Release 8.1.5
A67791-01
Library |
Product |
Contents |
Index |
| Oracle8i Replication Release 8.1.5 A67791-01 |
|
![]()
![]()
This chapter explains the concepts and architecture of Oracle Snapshots. This chapter covers the following topics:
Oracle uses snapshots, sometimes referred to as materialized views, to meet the requirements of delivering data to non-master sites in a replicated environment and caching "expensive" queries from a data warehouse. This chapter, and the Oracle8i Replication manual in general, will discuss snapshots for use in a replicated environment.
To learn more about materialized views for data warehousing, see the Oracle8i Tuning book.
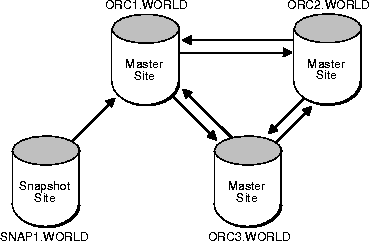
A snapshot is a replica of a target master table from a single point-in-time. Whereas in multimaster replication tables are continuously being updated by other master sites, snapshots are updated by one or more master tables via individual batch updates, known as a refresh, from a single master site (Figure 3-1).
Snapshots also have the option of containing a WHERE clause so that snapshot sites can contain custom data sets, which can be very helpful for regional offices or sales forces that don't require the complete corporate data set.
Oracle offers a variety of snapshots to meet the needs of many different replication (and non-replication) situations; each of these snapshots will be discussed in detail in following sections. You might use a snapshot to achieve one or more of the following:
If one of your goals is to reduce network loads, you can use snapshots to distribute your corporate database to regional sites; instead of the entire company accessing a single database server, user load is distributed across multiple database servers.
While multimaster replication also distributes a corporate database to multiple sites, the networking requirements are greater than replicating with snapshots because of the transaction by transaction nature of multimaster replication. Since multimaster replication can provide real-time or near real-time results, network traffic is much greater, resulting in the need for a dedicated network link.
Snapshots are updated via an efficient batch process from a single master site and have less network requirements and dependency than multimaster replication because of the point-in-time nature of snapshot replication. In addition to not requiring a dedicated network connection, replicating data with snapshots increases data availability by providing local access to the target data. These benefits, combined with mass deployment and data subsetting (both of which also reduce network loads), will greatly enhance the performance and reliability of your replicated database.
Deployment templates allow you to precreate a snapshot environment locally. Deployment templates allow you to quickly and easily deploy snapshot environments to support sales force automation and other mass deployed environments. Parameters allow you to create custom data sets for individual users without changing the deployment template. This technology allows you to rollout a database infrastructure to hundreds or thousands of users.
Snapshots allow you to replicate data based on column and/or row-level subsetting (remember that multimaster replication requires replication of the entire table). Data subsetting allows you to replicate information that only pertains to a particular site. For example, if you have a regional sales office, you might replicate only the data that is needed in that region, thereby cutting down on unnecessary network traffic.
Unlike multimaster replication, snapshots do not require a dedicated network link. Though you have the option of automating the refresh process by scheduling a job, you can manually refresh your snapshot on-demand. This is an ideal solution for sales applications running on a laptop. For example, a developer can integrate the Oracle Replication Management API to refresh on-demand into the sales application. When the sales person has completed the day's order, they simply dial-up the network and use the integrated mechanism to refresh the database, thus transferring the orders to the main office.
As previously mentioned, there are several types of snapshots available to meet a variety of distributed database needs. The following sections describe each snapshot and also describe some environments for which they are best suited.
Primary key snapshots are considered the normal (default) type of snapshot. Primary key snapshots are updateable if the snapshot has been created as part of a snapshot group (see "Snapshot Groups") and "FOR UPDATE" was specified when defining the snapshot. Changes are propagated according to the row changes as identified by the primary key value of the row (vs. the ROWID). The SQL command for creating an updateable, primary key snapshot might look like:
CREATE SNAPSHOT sales.customers FOR UPDATE AS SELECT * FROM sales.customers@dbs1.acme.com;
Primary key snapshots may contain a subquery so that you can create a horizontally partitioned subset of data at the remote snapshot site. This subquery may be as simple as a basic WHERE clause or as complex as a multilevel WHERE EXISTS clause. Primary key snapshots that contain a selected class of subqueries can still be incrementally or fast refreshed (see "Snapshots with Subqueries" for more information). The following is a subquery snapshot with a WHERE clause containing a subquery:
CREATE SNAPSHOT sales.orders REFRESH FAST AS SELECT * FROM sales.orders@dbs1.acme.com o WHERE EXISTS (SELECT 1 FROM sales.customers@dbs1.acme.com c WHERE o.c_id = c.c_id AND zip = 19555);
For backwards compatibility, Oracle supports ROWID snapshots in addition to the default, primary key snapshots. A ROWID snapshot is based on the physical row identifiers (ROWIDs) of the rows in a master table. ROWID snapshots should be used only for snapshots based on master tables from an Oracle7 database, and should not be used when creating new snapshots based on master tables from Oracle8 or greater databases (see "Snapshot Log" for more information on the differences between a ROWID and Primary Key snapshot).
