Externe Daten mit AWS Glue Data Catalog abfragen
Autonomous AI Database unterstützt ein System für die Synchronisierung mit einer Amazon AWS Glue Data Catalog-Instanz.
Informationen zum Abfragen mit AWS Glue Data Catalog
Mit Autonomous AI Database können Sie mit Amazon Web Service-(AWS-)Glue Data Catalog-Metadaten synchronisieren. Eine externe Datenbanktabelle wird automatisch von Autonomous AI Database für jede Tabelle erstellt, die von AWS Glue über Daten erstellt wird, die in Amazon Simple Storage Service (S3) gespeichert sind. Benutzer können in S3 gespeicherte Daten aus Autonomous AI Database abfragen, ohne das Schema für die externen Datenquellen manuell ableiten und externe Tabellen erstellen zu müssen.
Amazon AWS Glue Data Catalog ist ein zentralisierter Metadatenverwaltungsservice, mit dem Datenexperten Daten erkennen und Data Governance in der AWS-Cloud unterstützen können. Eine Autonomous AI Database-Instanz kann automatisch Datenkatalogmetadaten mit AWS Glue Data Catalog synchronisieren, sodass Datenbankbenutzer Daten, die in der AWS-Cloud gespeichert sind, sofort mit Autonomous AI Database abfragen können.
Die Synchronisierung mit AWS Glue Data Catalog hat dieselben Eigenschaften wie die Synchronisierung mit OCI Data Catalog. Die Synchronisierung ist dynamisch und hält die Datenbank in Bezug auf Änderungen an den zugrunde liegenden Daten auf dem neuesten Stand. Dadurch werden die Administrationskosten gesenkt, da sie automatisch Hunderte bis Tausende von Tabellen verwaltet.
Konzepte für die Abfrage mit AWS Glue Data Catalog
Für Abfragen mit Amazon Web Service (AWS) Glue-Datenkatalogen ist ein Verständnis der folgenden Konzepte erforderlich.
AWS Glue-Datenkatalog: Datenbank
Eine AWS Glue-Datenbank stellt eine Sammlung relationaler Tabellendefinitionen dar, die in einer logischen Gruppe organisiert sind. Jede AWS Glue-Datenkataloginstanz verwaltet mehrere Datenbanken.
AWS Glue-Datenkatalog: Tabelle
Eine AWS Glue-Tabelle stellt eine relationale Tabelle über Daten dar, die in der AWS-Cloud gespeichert sind. Eine AWS Glue-Tabelle definiert das Schema der zugrunde liegenden Daten und besteht aus Spalteninformationen, Partitionsinformationen, Serialisierungsinformationen, Speicherinformationen, Statistiken, benutzerdefinierten Metadaten und anderen Metadaten. Tabellen im AWS Glue-Datenkatalog können manuell oder automatisch mit einem AWS Glue-Crawler erstellt werden.
Glue Data Catalog: Crawler
Mit einem Crawler können Sie den AWS Glue-Datenkatalog mit Tabellen füllen. Dies ist die primäre Methode, die von den meisten AWS Glue-Benutzern verwendet wird. Ein Crawler kann mehrere Datenspeicher in einer einzelnen Ausführung crawlen. Nach Abschluss erstellt oder aktualisiert der Crawler eine oder mehrere Tabellen im Datenkatalog. ETL-(Extrahieren, Transformieren und Laden-)Jobs, die Sie in AWS Glue definieren, verwenden diese Datenkatalogtabellen als Quellen und Ziele. Der ETL-Job liest und schreibt in die Datenspeicher, die in den Quell- und Zieldatenkatalogtabellen angegeben sind.
AWS Glue-Tabellen können manuell vom Benutzer oder automatisch mit einem vordefinierten oder benutzerdefinierten Crawler erstellt werden. Crawler stellen eine Verbindung zu den zugrunde liegenden Datenspeichern her (z.B. Amazon S3), rufen Classifier auf, um das Schema der Daten abzuleiten, und erstellen AWS Glue-Tabellen zum Speichern der inferenzierten Metadaten. AWS Glue bietet Klassifikatoren für gängige Dateitypen, wie CSV, JSON, Parquet und AVRO.
