Release 8.1.5
A67772-01
Library |
Product |
Contents |
Index |
| Oracle8i Administrator's Guide Release 8.1.5 A67772-01 |
|
![]()
![]()
This chapter describes the various aspects of managing tables, and includes the following topics:
Before attempting tasks described in this chapter, familiarize yourself with the concepts in Chapter 12, "Guidelines for Managing Schema Objects".
This section describes guidelines to follow when managing tables, and includes the following topics:
Use these guidelines to make managing tables as easy as possible.
Usually, the application developer is responsible for designing the elements of an application, including the tables. Database administrators are responsible for setting storage parameters and defining clusters for tables, based on information from the application developer about how the application works and the types of data expected.
Working with your application developer, carefully plan each table so that the following occurs:
By specifying the PCTFREE and PCTUSED parameters during the creation of each table, you can affect the efficiency of space utilization and amount of space reserved for updates to the current data in the data blocks of a table's data segment.
See Also: For information about specifying PCTFREE and PCTUSED, see "Managing Space in Data Blocks".
By specifying the INITRANS and MAXTRANS parameters during the creation of each table, you can affect how much space is initially and can ever be allocated for transaction entries in the data blocks of a table's data segment.
See Also: For information about specifying INITRANS and MAXTRANS, see "Setting Storage Parameters".
If you have the proper privileges and tablespace quota, you can create a new table in any tablespace that is currently online. Therefore, you should specify the TABLESPACE option in a CREATE TABLE statement to identify the tablespace that will store the new table.
If you do not specify a tablespace in a CREATE TABLE statement, the table is created in your default tablespace.
When specifying the tablespace to contain a new table, make sure that you understand implications of your selection. By properly specifying a tablespace during the creation of each table, you can:
The following examples show how incorrect storage locations of schema objects can affect a database:
See Also: For information about specifying tablespaces, see "Assigning Tablespace Quotas to Users".
You can parallelize the creation of tables created with a subquery in the CREATE TABLE command. Because multiple processes work together to create the table, performance of the table creation can improve.
See Also: For more information about parallel table creation, see the Oracle8i Parallel Server Concepts and Administration guide.
For information about the CREATE TABLE command, see the Oracle8i SQL Reference.
When you create an unrecoverable table, the table cannot be recovered from archived logs (because the needed redo log records are not generated for the unrecoverable table creation). Thus, if you cannot afford to lose the table, you should take a backup after the table is created. In some situations, such as for tables that are created for temporary use, this precaution may not be necessary.
You can create an unrecoverable table by specifying UNRECOVERABLE when you create a table with a subquery in the CREATE TABLE...AS SELECT statement. However, rows inserted afterwards are recoverable. In fact, after the statement is completed, all future statements are fully recoverable.
Creating an unrecoverable table has the following benefits:
In general, the relative performance improvement is greater for larger unrecoverable tables than for smaller tables. Creating small unrecoverable tables has little effect on the time it takes to create a table. However, for larger tables the performance improvement can be significant, especially when you are also parallelizing the table creation.
Estimating the sizes of tables before creating them is useful for the following reasons:
For example, assume that you estimate the maximum size of a table before creating it. If you then set the storage parameters when you create the table, fewer extents will be allocated for the table's data segment, and all of the table's data will be stored in a relatively contiguous section of disk space. This decreases the time necessary for disk I/O operations involving this table.
Whether or not you estimate table size before creation, you can explicitly set storage parameters when creating each nonclustered table. (Clustered tables automatically use the storage parameters of the cluster.) Any storage parameter that you do not explicitly set when creating or subsequently altering a table automatically uses the corresponding default storage parameter set for the tablespace in which the table resides.
If you explicitly set the storage parameters for the extents of a table's data segment, try to store the table's data in a small number of large extents rather than a large number of small extents.
There are no limits on the physical size of tables and extents. You can specify the keyword UNLIMITED for MAXEXTENTS, thereby simplifying your planning for large objects, reducing wasted space and fragmentation, and improving space reuse. However, keep in mind that while Oracle allows an unlimited number of extents, when the number of extents in a table grows very large, you may see an impact on performance when performing any operation requiring that table.
|
Note: You cannot alter data dictionary tables to have MAXEXTENTS greater than the allowed block maximum. |
If you have such tables in your database, consider the following recommendations:
Separate the Table from Its Indexes Place indexes in separate tablespaces from other objects, and on separate disks if possible. If you ever need to drop and re-create an index on a very large table (such as when disabling and enabling a constraint, or re-creating the table), indexes isolated into separate tablespaces can often find contiguous space more easily than those in tablespaces that contain other objects.