CREATE SNAPSHOT sales.customers REFRESH WITH ROWID AS SELECT * FROM sales.customers@dbs1.acme.com;
If your snapshot does not need to be fast refreshable, then you can create a complex snapshot that allows for a defining SELECT statement that might contain an aggregate or a set operation. Specifically, a snapshot is considered complex when the defining query of a snapshot contains:
In most cases, you should avoid using complex snapshots since they cannot be fast refreshed, which may degrade network performance (see "Refresh Process" for information).
Note:
A sample complex snapshot CREATE statement might look like the following:
CREATE SNAPSHOT scott.snap_employees AS SELECT emp.empno, emp.ename FROM scott.emp@dbs1.acme.com UNION ALL SELECT new_emp.empno, new_emp.ename FROM scott.new_emp@dbs1.acme.com;
For certain applications, you might want to consider the use of a complex snapshot. Figure 3-2 and the following text discuss some issues that you should consider.
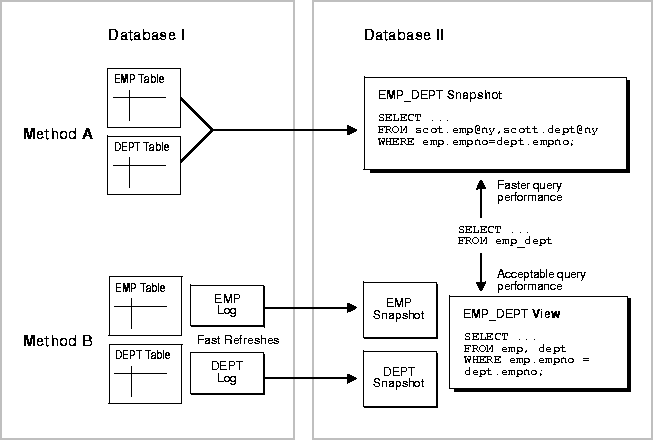
In summary, to decide which method to use:
Any of the previously described types of snapshots can be made read-only by omitting the FOR UPDATE clause (or disabling the equivalent checkbox in the Replication Manager GUI interface). Read-only snapshots use many of the same mechanisms as updateable snapshots, except that they do not need to belong to a snapshot group (see "Snapshot Groups" for more information).
In addition to not needing to belong to a snapshot group, using read-only snapshots eliminates introducing data conflicts originating from a remote snapshot site, though this convenience means that updates cannot be made at the remote snapshot site. You might define a read-only snapshot as:
CREATE SNAPSHOT sales.customers AS SELECT * FROM sales.customers@hq.acme.com
In certain situations, you will want your snapshot to reflect a horizontally or vertically partitioned segment of the master table's data. If you use deployment templates to build your snapshots, you can define vertical data subsets to replicate data along column boundaries (for additional information on vertical partitioning, see "Vertical Partitioning" ). Some reasons to consider partitioning data are:
In many instances, the above objectives can be met by using a simple WHERE clause. For example, the following DDL creates a snapshot that contains information about customers who are in the 19555 zip code:
CREATE SNAPSHOT sales.customers AS SELECT * FROM sales.customers@dbs1.acme.com WHERE zip = 19555;
The above example works very well for individual snapshots that don't have any referential constraints to other snapshots. But, if you want more than just the customer information, maintaining and defining these snapshots could be difficult.
Consider the scenario where you have three tables (Customer, Order, and Order_line) and you want to create three corresponding snapshots that maintain the referential integrity of these master tables. If a salesperson wants to retrieve the customer information, pending orders, and the associated order lines for all customers in the 19555 zip code, the most efficient method is to create snapshots with one or more subqueries in the defining query of the snapshot.
