

|
|
|
|
|
|
| | | |
クラスタの機能とインフラストラクチャ
以下の節では、クラスタ化されたオブジェクトと HTTP セッション ステートをサポートするために WebLogic Server クラスタで使われるインフラストラクチャについて説明します。
概要
また、WebLogic Server クラスタ内で実行される API とサービスで利用可能な一般的な機能、ロード バランシングとフェイルオーバについても説明します。これらの内容を理解しておくことは、Web アプリケーションのニーズを満たすように WebLogic Server クラスタをプランニングし、コンフィグレーションする際に重要となります。
クラスタ内のサーバの通信
クラスタ内の WebLogic Server インスタンスは、2 つの基本的なネットワーク技術を利用して互いに通信します。
WebLogic Server が IP マルチキャストとソケット通信を使用する方法は、管理者がクラスタを計画し、コンフィグレーションする方法と直接関係しています。
IP マルチキャストを使用した 1 対多通信
IP マルチキャストは、複数のアプリケーションが指定された IP アドレスとポート番号に「サブスクライブ」して、メッセージをリスンできるようにする単純なブロードキャスト技術です。マルチキャスト アドレスは、範囲が 224.0.0.0 ~ 239.255.255.255 の IP アドレスです。
IP マルチキャストはアプリケーションに対してメッセージをブロードキャストする簡単な方法ですが、メッセージが実際に届くことは保証されていません。アプリケーションのローカル マルチキャスト バッファがいっぱいの場合、新規のマルチキャスト メッセージをそのバッファに書き込めないので、アプリケーションにはメッセージが「届いた」ことがわかりません。この制約のため、WebLogic Server では、IP マルチキャストに対してブロードキャストされたメッセージが届かない可能性を考慮しています。
WebLogic Server は、クラスタ内のサーバ インスタンス間の 1 対多通信で IP マルチキャストを使用します。次の通信が対象です。
クラスタのプランニングとコンフィグレーションの意味
マルチキャストは、障害の検出とクラスタワイドの JNDI ツリーの保守に関わる重要な機能を制御するので、クラスタのコンフィグレーションもマルチキャスト通信との基本的なネットワーク トポロジ インタフェースも重要ではありません。WebLogic Server クラスタのコンフィグレーションとプランニングに際しては、常に以下の規則を考慮してください。
WAN クラスタのマルチキャスト要件
ほとんどのデプロイメントでは、クラスタ化されたサーバを 1 つのサブネットに制限すると、マルチキャスト メッセージが確実に転送されます。ただし、特別なケースでは、WebLogic Server クラスタをワイド エリア ネットワーク(WAN)内の複数のサブネット間に分散することもできます。この方法は、クラスタ化されたデプロイメント内で冗長性を高めたり、地理的に広い範囲でクラスタを分散したりする場合に適しています。
クラスタを WAN(または複数のサブネット)上に分散する場合、マルチキャスト メッセージがクラスタ内のすべてのサーバに必ず転送されるようにネットワーク トポロジをプランニングおよびコンフィグレーションしなければなりません。特に、ネットワークが以下の要件を満たす必要があります。
注意: WAN 上に WebLogic Server クラスタを分散するには、上記のマルチキャスト要件を満たす以外にも、ネットワーク機能を追加しなければならない場合があります。たとえば、不要なネットワーク ホップを経由せずにクライアント リクエストを最短経路でサーバに送るには、ロード バランシング ハードウェアをコンフィグレーションする必要があります。
ファイアウォールがマルチキャスト通信を遮断することがある
マルチキャスト トラフィックをファイアウォール内にトンネリングすることは可能ですが、WebLogic Server クラスタではお勧めしません。各 WebLogic Server クラスタは、Web アプリケーションのクライアントに対して 1 つまたは複数の別個のサービスを提供する論理単位として扱う必要があります。こうした論理単位は、異なるセキュリティ ゾーン間で分割しないでください。さらに、IP トラフィックの速度低下や中断につながる可能性のある技術は、ハートビートが届かないために誤ってエラーを発生させるので、WebLogic Server クラスタを分裂させることがあります。
WebLogic Server クラスタ専用のマルチキャスト アドレスを使用する
複数の WebLogic Server クラスタが 1 つの IP マルチキャスト アドレスとポート番号を共有することは可能ですが、他のアプリケーションは同じアドレスに対してブロードキャストしたり、サブスクライブしたりしてはなりません。他のアプリケーションと 1 つのマルチキャスト アドレスを「共有」すると、クラスタ化されたサーバが不要なメッセージを生成することになり、システムのオーバーヘッドが発生します。
