Maintaining Partition Definitions
This section provides an overview of partition management, defines partitioning terms, and describes how to maintain partition definitions.
For the Oracle platform, PeopleTools provides several pages, dialog boxes, and record definitions that enable you to establish and maintain table and index partition definitions within your PeopleSoft database . Partitioning subdivides tables and indexes into smaller pieces, enabling the database to access and manage the partitioned objects at a finer level of granularity. This provides more efficiency for administration with faster backups, for example, and better transaction performance, with queries being able to isolate the relevant data more quickly through partitions. SQL performance using partitioned tables or indexes may improve by several orders of magnitude.
Partitioning is transparent to PeopleSoft applications; no changes are required to underlying APIs to utilize partitioning.
Prerequisites
Tablespaces are required for partitioning definitions, and must be established before you can implement partitioning. If your PeopleSoft application includes partition definitions, the scripts for the required tablespaces are delivered, and must be run after installation. See your application documentation for more details.
The following table defines partitioning-related terms, and describes the types of partitioning that are supported.
|
Field or Control |
Definition |
|---|---|
| Partitioning |
Partitioning enables you to decompose very large tables and indexes into smaller and more manageable pieces called partitions. Each partition is an independent object with its own name and optionally its own storage characteristics. From the perspective of an application, only one schema object exists. DML statements require no modification to access partitioned tables. Partitioning is useful for many different types of database applications, particularly those that manage large volumes of data. Benefits include:
|
| Partition Key |
The partition key consists of one or more columns that determine the partition where each row is stored. Oracle automatically directs insert, update, and delete operations to the appropriate partition with the partitioning key. Each row in a partitioned table is unambiguously assigned to a single partition. |
| Partitioned Tables and Indexes |
You can partition tables and indexes. Partitioning helps to support very large tables and indexes by enabling you to divide the tables and indexes into smaller and more manageable pieces called partitions. SQL queries and DML statements do not have to be modified to access partitioned tables and indexes. Partitioning is transparent to the application. |
| Hash Partitioning |
In hash partitioning, the database maps rows to partitions based on a hashing algorithm that the database applies to the user-specified partitioning key. The destination of a row is determined by the internal hash function applied to the row by the database. The hashing algorithm is designed to evenly distribute rows across devices so that each partition contains about the same number of rows. Hash partitioning is useful for dividing large tables to increase manageability. Instead of one large table to manage, you have several smaller pieces. The loss of a single hash partition does not affect the remaining partitions and can be recovered independently. Hash partitioning is also useful in OLTP systems with high update contention. For example, a segment is divided into several pieces, each of which is updated, instead of a single segment that experiences contention. |
| List Partitioning |
In list partitioning, the database uses a list of discrete values as the partition key for each partition. You can use list partitioning to control how individual rows map to specific partitions. By using lists, you can group and organize related sets of data when the key used to identify them is not conveniently ordered. |
| Range Partitioning |
In range partitioning, the database maps rows to partitions based on ranges of values of the partitioning key. Range partitioning is the most common type of partitioning and is often used with dates. |
| Composite Partitioning/Sub Partitioning |
Composite partitioning is a partitioning technique that combines some of the other partitioning methods. A table is initially partitioned by the first data distribution method and then each partition is sub-partitioned by the second data distribution method. All sub partitions for a given partition represent a logical subset of the data. Composite partitioning supports historical operations, such as adding new range partitions, but also provides higher degrees of potential partition pruning and finer granularity of data placement through sub partitioning. The following composite partitions are supported in Oracle:
|
| Partition Pruning |
After partitions are defined, certain operations become more efficient. For example, for some queries, the database can generate query results by accessing only a subset of partitions, rather than the entire table. This technique (called partition pruning) can provide order-of-magnitude gains in improved performance. Partition pruning is the simplest and also the most substantial means to improve performance using partitioning. Partition pruning can often improve query performance by several orders of magnitude. For example, suppose an application contains an Orders table containing a historical record of orders, and that this table has been partitioned by week. A query requesting orders for a single week would only access a single partition of the Orders table. If the Orders table had 2 years of historical data, then this query would access one partition instead of 104 partitions. This query could potentially execute 100 times faster simply because of partition pruning. Partition pruning works with all of Oracle performance features. Oracle uses partition pruning with any indexing or join technique, or parallel access method. In addition, data management operations can take place at the partition level, rather than on the entire table. This results in reduced times for operations such as data loads; index creation and rebuilding; and backup and recovery. |
