Überblick über Speech
Mit dem Sprachservice können Sie Mediendateien in lesbaren Text konvertieren, der im JSON- und SRT-Format gespeichert ist.
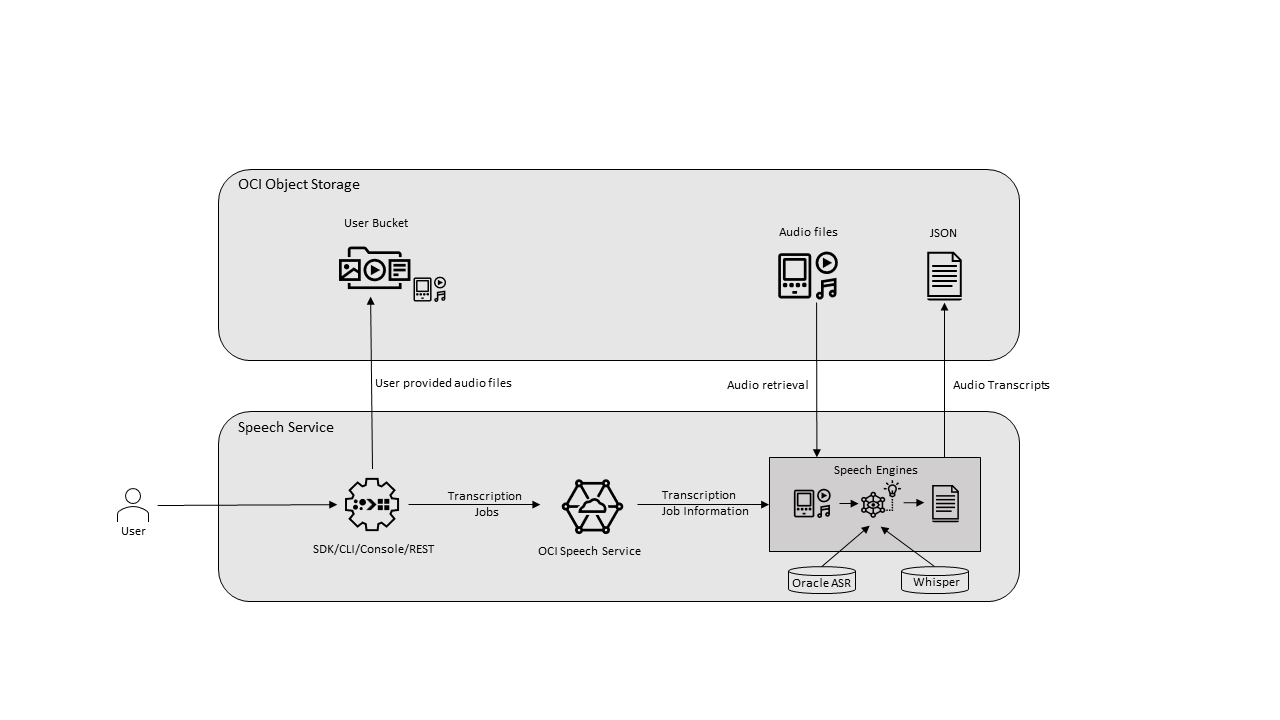
Speech nutzt die Kraft der gesprochenen Sprache, sodass Sie Mediendateien, die menschliche Sprache enthalten, problemlos in hochgenaue Texttranskriptionen konvertieren können. Der Service ist eine native Oracle Cloud Infrastructure-(OCI-)Anwendung, auf die Sie über die Konsole, die REST-API, die CLI und das SDK zugreifen können. Darüber hinaus können Sie den Speech-Service in einer Data Science-Notizbuchsession verwenden.
Speech verwendet die automatische Spracherkennungstechnologie (ASR), um eine grammatikalisch korrekte Transkription bereitzustellen. Speech verarbeitet Medienaufzeichnungen mit geringer Wiedergabetreue und transkribiert anspruchsvolle Aufzeichnungen wie Meetings oder Call Center-Anrufe. Mit Speech können Sie in Object Storage oder einem Datenasset gespeicherte Dateien in exakten, normalisierten, mit Zeitstempel versehenen und profanitätsgefilterten Text umwandeln. Diese Funktionalität ist nur mit der Sprache verfügbar. Beispiel: Sie können die Ausgabe von Sprache (eine Textdatei) mit Data Lake indexieren. Ohne die nachgelagerten Dienste existiert diese Funktion in Speech nicht.
