プラン抽出プロセスで作成されるファイル
プラン抽出プロセスによって一連のファイルが生成されます。 一部のファイルのファイル名はDATAで始まり、ファイル拡張子は.csv.gzです。 これらのファイルは、圧縮されたカンマ区切り値(CSV)ファイルです。
抽出プロセスでは、METAで始まり、内部使用のために.mdcsv.gz拡張子が付いたファイル名を持つ一連のファイルも生成されます。 METAファイルは無視してかまいません。
すべてのプラン抽出により、次のDATAファイルが生成されます。
|
生成されるファイル |
ファイルの説明 |
|---|---|
|
ディメンション・データ |
プラン抽出プロセスでは、抽出プロセスに選択したディメンションごとに1つのディメンション・データ・ファイルが生成されます。 このファイルには、すべてのレベル・メンバーと、そのディメンションのすべての階層に関連付けられた関係が含まれます。 |
|
ディメンション定義 |
プラン抽出プロセスでは、抽出ごとに1つのディメンション定義ファイルが生成され、階層およびレベルの名前が含まれます。 |
|
メジャー・データ |
プラン抽出プロセスでは、同じディメンションを共有するメジャーのセットごとに1つのメジャー・データ・ファイルが生成されます。 このファイルには、様々なディメンション別のメジャー値が含まれます。 |
|
メジャー定義 |
プラン抽出プロセスでは、抽出ごとに1つのメジャー定義ファイルが生成され、メジャーの名前、データ型、式、粒度および集計ルールが含まれます。 |
抽出プロセスでは、データ・ファイルの内容を理解するのに役立つディメンション定義ファイルおよびメジャー定義ファイルが生成されますが、レポートや分析には必須ではありません。 これらのファイルには、抽出を実行するプランナの言語に翻訳可能な文字列が含まれています。
抽出されるDATAファイルの命名規則
DATAプリフィクスと.csv.gzファイル拡張子に加えて、データ・ファイル名は特定の命名パターンに従います。 コンテンツ・サーバーでこの名前パターンを検索して、ダウンロードに必要なファイルを取得できます。
-
ディメンション・ファイル名のパターン
-
ディメンション・データ・ファイル:

-
ディメンション定義ファイル:
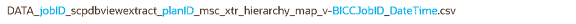
ディメンション・ファイル名の部分
説明
jobID
抽出予定済プロセスのジョブID。
planID
プランのID。 この名前はログ・ファイルで使用できます。
ディメンション・コード
ファイル内の階層が属するディメンション・コード。 ディメンション・データ・ファイルで使用されますが、ディメンション定義ファイルでは使用されません。
BICCJobID
BI Cloud Connector (BICC)ツールの抽出予定済ジョブのジョブID。
DateTime
抽出予定済プロセスが開始された日時。
-
-
メジャー・ファイル名のパターン
-
メジャー・データ・ファイル:

-
メジャー定義ファイル:
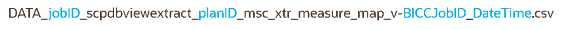
メジャー・ファイル名の部分
説明
jobID
抽出予定済プロセスのジョブID。
planID
プランのID。 この名前はログ・ファイルで使用できます。
ディメンション・グループ・コード
ディメンション・グループ・コードの名前。 メジャー・データ・ファイルで使用されますが、メジャー定義ファイルでは使用されません。
BICCJobID
BI Cloud Connector (BICC)ツールの抽出予定済ジョブのジョブID。
DateTime
抽出予定済プロセスが開始された日時。
-