Zuordnung zwischen autonomer KI-Datenbank und AWS Glue
Während des Synchronisierungsprozesses werden externe Tabellen in Autonomous AI Database erstellt, die aus den AWS Glue Data Catalog-Datenbanken und -Tabellen über Amazon S3 abgeleitet werden.
AWS Glue organisiert gesammelte Metadaten in Datenbanken und Tabellen. Eine AWS Glue-Datenbank ist eine Sammlung relationaler Tabellendefinitionen. AWS Glue-Tabellen, die das allgemeine Schema und die Eigenschaften der Dateien beschreiben, die mit der Tabelle verknüpft sind.
AWS Glue folgt dem relationalen Modell zur Darstellung von Attributen. Um hierarchische Schemas relationalen Schemas zuzuordnen, leitet AWS Glue das Schema der halbstrukturierten Daten ab und vereinfacht die Daten mithilfe eines ETL-Prozesses auf ein relationales Schema.
Die folgende Tabelle stellt die Zuordnung zwischen OCI Data Catalog-Konzepten und AWS Glue Data Catalog-Konzepten dar.
| OCI Data Catalog | AWS Glue-Datenkatalog | Oracle Database |
|---|---|---|
| Datenasset | Datenbank | Schema |
| Ordner | (Bucket) | Schema |
| Logische Entity | Tabelle | Tabelle |
Benutzerworkflow für die Abfrage mit AWS Glue Data Catalog
Der grundlegende Benutzerworkflow für die Abfrage von AWS S3-Daten mit AWS Glue Data Catalog umfasst die Verbindung mit AWS Glue Data Catalog, die Synchronisierung mit Autonomous AI Database, um automatisch externe Tabellen zu erstellen, und die Abfrage der S3-Daten.
Der Database Data Catalog-Administrator erstellt eine Verbindung zwischen der Autonomous AI Database-Instanz und einer AWS Glue Data Catalog-Instanz. Anschließend konfiguriert und führt er eine Synchronisierung (Sync) zwischen dem AWS Glue Data Catalog und der Autonomous AI Database aus. Autonomous AI Database erstellt automatisch eine externe Tabelle für Tabellen, die von AWS Glue zu in S3 gespeicherten Daten gesammelt werden.
Der Administrator der Datenbankdatenkatalogabfrage oder der Datenbankadministrator erteilt READ-Zugriff auf die generierten externen Tabellen, sodass Datenanalysten und andere Datenbankbenutzer autonome KI-Datenbanken durchsuchen und abfragen können, ohne das Schema für die externen Datenquellen manuell ableiten und externe Tabellen erstellen zu müssen.
Benutzer
In der folgenden Tabelle werden die verschiedenen Benutzertypen beschrieben, die Benutzerworkflowaktionen ausführen.
| Benutzer | Beschreibung |
|---|---|
| Datenbank-Data Catalog-Administrator | Datenbankbenutzer mit der Rolle DCAT_SYNC. |
| Datenbankdatenkatalog - Abfrageadministrator | Datenbankbenutzer können anderen Benutzern Zugriff auf automatisch erstellte externe Tabellen erteilen. |
| Datenanalyst | Datenbankbenutzer auf einer autonomen KI-Datenbank, der Daten in AWS S3 abfragt, entweder durch Abfragen automatisch erstellter externer Tabellen oder durch direkte Interaktion mit AWS Glue Data Catalog. |
| AWS Glue-Datenkatalogbenutzer | AWS-Benutzer mit Zugriff auf einen AWS Glue Data Catalog. |
| AWS S3 Object Storage-Benutzer | AWS-Benutzer mit Zugriff auf in AWS S3 gespeicherte Daten |
Benutzerworkflow
Hinweis: Das DBMS_DCAT-Package ist für die Ausführung der Aufgaben verfügbar, die zum Abfragen des AWS S3-Objektspeichers mit AWS Glue Data Catalog erforderlich sind. Siehe DBMS_DCAT-Package.