また、マルチキャスト アドレスの共有は、IP マルチキャスト バッファの過負荷と、WebLogic Server ハートビート メッセージの送信遅延につながる可能性があります。ハートビートが適切なタイミングで受信されないため、こうした遅延によって、WebLogic Server インスタンスがエラーとしてマークされる可能性があります。
こうした理由から、WebLogic Server クラスタ用には専用のマルチキャスト アドレスを割り当てて、そのアドレスを使用するすべてのクラスタのトラフィックをそのアドレスでブロードキャストできるようにします。
マルチキャスト ストームが発生する場合
クラスタ内のサーバ インスタンスが受信メッセージを適切なタイミングで処理しない結果として、NAK メッセージやハートビートの再転送などを含めて、ネットワーク トラフィックが増大する可能性があります。ネットワーク上でマルチキャスト パケットが繰り返し転送される現象はマルチキャスト ストームと呼ばれます。この現象により、ネットワークとそれに接続されたステーションの負荷が増加し、ひいては末端のステーションの停止または障害に至る可能性があります。マルチキャスト バッファのサイズを大きくすると、通知の転送率と受信率が改善されることによってマルチキャスト ストームを防止できる可能性があります。
クラスタ内のサーバ インスタンスが受信メッセージを適切なタイミングで処理していないことが理由でマルチキャスト ストームが発生する場合、マルチキャスト バッファのサイズを大きくすることで対処できます。
UNIX の ndd ユーティリティを使用して、TCP/IP カーネル パラメータを調整することができます。udp_max_buf パラメータは、UDP ソケットの送信バッファおよび受信バッファのサイズをバイト単位で設定します。udp_max_buf の適切な値はデプロイメント環境によって異なります。マルチキャスト ストームが発生している場合、udp_max_buf の値を 32K ずつ大きくして調整の効果を確認してください。
udp_max_buf パラメータは必要な場合以外は変更しないでください。udp_max_buf パラメータを変更する場合は、事前に『Solaris Tunable Parameters Reference Manual』(http://docs.sun.com/?p=/doc/806-6779/6jfmsfr7o&)の「TCP/IP Tunable Parameters」の章の「UDP Parameters with Additional Cautions」に記されている Sun からの警告を確認してください。
IP ソケットを使用したピア ツー ピア通信
クラスタ化されたサーバ間の 1 対多通信ではマルチキャストを使用するのに対し、WebLogic Server インスタンスどうしのピア ツー ピア通信では IP ソケットを使用します。IP ソケットは、2 つのアプリケーション間でメッセージとデータを転送するための単純で高性能のメカニズムです。クラスタ内の WebLogic Server インスタンスは、以下の目的で IP ソケットを使用します。
注意: WebLogic Server での IP ソケットの使い方はクラスタ関連にとどまらず、たとえば、Java クライアント アプリケーションがリモート オブジェクトにアクセスする場合など、すべての RMI 通信がソケットを使って行われます。
WebLogic Server クラスタのパフォーマンスは、ソケットのコンフィグレーションによって大きく左右されます。WebLogic Server でのソケット通信の効率は、次の 2 つの要因によって決まります。
pure-Java とネイティブ ソケット リーダーの実装の比較
ソケット リーダー スレッドの pure-Java 実装は、ピア ツー ピア通信を行うための、信頼性が高く移植可能な方法ですが、ソケットに大きな負荷がかかる WebLogic Server クラスタでの使い方に最適なパフォーマンスは提供できません。pure-Java ソケット リーダーを使用すると、スレッドは、ソケットにデータが入っているかどうかを調べるために、オープンしているソケットにポーリングする必要があります。つまり、ソケット リーダー スレッドはソケットのポーリングで常に「ビジー」となります。これはソケットがデータを持っていない場合でも変わりません。
この問題は、サーバがソケット リーダー スレッドの数よりも多くのソケットをオープンしている場合により顕著になります。こうした場合、各リーダー スレッドは、ソケットが非アクティブであると判断するためにタイムアウト条件が満たされるまで待ちながら、複数のオープン ソケットをポーリングしなければなりません。タイムアウトが発生したら、以下に示すように、スレッドは待機中の別のソケットに移動します。
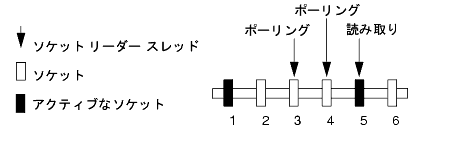
オープンしているソケットの数が使用可能なソケット リーダー スレッドの数を超えると、アクティブなソケットは、使用可能なソケット リーダー スレッドにポーリングされるまで、使用不可になる場合があります。