The Customer snapshot has a very simple defining query since the Customer master table is at the top of the hierarchy:
CREATE SNAPSHOT sales.customers AS SELECT * FROM sales.customers@dbs1.acme.com WHERE zip = 19555;
When you create the Orders snapshot, you want to retrieve all of the orders for the customers located in the 19555 zip code. If you look at the relationships in Figure 3-3, you will notice that the Customer and Orders table are related via the C_ID column. The following DDL will create the Orders snapshot with the appropriate data set:
CREATE SNAPSHOT sales.orders AS SELECT * FROM sales.orders@dbs1.acme.com o WHERE EXISTS (SELECT c_id FROM sales.customers@dbs1.acme.com c WHERE o.c_id = c.c_id AND c.zip = 19555);
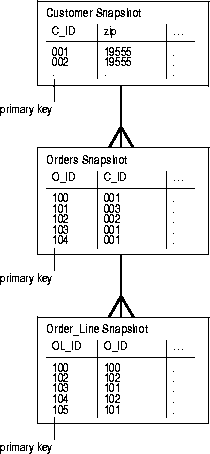
Creating the Order_line snapshot uses the same approach as the Orders snapshot, except that you have one additional subquery. Notice in Figure 3-3 that the Order_line and the Order tables are related via the O_ID row. The following DDL will create the Order_line snapshot with the appropriate data set:
CREATE SNAPSHOT sales.lines AS SELECT * FROM sales.order_line@dbs1.acme.com ol WHERE EXISTS (SELECT o_id FROM sales.orders@dbs1.acme.com o WHERE ol.o_id = o.o_id AND EXISTS (SELECT c_id FROM sales.customers@dbs1.acme.com c WHERE o.c_id = c.c_id AND c.zip = 19555));
The snapshots created by these three DDL statements are each fast refreshable. If new customers are identified in the target zip code, the new data will be propagated to the snapshot site during the subsequent refresh process. Likewise, if a customer is removed from the target zip code, the appropriate data will also be removed from the snapshot during the subsequent refresh process.
The subqueries in these snapshot examples walk-up the many-to-one references from the child to the parent tables. The snapshots will be populated with data that satisfies the defining query for each of these snapshots and will be refreshed only with data that satisfies these defining queries.
While the previous examples greatly enhance the flexibility of snapshots, there are certain limitations in the above example. Consider if the salesperson changed territories or the existing territory was assigned an additional zip code; the above snapshot definitions would need to be altered or recreated since the zip code 19555 was "hard coded" in the previous snapshot definitions.
With this in mind, if "assignment" tables are used in conjunction with subquery subsetting, changes to a snapshot environment can easily be controlled by the DBA. For example, consider the customer/salesperson relationship in Figure 3-4.
In this example, a salesperson is assigned their customers based on the Assignment table. If new salespersons are hired or other salespersons leave, the existing customers can be assigned to their new salesperson by simply modifying the contents of the assignment table. Besides creating a single point of administration, assignment tables used in conjunction with subquery subsetting enables this easy administration to remain secure. For example, salesman #1001 will not be able to view the customer information of other salesmen (very important if the customer information contains sensitive data).
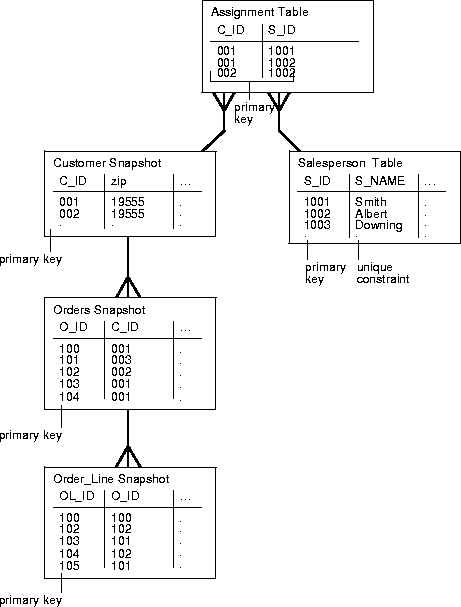
Considering the relationships pictured in Figure 3-4, if the Orders snapshot's defining query was specified as (pay special attention to the 'gsmith' value in the last line of the CREATE SNAPSHOT statement):
CREATE SNAPSHOT sales.orders AS SELECT * FROM sales.orders@hq.acme.com o -- conditions for customers WHERE EXISTS ( SELECT c_id FROM sales.customers@hq.acme.com c WHERE o.c_id = c.c_id AND EXISTS ( SELECT * FROM sales.assignments@hq.acme.com a WHERE a.c_id = c.c_id AND EXISTS ( SELECT * FROM sales.salespersons@hq.acme.com s WHERE a.s_id = s.s_id AND s.s_id = 'gsmith')));
then the Orders snapshot will be populated with order data for the customers that are assigned to salesperson 'gsmith'.
With this flexibility, managers can easily control snapshot data sets by making simple changes to the assignment table (without requiring a DBA to modify any SQL). For example, if the specified salesperson was assigned two new customers, the manager would simply assign these two new customers to the salesperson in the assignment table. After the next fast snapshot refresh, the data for these two customers will be propagated to the target snapshot site, such as the salesperson's laptop (see "Refresh Types" for more information). Conversely, if a customer was taken away from the specified salesperson, all data pertaining to the specified customer would be removed from the snapshot site after the next refresh and the salesperson would no longer be able to access that information.