Die Speech-Modelle sind robust gegenüber akustischen Umgebungen und Aufnahmekanälen, die dafür sorgen, dass es sich um einen qualitativ hochwertigen Transkriptionsdienst handelt.
Unterstützung mehrerer Medienformate pro Sprache
Diese Medienformate werden für alle unterstützten Sprachen im Sprachservice unterstützt:
AACAC3AMRAUFLACM4AMKVMP3MP4OGAOGGOPUSWAVWEBM
| Sprache | Sprach-Code | Abtastrate |
|---|---|---|
| Englisch - USA | en-US |
>= 8 khz |
| Spanisch-Spanien | es-ES |
>= 8 khz |
| Portugiesisch-Brasilien | pt-BR |
>= 8 khz |
| Englisch-Großbritannien | en-GB |
>= 16 khz |
| Englisch-Australien | en-AU |
>= 16 khz |
| Englisch-Indien | en-IN |
>= 16 khz |
| Hindi-Indien | hi-IN |
>= 16 khz |
| Französisch-Französisch | fr-FR |
>= 16 khz |
| Deutsch-Deutschland | de-DE |
>= 16 khz |
| Italienisch-Italien | it-IT |
>= 16 khz |
Für beste Ergebnisse:
- Verwenden Sie ein verlustfreies Format wie FLAC oder WAV mit PCM 16-Bit-Codierung.
- Verwenden Sie eine Abtastrate von 8.000 Hz für Medien mit niedriger Wiedergabetreue und 16.000 bis 48.000 Hz für Medien mit hoher Wiedergabetreue.
Sie können einkanalige 16-Bit-PCM-WAV-Mediendateien mit einer Abtastrate von 8 kHz oder 16 kHz verwenden. Wir empfehlen Audacity (GUI) oder FFmpeg (Befehlszeile) für Medientranskodierung. Eine maximale Mediendateilänge von vier Stunden und bis zu 2 GB wird unterstützt.
Sprache ist anfällig für die Qualität der Eingabemediendateien. Unterschiedliche Akzente, Hintergrundgeräusche, der Wechsel von einer Sprache zur anderen, die Verwendung von Fusionssprachen oder mehrere Lautsprecher gleichzeitig beeinflussen die Qualität der Transkription.
Speech bietet diese Funktionen
-
Präzise Transkriptionen - Erstellt präzise und benutzerfreundliche JSON- und SubRip-Untertiteldateien, die direkt in den ausgewählten Objektspeicher-Bucket geschrieben werden. Sie können die Transkription nutzen und sie direkt in Anwendungen integrieren und für Untertitel oder Inhaltssuche und -analyse verwenden.
- Flüsteres Modell – Mehrsprachige Daten werden aus dem Web gesammelt und unterstützen dateibasierte Sprach-zu-Text-Transkriptionen für mehr als 50 Sprachen.
-
JSON mit Zeitstempel - Die Transkription stellt einen Zeitstempel für jedes Token (Wort) bereit. Sie können den Zeitstempel verwenden, um den gesuchten Text in der Mediendatei zu suchen und zu finden und dann schnell zu diesem Speicherort zu springen.
-
Mehrsprachig – Erstellt genaue Transkriptionen in Englisch, Englisch-Großbritannien, Englisch-Australien, Englisch-Indien, Spanisch, Portugiesisch, Französisch, Italienisch, Deutsch und Hindi.
-
Asynchrone API – Einfache asynchrone APIs mit Transkriptionsaufgabenbatching. Die APIs ermöglichen das Abbrechen von Jobs, die noch nicht verarbeitet wurden, und sparen Zeit und Geld.
-
Textnormalisierungen – Stellt Textnormalisierungen für Zahlen, Adressen, Währungen usw. bereit. Mit Textnormalisierungen erhalten Sie eine qualitativ hochwertigere Transkription von künstlicher Intelligenz, die einfacher zu lesen und zu verstehen ist.
