Kritische Datenbanken mit Autonomous Data Guard vor Fehlern und Katastrophen schützen
Mit dem Autonomous Data Guard-Feature können Sie Ihre kritischen Produktionsdatenbanken trotz Ausfällen, Katastrophen, menschlichen Fehlern oder Datenbeschädigung für geschäftskritische Anwendungen verfügbar halten. Diese Art von Funktion wird häufig als Disaster Recovery bezeichnet.
In der autonomen KI-Datenbank auf dedizierter Exadata-Infrastruktur konfigurieren und verwalten Sie Autonomous Data Guard in der autonomen Containerdatenbank.
Autonomous Data Guard
Autonomous Data Guard erstellt und verwaltet zwei vollständig separate Kopien der Datenbank: eine Primärdatenbank, mit der Ihre Anwendungen verbunden sind und verwendet werden, und eine Standbydatenbank, bei dem es sich um eine synchronisierte Kopie der Primärdatenbank handhabt. Sollte die Primärdatenbank aus irgendeinem beliebigen Grund nicht mehr verfügbar sind, kann Autonomous Data Guard die Standbydatenbank in die Primärdatenbank konvertieren, und von den Anwendungen dann bedient werden.
Primär- und Standbydatenbanken werden häufig als Peerdatenbanken bezeichnet. Pro autonomer Containerdatenbank können bis zu zwei Standbydatenbanken vorhanden sein.
Hinweis: Anwendungen müssen dafür konfiguriert werden, Transparent Application Continuity (TAC) zu verwenden, um sämtliche Vorteile der Datenbankverfügbarkeitsfeatures von Autonomous Data Guard zu nutzen.
Das folgende Diagramm zeigt, wie jede Standbydatenbank mit der Primärdatenbank synchronisiert wird.
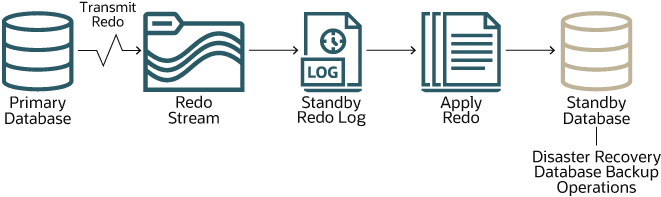
Beschreibung der Abbildung autonome-data-guard.png
An der Primärdatenbank vorgenommene Änderungen werden im Redo-Log der Primärdatenbank aufgezeichnet. Autonomous Data Guard überträgt diese Redo-Datensätze als Stream über das Netzwerk in das Redo-Log der Standbydatenbank. Anschließend wendet die Standbydatenbank diese Datensätze auf die Standbydatenbank an. Auf diese Weise bleibt die Standbydatenbank mit der Primärdatenbank synchronisiert.
Die Synchronisierung erfolgt nahezu unmittelbar. Wie der zuvor beschriebene Prozess nahelegt, gibt es jedoch zwei Vorgänge, die Zeit in Anspruch nehmen: die Übertragung der Redo-Datensätze an die Standbydatenbank und die Anwendung der Redo-Datensätze auf die Standbydatenbank. Die erste dieser Aktionen wird als Transport-Lag bezeichnet, die andere alsApply-Lag. Sie können die aktuellen Verzögerungswerte für eine autonome KI-Datenbank auf der Seite "Details" der Datenbank unter Autonomous Data Guard anzeigen. Auf ähnliche Weise können Sie die aktuellen Verzögerungswerte für alle autonomen KI-Datenbanken in einer Containerdatenbank auf der Seite "Details" der Containerdatenbank anzeigen.
Hinweis: Bei mehreren Standbydatenbanken wird kaskadierter Redo-Transport nicht unterstützt.
Autonomous Data Guard konfigurieren
In der autonomen KI-Datenbank auf dedizierter Exadata-Infrastruktur konfigurieren und verwalten Sie Autonomous Data Guard auf der Ebene der autonomen Containerdatenbank (ACD). Sie können Autonomous Data Guard für bereits bereitgestellte ACDs aktivieren und über die Oracle Cloud Infrastructure-Konsole auf der Seite Details bis zu zwei Standby-ACDs hinzufügen. Anweisungen finden Sie unter Autonomous Data Guard in einer autonomen Containerdatenbank aktivieren und Zweite autonome Standbycontainerdatenbank hinzufügen.
-
Sie können Autonomous Data Guard jetzt zwischen einer ACD in Oracle Cloud Infrastructure (OCI) und einer ACD in Amazon Web Services (AWS) erstellen und verwalten.
-
Sie können der bereits bereitgestellten ACD in der OCI-Region eine Standby-ACD aus der AWS-Region hinzufügen. Alternativ können Sie eine Standby-ACD in der OCI-Region zu einer bereits bereitgestellten ACD in der AWS-Region hinzufügen.