| Aktion | Wer ist der Benutzer | Beschreibung |
|---|---|---|
| Policys erstellen | Datenbank-Data Catalog-Administrator | Die Zugangsdaten für den Autonomous AI Database-Benutzer müssen über die entsprechenden Berechtigungen für den Zugriff auf AWS Glue Data Catalog und für das Lesen aus dem S3-Objektspeicher verfügen. Weitere Informationen: Erforderliche Zugangsdaten und IAM-Policys. |
| Zugangsdaten erstellen | Datenbank-Data Catalog-Administrator | {::nomarkdown} <p>Stellen Sie sicher, dass Datenbankzugangsdaten vorhanden sind, um auf AWS Glue Data Catalog zuzugreifen und den S3-Objektspeicher abzufragen. Der Benutzer ruft DBMS_CLOUD.CREATE_CREDENTIAL auf, um Benutzerzugangsdaten zu erstellen.</p><p>Hinweis: Nur Amazon Web Services-(AWS-)Zugangsdaten werden unterstützt. AWS Amazon Resource Names-(ARN-)Zugangsdaten werden nicht unterstützt.</p><p>Weitere Informationen: DBMS_CLOUD CREATE_CREDENTIAL-Prozedur,</p> |
| CONNECT | Datenbank-Data Catalog-Administrator | Herstellen einer Verbindung zwischen einer autonomen KI-Datenbankinstanz und einer AWS Glue Data Catalog-Instanz. Die Verbindung verwendet die Berechtigungen des AWS Glue Data Catalog-Benutzers. Verbindungen von einer autonomen KI-Datenbankinstanz zu mehreren AWS Glue Data Catalog-Instanzen werden unterstützt. So starten Sie eine Verbindung zwischen einer autonomen KI-Datenbankinstanz und einer AWS Glue Data Catalog-Instanz:
Nachdem die Verbindung hergestellt wurde, speichert Autonomous AI Database die zugehörigen Metadaten, wie die AWS Glue-Katalog-ID, die Region, den Endpunkt und die Zugangsdatenobjekte. Weitere Informationen: Prozedur SET_DATA_CATALOG_CONN, Prozedur UNSET_DATA_CATALOG_CONN, DBMS_DCAT. SET_DATA_CATALOG_CREDENTIAL, DBMS_DCAT.SET_OBJECT_STORE_CREDENTIAL. |
| Synchronisieren | Datenbank-Data Catalog-Administrator | Der Benutzer kann eine Synchronisierung mit verbundenen AWS Glue Data Catalogs mit Die Synchronisierung führt Folgendes aus:
|
| Synchronisierung überwachen | Datenbank-Data Catalog-Administrator | Der Benutzer kann den Synchronisierungsstatus anzeigen, indem er die Ansicht USER_LOAD_OPERATIONS abfragt. Nachdem der Synchronisierungsprozess abgeschlossen wurde, kann der Benutzer ein Log der Synchronisierungsergebnisse anzeigen, einschließlich Details zu den Mappings zu externen Tabellen. |
| Berechtigungen erteilen | Database Data Catalog-Abfrageadministrator, Datenbankadministrator | Der Data Catalog-Abfrageadministrator oder Datenbankadministrator der Datenbank muss Benutzern von Datenanalysten READ-Berechtigungen für generierte externe Tabellen erteilen. Dadurch können die Datenanalysten die generierten externen Tabellen abfragen. |
| Abfrage | Datenanalyst | Datenanalysten können die synchronisierten Schemas und Tabellen in den GLUE$*-Schemas prüfen und die externen Tabellen mit jedem Tool oder jeder Anwendung abfragen, das Oracle SQL unterstützt. Der Zugriff auf Daten in S3 erfolgt über die Berechtigungen des AWS S3 Object Storage-Benutzers. Weitere Informationen: Beispiel: Abfrage mit AWS Glue Data Catalog |
| Verbindungen beenden | Datenbank-Data Catalog-Administrator | Um eine vorhandene Data Catalog-Verknüpfung zu entfernen, ruft der Benutzer die Prozedur Diese Aktion wird nur ausgeführt, wenn Sie nicht mehr planen, den verbundenen AWS Glue Data Catalog und die externen Tabellen zu verwenden, die aus dem Katalog abgeleitet werden. Mit dieser Aktion werden AWS Glue Data Catalog-Metadaten gelöscht und synchronisierte externe Tabellen aus der Instanz der autonomen KI-Datenbank gelöscht. Weitere Informationen: Prozedur UNSET_DATA_CATALOG_CONN |
Beispiel: Abfrage mit AWS Glue Data Catalog
In diesem Beispiel werden Abfragen über Datasets ausgeführt, die in Amazon Simple Storage Service (Amazon S3) mit einem AWS Glue Data Catalog gespeichert sind.
