Release 8.1.5
A67778-01
Library |
Product |
Contents |
Index |
| Oracle8i Parallel Server Concepts and Administration Release 8.1.5 A67778-01 |
|
![]()
![]()
Last of the gods, Contention ends her tale.
This chapter provides an overview of Oracle Parallel Server (OPS) tuning issues. It covers the following topics:
"Oracle Parallel Server Management" for more information about using OPSM to administer multiple instances.
See Also:
This section covers the following topics:
With experience, you can anticipate most OPS application problems prior to rollout and testing of the application. Do this using the methods described in this chapter. In addition, a number of tunable parameters can enhance system performance. Tuning parameters can improve system performance, but they cannot overcome problems caused by poor analysis of potential Integrated Distributed Lock Manager (IDLM) lock contention.
Techniques you might use for single-instance applications are also valid in tuning OPS applications. It is still important, however, that you effectively tune the buffer cache, shared pool and all disk subsystems. OPS introduces additional parameters you must understand as well as OPS-specific statistics you must collect.
When collecting statistics to monitor OPS performance, the following general guidelines simplify and enhance the accuracy of your system debugging and monitoring efforts.
It is important to monitor all instances in the same way but keep separate statistics for each instance. This is particularly true if the partitioning strategy results in a highly asymmetrical solution. Monitoring each instance reveals the most heavily loaded nodes and tests the performance of the system's partitioning.
The best statistics to monitor within the database are those kept within the SGA, for example, the "V$" and "X$" tables. It is best to "snapshot" these views over a period of time. In addition you should maintain an accurate history of operating system statistics to assist the monitoring and debugging processes. The most important of these statistics are CPU usage, disk I/O, virtual memory use, network use and lock manager statistics.
In benchmarking or capacity planning exercises it is important that you effectively manage changes to the system setup. By documenting each change and effectively quantifying its effect, you can profile and understand the mechanics of the system and its applications. This is particularly important when debugging a system or determining whether more hardware resources are required. You must adopt a systematic approach for the measurement and tuning phases of a performance project. Although this approach may seem time consuming, it will save time and system resources in the long term.
This section covers the following topics:
To detect whether a large number of lock conversions is taking place, examine the "V$" tables that enable you to see locks the system is up- or and downgrading. The best views for initially determining whether lock contention problems exist are V$LOCK_ACTIVITY and V$SYSSTAT.
To determine the number of lock converts over a period of time, query the V$LOCK_ACTIVITY table. From this you can determine whether you have reached the maximum lock convert rate for the IDLM. If this is the case, you must repartition the application to remove the bottleneck. In this situation, adding more hardware resources such as CPUs, disk drives, and memory is unlikely to significantly improve system performance.
To determine whether there are too many lock conversions, calculate how often the transaction requires a lock conversion operation when a data block is accessed for either a read or a modification. To see this, query the V$SYSSTAT table.
In this way you can calculate a lock hit ratio that may be compared to the cache hit ratio. The value calculated is the number of times data block accesses occur that do not require lock converts, compared to the total number of data block accesses. The lock hit ratio is computed as:
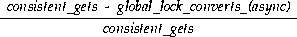
A SQL statement to compute this ratio is:
SELECT (b1.value - b2.value) / b1.value ops_ratio FROM V$SYSSTAT b1, V$SYSSTAT b2 WHERE b1.name = 'consistent gets' AND b2.name = 'global lock converts (async)';
If this ratio drops below 95%, you may not achieve optimal performance scaling as you add additional nodes.
Another indication of too many PCM lock conversions is the ping/write ratio, which is determined as follows:
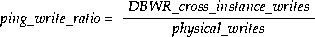
If an application shows performance problems and you determine that excessive lock conversion operations are the major problem, identify the transactions and SQL statements causing problems. When excessive lock contention occurs it is likely caused by one of three problem areas when setting up OPS. These areas are:
This section describes excessive lock conversion rates associated with contention for common resources.
In some cases within OPS, the system may not be performing as anticipated. This may be because the database setup or application design process overlooked some blocks that all instances must access for the entire time that the application runs. This forces the entire system to effectively "single thread" with respect to this resource.