ソケットの最適なパフォーマンスを実現するには、pure-Java 実装ではなく、オペレーティング システムに対応したネイティブ ソケット リーダー実装を使用するよう WebLogic Server ホスト マシンをコンフィグレーションします。ネイティブ ソケット リーダーは、ソケット上のデータの有無を非常に効率的な手法で調べます。ネイティブ ソケット リーダー実装では、リーダー スレッドはネイティブ ソケットをポーリングする必要がなく、アクティブなソケットに対してだけサービスとして、特定のソケットがアクティブになった場合には、(割り込みによって)直ちに通知されます。
ネイティブ ソケット リーダー実装を使用するように WebLogic Server ホスト マシンをコンフィグレーションする方法については、 サーバ インスタンスのホストであるマシンに対してネイティブ IP ソケット リーダーをコンフィグレーションするを参照してください。
Java ソケット実装用のリーダー スレッドのコンフィグレーション
pure-Java ソケット リーダー実装を使用する場合は、適切な数のソケット リーダー スレッドをコンフィグレーションすることで、ソケット通信のパフォーマンスを向上できます。最適なパフォーマンスを実現するには、WebLogic Server でのソケット リーダー スレッドの数を、同時にオープンするソケットの最大数に合わせる必要があります。これにより、リーダー スレッドを複数のソケットで「共有」せずに済むので、ソケットのデータを直ちに読み取ることができます。
ソケットの使用数の確定
各 WebLogic Server インスタンスは、クラスタ内で自身を除くすべてのサーバ インスタンスに対してソケットをオープンする可能性があります。ただし、実際に使用されるソケットの最大数は、クラスタのコンフィグレーションによって決まります。実際には、クラスタ化されたサービスをデプロイする方法のため、クラスタ化されたシステムが他のサーバ インスタンスすべてに対してソケットをオープンすることはありません。
たとえば、クラスタがインメモリ HTTP セッション ステートのレプリケーションを使用し、クラスタ化されたオブジェクトだけをすべての WebLogic Server インスタンスにデプロイする場合、各サーバがオープンするソケットは、次に示すように最大で 2 つだけです。
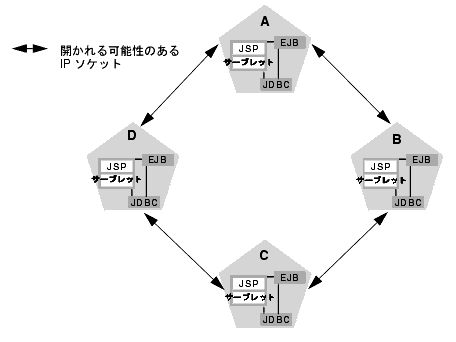
上記の例の 2 つのソケットは、プライマリ サーバとセカンダリ サーバとの間で HTTP セッション ステートをレプリケートするために使用されます。クラスタ化されたオブジェクトにアクセスする場合、WebLogic Server が連結の最適化を行うために、ソケットは不要となります。このコンフィグレーションでは、デフォルトのソケット リーダー スレッド コンフィグレーションで十分です。
クラスタ化されていない RMI オブジェクトを特定のサーバに固定する場合、サーバ インスタンスが固定されたオブジェクト(リモート サーバが固定されたオブジェクトを実際にルック アップした場合にのみ解放されます)にアクセスするために別のソケットをオープンすることがあるので、ソケットの最大数は増える可能性があります。以下の図は、クラスタ化されていない RMI オブジェクトをサーバ A にデプロイすることによる影響を示しています。
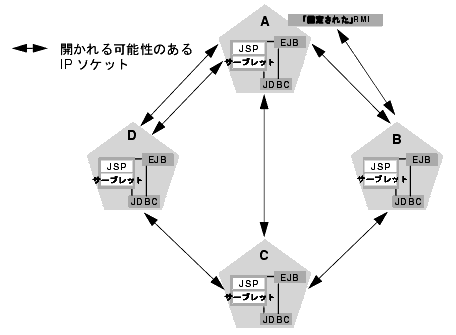
この例では、各サーバは、HTTP セッション ステートをレプリケートするためと、サーバ A 上で固定された RMI オブジェクトにアクセスするために、最大で同時に 3 つのソケットをオープンする可能性があります。
注意: 推奨多層アーキテクチャで説明するように、多層クラスタ アーキテクチャのサーブレット クラスタでは、さらにソケットが必要な場合があります。
リーダー スレッド数の設定方法については、 サーバ インスタンスのホストであるマシン上のリーダー スレッド数を設定するを参照してください。
ソケット経由のクライアント通信
クラスタのクライアントはソケット リーダー スレッドの Java 実装を使用します。WebLogic Server バージョン 6.1 の Java クライアント アプリケーションは、ファイアウォール経由で接続した場合でも、以前の WebLogic Server バージョンのクライアントよりも多くの IP ソケットをオープンできます。ファイアウォール経由でクラスタに接続するバージョン 4.5 および 5.1 の Java クライアントが 1 つのソケットを利用していましたが、WebLogic Server バージョン 6.1 にはこうした制約がありません。(明示的に、または「固定された」オブジェクトにアクセスすることで)クライアントがクラスタ内の複数のサーバ インスタンスにリクエストを送信する場合、クライアントは各サーバに対して個々にソケットをオープンします。
最適なパフォーマンスを得るためには、クライアントを実行する JVM 内に十分な数のソケット リーダー スレッドをコンフィグレーションします。詳細については、 クライアント マシン上のリーダー スレッド数を設定するを参照してください。
注意: WebLogic Server バージョン 6.1 クラスタに接続するブラウザベースのクライアントとアプレットは、IP ソケットを 1 つだけ使用します。
クラスタワイドの JNDI ネーミング サービス
