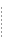



| dev2dev Home > dev2dev WebLogic Server > e-docs WebLogic Server BEA WebLogic Server バージョン 8.1 Documentation > WebLogic エンタープライズ JavaBeans プログラマーズ ガイド > コンテナ管理による永続性サービス : 基本機能 |
WebLogic エンタープライズ JavaBeans プログラマーズ ガイド
|
|
以下の節では、WebLogic Server EJB コンテナで利用できるコンテナ管理による永続性 (CMP) サービスの基本機能を説明します。「基本」機能とは、EJB アプリケーションを作成し実行できる状態にするために開発者が精通しておくべき機能を指します。高度な CMP 機能については、「コンテナ管理による永続性サービス : 高度な機能」を参照してください。
WebLogic Server のコンテナは、EJB と WebLogic Server インスタンス間の統一的なインタフェースを提供する役割を持っています。コンテナは、EJB の新しいインスタンスを作成し、これらの Bean リソースを管理し、トランザクション、セキュリティ、同時実行性、ネーミングなどの永続性サービスを実行時に提供します。
WebLogic Server のコンテナ管理による永続性 (CMP) モデルでは、EJB のインスタンス フィールドをデータベースのデータと同期することで、CMP エンティティ Bean の永続性を実行時に自動処理します。
WebLogic Server は次のデータベースについて、コンテナ管理による永続性をサポートしています。
WebLogic Server は、エンティティ Bean に永続性サービスを提供します。エンティティ EJB が任意のトランザクション対応またはトランザクション非対応の永続ストレージにその状態を保存する (「Bean 管理による永続性」) ことも、コンテナが EJB の非 transient インスタンス変数を自動的に保存する (「コンテナ管理による永続性」) こともできます。WebLogic Server では、このどちらも選択可能であり、両者を併用することもできます。
EJB がコンテナ管理の永続性を使用する場合、EJB が使用する永続性サービスのタイプを weblogic-ejb-jar.xml デプロイメント ファイルに指定します。自動永続性サービスのハイレベル定義は、persistence-use 要素に格納されます。persistence-use には、EJB がデプロイ時に使用するサービスが定義されます。
自動永続性サービスは、さらに別のデプロイメント ファイルを使用してそのデプロイメント記述子を指定し、エンティティ EJB ファインダ メソッドを定義します。たとえば、WebLogic Server RDBMS ベースの永続性サービスは、特定の Bean からデプロイメント記述子とファインダ定義を取得するときに、その Bean の weblogic-cmp-rdbms-jar.xml ファイルを使用します。詳細については、「WebLogic Server RDBMS 永続性の使い方」で説明します。
サードパーティの永続性サービスでは、他のファイル フォーマットを使用してデプロイメント記述子をコンフィグレーションします。しかし、ファイルのタイプに関係なく、コンフィグレーション ファイルは weblogic-ejb-jar.xml の persistence-use 要素で参照しなければなりません。
注意: コンテナ管理による永続性 Bean では、接続プールの最大接続数を 1 より大きい値にコンフィグレーションします。WebLogic Server のコンテナ管理による永続性サービスでは、同時に 2 つの接続を取得しなければならない場合があるからです。
EJB で WebLogic Server RDBMS ベースの永続性サービスを使用するには、次の手順に従います。
WebLogic Server のツールを使用してこのファイルを作成した場合、ファイルの名前は weblogic-cmp-rdbms-jar.xml となります。このファイルをまったく新しく作成する場合は、異なる名前でファイルを保存できます。ただし、weblogic-ejb-jar.xml の persistence-use 要素が適切なファイルを参照していることを確認する必要があります。
weblogic-cmp-rdbms-jar.xml は、WebLogic Server RDBMS ベースの永続性サービスを使用して EJB の永続性デプロイメント記述子を定義します。
各 weblogic-cmp-rdbms-jar.xml ファイルでは、以下の永続性オプションを定義します。
主キーとは、エンティティ Bean をそのホーム内でユニークに識別するオブジェクトです。コンテナでは、エンティティ Bean の主キーを操作できなければなりません。個々のエンティティ Bean クラスは、その主キーに対して別のクラスを定義できますが、複数のエンティティ Bean クラスが同じ主キー クラスを使用できます。主キーは、エンティティ Bean のデプロイメント記述子で指定されます。コンテナ管理の永続性を利用するエンティティ Bean の主キー クラスを指定するには、エンティティ Bean クラスの 1 つまたは複数のフィールドに主キーをマップします。
すべてのエンティティ オブジェクトはそのホーム内で一意な ID を持ちます。2 つのエンティティ オブジェクトのホームと主キーが共通する場合、両者は同一のものと見なされます。クライアントはエンティティ オブジェクトのリモート インタフェースへの参照に対して getPrimaryKey() メソッドを呼び出して、そのホーム内でのエンティティ オブジェクトの ID を調べることができます。参照と関連付けられたオブジェクト ID は、参照が有効な間は変化しません。したがって getPrimaryKey() メソッドは、同じエンティティ オブジェクトの参照に対して呼び出されたときは常に同じ値を返します。エンティティ オブジェクトの主キーを知っているクライアントは、Bean のホーム インタフェースの findByPrimaryKey(key) メソッドを呼び出すことによって、エンティティ オブジェクトへの参照を取得することができます。
エンティティ Bean クラスでは、主キーを 1 つの CMP フィールドにマップできます。ejb-jar.xml ファイルのデプロイメント記述子、primkey-field 要素を使用して、主キーであるコンテナ管理フィールドを指定します。prim-key-class 要素は、主キー フィールドのクラスでなければなりません。
1 つまたは複数の CMP フィールドをラップする主キー クラス
主キー クラスを 1 つまたは複数のフィールドにマップすることができます。主キー クラスは public でなければならず、パラメータを付けない public コンストラクタを持たなければなりません。ejb-jar.xml ファイルのデプロイメント記述子、prim-key-class 要素を使用して、エンティティ Bean の主キー クラスの名前を指定します。このデプロイメント記述子要素にはクラス名だけを指定できます。主キー クラス内のすべてのフィールドは public として宣言する必要があります。クラス内のフィールドは、ejb-jar.xml ファイルの主キー フィールドと同じ名前を持たなければなりません。
エンティティ Bean が無名主キークラスを使用する場合、EJB をサブクラス化し java.lang.Integer 型の cmp-field をそのサブクラスに追加する必要があります。そのフィールドの自動主キー生成を有効にし、コンテナがフィールドの値を自動的に埋め、そのフィールドを weblogic-cmp-rdbms-jar.xml デプロイメント記述子のデータベース カラムにマップできるようにします。
最終的に、ejb-jar.xml ファイルを更新して元の EJB クラスではなく EJB サブクラスを指定するようにし、その Bean を WebLogic Server にデプロイします。
元の EJB を無名主キー クラスとともに使用した場合、デプロイメント時にWebLogic Server から次のエラー メッセージが表示されます。
EJB の ejb_name では、「不明な主キー クラス (<prim-key-class> == java.lang.Object)」をデプロイメント時に (java.lang.Object 以外のオブジェクトとして) 指定する必要があります。
