ERMS Processes
ERMS uses application engine processes to fetch, route, and monitor inbound email.
These topics discuss:
High-level process flow.
The mail reader process.
The mail route process.
The scheduler process.
The email alert process.
Process instantiation.
Email process states and incompletely processed email.
Processing statuses for the unstructured email process.
The ERMS system comprises of these processes:
The mail reader process.
The mail reader process (RB_MAIL_READ) does all of the basic email handling that is common to both structured and unstructured email. Among other things, it fetches emails from external mail servers, saves the data in the PeopleSoft system, identifies email senders, associates relevant mailbox data with emails, and classifies emails as structured or unstructured.
The mail route process.
The mail route process (RB_MAILROUTE) is responsible for analyzing and routing emails. It checks emails' eligibility for address or domain-based routing, customer-based routing, thread-based routing and keyword-based routing. It carries out necessary email processing based on the email type (structured or unstructured). At the end, either some actions are preformed on emails automatically or they are routed to appropriate group worklists to be processed by agents.
The scheduler process.
The scheduler process (RB_CHECKUQ) determines whether any emails are awaiting further processing. If there are emails in queue, it schedules the unstructured content analysis job (PRCEMAIL), which includes the following two processes.
The SES Feed Generation Process (PTSF_GENFEED), which generates an XML feed for inbound email. This feed is used by SES to build the inbound email search index that is used for content-based routing.
This process also updates the email tables to identify the emails that it builds into the search index.
The mail route process (RB_MAILROUTE), which analyzes and routes emails.
Email alert process.
Two application engine processes make up the email alert process. Together, these processes monitor email due dates and send notifications when emails are not closed in time. The two processes are:
The time out process handler process (RB_SLA_SCHDR), which evaluates email due dates and statuses and schedules future notifications as necessary.
The time out notification process (RB_SLA_NOTIFY), which confirms email due dates and statuses for each notification and sends immediate notifications.
Image: ERMS high-level process flow of receiving and processing incoming email
The following process flow illustrates how the mail reader, mail route, scheduler, and email alert processes work together to process emails that are sent to an organization:
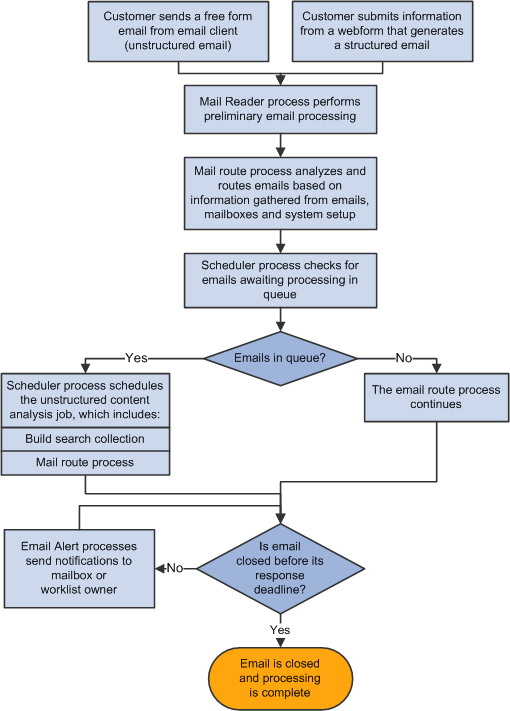
The mail reader process performs the following operations:
Schedules its own next instance.
Because this is the first operation performed, the next instance runs even if the current instance fails.
Determines whether the last instance of the mail scheduler process was able to schedule its own next instance, and if it wasn't, the mail reader process schedules an immediate instance for it.
Unlike all other ERMS processes, the scheduler process does not schedule its own next instance until the mail route process is complete. Therefore, a process failure could prevent future instances from being scheduled, if the mail reader process didn't check for this condition.
You can also use standard PeopleSoft Process Scheduler functionality to set up process-related notifications to alert an administrator of process failures.
Identifies the mailboxes to be polled.
Fetches emails from the external mail server.
The number of emails that the system fetches depends on the commit frequency that you set on the System Installations page.
Identifies exception emails and discards them.
Exception email is any email, structured or unstructured, that meets the mail-filtering criteria. When you set up ERMS, you can define addresses and domains to be automatically filtered. You can also create application classes to perform additional mail filtering.
Summary information about filtered email is stored in the exception email tables; your filter definitions determine whether the body text of the email is stored as well.
