- 福利厚生の実装
- 福利厚生ユーザー・エンティティを使用した抽出定義の作成
福利厚生ユーザー・エンティティを使用した抽出定義の作成
抽出定義は、BEN_EXT_ENRT_RSLT_UE、BEN_EXT_ENRT_DPNT_UE、BEN_EXT_ENRT_BNF_UEおよびBEN_EXT_ENRT_RTCVG_UEという福利厚生ユーザー・エンティティを使用して作成します。
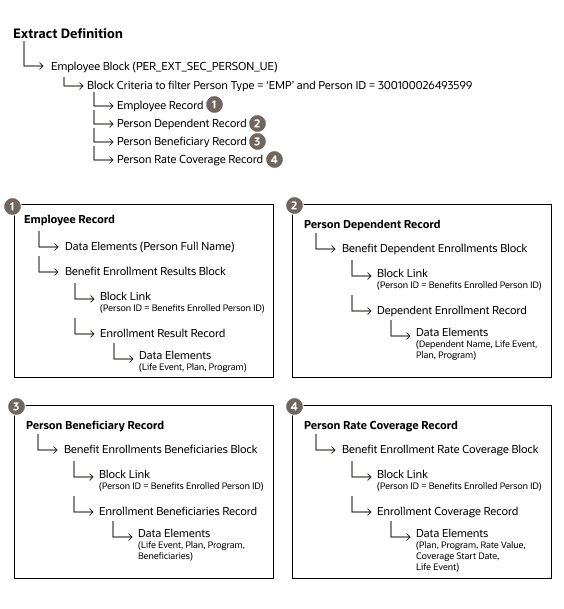
抽出定義を作成する方法を次に示します。
- 「ナビゲータ」>「自分のクライアント・グループ」>「データ交換」をクリックします。
- 「HCM抽出」セクションで、「定義の抽出」をクリックします。
- 「定義の抽出」ページで、「作成」をクリックします。
-
「抽出定義の作成」ウィンドウで、次の詳細を入力します。 残りのフィールドはそのままにします。
フィールド 値 Name 抽出定義のわかりやすい名前(SIMPLE_BEN_EXTRACT_01など) タイプ HRアーカイブ コンシューマ レポート - 「保存してクローズ」をクリックします。
- 定義を抽出ページで、作成した抽出定義の行で、「拡張編集」アイコンをクリックします。
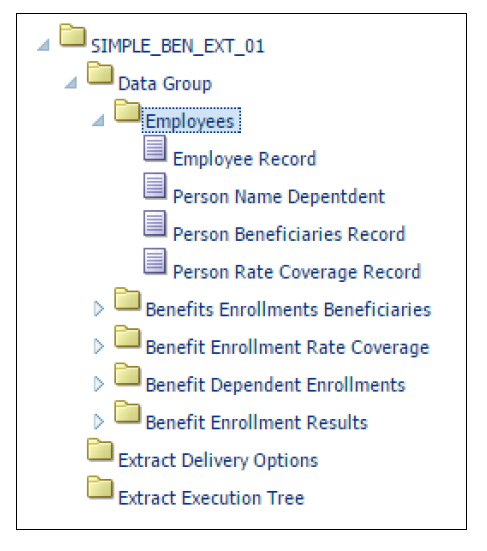
- 「抽出定義の編集」ページの「階層」ペインで、「データ・グループ」をクリックします。 データ・グループを作成して、福利厚生ユーザー・エンティティを抽出定義に関連付けます。
-
会社の従業員を表すルート・データ・グループを作成します。「データ・グループ」セクションで「作成」をクリックし、次のフィールドに入力します。
フィールド 値 Name 従業員 タグ名 従業員 ユーザー・エンティティ PER_EXT_SEC_PERSON_UE. これは従業員を表すユーザー・エンティティです。 ルート・データ・グループ 選択 スレッド・データベース・アイテム 抽出Person ID スレッド処理タイプ オブジェクト処理 - 「保存」をクリックします。
- 「データ・グループ・フィルタ基準」セクションで「追加」をクリックします。
-
「編集」をクリックします。 条件および演算子を使用して、次のフィルタ基準を作成します。
Extract Person System Person Type = 'EMP' And Extract Person ID = 300100026493599ノート:「拡張」オプションを使用して、フィルタ基準を直接入力します。 EMPは文字列データ型であるため、引用符を含めます。 Person IDは数値タイプであるため、引用符を含めないでください。 このPerson IDは、この手順の一例です。 - 前述と同じステップを使用して、福利厚生登録結果と呼ばれる別のデータ・グループ(ルート・データ・グループではない)を作成します。 このデータ・グループをBEN_EXT_ENRT_BNF_UEユーザー・エンティティに関連付けます。
- 「保存してクローズ」をクリックします。
- 「抽出定義の編集」ページで、福利厚生登録結果データ・グループを「従業員」親データ・グループに接続する必要があります。 「データ・グループ」セクションで、「福利厚生登録結果」をクリックします。
