10 TimesTen Database Performance Tuning
An application using TimesTen should obtain an order of magnitude performance improvement in its data access over an application using a traditional RDBMS. However, poor application design and tuning can erode the TimesTen advantage. This chapter discusses factors that can affect the performance of a TimesTen application. These factors range from subtle, such as data conversions, to more overt, such as preparing a command at each execution.
This chapter explains the full range of these factors, with a section on each factor indicating:
-
How to detect problems.
-
How large is the potential performance impact.
-
Where are the performance gains.
-
What are the tradeoffs.
The following sections describe how to tune and identify performance issues:
Note:
You can also identify performance issues by examining theSYS.SYSTEMSTATS table.For information on tuning TimesTen Java applications, see "Java Application Tuning" in the Oracle TimesTen In-Memory Database Java Developer's Guide. For information on tuning TimesTen C applications, see "ODBC Application Tuning" in the Oracle TimesTen In-Memory Database C Developer's Guide.
System and database tuning
The following sections include tips for tuning your system and databases:
-
Prevent reloading of the database after automatic recovery fails
-
Configure the checkpoint files and transaction log files to be on a different physical device
Provide enough memory
Performance impact: Large
Configure your system so that the entire database fits in main memory. The use of virtual memory substantially decreases performance. The database or working set does not fit if a performance monitoring tool shows excessive paging or virtual memory activity. You may have to add physical memory or configure the system software to allow a large amount of shared memory to be allocated to your process(es).
For Linux systems, you must configure shared memory so that the maximum size of a shared memory segment is large enough to contain the size of the total shared memory segment for the database.
In TimesTen Classic, the entire database resides in a single shared memory segment. In TimesTen Scaleout, you set settings for the shared memory segment of each host. Set the appropriate operating system kernel parameters for shmmax, shmall, memlock, and HugePages. See "Operating system prerequisites" in the Oracle TimesTen In-Memory Database Installation, Migration, and Upgrade Guide and "Configuring the operating system kernel parameters" in the Oracle TimesTen In-Memory Database Scaleout User's Guide for more details.
TimesTen includes the ttSize utility to help you estimate the size of tables in your database. For more information, see "ttSize" in the Oracle TimesTen In-Memory Database Reference.
Avoid paging of the memory used by the database
Performance impact: Variable
On Linux, the MemoryLock connection attribute specifies whether the real memory used by the database should be locked while the database is loaded into memory. Set MemoryLock to 4 to avoid paging of the memory used by the database. If MemoryLock is not set to 4, parts of the shared memory segment used by the database may be paged out to the swap area, resulting in poor database performance. See "MemoryLock" in the Oracle TimesTen In-Memory Database Reference for more information.
Size your database correctly
Performance impact: Variable
When you create a database, you are required to specify a database size. Specifically, you specify sizes for the permanent and temporary memory regions of the database. For details on how to size the database and shared memory, see "Specifying the memory region sizes of a database" in this book and "Configure shmmax and shmall" in the Oracle TimesTen In-Memory Database Installation, Migration, and Upgrade Guide for details.
Calculate shared memory size for PL/SQL runtime
Performance impact: Variable
The PL/SQL runtime system uses an area of shared memory to hold metadata about PL/SQL objects in TimesTen and the executable code for PL/SQL program units that are currently being executed or that have recently been executed. The size of this shared memory area is controlled by the PLSQL_MEMORY_SIZE first connect attribute.
When a new PL/SQL program unit is prepared for execution, it is loaded into shared memory. If shared memory space is not available, the cached recently-executed program units are discarded from memory until sufficient shared memory space is available. If all of the PL/SQL shared memory is being used by currently executing program units, then attempts by a new connection to execute PL/SQL may result in out of space errors, such as ORA-04031. If this happens, increase the PLSQL_MEMORY_SIZE.
Even if such out of space errors do not occur, the PLSQL_MEMORY_SIZE may be too small. It is less expensive in CPU time to execute a PL/SQL procedure that is cached in shared memory than one that is not cached. In a production application, the goal should be for PLSQL_MEMORY_SIZE to be large enough so that frequently-executed PL/SQL units are always cached. The TimesTen built-in procedure ttPLSQLMemoryStats can be used to determine how often this occurs. The PinHitRatio value returned is a real number between 0 and 1.
-
1.0: A value of 1.0 means that every PL/SQL execution occurred from the cache.
-
0.0: A value of 0.0 means that every execution required that the program unit be loaded into shared memory.
The proper value of PLSQL_MEMORY_SIZE for a given application depends on the application. If only a small number of PL/SQL program units are repeatedly executed, then the size requirements can be small. If the application uses hundreds of PL/SQL program units, memory requirements increase.
Performance increases dramatically as the PinHitRatio goes up. In one set of experiments, an application program repeatedly executed a large number of PL/SQL stored procedures. With a larger value for PLSQL_MEMORY_SIZE, the application results in a PinHitRatio of around 90%, and the average execution time for a PL/SQL procedure was 0.02 seconds. With a smaller value for PLSQL_MEMORY_SIZE, there was more contention for the cache, resulting in a PinHitRatio of 66%. In this experiment the average execution time was 0.26 seconds.
The default value for PLSQL_MEMORY_SIZE is 128 MB on Linux and UNIX systems. This should be sufficient for several hundred PL/SQL program units of reasonable complexity to execute. After running a production workload for some time, check the value of PinHitRatio. If it is less than 0.90, consider increasing PLSQL_MEMORY_SIZE.
Set appropriate limit on the number of open files
Performance impact: Variable
For multithreaded applications that maintain many concurrent TimesTen database connections, the default number of open files permitted to each process by the operating system may be too low. See "Limits on number of open files" in the Oracle TimesTen In-Memory Database Reference for details on how to set new limits for the number of open files.
Configure log buffer and log file size parameters
Performance impact: Large
Increasing the value of LogBufMB and LogFileSize could have a substantial positive performance impact. LogBufMB is related to the LogFileSize connection attribute, which should be set to the same value or integral multiples of LogBufMB for best performance.
Log buffer waits occur when application processes cannot insert transaction data to the log buffer and must stall to wait for log buffer space to be freed. The usual reason for this is that the log flusher thread has not cleared out data fast enough. This may indicate that log buffer space is insufficient, file system transfer rate is insufficient, writing to the file system is taking too long, or the log flusher is CPU-bound.
-
A small
LogBufMBcould slow down write transactions when these transactions have to wait for a log flush operation to make space for redo logging. An oversized log buffer has no impact other than consuming extra memory. The value ofLOG_BUFFER_WAITSshows the number of times a thread was delayed while trying to insert a transaction log record into the log buffer because the log buffer was full. Generally, if this value is increasing, it indicates that the log buffer is too small. -
The
LogFileSizeattribute specifies the maximum size of each transaction log file in megabytes. IfLogFileSizeis too small, then TimesTen has to create multiple log files within a transaction log flush operation. The overhead of file creation often leads toLOG_BUF_WAITSevents, which could significantly impact performance.
You can observe the value of the LOG_BUFFER_WAITS metric (using either the SYS.MONITOR table or the ttIsql monitor command) to see if it increases while running a workload. After which, you can increase the value of LogBufMB to improve the database performance.
The trade-off from increasing the value of LogBufMB is that more transactions are buffered in memory and may be lost if the process crashes. If DurableCommits are enabled, increasing the value of LogBufMB value does not improve performance.
If log buffer waits still persist after increasing the LogBufMB and LogFileSize values, then review the other possible issues mentioned above.
The LogBufParallelism connection attribute specifies the number of transaction log buffer strands. This attribute improves transaction throughput when multiple connections execute write transactions concurrently. Configure this to the lesser value of the number of CPU cores on the system and the number of concurrent connections executing write transactions.
Note:
For more details, see "LogBufMB", "LogFileSize" and "LogBufParallelism" in the Oracle TimesTen In-Memory Database Reference.Avoid connection overhead for TimesTen Classic databases
Performance impact: Large
An idle database is a database with no connections. By default, TimesTen loads an idle database into memory when a first connection is made to it. When the final application disconnects from a database, a delay occurs when the database is written to the file system. If applications are continually connecting and disconnecting from a database, the database may be loaded to and unloaded from memory continuously, resulting in excessive file system I/O and poor performance. Similarly, if you are using a very large database you may want to pre-load the database into memory before any applications attempt to use it.
To avoid the latency of loading a database into memory, you can change the RAM policy of a TimesTen Classic database to enable databases to always remain in memory. The trade-off is that since the TimesTen Classic database is never unloaded from memory, a final disconnect checkpoint never occurs. So, applications should configure frequent checkpoints with the ttCkptConfig built-in procedure. See "ttCkptConfig" in the Oracle TimesTen In-Memory Database Reference for more information.
Alternatively, you can specify that the TimesTen Classic database remain in memory for a specified interval of time and accept new connections. If no new connections occur in this interval, TimesTen Classic unloads the database from memory and checkpoints it. You can also specify a setting to enable a system administrator to load and unload the database from memory manually.
To change the RAM policy of a TimesTen Classic database, use the ttAdmin utility. For more details on the RAM policy and the ttAdmin utility, see "Specifying a RAM policy" in this book and the "ttAdmin" section in the Oracle TimesTen In-Memory Database Reference.
Load the database into RAM when duplicating
Performance impact: Large
Load a TimesTen Classic database into memory with the ttAdmin -ramLoad command before you duplicate this database with the ttRepAdmin -duplicate utility. This places the database in memory, available for connections, instead of unloading it with a blocking checkpoint. For more information, see "Avoid connection overhead for TimesTen Classic databases" in this book and the "ttAdmin" and "ttRepAdmin" sections in the Oracle TimesTen In-Memory Database Reference.