個々の WebLogic Server のクライアントは、JNDI 準拠のネーミング サービスを通してオブジェクトとサービスにアクセスします。JNDI ネーミング サービスには、サーバが提供するすべての公開サービスのリストが「ツリー」構造の形で含まれています。WebLogic Server が新しいサービスを提供するには、そのサービスを表す名前を JNDI ツリーにバインドします。クライアントがそのサービスを取得するには、そのサーバに接続し、バインドされたサービスの名前をルック アップします。
クラスタ内のサーバ インスタンスは、クラスタワイドの JNDI ツリーを利用します。クラスタワイドの JNDI ツリーは、ツリーが使用可能なサービスのリストを格納しているという点では、1 つのサーバ JNDI ツリーと似ています。ただし、クラスタワイドの JNDI ツリーは、ローカル サービスの名前だけでなく、クラスタ内の他のサーバ上にあるクラスタ化されたオブジェクト(EJB や RMI クラス)が提供するサービスも格納します。
クラスタ内の各 WebLogic Server インスタンスは、クラスタワイドの論理 JNDI ツリーをローカルにコピーして保守します。クラスタワイドのネーミング ツリーの保守方法を理解しておくと、クラスタ環境で発生する可能性のある名前の衝突の原因をより的確に分析できます。
警告: クラスタワイドの JNDI ツリーは、アプリケーション データの永続性メカニズムまたはキャッシング メカニズムとして使用しないでください。WebLogic Server は、クラスタ化されたサーバの JNDI エントリをクラスタ内の他のサーバにレプリケートしますが、元のサーバで障害が発生すると、これらのエントリはクラスタから削除されます。また、JNDI ツリー内に大きなオブジェクトを格納すると、マルチキャスト トラフィックが過負荷状態になり、クラスタの通常の処理の妨げとなる場合があります。
クラスタワイドの JNDI ツリーの作成
クラスタ内の各 WebLogic Server は、クラスタのすべてのメンバーが提供するサービスが入ったクラスタワイドの JNDI ツリーをローカルにコピーして保守します。クラスタワイドの JNDI ツリーを作成する場合は、まず各サーバ インスタンスをローカルの JNDI ツリーにバインドします。サーバが起動する(または新規サービスが動作中のサーバに動的にデプロイされる)と、サーバはまず、それらのサービスの実装をローカルの JNDI ツリーにバインドします。実装が JNDI ツリーにバインドされるのは、名前が他のサービスと重複していない場合だけです。
サーバがサービスをローカルの JNDI ツリーにバインドすると、レプリカ対応スタブを使用するクラスタ化されたオブジェクト向けに、次の手順が実行されます。クラスタ化されたオブジェクトの実装をローカルの JNDI ツリーにバインドしたら、サーバはそのオブジェクトのスタブを他のクラスタ メンバーに送信します。クラスタの他のメンバーはマルチキャスト アドレスをモニタして、リモート サーバが提供するサービスを追加したことを検出します。
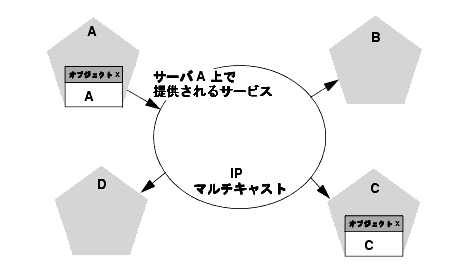
上の図は、JNDI をバインドするプロセスを示しています。サーバ A は、クラスタ化されたオブジェクト X の実装をローカルの JNDI ツリーにバインドしました。オブジェクト X はクラスタ化されているので、このサービスはクラスタ内の他のすべてのメンバーに提供されます。サーバ C はオブジェクト C の実装をバインド中です。
クラスタ内でマルチキャスト アドレスをリスンしている他のサーバは、サーバ A がクラスタ化されたオブジェクト X の新規サービスを提供し始めたことを検出します。これらのサーバは、自身のローカル JNDI ツリーを更新して、新規サービスをツリーに含めます。
ローカルの JNDI バインドは次のいずれかの方法で更新されます。
この方法によって、クラスタ内の各サーバはクラスタワイドの JNDI ツリーのコピーを独自に作成します。サーバ C が、オブジェクト X がローカルの JNDI ツリーにバインドされたことを通知する場合にも、処理順序は同じです。すべてのブロードキャスト メッセージが受信されたら、クラスタ内の各サーバは、以下の図のように、サーバ A とサーバ C 上でオブジェクト X が使用可能であることを同じように示します。
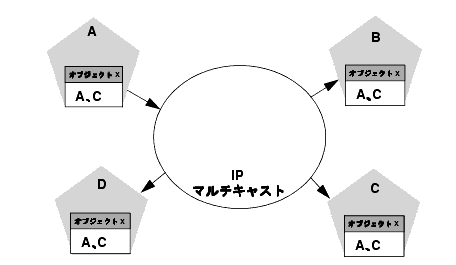
注意: 実際のクラスタ システムでは、オブジェクト X は均一にデプロイされ、実装は 4 つのサーバすべてで使用可能になります。
JNDI 名の衝突の処理
単純な JNDI 名の衝突は、サーバが JNDI ツリー内にバインド済みでクラスタ化されていないサービスと同じ名前を使って、別のクラスタ化されていないサービスをバインドしようとすると発生します。クラスタレベルの JNDI 名の衝突は、サーバが JNDI ツリー内にバインド済みでクラスタ化されていないサービスと同じ名前を使って、クラスタ化されているオブジェクトをバインドしようとしたときに発生します。
