ベクトル書込みノードと読取りノード
ビジネス・プロセスを効果的に自動化するには、AIワークフローで高品質で適切に構造化され、再利用可能なナレッジにアクセスする必要があります。 AI Agent Studioのベクトル書込みおよび読取りノードを使用して、ナレッジを埋込みとして格納し、セマンティック検索およびメタデータ・フィルタを使用してインテリジェントに取得できます。 これらのノードを活用することで、プロセス全体で重要なビジネス知識を取得、管理、再利用するワークフローを設計できるため、エンタープライズ環境の正確性、スケーラビリティおよび信頼性が向上します。
ここでは、ワークフロー・エージェントでVector WriteおよびReadノードを効果的に使用するために知っておく必要があることと、最適な取得のためにエンタープライズ・ナレッジを編成および管理するためのいくつかのベスト・プラクティスを示します。
ベクトル書込みノード
ベクトル書込みノードには、将来のセマンティック取得のための埋込みとして価値の高い知識が格納されます。 これらのノードは、ベクトル・ストア・ノードとも呼ばれます。
ノードを作成すると、実行時に動的に解決される式としてすべての値を構成できます。 ノード作成ウィンドウの例を次に示します。 各番号付きフィールドの詳細は、次の表で説明します。
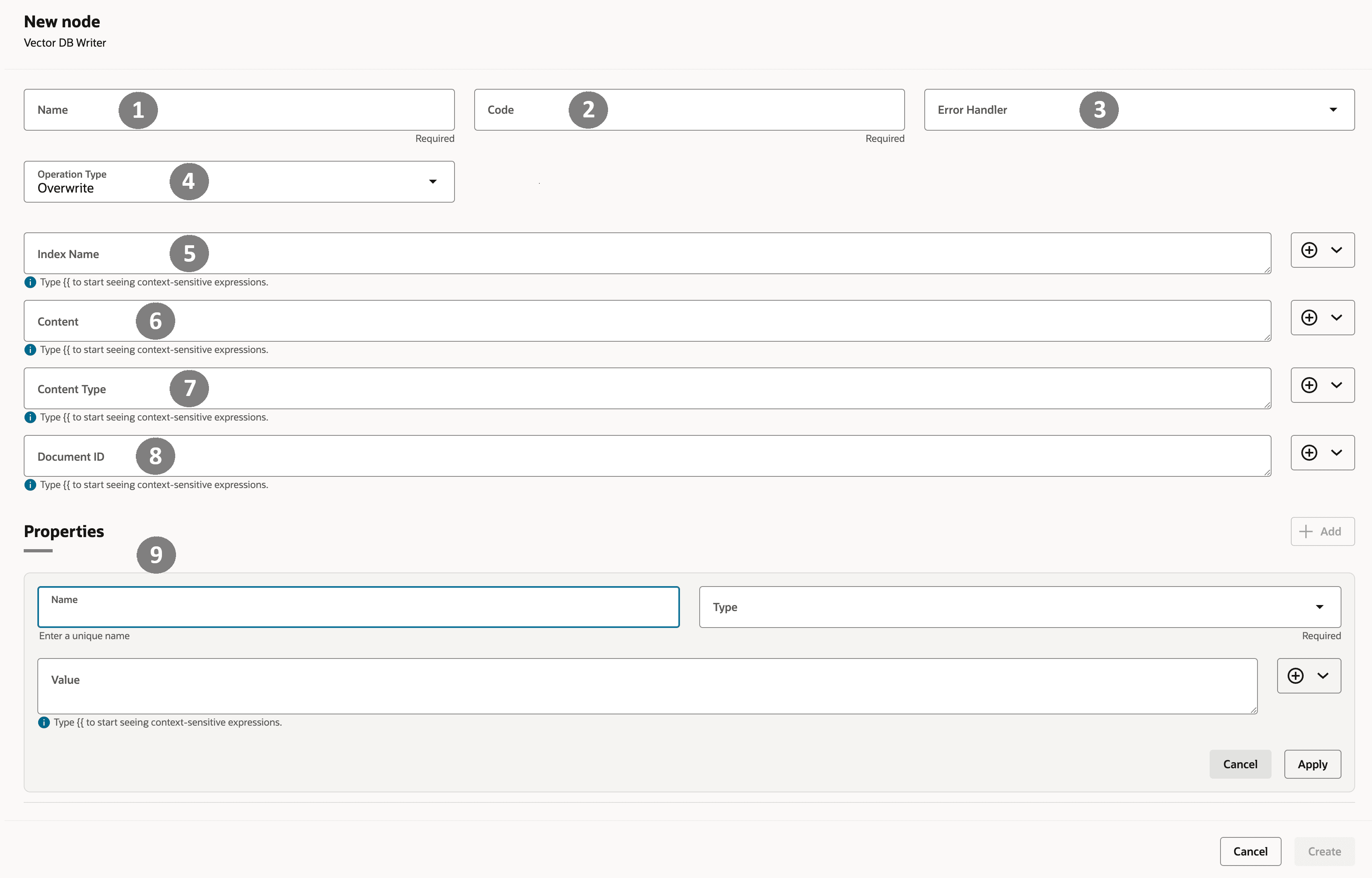
| コールアウト番号 | フィールド | 説明 | 例 |
|---|---|---|---|
| 1 | 名前 | ノードの設計時名 | ワークフローがわかりやすいように、WriteResolutionSummaryToVectorDBなどのわかりやすい名前を使用します。 |
| 2 | コード | ワークフロー・スキーマのプログラム識別子 | このフィールドは自動生成されます。ただし、write_resolution_vectorなどのユーザー定義フィールドに変更できます。 小文字とアンダースコアを使用します。 |
| 3 | エラー・ハンドラ | 失敗時のフォールバック・パス | エラー・ブランチまたは専用ハンドラ・ノードを選択して、障害をクリーンに管理します。 |
| 4 | 操作タイプ | ドキュメントをインデックスに書き込む方法 | 新規エントリの場合はINSERT 、コンテンツの置換の場合はOVERWRITE 、安全に更新または作成する場合はUPSERT 、エントリを削除する場合はDELETE を使用します。 |