Prevent reloading of the database after automatic recovery fails
Performance impact: Large
When TimesTen Classic recovers after a database is invalidated, a new database is reloaded. However, the invalidated database is only unloaded after all connections to this database are closed. Thus, both the invalidated database and the recovered database could exist in RAM at the same time.
Reloading a large database into memory when an invalidated database still exists in memory can fill up available RAM. See "Preventing an automatic reload of the database after failure" on how to stop automatic reloading of the database.
Reduce contention
Performance impact: Large
Database contention can substantially impede application performance.
To reduce contention in your application:
-
Choose the appropriate locking method. See "Choose the best method of locking".
-
Distribute data strategically in multiple tables or databases.
If your application suffers a decrease in performance because of lock contention and a lack of concurrency, reducing contention is an important first step in improving performance.
The lock.locks_granted.immediate, lock.locks_granted.wait and lock.timeouts columns in the SYS.SYSTEMSTATS table provide some information on lock contention:
-
lock.locks_granted.immediatecounts how often a lock was available and was immediately granted at lock request time. -
lock.locks_granted.waitcounts how often a lock request was granted after the requestor had to wait for the lock to become available. -
lock.timeoutscounts how often a lock request was not granted because the requestor did not want to wait for the lock to become available.
If limited concurrency results in a lack of throughput, or if response time is an issue, an application can reduce the number of threads or processes making API (JDBC, ODBC, or OCI) calls. Using fewer threads requires some queuing and scheduling on the part of the application, which has to trade off some CPU time for a decrease in contention and wait time. The result is higher performance for low-concurrency applications that spend the bulk of their time in the database.
Consider special options for maintenance
Performance impact: Medium
During special operations such as initial loading, you can choose different options than you would use during normal operations. In particular, consider using database-level locking for bulk loading; an example would be using ttBulkCp or ttMigrate. These choices can improve loading performance by a factor of two.
An alternative to database-level locking is to exploit concurrency. Multiple copies of ttBulkCp -i can be run using the -notblLock option. Optimal batching for ttBulkCp occurs by adding the -xp 256 option.
For more details, see "ttBulkCp" and "ttMigrate" in the Oracle TimesTen In-Memory Database Reference.
Check your driver
Performance impact: Large
There are two versions of the TimesTen Data Manager driver for each platform: a debug and production version. Unless you are debugging, use the production version. The debug library can be significantly slower. See "Creating a DSN on Linux and UNIX for TimesTen Classic" and "Connecting to TimesTen with ODBC and JDBC drivers" for a description of the TimesTen Data Manager drivers for the different platforms.
On Windows, make sure that applications that use the ODBC driver manager use a DSN that accesses the correct TimesTen driver. Make sure that applications are linked with the correct TimesTen driver. For direct connect applications, use the TimesTen Data Manager driver. An application can call the ODBC SQLGetInfo function with the SQL_DRIVER_NAME argument to determine which driver it is using.
Enable tracing only as needed
Performance impact: Large
Both ODBC and JDBC provide a trace facility to help debug applications. For performance runs, make sure that tracing is disabled except when debugging applications.
To turn the JDBC tracing on, use:
DriverManager.setLogStream method: DriverManager.setLogStream(new PrintStream(System.out, true));
By default tracing is off. You must call this method before you load a JDBC driver. Once you turn the tracing on, you cannot turn it off for the entire execution of the application.
Use metrics to evaluate performance
Performance impact: Variable
You can use the ttStats utility to collect and display database metrics. The ttStats utility can perform the following functions.
-
Monitor and display database performance metrics in real-time, calculating rates of change during each preceding interval.
-
Collect and store snapshots of metrics to the database then produce reports with values and rates of change from specified pairs of snapshots. (These functions are performed through calls to the
TT_STATSPL/SQL package.)
The ttStats utility gathers metrics from TimesTen system tables, views, and built-in procedures. In reports, this includes information such as a summary of memory usage, connections, and load profile, followed by metrics (as applicable) for SQL statements, transactions, PL/SQL memory, replication, logs and log holds, checkpoints, cache groups, latches, locks, XLA, and TimesTen connection attributes.
Call the ttStatsConfig built-in procedure to modify statistics collection parameters that affect the ttStatus utility. For more information on the parameters of the ttStatsConfig built-in procedure, see "ttStatsConfig" in the Oracle TimesTen In-Memory Database Reference.
For details on the ttStats utility, see "ttStats" in the Oracle TimesTen In-Memory Database Reference. For more details on the TT_STATS PL/SQL package, see "TT_STATS" in the Oracle TimesTen In-Memory Database PL/SQL Packages Reference.
Migrate data with character set conversions
Performance impact: Variable
If character set conversion is requested when migrating databases, performance may be slower than if character set conversion is not requested.
Use TimesTen native integer data types if appropriate
Performance impact: Variable
Declare the column types of a table with TimesTen native integer data types, TT_TINYINT, TT_SMALLINT, TT_INTEGER, or TT_BIGINT instead of the NUMBER data type to save space and improve the performance of calculations. TimesTen internally maps the SMALLINT, INTEGER, INT, DECIMAL, NUMERIC, and NUMBER data types to the NUMBER data type. When you define the column types of a table, ensure that you choose the appropriate native integer data type for your column to avoid overflow. For more information on native integer data types and the NUMBER data type, see "Numeric data types" in the Oracle TimesTen In-Memory Database SQL Reference.
If you use a TimesTen native integer data type when you create a TimesTen cache group that reads and writes to an Oracle database, ensure that the data type of the columns of the TimesTen cache group and the Oracle database are compatible. For more information about the mapping between Oracle Database and TimesTen data types, see "Mappings between Oracle Database and TimesTen data types" in the Oracle TimesTen Application-Tier Database Cache User's Guide.
Configure the checkpoint files and transaction log files to be on a different physical device
Performance impact: Large
For best performance, TimesTen recommends that you use the LogDir connection attribute to place the transaction log files on a different physical device from the checkpoint files. This is important if your application needs to have consistent response times and throughput. TimesTen places the checkpoint files in the location specified by the DataStore connection attribute, which is the full path name of the database and the file name prefix. If the transaction log files and checkpoint files are on different physical devices, I/O operations for checkpoints do not block I/O operations to the transaction log and vice versa. For more information on transaction logging, see "Transaction logging".
For more information about the LogDir and DataStore connection attributes, see "LogDir" and "DataStore" in the Oracle TimesTen In-Memory Database Reference.
Note:
If the database is already loaded into RAM and the transaction log files and checkpoint files for your database are on the same physical device, TimesTen writes a message to the daemon log file.Client/Server tuning
The following sections include tips for Client/Server tuning:
Diagnose Client/Server performance
Performance impact: Variable
You can analyze your Client/Server performance with the following statistics that are tracked in the SYS.SYSTEMSTATS table that can also be viewed with either the ttStats utility or the TT_STATS PL/SQL package:
Note:
For more details on theSYS.SYSTEMSTATS table, see "SYS.SYSTEMSTATS" in the Oracle TimesTen In-Memory Database System Tables and Views Reference. For details on the ttStats utility, see "ttStats" in the Oracle TimesTen In-Memory Database Reference. For more details on the TT_STATS PL/SQL package, see "TT_STATS" in the Oracle TimesTen In-Memory Database PL/SQL Packages Reference.-
Total number of executions from a Client/Server application.
-
Total number of
INSERT,UPDATE,DELETE,SELECT,MERGE,ALTER,CREATE,DROPstatements executed by the server. -
Total number of transactions committed or rolled back by the server.
-
Total number of table rows inserted, updated, or deleted by the server.
-
Total number of Client/Server roundtrips.
-
Total number of bytes transmitted or received by the server.
-
Total number of Client/Server disconnects.
Work locally when possible
Performance impact: Large
Using TimesTen Client to access databases on a remote server system adds network overhead to your connections. Whenever possible, write your applications to access TimesTen locally using a direct driver, and link the application directly with TimesTen.
Choose timeout connection attributes for your client
Performance impact: Variable
By default, connections wait 60 seconds for TimesTen Client and Server to complete a network operation. The TTC_Timeout attribute determines the maximum number of seconds a TimesTen Client application waits for the result from the corresponding TimesTen Server process before timing out.
The TTC_ConnectTimeout attribute specifies the maximum number of seconds the client waits for a SQLDriverConnect or SQLDisconnect request. It overrides the value of TTC_Timeout for those requests. Set the TTC_ConnectTimeout when you want connection requests to timeout with a different timeframe than the timeout provided for query requests. For example, you can set a longer timeout for connections if you know that it takes a longer time to connect, but set a shorter timeout for all other queries.
The overall elapsed time allotted for the SQLDriverConnect call depends on if automatic client failover is configured:
-
If there is just one
TTC_SERVERnconnection attribute defined, then there is no automatic client failover configured and the overall elapsed time allotted for the initial connection attempt is limited to 10 seconds. -
If automatic client failover is defined and there is more than one
TTC_SERVERnconnection attribute configured, then the overall elapsed time is four times the value of the timeout (whetherTTC_TimeoutorTTC_ConnectTimeout). For example, if the user specifiesTTC_TIMEOUT=10 and there are multipleTTC_SERVERnservers configured, then theSQLDriverConnectcall could take up to 40 seconds.
However, within this overall elapsed timeout, each connection attempt can take the time specified by the TTC_Timeout or TTC_ConnectTimeout value, where the TTC_ConnectTimeout value overrides the TTC_Timeout value.
