Understanding the Batch Architecture Process Flow
this topic discusses:
Global Payroll modes.
Payee selection.
Calculation (technical).
Arrays used in batch processing (technical).
Batch processing output tables.
Global Payroll processes payees and elements by utilizing a very specific processing order. All the components of the system that you define, such as payees, elements, and rules, come together at the time a payroll or absence run is executed.
Think of Global Payroll as having two primary modes:
Setup mode
During the setup mode, you define the various elements, rules, and other system configurations that make up your payroll system.
Processing mode
It is during the processing mode that Global Payroll looks at all the setup information that you've defined, along with any data that you've entered, and processes it according to your specifications.
Note: The discussion in this section about the batch architecture process flow is a very high-level overview of the process. Each phase of the process is discussed in greater detail later in this product documentation.
When you run a payroll or absence batch process, the first program that the system calls is the Service program. The Service program acts as the coordinator between the selection of payees to be processed and the calculation process. The Service program initiates the payee selection process. Once the payees are selected, the Service program passes control of the data that was created during the payee selection phase to the Calculation program.
This diagram shows how the Service program coordinates the payee selection and calculation phases.
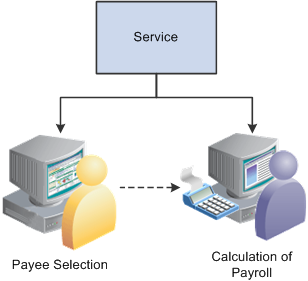
Before you can process a payroll, you must identify the payees that are to be processed. In Global Payroll, this is called payee selection or payee identification. Payee selection is required in payroll and absence processing.
The payee selection process is separate from the calculation process. No rules are defined for payee selection that is associated with a payroll or absence calculation. The payee selection phase of the process only identifies the payees and creates the data that is later passed on to the calculation phase.
The pay calendar acts as the controlling function that coordinates and defines the payee selection and calculation processes. The Payroll/Absence Run Control also controls payee selection.
On the calendar definition page, you indicate whether you want active payees or listed payees selected. If you select active payees, you are offered a number of other defining choices. If you select listed payees, you insert the employee ID numbers for the payees that you want to select.
The payee selection process also uses retroactive and period segmentation triggers. Retroactive triggers can cause other pay periods besides the current pay period to be processed for a particular payee. Period segmentation triggers can cause the pay period to be split into segments, thus producing multiple calculations.
The result of the payee selection process is the creation of Process Status (GP_PYE_PRC_STAT) and Segment Status (GP_PYE_SEG_STAT) records. A Process Stat record is created for each payee for each calendar (including retroactive processes). A Segment Stat record is created for each payee for each segment in each calendar. The Process Stat and Segment Stat records are the storage places for the payee data that is related to the calendar that is being run. Essentially, the Process Stat and Segment Stat records list the payees and all the pay periods that are to be processed, including the current pay period and possible retroactive periods.
Once payees have been selected, the Service program passes control to the calculation phase of the process. The calculation phase uses the data that is stored in the Process Stat and Segment Stat records as the beginning set of payee data.
The first step in calculating the payroll is to load process-level data into arrays, including data from sources such as pay entity, pay group, eligibility group, calendar, and the process list. This system data is more static than the payee-specific data.
The calculation programs process each payee, using the Payee Process Stat records and Payee Segment Stat Records that were created during the payee selection phase. The program loads all the payee-level data into payee arrays, including data from table sources such as Job, Person, Compensation, Overrides, and Positive Input.
The process that loads the payee-level data into the arrays also refreshes its data or reset pointers to data between every payment so that:
The correct effective-dated information is always used.
The correct year-to-date balances are always reflected.
Any positive input—such as absence data—is always forwarded into the next payment.
At this stage, all the process-level and payee-level data is loaded into arrays, ready for processing.
Next, the calculation phase checks element eligibility.
The calculation program calls the Process List Manager program, which looks to the process list to determine which elements will be processed and in what order.
When the Process List Manager encounters an element to be processed, it calls the PIN Manager (a program that manages individual elements) to process each element that passed the element eligibility check earlier in the process. The PIN Manager references the PINV array during this process. The PINV array stores the results of all element resolutions during payroll batch processing. If the data stored in PINV indicates that an element has not already been resolved, the PIN Manager calls a PIN resolution program (a program that processes specific types of elements).
A separate array, called PINW, stores the accumulator data that is resolved during batch processing.
Each PIN resolution program resolves a specific type of element. For example, one PIN resolution program might resolve earning elements while another might resolve formula elements. The PIN resolution program loads the element definition into memory. Then the program overrides the definition that is stored in memory with any payee overrides or positive input that is designated for that payee. If any elements are referenced in the element and overrides definitions that are now in memory, the program calls the PIN Manager to resolve them. Remember, an element can comprise other elements. During processing, this means that to resolve a single element, the system might need to resolve any number of other elements from which the primary element is created. The results of this process are used to calculate the values of earnings, deductions, and other elements, and pass the values back to the PIN Manager, which writes them to the main value array (PINV).