| Partition-Wise Joins |
Partition-wise joins reduce query response time by minimizing the amount of data exchanged among parallel execution servers when joins execute in parallel. Partition-wise joins can be applied when two tables are being joined and both tables are partitioned on the join key, or when a reference partitioned table is joined with its parent table. Partition-wise joins break a large join into smaller joins that occur between each of the partitions, completing the overall join in less time. This significantly reduces response time and improves the use of both CPU and memory resources for serial and parallel execution. In Oracle Real Application Clusters (Oracle RAC) environments, partition-wise joins also avoid or at least limit the data traffic over the interconnect, which is the key to achieving good scalability for massive join operations. |
| Partitioned Indexes |
A partitioned index is an index that, like a partitioned table, has been decomposed into smaller and more manageable pieces. Just like partitioned tables, partitioned indexes improve manageability, availability, performance, and scalability. They can either be partitioned independently (global indexes) or automatically linked to a table's partitioning method (local indexes). In general, global indexes should be used for OLTP applications and local indexes for data warehousing or decision support systems (DSS) applications. |
| Local Partitioned Indexes |
A local index is an index on a partitioned table that is coupled with the underlying partitioned table, 'inheriting' the partitioning strategy from the table. Consequently, each partition of a local index corresponds to one - and only one - partition of the underlying table. The coupling enables optimized partition maintenance; for example, when a table partition is dropped, Oracle simply has to drop the corresponding index partition as well. No costly index maintenance is required. Local indexes are most common in data warehousing environments. Local partitioned indexes are easier to manage than other types of partitioned indexes. They also offer greater availability and are common in DSS environments. The reason for this is equipartitioning: each partition of a local index is associated with exactly one partition of the table. This functionality enables Oracle to automatically keep the index partitions synchronized with the table partitions, and makes each table-index pair independent. Any actions that make one partition's data invalid or unavailable only affect a single partition. |
| Global Partitioned Indexes |
A global partitioned index is an index on a partitioned or non-partitioned table that is partitioned using a different partitioning-key or partitioning strategy than the table. Global-partitioned indexes can be partitioned using range or hash partitioning and are uncoupled from the underlying table. For example, a table could be range-partitioned by month and have twelve partitions, while an index on that table could be range-partitioned using a different partitioning key and have a different number of partitions. Global partitioned indexes are more common for OLTP than for data warehousing environments. Global range partitioned indexes are flexible in that the degree of partitioning and the partitioning key are independent from the table's partitioning method. The highest partition of a global index must have a partition bound; all of whose values are MAXVALUE. This ensures that all rows in the underlying table can be represented in the index. Global prefixed indexes can be unique or nonunique. Global hash partitioned indexes improve performance by spreading out contention when the index is monotonically growing. In other words, most of the index insertions occur only on the right edge of an index. |
| Global Non-Partitioned Indexes |
A global non-partitioned index is essentially identical to an index on a non-partitioned table. The index structure is not partitioned and uncoupled from the underlying table. In data warehousing environments, the most common usage of global non-partitioned indexes is to enforce primary key constraints. OLTP environments on the other hand mostly rely on global non-partitioned indexes. |
Limitations
Partitioning is supported only for alter tables; it is not supported for temporary tables.
The following partitioning types are not supported:
Interval partitioning
Reference partitioning
Virtual column based partitioning
System partitioning
The following compositve/sub-partitioning types are not supported:
List-Hash
Range-Hash
Interval-Range
Interval-List
Interval-Interval
To establish partitioning definitions, use the Partitioning page (PPMU_GEN_DDL_PG).
This page enables you to define partitioning parameters and generates the DDL scripts to create partitioned tables and indexes.
Navigation
Image: Partitioning Page
This example illustrates the fields and controls on the Partitioning page.
