Überblick über die Daten-Discovery
Mit der Daten-Discovery können Sie sensible Daten in Ihren Oracle-Datenbanken finden.
So sucht die Daten-Discovery nach sensiblen Daten
Der Schutz sensibler Daten beginnt mit dem Wissen, welche sensiblen Daten bei Ihnen vorhanden und wo diese gespeichert sind. Die Daten-Discovery stützt sich bei der Erkennung sensibler Daten in den Zieldatenbanken primär auf sensible Typen. Die Daten-Discovery sucht auch nach Dictionary-basierten referenziellen Beziehungen, um Beziehungen zwischen übergeordneten und untergeordneten Elementen zu finden. Sie können auch festlegen, dass bei der Daten-Discovery nach nicht Dictionary-basierten referenziellen Beziehungen (Beziehungen auf Anwendungsebene) gesucht werden soll.
Bei der Daten-Discovery werden sensible Spalten in den Oracle-Datenbanken mit den von Oracle vordefinierten und benutzerdefinierten sensiblen Typen Ihrer Wahl gesucht. Sie teilen der Daten-Discovery mit, was zu suchen ist, und das Tool findet die sensiblen Spalten, die Ihren Kriterien entsprechen.
Um die erkannten sensiblen Spalten zu validieren, können Sie während der Daten-Discovery nach Wunsch Beispieldaten aus Ihren Zieldatenbanken erfassen. Seien Sie bei der Verwendung dieses Features vorsichtig, weil die Beispieldaten sensible Daten sind. Nur autorisierte Personen sollten die Beispieldaten erfassen und anzeigen können.
Discovery über sensible Typen
Ein sensibler Typ definiert reguläre Ausdrücke, mit denen sensible Spalten basierend auf Spaltennamen, Daten und Kommentaren gesucht werden können. Oracle Data Safe stellt mehr als 170 vordefinierte sensible Typen bereit, mit denen Sie sensible Daten suchen können. Die vordefinierten sensiblen Typen sind in Kategorien organisiert, sodass Sie relevante sensible Typen einfach finden und verwenden können. Sie können vordefinierte sensible Typen nicht ändern oder löschen. Sie können jedoch eigene sensible Typen und Kategorien erstellen. Die Daten-Discovery erkennt keine sensiblen Spalten, die den Datentyp object aufweisen.
Die Kategorien der obersten Ebene für vordefinierte sensible Typen lauten:
-
Identifikationsinformationen: Enthält sensible Typen für nationale, persönliche und öffentliche IDs. Beispiele: US-Sozialversicherungsnummer (SSN), kanadische Sozialversicherungsnummer (SIN) sowie weitere nationale IDs, Visumsnummer sowie Vor- und Nachname.
-
Biografische Informationen: Enthält sensible Typen für Adresse, Familiendaten, erweiterte PII und Daten zur eingeschränkten Verarbeitung. Beispiele: Vollständige Adresse, Geburtsname der Mutter, Geburtsdatum und Konfessionszugehörigkeit.
-
IT-Informationen: Umfasst sensible Typen für IT- und Gerätedaten der Benutzer. Beispiele: Benutzer-ID, Kennwort und IP-Adresse.
-
Finanzinformationen: Enthält sensible Typen für Zahlungskartendaten und Bankkontendaten. Beispiele: Kartennummer, Kreditkartensicherheits-PIN und Bankkontonummer.
-
Gesundheitsinformationen: Enthält sensible Typen für Krankenversicherungsdaten, Daten des Anbieters für medizinische Dienstleistung und medizinische Daten. Beispiele: Krankenversicherungsnummer, Anbieter für medizinische Dienstleistungen und Blutgruppe.
-
Beschäftigungsinformationen: Enthält sensible Typen für Basisdaten, Organisationsdaten und Vergütungsdaten für Mitarbeiter. Beispiele: Tätigkeit, Austrittsdatum, Einkommen und Aktien.
-
Ausbildungsinformationen: Enthält sensible Typen für Basisdaten, Bildungseinrichtungsdaten und Leistungsdaten der Studierenden. Beispiele: Finanzielle Unterstützung, Name der Hochschule, Noten und Disziplinareinträge.
