9 The TimesTen Query Optimizer
The TimesTen query optimizer is a cost-based optimizer that determines the most efficient way to execute a given query by considering possible query plans. The query optimizer uses information about an application's tables and their available indexes to choose a fast path to the data.
A query plan in TimesTen Scaleout is affected by the distribution scheme and the distribution keys of a hash distribution scheme as well as the column and table statistics, the presence or absence of indexes, the volume of data, the number of unique values, and the selectivity of predicates.
Application developers can examine the plan chosen by the optimizer to check that indexes are used appropriately. If necessary, application developers can provide hints to influence the optimizer's behavior so that it considers a different plan.
This chapter includes the following topics:
When optimization occurs
TimesTen invokes the optimizer for SQL statements when more than one execution plan is possible. The optimizer chooses what it thinks is the optimum plan. This plan persists until the statement is either invalidated or dropped by the application.
A statement is automatically invalidated under the following circumstances:
-
An object that the command uses is dropped
-
An object that the command uses is altered
-
An index on a table or view that the command references is dropped
-
An index is created on a table or view that the command references
You can manually invalidate statements with either of the following methods:
-
Use the
ttOptCmdCacheInvalidatebuilt-in procedure to invalidate statements in the SQL command cache. For more information, see "Control the invalidation of commands in the SQL command cache". -
Set the
invalidationoption to 1 in thettOptUpdateStatsor thettOptEstimateStatsbuilt-in procedures. These built-in procedures also update statistics for either a specified table or all of the current user's tables.
Note:
For complete details on when to calculate statistics, see "Compute exact or estimated statistics". In addition, see "ttOptUpdateStats", or "ttOptEstimateStats" in the Oracle TimesTen In-Memory Database Reference.An invalid statement is usually reprepared automatically just before it is re-executed. This means that the optimizer is invoked again at this time, possibly resulting in a new plan. Thus, a single statement may be prepared several times.
Note:
When using JDBC, you must manually reprepare statement when a table has been altered.A statement may have to be prepared manually if, for example, the table that the statement referenced was dropped and a new table with the same name was created. When you prepare a statement manually, you should commit the prepare statement so it can be shared. If the statement is recompiled because it was invalid, and if recompilation involves DDL on one of the referenced tables, then the prepared statement must be committed to release the command lock.
For example, in ODBC a command joining tables T1 and T2 may undergo the following changes:
| Action | Description |
|---|---|
SQLPrepare |
Command is prepared. |
SQLExecute |
Command is executed. |
SQLExecute |
Command is re-executed. |
| Create Index on T1 | Command is invalidated. |
SQLExecute |
Command is reprepared, then executed. |
SQLExecute |
Command is re-executed. |
ttOptUpdateStats on T1 |
Command is invalidated if the invalidate flag is passed to the ttOptUpdateStats procedure. |
SQLExecute |
Command is reprepared, then executed. |
SQLExecute |
Command is re-executed. |
SQLTransact |
Command is committed. |
SQLFreeStmt |
Command is dropped. |
In JDBC, a command joining tables T1 and T2 may undergo the following changes:
| Action | Description |
|---|---|
Connection.prepareStatement() |
Command is prepared. |
PreparedStatement.execute() |
Command is executed. |
PreparedStatement.execute() |
Command is re-executed. |
| Create Index on T1 | Command is invalidated. |
PreparedStatement.execute() |
Command is reprepared, then executed. |
PreparedStatement.execute() |
Command is re-executed. |
ttOptUpdateStats on T1 |
Command is invalidated if the invalidate flag is passed to the ttOptUpdateStats procedure. |
PreparedStatement.execute() |
Command is reprepared, then executed. |
PreparedStatement.execute() |
Command is re-executed. |
Connection.commit() |
Command is committed. |
PreparedStatement.close() |
Command is dropped. |
As illustrated, optimization is generally performed at prepare time, but it may also be performed later when indexes are dropped or created, or when statistics are modified. Optimization does not occur if a prepare can use a command in the cache.
If a command was prepared with the genPlan flag set, it is recompiled with the same flag set. Thus, the plan is generated even though the plan for another query was found in the SYS.PLAN table.
If an application specifies optimizer hints to influence the optimizer's behavior, these hints persist until the command is deleted. See "Modifying plan generation" for more information. For example, when the ODBC SQLPrepare function or JDBC Connection.prepareStatement() method is called again on the same handle or when the SQLFreeStmt function or PreparedStatement.close() method is called. This means that any intermediate reprepare operations that occur because of invalidations use those same hints.