WebLogic Server で主キーを使用する場合のヒントをいくつか挙げておきます。
WebLogic Server では、データベース カラムを cmp-field と cmr-field に同時にマップすることができます。その場合、cmp-field は読み込み専用となります。cmp-field が主キー フィールドの場合、cmp-field に対して setXXX メソッドを使うことによって create() メソッドが呼び出されたときにフィールドの値が設定されるように指定します。
エンティティ Bean では、コンテナ管理による永続性を利用して、エンティティ Bean インスタンスで永続データ アクセスを実行するメソッドが生成されます。生成されたメソッドでは、エンティティ Bean インスタンスと基盤のリソース マネージャの間でデータが転送されます。永続性は実行時にコンテナによって処理されます。コンテナ管理の永続性を利用する利点は、エンティティが格納されるデータ ストアからエンティティ Bean が論理的に独立することです。コンテナでは、論理的な関係と物理的な関係のマッピングが実行時に管理されると同時に、それらの参照整合性が管理されます。
永続フィールドと関係によって、エンティティ Bean の抽象永続性スキーマが構成されます。デプロイメント記述子は、エンティティ Bean でコンテナ管理による永続性が使用されることを示します。また、デプロイメント記述子は、データにアクセスするコンテナへの入力としても使用されます。
エンティティ Bean は、他の Bean と関係を持つことができます。それらの関係は、双方向の場合と一方向の場合があります。たとえば、後述する関係のマッピングの 3 つの型それぞれに対し、たとえば、一方向の 1 対 1 関係と双方向の 1 対 1 関係といったように、双方向と一方向のマッピングを持つことができます。
関係は、ejb-jar.xml ファイルと weblogic-cmp-rdbms-jar.xml ファイルで指定します。コンテナ管理フィールドのマッピングは、weblogic-cmp-rdbms-jar.xml ファイルで指定します。
WebLogic Server では、WebLogic RDBMS のコンテナ管理による永続性 (CMP) によって管理される以下の 3 種類の関係をマップできます。
WebLogic Server の 1 対 1 の関係では、1 つの Bean の外部キーが別の Bean の主キーに物理的にマップされます。主キーの詳細については、「主キーの使用」を参照してください。
次の例では、ある Employee Bean と別の Employee Bean (前者の上司) の間の 1 対 1 の関係を示します。
<weblogic-rdbms-relation>
<relation-name>employee-manager</relation-name>
<weblogic-relationship-role>
<relationship-role-map>
<column-map>
<foreign-key-column>manager-id
</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
<relationship-role-name>employee
</relationship-role-name>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
図 5-1 では、manager-id という foreign-key-column がテーブルにあります。これは、関係の従業員側の Bean がマップされるフィールドです。また、主キー カラム (key-column) を指す foreign-key-column (id) が、関係の上司側 Bean のマップ先テーブルにあります。
関係内のどちらかの Bean が複数のテーブルにマップされる場合は、外部キーまたは主キーを含むその Bean のテーブルも relationship-role-map 要素で指定する必要があります。relationship-role-map の詳細については、「relationship-role-map」を参照してください。
WebLogic Server の 1 対多の関係では、ある Bean の外部キーが別の Bean の主キーに物理的にマップされます。ただし 1 対多の関係では、外部キーが常に、関係の「多」サイドのロールに格納されます。1 対多の関係では、外部キーが常に、関係の「多」サイドの Bean に関連付けられます。つまり、次の例の relationship-role-name の仕様は冗長ですが、統一性のために含まれています。
次の例では、Employee Bean と Department Bean の間の 1 対多の関係を示します。
<weblogic-rdbms-relation>
<relation-name>employee-department</relation-name>
<weblogic-relationship-role>
<relationship-role-map>
<column-map>
<foreign-key-column>dept-id
</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
<relationship-role-name>employee
</relationship-role-name>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
図 5-2 では、dept-id という foreign-key-column がテーブルにあります。これは、関係の従業員側の Bean がマップされるフィールドです。また、主キー カラム (key-column) を指す foreign-key-column (id) が、関係の部門側 Bean のマップ先テーブルにあります。
WebLogic Server の多対多の関係には、結合テーブルの物理的なマッピングが伴います。結合テーブルの各行には、関係に関与するエンティティの主キーに対応する 2 つの外部キーが格納されます。
次の例では、「friend」という Bean と「employees」という Bean の間でマップされている多対多の関係を示します。
<weblogic-rdbms-relation>
<relation-name>friends</relation-name>
<table-name>FRIENDS</table-name>
<weblogic-relationship-role>
<relationship-role-name>friend
</relationship-role-name>
<relationship-role-name>
<<column-map>
<foreign-key-column>first-friend-id
</foreign-key-column>
<key-column>id</key-column>
</column-map
</relationship-role-map>
<weblogic-relationship-role>
<weblogic-relationship-role>
<relationship-role-name>second-friend
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>second-
friend-id</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
図 5-3 では、FRIENDS 結合テーブルに、first-friend-id および second-friend-id という 2 つのカラムがあります。各カラムには、他の従業員の友人である特定の従業員を示す外部キーが格納されています。employee テーブルの主キー カラム (key-column) は、id といいます。この例では、Employee Bean が 1 つのテーブルにマップされています。Employee Bean が複数のテーブルにマップされている場合、主キー カラム (key-column) を格納するテーブルを relationship-role-map で指定する必要があります。
一方向の関係は、一方向だけでナビゲートされます。たとえば、エンティティ A とエンティティ B が 1 対 1 の関係にあり、その方向がエンティティ A からエンティティ B への一方向である場合、エンティティ A はエンティティ B の存在を認識していますが、エンティティ B はエンティティ A の存在を認識していません。このタイプの関係は、ナビゲーションの始点となるエンティティ Bean で cmr-field デプロイメント記述子要素が指定され、対象のエンティティ Bean では関連する cmr-field 要素が指定されない場合に実装されます。