- 「接続データ・グループ」セクションで、「追加」をクリックし、親データ・グループとして「従業員」を選択します。
- 「親データ・グループ・データベース・アイテム」リストで、「抽出Person ID」を選択します。
- 「データベース・アイテム」リストで、「Person ID」を選択します。
- 「保存」をクリックします。
- 「従業員」親データ・グループを選択します。 このグループのレコードを作成する必要があります。
-
「レコード」セクションで、「作成」をクリックします。
フィールド 値 次のデータ・グループ 福利厚生登録結果 順序 10 Name 従業員レコード タグ名 従業員レコード タイプ ヘッダー・レコード プロセス・タイプ FastFormula - 「保存」をクリックします。
-
次の表に示すように、この手順のステップを使用して、これらの追加データ・グループを作成し、関連するユーザー・エンティティにリンクします。
データ・グループ ユーザー・エンティティ 福利厚生登録受取人 BEN_EXT_ENRT_BNF_UE 福利厚生登録レート補償範囲 BEN_EXT_ENRT_RTCVG_UE 福利厚生扶養家族登録 EN_EXT_ENRT_DPNT_UE - この手順のステップを使用して、前のステップで作成したデータ・グループを「従業員」親データ・グループに接続します。
-
これらの追加レコードを従業員データ・グループに作成します。 各レコードの次のデータ・グループを対応する福利厚生抽出子データ・グループに設定してください。
- 個人名扶養家族レコード
- 個人受取人レコード
- 個人レート補償範囲レコード
- 従業員データ・グループ・レコードの場合は、「個人氏名」抽出属性を構成する必要があります。 「階層」ペインで、「従業員」データ・グループを展開し、「従業員レコード」を選択します。
-
「抽出属性」セクションで、「作成」をクリックします。 次のフィールドに入力します。
フィールド 値 Name 個人氏名 短縮コード fullnameデータ型 テキスト タイプ データベース・アイテム・グループ データベース・アイテム・グループ 個人氏名 出力ラベル 個人氏名 出力列 1 -
福利厚生登録結果データ・グループのレコードを作成します。 この表を使用して、キー・フィールドに値を指定します。
同様に、作成した他のデータ・グループのレコードを作成します。フィールド 値 次のデータ・グループ 空のままにします。 タイプ 詳細レコード プロセス・タイプ FastFormula - この手順のステップを使用して、各レコードに関連する抽出属性を作成します。
- 「階層」ペインで、「抽出実行ツリー」をクリックします。
- 「すべてのFormulaのコンパイル」をクリックします。 「リフレッシュ」をクリックして、現在のステータスを確認する必要があります。 コンパイルが成功すると、「ステータス」列の横に緑色のチェック・マークが表示されます。
- 「検証」をクリックして、作成した抽出定義の完全性を確認します。
- 「OK」をクリックします。 必要に応じて、検証レポートをデバイスにダウンロードすることもできます。
- 「XMLスキーマのエクスポート」をクリックして、後でRTFレポート・テンプレートの作成に使用するXSDファイルとして抽出定義をダウンロードします。
関連トピック