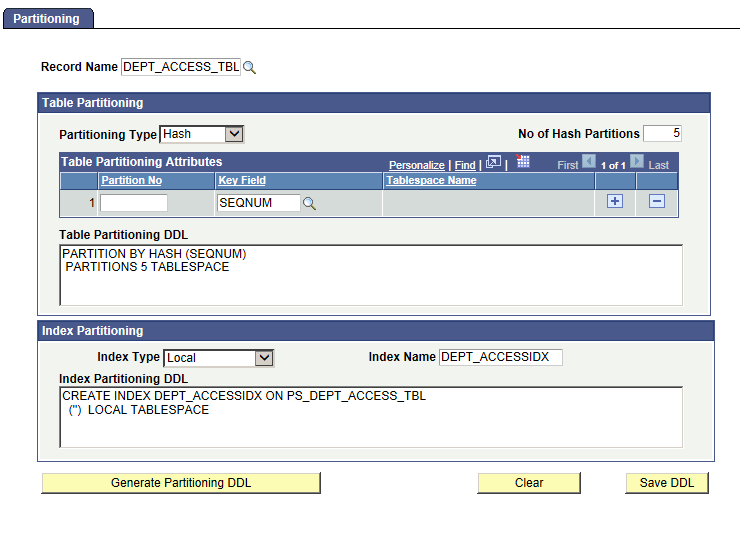
Complete the fields on this page to define table and/or index partitioning for a record, generate the partitioning DDL, revise the DDL (if required), and save the DDL.
|
Field or Control |
Definition |
|---|---|
| Record Name |
Select the table record for which to specify partitioning definitions. |
Table Partitioning
Complete the fields within the Table Partitioning group box to define table partitioning.
Hash, list, and range partitioning each have their own specific requirements:
For hash partitioning: specify the number of hash partitions and the tablespace for each partition.
For list partitioning: specify the partition name, the partition value, and the tablespace for each partition.
For range partitioning: specify the partition name, the partition criteria, and the tablespace for each partition.
|
Field or Control |
Definition |
|---|---|
| Partitioning Type |
Select the partitioning type. Options are:
For definitions of these partitioning types, see Partitioning Terminology |
| Sub Partitioning Required |
Select this check box if the table requires composite/sub partitioning. When you select this option, the sub-partitioning grid becomes available. This option is not available if the partitioning type is Hash. |
| No of Hash Partitions |
Enter the number of hash partitions to generate. This option is available only when the partitioning type is set to hash. |
| Table Partitioning Attributes |
For each table partition, complete the following fields (the available fields differ depending on the partitioning type): For hash partitions: Partition No (partition number), Key Field, TableSpace Name. For list partitions: Partition No, Key Field, Key Value, Partition Name, TableSpace Name. For range: Partition No, Key Field, Key Value, Partition Name, TableSpace Name |
| Sub Partitioning Type |
Select the sub partitioning type. Options are: Hash, List, and Range. The available options differ depending on the selected partitioning type. Only these sub-partitioning types are supported:
|
| Templatize Sub Partition |
A display-only indicator that the system uses the sub partition definition as a sub partition template for each and every partition definition. |
| Sub Partitioning Attributes |
If the Sub -Partitioning check box is selected, use the fields within this grid to specify sub-partitioning parameters. For each sub-partition, complete the following fields: Partition No, Key Field, Key Value, Partition Name, TableSpace Name. |
| Table Partitioning DDL |
This edit box displays the database definition language (DDL) for the table partitioning options specified. Initially, this field is blank. The system populates this field when you click the Generate Partitioning DDL button. If this page has been previously used to define table partitioning for the record, then this box will display the currently defined DDL. |
Index Partitioning
Complete the fields within the Index Partitioning group box to define index partitioning.
Note: Index partitioning is optional; a partitioned table does not require a partitioned index. If you change a table to a partitioned table, its existing indexes are generated as is with no change to the syntax. These “regular” indexes on a partitioned table are known as global non-partitioned indexes.