See "Choose SQL and PL/SQL timeout values" for information about how TTC_Timeout and TTC_ConnectTimeout relates to SQL and PL/SQL timeouts.
For more details, see "TTC_Timeout" and "TTC_ConnectTimeout" in the Oracle TimesTen In-Memory Database Reference.
Choose a lock wait timeout interval
Performance impact: Variable
By default, connections wait 10 seconds to acquire a lock. To change the timeout interval for locks, set the LockWait conection attribute or use the ttLockWait built-in procedure. When running a workload of high lock-contention potential, consider setting the LockWait conection attribute to a smaller value for faster return of control to the application, or setting LockWait to a larger value to increase the successful lock grant ratio (with a risk of decreased throughput).
For more details, see "Setting wait time for acquiring a lock" in this book or "LockWait" or "ttLockWait" in the Oracle TimesTen In-Memory Database Reference.
Choose the best method of locking
Performance impact: Variable
When multiple connections access a database simultaneously, TimesTen uses locks to ensure that the various transactions operate in apparent isolation. TimesTen supports the isolation levels described in Chapter 7, "Transaction Management". It also supports the locking levels: database-level locking, table-level locking and row-level locking. You can use the LockLevel connection attribute to indicate whether database-level locking or row-level locking should be used. Use the ttOptSetFlag procedure to set optimizer hints that indicate whether table locks should be used. The default lock granularity is row-level locking.
Note:
For more information, see "LockLevel" and "ttOptSetFlag" in the Oracle TimesTen In-Memory Database Reference.Choose an appropriate lock level
If there is very little contention on the database, use table-level locking. It provides better performance and deadlocks are less likely. There is generally little contention on the database when transactions are short or there are few connections. In that case, transactions are not likely to overlap.
-
Table-level locking is also useful when a statement accesses nearly all the rows on a table. Such statements can be queries, updates, deletes or multiple inserts done in a single transaction.
-
Database-level locking completely restricts database access to a single transaction, and it is not recommended for ordinary operations. A long-running transaction using database-level locking blocks all other access to the database, affecting even the various background tasks needed to monitor and maintain the database.
-
Row-level locking is generally preferable when there are many concurrent transactions that are not likely to need access to the same row. On modern systems with a sufficient number of processors using high-concurrency, for example, multiple
ttBulkCpprocesses, row-level locking generally outperforms database-level locking.
Note:
For more information on thettBulkCp utility, see "ttBulkCp" in the Oracle TimesTen In-Memory Database Reference.Choose an appropriate isolation level
When using row-level locking, applications can run transactions at the SERIALIZABLE or READ_COMMITTED isolation level. The default isolation level is READ_COMMITTED. You can use the Isolation connection attribute to specify one of these isolation levels for new connections.
When running at SERIALIZABLE transaction isolation level, TimesTen holds all locks for the duration of the transaction.
-
Any transaction updating a row blocks writers until the transaction commits.
-
Any transaction reading a row blocks out writers until the transaction commits.
When running at READ_COMMITTED transaction isolation level, TimesTen only holds update locks for the duration of the transaction.
-
Any transaction updating a row blocks out writers to that row until the transaction commits. A reader of that row receives the previously committed version of the row.
-
Phantoms are possible. A phantom is a row that appears during one read but not during another read, or appears in modified form in two different reads, in the same transaction, due to early release of read locks during the transaction.
You can determine if there is an undue amount of contention on your system by checking for time-out and deadlock errors (errors 6001, 6002, and 6003). Information is also available in the lock.timeouts and lock.deadlocks columns of the SYS.SYSTEMSTATS table.
For more details on isolation levels, see "Transaction isolation levels".
Use shared memory segment as IPC when client and server are on the same system
Performance impact: Variable
The TimesTen Client normally communicates with TimesTen Server using TCP/IP sockets. If both the TimesTen Client and TimesTen Server are on the same system, client applications show improved performance by using a shared memory segment or a UNIX domain socket for inter-process communication (IPC).
To use a shared memory segment as IPC, you must set the server options in the timesten.conf file. For a description of the server options, see "Modifying the TimesTen Server attributes".
In addition, applications that use shared memory for IPC must use a logical server name for the Client DSN with ttShmHost as the Network Address. For more information, see "Creating and configuring Client DSNs on Linux and UNIX".
This feature may require a significant amount of shared memory. The TimesTen Server pre-allocates the shared memory segment irrespective of the number of existing connections or the number of statements within all connections.
If your application is running on a Linux or UNIX system and you are concerned about memory usage, the applications using TimesTen Client ODBC driver may improve the performance by using UNIX domain sockets for communication. The performance improvement when using UNIX domain sockets is not as large as when using ShmIPC.
Applications that take advantage of UNIX domain sockets for local connections must use a logical server name for the Client DSN with ttLocalHost as the Network Address. For more information, see "Creating and configuring Client DSNs on Linux and UNIX". In addition, make sure that your system kernel parameters are configured to allow the number of connections you require.
For more information, see "Linux prerequisites" in the Oracle TimesTen In-Memory Database Installation, Migration, and Upgrade Guide.
Enable prefetch close for read-only transactions
A TimesTen extension enables applications to optimize read-only query performance in client/server applications. When you enable prefetch close, the server closes the cursor and commits the transaction after the server has fetched the entire result set for a read-only query. This enhances performance by decreasing the network round-trips between client and server
-
ODBC: Use the
SQLSetConnectOptionto set theTT_PREFETCH_CLOSEODBC connection option. See "Optimizing query performance" in the Oracle TimesTen In-Memory Database C Developer's Guide for details. -
JDBC: Call the
TimesTenConnectionmethodsetTtPrefetchClose()with a setting oftrue. "Optimizing query performance" in the Oracle TimesTen In-Memory Database Java Developer's Guide for details.
Use a connection handle when calling SQLTransact
You should always call SQLTransact with a valid HDBC and a null environment handle:
SQLTransact (SQL_NULL_HENV, ValidHDBC, fType)
It is possible to call SQLTransact with a non-null environment handle and a null connection handle, but that usage is not recommended as it abruptly commits or rolls back every transaction for the process, which is slow and can cause unexpected application behavior.
Enable multi-threaded mode to handle concurrent connections
The MaxConnsPerServer connection attribute sets the maximum number of concurrent connections allowed for a TimesTen server process. By default, MaxConnsPerServer equals to 1, meaning that each TimesTen server process can only handle one client connection.
Setting MaxConnsPerServer > 1 enables multi-threaded mode for the database so that it can use threads instead of processes to handle client connections. This reduces the time required for applications to establish new connections and increases overall efficiency in configurations that use a large number of concurrent client/server connections.
See "Defining Server DSNs for TimesTen Server on a Linux or UNIX system" for full details.
SQL tuning
After you have determined the overall locking and I/O strategies, make sure that the individual SQL statements are executed as efficiently as possible. The following sections describe how to streamline your SQL statements:
-
Collect and evaluate sampling of execution times for SQL statements
-
Control the invalidation of commands in the SQL command cache
-
Store data efficiently with column-based compression of tables
-
Control read optimization during concurrent write operations
Tune statements and use indexes
Verify that all statements are executed efficiently. For example, use queries that reference only the rows necessary to produce the required result set. If only col1 from table t1 is needed, use the statement:
SELECT col1 FROM t1...
instead of using:
SELECT * FROM t1...
Chapter 9, "The TimesTen Query Optimizer" describes how to view the plan that TimesTen uses to execute a statement. Alternatively, you can use the ttIsql showplan command to view the plan. View the plan for each frequently executed statement in the application. If indexes are not used to evaluate predicates, consider creating new indexes or rewriting the statement or query so that indexes can be used. For example, indexes can only be used to evaluate WHERE clauses when single columns appear on one side of a comparison predicate (equalities and inequalities), or in a BETWEEN predicate.
If this comparison predicate is evaluated often, it would therefore make sense to rewrite
WHERE c1+10 < c2+20
to
WHERE c1 < c2+10
and create an index on c1.
The presence of indexes does slow down write operations such as UPDATE, INSERT, DELETE and CREATE VIEW. If an application does few reads but many writes to a table, an index on that table may hurt overall performance rather than help it.
Occasionally, the system may create a temporary index to speed up query evaluation. If this happens frequently, it is better for the application itself to create the index. The CMD_TEMP_INDEXES column in the MONITOR table indicates how often a temporary index was created during query evaluation.
If you have implemented time-based aging for a table or cache group, create an index on the timestamp column for better performance of aging. See "Time-based aging".
Collect and evaluate sampling of execution times for SQL statements
Performance impact: Variable
TimesTen provides built-in procedures that measure the execution time of SQL operations to determine the performance of SQL statements. Instead of tracing, the built-in procedures sample the execution time of SQL statements during execution. The built-in procedures measure the execution time of SQL statements by timing the execution within the SQLExecute API.
You can configure the sampling rate and how the execution times are collected with the ttStatsConfig built-in procedure and the following name-value pairs:
Table 10-1 ttStatsConfig parameter and value descriptions
| Parameter | Description |
|---|---|
|
|
Configures how often a SQL statement execution timing sample is taken. The default is 0, which means that the sampling is turned off. For example, when set to 10, TimesTen captures the wall clock time of the SQL statement execution for every 10th statement. |
|
|
Configures how often a SQL statement sample is taken for an individual connection. The value includes two parameters separated by a comma within quotes, so that it appears as a single value. The first number is the connection ID; the second is the same as the |
|
|
When set to a nonzero value, clears the SQL execution time histogram data. |
|
|
Sets the level of statistics to be taken. Values can be set to either |
The following are examples of how to set the name-value pairs with the ttStatsConfig built-in procedure:
Note:
You can achieve the best results by choosing representative connections with theConnSampleFactor parameter in the ttStatsConfig built-in procedure, rather than sampling all transactions. Sampling all transactions with a small sample factor can affect your performance negatively.