weblogic-cmp-rdbms-jar.xml ファイルの cmr-field 要素の値を設定します。詳細については、「3 つの EJB デプロイメント記述子ファイル」を参照してください。
双方向の関係は、双方向でナビゲートされます。このタイプのコンテナ管理の関係は、抽象永続性スキーマが同じ EJB-jar ファイルで定義されており、したがって同じコンテナ マネージャによって管理される Bean の間だけで成立します。たとえば、エンティティ A とエンティティ B が 1 対 1 で双方向の関係にある場合、両者は互いに認識し合います。
別の Bean と関係を持つ Bean が削除されると、コンテナはその関係を自動的に削除します。
WebLogic Server は、セッション Bean およびエンティティ Bean 用のローカル インタフェースをサポートしています。ローカル インタフェースを使用すると、エンタープライズ JavaBean は、同じ EJB コンテナ内で別のセマンティクスと実行コンテキストを使用して動作できます。通常、EJB は同じ EJB 内にあり、同じ Java 仮想マシン (JVM) 内で動作します。このようにして、EJB は通信にネットワークを使用せず、Java Remote Method Invocation-Internet Inter-ORB Protocol (RMI-IIOP) 接続によるオーバーヘッドの発生を防ぎます。
EJB とコンテナ管理による永続性の関係は、EJB のローカル インタフェースに基づいています。関係に関わる EJB には、ローカル インタフェースが必要です。ローカル インタフェース オブジェクトは、軽量の永続的オブジェクトです。これらのオブジェクトを使用すると、リモート オブジェクトを使用するよりも完成度の高いコーディングが可能になります。ローカル インタフェースも参照渡しです。ゲッターはローカル インタフェースに含まれています。
以前のバージョンの WebLogic Server では、リモート インタフェースに基づいて関係を指定できます。しかし、新しいコードでは、リモート インタフェースを使用する CMP の関係を使用しないことをお勧めします。
EJB コンテナを使用すると、ローカル クライアントが JNDI 経由でローカル ホーム インタフェースにアクセスできるようになります。ローカル インタフェースを参照するには、ローカルの JNDI 名が必要です。エンティティ Bean のローカル ホスト インタフェースを実装するオブジェクトは、EJBLocalHome オブジェクトと呼ばれます。weblogic-ejb-jar.xml ファイルの jndi-name、または local-jndi-name を指定できます。詳細については、「3 つの EJB デプロイメント記述子ファイル」を参照してください。
WebLogic Server の以前のバージョンでは、リモート インタフェースを返すために ejbSelect メソッドが使用されていました。現在では、クエリの結果をローカルまたはリモートのどちらのオブジェクトにマップするかを示す ejb-jar.xml ファイルの result-type-mapping 要素を指定します。
セッション Bean またはエンティティ Bean のローカル クライアントは、セッション Bean、エンティティ Bean、メッセージ駆動型 Bean など別の EJB です。ローカル クライアントは、同じ EAR ファイルに含まれており、かつその EAR ファイルがリモートでない限り、サーブレットでもかまいません。ローカル Bean のクライアントは、EAR またはスタンドアロン JAR の一部でなければなりません。
ローカル クライアントは、Bean のローカル インタフェースとローカル ホーム インタフェースを介してセッション Bean またはエンティティ Bean にアクセスします。コンテナは、Bean のローカル インタフェースとローカル ホーム インタフェースを実装するクラスを提供します。これらのインタフェースを実装するオブジェクトは、ローカル Java オブジェクトです。次の図は、ローカル クライアントとローカル インタフェースを持つコンテナを示しています。
WebLogic Server は、EJB 間でローカルの関係と一方向のリモート関係の両方をサポートしています。EJB が同じサーバ上にあり、同じ JAR ファイルを構成している場合、EJB はローカルの関係を持ちます。EJB が同じサーバ上にない場合、関係はリモートでなければなりません。ローカル Bean の関係では、その関係を実装するキーが複合キーである場合は複数カラムのマッピングを指定します。リモート Bean の場合は、リモート Bean の主キーが不明であるため、単一の column-map だけが指定されます。ロールが group-name だけを指定している場合、column-map は指定されません。関係がリモートの場合は group-name は指定されません。
ローカル インタフェースを格納するために、コンテナの構造が変更され、以下のものが追加されています。
EJB クエリ言語 (QL) は、コンテナ管理による永続性を利用する 2.0 エンティティ EJB のファインダ メソッドを定義する移植可能なクエリ言語です。このクエリ言語は SQL に似ており、クエリ内の 1 つまたは複数のエンティティ EJB オブジェクトまたはフィールドを選択する場合に使用します。CMP フィールドはデプロイメント記述子で宣言するので、findByPrimaryKey() 以外のすべてのファインダ メソッドのクエリをデプロイメント記述子で作成できます。findByPrimaryKey は、コンテナによって自動的に処理されます。EJB QL クエリの検索スペースは、ejb-jar.xml (コンテナ管理によるフィールドとその関連データベース カラムの Bean のコレクション) で定義された EJB のスキーマからなります。
デプロイメント記述子では、EJB QL クエリ文字列を使用して、EJB 2.0 のエンティティ Bean の各ファインダ クエリを定義する必要があります。WebLogic Query Language (WLQL) を EJB 2.0 エンティティ Bean で使用することはできません。WLQL は、EJB 1.1 のコンテナ管理による永続性で使用することを想定しています。WLQL および EJB 1.1 のコンテナ管理による永続性の詳細については、「EJB 1.1 CMP 用の WebLogic クエリ言語 (WLQL) の使用」を参照してください。
以前のバージョンの WebLogic Server を使用したことがあれば、コンテナ管理によるエンティティ EJB ではファインダ メソッド用に WLQL を使用できます。この節では、WLQL の一般的な処理についてのクイック リファレンスを提供します。WLQL の構文と EJB QL の構文の対応については、次の表を参考にしてください。
EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方
WebLogic Server には、標準の EJB QL の拡張であり、SQL に似た WebLogic QL という言語が用意されています。この言語はファインダ式と連携し、RDBMS の EJB オブジェクトのクエリ用に使用されます。query は、weblogic-ql 要素を使用して、weblogic-cmp-rdbms-jar.xml デプロイメント記述子に定義します。
ejb-jar ファイルには、weblogic-cmp-rdbms-jar.xml ファイルの weblogic-ql 要素に対応するクエリ要素が必要です。ただし、weblogic-cmp-rdbms-jar.xml のクエリ要素の値は、ejb-jar.xml のクエリ要素の値をオーバーライドします。
WebLogic クエリ言語 (WL QL) の拡張機能である ORDERBY は、Finder メソッドと連携して、選択における CMP フィールドの選択順序を指定するキーワードです。
図5-5 id による順序付けを指定する WebLogic QL ORDERBY 拡張機能
ORDERBY
SELECT OBJECT(A) from A for Account.Bean
ORDERBY A.id
次のように ORDERBY に昇順 [ASC] か降順 [DESC] か指定することもできます。
