Working with Search Indexes
This topic provides an overview of index building process and discusses how to build an index.
In Elasticsearch, an index is a logical namespace that maps to one or more primary shards and can have zero or more replica shards.
Before end users can submit search requests against the Search Framework deployed objects, the search indexes must first be built on the search engine. Prior to the index being built, a deployed search definition is an empty shell, containing no searchable data. A search index needs to be built for search definitions.
An Application Engine program, PTSF_GENFEED, builds the search index data and pushes it to Integration Broker, which makes it available to Elasticsearch.
When an attachment is specified in a search definition, PeopleSoft Search Framework transfers the attachment data directly to the search engine using cURL and libcurl libraries and does not use the Integration Broker.
Creating a search index with the Search Framework involves the following technologies:
Search Framework
Application Engine
Query/Connected Query Manager
Process Scheduler
Integration Broker
cURL and libcurl Libraries
Once you invoke a search index build from the Build Search Index page, the system automatically completes these general steps:
The Schedule Search Index page initiates the PTSF_GENFEED Application Engine program.
The Pre Processing Application Engine program defined for the search definition runs.
PTSF_GENFEED Application Engine program runs the query (PeopleSoft Query or Connected Query) associated with the search definition.
Multiple PTSF_GENFEED Application Engine programs will run for a Connected Query in cases where users specify the number of partitions. See Partitioning Application Data in the Search Index Build Process for more information.
The query output becomes a data source for PeopleSoft Search Framework.
The PeopleSoft Search Framework converts the query output to the JSON format and pushes the data to Elasticsearch and the Delete query (for incremental indexing) defined for the search definition runs.
During this step, the following steps are also executed:
If it is full indexing, a delete request is sent to Elasticsearch to clear any indexed data that is present.
If Full Direct Transfer is not enabled (segments of documents without attachments), on clearing indexed data, the data to be indexed is pushed to an Ordered IB Queue (PTSF_ES_SEND_Q) partitioned with segments. IB Queue processes the data asynchronously based on the partition.
If Full Direct Transfer is enabled, on clearing indexed data, the data is transferred to Elasticsearch directly using cURL and libcurl libraries.
The Delete Query is invoked when incremental indexing is run after a full index is built. Stale data is removed from the index as selected by the Delete Query.
Note: Each partition pushes the data in JSON format to Elasticsearch synchronously (that is, waits for response from Elasticsearch) and the response is read and acknowledged in PeopleSoft through exception handling.
The Post Processing Application Engine program defined for the search definition runs.
A run control ID is bound to both, a search definition and a search instance.
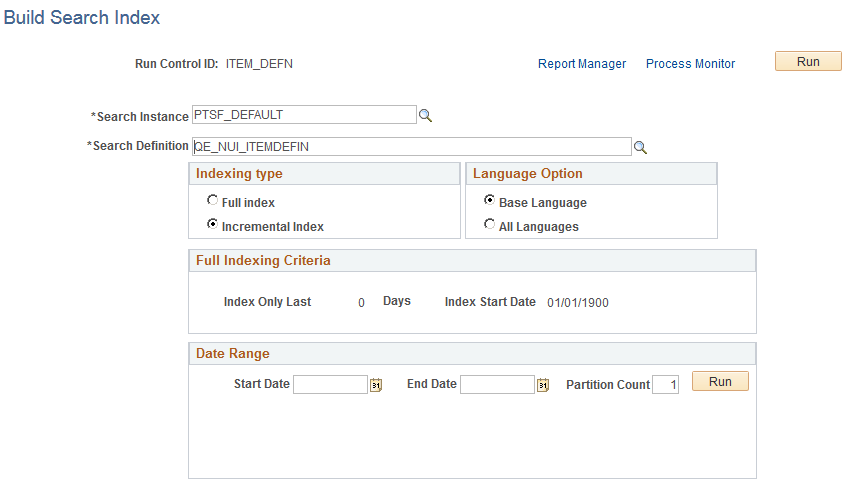
Access the Build Search Index page. (Select PeopleTools, Search Framework, Search Admin Activity Guide, Administration, Schedule Search Index.)
Image: Build Search Index page
This example illustrates the fields and controls on the Build Search Index page. You can find definitions for the fields and controls later on this page.
To build a Search Framework search index:
Select PeopleTools, Search Framework, Search Admin Activity Guide, Schedule Search Index.
Enter a run control ID.
On the Build Search Index page, select the appropriate options.
Field or Control
Definition
Search Instance Select the search instance in which you want to build the search index.
Search Definition Select the search definition for which you are building the search index.
Note: Once the Run Control is executed, the page becomes read-only. To change any parameters of the page, you need to create a new run control.