Beachten Sie Folgendes, bevor Sie Autonomous Data Guard konfigurieren:
-
Für autonome KI-Datenbanken, die auf Exadata Cloud@Customer bereitgestellt werden, muss Port 1522 geöffnet sein, damit der TCP-Traffic zwischen der Primärdatenbank und der Standbydatenbank in einem Autonomous Data Guard-Setup zulässig ist.
-
Autonomous Data Guard kann nicht auf einer ACD mit einem aktiven Wartungslauf aktiviert werden, der innerhalb der nächsten drei Tage geplant ist. Sie können zuerst die aktive Wartung ausführen und dann Autonomous Data Guard aktivieren oder den Wartungslaufplan ändern, sodass er erst gestartet wird, wenn die zweite Standbydatenbank hinzugefügt wurde.
-
Für das Hinzufügen einer zweiten Standbydatenbank ist ein automatischer Rolling-Neustart für die erste Standbydatenbank erforderlich. Die Primärdatenbank ist von diesem rollierenden Neustart nicht betroffen.
Autonomous Data Guard mit vom Kunden verwalteten Schlüsseln konfigurieren
In der autonomen KI-Datenbank auf dedizierter Exadata-Infrastruktur können Sie Autonomous Data Guard mit vom Kunden verwalteten Schlüsseln auf der Ebene der autonomen Containerdatenbank (ACD) konfigurieren und verwalten. Sie können Autonomous Data Guard für bereits bereitgestellte ACDs aktivieren und über die Oracle Cloud Infrastructure-Konsole auf der Seite "Details" bis zu zwei Standby-ACDs hinzufügen. Anweisungen finden Sie unter Autonomous Data Guard in einer autonomen Containerdatenbank aktivieren und Zweite autonome Standbycontainerdatenbank hinzufügen.
Beachten Sie Folgendes, bevor Sie Autonomous Data Guard mit vom Kunden verwalteten Schlüsseln konfigurieren:
-
Wenn Sie Oracle Cloud Infrastructure Key Management System (OCI KMS) verwenden und regionsübergreifendes Autonomous Data Guard aktivieren möchten:
-
Zuerst müssen Sie den OCI-Vault in die Region replizieren, in der Sie die Standbydatenbank hinzufügen möchten. Weitere Informationen finden Sie unter Vaults und Schlüssel replizieren.
-
Sie können nur die Primär- und die Standbydatenbank in maximal 2 Regionen verwenden. Wenn Sie also eine zweite Standby-Datenbank hinzufügen und bereits eine regionsübergreifende Datenbank für die erste Standby-Datenbank verwendet haben, muss sich die zweite Standby-Datenbank in der primären Region oder der ersten Standby-Region befinden.
Hinweis: Virtuelle Vaults, die vor der Einführung des Features für die regionsübergreifende Vault-Replikation erstellt wurden, können nicht regionsübergreifend repliziert werden. Erstellen Sie einen neuen Vault und neue Schlüssel, wenn Sie einen Vault haben, den Sie in einer anderen Region replizieren müssen, und die Replikation für diesen Vault nicht unterstützt wird. Alle privaten Vaults unterstützen jedoch die regionsübergreifende Replikation. Weitere Informationen finden Sie unter Regionsübergreifende Virtual-Vault-Replikation.
-
-
Wenn Sie Oracle Key Vault (OKV) verwenden und regionsübergreifendes Autonomous Data Guard aktivieren möchten, stellen Sie sicher, dass Sie Verbindungs-IP-Adressen für das OKV-Cluster im Keystore hinzugefügt haben.
-
Wenn Sie AWS Key Management System (AWS KMS) verwenden und regionsübergreifenden Autonomous Data Guard aktivieren möchten:
- In der primären Region muss ein AWS-Mehrregionsschlüssel registriert sein. Sie können den AWS-Schlüsseltyp nur dann als "Mehrere Regionen" auswählen, wenn Sie ihn erstellen, und er kann später nicht mehr geändert werden.
- Sie müssen die erforderlichen Policys in der replizierten Region festlegen, da Policys nicht automatisch repliziert werden.
- Der AWS KMS-Mehrregionsschlüssel muss von der Quellregion über die AWS-Konsole in die Zielregion repliziert werden. Weitere Informationen finden Sie unter AWS KMS-Schlüssel in der AWS-Konsole replizieren.
- Der AWS KMS-Mehrregionsschlüssel muss von der primären Region über die OCI-Konsole in die Zielregion repliziert werden. Weitere Informationen finden Sie unter AWS KMS-Schlüssel in der OCI-Konsole replizieren.
Rollenübergänge und zugehörige Vorgänge
Nachdem eine autonome Containerdatenbank (ACD) erstellt wurde, können Sie die Rolle der Peerdatenbanken mit einem Switchover- oder Failover-Vorgang ändern. Wenn der automatische Failover aktiviert ist, führt Autonomous Data Guard automatisch einen Failover-Vorgang aus, wenn die Primärdatenbank aus irgendeinem Grund nicht mehr verfügbar ist.