図5-6 id による順序付けを指定する WebLogic QL ORDERBY 拡張機能 (昇順/降順指定)
ORDERBY <field> [ASC|DESC], <field> [ASC|DESC]
SELECT OBJECT(A) from A for Account.Bean, OBJECT(B) from B for Account.Bean
ORDERBY A.id ASC; B.salary DESC
注意: ORDERBY は、すべてのソート処理を DBMS に委ねます。このため、取得される結果の順序は、実行中の Bean の基盤となる特定の DBMS によって異なります。
WebLogic Server では、EJB QL のサブクエリの次のような機能をサポートしています。
WebLogic QL とサブクエリの関係は、SQL クエリとサブクエリの関係に似ています。WebLogic QL のサブクエリは、外部 WebLogic QL クエリの WHERE 句内で使用してください。若干の例外はありますが、サブクエリの構文は WebLogic QL クエリのものとほぼ同じです。
WebLogic QL を指定する手順については、「EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方」を参照してください。この手順に従って、SELECT 文で次の例のようにサブクエリを指定します。
次のクエリは、成績順位をもとに平均以上の生徒を選択しています。
SELECT OBJECT(s) FROM studentBean AS s WHERE s.grade > (SELECT AVG(s2.grade) FROM StudentBean AS s2)
上記クエリの例の中で、サブクエリ、「SELECT AVG(s2.grade) FROM StudentBean AS s2」が EJB QL クエリと同じ構文を備えている点に注意してください。
サブクエリをネストすることもできます。この深さは、基盤データベースのネストの許容範囲によって制限されます。
WebLogic QL クエリでは、メイン クエリとそのすべてのサブクエリの FROM 句で宣言される識別子がユニークでなければなりません。これはつまり、サブクエリの内側で前にローカルに宣言した識別子をそのサブクエリで再び宣言することはできないということです。
たとえば、次の例は無効です。 Employee Bean がクエリとサブクエリの双方で emp として宣言されています。
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp.salary) FROM
EmployeeBean AS emp WHERE employee.state=MA)
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp2.salary) FROM
EmployeeBean AS emp2 WHERE emp2.state=MA)
この例では、サブクエリの Employee Bean がメインクエリの Employee Bean と異なる識別子になるように正しく宣言されています。
WebLogic QL サブクエリの戻り値の型は、次のような各種の型のいずれかになります。
WebLogic Server は、cmp-field で構成されている戻り値型をサポートしています。サブクエリから返される結果は、1 つの値または値の集合から構成されている可能性があります。cmp-field 型の値を返すサブクエリの例を次に示します。
SELECT emp.salary FROM EmployeeBean AS emp WHERE emp.dept = 'finance'
このサブクエリは、財務部門の従業員の給料すべてを選択しています。
WebLogic Server は、ある cmp-field に対する集約から構成されている戻り値型をサポートしています。集約は必ず1 つの値から構成されるので、ここで返される値も常に 1 つの値になります。cmp-field の集約 (MAX) の型の値を返すサブクエリの例を次に示します。
SELECT MAX(emp.salary) FROM EmployeeBean AS emp WHERE emp.state=MA
このサブクエリは、マサチューセッツで最高額の給料を一つだけ選択しています。
集約関数の詳細については、「集約関数の使用」を参照してください。
WebLogic Server は、単純主キーを持つ 1 つのcmp-bean で構成されている戻り値型をサポートしています。
単純主キーを持つ Bean 型の値を返すサブクエリの例を次に示します。
SELECT OBJECT(emp) FROM EMployeeBean As emp WHERE emp.department.budget>1,000,000
このサブクエリは、$1,000,000 以上の予算がある部門の全従業員のリストを返します。
注意: 複合主キーを持つ Bean はサポートされていません。複合主キーを持つ Bean をサブクエリの戻り値の型として指定しようとしても、クエリをコンパイルする時点で失敗に終わります。
サブクエリを比較演算子および算術演算子のオペランドとして使用します。WebLogic QL では、以下の演算子のオペランドとしてサブクエリをサポートしています。
[NOT]IN 比較演算子は、左側のオペランドが右側のサブクエリ オペランドのメンバーかどうか検査します。
サブクエリが NOT IN オペレータの右側のオペランドとなっている例を次に示します。
SELECT OBJECT(item)
FROM ItemBean AS item
WHERE item.itemId NOT IN
(SELECT oItem2.item.itemID
FROM OrderBean AS orders2, IN(orders2.orderItems)oIttem2
メイン クエリの NOT IN 演算子では、サブクエリによって返された集合の中に含まれていない品目すべてを選択しています。したがって、最終的に、メインクエリが未注文の品目すべてを選択します。
[NOT]EXISTS 比較演算子は、サブクエリ オペランドによって返された集合が空かどうか検査します。
サブクエリが NOT EXISTS オペランドのオペランドとなっている例を次に示します。
SELECT (cust) FROM CustomerBean AS cust
WHERE NOT EXISTS
(SELECT order.cust_num FROM OrderBean AS order
WHERE cust.num=order_num)
これは、相関サブクエリを用いたクエリの一例となっています。詳細については「相関サブクエリと非相関サブクエリ」を参照してください。次のクエリは、注文していない顧客をすべて返します。
SELECT (cust) FROM CustomerBean AS cust
WHERE cust.num NOT IN
(SELECT order.cust_um FROM OrderBean AS order
WHERE cust.num=order_num)
右側のサブクエリ オペランドが 1 つの値を返す場合、比較の算術演算子を使用できます。右側のサブクエリが複数の値を返す場合には、サブクエリの前に ANY または ALL 修飾子が必要です。
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered =
(SELECT MAX (subOItem.quantityOrdered)
FROM Order ItemBean AS subOItem
WHERE subOItem,item itemID = ?1)
AND oItem.item.itemId = ?1
特定の品目 ID に対し、サブクエリはその品目の注文の最高数を返します。サブクエリが返している集合が、「=」演算子に必要な 1 つの値となっている点に注意してください。
メイン クエリの「=」演算子では、これと同じ品目 ID に対し、どの注文の注文品目の注文量がサブクエリから返された注文の最高数に等しいかを調べています。最終的に、特定の品目について注文が最高数である OrderBean をクエリが返します。
右側のサブクエリ オペラントが複数の値を返す場合には、算術演算子と ANY または ALL と組み合わせて使用します。
ANY または ALL を使用したサブクエリの例を次に示します。
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered > ALL
(SELECT subOItem.quantityOrdered
FROM OrderBean AS suborder IN (subOrder.orderItems)subOItem