Indexing Type Select one of the following:
Full index. Crawls all transactional data specified by the query criteria and rebuilds the entire index. This option requires the most time. This option must be selected the first time an index is built.
Incremental index. Updates the existing index and adds only documents associated with rows that have been added or updated since the last index build or update. The system determines the required updates based on a comparison between the timestamp of the index and the “last updated” field for the data row.
Items are also removed from the index as designated by the delete query on the search definition.
Note: It is recommended to create one run control for incremental indexing, scheduled to run very frequently, and create another run control for full index rebuilding set to run less frequently. For example, incremental indexing might run daily, where a full index rebuild may be set to run every six months.
Language Options Select one of the following:
All Languages. Builds an index for each language enabled on the database.
Base Language. Builds an index only for the base language defined for the database.
Your selection depends on the languages enabled for your database and the languages through which you anticipate end users using to perform searches.
Full indexing Criteria Applies only to full index builds. Displays the span of time in which the system will retrieve and index application data for this search definition. The date span is defined on the Advanced Settings tab for the search definition. This enables you to limit index processing for data that could potentially generate very large indexes, if needed.
For more information on this option see, Working With Advanced Settings.
If you plan to use the partitioning option through the Date Range grid, you must note that the indexing date span is overridden by the date span entered in the Date Range grid. For more information, see Partitioning Application Data in the Search Index Build Process.
Date Range The Date Range option appears when the selected search definition is based on a connected query. The Date Range option enables you to partition the search data based on a date range. You need to specify:
Start Date. Specify the start date of the date range.
End Date. Specify the end date of the date range.
Partition. Enter the number of partitions you want the search index build process to create.
Note: Save the settings before you select the Run button in the Date Range option.
Note: PeopleSoft does not recommend using Date Range partitioning with search definitions that use preprocessing unless the preprocessing logic has been modified for use with partitioning. If you select search definitions that use preprocessing logic, then the indexing process may run preprocessing for each partition, which may yield undesirable results and may take considerable time to complete the indexing process.
For more details on using the Date Range option, see Partitioning Application Data in the Search Index Build Process.
Select Run.
Use Process Monitor to verify program completion and success.
Note: Once the Run Control is executed, the page becomes read-only. To change any parameters of the page, you need to create a new run control.
After the PTSF_GENFEED program begins to run, you can view the details which display on the Build Search Index page for that run control ID.
Note: The Details section shows the results of the most recent feed generation for this Search Definition. It may not be the same run control ID as the one you selected. If the run control ID differs from the one you selected, it will be highlighted.
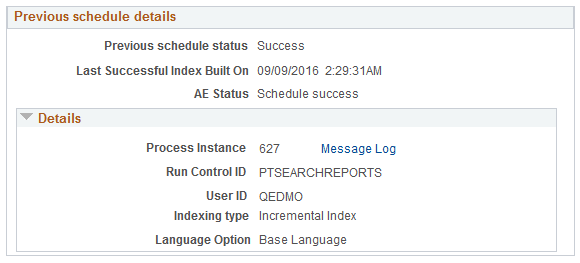
Image: Previous schedule details
This example illustrates the fields and controls on the Previous schedule details. You can find definitions for the fields and controls later on this page.
|
Field or Control |
Definition |
|---|---|
| Previous schedule status |
Displays the status of the most recently executed index build process. When errors occur while processing attachments, an Error link is displayed. Click the Error link to view the exceptions on the Attachment Transfer Exception Details page. |
| Last Successful Index Built On |
Displays the date when the index was built successfully. If an index was never built, it displays Never. |
| AE Status |
Indicates whether the most recently executed PTSF_GENFEED Application Program ran to completion. If the index build fails, this field displays the step where the process failed. |
| Resume schedule |
Appears in the case where the index build failed. If the index build fails, you can use the Rebuild index option to regenerate the index. If the build fails, see Handling Common Errors to determine the cause of the failure to build an index. |
| Process Instance |
Indicates whether the system successfully created the output that is required to populate the index. |
| Run Control ID |
Displays the run control ID used to generate the index. |
| User ID |
Displays the User ID who ran the run control, which may be a different user ID than the user who created the run control. |
| Indexing Type |
Displays the index type (Full Index or Incremental Index). |
| Language Option |
Displays the language options selected for the index build process (All Languages or Base Language). |
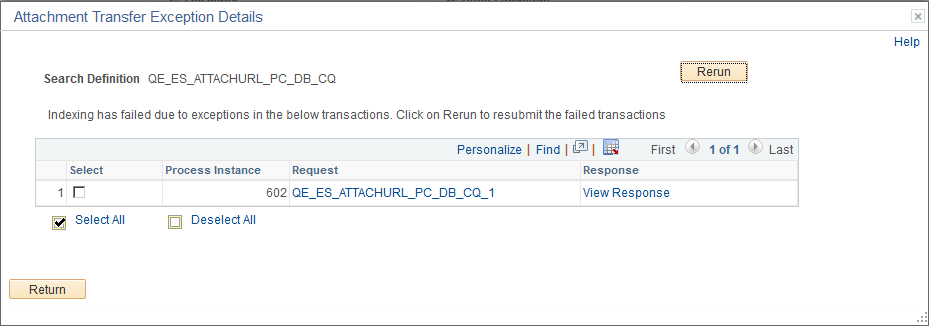
In the Previous schedule details section, select the Error link to view the details of exceptions with respect to attachment processing.