Viewing SQL statements stored in the SQL command cache
All commands executed—SQL statements, built-in procedures, and so on—are stored in the SQL command cache, which uses temporary memory. The commands are stored up until the limit of the SQL command cache is reached, then the new commands are stored after the last used commands are removed. You can retrieve one or more of these commands that are stored in the SQL command cache.
Note:
This section describes viewing the commands stored in the SQL command cache. For details on how to view the query plans associated with these commands, see "Viewing query plans associated with commands stored in the SQL command cache".The following sections describe how to view commands cached in the SQL command cache:
Managing performance and troubleshooting commands
You can view all one or more commands or details of their query plans with the ttSQLCmdCacheInfo and ttSQLCmdQueryPlan built-in procedures. Use the query plan information to monitor and troubleshoot your queries.
Viewing commands and query plans can help you perform the following:
-
Detect updates or deletes that are not using an index scan.
-
Monitor query plans of executing queries to ensure all plans are optimized.
-
Detect applications that do not prepare SQL statements or that re-prepare the same statement multiple times.
-
Detect the percentage of space used in the command cache for performance evaluation.
Displaying commands stored in the SQL command cache
The commands executed against the TimesTen database are cached in the SQL command cache. The ttSQLCmdCacheInfo built-in procedure displays a specific or all cached commands in the TimesTen SQL command cache. By default, all commands are displayed; if you specify a command id, then only this command is retrieved for display.
The command data is saved in the following format:
-
Command identifier, which is used to retrieve a specific command or its associated query plan.
-
Private connection identifier.
-
Counter for the number of executions.
-
Counter for the number of times the user prepares this statement.
-
Counter for the number of times the user re-prepares this SQL statement.
-
Freeable status, where if the value is one, then the subdaemon can free the space with the garbage collector. A value of zero determines that the space is not able to be freed.
-
Total size in bytes allocated for this command in the cache.
-
User who created the command.
-
Query text up to 1024 characters.
-
Number of fetch executions performed internally for this statement.
-
The timestamp when the statement started.
-
The maximum execution time in seconds for the statement.
-
Last measured execution time in seconds for the statement.
-
The minimum execution time in seconds for the statement.
-
The unique identifier of the statement compiled across the TimesTen.
-
Total temporary size in bytes used for this TimesTen statement the last time it was executed.
-
The maximum temporary size in bytes ever used to execute this TimesTen statement.
At the end of the list of all commands, a status is printed of how many commands were in the cache.
The following examples show how to display all or a single command from the SQL command cache using the ttSQLCmdCacheInfo built-in utility:
Example 9-1 Displaying all commands in the SQL command cache
This example executes within ttIsql the ttSQLCmdCacheInfo built-in procedure without arguments to show all cached commands. The commands are displayed in terse format. To display the information where each column is prepended with the column name, execute vertical on before calling the ttSQLCmdCacheInfo procedure.
Command> vertical 1;
Command> call ttSQLCmdCacheInfo;
SQLCMDID: 43402480
PRIVATE_COMMAND_CONNECTION_ID: -1
EXECUTIONS: 1
PREPARES: 1
REPREPARES: 0
FREEABLE: 1
SIZE: 4344
OWNER: HR
QUERYTEXT: INSERT INTO employees VALUES
( 191
, 'Randall'
, 'Perkins'
, 'RPERKINS'
, '650.505.4876'
, TO_DATE('19-DEC-1999', 'dd-MON-yyyy')
, 'SH_CLERK'
, 2500
, NULL
, 122
, 50
)
FETCHCOUNT: 0
STARTTIME: 2015-04-09 15:22:22.139000
MAXEXECUTETIME: 0
LASTEXECUTETIME: 0
MINEXECUTETIME: 0
GRIDCMDID: <NULL>
TEMPSPACEUSAGE: 0
MAXTEMPSPACEUSAGE: 0
SQLCMDID: 43311000
PRIVATE_COMMAND_CONNECTION_ID: -1
EXECUTIONS: 1
PREPARES: 1
REPREPARES: 0
FREEABLE: 1
SIZE: 4328
OWNER: HR
QUERYTEXT: INSERT INTO employees VALUES
( 171
, 'William'
, 'Smith'
, 'WSMITH'
, '011.44.1343.629268'
, TO_DATE('23-FEB-1999', 'dd-MON-yyyy')
, 'SA_REP'
, 7400
, .15
, 148
, 80
)
FETCHCOUNT: 0
STARTTIME: 2015-04-09 15:22:22.139000
MAXEXECUTETIME: 0
LASTEXECUTETIME: 0
MINEXECUTETIME: 0
GRIDCMDID: <NULL>
TEMPSPACEUSAGE: 0
MAXTEMPSPACEUSAGE: 0
...
