Importer des données supplémentaires
Important : Cette rubrique s'applique aux utilisateurs de la dernière version de Connect. Si votre compte utilise encore la version Connect classique, téléchargez le Guide de l'utilisateur de la version Connect classique.
Vous pouvez utiliser Connect pour importer des enregistrements dans une table de données supplémentaires d'Oracle Responsys.
A l'issue de l'exécution d'un travail d'import, le fichier chargé est archivé sur le serveur. En cas de succès du travail, le fichier est supprimé. En cas d'échec du travail, le fichier est supprimé uniquement dans les cas suivants :
- Le fichier est vide.
- Le fichier présente des problèmes de données (format de données non valide, etc.).
- Le fichier chargé et le fichier de comptage ne contiennent pas le même nombre d'enregistrements.
Pour créer un travail d'import de données supplémentaires :
- Dans la barre de navigation latérale, cliquez sur
 Données et sélectionnez Connect.
Données et sélectionnez Connect. - Cliquez sur Créer un travail sur la page Gérer Connect.
- Sélectionnez Importer les données supplémentaires dans la liste déroulante et entrez un nom et une description pour le travail d'import.
Les noms de travail ne doivent pas comporter plus de 100 caractères et ne peuvent comporter que les caractères suivants : A-Z a-z 0-9 espace ! - = @ _ [ ] { }
- Cliquez sur Terminé.
L'assistant Connect s'ouvre. Vous pouvez exécuter les étapes dans n'importe quel ordre et sauvegarder vos modifications pour continuer ultérieurement.
- Exécutez les étapes :
- Une fois toutes les étapes configurées, cliquez sur Sauvegarder. Pour sauvegarder et activer le travail, cliquez sur Activer.
Important : Avant de pouvoir sauvegarder ou activer le travail, vous devez définir une date d'expiration ou définir le travail pour ne jamais expirer. Pour définir une date d'expiration, cliquez sur Modifier en regard d'Expiration. Lorsque le travail expire, il est supprimé et ne peut pas être récupéré. En savoir plus sur la gestion de la date d'expiration.
en regard d'Expiration. Lorsque le travail expire, il est supprimé et ne peut pas être récupéré. En savoir plus sur la gestion de la date d'expiration.
Une fois terminé :
- Une fois le travail sauvegardé, vous pouvez utiliser la page Gérer Connect pour le gérer. En savoir plus sur la gestion des travaux.
- Lorsque vous sauvegardez votre travail, Connect peut renvoyer des erreurs. Cliquez sur Afficher les erreurs pour vérifier les erreurs et accéder rapidement à la page qui nécessite une correction. Vous devez corriger toutes les erreurs pour pouvoir activer le travail.
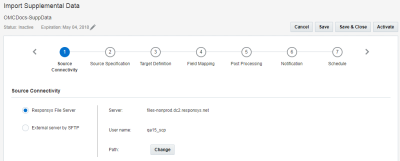
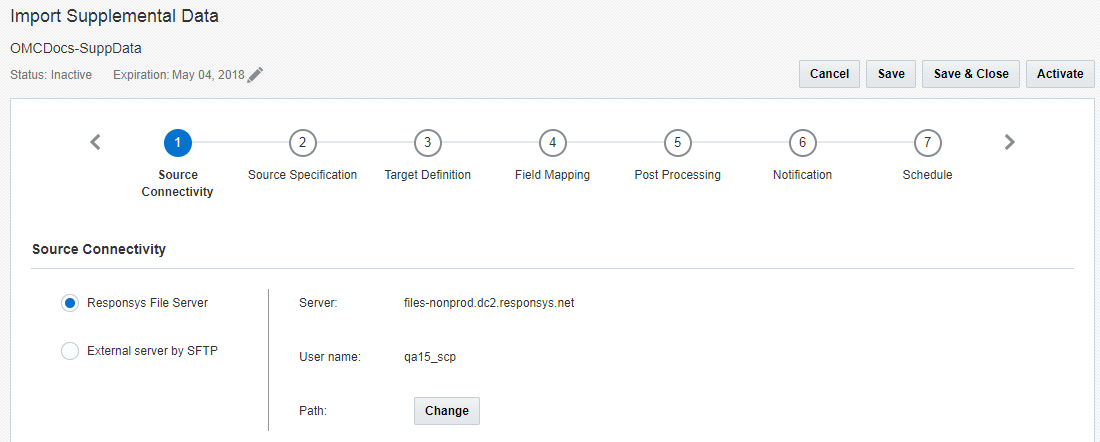
Etape 1 : Connectivité source
A cette étape, vous spécifiez les caractéristiques du serveur de fichiers pour extraire le fichier source.