Snapshots with a subquery must be of the primary key type (see "Primary Key" for more information about primary key snapshots). Additionally, the defining query of a snapshot with a subquery is subject to several other restrictions to preserve the snapshot's fast refresh capability.
|
Note: To determine whether a snapshot's subquery satisfies the many restrictions detailed in Table 3-1, create the snapshot with "fast refresh". Oracle will return errors if the snapshot violates any restrictions for simple subquery snapshots. If you specify "force refresh," you may not receive any errors because Oracle will automatically send data for a complete refresh. |
The mechanisms used in snapshot replication are depicted in Figure 3-5. Some of these mechanisms are optional and are used only as needed to support the created snapshot environment. For example, if you have a read-only snapshot, then you will not have an updatable snapshot log or internal trigger at the remote site. Also, if you have a complex snapshot that cannot be fast refreshed, then you may not have a snapshot log at the master site.

The three mechanisms displayed in Figure 3-6 are required at the master site to support fast refreshing of snapshots.
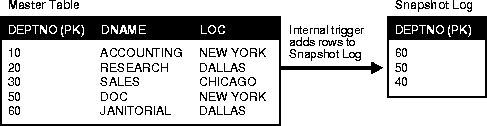
The master table is the basis for the snapshot and is located at the target master site. This table may be involved in both snapshot replication and multimaster replication (remember that a snapshot points to only one master site).
Changes made to the master table as recorded by the snapshot log will be propagated to the snapshot during the refresh process.
When changes are made to the master table using DML, an internal trigger records the primary key and/or ROWID of the rows affected and filter column1 information in the snapshot log. This is an internal trigger that is automatically activated when you create a snapshot log for the target master table.
When you create a snapshot log for a master table, Oracle creates an underlying table as the snapshot log. A snapshot log holds the primary keys and optionally the ROWIDs of rows that have been updated in the master table. A snapshot log can also contain filter columns to support fast refreshes of snapshots with subqueries (see footnote 1). The name of a snapshot log's table is MLOG$_master_table_name. The snapshot log is created in the same schema as the target master table. A single snapshot log for a single master table can support any number of snapshots.
As described in the previous section, the internal trigger adds the information to the snapshot log whenever a DML transaction has taken place at the target master table.
There are three types of snapshot logs:
A combination snapshot log works in the same manner as the primary key and ROWID snapshot log, except both the primary key and the ROWID of the affected row are recorded.
Though the difference between snapshot logs based on primary keys and ROWIDs is very small (one records rows affected using the primary key, while the other records affected rows using the physical ROWID), the practical impact is quite large. Using ROWID snapshots and snapshot logs will make reorganizing and/or truncating your master tables very difficult as it will prevent your ROWID snapshots from being FAST refreshed. If you reorganize or truncate your master table, your ROWID snapshot will need to be COMPLETE refreshed since the ROWIDs of the master table will have changed.
When a snapshot is created, several additional mechanisms are created at the snapshot site to support the snapshot. Specifically, a base table, at least one index, and optionally a view are created. If you create an updateable snapshot, an internal trigger and a local log (updateable snapshot log) are also created at the snapshot site.
Beginning with Oracle8i release 8.1.5, the base table is the actual snapshot (no view is required). The base table will have the name that you have specified during the creation process.
When the snapshot site compatibility setting is less than 8.1, the base table is the underlying support mechanism for the view described in the previous section (the compatibility setting is defined in the INIT.ORA file - see the Oracle8i Reference manual for more information). When the base table is the support mechanism for the view, it has the name SNAP$_Snapshot_Name.
Any indexes generated when you create the snapshot are created on the base table.
A view is only created to support snapshot replication with Oracle8 release 8.0 and earlier (if the snapshot sites compatibility setting is less than 8.1, then a view will always be created). If a view is created, the view will have the same name specified in the CREATE SNAPSHOT statement (i.e. CREATE SNAPSHOT sales.snap_customers AS ...).
At least one index is created at the remote snapshot site for each snapshot created. This index corresponds to the primary key of the target master table. Additional indexes may be created by Oracle at the remote snapshot site to support fast refreshing of snapshots with subqueries. The index has the name I_SNAP$_Snapshot_Name.
A local update log (USLOG$_Materialized_View_Name) is used to determine what data needs to be pulled from the target master table. A read-only snapshot does not require this local log.
Just like the internal trigger at the master site, the internal trigger at the snapshot site records DML changes applied to an updateable snapshot in the USLOG$_Snapshot_Name log.