-
Profanitätsfilterung - Ermöglicht das Entfernen, Maskieren oder Markieren von Wörtern, die anstößig sind.
-
Konfidenzscore pro Wort und Transkription - Erstellt Wort- und Transkriptionskonfidenzscores für die generierte JSON-Datei. Mit den Konfidenzscores können Sie schnell Wörter identifizieren, die Aufmerksamkeit erfordern.
-
Geschlossene Beschriftungen - Stellt eine SRT-Datei als zusätzliches Ausgabeformat bereit. Verwenden Sie das SRT, um Videodateien Untertitel hinzuzufügen.
-
Interpunktion – Langer Text erfordert Interpunktion, sodass Speech den Transkriptionsinhalt automatisch durchsetzt.
-
Telefone-fähig - Dateien können 8 kHz oder 16 kHz sein, und jede Datei wird automatisch erkannt, damit das richtige Modell angewendet wird. Mit dieser Funktion können Sie Telefonaufnahmen transkribieren.
-
Dialarisierung von Sprechern – Ordnet Transkriptionstext bestimmten Sprechern zu, wobei Szenarien für das Verständnis natürlicher Sprache verwendet werden, z. B. das Extrahieren eines Rezepts aus medizinischem Audio, indem der Dienstleister im Vergleich zum Patienten identifiziert wird. Die Speaker Diarization ist eine Kombination aus Speaker Segmentation und Speaker Clustering. Die Lautsprechersegmentierung findet die Lautsprecherwechselpunkte in einem Audiostream. Sprecherclustering gruppiert Sprachsegmente basierend auf Sprechercharakteristiken.
Wichtige Konzepte
Dies sind die wichtigsten Sprachservicekonzepte:
- Transkriptionsjobs
-
Ein Job ist eine einzelne asynchrone Anforderung von der Konsole oder der Sprach-API. Jeder Job wird eindeutig durch eine ID identifiziert, mit der Sie den Jobstatus und die Ergebnisse abrufen können.
Ein Job in einem Mandanten wird streng zuerst verarbeitet. Jeder Job kann bis zu 100 Aufgaben enthalten. Wenn Sie einen Job weiterleiten, der die maximale Anzahl an Aufgaben überschreitet, schlägt dieser Job fehl. Jobs werden 90 Tage aufbewahrt.
- Live-Transkription
- Ermöglicht das Senden eines Audiostreams an den Service und das Empfangen der Ergebnisse im Textformat (JSON- und SRT-Format) in Echtzeit.
- Aufgaben
-
Eine Aufgabe ist das Ergebnis einer einzelnen Datei, die in einem Job verarbeitet wird. Jobs können mehrere Aufgaben enthalten, je nachdem, was in Ihrem Objektspeicher-Bucket gespeichert ist, den Sie für einen Job angeben.
- Modelle
-
Vorgeschulte akustische und sprachliche Modelle, einschließlich Whisper-Modelle, unterstützen den Job-Transkriptionsprozess.
Authentifizierung und Autorisierung
Jeder Service in OCI kann zur Authentifizierung und Autorisierung für alle Schnittstellen (Konsole, SDK oder CLI und REST-API) in IAM integriert werden.
Ein Administrator in der Organisation muss Gruppen , Compartments und Policys einrichten, die den Zugriffstyp sowie den Zugriff der Benutzer auf Services und Ressourcen steuern. Beispiel: Die Policys steuern, wer Benutzer erstellen, das Cloud-Netzwerk erstellen und verwalten, Instanzen starten, Buckets erstellen, Objekte herunterladen kann usw. Weitere Informationen finden Sie unter Erste Schritte mit Policys.
- Einzelheiten zum Schreiben von Sprach-Policys finden Sie unter Informationen zu Sprach-Policys.
- Einzelheiten zum Schreiben von Policys für andere Services finden Sie in der Policy-Referenz.
Wenn Sie ein regulärer Benutzer sind (also kein Administrator), der OCI-Ressourcen Ihres Unternehmens verwenden muss, bitten Sie den Administrator, eine Benutzer-ID für Sie einzurichten. Der Administrator kann bestätigen, welche Compartments Sie verwenden sollten.