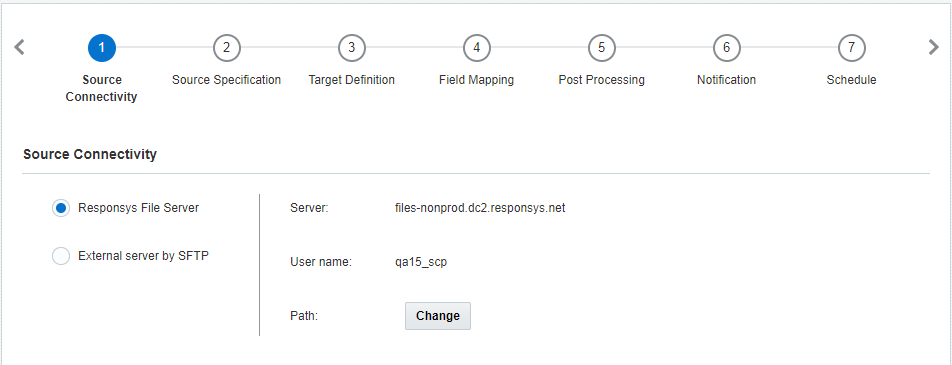
Sélectionnez l'une des options suivantes :
- Serveur de fichiers Responsys :n Les travaux Connect peuvent importer des données via le serveur de fichiers de votre compte Responsys SCP (Secure Copy Protocol). Ce compte comporte trois répertoires : chargement, téléchargement et archivage.
Important : Si elles ne l'ont pas déjà fait, l'équipe de support Oracle Responsys et l'équipe de votre propre service informatique devront travailler ensemble pour générer une paire de clés publique/privée SSH-2. Cela permet d'assurer un accès sécurisé au compte SCP via un client SSH/SCP. Vous pouvez également créer vos propres répertoires à l'aide d'un client SSH (Secure Shell).
- Si vous sélectionnez cette option, cliquez sur Modifier pour spécifier le répertoire dans lequel vos fichiers se trouvent.
- Serveur externe par SFTP : Si vous sélectionnez cette option, spécifiez les informations suivantes :
- Nom d'hôte : Sélectionnez le nom d'hôte dans la liste déroulante.
- Chemin du répertoire : Entrez le chemin du répertoire associé.
- Nom d'utilisateur : Entrez le nom utilisateur permettant d'accéder à la connexion SFTP.
- Authentification : En fonction de la configuration de votre serveur, sélectionnez Mot de passe ou Clé.
S'il s'agit de votre premier travail avec autorisation par clé, cliquez sur Accéder aux informations de clé ou les générer et entrez l'adresse électronique à laquelle recevoir la clé publique et les instructions pour ajouter cette clé à votre compte SFTP. Une fois la clé publique installée, cliquez sur Tester la connexion pour confirmer que la configuration de la connexion SFTP est valide.
A savoir : Pour plus d'informations sur l'authentification par clé, voir Sélectionner, importer ou générer des clés publiques.
Etape 2 : Spécification de la source
A cette étape, vous fournissez des informations sur le fichier à importer.
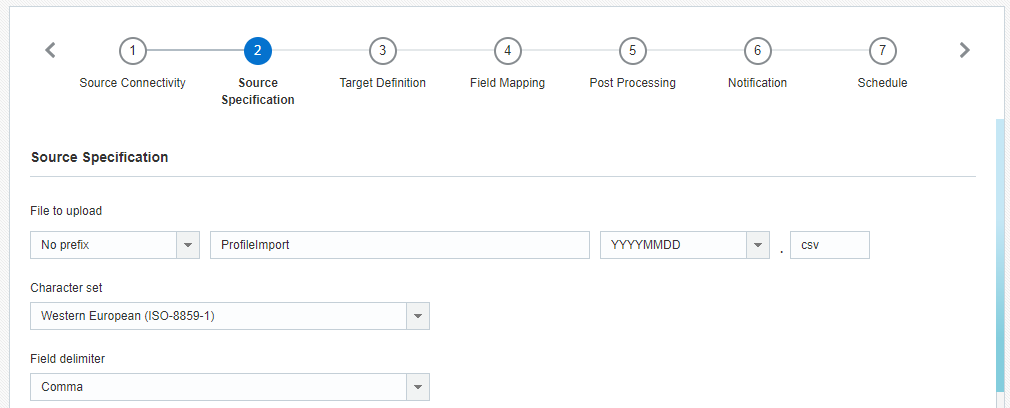
- Fichier à charger : Nom complet et extension du fichier à importer. Vous pouvez ajouter la date de création du fichier sous forme de préfixe ou suffixe.