102 rows found.
Example 9-2 Displaying a single SQL command
If you provide a command id as the input for the ttSQLCmdCacheInfo, the single command is displayed from within the SQL command cache. If no command id is provided to the ttSQLCmdCacheInfo built-in procedure, then it displays information about all current commands, where the command id is the first column of the output.
The following example displays the command identified by Command ID of 527973892. It is displayed in terse format; to view with the column headings prepended, execute vertical on before calling the ttSQLCmdCacheInfo built-in.
Command> call ttSQLCmdCacheInfo(43311000);
< 43311000, -1, 1, 1, 0, 1, 4328, HR, INSERT INTO employees VALUES
( 171, 'William', 'Smith', 'WSMITH', '011.44.1343.629268', TO_DATE('23-FEB-1999',
'dd-MON-yyyy'), 'SA_REP', 7400, .15, 148, 80), 0, 2015-04-09 15:22:22.139000, 0,
0, 0, <NULL>, 0, 0 >
1 row found.
Viewing SQL query plans
You can view the query plan for a command in one of two ways: storing the latest query plan into the system PLAN table or viewing all cached commands and their query plans in the SQL command cache. Both methods are described in the following sections:
Viewing a query plan from the system PLAN table
The optimizer prepares the query plans. For the last SQL statement to be executed, you can instruct that the plan be stored in the system PLAN table:
-
Instruct TimesTen to generate the plan and store it in the system
PLANtable. -
Prepare the statement means calling the ODBC
SQLPreparefunction or JDBCConnection.prepareStatement()method on the statement. TimesTen stores the plan into thePLANtable. -
Read the generated plan within the
SYS.PLANtable.
The stored plan is updated automatically whenever the command is reprepared. Re-preparation occurs automatically if one or more of the following occurs:
-
A table in the statement is altered.
-
If indexes are created or dropped.
-
The application invalidates commands when statistics are updated with the
invalidateoption in thettOptUpdateStatsbuilt-in procedure. -
The user invalidates commands with the
ttOptCmdCacheInvalidatebuilt-in procedure.
Note:
For more information, see "Control the invalidation of commands in the SQL command cache". For more information on the built-in procedures, see "ttOptUpdateStats" and "ttOptCmdCacheInvalidate" in the Oracle TimesTen In-Memory Database Reference.For these cases, read the PLAN table to view how the plan has been modified.
Instruct TimesTen to store the plan in the system PLAN table
Before you can view the plan in the system PLAN table, enable the creation of entries in the PLAN table with the plan generation option as follows:
-
For transaction level optimizer hints, call the built-in
ttOptSetFlagprocedure and enable theGenPlanflag. -
For statement level optimizer hints, set
TT_GENPLAN(1), which is only in effect for the statement. After the statement executes, the plan generation option takes on the value of theGenPlantransaction level optimizer hint.
Note:
See "Use optimizer hints to modify the execution plan" for details on statement level and transaction level optimizer hints.This informs TimesTen that all subsequent calls to the ODBC SQLPrepare function or JDBC Connection.prepareStatement() method in the transaction should store the resulting plan in the current SYS.PLAN table.
The SYS.PLAN table only stores one plan, so each call to the ODBC SQLPrepare function or JDBC Connection.prepareStatement() method overwrites any plan currently stored in the table.
If a command is prepared with plan generation option set, it is also recompiled for plan generation. Thus, the plan is generated even though the plan for another query was found in the SYS.PLAN table.
You can use showplan in ttIsql to test the query and optimizer hints, which enables plan generation as well as shows the query plan for the statements in the transaction. Autocommit must be off.
Command> autocommit 0; Command> showplan 1;
Reading query plan from the PLAN table
Once plan generation has been turned on and a command has been prepared, one or more rows in the SYS.PLAN table store the plan for the command. The number of rows in the table depends on the complexity of the command. Each row has seven columns, as described in "System Tables and Views" in the Oracle TimesTen In-Memory Database System Tables and Views Reference.