In addition to the snapshot mechanisms described in the previous section, there are several additional mechanisms that organize the snapshots at the snapshot site. These mechanisms maintain organizational consistency between the snapshot site and the master site as well as transactional (read) consistency with the target master group.
These mechanisms are snapshot groups and refresh groups.
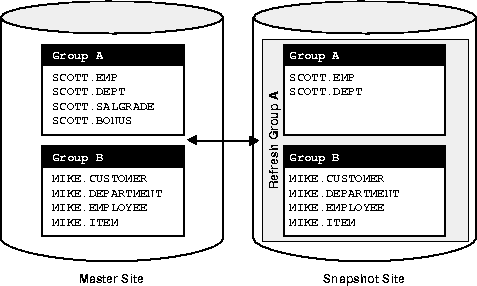
A snapshot group in an advanced replication system maintains a partial or complete copy of the objects at the target master group (snapshot groups cannot span across master group boundaries). Figure 3-7 displays the correlation between Groups A and B at the master site and Groups A and B at the snapshot site.

Group A at the snapshot site (Figure 3-7) contains only some of the objects in the corresponding Group A at the master site. Group B at the snapshot site contains all objects in Group B at the master site. Under no circumstances, however, could Group B at the snapshot site contain objects from Group A at the master site. As illustrated in Figure 3-7, snapshot groups are named the same as the master groups that the snapshot group is based on. For example, a snapshot group based on a "PERSONNEL" master group will also be named "PERSONNEL."
In addition to maintaining organizational consistency between snapshot sites and master sites, snapshot groups are required for supporting updateable snapshots. If a snapshot does not belong to a snapshot group, then it can only be a read-only snapshot.
If you need to support multiple users within the same database at a snapshot site, you may want to create multiple snapshot groups for the target master group. This enables you to define different subqueries for your snapshot definitions in each snapshot group, allowing each user to access only his or her subset of data.
Defining multiple data sets with different snapshot groups is more secure than defining different WHERE clauses for multiple views supporting different users. Since you can grant users access to individual snapshot objects, you can control what the user views, deletes, and inserts; with a WHERE clause in a view, you can only control what a user views, but not the deleting or inserting of data.
Defining multiple snapshot groups gives you the ability to control data sets at a group level. For example, if you create different snapshot groups for the HR, PERSONNEL, and MANUFACTURING departments, you can administer each department as a group (versus individual objects). For example, you can refresh the snapshots as a departmental group or you can drop the objects as a group.
With respect to dropping a department, if you group all data sets into a single snapshot group and the MANUFACTURING department needs to be removed from the data set, you will need to drop and re-create the snapshot with a WHERE clause that does not contain the MANUFACTURING department. In addition to causing you additional work, it could disrupt other departments from accessing their data. Compartmentalizing your data into separate groups allows you to efficiently manage the data since changes to one group will not affect another group.
To accommodate multiple snapshot groups at the same snapshot site that are based on a single master group, you can specify a group owner as an additional identifier when defining your snapshot group.
After you have defined your snapshot group with the addition of a group owner, you add your snapshot objects to the target snapshot group by defining the same group owner. When using a group owner, remember that each snapshot object must have a unique name. If a single snapshot site will have multiple snapshot groups based on the same master group, a snapshot group's object names cannot have the same name as snapshot objects in another snapshot group. To avoid conflicting names, you might want to append the group owner name to the end of your object name. For example, if you have group owners "HR" and "PERSONNEL", you might name the "EMP" snapshot object as "EMP_HR" and "EMP_PERSONNEL," respectively.
Additionally, all snapshot groups that are based on the same master group at a single snapshot site must "point" to the same master site. For example, if the SCOTT_MG snapshot group owned by HR is based on the associated master group at the ORC1.WORLD master site, then the SCOTT_MG snapshot group owned by PERSONNEL must also be based on the associated master group at ORC1.WORLD, assuming that the HR and PERSONNEL owned groups are at the same snapshot site.
See the "Using a Group Owner" section in Chapter 7 of the Oracle8i Replication API Reference manual for more information on defining a group owner using the replication management API.
To preserve referential integrity and transactional (read) consistency among multiple snapshots, Oracle has the ability to refresh individual snapshots as part of a refresh group. After refreshing all of the snapshots in a refresh group, the data of all snapshots in the group will correspond to the same transactionally consistent point-in-time.
As illustrated in Figure 3-8, a refresh group can contain snapshots from more than one snapshot group to maintain transactional (read) consistency across master group boundaries.
While you may want to define a single refresh group per snapshot group, it may be more efficient to use one large refresh group that contains objects from multiple snapshot groups (such a configuration reduces the amount of "overhead" needed to refresh your snapshots). A refresh group can contain up to 400 snapshots (the number of snapshots that a refresh group can contain has increased from earlier versions of Oracle Server).