Discovery über Dictionary-basierte referenzielle Beziehungen
Bei der Daten-Discovery wird auch das Oracle-Daten-Dictionary durchsucht, um Beziehungen zwischen Primärschlüsselspalten und Fremdschlüsselspalten zu finden. Die zugehörigen Spalten werden dann als sensibel gekennzeichnet. Beispiel: Angenommen, Sie haben zwei Tabellen. In der ersten Tabelle, CUSTOMERS, werden Informationen wie Vorname, Nachname und Startdatum des Kunden gespeichert. In der zweiten Tabelle, LOCATIONS, werden Informationen zu Ihren Vertriebsstandorten gespeichert.
In der Tabelle CUSTOMERS ist LOCATION_ID als Fremdschlüssel definiert, der den Primärschlüssel LOCATION_ID in der Tabelle LOCATIONS referenziert. Bei der Daten-Discovery werden diese Typen von referenziellen Beziehungen automatisch ermittelt.
Wenn in diesem Beispiel ein sensibler Typ für den Speicherort definiert ist, wird die Spalte LOCATION_ID in beiden Tabellen als sensibel identifiziert.
Discovery über nicht Dictionary-basierte referenzielle Beziehungen
In Oracle Data Safe haben Sie auch die Möglichkeit, nicht dictionary-basierte referenzielle Beziehungen zur Identifizierung sensibler Spalten zu verwenden. Dies sind Beziehungen zwischen Datenbankspalten, die in Anwendungen definiert sind, jedoch nicht im Oracle-Data Dictionary aufgezeichnet sind. Bei der Daten-Discovery werden Spaltennamensmuster und Spaltendatenmuster aus den gewählten sensiblen Typen verwendet, um potenzielle Beziehungen zwischen Spalten zu erkennen.
Beispiel: Die übergeordnete Tabelle hat den Namen CUSTOMER, und eine zugehörige Tabelle hat den Namen PAYMENT_METHOD. Die sensible Spalte lautet CUST_NAME in der übergeordneten Tabelle und CUST_NM in der zugehörigen Tabelle. Wenn die zugehörige Tabelle ohne Anzeige eines Links im Data Dictionary zur übergeordneten Tabelle erstellt wurde (das heißt, es wurden keine Fremdschlüsselinformationen in das Data Dictionary eingegeben), ist die Beziehung zwischen der übergeordneten und der zugehörigen Tabelle eine "nicht dictionary-basierte referenzielle Beziehung".
Modelle für sensible Daten
Mit der Daten-Discovery werden das Discovery-Ergebnisse als Modell für sensible Daten in einem angegebenen Compartment in Oracle Cloud Infrastructure gespeichert. Sie können Modelle für sensible Daten, auf die Sie Zugriff haben, auf der Seite "Modelle für sensible Daten" in Oracle Data Safe suchen. Die Ergebnisse bestehen aus sensiblen Spalten, referenziellen Beziehungen und einem Konfidenzniveau.
Die Spalte Konfidenzstufe in einem Modell für sensible Daten stellt den Grad der Sicherheit in der Klassifizierung für einen bestimmten sensiblen Typ dar. Sie werden es als hoch, mittel oder niedrig kategorisiert sehen. Für manuell hinzugefügte Spalten wird die Konfidenzstufe "Keine" angezeigt, die als - angezeigt wird. Der Konfidenzscore wird durch die Auswertung mehrerer Attribute bestimmt. Dazu gehört auch, ob die Daten, der Name und die Kommentare der Spalte übereinstimmen. Es sucht auch nach ähnlichen sensiblen Typen, die in denselben oder verwandten Tabellen gefunden werden, da die kontextbezogene Ähnlichkeit das Vertrauen stärken kann. Darüber hinaus wertet das Scoring aus, ob die Spalte personenbezogene Daten (PII) bilden kann, wenn sie mit anderen Spalten aus derselben oder verwandten Tabellen (Tabellen, die referenzielle Beziehungen teilen) kombiniert wird, sowie ob solche Kombinationen über nicht verwandte Tabellen hinweg auftreten. Derzeit sind Auswertungen, die auf sensiblen Typen in denselben oder verwandten Tabellen basieren, sowie Spalten, die personenbezogene Daten in verwandten oder nicht verwandten Tabellen bilden, auf die Schemas und sensiblen Typen beschränkt, die im Discovery-Geltungsbereich enthalten sind.