Ein Switchover ist eine Rollenumkehr zwischen der Primärdatenbank und ihrer Standbydatenbank. Ein Switchover erfolgt ohne Datenverlust. Während eines Switchovers geht die Primärdatenbank in die Standbyrolle und die Standbydatenbank in die Primärrolle über. Informationen zum Ausführen eines Switchover-Vorgangs finden Sie unter Rollen in einer Autonomous Data Guard-Konfiguration wechseln.
Ein Failover tritt auf, wenn die Primärdatenbank nicht verfügbar ist. Der Failover führt zu einem Übergang der Standbydatenbank in die Primärrolle. Wenn der automatische Failover nicht aktiviert ist, können Sie einen manuellen Failover ausführen, wie unter Failover zur Standbydatenbank in einer Autonomous Data Guard-Konfiguration beschrieben.
Die Verfügbarkeit und der Status der Datenbank nach einem Failover-Vorgang sind durch zwei Recovery-Ziele gekennzeichnet:
-
Recovery Time Objective (RTO). Das RTO ist die maximale Zeit, die erforderlich ist, damit die Datenbank nach einem Failover für Anwendungen verfügbar wird. Es hängt zu einem gewissen Grad mit dem Apply-Lag zum Zeitpunkt des Fehlers zusammen. Für Autonomous Data Guard beträgt das RTO wenige Sekunden bis zwei Minuten.
-
Recovery Point Objective (RPO). Das RPO ist die maximale Dauer des potenziellen Datenverlusts aufgrund der ausgefallenen Primärdatenbank. Es hängt zu einem gewissen Grad mit dem Transport-Lag zum Zeitpunkt des Fehlers zusammen. Für Autonomous Data Guard beträgt das RPO nahezu null.
Nach einem Failover wird die ausgefallene Primärdatenbank zu einer deaktivierten Standbydatenbank und bleibt für jede Datenbankverbindung nicht verfügbar. Sie können sie erneut aktivieren und in eine fehlerfreie Standbydatenbank umwandeln, indem Sie einen reinstate-Vorgang ausführen. Nachdem eine ausgefallene Primärdatenbank als Standbydatenbank wiederhergestellt wurde, können Sie ein Switchover ausführen, um sie wieder in ihre ursprüngliche Primärrolle zurückzuversetzen. Informationen zum Ausführen eines Neuinstanziierungsvorgangs finden Sie unter Deaktivierte Standbydatenbank in einer Autonomous Data Guard-Konfiguration neu instanziieren.
Automatischer Failover oder Fast-Start Failover
Beim automatischen Failover wird automatisch ein Failovers ausgeführt, wenn die primäre ACD aufgrund eines Regionsfehlers, eines Availability-Domainfehlers, eines Ausfalls in der Region, der Exadata-Infrastruktur oder dem autonomen Exadata-VM-Cluster (AVMC) oder des Ausfalls der ACD selbst nicht verfügbar ist. Dies wird auch als Fast-Start Failover bezeichnet.
Sie können das automatische Failover nicht aktivieren, während Sie Autonomous Data Guard auf einer ACD konfigurieren. Automatisches Failover kann nur aktiviert oder deaktiviert werden, wenn die Autonomous Data Guard-Einstellungen auf der Seite Details der ACD aktualisiert werden.
Hinweis: Automatisches Failover kann nicht für autonome KI-Datenbanken aktiviert werden, die in Exadata Cloud@Customer mit regionsübergreifendem Autonomous Data Guard-Setup bereitgestellt sind.
Sie können keine zweite Standby-ACD hinzufügen, bei der das automatische Failover für die erste Standby-ACD aktiviert ist. Deaktivieren Sie daher das automatische Failover mit Autonomous Data Guard-Einstellungen aktualisieren, bevor Sie die zweite Standby-ACD erstellen, und aktivieren Sie es bei Bedarf später erneut.
Sowohl der Schutzmodus für maximale Performance als auch der Schutzmodus für maximale Verfügbarkeit unterstützen automatischen Failover:
-
Im Modus Maximale Verfügbarkeit garantiert automatisches Failover keinen Datenverlust.
-
Im Modus Maximale Performance stellt der automatische Failover sicher, dass die Standbydatenbank gegenüber der Primärdatenbank nicht mehr über den für Lag-Grenzwert für Fast Start Failover angegebenen Wert hinaus in Rückstand liegt. Standardmäßig ist Lag-Grenzwert fürFast Start-Failover auf 30 Sekunden eingestellt und gilt nur für den Modus "Maximale Performance" In diesem Fall ist ein automatisches Failover nur möglich, wenn der Apply Lag (potenzieller Datenverlust) der Standbydatenbank den konfigurierten Lag-Grenzwert nicht überschreitet. Sie können das Fast Start Failover-Lag-Limit auf einen beliebigen Wert zwischen 5 und 3600 ändern.
Weitere Informationen finden Sie unter Autonomous Data Guard-Einstellungen aktualisieren.