Example 9-3 Generating a query plan
This example uses the following query:
Command> SELECT COUNT(*) FROM t1, t2, t3 WHERE t3.b/t1.b > 1 AND t2.b <> 0 AND t1.a = -t2.a AND t2.a = t3.a
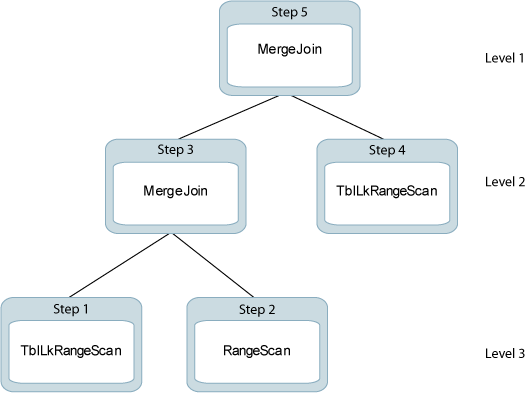
The optimizer generates the five SYS.PLAN rows shown in the following table. Each row is one step in the plan and reflects an operation that is performed during query execution.
| Step | Level | Operation | TblNames | IXName | Pred | Other Pred |
|---|---|---|---|---|---|---|
| 1 | 3 | TblLkRangeScan | t1 | IX1 | N/A | N/A |
| 2 | 3 | TblLkRangeScan | t2 | IX2(D) | N/A | t2.b <> 0 |
| 3 | 2 | MergeJoin | N/A | N/A | t1.a = -t2.a | N/A |
| 4 | 2 | TblLkRangeScan | t3 | IX3(D) | N/A | N/A |
| 5 | 1 | MergeJoin | N/A | N/A | t2.a = t3.a | t3.b / t1.b > 1 |
For details about each column in the SYS.PLAN table, see "Describing the PLAN table columns".
Describing the PLAN table columns
The SYS.PLAN table has seven columns.
Column 1 (Step)
Indicates the order of operation, which always starts with one. Example 9-3 uses a table lock range scan in the following order:
-
Table locking range scan of IX1 on table
t1. -
Table locking range scan of IX2 on
t2. -
Merge join of
t1andt2and so forth.
Column 2 (Level)
Indicates the position of the operation in the join-tree diagram that describes the execution. For Example 9-3, the join tree is as follows:
Description of the illustration ''jointree.png''
Column 3 (Operation)
Indicates the type of operation being executed. For a description of the potential values in this field and the type of table scan each represents, see SYS.PLAN in "System Tables and Views" in the Oracle TimesTen In-Memory Database System Tables and Views Reference.
Not all operations the optimizer performs are visible to the user. Only operations significant to performance analysis are shown in the SYS.PLAN table. TblLk is an optimizer hint that is honored at execution time in Serializable or Read Committed isolation. Table locks are used during a scan only if row locks are disabled during preparation.
Column 4 (TblNames)
Indicates the table that is being scanned. This column is used only when the operation is a scan. In all other cases, this column is NULL.
Column 5 (IXName)
Indicates the index that is being used. This column is used only when the operation is an index scan using an existing index—such as a hash or range scan. In all other cases, this column is NULL. Names of range indexes are followed with "(D)" if the scan is descending—from large to small rather than from small to large.
Column 6 (Pred)
Indicates the predicate that participates in the operation, if there is one. Predicates are used only with index scan and MergeJoin operations. The predicate character string is limited to 1,024 characters.
This column may be NULL—indicating no predicate—for a range scan. The optimizer may choose a range scan over a table scan because, in addition to filtering, it has two useful properties:
-
Rows are returned in sorted order, on index key.
-
Rows may be returned faster, especially if the table is sparse.
In Example 9-3, the range scans are used for their sorting capability; none of them evaluates a predicate.
Column 7 (Other Pred)
Indicates any other predicate that is applied while the operation is being executed. These predicates do not participate directly in the scan or join but are evaluated on each row returned by the scan or join.
For example, at step two of the plan generated for Example 9-3, a range scan is performed on table t2. When that scan is performed, the predicate t2.b <> 0 is also evaluated. Similarly, once the final merge-join has been performed, it is then possible to evaluate the predicate t3.b / t1.b > 1.
Viewing query plans associated with commands stored in the SQL command cache
Use the query plan information to monitor and troubleshoot your queries.
Note:
For more reasons why to use thettSQLCmdQueryPlan built-in procedure, see "Managing performance and troubleshooting commands".The ttSQLCmdQueryPlan built-in procedure displays the query plan of a specific statement or all statements in the command cache. It displays the detailed run-time query plans for the cached SQL queries. By default, all query plans are displayed; if you specify the command id taken from the command output, only the query plan for the specified command is displayed.