WebLogic Server は、ローカルの JNDI ツリーにサービスをバインドするときに、(クラスタ化されていないサービスの)単純な名前の衝突を検出します。クラスタレベルの JNDI の衝突は、マルチキャストを使って新規サービスの通知を行うときに発生します。たとえば、クラスタ内のあるサーバに固定された RMI オブジェクトをデプロイする場合、同じオブジェクトでレプリカ対応のものを別のサーバ インスタンス上にデプロイすることはできません。
クラスタ内の 2 つのサーバが、クラスタ化された別々のオブジェクトを同じ名前を使ってバインドしようとした場合、どちらのバインドもローカルには成功します。ただし、JNDI 名の衝突が発生するので、各サーバでは、他のサーバのレプリカ対応スタブを JNDI ツリーにバインドすることはできません。このタイプの衝突は、2 つのサーバのどちらかが終了するか、どちらかのサーバが衝突の原因となったクラスタ化オブジェクトをアンデプロイするまで解決しません。これと同じ衝突は、両方のサーバが固定されたオブジェクトを同じ名前でデプロイしようとした場合にも発生します。
均一デプロイメント
クラスタレベルの JNDI の衝突を回避するには、すべてのレプリカ対応オブジェクトを、クラスタ内のすべての WebLogic Server インスタンスにデプロイする必要があります(均一デプロイメント)。デプロイメントが WebLogic Server インスタンス間でバランスを欠いていると、起動時または再デプロイメント時に JNDI 名の衝突が発生する可能性が高まります。また、クラスタ内の処理負荷のバランスも取れなくなることがあります。
特定の RMI オブジェクトまたは EJB を個々のサーバに固定する必要がある場合は、そのオブジェクトのバインドをクラスタ間でレプリケートしないようにします。
JNDI ツリーの更新
クラスタ化されたオブジェクトを削除(サーバからアンデプロイ)した場合、JNDI ツリーの更新は、新規サービスの追加と似た方法で処理されます。アンデプロイされたサービスがあった WebLogic Server は、そのサービスが提供されなくなったことを示すメッセージをブロードキャストします。すでに説明したように、マルチキャスト メッセージを監視しているクラスタ内の他のサーバは、JNDI ツリーのローカル コピーを更新して、オブジェクトをアンデプロイしたサーバ上でそのサービスが使用できなくなったことを反映させます。
クライアントがレプリカ対応スタブを取得すると、クラスタ内のサーバ インスタンスは、「 JNDI ツリーの更新」で説明したように、クラスタ化されたオブジェクトのホスト サーバの追加と削除を続行できます。JNDI ツリー内の情報が変更されると、クライアントのスタブも更新されます。その後の RMI リクエストには、クライアントのスタブが常に最新の情報を持つように、必要に応じて更新情報が含まれます。
クライアントとクラスタワイドの JNDI ツリーとの対話
WebLogic Server クラスタに接続して、クラスタ化されたオブジェクトをルック アップするクライアントは、そのオブジェクトのレプリカ対応スタブを取得します。このスタブには、そのオブジェクトの実装のホストとして使用可能なサーバ インスタンスのリストが入っています。スタブには、ホスト サーバ間で負荷を分散するためのロード バランシング ロジックも含まれています。
( オブジェクトのクラスタ化についてでは、EJB および RMI クラスのレプリカ対応スタブについて説明しています。)
クラスタ環境での WebLogic JNDI の実装方法と、独自のオブジェクトを JNDI クライアントから使用できるようにする方法については、『WebLogic JNDI プログラマーズ ガイド』の「クラスタ環境での WebLogic JNDI の使い方」を参照してください。
クラスタ化されたサービスのロード バランシング
クラスタがスケーラブルになるには、 各サーバを完全に利用できるようにする必要があります。これを実現する標準的な手法がロード バランシングです。ロード バランシングを支える基本的な考え方は、負荷をクラスタ内のすべてのサーバに均等に分散することで、各サーバがフル稼働できるというものです。ロード バランシングを行うには、単純ながらも十分な手法を利用します。クラスタ内のすべてのサーバが同じ能力を持ち、同じサービスを提供する場合は、サーバの知識を必要としない非常に単純なアルゴリズムを使用することができます。サーバの能力やサーバがデプロイするサービスの種類が異なる場合、アルゴリズムはこれらの相違を考慮する必要があります。
HTTP セッション ステートのロード バランシング
サーブレットと JSP HTTP セッション ステートのロード バランシングは、別途ロード バランシング ハードウェアを使用するか、または WebLogic プロキシ プラグインに組み込まれているロード バランシング機能を使用して実現します。
Web サーバのバンクと WebLogic プロキシ プラグインを利用するクラスタの場合、プロキシ プラグインは、リクエストをクラスタ内のサーブレットと JSP に分散するために、ラウンドロビン アルゴリズムのみを提供します。このロード バランシング方法については、「 ラウンドロビン(デフォルト)」で説明します。
ハードウェア ロード バランシング ソリューションを利用するクラスタでは、ハードウェアがサポートしているすべてのロード バランシング アルゴリズムを利用できます。この中には、個々のマシンの利用状況をモニタする負荷ベースの高度なバランシング方式を採用しているものもあります。