One configuration that you want to avoid is using multiple refresh groups to refresh the contents of a single snapshot group. Using multiple refresh groups to refresh the contents of a single snapshot group may introduce inconsistencies in the snapshot data, which may cause referential integrity problems at the snapshot site. This type of configuration should only be used when you have in-depth knowledge of the database environment and can prevent any referential integrity problems.
A snapshot's data does not necessarily match the current data of its master table. A snapshot is a transactionally (read) consistent reflection of its master table as the data existed at a specific point-in-time (i.e. at creation or at a refresh interval). To keep a snapshot's data relatively current with the data of its master table, the snapshot needs to be periodically refreshed. A snapshot refresh is an efficient batch operation that makes that snapshot reflect a more current state of its master table.
You must decide how and when to refresh each snapshot to make it more current. For example, snapshots based on master tables that applications update often require frequent refreshes. In contrast, snapshots based on relatively static master tables usually require infrequent refreshes. In summary, you must analyze application characteristics and requirements to determine appropriate snapshot refresh intervals.
To refresh snapshots, Oracle supports several refresh types and methods of initiating a refresh.
Oracle can refresh a snapshot using either a FAST, COMPLETE, or FORCE refresh.
To perform a complete refresh of a snapshot, the server that manages the snapshot executes the snapshot's defining query. The result set of the query replaces the existing snapshot data to refresh the snapshot. Oracle can perform a complete refresh for any snapshot. Depending on the amount of data that satisfies the defining query, a complete refresh can take a substantially longer amount of time to perform than a fast refresh.
To perform a fast refresh, the server that manages the snapshot first identifies the changes that occurred in the master since the most recent refresh of the snapshot and then applies them to the snapshot. Fast refreshes are more efficient than complete refreshes when there are few changes to the master because the participating server and network replicate less data. Fast refreshes are available for snapshots only when the master table has a snapshot log.
If a fast refresh is not possible, an error is raised and the snapshot(s) will not be refreshed.
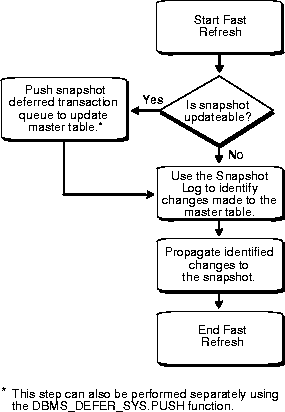
To perform a force refresh of a snapshot, the server that manages the snapshot first tries to perform a fast refresh. If a fast refresh is not possible, then Oracle performs a complete refresh. Use the Force setting when you want the snapshot to refresh if the fast refresh fails.
When creating a refresh group, administrators may configure the group so that Oracle can automatically refresh its snapshots at scheduled intervals. Conversely, administrators may omit scheduling information so that the refresh group needs to be refreshed manually or "on-demand" (manual refreshing is an ideal solution when refreshing is performed with a dial-up network connection).
When you create a refresh group for scheduled refreshing, you must specify a scheduled refresh interval for the group during the creation process. When setting a group's refresh interval, consider the following characteristics:
Scheduled snapshot refreshes may not always be the appropriate solution for your environment/situation. For example, immediately following a bulk data load into a master table, dependent snapshots will no longer represent the master table's data. Rather than wait for the next scheduled automatic group refreshes, you might want to manually refresh dependent snapshot groups to immediately propagate the new rows of the master table to associated snapshots.
You may also want to refresh your snapshots on-demand when your snapshots are integrated with a sales force automation system located on a disconnected laptop. Developers designing the sales force automation software can create an application control (i.e. a button) that a sales person can use to refresh the snapshots when they are ready to transfer the day's orders to the server after establishing a dial-up network connection.
Most problems encountered with snapshot replication come from not preparing the environment properly. There are four essential tasks that you must perform before you begin creating your snapshot environment: create the necessary schema, create the necessary database links, assign the appropriate privileges, and allocate sufficient job processes.
Oracle's Replication Manager setup wizard automatically performs the tasks that are described below. The following is provided for your understanding of the replication environment and especially for those that use the Replication Management API. After the setup wizard is executed, you need to make sure to create the necessary snapshot logs (see "Create a Snapshot Log"). See "Setting Up Snapshot Site" for instructions on using Replication Manager to setup your snapshot site. You are encourage to use Replication Manager whenever possible.
If you are not able to use Replication Manager, review the "Setup Snapshot Site" section in chapter 2 of the Oracle8i Replication API Reference for detailed instructions on setting up your snapshot site using the Replication Management API.