Beispiel: Eine Spalte mit dem Namen CUST_EMAIL in der Tabelle CUSTOMERS. Der Spaltenname entspricht eindeutig dem sensiblen Typ Email Address, der zum Konfidenzscore beiträgt. Die Daten in der Spalte folgen auch gültigen E-Mail-Adressmustern und erhöhen das Vertrauen weiter. Darüber hinaus enthält eine zugehörige Tabelle mit dem Namen ORDERS die Spalte CUST_PHONE, die auch als PII klassifiziert wird, wodurch der Kontext gestärkt wird. Basierend auf diesen Attributen wird der Spalte CUST_EMAIL ein hohes Konfidenzniveau zugewiesen.
Wenn in einer Zieldatenbank Änderungen auftreten, können Sie inkrementelle Aktualisierungen eines Modells für sensible Daten durchführen, sensible Spalten zum Modell für sensible Daten hinzufügen und daraus entfernen sowie die referenziellen Beziehungen zwischen den sensiblen Spalten verwalten. Die Spalte Konfidenzniveau wird aktualisiert, wenn eine inkrementelle Discovery ausgeführt wird. So können Sie Konfidenzniveaus sowohl nach Abschluss der Erstellung des Modells für sensible Daten als auch nach Ausführung eines inkrementellen Discovery-Jobs anzeigen. Sie können ein Modell für sensible Daten herunterladen, offline ändern und dann in dieselben oder andere Oracle Data Safe-Regionen hochladen. Ein Modell für sensible Daten wird jeweils mit einer Zieldatenbank verknüpft. Bei Bedarf können Sie diese Zieldatenbank jedoch ändern.
Sie können ein leeres Modell für sensible Daten direkt erstellen, um einen maßgeschneiderten Ansatz für das Tracking und die Maskierung sensibler Objekte zu ermöglichen. Anstatt die Daten-Discovery auszuführen und unerwünschte Spalten zu entfernen, können Sie ein neues Modell für sensible Daten ohne vordefinierte Spalten erstellen und anschließend nur relevante Spalten hinzufügen.
Damit Sie Ihre sensiblen Daten besser verstehen und Informationen dazu aufbewahren können, stellt die Daten-Discovery herunterladbare Berichte für Modelle für sensible Daten und inkrementelle Discoverys bereit. Beide Berichtstypen enthalten die Gesamtanzahl der sensiblen Tabellen, Spalten und Werte sowie Details zu den sensiblen Spalten. Die sensiblen Spalten werden basierend auf den sensiblen Typen kategorisiert.
Optional können Sie Metadaten in einem Modell für sensible Daten speichern, einschließlich Beispieldaten und geschätzte Zeilenanzahl. Mit diesen Informationen erhalten Sie einen Überblick, wie viele verschiedene Typen von sensiblen Daten in den Zieldatenbanken vorhanden sind.
Mit einem Modell für sensible Daten können Sie andere Sicherheitskontrollen wie eine Datenmaskierung implementieren. Beispiel: Sie können eine Maskierungs-Policy mit einem Modell für sensible Daten definieren und zur Maskierung der sensiblen Daten in Zieldatenbanken verwenden. Sie können ein Modell für sensible Daten für mehrere Maskierungs-Policys wiederverwenden.
Landingpage für Daten-Discovery
Die Daten-Discovery-Landingpage bietet einen allgemeinen Überblick über Ihre sensiblen Daten über die Zieldatenbanken in den ausgewählten Compartments. Sie können die Filter, die für Zieldatenbankgruppen und sensible Typgruppen festgelegt sind, nach Bedarf ändern. Die Diagramme und Tabellen werden sofort aktualisiert.
Registerkarte "Sensible Typen"
Auf der Registerkarte Sensible Typen im Daten-Discovery-Dashboard erhalten Sie einen Überblick darüber, wie häufig die 21 allgemeinen sensiblen Typen in Ihrer Zieldatenbankflotte verwendet werden. Die 21 allgemeinen sensiblen Typen wurden von Oracle als die sensiblen Typen identifiziert, die am ehesten in einer Datenbank vorhanden sind. Mit der Suche nach sensiblen Typen können Sie ermitteln, wie häufig andere sensible Typen in Ihrer Zieldatenbankflotte verwendet werden.