注意: 外部のロード バランサは、HTTP トラフィックを分散させることはできますが、EJB と RMI オブジェクトに対するロード バランシングの機能は備えていません。オブジェクト レベルのロード バランシングを行うには、現在の外部ロード バランサにはない特殊なアルゴリズムとサービスが必要です。WebLogic Server におけるオブジェクト レベルのロード バランシングについては、 クラスタ化されたオブジェクトのロード バランシングを参照してください。
クラスタ化されたオブジェクトのロード バランシング
WebLogic Server クラスタは、クラスタ化されたオブジェクトをロード バランシングするための複数のアルゴリズムをサポートしています。選択した特定のアルゴリズムは、クラスタ化されたオブジェクトのレプリカ対応スタブ内で維持されます。クラスタ化されたオブジェクトのロード バランシングには、以下のアルゴリズムをコンフィグレーションできます。
IIOP プロトコルを介してクライアント上で動作するオブジェクトに対しては、ロード バランシングはサポートされていません。詳細については、 クラスタ化されたオブジェクトと RMI-IIOP クライアントを参照してください。
ラウンドロビン(デフォルト)
WebLogic Server は、特定のアルゴリズムが指定されていない場合には、クラスタ化されたオブジェクトのロード バランシング方式としてラウンドロビン アルゴリズムを使用します。ラウンドロビンは、WebLogic プロキシ プラグインが HTTP セッション ステートのクラスタ化に対して使用する唯一のロード バランシング方式です。
このアルゴリズムは、WebLogic Server インスタンスのリストを順番に循環します。クラスタ化されたオブジェクトの場合、サーバ リストはそのオブジェクトのホストとなる WebLogic Server インスタンスからなります。プロキシ プラグインの場合、リストは、クラスタ化されたサーブレットまたは JSP のホストとなるすべての WebLogic Server からなります。
このアルゴリズムの長所は、単純で軽く非常に予測しやすいということです。主な短所は、コンボイの可能性が若干あることです。コンボイは、あるサーバがその他のサーバよりも著しく速度が低下したときに発生します。レプリカ対応スタブまたはプロキシは同じ順序でサーバにアクセスするので、速度の遅いサーバがあると、リクエストがそのサーバ上で「同期」するため、その他のサーバが将来のリクエストに備えて停滞する可能性があります。
重みベース
重みベースのアルゴリズムは、オブジェクトのクラスタ化に対してのみ適用されます。このアルゴリズムは、各サーバに対してあらかじめ割り当てておいた重みを考慮することで、ラウンド ロビン アルゴリズムを改良したものです。クラスタ内の各サーバには、WebLogic Server Administration Console の [クラスタの重み] フィールドを使って、1 ~ 100 の範囲で重みを割り当てます。これは、他のサーバと比較して、負荷をかける比率を宣言するものです。すべてのサーバがデフォルトの重み(100)または、同じ重みであれば、負荷の割合も同じになります。あるサーバの重みが 50 で、他のサーバがすべて重み 100 の場合、重み 50 のサーバへの割り当ては、他のサーバの半分になります。このアルゴリズムを使うと、均一でないクラスタに対してラウンドロビン アルゴリズムの利点を活かすことができます。
重みベースのアルゴリズムを使用する場合、各サーバ インスタンスに割り当てる重みを決定するには十分な検討が必要です。サーバの重みは、以下の要因を考慮して割り当てます。
サーバに指定した重みを変更してサーバを再起動すると、レプリカ対応スタブ経由で新しい重みの情報がクラスタ全体に伝播されます。詳細については、 クラスタワイドの JNDI ネーミング サービスを参照してください。
ランダム
このアルゴリズムは、オブジェクトのクラスタ化にのみ適用されます。このアルゴリズムは、次のレプリカをランダムに選択します。結果的には、呼び出しはレプリカ間で均等に分散されます。各サーバが同じ能力を持ち、同じサービスのホストとなっているクラスタでのみ使用することをお勧めします。この方式のメリットは、単純で比較的軽いことです。主なデメリットは、各リクエストに対して乱数を生成するためのコストが多少生じることと、実行回数が少ない場合は負担が均一に分散しない可能性が若干あることです。
クラスタ化されたオブジェクトのパラメータベースのルーティング
ロード バランシングをきめ細かく制御することも可能です。クラスタ化されたオブジェクトを CallRouter に割り当てることができます。これはパラメータにより各呼び出しの前に呼び出されるクラスです。CallRouter はそのパラメータを自由に調べ、呼び出しの送り先となるネーム サーバを返します。カスタム CallRouter クラスの作成の詳細については、
WebLogic クラスタの APIを参照してください。
ロード バランシングと JDBC 接続
JDBC 接続のロード バランシングを行うには、ロード バランシング用にコンフィグレーションされたマルチプールを使用する必要があります。ロード バランシングのサポートは、マルチプールをコンフィグレーションするときに選択できるオプションです。