Image: Attachment Transfer Exception Details page
This example illustrates the fields and controls on the Attachment Transfer Exception Details page. You can find definitions for the fields and controls later on this page.
|
Field or Control |
Definition |
|---|---|
| Process Instance |
The process instance ID of the PTSF_GENFEED Application Engine program that is causing the exception. |
| Request |
The request sent by the PTSF_GENFEED Application Engine program to Elasticsearch. |
| Response |
The response received by the PTSF_GENFEED Application Engine program from Elasticsearch. |
| Rerun |
Use the Rerun button to resubmit the selected transactions to Elasticsearch. In the case where the maximum exceptions limit is not reached, when you select the Rerun button, the transactions are directly submitted to Elasticsearch without re-execution of the PTSF_GENFEED Application Engine program. In the case where the maximum exceptions limit is reached, the Rerun button acts as a re-submit of the PTSF_GENFEED Application Engine program. |
Indexing of search definitions that are based on connected query and that have reasonably large data volume can pose performance issues. To overcome such performance issues, PeopleSoft Search Framework enables you to partition the application data using the Date Range option. After the date range and number of partitions are specified, the Partition Manager partitions the date range into equal date spans based on the number of partitions. The search index build process creates multiple PTSF_GENFEED Application Engine programs to run the connected query on the partitioned data. The search index build process also creates multiple run control IDs based on the number of partitions that enables you to re-run any of the run control IDs associated with a partition. The partitioning of application data is performed based on the date range and the number of partitions that are specified.
You can specify the number of partitions, but you cannot control the date span within a date range that is allotted for each partition. The Partition Manager allots date span for the number of partitions specified by you.
Partitioning of application data works best when the volume of data is evenly spread over the specified date range. The purpose of partitioning is to divide the data volume into chunks and to run a connected query on the partitioned data, so when you plan to use the partitioning option, you must consider whether the search documents for a specific search definition are spread evenly over a specific date range. That is, if within a date range, for example, 01/01/2017 to 03/31/2017, a huge volume of search data is concentrated in the month of March and the other two months have few attachments, and you specify 3 partitions, then the partitioning may not be very effective because only one partition may get the bulk of the search documents, so you may still face performance issues.
The naming convention followed for run control IDs that are generated for each partition is as follows: _<USERID>_RUNCNTL_<TIME>_<SEQUENCE NUMBER>
For example, _QEDMO_RUNCNTL_020022_2
Note: Partitioning is available for both full and incremental indexing. However, Oracle PeopleSoft recommends that you use partitioning only with full indexing.
Note: When you specify a date range to implement partitioning of search data, the date span entered in the Full Indexing Criteria option is overridden.
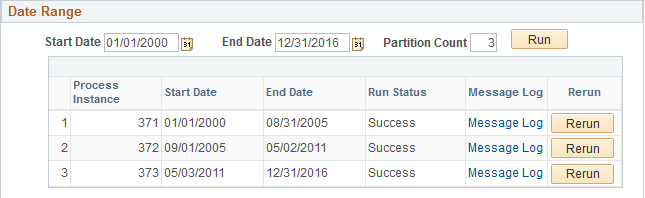
After you use the partitioning option and run the indexing process, the Build Search Index page displays this information.
Image: Date Range grid
This example illustrates the fields and controls on the Date Range grid. You can find definitions for the fields and controls later on this page.
|
Field or Control |
Definition |
|---|---|
| Process Instance |
Search index build process creates multiple PTSF_GENFEED Application Engine programs for the specified number of partitions. Displays the process instance for each partition. |
| Start Date |
Displays the start date (within the specified date range) for each partition. |
| End Date |
Displays the end date (within the specified date range) for each partition. |
| Run Status |
Displays the status of each process instance. |
| Message Log |
If the run status displays error status, use the Message Log link to view the error message. |
| Rerun |
Use the Rerun button to run the partitioned process again. |