Allocate Sufficient Temporary Space If applications that access the data in a very large table perform large sorts, ensure that enough space is available for large temporary segments and that users have access to this space (temporary segments always use the default STORAGE settings for their tablespaces).
Before creating tables, make sure you are aware of the following restrictions:
Oracle has a limit on the total number of columns that a table (or attributes that an object type) can have (see Oracle8i SQL Reference for this limit.) When you create a table that contains user-defined type data, Oracle maps columns of user-defined type to relational columns for storing the user-defined type data. These "hidden" relational columns are not visible in a DESCRIBE table statement and are not returned by a SELECT * statement. Therefore, when you create an object table, or a relational table with columns of REF, varray, nested table, or object type, the total number of columns that Oracle actually creates for the table may be more than those you specify, because Oracle creates hidden columns to store the user-defined type data. The following formulas determine the total number of columns created for a table with user-defined type data:
num_columns(object_table) = num_columns(object_identifier) + num_columns(row_type) + number of top-level object columns in the object type of table + num_columns(object_type)
num_columns(relational_table) = number of scalar columns in the table + number of object columns in the table + SUM [num_columns(object_type(i))] i= 1 -> n + SUM [num_columns(nested_table(j))] j= 1 -> m + SUM [num_columns(varray(k))] k= 1 -> p + SUM [num_columns(REF(l))] l= 1 -> q where in the given relational table object_type(i) is the ith object type column and n is the total number of such object type columns nested_table(j) is the jth nested_table column and m is the total number of such nested table columns varray(k) is the kth varray column and p is the total number of such varray columns, REF(l) is the lth REF column and q is the total number of such REF columns. num_columns(object identifier) = 1 num_columns(row_type) = 1 num_columns(REF) = 1, if REF is unscoped = 1, if the REF is scoped and the object identifier is system generated and the REF has no referential constraint = 2, if the REF is scoped and the object identifier is system generated and the REF has a referential constraint = 1 + number of columns in the primary key, if the object identifier is primary key based num_columns(nested_table) = 2 num_columns(varray) = 1 num_columns(object_type) = number of scalar attributes in the object type + SUM[num_columns(object_type(i))] i= 1 -> n + SUM[num_columns(nested_table(j))] j= 1 -> m + SUM[num_columns(varray(k))] k= 1 -> p + SUM[num_columns(REF(l))] l= 1 -> q
where in the given object type:
object_type(i) is an embedded object type attribute and n is the total number of such object type attributes, nested_table(j) is an embedded nested_table attribute and m is the total number of such nested table attributes, varray(k) is an embedded varray attribute and p is the total number of such varray attributes, REF(l) is an embedded REF attribute and q is the total number of such REF attributes.
CREATE TYPE physical_address_type AS OBJECT (no CHAR(4), street CHAR(31), city CHAR(5), state CHAR(3)); CREATE TYPE phone_type AS VARRAY(5) OF CHAR(15); CREATE TYPE electronic_address_type AS OBJECT (phones phone_type, fax CHAR(12), email CHAR(31)); CREATE TYPE contact_info_type AS OBJECT (physical_address physical_address_type, electronic_address electronic_address_type); CREATE TYPE employee_type AS OBJECT (eno NUMBER, ename CHAR(60), contact_info contact_info_type); CREATE TABLE employee_object_table OF employee_type;
To calculate number of columns in employee object table, we first need to calculate number of columns required for employee_type:
num_columns(physical_address_type) = number of scalar attributes = 4 num_columns(phone_type) = num_columns(varray) = 1 num_columns(electronic_address_type) = number of scalar attributes + num_columns(phone_type) = 2 + 1 = 3 num_columns(contact_info_type) = num_columns(physical_address_type) + num_columns(electronic_address_type) = 3 + 4 = 7 num_columns(employee_type) = number of scalar attributes + num_columns(contact_info_type) = 2 + 7 = 9 num_columns (employee_object_table) = num_columns(object_identifier) + num_columns(row_type) + number of top level object columns in employee_type + num_columns(employee_type) = 1 + 1 + 1 + 9 = 12
CREATE TABLE employee_relational_table (einfo employee_type); num_columns (employee_relational_table) = number of object columns in table + num_columns(employee_type) = 1 + 9 = 10
CREATE TYPE project_type AS OBJECT (pno NUMBER, pname CHAR(30), budget NUMBER); CREATE TYPE project_set_type AS TABLE OF project_type; CREATE TABLE department (dno NUMBER, dname CHAR(30), mgr REF employee_type REFERENCES employee_object_table, project_set project_set_type) NESTED TABLE project_set STORE AS project_set_nt; num_columns(department) = number of scalar columns + num_columns(mgr) + num_columns(project_set) = 2 + 2 + 2 = 6
To create a new table in your schema, you must have the CREATE TABLE system privilege. To create a table in another user's schema, you must have the CREATE ANY TABLE system privilege. Additionally, the owner of the table must have a quota for the tablespace that contains the table, or the UNLIMITED TABLESPACE system privilege.