Note: Because no further processing is performed on exception emails, the following steps apply only to valid emails.
Saves data to PeopleTools email tables using PeopleTools ERMS application programming interfaces.
The PeopleSoft system deals with only two constructs—plain text and attachments. Any Multipurpose Internet Mail Extension (MIME) parts other than plain text, such as HTML areas and graphics, make emails no longer purely plain text and cause the part containing that construct to be stored as an attachment in the PeopleSoft system. The mail client of the sender determines the MIME format of an email.
Email body text is saved to a PeopleTools tabled named MCFEM_MAIL_PART. The SES Feed Generation process (PTSF_GENFEED) calls the RB_STG_EMAIL AE process to populate email body text in the staging table (RB_IN_EMAIL_STG) before the PSQuery built for indexing email runs to extract data for the XML feed. After the feed is generated successfully, the RB_STG_EMAIL process deletes the email body text from the staging table.
See PeopleTools: MultiChannel Framework.
Authorizes attachments in case emails have attachments.
PeopleTools secures all attachments. During this step, the mail reader process authorizes anyone with access to the Inbound Email component to view all of the email's attachments.
Classifies email as structured or unstructured, and saves a pointer to the email in either the unstructured email queue or the structured email queue.
The mail route process looks at these queues to determine which emails to process, and deletes the pointers when processing is complete.
Email is classified as structured if the <?xml version="1.0"?> and <WEBFORM_TEMPL_ID> XML tags appear in the email body. All other email is unstructured.
Analyzes the sender's email address to identify the sender.
If the sender cannot be identified as a known customer or worker, the mail reader process performs one of these actions based on the mailbox configuration:
Associates the email with the unknown user business object that you choose in the System Installations page when you set up ERMS.
Creates a new user based on the setting of the business unit that the mailbox associates with. The role type of the new user matches the type of the mailbox, which means that the user has the role of consumer if the mailbox type is external, and worker if the mailbox type is internal.
Saves data to the main CRM email table.
The CRM email table includes a pointer to the PeopleTools table and contains additional CRM-specific fields. The component interface that is used to store the data in the CRM table performs certain additional processing:
Creates an interaction for the email.
Calculates when the mailbox-level warning and final notifications should be sent and saves this information to the CRM email table.
Deletes email from the external mailbox.
This does not happen until after the email is saved to the CRM database. This protects you from data loss in case of a process failure.
Updates processing statistics.
For each instance of the mail reader process, the system tracks the number of exception, structured, and unstructured emails processed overall and for each mailbox.
Checks if the system option to create case for new inbound email is selected; if yes, create cases accordingly.
Check if the system option to add notification as note to the associated case; if yes, add case notes accordingly.
Image: Mail reader process flow for classifying incoming email and storing data to database tables
The following diagram illustrates the mail reader flow, which classifies incoming email and stores email data in appropriate database tables:
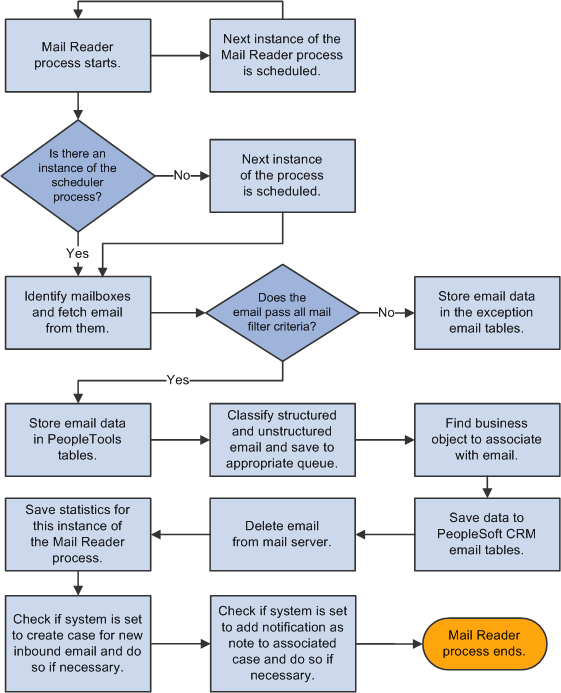
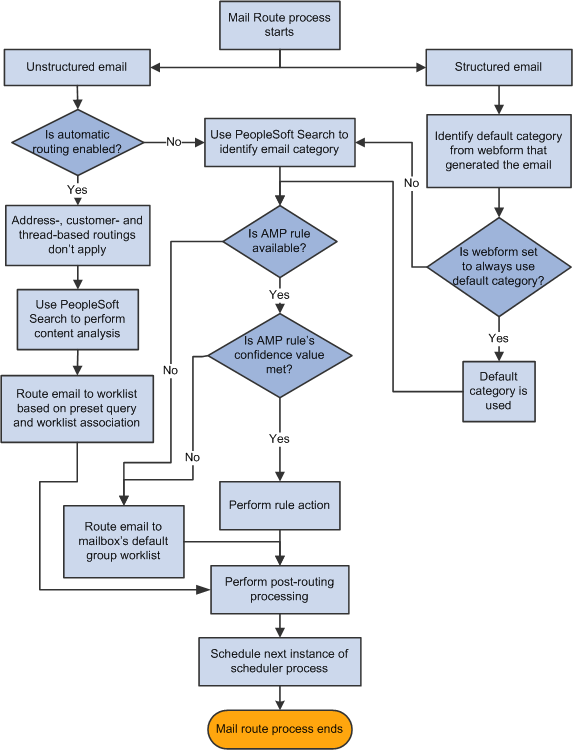
The mail route process performs the following operations on structured and unstructured emails:
If the incoming email is unstructured:
The mail route process first checks if automatic routing is enabled at the mailbox level.