- Jeu de caractères : Jeu de caractères du fichier. Si votre fichier contient des emojis, vous devez sélectionner le jeu de caractères Unicode (UTF-8).
- Délimiteur de champ : Délimiteur qui sépare les champs (colonnes) dans le fichier.
- Encadrement de champ : Indiquez si les colonnes de texte et les valeurs sont encadrées par des guillemets simples ou doubles ou ne sont pas encadrées.
- Format de date : Sélectionnez le format de date du fichier d'import. Pour plus d'informations sur les formats de date pris en charge, voir Format de date pris en charge dans Connect.
- La première ligne contient les noms de colonne : Cochez cette case si la première ligne du fichier contient des noms de champ.
- Le fichier est crypté avec la clé PGP/GPG : Cochez cette case si le fichier est crypté à l'aide d'une clé et s'il doit être décrypté avant le chargement.
- Le fichier est signé avec la clé PGP/GPG : Cochez cette case si le fichier est signé à l'aide d'une clé.
- Fichier pour confirmer le nombre d'enregistrements attendus : Cochez cette case et spécifiez un fichier à utiliser pour comparer le nombre d'enregistrements au nombre d'enregistrements importés (facultatif). Par exemple, si le nombre d'enregistrements attendus dans ce fichier indique 300, mais que le fichier importé n'en contient que 100, une erreur de transfert est notée et le processus de chargement est abandonné.
Etape 3 : Définition de la cible
A cette étape, vous sélectionnez la table de données supplémentaires dans laquelle importer les données.
Remarque : Vous devrez aussi sélectionner des tables cible lors du mappage des champs à l'étape 4.
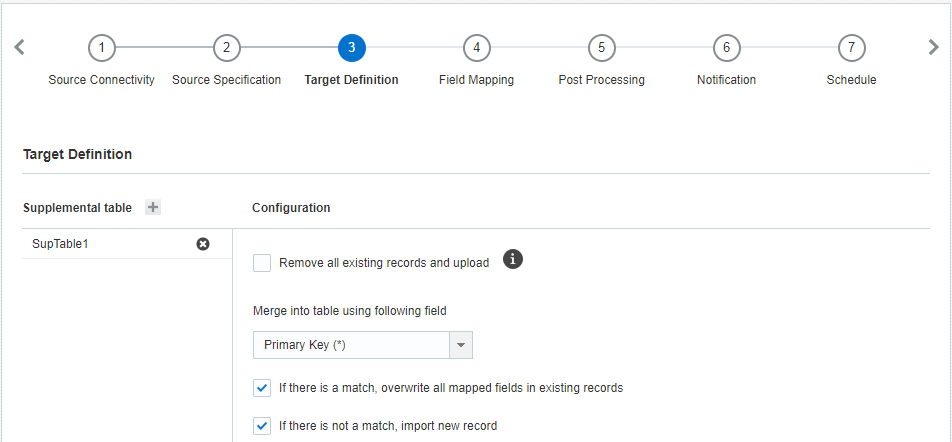
Pour ajouter une définition de cible :
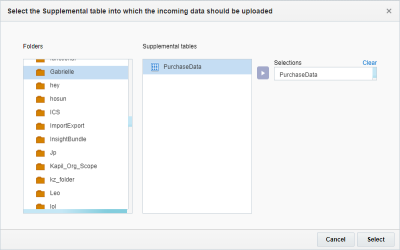
- A l'étape Définition de la cible, cliquez sur Ajouter + et sélectionnez la table de données supplémentaires dans laquelle importer les données.
- Dans la section Configuration, spécifiez les options suivantes :
- Retirer tous les enregistrements existants de la table cible, puis insérer les nouveaux enregistrements : Cochez cette case pour remplacer les enregistrements existants par ceux nouvellement chargés.
- Fusionner dans la table en utilisant le champ suivant : Si vous ne retirez pas tous les enregistrements existants, sélectionnez le champ destiné à la fusion des nouveaux enregistrements avec les enregistrements existants.