Neben Hardwarefehlern, Availability-Domainausfällen und regionalen Ausfällen gibt es einige weitere Datenbankzustände, die einen Fast-Start Failover auslösen können, wie unten aufgeführt:
| Datenbankzustand | Beschreibung |
|---|---|
| Beschädigte Kontrolldatei | Die Kontrolldatei ist wegen eines Datenträgerfehlers dauerhaft beschädigt. |
| Beschädigtes Dictionary | Dictionary-Beschädigung einer kritischen Datenbank. Dieser Status wird derzeit nur erkannt, wenn die Datenbank geöffnet ist. |
| Datendatei-Schreibfehler | Schreibfehler treten in beliebigen Datendateien auf, einschließlich temporärer Dateien, Systemdatendateien und Undo-Dateien. |
Durch einen automatischen Failover ändert sich die Rolle der ausgefallenen Primärdatenbank in "Deaktivierte Standbydatenbank". Nach kurzer Zeit übernimmt die Standbydatenbank die Rolle der Primärdatenbank. Nach Abschluss des automatischen Failovers wird auf der Detailseite der deaktivierten Standbydatenbank gemeldet, dass ein Failover stattgefunden hat.
Nachdem der Service die Probleme mit der ursprünglichen autonomen Primärcontainerdatenbank behoben hat, können Sie einen manuellen Switchover ausführen, um beide Datenbanken in ihre anfänglichen Rollen zurückzuversetzen. Nachdem Sie die Standbydatenbank bereitgestellt haben, können Sie verschiedene Verwaltungsaufgaben für die Standbydatenbank ausführen, darunter:
-
Manuellen Switchover einer Primärdatenbank zu einer Standbydatenbank durchführen
-
Manuellen Failover einer Primärdatenbank zu einer Standbydatenbank durchführen
-
Primärdatenbank nach Failover in Standbyrolle neu instanziieren
-
Standbydatenbank beenden
In einem Autonomous Data Guard-Setup mit mehreren Standbydatenbanken und automatischem Failover:
-
Bei manuellen Failovers müssen Sie die ursprüngliche primäre Datenbank, die zur neuen Standby-Datenbank wird, manuell neu instanziieren.
-
Bei jedem automatischen Failover versucht die autonome KI-Datenbank auf der dedizierten Exadata-Infrastruktur, die alte Primärdatenbank als Standbyinstanz neu zu instanziieren. Wenn dieser Versuch jedoch fehlschlägt, muss er manuell wiederhergestellt werden.
Snapshot-Standbydatenbank
Eine Snapshot-Standbydatenbank ist eine vollständig aktualisierbare Standbydatenbank, die durch Konvertieren einer autonomen Standbycontainerdatenbank (ACD) in eine Snapshot-Standby-ACD erstellt wird. Schritt-für-Schritt-Anweisungen finden Sie unter Physische Standbydatenbank in Snapshot Standby konvertieren.
Eine Snapshot-Standbydatenbank empfängt und archiviert Redo-Daten aus der Primärdatenbank, gilt jedoch nicht. Es erhöht jedoch das Recovery Time Objective (RTO), da Echtzeitänderungen aus der Primärdatenbank nicht angewendet werden.
Die Snapshot-Standbyfunktion unterstützt verschiedene Anwendungsfälle, aber hier sind die primären Anwendungsfälle:
-
Verbinden Sie Primär- und Standby-Anwendungsinstanzen mit Primär- und Standbydatenbanken im Lese-/Schreibmodus, um anfängliche Konfigurationen auszuführen.
-
Patchen Sie zunächst die Snapshot-Standbydatenbank, und testen Sie sie mit der Standbyanwendungsinstanz, um die Patchstabilität zu bestätigen. Dazu muss zuerst die physische Standbydatenbank in eine Snapshot-Standbydatenbank konvertiert werden, damit der Patch in der Snapshot-Standbydatenbank eingespielt werden kann.
Hinweis: Sie können eine autonome Standbycontainerdatenbank einer physischen Standbydatenbank nicht in eine Snapshot-Standbydatenbank konvertieren, wenn das automatische Failover aktiviert ist.
Bei der Konvertierung in eine Snapshot-Standbydatenbank können Sie entweder neue Datenbankservices aktivieren, die nur im Snapshot-Modus aktiv sind, oder dieselben Services verwenden, die mit der primären Datenbank verwendet werden. Das Aktivieren von Primärdatenbankservices in der Snapshot-Standbydatenbank kann jedoch dazu führen, dass Snapshot-Standbyverbindungsanforderungen an die Primärdatenbank weitergeleitet werden, oder umgekehrt, wenn Sie falsche Datenbankverbindungszeichenfolgen verwenden. Daher müssen Sie beim Herstellen einer Verbindung zur Primär- und Snapshot-Standbydatenbank unbedingt die entsprechende Verbindungszeichenfolge verwenden.
Hinweis: Wenn Sie neue Services mit Snapshot Standby erstellen, werden Wallets für alle autonomen KI-Datenbanken in der Snapshot Standby-ACD aktualisiert. Um auf die Datenbank zuzugreifen, laden Sie die Wallets aus autonomen Standby-AI-Datenbanken neu, und verwenden Sie Snapshot-Standbyverbindungszeichenfolgen.