This problem can also occur in single instance cases where all users require exclusive access to a single resource. In an inventory system, for example, all users may wish to modify a common stock level.
In OPS applications, the most common points for contention are associated with contention for a common set of database blocks. To determine whether this is happening, you can query an additional set of V$ tables. These are the V$BH, V$CACHE and V$PING tables.
These tables yield basically the same data, but V$CACHE and V$PING have been created as views joining additional data dictionary tables to make them easier to use. These tables and views examine the status of the current data blocks within an instance's SGA. They also enable you to construct queries to see how many times a block has been pinged between nodes and how many versions of the same data block exist within an SGA. You can use both of these features to determine whether excessive single threading upon a single database block is occurring.
The most common areas of excessive block contention tend to be:
This involves routing transactions altering this table to a single instance and running the system asymmetrically. If you cannot do this, consider partitioning the table and using a data dependent routing strategy.
In tables with random access for SELECT, UPDATE and DELETE statements, each node needs to perform a number of PCM lock up- and downgrades. If these lock conversion operations require disk I/O, they will be particularly expensive and adversely affect performance.
If, however, many of the lock converts can be satisfied by just converting the lock without a disk I/O, a performance improvement can be made. This is often referred to as an I/O-less ping, or a ping not requiring I/O. The reason the lock convert can be achieved without I/O is that the database is able to age data blocks out of the SGA using DBWR as it would with a single instance. This is only likely when the table is very large compared to the size of the SGA. Small tables are likely to require disk I/O, since they are unlikely to age out of the SGA.
With small tables where random access occurs you can still achieve performance improvements by using aggressive checkpointing. To do this, reduce the number of rows stored in a data block by increasing the table PCTFREE value and by reducing the number of data blocks managed by a PCM lock. The process of adjusting the number of rows managed per PCM lock can be performed until lock converts are minimized or the hardware configuration runs out of PCM locks.
The number of PCM locks managed by the IDLM is not an infinite resource. Each lock requires memory on each OPS node, and this resource may be quickly be exhausted. Within an OPS environment, the addition of more PCM locks lengthens the time taken to restart or recover an OPS instance. In environments where high availability is required, the time taken to restart or recover an instance may determine the maximum number of PCM locks you can practically allocate.
In certain situations, excessive lock conversion rates cannot be reduced due to certain constraints. In large tables, clusters, or indexes many gigabytes in size, it becomes impossible to allocate enough PCM locks to prevent high lock convert rates even if these are all false pings. This is mainly due to the physical limitations of allocating enough locks. In this situation, a single PCM lock may effectively manage more than a thousand data blocks.
Where random access is taking place, lock converts are performed even if there is no contention for the same data block. In this situation, tuning the number of locks is unlikely to enhance performance since the number of locks required is far in excess of what can actually be created by the IDLM.
In such cases you must either restrict access to these database objects or else develop a partitioned solution.
Failure of an Oracle instance on one OPS node may be caused by problems that may or may not require rebooting the failed node. If the node fails and requires a reboot or restart, the recovery process on remaining nodes will take longer. Assuming a full recovery is required, the recovery process will be performed in three discreet phases:
The first phase of recovery is to detect that either a node or an OPS instance has failed. Complete node failure or failure of an Oracle instance is detected through the operating system node management facility.
If a complete node failure has occurred, the remaining nodes must remaster locks held by the failed node. On non-failed instances, all database processing stops until recovery has completed. To speed IDLM processing it is important to have the minimum number of PCM locks. This will eventually be reflected in a trade-off between database performance and availability requirements.
Once the IDLM has recovered all lock information, one of the remaining nodes can get an exclusive lock on the failed instance's IDLM instance lock. This node enables the failed instance to provide roll forward/roll backward recovery of the failed instance's redo logs. This is performed by the SMON background process. The time needed to perform this process depends upon the number of redo logs to be recovered. This is a function of how often the system was checkpointed at runtime. Again, this is a trade-off between system runtime performance, which favors a minimum of checkpoints, and system availability requirements.