WHERE subOrder,orderId = ?1)
サブクエリは、特定の注文 ID に対し、その注文 ID で注文された各品目の注文数の集合を返します。メイン クエリの「>」ALL 演算子は、各品目の注文数がサブクエリから返された集合内のすべての値を上回っている注文すべてを探しています。最終的にメインクエリは、入力された注文に対して、全品目で注文数を上回っている注文すべてを返します。
サブクエリが複数の値を持つ結果を返す可能性があるため、「>」演算子ではなく、「>」ALL 演算子が使用されている点に注意してください。
WebLogic Server は、相関サブクエリと非相関サブクエリの双方をサポートしています。
非相関サブクエリは、その外部クエリとは独立に評価されます。非相関サブクエリの例を次に示します。
SELECT OBJECT(emp) FROM EmployeeBean AS emp
WHERE emp.salary>
(SELECT AVG(emp2.salary) FROM EmployeeBean AS emp2)
この非相関サブクエリの例では、平均以上の給与の従業員を選択しています。この例では、算術演算子「>」を使用します。
相関サブクエリは、その外部クエリの値がサブクエリでの評価に関与するサブクエリです。相関サブクエリの例を次に示します。
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
この相関サブクエリの例では、最後に出荷された 10 個の注文を選択しています。NOT IN 演算子を使用しています。
注意: 相関クエリでは、非相関クエリより処理オーバーヘッドが大きくなる可能性があることに注意してください。
サブクエリ内で DISTINCT 句を使用すると、そのサブクエリで生成される SELECT DISTINCT 内で SQL SELECT DISTINCT を使うことができます。サブクエリでの DISTINCT 句の使い方は、メインクエリでの使い方とは異なります。 メインクエリ内の DISTINCT 句は EJB コンテナによって施されますが、サブクエリ内の DISTINCT 句は生成された SQL の SQL SELECT DISTINCT によって施されます。サブクエリの DISTINCT 句の例を示します。
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
WebLogic Server では、WebLogic QL の集約関数をサポートしています。これらは、WHERE 句のようなクエリの一部ではなく、SELECT 句の対象として使われるのみです。集約関数の振る舞いは SQL 関数と似ています。これらの関数は、クエリの WHERE 条件によって返される Bean の外側で評価されます。
WebLogic QL を指定する手順については、「EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方」を参照してください。これに従って、次の表のサンプルのように、集約関数を指定した SELECT 文を記述します。
次の手順で、ResultSet として集約関数を返すことができます。
WebLogic Server は、複数カラム クエリの結果を java.sql.ResultSet の形式で返す、 ejbSelect() クエリをサポートしています。この機能を支援するために、WebLogic Serverでは、次のように SELECT 句の対象フィールドをカンマで区切って指定できるようになりました。
SELECT emmp.name, emp.zip FROM EmployeeBean AS emp
このクエリは、従業員の名前と郵便番号の値をカラムとしその数行を含んだ java.sqlResultSet を返します。
WebLogic QL を指定する手順については、「EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方」を参照してください。「EJB QL の EJB 2.0 WebLogic QL 拡張機能の使い方」の手順に従って、上記のクエリの例で WebLogic QL を指定したように、ResultSet を指定するクエリを記述します。また、同様にこれに従って、下記の表のサンプルで示すように、集約クエリを指定した SELECT 文を記述します。
EJB QL で作成される ResultSet は、cmp-field の値、または、cmp-field 値の集合だけを返します。 Bean を返すことはできません。
さらに、cmp-field と集約関数を組み合わせた場合、下記のサンプルに示すような強力なクエリを作成できます。
次の行 (Bean) は、各地区の従業員の給与を示しています。
表5-1 カリフォルニア市内の従業員の給与を示す CMP フィールド
次の SELECT 文のクエリでは、ResultSet、集約関数 (AVG) とともに、GROUP BY 文と ORDER BY 文を使用し、複数カラム クエリの結果を降順ソートを使って取り出します。
SELECT e.location, AVG(e.salary)
FROM Finder EmployeeBean AS e
GROUP BY e.location
ORDER BY 2 DESC
このクエリは、各地区の従業員の平均給与を降順で示します。2 という数字は、ORDERBY ソートを SELECT 文の 2 番目の項目で実行することを意味しています。GROUP BY 句 は、e.location 属性に一致する従業員の平均給与を指定しています。
注意: ResultSet を返すクエリ内で ORDERBY の引数として使用できるのは整数だけです。WebLogic Server では、Bean を返すファインダ、または ejbselect() 内で ORDERBY の引数として整数を使用することはできません。
EJB QL クエリに、(明示的クロス製品とは対照的な) 暗黙的クロス製品が含まれる場合、EJB QL クエリは結果として空の値を返すことができます。
SELECT OBJECT(e) FROM EmployeeBean AS e WHERE e.name LIKE 'Joe' OR e.acct.balance < 100
このクエリは AccountEJB を参照していますが、AccountEJB は FROM 句にリストされていません。このクエリの結果は、FROM 句に明示的にリストされた AccountEJB のあるクエリの場合と同じです。
EJB QL のコンパイラ エラー メッセージでは、クエリのどの部分にエラーが生じているのかを特定できるビジュアルな表示が用意され、コンパイルごとに複数のエラーを報告できます。
エラーが報告されると、EJB QL は問題のある場所を記号 =>> <<= で囲んで示します。これらの記号は、次に示すサンプルのコンパイラ エラー報告では赤色で強調されています。
ERROR: Error from appc: Error while reading 'META-INF/FinderEmployeeBeanRDBMS.xml'. The error was:
Query:
EJB Name: FinderEmployeeEJB
Method Name: findThreeLowestSalaryEmployees
Parameter Types: (java.lang.String)
Input EJB Query: SELECT OBJECT(e) FROM FinderEmployeeBean e WHERE f.badField = '2' O
R (e.testId = ?1) ORDERBY e.salary
SELECT OBJECT(e ) FROM FinderEmployeeBean e
WHERE =>> f.badField <<= = '2' OR ( e.testId = ?1 ) ORDERBY e.salary
Invalid Identifier in EJB QL expression:
Problem, the path expression/Identifier 'f.badField' starts with an identifier: 'f'. The identifier 'f', which can be either a range variable identifier or a collection member identifier, is required to be declared in the FROM clause of its query or in the FROM clause of a parent query.