In diesem Beispiel werden Metadaten in einem AWS Glue Data Catalog geprüft, um zu sehen, welche Amazon S3-Objekte zuvor gecrawlt wurden und im Datenkatalog vorhanden sind. Die autonome KI-Datenbank wird dann mit dem AWS Glue Data Catalog und Amazon S3 verknüpft. Der Datenkatalog wird mit Autonomous AI Database synchronisiert, um externe Tabellen über die in Amazon S3 gespeicherten Datasets zu erstellen. Die externen Tabellen werden zur Abfrage der Datasets in Amazon S3 verwendet.
-
Prüfen Sie Metadaten im AWS Glue Data Catalog.
-
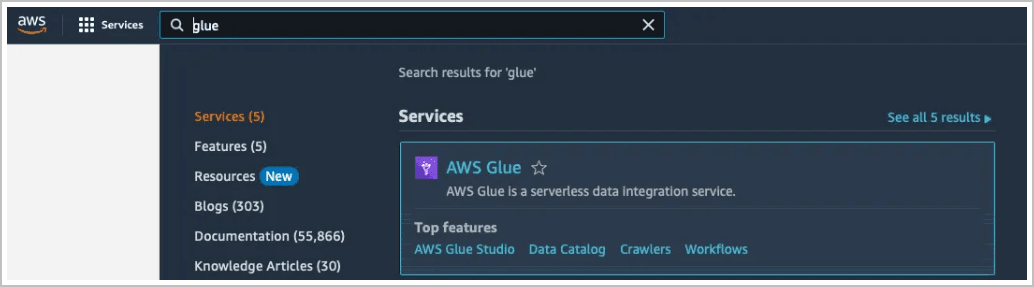
Starten Sie die AWS Glue Konsole.
-
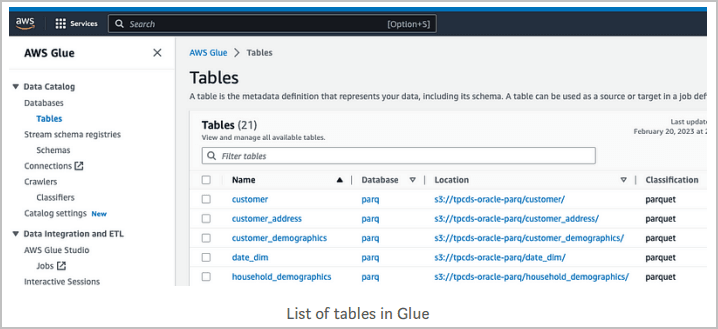
Navigieren Sie zum Datenkatalog, zu Datenbanken und Tabellen, um vorhandene Objekte zu suchen.
In diesem Beispiel sind einige Objekte in Amazon S3 vorhanden, für die AWS Glue zuvor Tabellen gecrawlt und erstellt hat, wie unten gezeigt:
-
-
AWS Glue mit einer autonomen KI-Datenbank verknüpfen
-
Zugangsdaten in autonomer KI-Datenbank erstellen.