Sie können die Snapshot-Standby-ACD manuell von Oracle Cloud Infrastructure (OCI) in eine physische Standby-ACD konvertieren. Ausführliche Anweisungen finden Sie unter Snapshot-Standby in physische Standbydatenbank konvertieren. Wenn eine Snapshot-Standbydatenbank nicht manuell in eine physische Standbydatenbank konvertiert wird, wird sie nach 7 Tagen nach ihrer Erstellung automatisch wieder in eine physische Standbydatenbank konvertiert. Wenn Sie die Snapshot-Standbydatenbank zurück in eine physische Standbydatenbank konvertieren, werden in jedem Fall alle lokalen Updates in den Snapshot-Standbydatenbanken verworfen, und die von den Primärdatenbanken empfangenen Redo-Daten werden eingespielt.
Wenn sich eine Standby-ACD im Snapshot-Standbymodus befindet, können Sie die folgenden Vorgänge nicht auf der primären ACD ausführen:
-
Autonome KI-Datenbanken erstellen oder beenden
-
Autonome KI-Datenbanken vertikal oder horizontal skalieren
-
Autonome KI-Datenbanken wiederherstellen
Wenn die Situation dies erfordert, können Sie manuell einen Failover von der Primärdatenbank auf eine Snapshot-Standbydatenbank durchführen. In diesem Fall konvertiert Failover die Snapshot-Standbydatenbank in eine physische Standbydatenbank, indem alle lokalen Aktualisierungen, die an der Snapshot-Standbydatenbank vorgenommen wurden, verworfen und Daten aus der Primärdatenbank angewendet werden. Schritt-für-Schritt-Anweisungen finden Sie unter Failover zur Standbydatenbank in einer Autonomous Data Guard-Konfiguration.
Ein Switchover zwischen der Primärdatenbank und ihrer Snapshot-Standbydatenbank ist nicht zulässig. Sie müssen die Snapshot-Standbydatenbank vor einem Switchover manuell in eine physische Standbydatenbank konvertieren.
Aus Clientanwendungen auf Standbydatenbanken zugreifen
In einer Autonomous Data Guard-Konfiguration stellen Ihre Clientanwendungen in der Regel eine Verbindung zur Primärdatenbank her und führen Vorgänge für diese Datenbank aus.
Verbindung mit der physischen Standbydatenbank herstellen
Neben dieser normalen Konnektivität bietet Ihnen Autonomous Data Guard die Möglichkeit, Clientanwendungen zu verbinden, die schreibgeschützte Vorgänge ausführen, mit der Standbydatenbank. Um diese Option in Anspruch zu nehmen, stellen Clientanwendungen eine Verbindung zur Datenbank mit Datenbankservicenamen, die "_RO" (für "schreibgeschützt") enthalten, wie unter Vordefinierte Datenbankservicenamen für autonome KI-Datenbanken beschrieben.
Verbindung zur Snapshot-Standbydatenbank herstellen
Mit Autonomous Data Guard können Sie auch Clientanwendungen, die Lese-/Schreibvorgänge ausführen, mit der Snapshot-Standbydatenbank verbinden. Diese Vorgänge sind lokal in der Snapshot-Standbydatenbank und ändern ihre Primärdatenbank nicht. Um eine Verbindung zu einer Snapshot-Standbydatenbank herzustellen, können Clientanwendungen Datenbankservicenamen verwenden, die "_SS" (für "Snapshot-Standby") enthalten, wie unter Vordefinierte Datenbankservicenamen für autonome KI-Datenbanken beschrieben.
Hinweis: Wenn sich die Standbydatenbank im Snapshot-Standbymodus befindet, sind alle Datenbankservices, die "_RO"-Services in ihrem Namen enthalten, inaktiv und können nicht für Verbindungen verwendet werden.
Lag-Zeiten überwachen
Während Ihre Datenbanken, die Autonomous Data Guard verwenden, ausgeführt werden, können Sie Transport- und Apply-Lag-Zeiten über die Detailseite der Datenbank (oder Containerdatenbank) überwachen, indem Sie Autonomous Data Guard-Gruppen auswählen. Sie können auch die OCI-Konsole oder Beobachtbarkeits-APIs verwenden, um Transportverzögerungen zu überwachen und Alarme und Benachrichtigungen zu konfigurieren. Weitere Informationen finden Sie unter Datenbankbeobachtbarkeit mit autonomen KI-Datenbankmetriken.
Sie sollten mit einer geringfügigen Fluktuation im Laufe der Zeit rechnen, während die Workloads in der Datenbank ab- und zunehmen. Wenn Sie jedoch einen anhaltenden Aufwärtstrend bei der Lag-Zeit feststellen, können Sie das Problem wie folgt beheben:
-
Aufwärtstrend bei Apply Lag. Ein anhaltender Aufwärtstrend beim Apply Lag weist darauf hin, dass die Standbydatenbank nicht über ausreichende Kapazität für die von der Primärdatenbank eingehenden Redo-Datensätze verfügt. Um diese Situation zu beheben, skalieren Sie die OCPUs der Datenbank, wie unter CPU- oder Speicherressourcen zu einer dedizierten autonomen KI-Datenbank hinzufügen beschrieben.