Note:
If you want to display a query plan for a specific command, you must provide the command identifier that is displayed with thettSQLCmdCacheInfo built-in procedure. See "Displaying commands stored in the SQL command cache" for full details.The plan data displayed when you invoke this built-in procedure is as follows:
-
Command identifier
-
Query text up to 1024 characters
-
Step number of the current operation in the run-time query plan
-
Level number of the current operation in the query plan tree
-
Operation name of current step
-
Name of table used
-
Owner of the table
-
Name of index used
-
If used and available, the index predicate
-
If used and available, the non-indexed predicate
Note:
For more information on how to view this information, see "Reading query plan from the PLAN table". The source of the data may be different, but the mapping and understanding of the material is the same as the query plan in the systemPLAN table.The ttSQLCmdQueryPlan built-in process displays the query plan in a raw data format. Alternatively, you can execute the ttIsql explain command for a formatted version of this output. For more information, see "Display query plan for statement in SQL command cache".
The following examples show how to display all or a single SQL query plan from the SQL command cache using the ttSQLCmdQueryPlan built-in procedure:
Example 9-4 Displaying all SQL query plans
You can display all SQL query plans associated with commands stored in the command cache with the ttSQLCmdQueryPlan built-in procedure within the ttIsql utility.
The following example shows the output when executing the ttSQLCmdQueryPlan built-in procedure without arguments, which displays detailed run-time query plans for all valid queries. For invalid queries, there is no query plan; instead, the query text is displayed.
The query plans are displayed in terse format. To view with the column headings prepended, execute vertical on before calling the ttSQLCmdQueryPlan built-in procedure.
Note: For complex expressions, there may be some difficulties in printing out the original expressions.
Command> call ttSQLCmdQueryPlan();
< 528079360, select * from t7 where x7 is not null or exists (select 1 from t2,t3
where not 'tuf' like 'abc'), <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL> >
< 528079360, <NULL>, 0, 2, RowLkSerialScan , T7
, PAT , , , >
< 528079360, <NULL>, 1, 3, RowLkRangeScan , T2
, PAT , I2 , , NOT(LIKE( tuf
,abc ,NULL )) >
< 528079360, <NULL>, 2, 3, RowLkRangeScan , T3
, PAT , I2 , , >
< 528079360, <NULL>, 3, 2, NestedLoop ,
, , , , >
< 528079360, <NULL>, 4, 1, NestedLoop(Left OuterJoin) ,
, , , , >
< 528079360, <NULL>, 5, 0, Filter ,
, , , , X7 >
< 527576540, call ttSQLCmdQueryPlan(527973892), <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL>, <NULL> >
< 527576540, <NULL>, 0, 0, Procedure Call ,
, , , , >
< 528054656, create table t2(x2 int,y2 int, z2 int), <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL>, <NULL>, <NULL> >
< 528066648, insert into t2 select * from t1, <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL>, <NULL> >
< 528066648, <NULL>, 0, 0, Insert , T2
, PAT , , , >
< 528013192, select * from t1 where exists (select * from t2 where x1=x2) or
y1=1, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL> >
< 528061248, create index i1 on t3(y3), <NULL>, <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL> >
< 528070368, call ttOptSetOrder('t3 t4 t2 t1'), <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL>, <NULL> >
< 528070368, <NULL>, 0, 0, Procedure Call ,
, , , , >
< 528018856, insert into t2 select * from t1, <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL>, <NULL> >
< 527573452, call ttSQLCmdCacheInfo(527973892), <NULL>, <NULL>, <NULL>, <NULL>,
<NULL>, <NULL>, <NULL>, <NULL> >
< 527573452, <NULL>, 0, 0, Procedure Call ,
, , , , >
< 528123000, select * from t1 where x1 = 1 or x1 = (select x2 from t2,t3 where
z2=t3.x3), <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL> >
< 528123000, <NULL>, 0, 2, RowLkSerialScan , T1
, PAT , , , >
< 528123000, <NULL>, 1, 6, RowLkRangeScan , T2
, PAT , I2 , , >
< 528123000, <NULL>, 2, 6, RowLkRangeScan , T3
, PAT , I2 , , Z2 = X3; >
< 528123000, <NULL>, 3, 5, NestedLoop ,
, , , , >
< 528123000, <NULL>, 4, 4, Materialized View ,
, , , , >
< 528123000, <NULL>, 5, 3, GroupBy ,
, , , , >
< 528123000, <NULL>, 6, 2, Filter ,
, , , , X1 =
colum_name; >
< 528123000, <NULL>, 7, 1, NestedLoop(Left OuterJoin) ,
, , , , >
< 528123000, <NULL>, 8, 0, Filter ,
, , , , X1 = 1; >
Example 9-5 Displaying a single SQL query plan
You can display any query plan associated with a command by providing the command id of the command as the input for the ttSQLCmdQueryPlan built-in procedure. The single query plan is displayed from within the SQL command cache. If no command id is supplied, the ttSQLCmdCacheInfo built-in procedure displays information about all current commands in the TimesTen cache.