| 5 | 索引名 | 書込み先のベクトル索引の名前 | 既存の索引を選択するか、support_ticket_summariesやproduct_docs_indexなどの新しい索引を指定します。 |
| 6 | コンテンツ | 埋め込むテキスト・データ | これをクリーンで構造化された方法で要約します。 RAWログを回避します。 かわりに、LLM生成のサマリー、抽出されたファクトまたはキュレーションされたナレッジを使用します。 |
| 7 | コンテンツ・タイプ | 索引付けまたは埋込みされるコンテンツのタイプ | 通常の値は、json またはtextです。 |
| 8 | 文書ID | このレコードの一意識別子 | ticket_1123やcustomer_450_profileなどの安定した識別子を使用します。 |
| 9 | プロパティ | 追加のオプションのメタデータ・キー値 | {objectId:"a12345", region:“NA”, severity:“High”} |
ベクトル書込みノードの構築のベスト・プラクティス
ベクトル・ストアは、ノイズ、重複およびトピック・ドリフトを回避しながら、明確で意味のあるメタデータが豊富な知識を記述する場合に最も効果的です。
| ベスト・プラクティス | 説明 |
|---|---|
| 公開および再利用可能なナレッジのみを保存 | 個人を識別可能な情報(PII)、資格証明、機密文書、権限チェックが必要な情報など、機密情報、権限制御情報または個人情報を除外します。 |
| 耐久性の高い価値の高いコンテンツにフォーカス | ケース解決、構造化サマリー、検証済インサイトなど、将来のワークフローに長期的な価値をもたらす情報を格納します。 生のチャット・ログや一時的な指示など、ノイジー・コンテンツ、ワンオフ・コンテンツまたはエフェメラル・コンテンツを書き込むことは避けてください。 |
| 書く前にきれいにして正常化して下さい | 常にコンテンツの標準化、ドキュメントの要約、重複の排除、無関係な詳細の削除、重要なメタデータの添付を行います。 |
| データを最新に保つ |
ベクターの書き込みは最新の真実を反映する必要があります。 古いエントリは精度を低下させ、誤った回答につながります。
|