Der folgende Prozeduraufruf umfasst die Zugriffs-ID und den Secret Key, um Autonomous AI Database Zugriff auf die zugrunde liegenden Daten in Amazon S3 zu ermöglichen.
exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>'); -
Verknüpfen Sie die Zugangsdaten mit dem AWS Glue Data Catalog und dem Amazon S3-Objektspeicher.
Diese Prozeduraufrufe verknüpfen den Datenkatalog bzw. den Objektspeicher mit den Zugangsdaten.
exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS'); -
Einrichten einer AWS-Region, in der Glue ausgeführt wird.
exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');
-
-
Synchronisieren Sie Metadaten, um externe Tabellen in Autonomous AI Database zu erstellen, die aus AWS Glue-Datenbanken und -Tabellen abgeleitet werden.
-
Nachdem die Verknüpfung abgeschlossen ist, suchen Sie in der Ansicht
all_glue_databases, welche Datenbanken sich in einem AWS Glue Data Catalog befinden.select * from all_glue_databases order by name; -
Mit der Ansicht
all_glue_tableskönnen Sie eine Liste der Tabellen abrufen, die für die Synchronisierung verfügbar sind.select * from all_glue_tables order by database_name, name;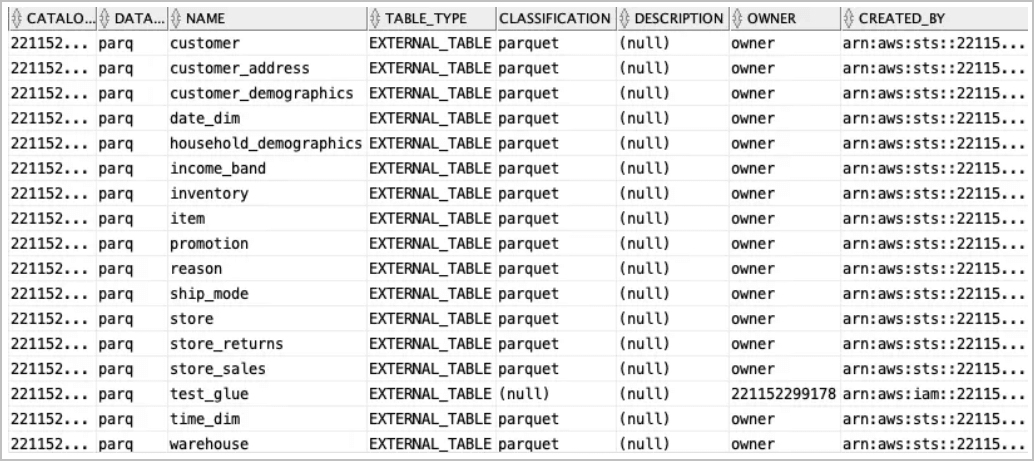
-
Synchronisieren Sie die autonome KI-Datenbank mit zwei Tabellen,
storeunditem, die in der Datenbankparqenthalten sind.begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /
-
-
Prüfen Sie neue Objekte in der autonomen KI-Datenbank, und führen Sie eine Abfrage auf S3 aus.
-
Mit SQL Developer können Sie neue Objekte anzeigen, die durch den vorherigen Synchronisierungsvorgang erstellt wurden.
Das Schema
GLUE$PARQ_TPCDS_ORACLE_PARQwurde automatisch durch den Prozeduraufrufdbms_dcat.run_syncgeneriert und benannt.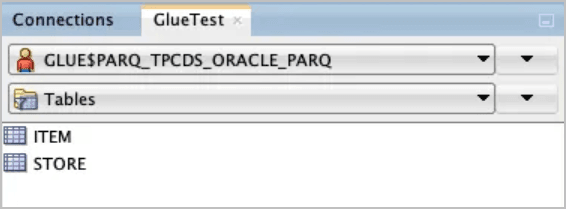
-
SQL-Abfrage über Datasetspeicher in Amazon S3 ausführen
SELECT * FROM glue$parq_tpcds_oracle_parq.store;
-