If automatic routing is enabled, the process checks to see if the address or domain based routing applies to the email and route it accordingly.
If address-based routing doesn't apply, then it checks to see if customer-based routing applies to the email and route it to the group worklist specified in the custom application class code.
If customer-based routing doesn't apply, it checks to see if the email is threaded. If yes, it is routed to:
(If the Process customer response as new email option is selected at the system level) The group worklist to which the previous inbound email was routed.
(If the Process customer response as new email option is selected at the system level) The group worklist of the provider group, if the email is associated with a case and the case is assigned to a provider group.
(If the Process customer response as new email option is not selected at the system level) The group worklist to which the sender (agent) of the previous outbound email belongs.
If thread-based routing doesn't apply, it proceeds to keyword-based routing that is performed by PeopleSoft Search and routes the email to the best suited group worklist based on the predefined query and worklist association.
In the case where automatic routing is disabled at the mailbox level, Automated Mail Processing (AMP) is used for email routing purposes. The AMP rules engine uses PeopleSoft Search to search for predefined keywords (which are associated with categories) in email. For each keyword match that is found, a score is given to the associated category. As a result, email is assigned to the category with the highest score, and the rules engine can then trigger the actions that are associated with that category on the email. If the score returned for the email category does not meet the confidence level of any AMP rules for that email category, or that the email category is not associated with any rules, the system routes the email to the default group worklist of the mailbox.
See AMP Overview.
If the incoming email is structured:
The mail route process first converts the email from XML to plain text and extracts the email subject and body based on the webform and email workspace field mapping.
It identifies the default category from the webform definition that is associated with the email.
It checks if the option to always use the default category is selected in the webform definition.
If yes, the system uses the default category as the email category, looks up any AMP rules that are associated with it, and performs rule actions on the email.
Make sure that the default category is associated to a AMP rule to apply actions. If using the default category doesn't resolve in performing any rule actions, the system routes the email to the mailbox's default group worklist.
If no, the system uses PeopleSoft Search to identify the category of the structured email, just like the way unstructured email are processed when automatic routing is disabled in the system. If the returned category score does not meet the confidence value of any AMP rule associated with the category, the system routes the email to the default group worklist of the mailbox.
Lastly, the mail route process performs the following post-routing operations:
Sends an auto-acknowledgement email to the sender, if the mailbox is so configured.
Deletes successfully processed emails from the email queue.
Establishes thread associations if the mailbox's automatic routing setting prevented the associations from being established during routing analysis.
Image: Mail route process flow for routing unstructured and structured emails
The mail route process schedules the next instance of the scheduler process.
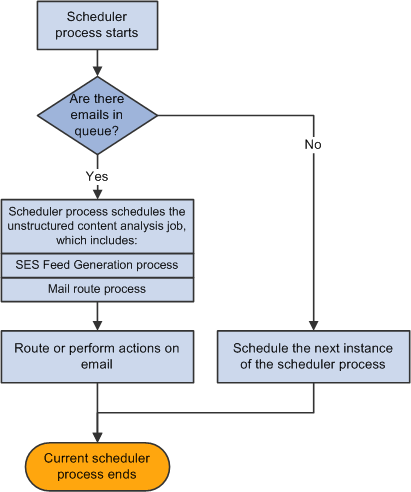
This topic provides a high-level overview of the scheduler process. Additional details about the email analysis and routing steps are provided in the documentation for setting up unstructured email routing rules.