Create tables using the SQL statement CREATE TABLE. When user SCOTT issues the following statement, he creates a nonclustered table named EMP in his schema and stores it in the USERS tablespace:
CREATE TABLE emp ( empno NUMBER(5) PRIMARY KEY, ename VARCHAR2(15) NOT NULL, job VARCHAR2(10), mgr NUMBER(5), hiredate DATE DEFAULT (sysdate), sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(3) NOT NULL CONSTRAINT dept_fkey REFERENCES dept) PCTFREE 10 PCTUSED 40 TABLESPACE users STORAGE ( INITIAL 50K NEXT 50K MAXEXTENTS 10 PCTINCREASE 25 );
Notice that integrity constraints are defined on several columns of the table and that several storage settings are explicitly specified for the table.
See Also: For more information about system privileges, see Chapter 24, "Managing User Privileges and Roles". For more information about tablespace quotas, see Chapter 23, "Managing Users and Resources".
To alter a table, the table must be contained in your schema, or you must have either the ALTER object privilege for the table or the ALTER ANY TABLE system privilege.
A table in an Oracle database can be altered for the following reasons:
You can increase the length of an existing column. However, you cannot decrease it unless there are no rows in the table. Furthermore, if you are modifying a table to increase the length of a column of datatype CHAR, realize that this may be a time consuming operation and may require substantial additional storage, especially if the table contains many rows. This is because the CHAR value in each row must be blank-padded to satisfy the new column length.
When altering the data block space usage parameters (PCTFREE and PCTUSED) of a table, note that new settings apply to all data blocks used by the table, including blocks already allocated and subsequently allocated for the table. However, the blocks already allocated for the table are not immediately reorganized when space usage parameters are altered, but as necessary after the change.
When altering the transaction entry settings (INITRANS, MAXTRANS) of a table, note that a new setting for INITRANS applies only to data blocks subsequently allocated for the table, while a new setting for MAXTRANS applies to all blocks (already and subsequently allocated blocks) of a table.
The storage parameters INITIAL and MINEXTENTS cannot be altered. All new settings for the other storage parameters (for example, NEXT, PCTINCREASE) affect only extents subsequently allocated for the table. The size of the next extent allocated is determined by the current values of NEXT and PCTINCREASE, and is not based on previous values of these parameters.
You can alter a table using the SQL command ALTER TABLE. The following statement alters the EMP table:
ALTER TABLE emp PCTFREE 30 PCTUSED 60;
See Also: See "Managing Object Dependencies" for information about how Oracle manages dependencies.
Oracle dynamically allocates additional extents for the data segment of a table, as required. However, you might want to allocate an additional extent for a table explicitly. For example, when using the Oracle Parallel Server, an extent of a table can be allocated explicitly for a specific instance.
A new extent can be allocated for a table using the SQL command ALTER TABLE with the ALLOCATE EXTENT option.
See Also: For information about the ALLOCATE EXTENT option, see Oracle8i Parallel Server Concepts and Administration.
To drop a table, the table must be contained in your schema or you must have the DROP ANY TABLE system privilege.
To drop a table that is no longer needed, use the SQL command DROP TABLE. The following statement drops the EMP table:
DROP TABLE emp;
If the table to be dropped contains any primary or unique keys referenced by foreign keys of other tables and you intend to drop the FOREIGN KEY constraints of the child tables, include the CASCADE option in the DROP TABLE command, as shown below:
DROP TABLE emp CASCADE CONSTRAINTS;
Oracle enables you to drop columns from rows in a table, thereby cleaning up unused, and potentially space-demanding columns without having to export/import data, and recreate indexes and constraints.