The following example displays the query plan of the command identified by command id of 528078576. It is displayed in terse format; to view with the column headings prepended, execute vertical on before calling the ttSQLCmdQueryPlan built-in procedure.
Note: for complex expressions, there are some difficulties to print original expressions.
Command> call ttSQLCmdQueryPlan( 528078576); < 528078576, select * from t1 where 1=2 or (x1 in (select x2 from t2, t5 where y2 in (select y3 from t3)) and y1 in (select x4 from t4)), <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, <NULL> > < 528078576, <NULL>, 0, 4, RowLkSerialScan , T1 , PAT , , , > < 528078576, <NULL>, 1, 7, RowLkRangeScan , T2 , PAT , I2 , , > < 528078576, <NULL>, 2, 7, RowLkRangeScan , T5 , PAT , I2 , , > < 528078576, <NULL>, 3, 6, NestedLoop , , , , , > < 528078576, <NULL>, 4, 6, RowLkRangeScan , T3 , PAT , I1 , ( (Y3=Y2; ) ) , > < 528078576, <NULL>, 5, 5, NestedLoop , , , , , > < 528078576, <NULL>, 6, 4, Filter , , , , , X1 = X2; > < 528078576, <NULL>, 7, 3, NestedLoop(Left OuterJoin) , , , , , > < 528078576, <NULL>, 8, 2, Filter , , , , , > < 528078576, <NULL>, 9, 2, RowLkRangeScan , T4 , PAT , I2 , , Y1 = X4; > < 528078576, <NULL>, 10, 1, NestedLoop(Left OuterJoin) , , , , , > < 528078576, <NULL>, 11, 0, Filter , , , , , > 13 rows found. Command>
Modifying plan generation
If you decide that you want to modify a query plan, you can only modify the query plan that exists in the system PLAN table as described in "Viewing a query plan from the system PLAN table". Once you do modify the query plan, it does not replace the query plan, but creates a new query plan with your changes.
The following sections describe why you may want to modify execution plans and then how to modify them:
Why modify an execution plan?
Applications may want to modify an execution plan for two reasons:
-
The plan is optimally fast but is ill-suited for the application. The optimizer may select the fastest execution path, but this path may not be desirable from the application's point of view. For example, if the optimizer chooses to use certain indexes, these choices may prevent other operations-such as certain update or delete operations-from occurring simultaneously on the indexed tables. In this case, an application can prevent the use of those indexes.
The plan chosen by the optimizer may also consume more memory than is available or than the application wants to allocate. For example, this may happen if the plan stores intermediate results or requires the creation of temporary indexes.
-
The plan is not optimally performant. The query optimizer chooses the plan that it estimates will execute the fastest based on its knowledge of the tables' contents, available indexes, statistics, and the relative costs of various internal operations. The optimizer often has to make estimates or generalizations when evaluating this information, so there can be instances where it does not choose the fastest plan. In this case, an application can adjust the optimizer's behavior to try to produce a better plan.
How hints can influence an execution plan
You can apply hints to pass instructions to the TimesTen query optimizer. The optimizer considers these hints when choosing the best execution plan for your query. Transaction level hints are in effect for all calls to the ODBC SQLPrepare function or JDBC PreparedStatement objects in the transaction.
-
If a command is prepared with certain hints in effect, those hints continue to apply if the command is reprepared automatically, even when this happens outside the initial prepare transaction. This can happen when a table is altered, or an index is dropped or created, or when statistics are modified, as described in "When optimization occurs".
-
If a command is prepared without hints, subsequent hints do not affect the command if it is reprepared automatically. An application must call the ODBC
SQLPreparefunction or JDBCConnection.prepareStatement()method a second time so that hints have an effect.
Example 9-6 Tuning a join when using ODBC
When using ODBC, a developer tuning a join on T1 and T2 might go through the steps shown in the following figure.
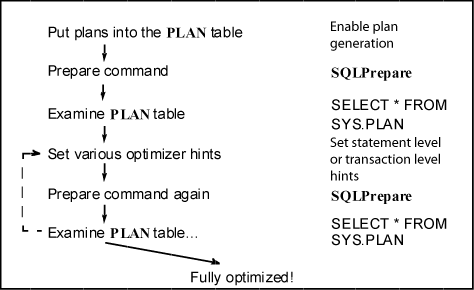
Description of the illustration ''tune_join.gif''
During execution, the application may then go through the steps shown in the following figure.