The following sections describe what the Replication Manager setup wizard or the script in the Oracle8i Replication API Reference will do to setup your snapshot site.
Each snapshot site needs several users to perform the administrative and refreshing activities at the snapshot site. You will need to create and grant the necessary privileges to the snapshot administrator and to the refresher.
You will need equivalent proxy users at the target master site to perform tasks on behalf of the snapshot site users. Usually, a proxy snapshot administrator and a proxy refresher will be created.
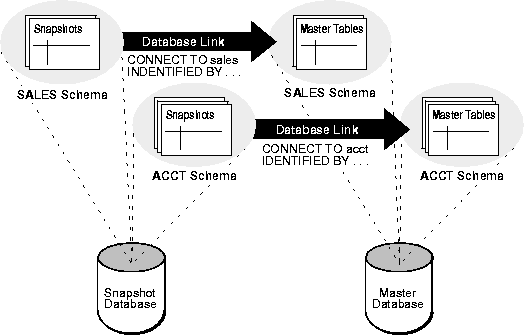
A schema containing a snapshot in a remote database should correspond to the schema that contains the master table in the master database. Therefore, identify the schemas that contain the master tables that you want to replicate with snapshots. Once you have identified the target schemas at the master database, create the corresponding accounts with the same names at the remote database. For example, if all master tables are in the SALES schema of the DB1 database, create a corresponding SALES schema in the snapshot database DB2. (If you are reviewing the steps in Oracle8i Replication API Reference manual, the necessary schema(s) are created as part of the script described in chapter 5.)
The defining query of a snapshot may use one or more database links to reference remote table data. Before creating snapshots, the database links you plan to use must be available. Furthermore, the account that a database link uses to access a remote database defines the security context under which Oracle creates and subsequently refreshes a snapshot.
To ensure proper behavior, a snapshot's defining query must use a database link that includes an embedded user name and password in its definition; you cannot use a public database link when creating a snapshot. A database link with an embedded name and password always establishes connections to the remote database using the specified account. Additionally, the remote account that the link uses must have the SELECT privileges necessary to access the data referenced in the snapshot's defining query.
Before creating your snapshots, you need to create several administrative database links. Specifically, you should create a PUBLIC database link from the snapshot site to the master site (this makes defining your private database links easier since you don't need to include the USING clause in each link). You will also need private database links from the snapshot administrator to the proxy administrator and from the propagator to the receiver (if you use the Replication Manager Setup Wizard, these database links will be created for you). See "Security Setup for Snapshot Replication" for more information on snapshot users and database links. Additionally, see Chapter 2 of the Oracle8i Replication API Reference manual.
After the administrative database links have been created, a private database link needs to be created connecting each replicated snapshot schema at the snapshot database to the corresponding schema at the master database. Be sure to embed the associated master database account information in each private database link at the snapshot database. For example, the SALES schema at a snapshot database DB2 should have a private database link DB1 that connects using the SALES username and password.
Both the creator and the owner of (schema that contains) the snapshot must be able to issue the defining SELECT statement of the snapshot. If a user other than the replication or snapshot administrator will be creating the snapshot, then that user must have the CREATE snapshot privilege and the appropriate SELECT privileges to execute the defining SELECT statement. (If you are reviewing the steps in Oracle8i Replication API Reference manual, the necessary privileges are granted as part of the script described in chapter 5.)
In order to keep the size of the deferred transaction queue in check, you need to schedule a purge operation to remove all successfully completed deferred transactions from the deferred transaction queue. This operation may have already been performed at the master site; re-scheduling the purge operation will not harm the master site, but may change the purge scheduling characteristics.
Often referred to as a scheduled link, scheduling a push at the snapshot site will automatically propagate and deferred transactions at the snapshot site to the associated target master site. Typically, there will only be a single scheduled link per snapshot group at a snapshot site (since a snapshot group only has a single target master site).
It is important that you have allocated sufficient SNP background processes to handle the automatic refreshing of your snapshots. Since your snapshot site will typically have only a single scheduled link to the target master site, the snapshot site will only require a single SNP process, but to handle additional activity, you may want to allocate at least two SNP processes at the snapshot site.
The SNP processes are defined using the job_queue_processes parameter in the init.ora file for your database. To set your SNP processes, you can either use Instance Manager, a component of Oracle Enterprise Manager, or manually edit the init.ora file.
The SNP job interval determines how often your SNP processes "wake-up" to execute any pending operations (such as pushing a queue). While the default value of 60 seconds is adequate for most replicated environments, you may need to adjust this value to maximize performance for your individual requirements. For example, if you want to propagate changes to the target master site every 20 seconds, a job interval of 60 seconds would not be sufficient. On the other hand, if you need to propagate your changes once a day, you may only want your SNP process to check for a pending operation once an hour.