-
Aufwärtstrend bei Transport-Lag. Ein anhaltender Aufwärtstrend beim Transport-Lag weist auf ein Problem mit der Netzwerkperformance hin. Das Oracle Cloud-Betriebspersonal überwacht konstant die Netzwerkperformance, sodass das Problem behoben werden sollte, ohne dass Sie Maßnahmen ergreifen müssen. Bei Bedarf können Sie das Problem jedoch dem Betriebspersonal melden, indem Sie eine Serviceanfrage stellen, wie unter Serviceanfrage in My Oracle Support erstellen beschrieben.
Konfigurationsoptionen für Autonomous Data Guard
Wenn Sie Autonomous Data Guard konfigurieren, geben Sie an, in welchen Exadata-Infrastruktur- und autonomen Exadata-VM-Clusterressourcen die Standbydatenbank erstellt werden soll und welcher Datenschutzmodus verwendet werden soll.
Sie haben folgende Auswahlmöglichkeiten, wenn sie angeben, welche Exadata-Infrastruktur- und autonomen Exadata-VM-Clusterressourcen für die Standbydatenbank verwendet werden sollen:
-
In einer anderen Region als Exadata-Infrastruktur und das autonome Exadata-VM-Cluster der Primärdatenbank:
Diese Option bietet den höchsten Schutz vor Katastrophen, einschließlich eines Ausfalls der gesamten externen Netzwerkkonnektivität oder Stromversorgung in einer gesamten Region.
Um diesen regionsübergreifenden Schutz optimal nutzen zu können, muss auch die Application Tier so konfiguriert sein, dass regionsübergreifender Schutz unterstützt wird. Daher empfiehlt Oracle, diese Option auszuwählen, wenn die Application Tier bereits so konfiguriert ist oder wenn Sie sie so neu konfigurieren möchten, dass regionsübergreifender Schutz unterstützt wird.
Wenn Sie die Standbydatenbank in einer anderen Region suchen, empfiehlt Oracle, den Schutzmodus Maximale Performance zu verwenden.
-
In einer anderen Availability-Domain (AD) als Exadata-Infrastruktur und das autonome Exadata-VM-Cluster der Primärdatenbank:
Diese Option bietet einen hohen Schutz vor Katastrophen, einschließlich eines Ausfalls der externen Netzwerkkonnektivität oder Stromversorgung zu einer Availability-Domain innerhalb einer Region.
Diese Option bietet ein ausgewogenes Verhältnis zwischen Datenschutz und einfacher Konfiguration in der Application Tier.
Wenn Sie die Standbydatenbank in einer anderen Availability-Domain suchen, empfiehlt Oracle, den Schutzmodus Maximale Verfügbarkeit zu verwenden.
-
In derselben Availability-Domain (AD) wie Exadata-Infrastruktur und das autonome Exadata-VM-Cluster der Primärdatenbank:
Diese Option bietet ein Mindestmaß an Schutz vor Katastrophen, und Oracle empfiehlt, diese Option nicht auszuwählen.
Wenn sich die Exadata-Infrastruktur- und autonomen Exadata-VM-Clusterressourcen für die Primärdatenbank in einer Region befinden, die nur eine Availability-Domain aufweist, empfiehlt Oracle, die Option "In einer anderen Region" zu verwenden.
Wenn Sie die Standbydatenbank in derselben Availability-Domain suchen, empfiehlt Oracle, den Schutzmodus Maximale Verfügbarkeit zu verwenden.
-
In einem anderen Mandanten als Exadata-Infrastruktur und das autonome Exadata-VM-Cluster der Primärdatenbank:
Gilt nur für:
 Oracle Public Cloud
Oracle Public CloudMit dieser Option können Sie eine Standbydatenbank in einem anderen Mandanten als die Primärdatenbank hinzufügen, sodass Ihr Datenbank-Failover oder -Switchover zu dieser mandantenübergreifenden Standbydatenbank möglich ist. Sie können auch eine Snapshot-Standbydatenbank im Remotemandanten erstellen. Eine mandantenübergreifende Standbydatenbank kann bei der Datenbankmigration mandantenübergreifend hilfreich sein.
Mandantenübergreifende Standbydatenbanken:
-
Kann mit ECPU- oder OCPU-Compute-Modell aktiviert werden. Die Standbydatenbank muss dasselbe Compute-Modell wie die Primärdatenbank verwenden.
-
Unterstützt automatisches Failover. Automatisches Failover kann jedoch nicht für autonome KI-Datenbanken aktiviert werden, die in Exadata Cloud@Customer mit regionsübergreifendem Autonomous Data Guard-Setup bereitgestellt sind.