For meaningful results, the database should remain in memory since unloading and re-loading the database empties the SQL command cache.
Sample every 5th statement on connection 1.
Command> call ttStatsConfig('ConnSampleFactor', '1,5');
< CONNSAMPLEFACTOR, 1,5 >
1 row found.
Turn off sampling on connection 1.
Command> call ttStatsConfig('ConnSampleFactor', '1,0');
< CONNSAMPLEFACTOR, 1,0 >
1 row found.
Sample every command:
Command> call ttStatsConfig('SqlCmdSampleFactor',1);
< SQLCMDSAMPLEFACTOR, 1 >
1 row found.
Check whether sampling:
Command> call ttStatsConfig('SqlCmdSampleFactor');
< SQLCMDSAMPLEFACTOR, 1 >
1 row found.
Check the current database statistics collection level.
Command> call ttStatsConfig('StatsLevel');
< STATSLEVEL, TYPICAL >
1 row found.
Turn off database statistics collection by setting to NONE.
Command> call ttStatsConfig('StatsLevel','None');
< STATSLEVEL, NONE >
1 row found.
Once you have configured the statistics that you want collected, the collected statistics are displayed with the ttSQLCmdCacheInfo built-in procedure. To display the execution time histogram at either the command or database levels, use the ttSQLExecutionTimeHistogram built-in procedure.
The ttSQLCmdCacheInfo built-in procedure displays the following information relating to SQL execution time statistics:
-
Number of fetch executions performed internally for this statement.
-
The timestamp when the statement started.
-
The maximum wall clock execute time in seconds of this statement.
-
Last measured execution time in seconds of the statement.
-
The minimum execute time in seconds of the statement.
In the following example, the display shows these statistics as the last five values:
Command> vertical call ttSQLCmdCacheInfo(135680792); SQLCMDID: 135680792 PRIVATE_COMMAND_CONNECTION_ID: -1 EXECUTIONS: 97414 PREPARES: 50080 REPREPARES: 1 FREEABLE: 1 SIZE: 3880 OWNER: ORATT QUERYTEXT: select min(unique2) from big1 FETCHCOUNT: 40 STARTTIME: 2018-04-10 13:10:46.808000 MAXEXECUTETIME: .001319 LASTEXECUTETIME: .000018 MINEXECUTETIME: .000017 EXECLOC: 0 GRIDCMDID: 00000000000000000000 TEMPSPACEUSAGE: 0 MAXTEMPSPACEUSAGE: 0 1 row found.
For more information on the ttSQLCmdCacheInfo built-in procedure, see "ttSQLCmdCacheInfo" in the Oracle TimesTen In-Memory Database Reference.
The ttSQLExecutionTimeHistogram built-in procedure displays a histogram of SQL execution times for either a single SQL command or all SQL commands in the command cache, assuming that sampling is enabled where SQLCmdSampleFactor is greater than zero.
The histogram displays a single row for each bucket of the histogram. Each row includes the following information:
-
The number of SQL statement execution time operations that have been measured since either the TimesTen database was started or after the
ttStatsConfigbuilt-in procedure was used to reset statistics. -
Accumulated wall clock execution time.
-
The execution time limit that denotes each time frame.
-
The last row shows the number of SQL statements that executed in a particular time frame.
The following example shows the output for the ttSQLExecutionTimeHistogram built-in procedure:
The following example of the ttSQLExecutionTimeHistogram built-in procedure shows that a total of 1919 statements executed. The total time for all 1919 statements to execute was 1.090751 seconds. This example shows that SQL statements ran in the following time frames:
-
278 statements executed in a time frame that was less than or equal to .00001562 seconds.
-
1484 statements executed in a time frame that was greater than .00001562 seconds and less than or equal to .000125 seconds.
-
35 statements executed in a time frame that was greater than .000125 seconds and less than or equal to .001 seconds.
-
62 statements executed in a time frame that was greater than .001 seconds and less than or equal to .008 seconds.
-
60 statements executed in a time frame that was greater than .008 seconds and less than or equal to .064 seconds.
Command> call ttSQLExecutionTimeHistogram; < 1919, 1.090751, .00001562, 278 > < 1919, 1.090751, .000125, 1484 > < 1919, 1.090751, .001, 35 > < 1919, 1.090751, .008, 62 > < 1919, 1.090751, .064, 60 > < 1919, 1.090751, .512, 0 > < 1919, 1.090751, 4.096, 0 > < 1919, 1.090751, 32.768, 0 > < 1919, 1.090751, 262.144, 0 > < 1919, 1.090751, 9.999999999E+125, 0 > 10 rows found.
Select the type of index appropriately
The TimesTen database supports hash and range indexes. The following details when it is appropriate to use each type of index.
Hash indexes are useful for finding rows with an exact match on one or more columns. Hash indexes are useful for doing equality searches. A hash index is created with either of the following:
-
You can create a hash index or a unique hash index with the
CREATE [UNIQUE] HASH INDEXstatement. -
You can create a unique hash index when creating your table with the
CREATE TABLE... UNIQUE HASH ONstatement. The unique hash index is specified over the primary key columns of the table.
Range indexes are created by default with the CREATE TABLE statement or created with the CREATE [UNIQUE] HASH INDEX statement. Range indexes can speed up exact key lookups but are more flexible and can speed up other queries as well. Select a range index if your queries include LESS THAN or GREATER THAN comparisons. Range indexes are effective for high-cardinality data: that is, data with many possible values, such as CUSTOMER_NAME or PHONE_NUMBER. Range indexes are optimized for in-memory data management.
Range indexes can also be used to speed up "prefix" queries. A prefix query has equality conditions on all but the last key column that is specified. The last column of a prefix query can have either an equality condition or an inequality condition.
Consider the following table and index definitions:
Command> CREATE TABLE T(i1 tt_integer, i2 tt_integer, i3 tt_integer, ...); Command> CREATE INDEX IXT on T(i1, i2, i3);
The index IXT can be used to speed up the following queries:
Command> SELECT * FROM T WHERE i1>12; Command> SELECT * FROM T WHERE i1=12 and i2=75; Command> SELECT * FROM T WHERE i1=12 and i2 BETWEEN 10 and 20; Command> SELECT * FROM T WHERE i1=12 and i2=75 and i3>30;
The index IXT is not used for the following queries, because the prefix property is not satisfied:
Command> SELECT * FROM T WHERE i2=12;
There is no equality condition for i1.
The index IXT is used, but matching only occurs on the first two columns for queries like the following:
Command> SELECT * FROM T WHERE i1=12 and i2<50 and i3=630;
Range indexes have a dynamic structure that adjusts itself automatically to accommodate changes in table size. A range index can be either unique or nonunique and can be declared over nullable columns. It also allows the indexed column values to be changed once a record is inserted. A range index is likely to be more compact than an equivalent hash index.
Size hash indexes appropriately
TimesTen uses hash indexes as both primary key constraints and when specified as part of the CREATE INDEX statement. The size of the hash index is determined by the PAGES parameter specified in the UNIQUE HASH ON clause of the CREATE TABLE and CREATE INDEX statements. The value for PAGES should be the expected number of rows in the table divided by 256; for example, a 256,000 row table should have PAGES = 1000. A smaller value may result in a greater number of hash collisions, decreasing performance, while a larger value may provide somewhat increased performance at the cost of extra space used by the index.
If the number of rows in the table varies dramatically, and if performance is the primary consideration, it is best to create a large index. If the size of a table cannot be accurately predicted, consider using a range index. Also, consider the use of unique indexes when the indexed columns are large CHAR or binary values or when many columns are indexed. Unique indexes may be faster than hash indexes in these cases.
If the performance of record inserts degrades as the size of the table gets larger, it is very likely that you have underestimated the expected size of the table. You can resize the hash index by using the ALTER TABLE statement to reset the PAGES value in the UNIQUE HASH ON clause. See information about SET PAGES in the "ALTER TABLE" section in the Oracle TimesTen In-Memory Database SQL Reference.
Use foreign key constraint appropriately
Performance impact: Variable
The declaration of a foreign key has no performance impact on SELECT queries, but it slows down the INSERT and UPDATE operations on the table that the foreign key is defined on and the UPDATE and DELETE operations on the table referenced by the foreign key. The slow down is proportional to the number of foreign keys that either reference or are defined on the table.
Compute exact or estimated statistics
Performance impact: Large
If statistics are available on the data in the database, the TimesTen optimizer uses them when preparing a command to determine the optimal path to the data. If there are no statistics, the optimizer uses generic guesses about the data distribution.
Note:
See Chapter 9, "The TimesTen Query Optimizer" for more information.You should compute statistics before preparing your statements, since the information is likely to result in a more efficient query optimizer plan. When gathering statistics, you need to determine when and how often to gather new statistics as performance is affected by the statistics collection process. The frequency of collection should balance the task of providing accurate statistics for the optimizer against the processing overhead incurred by the statistics collection process.
Since computing statistics is a time-consuming operation, you should compute statistics with the following guidelines:
-
Update statistics after loading your database or after major application upgrades.
-
Do not update statistics during a heavy transaction load.
-
Update statistics when there is substantial creation or alteration on tables, columns, or PL/SQL objects.