See Understanding Unstructured Email Routing.
The scheduler process performs the following operations:
It reviews the data in the email queue.
Note: If there are no emails in the queue, the scheduler process schedules its own next instance, and the process ends. This ensures that the system does not attempt to build the search index unnecessarily.
If there are emails in the queue, the scheduler process removes all emails with a status of Successfully Processed, and then it changes the status of any remaining emails to Queued for Content Analysis. This ensures that emails that were partially processed (those with a status of 0 - Queued for Content Analysis, 1 - Index Built, and 2 - Content Analysis Processing) are ready to be reprocessed.
If the queue contains emails, the scheduler process schedules the unstructured content analysis job (PRCEMAIL), which consists of the SES Feed Generation process and the mail route process.
The SES Feed Generation process creates XML feed for inbound emails in the queue.
The mail route process analyzes and routes the email based on its content. Refer to the mail route process topic above for more information.
If the process is unable to route an email based on its individual characteristics, the process routes the email to the default worklist for the mailbox.
Image: High-level process flow for the scheduler process to analyze and route emails
The following graphic illustrates the scheduler process flow:
Every email has up to four associated notification times that the Email Alert processes monitor:
Mailbox-level warning and final notification times are established when the email is saved to the PeopleSoft CRM email tables.
The system calculates these times from the time that the external mail server receives the email. The mailbox metrics change every time an email is reassigned to a different mailbox.
Worklist-level warning and final notification times are established when an email is routed to a group worklist.
The system calculates these times from the time the email is routed to the group worklist. The group worklist metrics change every time an email is reassigned to a different group worklist, and that is why individual assignments must always be associated with a group worklist.
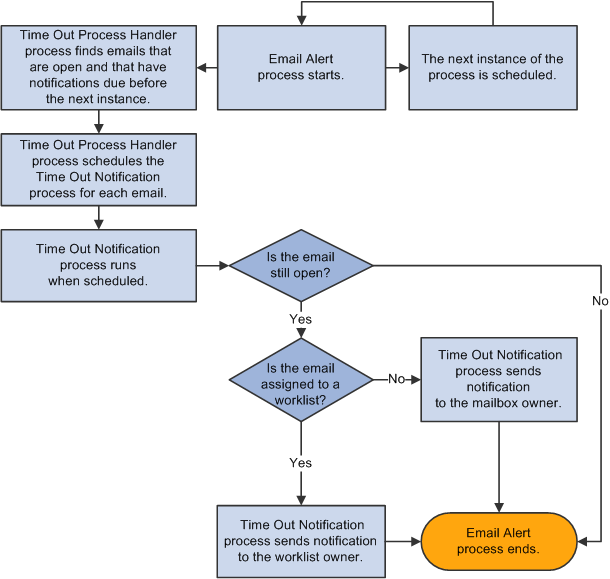
The Email Alert processes perform the following operations:
The Time Out Process Handler process schedules its own next instance.
The process identifies email that has one or more notifications scheduled to occur before the next instance of the process (the one that was just scheduled).
The process identifies emails with statuses other than Cancelled or Completed.
Emails that have been canceled or completed are ignored because alerts are intended to notify users of email that is still pending.
For email that is not canceled or completed, the process uses the notification time stored on the email record to schedule the Time Out Notification process.
The system schedules the notification process using a run control that includes the email ID.
When the Time Out Notification process runs (at the scheduled notification time), it does the following:
Verifies that the email is still not canceled or completed.
If the email is canceled or completed, the process ends without sending any notifications.
If the email is not canceled or completed, sends a notification.
First, the system determines whether the email is assigned to a group worklist. If it is, all notifications (mailbox-level and worklist-level) go to the group worklist owner. If the email is not assigned to a worklist, there are no worklist-level notifications, and any mailbox-level notifications go to the mailbox owner.
Image: Process flow for sending alert notifications for emails that are reaching commitment deadlines
The following graphic illustrates the email alert flow that sends out notifications for emails reaching commitment deadlines:
The mail reader process is the master controller for all ERMS processes. In addition to performing basic operations common to all emails, this process schedules the first occurrence of each of the other ERMS processes and also schedules its own recurrences.