-
Kann nicht mit der Oracle Cloud Infrastructure-Konsole hinzugefügt werden. Sie können eine mandantenübergreifende Standbydatenbank nur mit der CLI oder REST-API hinzufügen. Nachdem Sie die Standbydatenbank hinzugefügt haben, können Sie über die Oracle Cloud Infrastructure-Konsole die mandantenübergreifende Standbydatenbank anzeigen, ein Failover oder ein Switchover zur mandantenübergreifenden Standbydatenbank ausführen.
-
Schutzmodi
Autonomous Data Guard stellt die folgenden Datenschutzmodi bereit:
-
Maximale Verfügbarkeit. Dieser Schutzmodus bietet den höchsten Datenschutz, der ohne Auswirkungen auf die Verfügbarkeit der Primärdatenbank möglich ist.
Die Primärdatenbank schreibt Transaktionen erst fest, wenn sie die Bestätigung erhält, dass die Daten in der Standbydatenbank empfangen wurden (nicht, dass sie auf den Datenträger geschrieben wurden). Wenn die Primärdatenbank diese Bestätigungsmeldung nicht innerhalb von 30 Sekunden erhält, arbeitet sie wie im Modus "Maximale Performance", um die Verfügbarkeit von Primärdatenbank zu erhalten, bis sie wieder zeitnah Bestätigen erhält.
Dieser Schutzmodus stellt sicher, dass kein Datenverlust auftritt, außer bei bestimmten doppelten Fehlern wie dem Ausfall einer Primärdatenbank nach einem Ausfall der Standbydatenbank.
-
Maximale Performance. Dies ist der Standardschutzmodus. Dieser Schutzmodus bietet den höchsten Datenschutz, der ohne Auswirkungen auf die Performance der Primärdatenbank möglich ist.
Die Primärdatenbank schreibt Transaktionen fest, sobald alle von diesen Transaktionen generierten Redo-Daten in das Online-Redo-Log geschrieben wurden. Außerdem werden Redo-Daten an die Standbydatenbank gesendet. Dies erfolgt jedoch hinsichtlich der Transaktions-Commits asynchron, sodass die Performance der Primärdatenbank durch Verzögerungen beim Schreiben von Redo-Daten in die Standbydatenbank nicht beeinträchtigt wird.
Dieser Schutzmodus bietet etwas weniger Datenschutz als der Modus "Maximale Verfügbarkeit" und hat minimale Auswirkungen auf die Performance der Primärdatenbank.
Sie können den Schutzmodus in einem Autonomous Data Guard-Setup über die Oracle Cloud Infrastructure-(OCI-)Konsole ändern. Schritt-für-Schritt-Anweisungen finden Sie unter Autonomous Data Guard-Einstellungen aktualisieren.
Weitere Informationen zu Schutzmodi in Oracle Data Guard (das dem Autonomous Data Guard-Feature zugrunde liegt) finden Sie unter Oracle Data Guard Protection Modes in Oracle Data Guard Concepts and Administration.
Best Practices beim Konfigurieren von Autonomous Data Guard
Mit Autonomous AI Database können Sie zwar bis zu zwei Standby-ACDs mit Autonomous Data Guard erstellen, Sie können jedoch je nach Anforderung einzelne oder mehrere Standby-ACDs verwenden. Um jedoch die resilientste Disaster-Recovery-Option zu verwenden, die eine autonome KI-Datenbank bietet, können Sie eine lokale Standby-ACD und eine Remote- oder regionsübergreifende Standby-ACD mit maximaler Verfügbarkeit als Datenschutzmodus hinzufügen.
Lassen Sie uns die Vorteile dieses Designs verstehen:
-
Lokale Standbydatenbank:
-
Das automatische Failover auf eine lokale Standbydatenbank in derselben Region bietet eine erhebliche lokale Disaster-Isolation und Einfachheit beim Anwendungs-Failover.
-
Der Geschäftswert einer lokalen Standby-Datenbank wird durch Failover ohne Datenverlust und durch Ausfallzeiten der Anwendung auf Sekunden reduziert.
-
Anwendungen führen automatisch und transparent ein Failover zur lokalen Standbydatenbank durch und behalten dabei die gleiche Latenz zwischen Anwendungsservern und der Datenbank bei. Dies ist besonders wichtig für OLTP- und Packageanwendungen, da sich eine höhere Latenz erheblich auf den Durchsatz und die Antwortzeit der gesamten Anwendung auswirken kann.
-
-
Remote-Standby:
-
Wenn bei einer regionalen Katastrophe der Zugriff auf das primäre und das lokale Standbysystem nicht möglich ist, können Anwendung und Datenbank ein Failover zur Remote-Standbydatenbank ausführen.
-
Obwohl die Ausfallzeit der Datenbank bei einem regionalen Ausfall immer noch sehr gering ist, kann die Ausfallzeit der Anwendung aufgrund zusätzlicher Orchestrierung für DNS-, Anwendungs- und Datenbank-Failover-Vorgänge in die sekundäre Region höher sein.
-
-
Maximale Verfügbarkeit:
-
Wenn automatisches Failover oder Fast-Start Failover (FSFO) aktiviert ist und die primäre ACD nicht mehr verfügbar ist, führt Autonomous Data Guard ein Failover zur lokalen Standbydatenbank aus, ohne dass Daten verloren gehen und keine Änderung an der Datenbanklatenz in der Anwendung erfolgt.