| スマート・アップデート・プラクティスに従う |
制御された意図的な方法でベクトルを更新します。 更新ごとに新しいエントリを作成したり、競合するデータや古いデータを格納したりしないでください。
|
| 常にリッチ・メタデータを含める | ビジネス・オブジェクトID、製品番号、バージョン情報およびその他の検索可能な属性を含むタグ。 エージェントおよび索引全体で一貫性のあるメタデータ・スキーマを使用します。 |
| データ汚染の防止 | 重複や一貫性のないタグを避けるために、既存のナレッジを確認してください。 低価格のコンテンツを定期的に削除します。 |
| ビジネス・オブジェクト・データの除外 | ベクトル・メモリーでこのデータを複製すると、ノイズ、冗長性およびバージョン・ドリフトが作成されます。 |
ベクトル読取りノード
ベクトル読取りノードは、セマンティック類似性およびメタデータ・フィルタを使用して、最も関連性の高いナレッジを取得します。
次に、ノード作成ウィンドウの概要を示します。 ノードの作成時に、すべての値を、実行時に解決される式として構成できます。
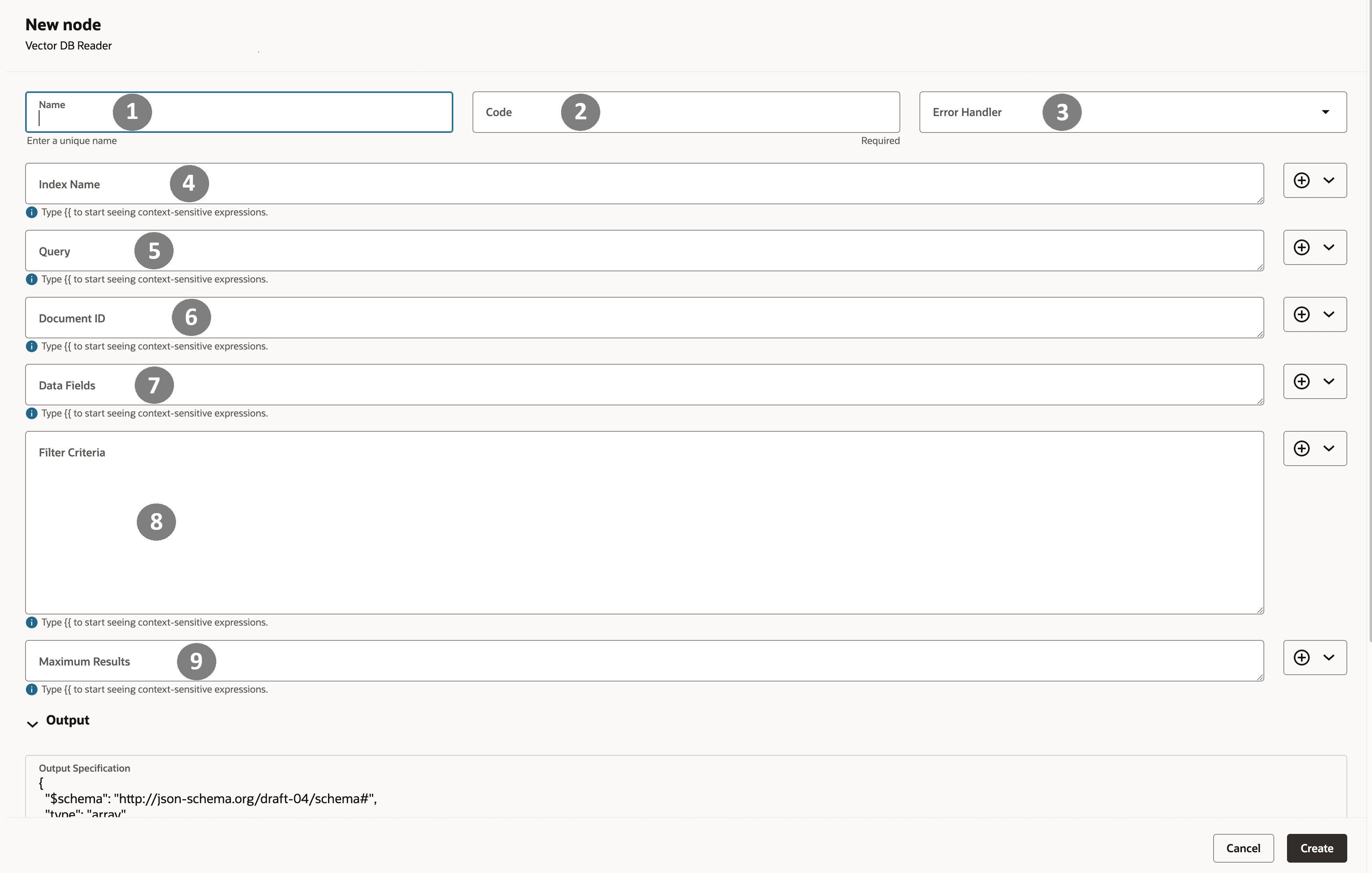
| コールアウト番号 | フィールド | 説明 | 例 |
|---|---|---|---|
| 1 | 名前 | ノードの名前 | RetrieveTicketContextFromVectorDBなどのクリア名を使用して、ワークフローを読み取り可能にします。 |
| 2 | コード | 内部プログラム識別子 | このフィールドは自動生成されます。ただし、 read_ticket_context_vectorのようにユーザー定義フィールドに変更できます。 |
| 3 | エラー・ハンドラ | 障害発生時の状況を定義します。 | 空または無効なエージェント・レスポンスを回避するために、エラー・ハンドラまたはフォールバック・ロジックにルーティングします。 |
| 4 | 索引名 | 検索するベクトルインデックス | support_ticket_summariesやemployee_profile_indexなど、ライターが使用する索引と同じ索引を選択します。 |
| 5 | 問合せ | 自然言語検索クエリ | 曖昧な問合せを回避し、「どのようなトラブルシューティング・ステップが実行されたか」などのインテント固有の情報を要求します。 |