You can drop columns you no longer need or mark columns to be dropped at a future time when there is less demand on your system's resources.
The following statement drops unused columns from table t1:
ALTER TABLE t1 DROP UNUSED COLUMNS;
The following restrictions apply to drop column operations:
See Also: For more information about the syntax used for dropping columns from tables, see the Oracle8i SQL Reference.
This section describes aspects of managing index-organized tables, and includes the following topics:
Index-organized tables are tables with data rows grouped according to the primary key. This clustering is achieved using a B*-tree index. B*-tree indexes are special types of index trees that differ from regular table B-tree indexes in that they store both the primary key and non-key columns. The attributes of index-organized tables are stored entirely within the physical data structures for the index.
Index-organized tables provide fast key-based access to table data for queries involving exact match and range searches. Changes to the table data (such as adding new rows, updating rows, or deleting rows) result only in updating the index structure (because there is no separate table storage area).
Also, storage requirements are reduced because key columns are not duplicated in the table and index. The remaining non-key columns are stored in the index structure.
Index-organized tables are particularly useful when you are using applications that must retrieve data based on a primary key. Also, index-organized tables are suitable for modeling application-specific index structures. For example, content-based information retrieval applications containing text, image and audio data require inverted indexes that can be effectively modeled using index-organized tables.
See Also: For more details about index-organized tables, see Oracle8i Concepts.
Index-organized tables are like regular tables with a primary key index on one or more of its columns. However, instead of maintaining two separate storage spaces for the table and B*tree index, an index-organized table only maintains a single B*tree index containing the primary key of the table and other column values.
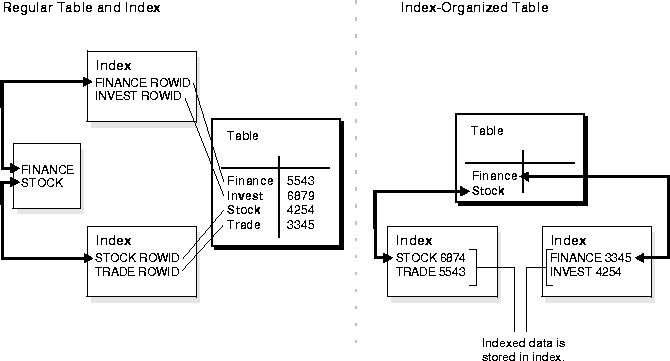
Index-organized tables are suitable for accessing data by way of primary key or any key that is a valid prefix of the primary key. Also, there is no duplication of key values because a separate index structure containing the key values and ROWID is not created. Table 14-1 summarizes the difference between an index-organized table and a regular table.
You can use the CREATE TABLE statement to create index-organized tables; when doing so, you need to provide the following additional information:
The row overflow tablespace is defined as a percentage of the block size. If a row size is greater than the specified threshold value (PCTTHRESHOLD), the non-key column values are stored in the overflow tablespace. In other words, the row is broken at a column boundary into two pieces, a head piece and tail piece. The head piece fits in the specified threshold and is stored along with the key in the index leaf block. The tail piece is stored in the overflow area as one or more row pieces. Thus, the index entry contains the key value, the non-key column values that fit the specified threshold, and a pointer to the rest of the row.
CREATE TABLE docindex( token char(20), doc_id NUMBER, token_frequency NUMBER, token_offsets VARCHAR2(512), CONSTRAINT pk_docindex PRIMARY KEY (token, doc_id)) ORGANIZATION INDEX TABLESPACE ind_tbs PCTTHRESHOLD 20 OVERFLOW TABLESPACE ovf_tbs;
This example shows that the ORGANIZATION INDEX qualifier specifies an index-organized table, where the key columns and non-key columns reside in an index defined on columns that designate the primary key (token,doc_id) for the table.
Index-organized tables can store object types. For example, you can create an index-organized table containing a column of object type mytype (for the purpose of this example) as follows:
CREATE TABLE iot (c1 NUMBER primary key, c2 mytype) ORGANIZATION INDEX;
However, you cannot create an index-organized table of object types. For example, the following statement would not be valid:
CREATE TABLE iot of mytype ORGANIZATION INDEX;
See Also: For more details about the CREATE INDEX statement, see the Oracle8i SQL Reference.
You can create an index-organized table using the AS subquery. Creating an index-organized table in this manner enables you to load the table in parallel by using the PARALLEL option.