-
Wenn automatisches Failover oder Fast-Start Failover (FSFO) aktiviert ist und immer dann, wenn auf die gesamte primäre Region nicht mehr zugegriffen werden kann, geht das System mit einem potenziellen Datenverlust auf die Remote-Standbydatenbank über.
-
Auswirkungen von Autonomous Data Guard auf Standardverwaltungsvorgänge
In einigen Fällen funktionieren die Standardverwaltungsvorgänge, die Sie in autonomen Containerdatenbanken ausführen, in der Primär- und Standbycontainerdatenbank in einer Autonomous Data Guard-Konfiguration anders als in Standardcontainerdatenbanken. In der folgenden Liste werden diese Unterschiede beschrieben.
-
Wartungsplan ändern
Die Wartungsplanung einer Primärcontainerdatenbank ist mit dem ihrer Standbydatenbank verknüpft: Die Wartung der Standbydatenbank wird mehrere Tage vor der Wartung der Primärdatenbank ausgeführt. Der Standardwert beträgt 7 Tage. Sie können 1 bis 7 Tage auswählen, wenn Sie die Primärcontainerdatenbank erstellen oder die zugehörigen Wartungsdetails später bearbeiten.
-
Wartungstyp ändern
Der Wartungstyp einer Primärcontainerdatenbank muss mit dem ihrer Standbydatenbank identisch sein. Sie wählen den Wartungstyp sowohl für die Primär- und die Standbydatenbank aus, wenn Sie die Primärcontainerdatenbank erstellen oder die zugehörigen Wartungsdetails später bearbeiten.
-
Automatische Backups deaktivieren
Beim Provisioning einer autonomen Containerdatenbank (ACD) mit Autonomous Data Guard können Sie keine automatischen Backups deaktivieren.
-
Geplante Wartung verwalten
Sie können die geplante Wartung einer Primärcontainerdatenbank und ihrer Standbydatenbank separat verwalten. Da die Wartungspläne der beiden Datenbanken jedoch verknüpft sind, müssen Sie die geplante Wartung für die Standbydatenbank vor der Primärdatenbank ausführen, wenn Sie die geplante Wartungszeit außer Kraft setzen möchten.
-
Zu einem anderen Compartment wechseln
Sie können Primär- und Standbycontainerdatenbanken separat und unabhängig in andere Compartments verschieben, genauso wie Standardcontainerdatenbanken. Wie bei Standardcontainerdatenbanken sollten Sie jedoch beim Verschieben einer Containerdatenbank äußerst vorsichtig sein. Stellen Sie sicher, dass die Containerdatenbank für die erforderlichen Gruppen von Cloud-Benutzern zugänglich bleibt.
-
Neustart
Sie können Primär- und Standbycontainerdatenbanken separat und unabhängig neu starten, genauso wie Standardcontainerdatenbanken.
-
Verschlüsselungsschlüssel rotieren
Sie können die Verschlüsselungsschlüssel aus der primären ACD oder Primärdatenbank rotieren.
-
Beenden
Sie können Primär- und Standbycontainerdatenbanken separat beenden. Das Beenden einer Primärcontainerdatenbank hat jedoch andere Folgen als das Beenden einer Standbycontainerdatenbank:
-
Beim Beenden einer Primärcontainerdatenbank werden sowohl die primäre als auch die Standbycontainerdatenbank beendet. Sie können keine Primärcontainerdatenbanken beenden, die autonome KI-Datenbanken enthalten.
-
Wenn Sie eine Standbycontainerdatenbank beenden, wird die Standbycontainerdatenbank beendet, und die Autonomous Data Guard-Konfiguration wird daraus entfernt. Wenn nur noch eine primäre Datenbank vorhanden ist, wird die Autonomous Data Guard-Konfiguration entfernt. Dadurch wird die primäre Datenbank in eine Standalone-Containerdatenbank umgewandelt.
-
Schritt-für-Schritt-Anleitungen
Schritt-für-Schritt-Anleitungen zum Verwalten der Autonomous Data Guard-Konfiguration in einer autonomen Containerdatenbank finden Sie unter:
-
Autonomous Data Guard auf einer autonomen Containerdatenbank aktiviert
-
Rollen in einer Autonomous Data Guard-Konfiguration wechseln
-
Failover zur Standbydatenbank in einer Autonomous Data Guard-Konfiguration
-
Deaktivierte Standbydatenbank in einer Autonomous Data Guard-Konfiguration wieder in Betrieb nehmen
-
Physische Standbydatenbank in Snapshot-Standbydatenbank konvertieren
-
Snapshot-Standbydatenbank in physische Standbydatenbank konvertieren
Mit der API können Sie auch die Autonomous Data Guard-Konfiguration anzeigen und verwalten. Weitere Details finden Sie unter API zum Verwalten der Autonomous Data Guard-Konfiguration.