|
Field or Control |
Definition |
|---|---|
| Index Type |
Select the index type. Options are:
For definitions of these index types, see Partitioning Terminology |
| Index Name |
Specify the index name. To avoid clashes, avoid using the regular PeopleSoft index naming convention for the index name. |
| Partitioning Type |
Select the index partitioning type. Options are:
|
| Index Partitioning Attributes |
For global partitioning index types only. Define the index partitioning attributes using the fields in this grid. The available fields differ depending on the index partitioning type. For hash partitions: Partition No (partition number), Key Field, TableSpace Name For list partitions: Partition No, Key Field, Key Value, Partition Name, TableSpace Name For range: Partition No, Key Field, Key Value, Partition Name, TableSpace Name |
| No of Hash Partitions |
Enter the number of hash partitions to generate. This option is available only when the index partitioning type is set to hash. |
| Index Partitioning DDL |
This edit box displays the database definition language (DDL) for the index partitioning options specified. Initially, this field is blank. The system populates this field when you click the Generate Partitioning DDL button. Initially, this field is blank. The system populates this field when you click the Generate Partitioning DDL button. If this page has been previously used to define index partitioning for the record, then this box will display the currently defined DDL. |
If you create a partitioning index with keys that are identical to an existing global non-partitioned index, in order for the partitioning index to be used, you must disable generation of the previously defined global non-partitioned index using Application Designer by completing these steps:
In Application Designer, open the record.
Select .
Double-click the index name that has keys identical to the partitioned index.
The Edit Index dialog box opens.
Set the Platform radio button to Some.
Deselect the Oracle check box.
Click OK.
DDL Actions
|
Field or Control |
Definition |
|---|---|
| Generate Partitioning DDL |
Click to populate the Table Partitioning DDL and Index Partitioning DDL fields. |
| Clear |
Click to clear all values in the page. |
| Save DDL |
Click to save the DDL to the PeopleTools metadata tables. The DDL is written to these tables: The table partitioning DDL is stored in PS_PTTBLPARTDDL. The index partitioning DDL is stored in PS_PTIDXPARTDDL Only the Table and Index Partitioning DDL is stored. The Table/Index Partitioning attributes are not captured, to prevent synchronization issues with the system catalog. To apply the partition, in Application Designer, use the Maintain Partitioning DDL dialog to apply the partitioning and build (alter) the record. At that point the DDL from the definition is applied, and updates the Oracle database system catalog. |
In PeopleSoft Application Designer, you review and apply partition DDL using the Maintain Partitioning DDL dialog. You can review DDL from the PeopleTools metadata tables or from the system catalog tables, and apply it. If partitioning DDL has not been defined, you can enter it directly here.
Navigation
Image: Maintain Partitioning DDL Dialog Box
This example illustrates the Maintain Partitioning DDL dialog box.
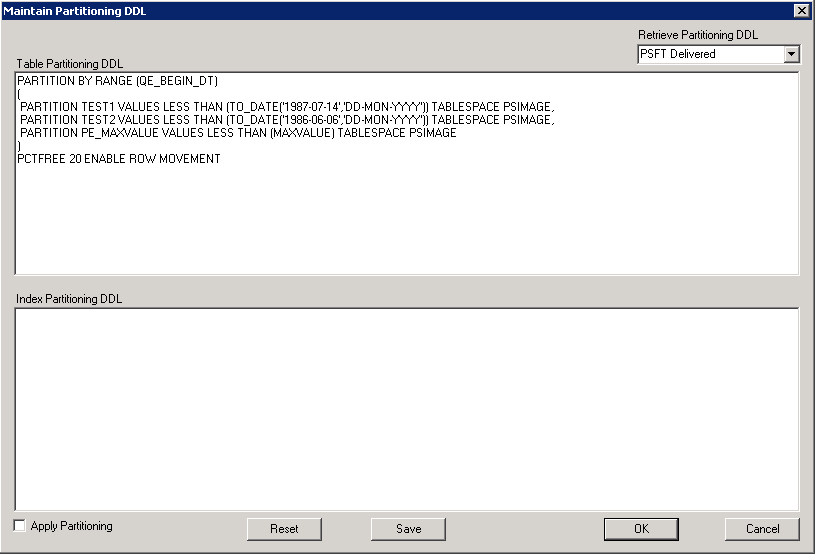
Warning! PeopleTools performs no validation on the SQL that you enter in the table or index partitioning DDL edit boxes. It is your responsibility to ensure that the DDL SQL is correct.