- S'il y a une correspondance, remplacer tous les champs mappés dans l'enregistrement existant : Cochez cette case pour remplacer les enregistrements existants par les nouvelles données en cas d'enregistrements correspondants. Si vous ne cochez pas cette case, l'enregistrement entrant est ignoré.
- En l'absence de correspondance, importer un nouvel enregistrement : Cochez cette case pour importer les enregistrements en cas d'absence de correspondance. Si vous ne cochez pas cette case, l'enregistrement entrant est ignoré.
Etape 4 : Mappage des champs
A cette étape, vous mappez les colonnes du fichier source aux champs de la table cible. L'opération de mappage permet de préciser la correspondance entre les champs source et cible.
Vous pouvez mapper les champs manuellement, à l'aide d'un fichier de chargement, ou automatiquement en générant un mappage de fichiers.
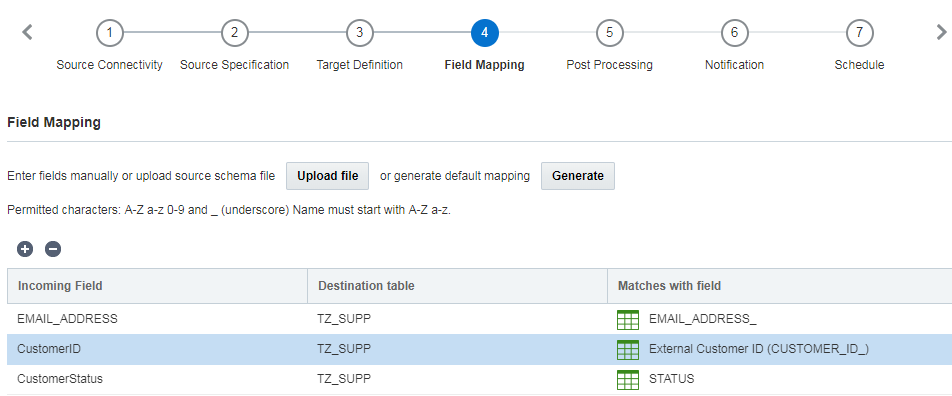
Notez ce qui suit :
- Lorsqu'ils sont trop longs, les noms de champ sont tronqués à 30 caractères.
- Les noms de champ doivent commencer par une lettre ou un chiffre et contenir uniquement des lettres, des chiffres ou des traits de soulignement.
- Lors de leur création, les noms de champ ne respectent pas la casse ; ils sont convertis ensuite en majuscules.
- Si des modifications entraînent des noms de champ en double, vous devez les renommer manuellement.
- Tous les noms de champ système (définis et réservés par Oracle Responsys) se terminent par un trait de soulignement (par exemple, EMAIL_ADDRESS_). La meilleure pratique consiste à ne pas utiliser de trait de soulignement comme dernier caractère des noms de champs chargés car cela est réservé aux champs système.
- Lorsque possible, faites correspondre les champs entrants et les champs existants portant des noms se ressemblant, comme par exemple, faites correspondre CUST_ID et CUSTOMER_ID_.
Pour plus de détails sur les exigences en matière de type de données et de nom de champ, voir Types de données et noms de champ.
Pour charger un fichier de mappage :
- A l'étape Mappage de champs, cliquez sur Charger un fichier.
- Sélectionnez le fichier de mappage et renseignez les détails.
- Les champs sont délimités par : Sélectionnez le délimiteur (généralement une tabulation ou une virgule) séparant les colonnes dans le fichier.
- Les champs sont encadrés par : Indiquez si les colonnes de texte et les valeurs sont encadrées par des guillemets simples ou doubles ou ne sont pas encadrées.
- La première ligne contient les noms de colonne : Cochez cette case si la première ligne contient des noms de champ.
Pour mapper des champs :
- A l'étape Mappage de champs, cliquez sur Ajouter +.
- Veillez aussi à sélectionner la table cible pour ce champ.
- Spécifiez le champ entrant et le champ avec lequel le mapper. Pour ne pas mapper un champ, sélectionnez ignorer ce champ.
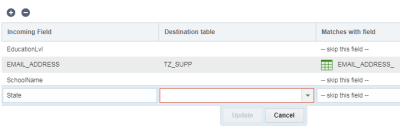
- Cliquez sur Mettre à jour.