'f' is not defined in the FROM clause of either its query or in any parent query.
Action, rewrite the query paying attention to the usage of 'f.badField'.
クエリに複数のエラーが含まれていた場合、EJB QL では、1 回のコンパイル後にこれらのエラーを複数個報告できるようになりました。これまでは、コンパイラが報告できるエラーはコンパイル 1 回につき 1 つだけでした。後続のエラーの報告には、再コンパイルが必要でした。
注意: コンパイラが 1 回のコンパイル後にすべてのエラーを報告する保証はありません。
動的クエリを使用すると、各自のアプリケーション コードでプログラム的にクエリを作成したり実行できるようになります。たとえば、クエリを使ってRDBMS に対して EJB オブジェクトの情報を要求できます。動的クエリの使用には、次のような利点があります。
次のコード例では、動的クエリをどのように実行するかを示します。
InitialContext ic=new InitialContext();
FooHome fh=(FooHome)ic.lookup("fooHome");
QueryHome qh=(QueryHome)fh;
Sring ejbql="SELECT OBJECT(e)FROM EmployeeBean e WHERE e.name='rob'"
Query query=qh.createQuery();
query.setMaxElements(10)
Collection results=query.find(ejbql);
Oracle DBMS の BLOB および CLOB DBMS カラムのサポート
WebLogic Server は、Oracle Binary Large Object (BLOB) および Character Large Object (CLOB) DBMS カラムを EJB CMP でサポートしています。BLOB および CLOB は、大きなオブジェクトを効率的に保存したり、検索したりするためのデータ型です。CLOB は文字オブジェクトで、BLOB は大きなバイト配列に変換される画像などのバイナリまたはシリアライズ可能オブジェクトです。
BLOB および CLOB は、文字列変数である OracleBlob または OracleClob の値を BLOB または CLOB カラムにマップします。WebLogic Server は、CLOB をデータ型 java.lang.string にしかマップしません。現時点では、char 配列を CLOB カラムにマップすることはできません。
BLOB/CLOB サポートを有効にするには次の手順に従います。
BLOB/CLOB オブジェクトのサイズが大きいため、BLOB または CLOB を使用すると、パフォーマンスが低下する場合があります。
次の XML コードは、weblogic-cmp-rdbms-jar-xml ファイルの dbms-column 要素を使用して BLOB オブジェクトを指定する方法を示しています。
<field-map>
<cmp-field>photo</cmp-field>
<dbms-column>PICTURE</dbms-column>
<dbms_column-type>OracleBlob</dbms-column-type>
</field-map>
次の XML コードは、weblogic-cmp-rdbms-jar-xml ファイルの dbms-column 要素を使用して CLOB オブジェクトを指定する方法を示しています。
<field-map>
<cmp-field>description</cmp-field>
<dbms-column>product_description</dbms-column>
<dbms_column-type>OracleClob</dbms-column-type>
</field-map>
カスケード削除メカニズムは、エンティティ Bean オブジェクトを削除する場合に使用します。カスケード削除を特定の関係に対して指定した場合、エンティティ オブジェクトの有効期間は他方のエンティティ オブジェクトに依存します。指定できるカスケード削除は 1 対 1 関係と 1 対多関係についてであり、多対多関係については指定できません。cascade delete() メソッドは WebLogic Server の削除機能を使用し、database cascade delete() メソッドでは、基盤データベースに組み込まれているカスケード削除のサポートを使用するよう WebLogic Server に指示します。
この機能を有効にするには、Bean コードを再コンパイルしてデプロイメント記述子の変更を有効にする必要があります。
カスケード削除を有効にするには、以下の 2 つの方法のいずれかに従います。
cascade delete() メソッドでは、WebLogic Server を使用してオブジェクトを削除します。削除したエンティティに関連するエンティティ Bean に対して cascade delete 要素が指定されている場合、カスケード削除が行われ、関連するエンティティ Bean もすべて削除されます。
カスケード削除を指定するには、ejb-jar.xml デプロイメント記述子要素の cascade-delete 要素を使用します。これはデフォルト メソッドです。データベースの設定には変更を加えません。WebLogic Server は、カスケード削除が行われる場合に削除対象のエンティティ オブジェクトをキャッシュします。
カスケード削除を指定するには、ejb-jar.xml ファイルの cascade-delete 要素を使用します。
<ejb-relation>
<ejb-relation-name>Customer-Account</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>Account-Has-Customer
</ejb-relationship-role-name>
<multiplicity>one</multiplicity>
<cascade-delete/>
</ejb-relationship-role>
</ejb-relation>
注意: この cascade delete() メソッドは、ejb-relation 要素に含まれる一方の ejb-relationship-role 要素に対してのみ指定できます。この場合、同じ ejb-relation 要素の他方の ejb-relationship-role 要素に値が one の multiplicity 属性が指定されている必要があります。
database cascade delete() メソッドを使用すると、アプリケーションはデータベースに組み込まれているカスケード削除のサポートを利用できるので、パフォーマンスの向上を見込めます。db-cascade-delete 要素を weblogic-cmp-rdbms-jar.xml ファイルにまだ指定していない場合、データベースのカスケード削除機能を有効にしないでください。 有効にすると、データベースで不正な結果が生成されます。