Mit dem Diagramm Sensible Typen können Sie ermitteln, welche sensiblen Typen in Ihren Zieldatenbanken am häufigsten vorkommen. Dabei wird eine prozentuale Aufschlüsselung der 21 allgemeinen sensiblen Typen in Ihrer Zieldatenbankflotte angezeigt.
Mit der Tabelle Sensible Typen können Sie ermitteln, ob die Daten-Discovery in Ihrer Zieldatenbankflotte gut genutzt wird. Dabei wird die Anzahl der Datenbanken angezeigt, die ein Modell für sensible Daten erstellt haben und noch nicht.
Die folgende Abbildung zeigt die Liste der sensiblen Typen in der Daten-Discovery. 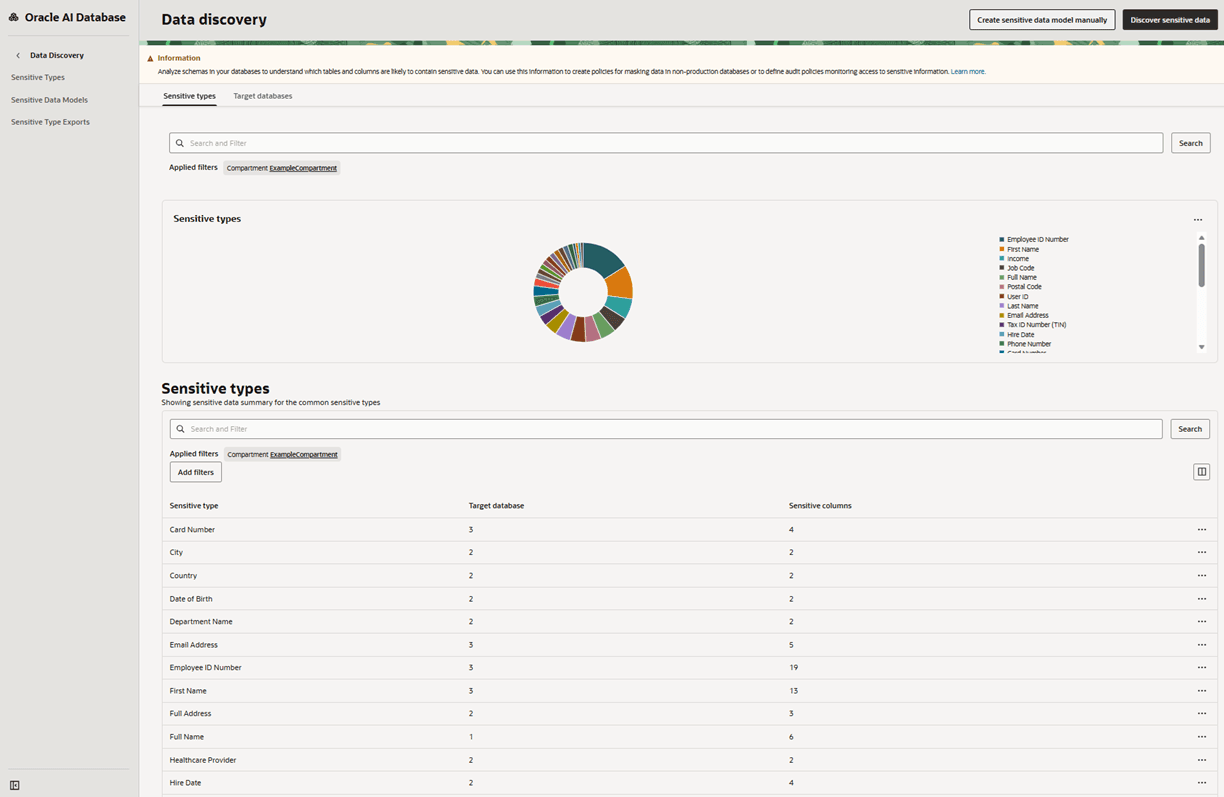
Beschreibung der AbbildungDiscovery-dashboard-common-sensitive-tab.png
Registerkarte "Zieldatenbanken"
Die Diagramme oben im Dashboard beziehen sich auf Ihre fünf wichtigsten Zieldatenbanken. Mit dem Diagramm Top 5 Ziele (nach sensiblen Spalten) können Sie ermitteln, welche Zieldatenbanken die meisten sensiblen Spalten aufweisen. Zu diesem Zweck wird eine prozentuale Aufschlüsselung der sensiblen Spalten in den fünf wichtigsten Zielen angezeigt. Mit dem Diagramm Top 5 Ziele (nach sensiblen Werten) können Sie ermitteln, welche Zieldatenbanken die meisten sensiblen Werte enthalten. Zu diesem Zweck wird eine prozentuale Aufschlüsselung der sensiblen Werte für die fünf Ziele angezeigt.