The following statement creates an index-organized table (in parallel) by selecting rows from a conventional table, rt:
CREATE TABLE iot(i primary key, j) ORGANIZATION INDEX PARALLEL (DEGREE 2) AS SELECT * FROM rt;
See Also: For details about the syntax for creating index-organized tables, see the Oracle8i SQL Reference.
The overflow clause specified in the earlier example indicates that any non-key columns of rows exceeding 20% of the block size are placed in a data segment stored in the TEXT_COLLECTION_OVERFLOWtablespace.The key columns should fit the specified threshold.
If an update of a non-key column causes the row to decrease in size, Oracle identifies the row piece (head or tail) to which the update is applicable and rewrites that piece.
If an update of a non-key column causes the row to increase in size, Oracle identifies the piece (head or tail) to which the update is applicable and rewrites that row piece. If the update's target turns out to be the head piece, note that this piece may again be broken into 2 to keep the row size below the specified threshold.
The non-key columns that fit in the index leaf block are stored as a row head-piece that contains a ROWID field linking it to the next row piece stored in the overflow data segment. The only columns that are stored in the overflow area are those that do not fit.
You should choose a threshold value that can accommodate your key columns, as well as the first few non-key columns (if they are frequently accessed).
After choosing a threshold value, you can monitor tables to verify that the value you specified is appropriate. You can use the ANALYZE TABLE...LIST CHAINED ROWS statement to determine the number and identity of rows exceeding the threshold value.
See Also: For more information about the ANALYZE statement see the Oracle8i SQL Reference.
In addition to specifying PCTTHRESHOLD, you can use the INCLUDING <column_name> clause to control which non-key columns are stored with the key columns. Oracle accommodates all non-key columns up to the column specified in the INCLUDING clause in the index leaf block, provided it does not exceed the specified threshold. All non-key columns beyond the column specified in the INCLUDING clause are stored in the overflow area.
For example, you can modify the previous example where an index-organized table was created so that it always has the token_offsets column value stored in the overflow area:
CREATE TABLE docindex( token CHAR(20), doc_id NUMBER, token_frequency NUMBER, token_offsets VARCHAR2(512), CONSTRAINT pk_docindex PRIMARY KEY (token, doc_id)) ORGANIZATION INDEX TABLESPACE ind_tbs PCTTHRESHOLD 20 INCLUDING token_frequency OVERFLOW TABLESPACE ovf_tbs;
Here, only non-key columns up to token_frequency (in this case a single column only) are stored with the key column values in the index leaf block.
Creating an index-organized table using key compression enables you to eliminate repeated occurrences of key column prefix values.
Key compression breaks an index key into a prefix and a suffix entry. Compression is achieved by sharing the prefix entries among all the suffix entries in an index block. This sharing can lead to huge savings in space, allowing you to store more keys per index block while improving performance.
You can enable key compression using the COMPRESS clause while:
You can also specify the prefix length (as the number of key columns), which identifies how the key columns are broken into a prefix and suffix entry.
CREATE TABLE iot(i INT, j INT, k INT, l INT, PRIMARY KEY (i, j, k)) ORGANIZATION INDEX COMPRESS;
The preceding statement is equivalent to the following statement:
CREATE TABLE iot(i INT, j INT, k INT, l INT, PRIMARY KEY(i, j, k)) ORGANIZATION INDEX COMPRESS 2;
For the list of values (1,2,3), (1,2,4), (1,2,7), (1,3,5) (1,3,4), (1,4,4) the repeated occurrences of (1,2), (1,3) are compressed away.
You can also override the default prefix length used for compression as follows:
CREATE TABLE iot(i INT, j INT, k INT, l INT, PRIMARY KEY (i, j, k)) ORGANIZATION INDEX COMPRESS 1;
For the list of values (1,2,3), (1,2,4), (1,2,7), (1,3,5), (1,3,4), (1,4,4), the repeated occurrences of 1 are compressed away.
You can disable compression as follows:
ALTER TABLE A MOVE NOCOMPRESS;
See Also: For more details about key compression, see Oracle8i Concepts and the Oracle8i SQL Reference.
Index-organized tables differ from regular tables only in physical organization; logically, they are manipulated in the same manner. You can use an index-organized table in place of a regular table in INSERT, SELECT, DELETE, and UPDATE statements.