weblogic-cmp-rdbms-jar.xml ファイルのdb-cascade-delete 要素では、基盤となる DBMS の組み込みカスケード削除機能をカスケード削除処理で使用するよう指定します。この機能はデフォルトでは無効になっているので、EJB コンテナは Bean ごとに SQL DELETE 文を発行してカスケード削除に関連する Bean を削除します。
db-cascade-delete 要素を weblogic-cmp-rdbms-jar.xml に指定する場合、cascade-delete 要素を ejb-jar.xml に指定する必要があります。
db-cascade-delete を有効にすると、データベース テーブルの追加設定が必要になります。たとえば、dept がデータベースに削除された場合、Oracle データベース テーブルの次の設定によって、すべての従業員がカスケード削除されます。
図5-10 カスケード削除用の Oracle テーブルの設定
CREATE TABLE dept
(deptno NUMBER(2) CONSTRAINT pk_dept PRIMARY KEY,
dname VARCHAR2(9) );
CREATE TABLE emp
(empno NUMBER(4) PRIMARY KEY,
ename VARCHAR2(10),
deptno NUMBER(2) CONSTRAINT fk_deptno
REFERENCES dept(deptno)
ON DELETE CASCADE );
トランザクションによる更新内容は、トランザクションで発行されたクエリ、ファインダ、および ejbSelect の結果に反映させる必要があります。この要件に従うとパフォーマンスが低下する場合があるので、weblogic-cmp-rdbms-jar.xml の include-updates 要素により、Bean に関するクエリを実行する前にキャッシュをフラッシュするように指定することができます。
このオプションが無効の場合、現在のトランザクションの結果はクエリに反映されません。このオプションを有効にした場合 (デフォルト)、コンテナはキャッシュされているトランザクションの変更をすべてデータベースに書き込んでから新しいクエリを実行します。この方法により、変更が結果に表示されます。
WebLogic Server 8.1 より前のリリースでは、include-updates のデフォルト設定は False でした。J2EE に準拠するため、このデフォルト設定は WebLogic Server 8.1 から True に変更されています。
次のコード サンプルでは、include-updates を True に設定することにより、トランザクション結果がクエリに反映されるように指定しています。
図5-11 トランザクションの結果をクエリに反映するための指定
<weblogic-query>
<query-method>
<method-name>findBigAccounts</method_name>
<method-params>
<method-param>double</method-param>
</method-params>
</query-method>
<weblogic-ql>WHERE BALANCE>10000 ORDERBY NAME</weblogic-ql>
<include-updates>True</include-updates>
</weblogic-query>
この機能を使用するかどうかは、データを最新かつ一貫性のあるものにしておくことよりもパフォーマンスを重視するかどうかで判断します。include-updates を False に設定すると最大限のパフォーマンスが得られ、True に設定すると、最新かつ一貫性のあるデータが得られます。
同時方式は、EJB コンテナがエンティティ Bean への同時アクセスをどのように管理するかを指定するものです。Database オプションが WebLogic Server のデフォルトの同時方式ですが、その Bean でどのような同時アクセスが必要になるかによって、別のオプションを指定したくなるでしょう。WebLogic Serverでは次の同時方式オプションを提供しています。
|
Bean がトランザクションに関連付けられている場合、キャッシュされたエンティティ EJB インスタンスを排他的にロックする。EJB インスタンスに対するリクエストは、トランザクションが完了するまでブロックされます。このオプションは、WebLogic Server バージョン 3.1 〜 5.1 までのデフォルトのロック動作。 |
|
|
エンティティ EJB に対するリクエストのロックを基盤のデータストアに委ねる。WebLogic Server は、独立したエンティティ Bean を割り当て、ロックとキャッシングをデータベースが処理できるようにする。これは現在のデフォルト オプション。 |
|
|
トランザクションの実行中、EJB コンテナあるいはデータベースでロックを行わない。EJB コンテナはトランザクションをコミットする前に、そのトランザクションで更新したデータがどれも変化していないことを確認する。更新データのどれかが変わっていた場合、EJB コンテナはトランザクションをロールバックする。 |
|
|
読み込み専用エンティティ Bean のみで使用される。トランザクションごとに新たなインスタンスをアクティブ化する。これにより、リクエストは並列処理される。WebLogic Server は、read-timeout-seconds パラメータを基に、ReadOnly Bean に対して ejbLoad() を呼び出す。 |
read-write EJB の場合、Exclusive、Database、Optimistic 同時方式を使えます。WebLogic Server では、各トランザクションの最初に EJB データをキャッシュにロードするか、または、「トランザクション間のキャッシュを使用した ejbStore() の呼び出しの制限」のようになります。トランザクションが正常にコミットしたとき、WebLogic Server は ejbStore() を呼び出します。
EJB で使用するロック メカニズムを指定するには、weblogic-ejb-jar.xml の concurrency-strategy デプロイメント パラメータを設定します。concurrency-strategy は個々の EJB レベルで設定するので、EJB コンテナ内でロック メカニズムが混在することがあります。
次の例は weblogic-ejb-jar.xml からの抜粋ですが、ある EJB に同時方式を設定する手順を示しています。この XML コード例では、デフォルトのロック メカニズム、Database を指定しています。
<entity-descriptor>
<entity-cache>
...
<concurrency-strategy>Database</concurrency-strategy>
</entity-cache>
...