Etape 5 : Post-traitement
A cette étape, vous pouvez lancer des campagnes après l'exécution réussie d'un travail. Vous pouvez sélectionner jusqu'à 40 campagnes
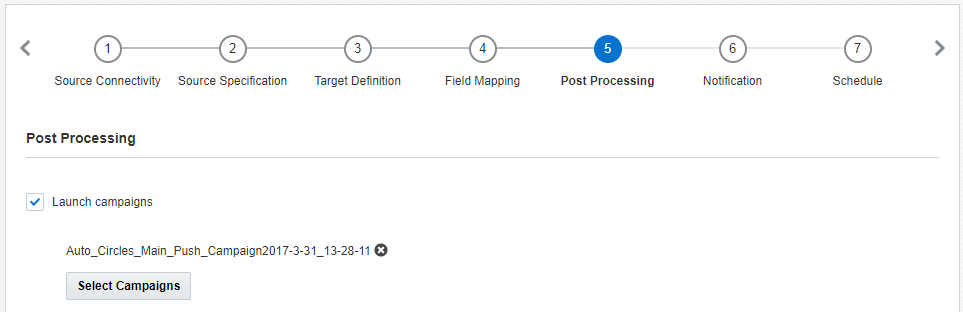
Pour recevoir des notifications d'avancement sur les lancements de campagnes, vérifiez que les paramètres de chaque campagne contiennent une ou plusieurs adresses électroniques auxquelles envoyer ces notifications.
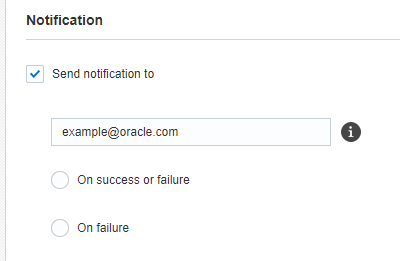
Etape 6 : Notification
A cette étape, vous configurez les notifications par courriel concernant le travail. Vous pouvez choisir d'envoyer des notifications après l'exécution réussie ou l'échec d'un travail.
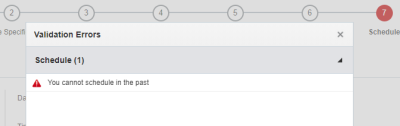
Etape 7 : Planification
A cette étape, vous planifiez le travail. Vous pouvez l'exécuter à une date et heure spécifiques ou suivant une planification récurrente. Pour exécuter le travail à la demande, utilisez l'option Ne pas planifier.
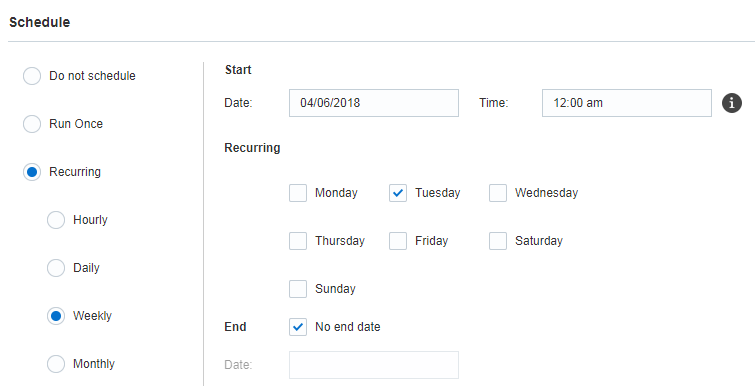
Important : Pour assurer que les années bissextiles et les mois à 31 jours ne posent pas de problème, vous ne pouvez pas planifier d'exécution mensuelle récurrente les 29, 30 et 31 du mois. Vous pouvez planifier l'exécution du travail un jour de la semaine correspondant au dernier du mois, par exemple, le dernier vendredi du mois.
Lors de la définition de l'heure de début d'un travail, sélectionnez l'un des quatre créneaux horaires dans une heure : 0-14, 15-29, 30-44, 45-59. Pour chaque travail planifié, le système utilise une minute de manière aléatoire (par exemple, 12 pour le segment 0-14). Cela répartit les heures de début des travaux de manière plus égale.
Le travail commence à des moments aléatoires dans le créneau horaire choisi. Si vous essayez de définir un nouveau travail dans un créneau horaire qui chevauche l'heure en cours, un message d'erreur est émis indiquant que l'heure sélectionnée se situe dans le passé. La meilleure pratique consiste donc à choisir le créneau horaire qui suit immédiatement le créneau en cours.