Description of the illustration ''execution_steps.gif''
Example 9-7 Tuning a join when using JDBC
When using JDBC, a developer tuning a join on T1 and T2 might go through the steps shown in the following figure.
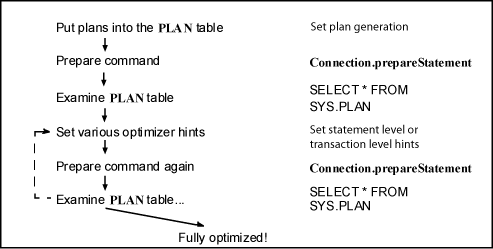
Description of the illustration ''jdbc_steps.gif''
During execution, the application may then go through the steps shown in the following figure.

Description of the illustration ''jdbc_exec_steps.gif''
Use optimizer hints to modify the execution plan
You can apply hints to pass instructions to the TimesTen query optimizer as follows:
-
To apply a hint only for a particular SQL statement, use a statement level optimizer hint.
-
To apply a hint for an entire transaction, use a transaction level optimizer hint with the appropriate TimesTen built-in procedure.
-
To apply a hint for an entire TimesTen connection, use a connection level optimizer hint.
The order of precedence for optimizer hints is statement level hints, transaction level hints and then connection level hints.
Note:
TimesTen concurrently processes read and write operations optimally. Your read operations can be optimized for read-only concurrency when you use transaction level optimizer hints such asttOptSetFlag ('tblLock',1) or statement level optimizer hints such as /*+ tt_tbllock(1) tt_rowlock(0) */. Write operations that operate concurrently with read optimized operations may result in contention.
You can control read optimization during periods of concurrent write operations with the ttDbWriteConcurrencyModeSet built-in procedure. For more information, see "Control read optimization during concurrent write operations".
Directions for applying hints are described in the following sections:
Apply statement level optimizer hints for a SQL statement
A statement level optimizer hint is a specially formatted SQL comment containing instructions for the SQL optimizer. A statement level optimizer hint can be specified within the SQL statement that it is to be applied against with one of the following methods:
-
/*+ */ The hints can be defined over multiple lines. The hints must be enclosed in the comment syntax. The plus sign (+) denotes the start of a hint.
-
--+ The hint must be defined on a single line after the plus sign (+).
The statement level optimizer hint can be specified in the SELECT, INSERT, UPDATE, MERGE, DELETE, CREATE TABLE AS SELECT, or INSERT ... SELECT statements. You must specify the hint within comment syntax immediately following the SQL VERB.
See "Statement level optimizer hints" in the Oracle TimesTen In-Memory Database SQL Reference for information specific to statement level optimizer hints. See "Using optimizer hints" in the Oracle TimesTen In-Memory Database Scaleout User's Guide for optimizer hints that are specific to TimesTen Scaleout.
Note:
If you specify any statement level optimizer hints incorrectly, TimesTen ignores these hints and does not provide an error. If you define conflicting hints, the rightmost hint overrides any conflicting hints for the statement.Apply transaction level optimizer hints for a transaction
To change the query optimizer behavior for all statements in a transaction, an application calls one of the following built-in procedures using the ODBC procedure call interface:
Note:
Make sure autocommit is off for transaction level optimizer hints. All optimizer flags are reset to their default values when the transaction has been committed or rolled back. If optimizer flags are set while autocommit is on, the optimizer flags are ignored because each statement is executed within its own transaction.-
ttOptSetFlag—Sets certain optimizer parameters. Provides the optimizer with transaction level optimizer hints with a recommendation on how to best optimize a particular query. -
ttOptGetFlag—View the existing transaction level hints set for a database. -
ttOptSetOrder—Enables an application to specify the table join order. -
ttOptUseIndex—Enables an application to specify that an index be used or to disable the use of certain indexes; that is, to specify which indexes should be considered for each correlation in a query. -
ttOptClearStats,ttOptEstimateStats,ttOptSetColIntvlStats,ttOptSetTblStats,ttOptUpdateStats—Manipulate statistics that TimesTen maintains on the application's data that are used by the query optimizer to estimate costs of various operations.
Some of these built-in procedures require that the user have privileges to the objects on which the utility executes. For full details on these built-in procedures and any privileges required, see "Built-In Procedures" in the Oracle TimesTen In-Memory Database Reference.