</entity-descriptor>
concurrency-strategy を指定しない場合、WebLogic Server はエンティティ EJB インスタンスに対しデータベース ロックを実行します。
Exclusive 同時方式は、EJB データへのアクセスの信頼性を高め、ejbLoad() を不必要に呼び出して EJB インスタンスの永続フィールドをリフレッシュするのを防ぎます。しかし、排他的ロック メカニズムは、EJB のデータへの同時アクセスに対しては最良のモデルとはなりません。いったんクライアントが EJB インスタンスをロックすると、他のクライアントは、永続フィールドを読もうとしているだけであっても、EJB のデータからブロックされてしまうからです。
WebLogic Server の EJB コンテナは、エンティティ EJB インスタンスに対して排他的ロック メカニズムを使用します。クライアントが EJB または EJB メソッドをトランザクションに関与させると、WebLogic Server はそのトランザクションの間そのインスタンスを排他的にロックします。同じ EJB またはメソッドを要求する他のクライアントは、現在のトランザクションが完了するまでブロックされます。
Exclusive 同時方式を使用するトランザクションのデッドロックを回避する
スループットが高い状況では、カスケード削除を実行するトランザクションが、カスケード削除を実行しないトランザクションと同じ Bean にアクセスする必要がある場合に、排他的な同時方式を使用するトランザクションでデッドロックが発生する可能性があります。
このようなデッドロックは、weblogic-cmp-rdbms-jar.xml デプロイメント記述子ファイルの lock-order 要素を使用して回避できます。
注意: この機能は、関与しているトランザクションの 1 つがカスケード削除を実行する場合にのみ意味を持ちます。
2 つのトランザクション T1 および T2 があり、双方とも Exclusive 同時方式を使用しています。T1 ではカスケード削除も指定していますが、T2 では指定していません。
2 つのエンティティ Bean、B1 および B 2 があります。
lock-order を設定していないデッドロックのシナリオ
Bean に lock-order を指定すると、シナリオは変わります。Bean は、lock-order 値に従ってロックされます。
B1 の lock-order が 1、B2 の lock-order が 2 に設定されているとします。
カスケード削除の詳細については、「カスケード削除メソッド」を参照してください。lock-order 要素の詳細については、「lock-order」を参照してください。
Database 同時方式は WebLogic Server におけるデフォルトであり、EJB 1.1 と EJB 2.0 で推奨されているメカニズムです。データベース ロックによって、エンティティ EJB の同時アクセスの処理速度が向上します。WebLogic Server コンテナでは、ロック サービスを基盤となるデータベースに任せます。排他的ロックとは異なり、基盤データ ストアはより高い粒度で EJB データをロックでき、またデッドロックを検出することができます。
データベース ロック メカニズムでは、EJB コンテナが引き続きエンティティ EJB クラスのインスタンスをキャッシュします。しかし、コンテナはトランザクション間の EJB インスタンスの中間状態をキャッシュしません。代わりに、WebLogic Server は、トランザクションの開始時に各インスタンスに対して ejbLoad() を呼び出して、最新の EJB データを取得します。続いて、データのコミット リクエストがデータベースに送られます。このためデータベースは、EJB データのロック管理とデッドロック検出をすべて処理します。
基盤となるデータベースにロックを任せることで、エンティティ EJB データへの同時アクセスのスループットを上げつつ、デッドロックの検出も実行できます。しかし、データベース ロックを使用するには、基盤となるデータベースのロック方式に関するより詳細な知識が必要となります。この結果、EJB の異なるシステム間での移植性が低下する可能性があります。
caching-between-transactions 要素を True に設定し、Optimistic ではなく Database 同時方式を使う場合、コンパイラは cache-between-transactions を無効にすべきであることを伝える警告を発行します。この条件が揃っている場合、WebLogic Server は caching-between-transactions を自動的に無効にします。
Optimistic 同時方式は、トランザクションの実行中、EJB コンテナまたはデータベースでどのようなロックも行いません。このオプションを指定した場合、EJB コンテナはあるトランザクションが更新したデータが変化していないことを確かめます。トランザクションのコミット前にフィールドをチェックするという手段によって、「効率的な更新」を実行します。
注意: EJB コンテナは、Blob/Clob フィールドのオプティミスティックな同時実行性をチェックしません。これを回避するには、バージョン チェックまたはタイムスタンプ チェックを行います。
データの有効性を確認するため、weblogic-cmp-rdbms-jar.xml ファイルの verify-columns デプロイメント記述子要素を設定することによってオプティミスティックなチェックを有効化します。Optimistic 同時方式を使用する場合、verify-columns 要素によって有効性をチェックするテーブル カラムが指定されます。
注意: デフォルトでは、この機能ではトランザクション間のキャッシングは有効でありません。明示的に有効にする必要があります。手順については、「トランザクション間のキャッシュを使用した ejbStore() の呼び出しの制限」を参照してください。
WebLogic Server では、読み込み専用エンティティ Bean に対する同時アクセスをサポートしています。このキャッシング方式では、トランザクションごとに 1 つの読み込み専用エンティティ Bean インスタンスをアクティブ化することでリクエストを並行に処理できるようにします。
これまでは、読み込み専用エンティティ Bean には排他的ロック同時方式が用いられていました。この方式では、Bean がトランザクションに関連付けられている場合、キャッシュされたエンティティ Bean インスタンスを排他的にロックします。このエンティティ Bean に対する他のリクエストは、トランザクションが完了するまでブロックされます。
データベースからの読み込みを避け、WebLogic Server では キャッシュ中の既存インスタンスからEJB 2.0 CMP Bean の状態をコピーします。このリリースでは、ReadOnly オプションが読み込み専用エンティティ Bean のデフォルトの同時方式です。
アプリケーションレベルまたはコンポーネントレベルにおいて、読み込み専用エンティティ Bean のキャッシングを指定することができます。
読み込み専用エンティティ Bean のキャッシングを有効にするには、次の手順に従います。
WebLogic Server は、デプロイメント記述子で設定する read-timeout 要素によって、読み込み専用エンティティ Bean を引き続きサポートします。ReadOnly オプションが concurrency strategy 要素で選択され、read-timeout-seconds 要素が weblogic-ejb-jar.xml ファイルで設定されている場合、読み込み専用エンティティ Bean が呼び出されると、WebLogic Server はキャッシュされているデータが read-timeout 設定よりも古いかどうかを確認します。古い場合は、Bean の ejbLoad が呼び出されます。それ以外の場合は、キャッシュされているデータが使用されます。したがって、以前のバージョンの読み込み専用エンティティ Bean はこのバージョンの WebLogic Server で機能します。
read-only 同時方式を使用するエンティティ EJB は、以下の制限に従わなければなりません。
この Bean の基盤データは外部ソースによって更新されるため、ejbLoad() の呼び出しはデプロイメント パラメータの read-timeout-seconds によって制御されます。
|

|

|
| Contact BEA Site Map Feedback Privacy Copyright © BEA Systems, Inc. All rights reserved. | ||