Die folgende Abbildung zeigt eine Zusammenfassung der sensiblen Daten für die Zieldatenbanken in den ausgewählten Compartments. 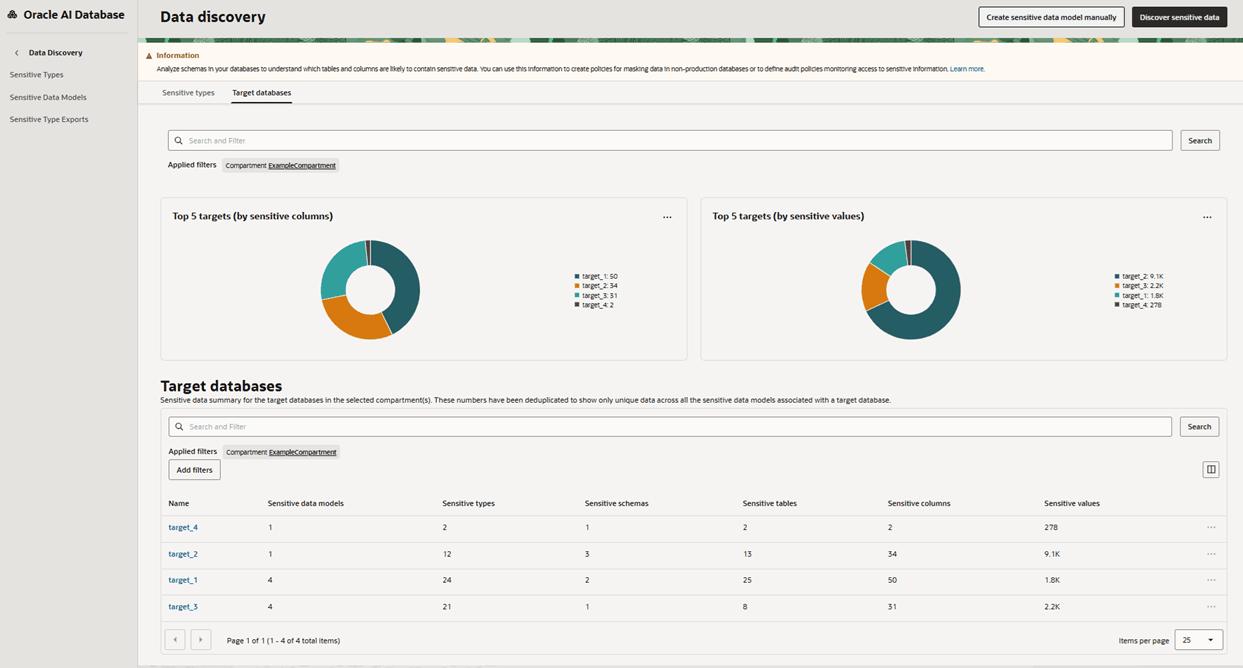
Beschreibung der Abbildung data-discovery-dashboard.png
Auf die Diagramme folgt die Zusammenfassung der sensiblen Daten für die Zieldatenbanken in den ausgewählten Compartments. Mit der Übersicht können Sie Statistiken zwischen den Zieldatenbanken vergleichen, einschließlich der Anzahl der für jede Zieldatenbank erstellten Modelle für sensible Daten sowie der Anzahl der sensiblen Typen, sensiblen Schemas, sensiblen Tabellen, sensiblen Spalten und sensiblen Werte in jeder Zieldatenbank.