Each element is resolved in a cyclical (or recursive) manner; that is, each element is resolved, and the data is stored (in PINV or PINW). Then the Process List Manager again looks to the process list to see what element is to be processed next, and the process is repeated.
When all calculations are complete for the payroll or absence run, the program writes the results to the appropriate output tables. First, the program references the PINV and PINW arrays and writes the results to the database. Then it references all positive input and writes the data to the positive input history records. Finally, the program generates deltas for any future retroactive processing.
This diagram shows the calculation phase of the batch process.

In Global Payroll batch processing, arrays are used to store data. Arrays are temporary tables that COBOL programs use to store data during processing. Once processing is complete, the programs write the data from the temporary arrays to the appropriate output tables.
Occasionally you might need to modify the COBOL programs to accommodate a larger maximum array size than is defined in the programs that are delivered by PeopleSoft. If an array is too small (the data overflows the array), you get an error message, and the batch process fails. The error message (MSGID-ARRAY-OFLOW) identifies the array and the COBOL file where the array is defined. This guides you to the location in the designated file that might need modification.
Increasing the Occurs Count in Arrays
The table access programs allocate a specified, limited amount of memory space to store in a table array all the details of the payroll process tables that are typical for a payroll run.
You can increase the maximum size of an array by increasing the occurs count in the appropriate table access program.
Note: This is the only COBOL modification that we detail because COBOL modifications to the delivered Global Payroll programs are strongly discouraged.
For example, let's look at a piece of unmodified code in GPCDPDM.CBL.
Below is an array and its related COUNT control field that prevents the program from aborting. When you make a modification, both highlighted numbers must be changed and kept in sync.
05 L-PMT-COUNT PIC 9999 VALUE 0 COMP.
88 L-PMT-COUNT-MAX VALUE 200.05 L-PMT-DATA OCCURS 200
INDEXED BY PMT-IDX.The assumption here is that there will never be more than 200 payments processed for a payee during any calendar run. If more than 200 payments were processed, the program would issue an error message (MSGID-ARRAY-OFLOW), and the payroll process would terminate.
While the system loads and refreshes this array once for each payee, the system refreshes other arrays for each payment, and loads and increments others throughout the entire process.
This type of modification is not difficult to deal with when you upgrade to a new Global Payroll release, when PeopleSoft delivers a whole new set of source code. Simply move your array size modifications to the new code line. Whenever you change the size of an array, be sure to recompile the entire Global Payroll COBOL code line (GPP*).
The goal of a payroll or absence batch processing run is to produce a set of output tables, where your important batch processing data results reside. Once you know the type of information that resides in the output tables that are generated by Global Payroll, you can use those tables to produce reports and other data manipulations that are relevant to your organization's needs.
This diagram shows the relationships between the batch processing output tables.
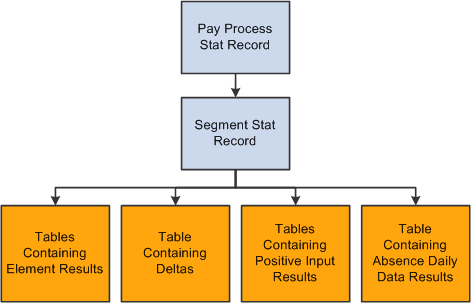
Tables Generated by Payee Selection Process
The payee selection process generates the following tables:
Pay Process Stat (status) record (GP_PYE_PRC_STAT).
There is one Pay Process Stat record for every EMPLID/EMPL_RCD combination per calendar.
There is a one-to-one/many relationship between the Pay Process Stat record and the Segment Stat record.
Segment Stat record (GP_PYE_SEG_STAT).
The Segment Stat record is a child of the Pay Process Stat record. There is one Segment Stat record for each gross to net within the calendar.
Tables Containing Element Results
The following tables contain element results:
Earnings/Deductions (GP_RSLT_ERN_DED).
Contains the results of earnings and deductions after batch processing.
Other Elements (GP_RSLT_PIN).
Contains the results of miscellaneous element resolutions after batch processing including the results for absence entitlement elements.
Table Containing Accumulator Results
The Accumulators table (GP_RSLT_ACUM) contains the results of accumulators after batch processing.
Table Containing Deltas
The Deltas table (GP_RSLT_DELTA) contains deltas, which are the differences between two element results. This data is often important for processing retroactivity. This table is a child table to the Segment Stat (segment status) table (GP_PYE_SEG_STAT), which is a child of the Pay Process Stat table (GP_PYE_PRC_STAT).
Tables Containing Positive Input Results
The following tables contain positive input results:
Positive Input Data (GP_RSLT_PI_DATA).
Contains the results of positive input calculations after batch processing. Only the positive input rows that were used in the calculation are included in this table.
Positive Input Supporting Element Overrides (GP_RSLT_PI_SOVR).
Contains the results of supporting element overrides after batch processing.
Absence Daily Data (GP_RSLT_ABS).
Contains the absence daily data results.