If you have created or altered a substantial number of tables, columns, or PL/SQL objects in your database, you should update the data dictionary optimizer statistics for the following system tables:
SYS.TABLES,SYS.COLUMNS, andSYS.OBJ$. -
When you substantially modify tables in batch operations, such as a bulk load or bulk delete, you can gather statistics on these tables as part of the batch operation.
-
Update statistics infrequently, such as once a week or once a month, when tables are only incrementally modified.
-
Update statistics as part of a regularly executed script or batch job during low transaction load times.
-
When updating the statistics for multiple large tables, see "Update table statistics for large tables in parallel".
Note:
For performance reasons, TimesTen does not hold a lock on tables or rows when computing statistics.Use the following for computing statistics: ttIsql statsupdate command, ttOptUpdateStats, or ttOptEstimateStats. Providing an empty string as the table name updates statistics for all tables in the current user's schema.
-
The
statsupdatecommand withinttIsqlevaluates every row of the table(s) in question and computes exact statistics. -
The
ttOptUpdateStatsbuilt-in procedure evaluates every row of the table(s) in question and computes exact statistics. -
The
ttOptEstimateStatsprocedure evaluates only a sampling of the rows of the table(s) in question and produces estimated statistics. This can be faster, but may result in less accurate statistics. Computing statistics with a sample of 10 percent is about ten times faster than computing exact statistics and generally results in the same execution plans.
Note:
For more details onttIsql or the built-in procedures, see "ttIsql" and "Built-In Procedures" in the Oracle TimesTen In-Memory Database Replication Guide.Update table statistics for large tables in parallel
Performance impact: Large
It is important to keep table statistics up to date for all TimesTen tables. However, this process can be time-consuming and performance intensive when used on large tables. Consider calling the ttOptUpdateStats built-in procedure in parallel when updating the statistics for multiple large tables.
Note:
A TimesTen table is considered a small table when it contains less than 1 million rows. A TimesTen table is considered a large table when it contains over 100 million rows.Call the ttOptUpdateStats built-in procedure for all of the large tables where you want to update table statistics. Make sure to call each ttOptUpdateStats built-in procedure in parallel. For more information on the ttOptUpdateStats built-in procedure, see "ttOptUpdateStats" in the Oracle TimesTen In-Memory Database Reference.
Command> call ttOptUpdateStats('table1',0,0);
Command> call ttOptUpdateStats('table2',0,0);
...
...
Command> call ttOptUpdateStats('finaltable',0,0);
Once the ttOptUpdateStats built-in procedure calls have completed, determine how many transactions are accessing the large TimesTen tables for which you updated table statistics. During low transaction load times execute the ttOptCmdCacheInvalidate('',1) built-in procedure. For more information on the ttOptCmdCacheInvalidate built-in procedure, see "ttOptCmdCacheInvalidate" in the Oracle TimesTen In-Memory Database Reference. During high transaction load times execute the following built-in procedures and make sure to call each ttOptCmdCacheInvalidate built-in procedure in parallel:
Command> call ttOptCmdCacheInvalidate('table1',1);
Command> call ttOptCmdCacheInvalidate('table2',1);
...
...
Command> call ttOptCmdCacheInvalidate('finaltable',1);
The table statistics of your tables are now up to date and compiled commands in the SQL command cache are invalidated.
Create script to regenerate current table statistics
Performance impact: Variable
You can generate a SQL script with the ttOptStatsExport built-in procedure from which you can restore the table statistics to the current state. When you apply these statements, you re-create the same environment. Recreating the table statistics could be used for diagnosing SQL performance.
Call the ttOptStatsExport built-in procedure to return the set of statements required to restore the table statistics to the current state. If no table is specified, ttOptStatsExport returns the set of statements required to restore the table statistics for all user tables that the calling user has permission to access.
Note:
For more information and syntax for this built-in procedure, see "ttOptStatsExport" in the Oracle TimesTen In-Memory Database Reference.The following example returns a set of built-in procedure commands that would be required to be executed to restore the statistics for the employees table:
Command> call ttOptStatsExport('hr.employees');
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'EMPLOYEE_ID', 0, (6, 0, 107, 107,
(20, 20, 1 ,100, 120, 101), (20, 20, 1 ,121, 141, 122), (20, 20, 1 ,142, 162,
143), (20, 20, 1 ,163, 183, 164), (20, 20, 1 ,184, 204, 185), (1, 1, 1 ,205, 206,
205))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'FIRST_NAME', 0, (1, 0, 89, 107,
(89, 107, 0, 'Adam', 'Winston', 'Adam'))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'LAST_NAME', 0, (1, 0, 97, 107, (97,
107, 0, 'Abel', 'Zlotkey', 'Abel'))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'EMAIL', 0, (6, 0, 107, 107, (20,
20, 1, 'ABANDA', 'DGREENE', 'ABULL'), (20, 20, 1, 'DLEE', 'JKING', 'DLORENTZ'),
(20, 20, 1, 'JLANDRY', 'LOZER', 'JLIVINGS'), (20, 20, 1, 'LPOPP', 'RMATOS',
'LSMITH'), (20, 20, 1, 'RPERKINS', 'WGIETZ', 'SANDE'), (1, 1, 1, 'WSMITH',
'WTAYLOR', 'WSMITH'))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'PHONE_NUMBER', 0, (1, 0, 103, 107,
(103, 107, 0, '011.44.1343.329268', '650.509.4876', '011.44.1343.329268'))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'HIRE_DATE', 0, (1, 0, 90, 107, (90,
107, 0 ,'1987-06-17 00:00:00', '2000-04-21 00:00:00', '1987-06-17 00:00:00'))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'JOB_ID', 0, (4, 0, 19, 107, (11,
16, 5, 'AC_ACCOUNT', 'PR_REP', 'FI_ACCOUNT'), (3, 11, 30, 'PU_CLERK', 'SA_REP',
'SA_REP'), (1, 20, 20, 'SH_CLERK', 'ST_CLERK', 'ST_CLERK'), (0, 0, 5, 'ST_MAN',
'ST_MAN', 'ST_MAN'))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'SALARY', 0, (1, 0, 57, 107, (57,
107, 0 ,2100, 24000, 2100))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'COMMISSION_PCT', 0, (1, 72, 7, 107,
(7, 35, 0 ,0.1, 0.4, 0.1))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'MANAGER_ID', 0, (1, 1, 18, 107,
(18, 106, 0 ,100, 205, 100))); >
< call ttoptsetcolIntvlstats('HR.EMPLOYEES', 'DEPARTMENT_ID', 0, (3, 1, 11, 107,
(4, 10, 45 ,10, 50, 50), (2, 6, 34 ,60, 80, 80), (2, 5, 6 ,90, 110, 100))); >
< call ttoptsettblstats('HR.EMPLOYEES', 107, 0); >
12 rows found.
Control the invalidation of commands in the SQL command cache
Performance impact: Variable
TimesTen caches compiled commands in the SQL command cache. These commands can be invalidated. An invalidated command is usually reprepared automatically just before it is re-executed. A single command may be prepared several times.
Note:
See "When optimization occurs" for more information on how commands are automatically invalidated.When you compute statistics, the process of updating and compiling commands may compete for the same locks on certain tables. If statistics are collected in multiple transactions and commands are invalidated after each statistics update, the following issues may occur:
-
A join query that references multiple tables might be invalidated and recompiled more than once.
-
Locks needed for recompilation could interfere with updating statistics, which could result in a deadlock.
You can avoid these issues by controlling when commands are invalidated in the SQL command cache. In addition, you may want to hold off invalidation of all commands if you know that the table and index cardinalities will be changing significantly.
You can control invalidation of the commands, as follows:
-
Compute statistics without invalidating the commands in the SQL command cache. Set the
invalidateoption to 0 in either thettIsqlstatsupdatecommand, thettOptUpdateStatsbuilt-in procedure, or thettOptEstimateStatsbuilt-in procedure -
Manually invalidate the commands in the SQL command cache once all statistics have been compiled with the
ttOptCmdCacheInvalidatebuilt-in procedure.
The ttOptCmdCacheInvalidate built-in procedure can invalidate commands associated solely with a table or all commands within the SQL command cache. In addition, you can specify whether the invalidated commands are to be recompiled or marked as unusable.
Note:
For complete details on when to optimally calculate statistics, see "Compute exact or estimated statistics". In addition, see "ttIsql", "ttOptUpdateStats", "ttOptEstimateStats", or "ttOptCmdCacheInvalidate" in the Oracle TimesTen In-Memory Database Reference.Avoid ALTER TABLE
Performance impact: Variable
The ALTER TABLE statement allows applications to add columns to a table and to drop columns from a table. Although the ALTER TABLE statement itself runs very quickly in most cases, the modifications it makes to the table can cause subsequent DML statements and queries on the table to run more slowly. The actual performance degradation that the application experiences varies with the number of times the table has been altered and with the particular operation being performed on the table.
Dropping VARCHAR2 and VARBINARY columns is slower than dropping columns of other data types since a table scan is required to free the space allocated to the existing VARCHAR2 and VARBINARY values in the column to be dropped.
Avoid nested queries
Performance impact: Variable
If you can, it is recommended that you should rewrite your query to avoid nested queries that need materialization of many rows.