Klicken Sie in der Zusammenfassung der sensiblen Daten auf die Registerkarte Zieldatenbanken, und klicken Sie dann auf einen Zieldatenbanknamen, um die Registerkarte Details und die Registerkarte Modelle für sensible Daten anzuzeigen. Die Modelle für sensible Daten listet Modelle für sensible Daten auf, die mit der ausgewählten Zieldatenbank verknüpft sind. In dieser Tabelle werden für jedes Modell der sensiblen Daten der Zielname und die Menge der folgenden Elemente in dem Modell angezeigt: sensible Typen, sensible Schemas, sensible Geschichten, sensible Spalten und sensible Werte.
Daten-Discovery-Workflow
Bevor Sie ein Modell für sensible Daten erstellen, müssen Sie folgende Schritte ausführen:
-
Rufen sie die entsprechenden Berechtigungen in Oracle Cloud Infrastructure Identity and Access Management ab, und registrieren Sie die Zieldatenbank.
-
(Optional) Wenn die Statistiken auf Schemaebene nicht aktuell sind, erfassen Sie Schemastatistiken in der Zieldatenbank, um korrekte Ergebnisse zu gewährleisten. Führen Sie dazu die Prozedur
dbms_stats.gather_schema_statsaus. Es wird empfohlen, diese Prozedur nur bei Bedarf auszuführen, weil sie ein ressourcenintensiver Vorgang ist. Informationen zu den Parametern, die Sie aufnehmen können, finden Sie unter GATHER_SCHEMA_STATS-Prozeduren. Im folgenden Beispiel werden Statistiken zumHCM1-Schema erfasst:exec dbms_stats.gather_schema_stats(ownname => 'HCM1');
Jetzt können Sie ein Modell für sensible Daten erstellen. Wenn Sie in der Daten-Discovery arbeiten, führen Sie beim Erstellen eines Modells für sensible Daten die folgenden allgemeinen Schritte aus:
-
Geben Sie Informationen zum Modell für sensible Daten an, und wählen Sie eine Zieldatenbank aus.
-
(Optional) Wenn die Schemas in der Zieldatenbank seit der angegebenen Uhrzeit und dem angegebenen Datum aktualisiert wurden, klicken Sie auf Datenbankschemas aktualisieren.
-
Wählen Sie die Schemas aus, in denen Sie sensible Daten suchen möchten. Sie können auch alle Schemas auswählen. Nur von Oracle nicht verwaltete Schemas werden angezeigt und können ausgewählt werden.
-
Wählen Sie die sensiblen Typen aus, nach denen in der Zieldatenbank gesucht werden soll. Sie können auch alle sensiblen Typen auswählen.
-
Wählen Sie optionale Discovery-Optionen aus, einschließlich des Abrufs von Beispieldaten und der Suche nach referenziellen Beziehungen auf Anwendungsebene.
Nachdem das Modell für sensible Daten anfänglich mit sensiblen Spalten aufgefüllt wurde, gehen Sie wie folgt vor:
-
Ändern Sie das Modell für sensible Daten nach Bedarf so, dass es die sensiblen Daten in der Zieldatenbank genau wiedergibt.
-
Ereignisbenachrichtigungen einrichten. Beispiel: Sie können ein
Sensitive Data Model Create Begin-Ereignis erstellen, das automatisch informiert wird, wenn ein Modell für sensible Daten erstellt wird.
Im Lauf der Zeit können Sie folgende Aufgaben ausführen:
-
Verwenden Sie das Modell für sensible Daten mit anderen Zieldatenbanken. Dazu können Sie das Modell für sensible Daten herunterladen und in eine andere Oracle Data Safe-Region hochladen. Sie können ein Modell für sensible Daten auch mit einer anderen Zieldatenbank verknüpfen.
-
Verschieben Sie das Modell für sensible Daten in ein anderes Compartment.
-
Erstellen Sie manuell ein Modell für sensible Daten, um einen maßgeschneiderten Ansatz für das Tracking und die Maskierung sensibler Objekte zu ermöglichen.