You will often use Instance Manager to configure the SNP processes and interval at the snapshot site if you have a dedicated network link to the snapshot site or you are able to schedule the network link. This is required because Instance Manager will, in most cases, not be at the snapshot site and thus the configuration will need to be done remotely from the master site (if remote configuration is not possible, see the next section).

Complete the following to set your job processes using Instance Manager (see the Oracle Enterprise Manager Administrator's Guide for more information using Instance Manager to configure your database):
2 in the Value field next to the job_queue_process Parameter Name.
job_queue_interval as necessary (entered values should be in seconds).
You will have the opportunity to save this configuration; this is helpful if you use Instance Manager to manage your database. See the Oracle Enterprise Manager Administrator's Guide and/or online documentation for more information on using Instance Manager.
If you do not have access to Instance Manager, you can manually edit the init.ora file. Use a text editor, such as Notepad, EMACS, or vi (depending on your operating system), to modify the contents of your init.ora file.
In most cases, you will see all of the parameters used in replication grouped together under an Oracle replication heading in your init.ora file.

After you have modified the contents of your init.ora file, you will need to restart your database with these new settings (see Oracle8i Administrator's Guide for information on restarting your database).
Before creating snapshot groups and snapshots for a remote snapshot site, make sure to create the necessary snapshot logs at the master site. A snapshot log is necessary for every master table that supports at least one snapshot with fast refreshes.
To create a snapshot log at the master site:
You can optionally press the Create Snapshot Log button on the toolbar.
If your snapshot log needs to support both Row ID and Primary Key snapshots, be sure that you enable both the Row ID and the Primary Key checkboxes.
See the following section, "Using Filter Columns" for more information on filter columns.
Press the Help button to see additional information about the available storage settings.
Filter columns are an essential component when using subquery snapshots (see "Data Subsetting with Snapshots" for more information). A filter column must be defined in a snapshot log (see "Create a Snapshot Log") that is supporting a snapshot that references a column in a WHERE clause and is not part of the equijoin (see "Restrictions for Snapshots with Subqueries" for additional information).
Consider the following DDL:
1) CREATE SNAPSHOT sales.orders AS 2) SELECT * FROM sales.orders@dbs1.acme.com o 3) WHERE EXISTS 4) (SELECT c_id FROM sales.customers@dbs1.acme.com c 5) WHERE o.c_id = c.c_id AND zip = 19555);
If you pay close attention to line 5 of the above DDL, you will see that three columns are referenced in the WHERE clause. Columns o.c_id and c.c_id are referenced as part of the equijoin clause; the column zip is an additional filter column. You will therefore need to create a filter column in the snapshot log for the zip column of the sales.customers table.
You are encouraged to analyze the defining queries of your planned snapshot(s) and identify which filter columns will need to be created in your snapshot log(s). If you try to create or refresh a snapshot that requires a filter column before creating the snapshot log containing the filter column, your snapshot creation or refresh may fail.
Snapshot environments can be created in several different ways and from several different locations. In most cases, you will want to use deployment templates to locally pre-create a snapshot environment that will be individually deployed to the target snapshot site.
You can also individually create the snapshot environment by establishing a connection to the snapshot site and building the snapshot environment directly.
See Chapter 4, "Creating Snapshots with Deployment Templates" for information on using deployment templates to centrally create a snapshot environment using Replication Manager.
See Chapter 5, "Directly Create Snapshot Environment" for information on individually creating the snapshot environment with a direct connection to the remote snapshot site using Replication Manager.
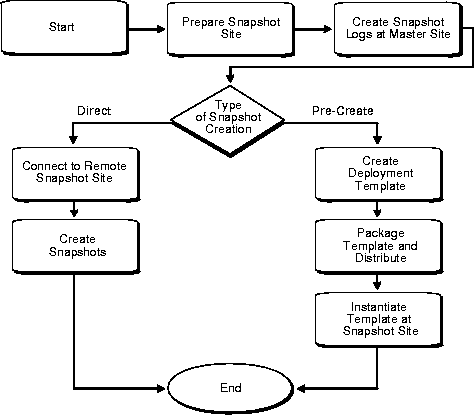
See Chapter 4 of the Oracle8i Replication API Reference manual for information on using deployment templates to centrally pre-create a snapshot environment using the Replication Management API.
See Chapter 5 of the Oracle8i Replication API Reference manual for information on individually creating the snapshot environment with a direct connection to the remote snapshot site using the Replication Management API.
1
Filter columns are required when the snapshot contains a subquery. See "Data Subsetting with Snapshots" for information on subquery snapshots and "Using Filter Columns" for more information.