You can use the ALTER TABLE statement to modify physical and storage attributes for both primary key index and overflow data segments. All the attributes specified prior to the OVERFLOW keyword are applicable to the primary key index segment. All attributes specified after the OVERFLOW key word are applicable to the overflow data segment. For example, you can set the INITRANS of the primary key index segment to 4 and the overflow of the data segment INITRANS to 6 as follows:
ALTER TABLE docindex INITRANS 4 OVERFLOW INITRANS 6;
You can also alter PCTTHRESHOLD and INCLUDING column values. A new setting is used to break the row into head and overflow tail pieces during subsequent operations. For example, the PCTHRESHOLD and INCLUDING column values can be altered for the docindex table as follows:
ALTER TABLE docindex PCTTHRESHOLD 15 INCLUDING doc_id;
By setting the INCLUDING column to doc_id, all the columns that follow doc_id, namely, token_frequency and token_offsets, are stored in the overflow data segment.
For index-organized tables created without an overflow data segment, you can add an overflow data segment by using the ADD OVERFLOW clause. For example, if the docindex table did not have an overflow segment, then you can add an overflow segment as follows:
ALTER TABLE docindex ADD OVERFLOW TABLESPACE ovf_tbs;
See Also: For details about the ALTER TABLE statement, see the Oracle8i SQL Reference.
Because index-organized tables are primarily stored in a B*-tree index, you may encounter fragmentation as a consequence of incremental updates. However, you can use the ALTER TABLE...MOVE statement to rebuild the index and reduce this fragmentation.
The following statement rebuilds the index-organized table docindex after setting its INITRANS to 10:
ALTER TABLE docindex MOVE INITRANS10;
You can move index-organized tables with no overflow data segment online using the ONLINE option. For example, if the docindex table does not have an overflow data segment, then you can perform the move online as follows:
ALTER TABLE docindex MOVE ONLINE INITRANS 10;
The following statement rebuilds the index-organized table docindex along with its overflow data segment:
ALTER TABLE docindex MOVE TABLESPACE ix_tbs OVERFLOW TABLESPACE ov_tbs;
And in this last statement, index-organized table iot is moved while the LOB index and data segment for C2 are rebuilt:
ALTER TABLE iot MOVE LOB (C2) STORE AS (TABLESPACE lob_ts);
See Also: For more information about the MOVE option, see the Oracle8i SQL Reference.
A key column update is logically equivalent to deleting the row with the old key value and inserting the row with the new key value at the appropriate place to maintain the primary key order.
Logically, in the following example, the employee row for dept_id=20 and e_id=10 are deleted and the employee row for dept_id=23 and e_id=10 are inserted:
UPDATE employees SET dept_id=23 WHERE dept_id=20 and e_id=10;
Just like conventional tables, index-organized tables are analyzed using the ANALYZE statement:
ANALYZE TABLE docindex COMPUTE STATISTICS;
The ANALYZE statement analyzes both the primary key index segment and the overflow data segment, and computes logical as well as physical statistics for the table.
SELECT * FROM DBA_INDEXES WHERE INDEX_NAME= 'PK_DOCINDEX';
SELECT * FROM DBA_TABLES WHERE IOT_TYPE='IOT_OVERFLOW' and IOT_NAME= 'DOCINDEX'
If an ORDER BY clause only references the primary key column or a prefix of it, then the optimizer avoids the sorting overhead as the rows are returned sorted on the primary key columns.
For example, you create the following table:
CREATE TABLE employees (dept_id INTEGER, e_id INTEGER, e_name VARCHAR2, PRIMARY KEY (dept_id, e_id)) ORGANIZATION INDEX;
The following queries avoid sorting overhead because the data is already sorted on the primary key:
SELECT * FROM employees ORDER BY (dept_id, e_id); SELECT * FROM employees ORDER BY (dept_id);
If, however, you have an ORDER BY clause on a suffix of the primary key column or non-primary key columns, additional sorting is required (assuming no other secondary indexes are defined).
SELECT * FROM employees ORDER BY (e_id); SELECT * FROM employees ORDER BY (e_name);
You can convert index-organized tables to regular tables using the Oracle IMPORT/EXPORT utilities, or the CREATE TABLE...AS SELECT statement.
To convert an index-organized table to a regular table:
|
Note: Before converting an index-organized table to a regular table, be aware that index-organized tables cannot be exported using pre-Oracle8 versions of the Export utility. |
See Also: For more details about using IMPORT/EXPORT, see Oracle8i Utilities.