreamFactory.newInstance().newOutputStream(doc);
XMLOutputStreamFactory.newOutputStream() メソッドを使用して、以下の 4 つの Java オブジェクトに基づく出力ストリームを作成できます。オブジェクトは、XML ドキュメントの最終形式を何にするか(オペレーティング システム上のファイル、DOM ツリーなど)に応じて決定します。
出力ストリームへの要素の追加
出力ストリームに要素を追加するには、XMLOutputStream.add(XMLEvent) メソッドを使用します。特定の要素を作成するには、ElementFactory を使用します。
ElementFactory インタフェースには、各タイプの要素を作成するためのメソッドが入っています。一般的フォーマットは ElementFactory.createXXX() です。XXX は、createStartElement()、createCharacterData()などの特定の要素を表わします。String または XMLName のような名前を渡すことにより、大部分の要素を作成できます。
警告: XMLOutputStream は XML を検証しません。
注意: 開始要素を作成するたびに、終了要素もどこかに明示的に作成する必要があります。同じ規則が開始ドキュメントの作成にも適用されます。
たとえば、次のような小さな XML を作成するとします。
<name>Juliet Shackell</name>
出力ストリームにこの要素を追加する Java コードは次のようになります。
output.add(ElementFactory.createStartElement("name"));
output.add(ElementFactory.createCharacterData("Juliet Shackell"));
output.add(ElementFactory.createEndElement("name"));
output.add(ElementFactory.createCharacterData("¥n"));最後の createCharacterData() メソッドは、出力ストリームに改行文字を追加します。この指定は必須ではありませんが、読みやすい XML を作成するときに便利です。
出力ストリームの要素への属性の追加
作成した要素に属性を追加するには、XMLOutputStream.add(Attribute) を使用します。特定の属性を作成するには、ElementFactory.createAttribute() メソッドを使用します。
たとえば、次のような小さな XML を作成するとします。
<item id="1234" quantity="2">Fabulous Chair</item>
出力ストリームにこの要素を追加する Java コードは次のようになります。
output.add(ElementFactory.createStartElement("item"));
output.add(ElementFactory.createAttribute("id","1234"));
output.add(ElementFactory.createAttribute("quantity","2"));
output.add(ElementFactory.createCharacterData("Fabulous Chair"));
output.add(ElementFactory.createEndElement("item"));
output.add(ElementFactory.createCharacterData("¥n"));注意: 要素への属性の追加は、開始要素を作成した後、対応する終了要素の作成より前に行ってください。そうでない場合、コードは正常にコンパイルされますが、プログラム実行時にエラーが発生します。たとえば、次のコードでは、<item> 要素が明示的に終了した後に、この要素に属性が追加されているので、エラーが返されます。
output.add(ElementFactory.createStartElement("item"));
output.add(ElementFactory.createEndElement("item"));
output.add(ElementFactory.createAttribute("id","1234"));
output.add(ElementFactory.createAttribute("quantity","2"));
output.add(ElementFactory.createCharacterData("Fabulous Chair"));
output.add(ElementFactory.createCharacterData("¥n"));出力ストリームへの入力ストリームの追加
XML 出力ストリームを作成する際、XML ファイルや DOM ツリーのような既存の XML ドキュメントを出力ストリームに追加したいことがあります。これを行うには、まず、その XML ドキュメントを XML 入力ストリームに変換してから、XMLOutputStream.add(XMLInputStream) メソッドを使用して出力ストリームに入力ストリームを追加します。
次の例では、まず、XML ファイルから XML 入力ストリームを作成する getInputStream() というメソッドを示し、その後、このメソッドを使用して作成された入力ストリームを出力プログラムに追加する方法を示します。
/**
* ストリームでハンドルを取得するためのヘルパー メソッド
* 名前で取得し、ストリームを戻す
* このメソッドは、InputStreamFactory を使用して、
* XMLInputStream のインスタンスを作成する
* @param name 解析するファイル
* @return XMLInputStream 解析するストリーム
*/
public XMLInputStream getInputStream(String name)
throws XMLStreamException, FileNotFoundException
{
XMLInputStreamFactory factory = XMLInputStreamFactory.newInstance();
XMLInputStream stream = factory.newInputStream(new FileInputStream(name));
return stream;
}
....
// 各 XML ファイル引数から入力ストリームを作成し、それを出力に追加する
for (int i=0; i < args.length; i++)
//
// 入力ストリームを取得し、それを出力ストリームに追加する
//
output.add(printer.getInputStream(args[i]));
出力ストリームの出力
オブジェクトから作成した XML 出力ストリームをプリントアウトするには、XMLOutputStream.flush() メソッドを使用します。たとえば、PrintWriter オブジェクトから XML 出力ストリームを作成した場合、そのストリームは、flush() メソッドにより標準出力に出力されます。
注意: DOM ツリーに基づいて XMLOutputStream に書き込む場合、まず flush() メソッドを実行しなければ、DOM を操作することはできません。
次の例では、出力ストリームを出力する方法を示します。
//
// 結果を画面に出力する
//
output.flush();
出力ストリームのクローズ
プログラミング慣行として、XML 出力ストリームでの作業終了時に入力ストリームを明示的にクローズします。出力ストリームをクローズするには、XMLOutputStream.close() メソッドを使用します。以下に例を示します。
// 出力ストリームをクローズする
output.close();
|

|

|