マルチプールのロード バランシングを行うと、 フェイルオーバと JDBC 接続で説明する高可用性の動作が実現されることに加えて、マルチプール内の接続プール間で負荷が調整されます。マルチプールには、その中の接続プールの順番付きリストがあります。ロード バランシングを使用するようにマルチプールをコンフィグレーションしない場合、マルチプールは常に、リスト内の最初の接続プールから接続を取得しようと試みます。ロード バランシングされるマルチプールでは、その中の接続プールへのアクセスはラウンドロビン方式で行われます。クライアントからのその後のマルチプール接続リクエストのたびに、リストが循環し、選択された最初のプールがリストの最後尾に回ります。
JDBC 接続をクラスタ化する方法については、 クラスタ化された JDBC をコンフィグレーションするを参照してください。
ロード バランシングと JMS
クラスタ内の複数の管理対象サーバ間で JMS 送り先のロード バランシングを行うことができます。これは、複数の JMS サーバをコンフィグレーションし、ターゲットを使用してそれらを定義済みの WebLogic Server に割り当てることによって行います。各 JMS サーバはただ 1 つの WebLogic Server にデプロイされ、送り先の集合に対するリクエストを処理します。
ロード バランシングは動的ではありません。コンフィグレーションの間、システム管理者は JMS サーバに対してターゲットを指定することによってロード バランシングを定義します。クラスタに対して JMS を設定する手順については、 JMS をコンフィグレーションするを参照してください。
クラスタ化されたサービスのフェイルオーバ サポート
クラスタが高可用性を提供するためには、サービスの障害からの回復が可能でなければなりません。この節では、WebLogic Server がクラスタ内の障害を検出する方法と、レプリケートされた HTTP セッション ステートとクラスタ化されたオブジェクトに対してフェイルオーバが機能する仕組みの概要について説明します。
WebLogic Server の障害検出方法
クラスタ内の WebLogic Server インスタンスは、以下のものをモニタすることで、自身のピア サーバ インスタンスの障害を検出します。
IP ソケットを使用した障害検出
WebLogic Server は、障害を直ちに検出するために、ピア サーバ インスタンス間で IP ソケットが使用されているかどうかをモニタします。サーバがクラスタ内のピアのいずれかに接続し、ソケットを使ってデータ転送を始めた場合、そのソケットが突然クローズされると、ピア サーバが「エラー」としてマークされ、その関連サービスが JNDI ネーミング ツリーから削除されます。
WebLogic Server の「ハートビート」
クラスタ化されたサーバ インスタンスがピア ツー ピア通信用にソケットをオープンしていない場合、障害が発生したサーバは、WebLogic Server の「ハートビート」を使って検出できます。クラスタ内のすべてのサーバ インスタンスはマルチキャストを使用して、定期的なサーバ「ハートビート」メッセージを他のクラスタ メンバーにブロードキャストします。各サーバ ハートビートには、メッセージの送信元のサーバをユニークに識別するデータが入っています。サーバは、自身のハートビート メッセージを 10 秒間隔で定期的にブロードキャストします。同時に、クラスタ内の各サーバはマルチキャスト アドレスをモニタして、すべてのピア サーバのハートビート メッセージが送信されているかどうかを確認します。
マルチキャスト アドレスをモニタ中のサーバにピア サーバからのハートビート メッセージが 3 回届かなかった場合(つまり、モニタする側のサーバが他のサーバから 30 秒以上ハートビートを受信していない場合)、モニタする側のサーバはピア サーバを「エラー」としてマークします。次に、必要であればローカルの JNDI ツリーを更新して、障害が発生したサーバでホストされていたサービスを削除します。
このようにして、サーバは、ピア ツー ピア通信でソケットがオープンされていない場合でも、障害を検出できます。
クラスタ化されたサーブレットと JSP のフェイルオーバ
WebLogic プロキシ プラグインを持つ Web サーバを利用しているクラスタの場合、プロキシ プラグインはクライアントからは透過的にフェイルオーバを処理します。特定のサーバに障害が発生した場合、プラグインはセカンダリ サーバ上でレプリケート済みの HTTP セッション ステートを探して、クライアントのリクエストをそのままリダイレクトします。
サポート対象のハードウェア ロード バランシング ソリューションを使用しているクラスタの場合、ロード バランシング ハードウェアは、WebLogic Server クラスタ内で使用可能な任意のサーバにクライアントのリクエストを単純にリダイレクトします。クラスタ自身は、クライアントの HTTP セッション ステートのレプリカをクラスタ内のセカンダリ サーバから取得します。
レプリケートされた HTTP セッション ステートのフェイルオーバ手順の詳細については、 JMS をコンフィグレーションするを参照してください。