| 6 | 文書ID | このレコードの一意の識別子。 | ticket_12345_summaryなど、既知のレコードに詳細を関連付ける場合にこれを指定します。 |
| 7 | データ・フィールド | 返されるメタデータ・フィールド | フィルタで使用する文字列の配列を指定します。 |
| 8 | フィルタ基準 | ランキング前に適用された論理フィルタ | このフィールドを指定して、高精度を有効にし、product = Payroll、region = US、severity >= Highなどの取得結果を制限します。 |
| 9 | 最大結果 | 返されるランク付け結果の最大数 | 表示する結果の最大数の整数値を指定します。 |
ベクトル読取りノードの構築のベスト・プラクティス
ベクトル読取りノードは、メタデータ・フィルタを利用して意味的に正確なレスポンスを確保し、トピックのドリフトやハルシネーションを防止する明確な特定の問合せを記述する場合に最も効果的です。
| ベスト・プラクティス | 説明 |
|---|---|
|
明確で意図的な問合せの記述 |
問合せが固有であり、正確なワークフローまたはエージェント・タスクと一致していることを確認します。 たとえば、"Help me with this"のような曖昧な問題ではなく、"What resolve similar issues?"のような正確なプロンプトを使用します。 |
|
精度にメタデータ・フィルタを使用 |
フィルタ(エンティティ・タイプ、ビジネス・オブジェクトID、製品番号など)を適用して、関連するコンテンツのみをターゲットにします。 |
|
取得した結果を使用する前に検証 |
ワークフローで結果を信頼または使用する前に、メタデータとコンテキストを確認してください。 この検証により、誤った回答、サイレント・ワークフローの失敗、LLMの幻覚が悪質な証拠に根付くのを防ぐことができます。 |
|
適切な |
3から5以上の結果を返すように |
|
正常なフォールバック・ロジックの追加 |
問合せで結果が返されないケースを処理するために、ビジネス・オブジェクトやAPI参照などのバックアップ・ステップを実装します。 |
|
広範囲または無関係な取得の回避 |
必要なものだけに問合せをスコープ指定します。 無関係またはノイズの多いインデックスをスキップして、取得した結果のパフォーマンスと精度を向上させます。 |