The following examples provide an ODBC and JDBC method on how to use the ttOptSetFlag built-in procedure:
Note:
You can also experiment with optimizer settings using thettIsql utility. The commands that start with "try" control transaction level optimizer hints. To view current transaction level optimizer hint settings, use the optprofile command.Example 9-8 Using ttOptSetFlag in JDBC
This JDBC example illustrates the use of ttOptSetFlag to prevent the optimizer from choosing a merge join.
import java.sql.*;
class Example
{
public void myMethod() {
CallableStatement cStmt;
PreparedStatement pStmt;
. . . . .
try {
. . . . . . .
// Prevent the optimizer from choosing Merge Join
cStmt = con.prepareCall("{
CALL ttOptSetFlag('MergeJoin', 0)}");
cStmt.execute();
// Next prepared query
pStmt=con.prepareStatement(
"SELECT * FROM Tbl1, Tbl2 WHERE Tbl1.ssn=Tbl2.ssn");
. . . . . . .
catch (SQLException ex) {
ex.printStackTrace();
}
}
. . . . . . .
}
Example 9-9 Using ttOptSetFlag in ODBC
This ODBC example illustrates the use of ttOptSetFlag to prevent the optimizer from choosing a merge join.
#include <sql.h>
SQLRETURN rc;
SQLHSTMT hstmt; fetchStmt;
....
rc = SQLExecDirect (hstmt, (SQLCHAR *)
"{CALL ttOptSetFlag (MergeJoin, 0)}",
SQL_NTS)
/* check return value */
...
rc = SQLPrepare (fetchStmt, ...)
/* check return value */
...
Apply connection level optimizer hints for a TimesTen connection
To change the query optimizer behavior for all statements of a specific connection, define the OptimizerHint connection attribute. The value of the OptimizerHint connection attribute is a string that uses the same format as a statement level optimizer hint but without the delimiters of /*+, */, and --+.
You cannot include comments with connection level optimizer hints.
Transaction level optimizer hints overwrite connection level optimizer hints for the current transaction. After a commit, the transaction level optimizer hints are lost and the connection level optimizer hints take effect. Statement level optimizer hints overwrite transaction level optimizer hints and connection level optimizer hints for the scope of the statement. Since this is a connection attribute, the ttConfiguration utility shows the connection level optimizer hints.
Note:
In a client server setting, the client connection setting of this connection attribute overwrites the Server DSN setting of this attribute.Example 9-10 Using connection level optimizer hints
This example illustrates the use of TT_RowLock, TT_TblLock, and TT_MergeJoin to enable row locking, disable table locking, and disable merge joins. Note that /disk1/timesten is the timesten_home.
... [database1] Driver=/disk1/timesten/install/lib/libtten.so DataStore=/disk1/timesten/info/DemoDataStore/database1 PermSize=128 TempSize=64 DatabaseCharacterSet=AL32UTF8 OptimizerHint= TT_RowLock (1) TT_TblLock (0) TT_MergeJoin (0) ...
Example 9-11 Using TT_INDEX as a connection level optimizer hint
TimesTen does not support the use of the semicolon (;) character in connection attributes. Therefore, when you want to use more than one TT_INDEX optimizer hint at the connection level, you cannot use the same syntax that you use for the statement level.
For example, TT_INDEX(EMPLOYEES,EMP_NAME_IX,1;EMPLOYEES,EMP_MANAGER_IX,1) is a valid statement level optimizer hint, but it is an invalid connection level optimizer hint. TimesTen merges multiple TT_INDEX optimizer hints if they are specified on the same line. Therefore, TT_INDEX(EMPLOYEES,EMP_NAME_IX,1) TT_INDEX(EMPLOYEES,EMP_MANAGER_IX,1)is equivalent to TT_INDEX(EMPLOYEES,EMP_NAME_IX,1;EMPLOYEES,EMP_MANAGER_IX,1).
This example illustrates the use of multiple TT_INDEX optimizer hints at the connection level. Note that /disk1/timesten is the timesten_home.
... [database1] Driver=/disk1/timesten/install/lib/libtten.so DataStore=/disk1/databases/info/DemoDataStore/database1 PermSize=128 TempSize=64 DatabaseCharacterSet=AL32UTF8 OptimizerHint= TT_INDEX(EMPLOYEES,EMP_NAME_IX,1) TT_INDEX(EMPLOYEES,EMP_MANAGER_IX,1) ...
For more information on the OptimizerHint connection attribute, see "OptimizerHint" in the Oracle TimesTen In-Memory Database Reference.