クラスタ化されたオブジェクトのフェイルオーバ
クラスタ化されたオブジェクトの場合、フェイルオーバは、オブジェクトのレプリカ対応スタブを使用して実行されます。クライアントがレプリカ対応スタブを通じて障害が発生したサービスに対して呼び出しを行うと、スタブはその障害を検出し、別のレプリカに対してその呼び出しを再試行します。
IIOP プロトコルを介してクライアント上で動作するオブジェクトに対しては、フェイルオーバはサポートされていません。詳細については、 クラスタ化されたオブジェクトと RMI-IIOP クライアントを参照してください。
多重呼び出し不変オブジェクト
クラスタ化されたオブジェクトについては、オブジェクトが多重呼び出し不変の場合にだけ自動的なフェイルオーバが行われます。メソッドを何回呼び出しても 1 回呼び出したときと効果に違いがなければ、オブジェクトは多重呼び出し不変となります。このことは、恒久的な副作用を持たないメソッドに関して常に当てはまります。副作用のあるメソッドは、特に多重呼び出し不変性に留意して作成する必要があります。
ここでショッピング カートに商品を追加するショッピング カード サービス呼び出し addItem() を考えてみます。クライアント C がこの呼び出しをサーバ S1 上のレプリカで行うものとします。S1 が呼び出しを受け取った後、呼び出しを C に返す前に、S1 がクラッシュしたとします。この時点では、商品がショッピング カートに追加されていますが、レプリカ対応スタブは例外を受け取っています。スタブがサーバ S2 でこのメソッドを再試行すれば、商品がショッピングカートに 2 回追加されることになります。この理由から、レプリカ対応スタブは、デフォルトでは、リクエストが送られた後、そのリクエストが返ってくるまでは、メソッドの再試行は行いません。この動作は、サービスを多重呼び出し不変としてマークすることで、オーバーライドできます。
他のフェイルオーバの例外
クラスタ化されたオブジェクトが多重呼び出し不変でない場合でも、WebLogic Server は、ConnectException または MarshalException が発生したときに自動フェイルオーバを実行します。いずれの例外もオブジェクトが変更されないことを示しているため、別のインスタンスにフェイルオーバすることでデータの矛盾が起こる危険性はありません。
フェイルオーバと JDBC 接続
JDBC はクライアントと DBMS の間の非常にステートフルなプロトコルであり、DBMS 接続とトランザクション状態が、DBMS プロセスとクライアント(ドライバ)の間のソケットに直接結び付けられます。この理由から、接続のフェイルオーバはサポートされていません。WebLogic Server インスタンスが停止すると、そのインスタンスによって管理されていた JDBC 接続もすべて切断され、DBMS は進行中であったすべてのトランザクションをロールバックします。影響を受けるアプリケーションは、その時点でのトランザクションを最初から再開しなければなりません。切断された接続と関連付けられていたすべての JDBC オブジェクトも機能を停止します。JDBC をクラスタ化すると、再接続のプロセスが容易になります。外部クライアント アプリケーション内の WebLogic データ ソースはクラスタに対応しているため、以前の接続のホストであったサーバ インスタンスが停止した場合、クライアントは WebLogic データ ソースから別の接続を要求することができます。
同期されるデータベース インスタンスを複製済みである場合、JDBC マルチプールを使用してデータベースのフェイルオーバを実現できます。そのような環境では、プールが存在しないか、プールからのデータベース接続が機能していないことによってクライアントがプール内のある接続プールが接続を取得できない場合、WebLogic Server はプール リスト内の次の接続プールから接続の取得を試みます。
注意: すべての接続が使用中であるプールに対してクライアントが接続を要求すると、例外が生成され、WebLogic Server は別のプールからの接続取得を試みません。この問題には、接続プール内の接続の数を増やすことによって対処できます。
マルチプールに割り当てられるすべての接続プールは、予約時にその接続をテストするようにコンフィグレーションされる必要があります。これは、接続状態が良好であることをプールが検証するための唯一の方法であり、プール リスト上の次のプールへのフェイルオーバを行う時期をマルチプールが認識するための唯一の方法でもあります。
JDBC 接続をクラスタ化する方法については、 クラスタ化された JDBC をコンフィグレーションするを参照してください。
フェイルオーバと JMS
このリリースの WebLogic JMS では、自動フェイルオーバはサポートされていません。『管理者ガイド』の「WebLogic Server の障害からの回復」では、システム障害時に WebLogic Server インスタンスの再起動または入れ替えを行う方法について説明しています。また、手動でのフェイルオーバなどが行われる前に JMS アプリケーションを正しく終了させるためのプログラミング上の考慮事項についても示しています。
|
|
|
|