-
Anstatt die Daten-Discovery auszuführen und unerwünschte Spalten zu entfernen, können Sie ein neues Modell für sensible Daten ohne vordefinierte Spalten erstellen und anschließend nur relevante Spalten hinzufügen.
-
Klicken Sie dazu im Dashboard auf die Schaltfläche Modell für sensible Daten manuell erstellen, oder aktivieren Sie das Kontrollkästchen Modell für sensible Daten manuell erstellen im Bereich Sensible Daten ermitteln.
-
Nachdem das neue Modell für sensible Daten erstellt wurde, klicken Sie auf Spalten hinzufügen, um dem Modell für sensible Daten relevante Spalten manuell hinzuzufügen.
-
Nicht unterstützte Datentypen, Objekte und Datenbankfeatures für die Daten-Discovery
Folgende Datentypen werden für die Daten-Discovery nicht unterstützt:
- LONG
- RAW
- BFILE
- BLOB
- JSON
Folgende Objekttypen werden für die Daten-Discovery nicht unterstützt:
- XMLTYPE
- HTTPURITYPE
- XDBURITYPE
- DBURITYPE
- ADT
Die folgenden nicht unterstützten Datenbankfunktionen für die Daten-Discovery:
- Externe Tabellen
- Temporäre Tabellen
- Anzeigen
- Index
- Verschachtelte Tabellen
Voraussetzungen für die Verwendung der Daten-Discovery
Die Voraussetzungen für die Verwendung von Daten-Discovery lauten wie folgt:
-
registrieren Sie die Zieldatenbanken, die Sie mit Daten-Discovery verwenden möchten.
- Wenn eine Zieldatenbank bereits von einer anderen Person bei Oracle Data Safe registriert ist, müssen Sie die Berechtigung
READfür die Zieldatenbankressource in Oracle Cloud Infrastructure Identity and Access Management (IAM) abrufen, um Discovery-Jobs auszuführen.
- Wenn eine Zieldatenbank bereits von einer anderen Person bei Oracle Data Safe registriert ist, müssen Sie die Berechtigung
-
Erteilen Sie die Rolle "Daten-Discovery" in der Zieldatenbank. Ein Datenbankadministrator kann diese Rolle dem Oracle Data Safe-Serviceaccount in der Zieldatenbank erteilen.
-
Rufen Sie die Berechtigung in IAM ab, das Feature "Daten-Discovery" in Oracle Data Safe zu verwenden. Ein Mandantenadministrator kann diese Berechtigungen erteilen. Für diese Ressourcen sind Berechtigungen erforderlich:
-
data-safe-discovery-jobsErfordert die Berechtigung
manage, um Discovery-Jobs auszuführen. -
data-safe-sensitive-data-modelsErfordert die Berechtigung
managefür die Ausführung von Discovery-Jobs und die Änderung von Modellen für sensible Daten. -
data-safe-sensitive-typesErfordert die Berechtigung
managezum Erstellen sensibler Typen. -
data-safe-work-requestsErfordert die Berechtigung
readzum Anzeigen von Arbeitsanforderungen.
Als Alternative zum selektiven Erteilen von Berechtigungen können Sie Berechtigungen für
data-safe-discovery-familyin den relevanten Compartments erteilen, was Berechtigungen für alle oben genannten Ressourcen umfassen würde. Siehe data-safe-discovery-family Resource. -
Hinweis
Hinweis: Da das Daten-Discovery von der Oracle Data Safe-Konsole in ein Sicherheitscenter in Oracle Cloud Infrastructure verschoben wurde, muss ein Administrator vorhandene Daten-Discovery-Berechtigungen zu IAM migrieren. Nach Abschluss dieser Migration können in IAM weiteren Benutzergruppen Berechtigungen zur Verwendung des Features "Daten-Discovery" erteilt werden.
Verwandte Themen
-
Unter Rollen für den Oracle Data Safe-Serviceaccount in der Zieldatenbank erteilen werden die Rollen beschrieben, die für die Daten-Discovery und für andere Oracle Data Safe-Features erforderlich sind.
-
Unter IAM-Policys für Oracle Data Safe erstellen werden die Berechtigungen beschrieben, die für jedes Feature in Oracle Data Safe erforderlich sind.