The following are examples of nested queries that may need to be materialized and result in multiple rows:
-
Aggregate nested query with
GROUP BY -
Nested queries that reference
ROWNUM -
Union, intersect, or minus nested queries
-
Nested queries with
ORDER BY
For example, the following aggregate nested query results in an expensive performance impact:
Command> SELECT * FROM (SELECT SUM(x1) sum1 FROM t1 GROUP BY y1), (SELECT sum(x2) sum2 FROM t2 GROUP BY y2) WHERE sum1=sum2;
The following is an example of a nested query that references ROWNUM:
Command> SELECT * FROM (SELECT rownum rc, x1 FROM t1 WHERE x1>100), (SELECT ROWNUM rc, x2 FROM t2 WHERE x2>100) WHERE x1=x2;
The following is an example of a union nested query:
Command> SELECT * FROM (SELECT x1 FROM t1 UNION SELECT x2 FROM t2), (SELECT x3 FROM t3 GROUP BY x3) WHERE x1=x3;
For more information on subqueries, see "Subqueries" in the Oracle TimesTen In-Memory Database SQL Reference.
Prepare statements in advance
Performance impact: Large
If you have applications that generate a statement multiple times searching for different values each time, prepare a parameterized statement to reduce compile time. For example, if your application generates statements like:
SELECT A FROM B WHERE C = 10; SELECT A FROM B WHERE C = 15;
You can replace these statements with the single statement:
SELECT A FROM B WHERE C = ?;
TimesTen shares prepared statements automatically after they have been committed. As a result, an application request to prepare a statement for execution may be completed very quickly if a prepared version of the statement already exists in the system. Also, repeated requests to execute the same statement can avoid the prepare overhead by sharing a previously prepared version of the statement.
Even though TimesTen allows prepared statements to be shared, it is still a good practice for performance reasons to use parameterized statements. Using parameterized statements can further reduce prepare overhead, in addition to any savings from sharing statements.
Avoid unnecessary prepare operations
Performance impact: Large
Because preparing SQL statements is an expensive operation, your application should minimize the number of calls to the prepare API. Most applications prepare a set of statements at the beginning of a connection and use that set for the duration of the connection. This is a good strategy when connections are long, consisting of hundreds or thousands of transactions. But if connections are relatively short, a better strategy is to establish a long-duration connection that prepares the statements and executes them on behalf of all threads or processes. The trade-off here is between communication overhead and prepare overhead, and can be examined for each application. Prepared statements are invalidated when a connection is closed.
See "ttSQLCmdCacheInfoGet" in the Oracle TimesTen In-Memory Database Reference for related information.
Store data efficiently with column-based compression of tables
Performance impact: Large
TimesTen provides the ability to compress tables at the column level, which stores the data more efficiently at the cost of lower performance. This mechanism provides space reduction for tables by eliminating the redundant storage of duplicate values within columns and improves the performance of SQL queries that perform full table scans.
When compressing columns of a TimesTen table, consider the following:
-
Compress a column if values are repeated throughout such as the name of countries or states.
-
Compress a column group if you often access multiple columns together.
-
Do not compress columns that contain data types that require a small amount of storage such as
TT_TINYINT. -
TimesTen does not compress
NULLvalues.
You can define one or more columns in a table to be compressed together, which is called a compressed column group. You can define one or more compressed column groups in each table.
A dictionary table is created for each compressed column group that contains a column with all the distinct values of the compressed column group. The compressed column group now contains a pointer to the row in the dictionary table for the appropriate value. The width of this pointer can be 1, 2, or 4 bytes long depending on the maximum number of entries you defined for the dictionary table. So if the sum of the widths of the columns in a compressed column group is wider than the 1, 2, or 4 byte pointer width, and if there are a lot of duplicate values of those column values, you have reduced the amount of space used by the table.
Figure 10-1 shows the compressed column group in the table pointing to the appropriate row in the dictionary table.
Figure 10-1 Column-based compression of tables
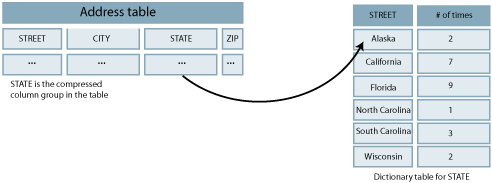
Description of ''Figure 10-1 Column-based compression of tables''
The dictionary table has a column of pointers to each of the distinct values. When the user configures the maximum number of distinct entries for the compressed column group, the size of the compressed column group is set as follows:
-
1 byte for a maximum number of entries of 255 (28-1). When the maximum number is between 1 and 255, the dictionary size is set to 255 (28-1) values and the compressed column group pointer column is 1 byte.
-
2 bytes for a maximum number of entries of 65,535 (216-1). When the maximum number is between 256 and 65,535, the dictionary size is set to 65,535 (216-1) values and the compressed column group pointer column is 2 bytes.
-
4 bytes for a maximum number of entries of 4,294,967,295 (232-1). When the maximum number is between 65,536 and 4,294,967,295, the dictionary size is set to 4,294,967,295 (232-1) values and the compressed column group pointer column is 4 bytes. This is the default.
Compressed column groups can be added at the time of table creation or added later using ALTER TABLE. You can drop the entire compressed column group with the ALTER TABLE statement. For more information, see "ALTER TABLE" and "CREATE TABLE" in the Oracle TimesTen In-Memory Database SQL Reference.
You can call the ttSize built-in procedure to review the level of compression that TimesTen achieved on your compressed table. For more information on the ttSize built-in procedure, see "ttSize" in the Oracle TimesTen In-Memory Database Reference.
Control read optimization during concurrent write operations
Performance impact: Variable
TimesTen concurrently processes read and write operations optimally. Your read operations can be optimized for read-only concurrency when you use transaction level optimizer hints such as ttOptSetFlag ('tblLock',1) or statement level optimizer hints such as /*+ tt_tbllock(1) tt_rowlock(0) */. Write operations that operate concurrently with read optimized queries may result in contention.
You can control read optimization during periods of concurrent write operations with the ttDBWriteConcurrencyModeSet built-in procedure. This built-in procedure enables you to switch between a standard mode and an enhanced write concurrent mode. In the standard mode, the optimizer respects read optimization hints. In the enhanced write concurrent mode, the optimizer ignores read optimization hints and does not use shared read table locks or write table locks.
Note:
For more information about table locking, see "Locking granularities".For more information about optimizer hints, see "Use optimizer hints to modify the execution plan".
For more information about transaction level optimizer hints, see "ttOptSetFlag" in the Oracle TimesTen In-Memory Database Reference.
Set the mode of the ttDBWriteConcurrencyModeSet built-in procedure to 1 to enable the enhanced write concurrent mode and disable read optimization. Set the mode to 0 to disable the enhanced write concurrent mode and re-enable read optimization.
When the mode is set to 1, all transaction and statement table lock optimizer hints are ignored. This affects the following:
-
Shared read table-level locks for
SELECTquery and subqueries that are triggered by optimizer hints. -
Write table locks for DML statements that are triggered by optimizer hints.
Regardless of the mode setting, table locks that are not triggered by optimizer hints are not affected.
Set the wait of the ttDBWriteConcurrencyModeSet built-in procedure to 0 to perform a mode switch without notifications. Set the wait of the ttDBWriteConcurrencyModeSet built-in procedure to 1 to force the built-in procedure to wait until the mode transition is complete.
Execution of certain SQL statements causes the mode of the ttDBWriteConcurrencyModeSet built-in procedure to remain in transition. Such SQL statements must match the following two conditions:
-
Affected by the write concurrency mode.
-
Compiled in a different write concurrency mode.
The mode of the ttDBWriteConcurrencyModeSet built-in procedure remains in transition until all such SQL statements complete. The ttDBWriteConcurrencyModeSet built-in procedure uses lock acquisition to wait during the mode transition. An error is returned if the ttDBWriteConcurrencyModeSet built-in procedure is not granted a lock within the timeout interval of the current connection.
Note:
For more information about thettDBWriteConcurrencyModeSet, ttLockWait, ttDBWriteConcurrencyModeGet built-in procedures, see "ttDBWriteConcurrencyModeSet", "ttLockWait", and "ttDBWriteConcurrencyModeGet" in the Oracle TimesTen In-Memory Database Reference.Choose SQL and PL/SQL timeout values
Performance impact: Variable
When setting timeout values, consider the relationship between these attributes:
-
SQLQueryTimeoutorSQLQueryTimeoutMSec: Controls how long a SQL statement executes before timing out.By default, SQL statements do not time out. In some cases, you may want to specify a value for either the
SQLQueryTimeoutorSQLQueryTimeoutMSecconnection attribute to set the time limit in seconds or milliseconds within which the database should execute SQL statements. (Note that this applies to any SQL statement, not just queries.)Both
SQLQueryTimeoutandSQLQueryTimeoutMsecattributes are internally mapped to one timeout value in milliseconds. If different values are specified for these attributes, only one value is retained. For more details, see "SQLQueryTimeout" and "SQLQueryTimeoutMSec" in the Oracle TimesTen In-Memory Database Reference. -
PLSQL_TIMEOUT: Controls how long a PL/SQL block executes before timing out.By default, PL/SQL program units (PL/SQL procedures, anonymous blocks and functions) are allowed to run for 30 seconds before being automatically terminated. In some cases, you may want to modify the
PLSQL_TIMEOUTconnection attribute value to allow PL/SQL program units additional time to run. You can also modify this attribute with an "ALTER SESSION" statement during runtime.For more details, see "PLSQL_TIMEOUT" in the Oracle TimesTen In-Memory Database Reference.
-
TTC_Timeout: Controls how long a TimesTen client waits for a response from the TimesTen Server when the client has requested the server to execute a SQL statement or PL/SQL block. -
TTC_ConnectTimeout: Controls how long the client waits for aSQLDriverConnectorSQLDisconnectrequest. It overrides the value ofTTC_Timeoutfor those requests.Also see "Choose timeout connection attributes for your client".