The mail reader process recurrence frequency is based on the polling frequencies of all active mailboxes. The first time the mail reader process runs, it processes all mailboxes. It then calculates the next polling time for each mailbox and schedules future processing times accordingly. If an instance is already scheduled at the appropriate time, an additional instance is not scheduled.
For example, suppose that you have three active mailboxes. The polling frequencies are 10 minutes for mailbox A, 15 minutes for mailbox B, and 20 minutes for mailbox C. If you start the first instance of the mail reader process at 12:00, it reads mail from all three mailboxes and then schedules future instances for 12:10, 12:15, and 12:20. The 12:10 instance reads mail from mailbox A and then determines that the next time to check mailbox A is at 12:20. Because an instance of the process is already scheduled for 12:20, another instance is not scheduled. When the 12:20 instance of the process runs, it reads mail from both mailbox A and mailbox C.
The first instance of the mail reader process also schedules the first instance of the scheduler process and the email alert process. Each of these processes then schedules its own next occurrence based on intervals that you define.
Image: Relationship of ERMS processes and the process instantiation flow
The following graphic illustrates the relationship between all ERMS processes and how one process triggers the rest:
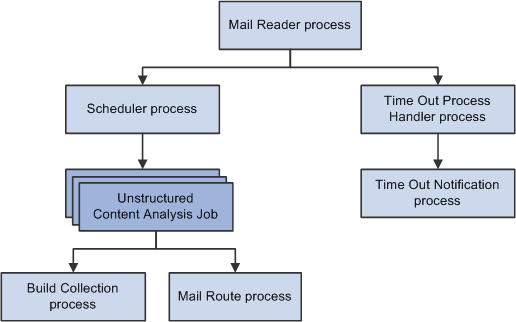
As the ERMS processes handle an email, they maintain process state information. The process state indicates how far along the automated processing is.
Before an email is completely processed, its process state can be:
Email Instance Created: the initial state of an email after it is saved to the PeopleSoft CRM email tables and before any additional processing occurs.
Queued for Routing: the Mail Reader process (RB_MAIL_READ) has finished with email, and the email is queued to be processed as an unstructured or structured email.
Mailbox Forwarding: the mailbox reset operation is performed.
After an email is completely processed, its process state can be:
Auto Responded By System: the email process sent an automatic response.
Email Routed: the structured email process has routed the email to a group worklist.
The process state is visible on the Message Details page of the email workspace only if the email is not completely processed. Users might access incompletely processed emails under two conditions:
A user accesses the email between the time the mail reader process saves it to the CRM email tables and the time the appropriate email handling process completes its processing.
The email process fails.
In both situations, the email can be accessed only through the menu navigation to the Search Inbound Emails component: incompletely processed emails do not appear in worklists or the Multichannel Toolbar. Agents who interact with emails only through the Worklist or the Multichannel Toolbar will normally never even see incompletely processed emails.
Only the email's mailbox owner can work with incompletely processed emails. (Although the email's group worklist owner has the same privileges as the mailbox owner, incompletely processed emails do not have a group worklist owner because they have not yet been assigned to a group worklist.)
To handle an incompletely processed email, the mailbox owner:
Accesses the email in the email workspace.
Verifies the process state.
Enters sender information, if necessary.
Depending on which process failed, and when, the sender information may already be present.
Establishes a thread association.
Depending on which process failed, and when, the thread association may already be established.
Changes the process state to Email Routed.
This prevents the next instance of the email process from attempting to reprocess the email.
Clicks the Reassign button and send the email to the appropriate group worklist.
This saves changes to the email.
Email that is placed in the unstructured email queue has an additional status tracking field (different from the overall process state) that indicates how far along the unstructured email process is. Each email in the unstructured email queue has one of these statuses:
0: Ready for processing.
1: Collection built.
2: Processing.
3: Successfully processed.
When the mail reader process first creates an entry in the unstructured email queue, it assigns status 0 (ready for processing). When the unstructured email process runs, it updates the status.
Each instance of the unstructured email process picks up all emails with statuses other than 3 (successfully processed). This practice ensures that a future instance of the unstructured email process will attempt to reprocess any emails that are not successfully routed.
The unstructured email process status is not visible from the email workspace. To view this data, you must query the database.