Ressourcen-IDs
Der Speech-Service unterstützt Jobs und Aufgaben als OCI-Ressourcen. Die meisten Ressourcentypen verfügen über eine eindeutige, von Oracle zugewiesene ID, die als Oracle Cloud-ID (OCID) bezeichnet wird. Informationen zum OCID-Format und zu weiteren Möglichkeiten zur Identifizierung Ihrer Ressourcen finden Sie unter Ressourcen-IDs.
Regionen und Availability-Domains
Speech ist in allen kommerziellen OCI-Regionen verfügbar. Unter Regionen und Availability-Domains finden Sie eine Liste der verfügbaren Regionen für OCI sowie zugehörige Standorte, Regions-IDs, Regionsschlüssel und Availability-Domains.
Text to Speech ist nur in der kommerziellen Region "US West (Phoenix)" verfügbar.
Möglichkeiten für den Zugriff
Auf Speech können Sie über die Konsole (eine browserbasierte Oberfläche), die Befehlszeilenschnittstelle (CLI) oder die REST-API zugreifen. Anweisungen für die Konsole, CLI und API sind in verschiedenen Themen in dieser Dokumentation enthalten.
Um auf die Konsole zuzugreifen, müssen Sie einen unterstützten Browser verwenden. Um zur Anmeldeseite der Konsole aufzurufen, öffnen Sie das Navigationsmenü oben auf dieser Seite, und klicken Sie auf Infrastrukturkonsole. Dort werden Sie aufgefordert, Ihren Cloud-Mandanten, Benutzernamen und Ihr Kennwort einzugeben.
Eine Liste der verfügbaren SDKs finden Sie unter SDKs und die CLI. Allgemeine Informationen zur Verwendung der APIs finden Sie unter REST-API.
Servicelimits
In jeder Region, die für Ihren Mandanten aktiviert ist, gelten die folgenden Limits:
Dateilimits
-
Die maximale Dateigröße beträgt 2 GB.
-
Die Dateidauer beträgt maximal 4 Stunden.
Joblimits
Text to Speech
Text in Sprache unterstützt maximal 10000 Zeichen pro Anforderung.
Live-Transkription
Live transcribe unterstützt maximal 10 gleichzeitige Sessions pro Mandant. Limit kann durch Öffnen einer Serviceanfrage beim Oracle-Support ausgelöst werden. Weitere Informationen finden Sie unter Erhöhung des Servicelimits beantragen.
Whisper- und Oracle ASR-Modelle vergleichen
Vergleichen Sie das Whisper-Modell und das Oracle ASR-Modell für die Erstellung von Transkriptionsjobs.
Zusätzlich zum nativen Oracle ASR-Sprachmodell unterstützt Speech das Whisper-Modell aus OpenAI. Whisper wird auf einem großen Korpus von mehrsprachigen Daten trainiert, die aus dem Internet gesammelt werden, und es unterstützt die dateibasierte Voice-to-Text-Transkription für über 50 Sprachen. Dieses Modell verwendet dieselben Serviceendpunkte und API- und SDK-Schnittstellen wie das Oracle ASR-Modell, um Ihnen Flexibilität und Kompatibilität zu bieten. Darüber hinaus verwendet das Whisper-Modell die Diarisierung, um einzelne Lautsprecher in der Aufnahme zu kennzeichnen.
Verwenden Sie den folgenden Vergleich der Whisper- und Oracle ASR-Modelle, um das richtige Modell beim Erstellen eines Transkriptionsjobs auszuwählen.
| Feature | Oracle ASR-Modell | Flüstermodell in OCI Speech |
|---|---|---|
| Transkriptionen in Echtzeit | Unterstützte | Unterstützte |
| Große Dateigröße | Bis zu 2 GB | Bis zu 2 GB |
| Zeitstempel auf Wortebene | Unterstützte | Unterstützte |
| Dateiformat | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM |
| Mehrsprachige Unterstützung | Englisch, Spanisch, Französisch, Deutsch, Italienisch, Portugiesisch und Hindi | Entspricht dem Oracle ASR-Modell und 50 anderen Sprachen* |
| Diarisierung | Unterstützte | Unterstützte |