If you use TimesTen Client/Server, then SQLQueryTimeout (or SQLQueryTimeoutMSec) and PLSQL_TIMEOUT (relevant for PL/SQL) should be set to significantly lower values than TTC_Timeout, to avoid the possibility of the client mistaking a long-running SQL statement or PL/SQL block for a non-responsive server.
If you use PL/SQL, the relationship between SQLQueryTimeout (or SQLQueryTimeoutMSec) and PLSQL_TIMEOUT depends on how many SQL statements you use in your PL/SQL blocks. If none, there is no relationship. If the maximum number of SQL statements in a PL/SQL block is n, then PLSQL_TIMEOUT should presumably equal at least n x SQLQueryTimeout (or n x 1000 x SQLQueryTimeoutMSec), including consideration of processing time in PL/SQL.
Note:
IfSQLQueryTimeout (or SQLQueryTimeoutMSec) and PLSQL_TIMEOUT are not set sufficiently less than TTC_Timeout, and the client mistakes a long-running SQL statement or PL/SQL block for a non-responsive server and terminates the connection, the server will cancel the SQL statement or PL/SQL block as soon as it notices the termination of the connection.Materialized view tuning
The following sections include tips for improving performance of materialized views:
Limit number of join rows
Performance impact: Variable
Larger numbers of join rows decrease performance. You can limit the number of join rows and the number of tables joined by controlling the join condition. For example, use only equality conditions that map one row from one table to one or at most a few rows from the other table.
Use indexes on join columns
Performance impact: Variable
Create indexes on the columns of the detail table that are specified in the SELECT statement that creates the join. Also consider creating an index on the materialized view itself. This can improve the performance of keeping the materialized view updated.
If an UPDATE or DELETE operation on a detail table is often based on a condition on a column, try to create an index on the materialized view on this column if possible.
For example, cust_order is a materialized view of customer orders, based on two tables. The tables are customer and book_order. The former has two columns (cust_id and cust_name) and the latter has three columns (order_id, book, and cust_id). If you often update the book_order table to change a particular order by using the condition book_order.order_id=const, then create an index on cust_order.order_id. On the other hand, if you often update based on the condition book_order.cust_id=const, then create an index on Cust_order.cust_id.
If you often update using both conditions and cannot afford to create both indexes, you may want to add book_order.ROWID in the view and create an index on it instead. In this case, TimesTen updates the view for each detail row update instead of updating all of the rows in the view directly and at the same time. The scan to find the row to be updated is an index scan instead of a row scan, and no join rows need to be generated.
If ViewUniqueMatchScan is used in the execution plan, it is a sign that the execution may be slower or require more space than necessary. A ViewUniqueMatchScan is used to handle an update or delete that cannot be translated to a direct update or delete of a materialized view, and there is no unique mapping between a join row and the associated row in the materialized view. This can be fixed by selecting a unique key for each detail table that is updated or deleted.
Avoid unnecessary updates
Try not to update a join column or a GROUP BY column because this involves deleting the old value and inserting the new value.
Try not to update an expression that references more than one table. This may disallow direct update of the view because TimesTen may perform another join operation to get the new value when one value in this expression is updated.
View maintenance based on an update or delete is more expensive when:
-
The view cannot be updated directly. For example, not all columns specified in the detail table
UPDATEorDELETEstatement are selected in the view, or -
There is not an indication of a one-to-one mapping from the view rows to the join rows.
For example:
Command> CREATE MATERIALIZED VIEW v1 AS SELECT x1 FROM t1, t2 WHERE x1=x2; Command> DELETE FROM t1 WHERE y1=1;
The extra cost comes from the fact that extra processing is needed to ensure that one and only one view row is affected due to a join row.
The problem is resolved if either x1 is UNIQUE or a unique key from t1 is included in the select list of the view. ROWID can always be used as the unique key.
Avoid changes to the inner table of an outer join
Performance impact: Variable
Since outer join maintenance is more expensive when changes happen to an inner table, try to avoid changes to the inner table of an outer join. When possible, perform INSERT operations on an inner table before inserting into the associated join rows into an outer table. Likewise, when possible perform DELETE operations on the outer table before deleting from the inner table. This avoids having to convert non-matching rows into matching rows or vice versa.
Limit number of columns in a view table
Performance impact: Variable
The number of columns projected in the view SelectList can impact performance. As the number of columns in the select list grows, the time to prepare operations on detail tables increases. In addition, the time to execute operations on the view detail tables also increases. Do not select values or expressions that are not needed.
The optimizer considers the use of temporary indexes when preparing operations on detail tables of views. This can significantly slow down prepare time, depending upon the operation and the view. If prepare time seems slow, consider using ttOptSetFlag to turn off temporary range indexes and temporary hash scans.
Transaction tuning
The following sections describe how to increase performance when using transactions:
Locate checkpoint and transaction log files on separate physical device
To improve performance, locate your transaction log files on a separate physical device from the one on which the checkpoint files are located. The LogDir connection attribute determines where log files are stored. For more information, see "Managing transaction log buffers and files" in this book or "LogDir" in the Oracle TimesTen In-Memory Database Reference.
Size transactions appropriately
Performance impact: Large
Each transaction, when it generates transaction log records (for example, a transaction that does an INSERT, DELETE or UPDATE), incurs a file system write operation when the transaction commits. File system I/O affects response time and may affect throughput, depending on how effective group commit is.
Performance-sensitive applications should avoid unnecessary file system write operations at commit. Use a performance analysis tool to measure the amount of time your application spends in file system write operations (versus CPU time). If there seems to be an excessive amount of I/O, there are two steps you can take to avoid writes at commit:
-
Adjust the transaction size.
-
Adjust whether file system write operations are performed at transaction commit. See "Use durable commits appropriately".
Long transactions perform fewer file system write operations per unit of time than short transactions. However, long transactions also can reduce concurrency, as discussed in Chapter 7, "Transaction Management".
-
If only one connection is active on a database, longer transactions could improve performance. However, long transactions may have some disadvantages, such as longer rollback operations.
-
If there are multiple connections, there is a trade-off between transaction log I/O delays and locking delays. In this case, transactions are best kept to the natural length, as determined by requirements for atomicity and durability.
Use durable commits appropriately
Performance impact: Large
By default, each TimesTen transaction results in a file system write operation at commit time. This practice ensures that no committed transactions are lost because of system or application failures. Applications can avoid some or all of these file system write operations by performing nondurable commits. Nondurable commits do everything that a durable commit does except write the transaction log to the file system. Locks are released and cursors are closed, but no file system write operation is performed.
Note:
Some drivers only write data into cache memory or write to the file system some time after the operating system receives the write completion notice. In these cases, a power failure may cause some information that you thought was durably committed to be lost. To avoid this loss of data, configure your file system to write to the recording media before reporting completion or use an uninterruptible power supply.The advantage of nondurable commits is a potential reduction in response time and increase in throughput. The disadvantage is that some transactions may be lost in the event of system failure. An application can force the transaction log to be persisted to the file system by performing an occasional durable commit or checkpoint, thereby decreasing the amount of potentially lost data. In addition, TimesTen itself periodically flushes the transaction log to the file system when internal buffers fill up, limiting the amount of data that could be lost.
Transactions can be made durable or can be made nondurable on a connection-by-connection basis. Applications can force a durable commit of a specific transaction by calling the ttDurableCommit procedure.
Applications that use durable commits can benefit from using synchronous writes in place of write and flush. To turn on synchronous writes set the first connection attribute LogFlushMethod=1. The LogFlushMethod attribute controls how TimesTen writes and synchronizes data to transaction log files. Although application performance can be affected by this attribute, transaction durability is not affected. For more information, see "LogFlushMethod" in the Oracle TimesTen In-Memory Database Reference.
The txn.commits.durable column of the SYS.SYSTEMSTATS table indicates the number of transactions that were durably committed.
Avoid manual checkpoints
Performance impact: Large
Manual checkpoints only apply to TimesTen Classic. Manual checkpoints are not supported in TimesTen Scaleout.
If possible it is best to avoid performing manual checkpoints. You should configure background checkpoints with the ttCkptConfig built-in procedure. Background checkpoints are less obtrusive and use non-blocking (or "fuzzy") checkpoints.
If a manual checkpoint is deemed necessary, it is generally better to call ttCkpt to perform a non-blocking (or "fuzzy") checkpoint than to call ttCkptBlocking to perform a blocking checkpoint. Blocking or ("transaction-consistent") checkpoints can have a significant performance impact because they require exclusive access to the database. Non-blocking checkpoints may take longer, but they permit other transactions to operate against the database at the same time and thus impose less overall overhead. You can increase the interval between successive checkpoints (ckptLogVolume parameter of the ttCkptConfig built-in procedure) by increasing the amount of file system space available for accumulating transaction log files.
As the transaction log increases in size (if the interval between checkpoints is large), recovery time increases accordingly. If reducing recovery time after a system crash or application failure is important, it is important to properly tune the ttCkptConfig built-in procedure. The ckpt.completed column of the SYS.SYSTEMSTATS table indicates how often checkpoints have successfully completed.
For more information, see "ttCkptConfig" in the Oracle TimesTen In-Memory Database Reference.
Turn off autocommit mode
Performance impact: Large
AUTOCOMMIT mode forces a commit after each statement, and is enabled by default. Committing each statement after execution, however, can significantly degrade performance. For this reason, it is generally advisable to disable AUTOCOMMIT, using the appropriate API for your programming environment.
The txn.commits.count column of the SYS.SYSTEMSTATS table indicates the number of transaction commits.