|
Field or Control |
Definition |
|---|---|
| Retrieve Partitioning DDL |
Select the source of the partitioning DDL to view. Options are: PSFT Delivered: Choose this option to view DDL from the PeopleTools Metadata tables. This is the DDL that is generated by the partitioning attributes specified on the Establishing Partitioning Definitions (PPMU_GEN_DDL_PG) in PeopleSoft Internet Architecture. The table and index partitioning DDL is retrieved from the PS_PTTBLPARTDDL and PS_PTIDXPARTDDL tables, respectively. System Catalog Choose this option to view DDL from the Oracle database system catalog table. This enables you to review and apply any customized partitioning that is currently defined on your Oracle database instead of the PeopleTools partitioning DDL. |
| Table Partitioning DDL |
This edit box contains the table partitioning DDL from the PeopleTools Metadata table or the system catalog, depending on the option selected in Retrieve Partitioning DDL. If no table partitioning is currently defined, then the edit box will be blank. You can review and modify the DDL, or enter the DDL if the table has none defined. |
| Index Partitioning DDL |
This edit box contains the index partitioning DDL from the PeopleTools Metadata table or the system catalog, depending on the option selected in Retrieve Partitioning DDL. If no index partitioning is currently defined, then the edit box will be blank. You can review and modify the DDL, or enter the DDL if the table has none defined. |
| Apply Partitioning |
Select this check box to specify that the system apply the partitioning DDL to the CREATE/ALTER TABLE DDL while altering/creating the table for this record. The value set for Apply Partitioning (Y if selected, N if deselected) is stored in the AUXFLAGMASK field of the PSRECDEFN table against the record name and it is used during the build process to determine if partitioning needs to be applied or not. You must build the record definition to update the PeopleTools and system catalog tables. During the build process this is reset to N. |
| Reset |
Click to clear the contents of the Table Partitioning DDL and index Partitioning DDL edit boxes. |
| Save |
Click to store the partitioning DDL in the PeopleTools metadata table. |
| OK |
Click to save and exit the dialog box. |
| Cancel |
Click to exit the dialog box without making any changes. |
Note: The partitioning DDL is not automatically updated for subsequent table customizations.
Record and index partitioning is not migrated as part of the IDE project. If you want to migrate the partitioning metadata along with the record, you will need to complete the following tasks:
Create an IDE project containing the record or records on the source database.
Create a Data Migration project containing the partitioning metadata on the source database and copy the project to file.
Copy the IDE project to the target database.
Load the Data Migration Project on the target database.
Optionally, you can run a compare on the project.
Copy the Data Migration project to the target database.
In Application Designer on the target database, open the project containing the partitioning and alter the records.
To create the Data Migration project on the Source Database:
In PIA for the source database, select PeopleTools, Lifecycle Tools, Migrate Data, Data Migration Workbench.
Click the Add a New Value link.
Enter a project name and description.
Select PTTBLIDXPART as the Data Set Name.
The Insert Data Content page will open.
Enter the criteria for the record or records containing portioning that you want to migrate and click Search.
For search options, refer to Defining ADS Project.
Select the records that you want to migrate from the Search results.
Click the Insert and Return button to insert the selected items.
Click OK on the message that the instances were inserted into the project.
Click Save
Click the Copy to File button.
Before you can Copy to File, the Project Repository must be defined. Define the same project repository on both the source and target database.
To load the Data Migration Project on the Target Database:
In PIA for the source database, select PeopleTools, Lifecycle Tools, Migrate Data, Data Migration Workbench.
Click the Load Project From File link.
Select the file to load and click Load.
If you want to compare the file:
Click the Compare button.
Click Run on the Compare From File page.
Click OK on the Process Scheduler Request page.
Click OK again to return to the Project.
Click Refresh, when the compare has completed, the compare results will be displayed.
For details on viewing compare reports see Viewing Compare Reports.
Click Submit for Copy.
Click Run on the Copy From File page.
Click OK on the Process Scheduler Request page.
Click OK to return to the project.
Click Refresh to verify the copy completed successfully.
To Alter the records in Application Designer:
Note: The tablespace for the partitioned records must exist on the target database.
Open the project in Application Designer on the target database.
Open the record.
Select Tools, Data Administration, Partitioning.
Select Apply Partitioning and click Save.
Click OK.
If you partitioned on indexes, select Tools, Data Administration, Indexes.
Select the Index and click Edit Index DLL.
Select Some for platform and deselect Oracle if it is selected.
Click OK twice.
Save the record.
Repeat steps 2 through 10 for each record in the project that contains partitioning.
Select Build, Project.
Select Alter Tables.
Click the Settings button and go to the Alter tab.
Select Alter even if no changes and Alter by Table Rename.
Set your logging and script options.
Click OK.
Click Build.
Use your SQL tool to view the script and run it.