Note:
If you do not include any explicit commits in your application, the application can use up important resources unnecessarily, including memory and locks. All applications should do periodic commits.Avoid transaction roll back
Performance impact: Large
When transactions fail due to erroneous data or application failure, they are rolled back by TimesTen automatically. In addition, applications often explicitly roll back transactions to recover from deadlock or timeout conditions. This is not desirable from a performance point of view, as a roll back consumes resources and the entire transaction is wasted.
Applications should avoid unnecessary rollback operations. This may mean designing the application to avoid contention and checking application or input data for potential errors in advance, if possible. The txn.rollbacks column of the SYS.SYSTEMSTATS table indicates the number of transactions that were rolled back.
Avoid large DELETE statements
Performance impact: Large
Consider the following ways to avoid large delete statements:
Avoid DELETE FROM statements
If you attempt to delete a large number of rows (100,000 or more) from a table with a single SQL statement the operation can take a long time. TimesTen logs each row deleted, in case the operation needs to be rolled back, and writing all of the transaction log records to the file system can be very time-consuming.
Another problem with such a large delete operation is that other database operations will be slowed down while the write-intensive delete transaction is occurring. Deleting millions of rows in a single transaction can take minutes to complete.
Another problem with deleting millions of rows at once occurs when the table is being replicated. Because replication transmits only committed transactions, the replication agent can be slowed down by transmitting a single, multi-hundred MB (or GB) transaction. TimesTen replication is optimized for lots of small transactions and performs slowly when millions of rows are deleted in a single transaction.
For more information about the DELETE SQL statement, see "DELETE" in the Oracle TimesTen In-Memory Database SQL Reference.
Consider using the DELETE FIRST clause
If you want to delete a large number of rows and TRUNCATE TABLE is not appropriate, consider using the DELETE FIRST NumRows clause to delete rows from a table in batches. The DELETE FIRST NumRows syntax allows you to change ”DELETE FROM TableName WHERE . . .” into a sequence of ”DELETE FIRST 10000 FROM TableName WHERE . . .” operations.
By splitting a large DELETE operation into a batch of smaller operations, the rows will be deleted much faster, and the overall concurrency of the system and replication will not be affected.
For more information about the DELETE FIRST clause, see "DELETE" in the Oracle TimesTen In-Memory Database SQL Reference.
Increase the commit buffer cache size
Performance impact: Large
TimesTen resource cleanup occurs during the reclaim phase of a transaction commit. During reclaim, TimesTen reexamines all the transaction log records starting from the beginning of the transaction to determine the reclaim operations that must be performed.
The reclaim phase of a large transaction commit results in a large amount of processing and is very resource intensive. You can improve performance, however, by increasing the maximum size of the commit buffer, which is the cache of transaction log records used during reclaim operations.
You can use the TimesTen CommitBufferSizeMax connection attribute to specify the maximum size of the commit buffer, in megabytes. This setting has the scope of your current session.
See "Configuring the commit buffer for reclaim operations" for information.
Recovery tuning
The following sections include tips for improving performance of database recovery after database shutdown or system failure:
Set RecoveryThreads
Performance impact: Large
RecoveryThreads defines the number of parallel threads used to rebuild indexes during database recovery time. For performance reasons, TimesTen does not log changes to indexes. In the event of a crash, all indexes need to be rebuilt. To reduce the index rebuild time, set the RecoveryThreads attribute to the number of CPUs to improve recovery performance. See "RecoveryThreads" in the Oracle TimesTen In-Memory Database Reference for more details.
Set CkptReadThreads
Performance impact: Large
When a database has large checkpoint files (hundreds of gigabytes), first connection or recovery operations may not perform well and, in extreme cases, may take hours to complete. To improve recovery performance, use the CkptReadThreads connection attribute to increase the number of concurrent threads used for reading the checkpoint files during the loading of the database into memory. This reduces the amount of time it takes to load the TimesTen database to memory by enabling parallel threads to read the TimesTen database checkpoint files.
For more information on the CkptReadThreads attribute, see "CkptReadThreads" in the Oracle TimesTen In-Memory Database Reference.
Scaling for multiple CPUs
The following sections include tips for improving performance for multiple CPUs:
Run the demo applications as a prototype
Performance impact: Variable
One way to determine the approximate scaling you can expect from TimesTen is to run one of the scalable demo applications, such as tptbm, on your system.
The tptbm application implements a multi-user throughput benchmark. It enables you to control how it executes, including options to vary the number of processes that execute TimesTen operations and the transaction mix of SELECTs, UPDATEs, and INSERTs, for example. Run tptbm -help to see the full list of options.
By default the demo executes one operation per transaction. You can specify more operations per transaction to better model your application. Larger transactions may scale better or worse, depending on the application profile.
Run multi-processor versions of the demo to evaluate how your application can be expected to perform on systems that have multiple CPUs. If the demo scales well but your application scales poorly, you might try simplifying your application to see where the issue is. Some users comment out the TimesTen calls and find they still have bad scaling due to issues in the application.
You may also find, for example, that some simulated application data is not being generated properly, so that all the operations are accessing the same few rows. That type of localized access greatly inhibits scalability if the accesses involve changes to the data.
See the Quick Start home page at installation_dir/quickstart.html for additional information about tptbm and other demo applications. Go to the ODBC link under "Sample Programs".
Limit database-intensive connections per CPU
Performance impact: Variable
Check the lock.timeouts or lock.locks_granted.wait fields in the SYS.SYSTEMSTATS table. If they have high values, this may indicate undue contention, which can lead to poor scaling.
Because TimesTen is quite CPU-intensive, optimal scaling is achieved by having at most one database-intensive connection per CPU. If you have a 4-CPU system or a 2-CPU system with hyperthreading, then a 4-processor application executes well, but an 8-processor application does not perform well. The contention between the active threads is too high. The only exception to this rule is when many transactions are committed durably. In this case, the connections are not very CPU-intensive because of the increase in I/O operations to the file system, and so the system can support many more concurrent connections.
Use read operations when available
Performance impact: Variable
Read operations scale better than write operations. Make sure that the read and write balance reflects the real-life workload of your application.
Limit prepares, re-prepares and connects
Performance impact: Variable
Prepares are resource-intensive operations that do not scale well compared to SQL execution operations. Ensure that you use parameterized SQL statements wherever possible and always pre-prepare statements that are executed more than once. The stmt.prepares.count column of the SYS.SYSTEMSTATS table indicates how often statements were prepared directly by an application. If the stmt.prepares.count column has a high value, ensure the following:
-
Your application uses parametrized statements.
-
Your application only prepares any given SQL statement once and not for every single execution.
-
Your application does not connect and disconnect frequently from the database. If that is the case, consider using long lived connections.
Connect and disconnect operations are resource-intensive operations that do not scale well. Ensure that your application minimizes the number of connect and disconnect operations. Use long lived connections with parameterized and pre-prepared SQL statements to improve performance.
If your application cannot avoid frequent connect and disconnect operations or you are unable to modify the application to use long-lived connections, consider using connection pooling. Connection pooling can reduce the frequency of connect and disconnect operations and improve the utilization of prepared statements compared to the case where an application frequently connects and disconnects from the database.
Allow indexes to be rebuilt in parallel during recovery
Performance impact: Variable
On multi-processor systems, set RecoveryThreads to minimum(number of CPUs available, number of indexes) to allow indexes to be rebuilt in parallel if recovery is necessary. If a rebuild is necessary, progress can be viewed in the user log. Setting RecoveryThreads to a number larger than the number of CPUs available can cause recovery to take longer than if it were single-threaded.
Use private commands
Performance impact: Variable
When multiple connections execute the same command, they access common command structures controlled by a single command lock. To avoid sharing their commands and possibly placing contention on the lock, you can set PrivateCommands=1. The use of private commands increases the amount of temporary space used, but provides better scaling at the cost.
For more information, see "PrivateCommands" in the Oracle TimesTen In-Memory Database Reference.
XLA tuning
The following sections include tips for improving XLA performance:
Increase transaction log buffer size when using XLA
Performance impact: Large
A larger transaction log buffer size is appropriate when using XLA. When XLA is enabled, additional transaction log records are generated to store additional information for XLA. To ensure the transaction log buffer is properly sized, one can watch for changes in the SYS.MONITOR table entries LOG_FS_READS and LOG_BUFFER_WAITS. For optimal performance, both of these values should remain 0. Increasing the transaction log buffer size may be necessary to ensure the values remain 0. For more information on how to resize the transaction log buffer size, see "LogBufMB" in the Oracle TimesTen In-Memory Database Reference.
Prefetch multiple update records
Performance impact: Medium
Prefetching multiple update records at a time is more efficient than obtaining each update record from XLA individually. Because updates are not prefetched when you use AUTO_ACKNOWLEDGE mode, it can be slower than the other modes. If possible, you should design your application to tolerate duplicate updates so you can use DUPS_OK_ACKNOWLEDGE, or explicitly acknowledge updates. Explicitly acknowledging updates usually yields the best performance if the application can tolerate not acknowledging each message individually.
Acknowledge XLA updates
Performance impact: Medium
To explicitly acknowledge an XLA update, you call acknowledge on the update message. Acknowledging a message implicitly acknowledges all previous messages. Typically, you receive and process multiple update messages between acknowledgements. If you are using the CLIENT_ACKNOWLEDGE mode and intend to reuse a durable subscription in the future, you should call acknowledge to reset the bookmark to the last-read position before exiting.
Cache and replication tuning
For recommendations on improving performance for when using a replication scheme, see "Improving Replication Performance" in the Oracle TimesTen In-Memory Database Replication Guide.
For recommendations on improving performance when using cache groups, see "Cache Performance" in the Oracle TimesTen Application-Tier Database Cache User's Guide.