Tabellen in Oracle NoSQL Database Cloud Service entwerfen
Erfahren Sie, wie Sie Tabellen in Oracle NoSQL Database Cloud Service entwerfen und konfigurieren.
Dieser Artikel enthält die folgenden Themen:
Tabellenfelder
Erfahren Sie, wie Sie Daten unter Verwendung von Tabellenfeldern entwerfen und konfigurieren.
Eine Anwendung bietet die Möglichkeit, schemalose Tabellen zu verwenden, bei denen eine Zeile aus Schlüsselfeldern und einem einzelnen JSON-Datenfeld besteht. Eine schemalose Tabelle bietet Flexibilität hinsichtlich der Daten, die in einer Zeile gespeichert werden können.
Alternativ kann die Anwendung Tabellen mit festem Schema verwenden, bei denen sämtliche Tabellenfelder als bestimmte Typen definiert sind.
Tabellen mit festem Schema mit typisierten Daten bieten hinsichtlich Durchsetzung und Speichereffizienz höhere Sicherheit. Das Schema dieser Tabellen kann zwar bearbeitet werden, die Tabellenstruktur kann jedoch nicht einfach geändert werden. Eine schemalose Tabelle ist flexibel, und die Tabellenstruktur kann einfach geändert werden.
Schließlich kann eine Anwendung auch einen Hybrid-Datenmodellansatz verwenden, bei dem eine Tabelle Daten und JSON-Datenfelder eingegeben haben kann.
In den folgenden Beispielen wird veranschaulicht, wie Daten für alle drei Ansätze entworfen und konfiguriert werden.
Beispiel 1: Schemalose Tabelle entwerfen
Sie haben mehrere Möglichkeiten, Informationen zu Navigationsmustern in Ihrer Tabelle zu speichern. Eine Möglichkeit besteht darin, eine Tabelle zu definieren, die eine Cookie-ID als Schlüssel verwendet und Zielgruppensegmentierungsdaten als ein einzelnes JSON-Feld speichert.
// schema less, data is stored in a JSON field
CREATE TABLE audience_info (
cookie_id LONG,
audience_data JSON,
PRIMARY KEY(cookie_id))In diesem Fall kann die Tabelle audience_info ein JSON-Objekt enthalten. Beispiel:
{
"cookie_id": "",
"audience_data": {
"ipaddr" : "
10.0.00.xxx",
"audience_segment: {
"sports_lover" : "2018-11-30",
"book_reader" : "2018-12-01"
}
}
}Die Anwendung verfügt über ein Schlüsselfeld und ein Datenfeld für diese Tabelle. Das Feld audience_data ist so flexibel, dass beliebige Daten gespeichert werden können. Daher können Sie die verfügbaren Typen von Daten einfach ändern.
Beispiel 2: Tabelle mit festem Schema entwerfen
Sie können Informationen zu Navigationsmustern speichern, indem Sie Ihre Tabelle mit eindeutiger deklarierten Feldern erstellen:
// fixed schema, data is stored in typed fields.
CREATE TABLE audience_info(
cookie_id LONG,
ipaddr STRING,
audience_segment RECORD(sports_lover TIMESTAMP(9),
book_reader TIMESTAMP(9)),
PRIMARY KEY(cookie_id))In diesem Beispiel weist die Tabelle ein Schlüsselfeld und zwei Datenfelder auf. Ihre Daten sind kompakter, und Sie können sicherstellen, dass alle Datenfelder korrekt sind.
Beispiel 3: Hybridtabelle entwerfen
Sie können Informationen zu Navigationsmustern speichern, indem Sie sowohl typisierte Datenfelder als auch JSON-Datenfelder in der Tabelle verwenden.
// mixed, data is stored in both typed and JSON fields.
CREATE TABLE audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Primärschlüssel und Shard-Schlüssel
Erfahren Sie mehr über den Zweck von Primärschlüsseln und Shard-Schlüsseln beim Entwerfen Ihrer Anwendung.
Primärschlüssel und Shard-Schlüssel sind wichtige Elemente in Ihrem Schema. Mit ihnen können Sie Daten effizient aufrufen und verteilen. Sie erstellen Primärschlüssel und Shard-Schlüssel nur beim Erstellen einer Tabelle. Sie bleiben für die Lebensdauer der Tabelle erhalten und können nicht geändert oder gelöscht werden.
Primärschlüssel
Sie müssen beim Erstellen der Tabelle mindestens eine Primärschlüsselspalte angeben. Ein Primärschlüssel identifiziert jede Zeile in der Tabelle eindeutig. Bei einfachen CRUD-Vorgängen ruft Oracle NoSQL Database Cloud Service bestimmte Zeilen anhand ihres Primärschlüssels für Lese- oder Änderungsvorgänge ab. Angenommen, eine Tabelle enthält die folgenden Felder:
-
productName -
productType -
productLine
Erfahrungsgemäß ist der Produktname wichtig und für jede Zeile eindeutig. Sie legen also productName als Primärschlüssel fest. Anschließend rufen Sie die gewünschten Zeilen basierend auf productName ab. Verwenden Sie in einem solchen Fall eine Anweisung wie diese, um die Tabelle zu definieren.
/* Create a new table called users. */
CREATE TABLE if not exists myProducts
(
productName STRING,
productType STRING,
productLine INTEGER,
PRIMARY KEY (productName)
)"Shard-Schlüssel
Der Hauptzweck von Shard-Schlüsseln besteht in der Verteilung von Daten über das Oracle NoSQL Database Cloud Service-Cluster zwecks Verteilung und Positionierung von Datensätzen mit derselben Shard-Taste zwecks einfacher Referenz und schneller Zugriff lokal. Datensätze mit einem gemeinsamen Shard-Schlüssel werden am selben physischen Speicherort gespeichert und können atomar und effizient aufgerufen werden.
Das Design des Primärschlüssels und des Shard-Schlüssels hat Auswirkungen auf die Skalierung und die Erreichung des bereitgestellten Durchsatzes. Beispiel: Wenn Datensätze denselben Shard-Schlüssel verwenden, können Sie mehrere Tabellenzeilen in einem atomaren Vorgang löschen oder eine Teilmenge von Zeilen in der Tabelle in einem einzigen atomaren Vorgang abrufen. Optimal konzipierte Shard-Schlüssel ermöglichen nicht nur die Skalierung, sondern können auch die Performance verbessern, da weniger Zyklen erforderlich sind, um Daten einem einzelnen Shard zuzuweisen oder Daten aus einem einzelnen Shard abzurufen.
Angenommen, Sie geben drei Primärschlüsselfelder an:
PRIMARY KEY (productName, productType, productLine)Da Ihre Anwendung regelmäßig Abfragen mit den Spalten productName und productType ausführt, empfehlen es sich, diese Felder als Shard-Schlüssel anzugeben. Die Festlegung als Shard-Schlüssel stellt sicher, dass alle Zeilen für diese beiden Spalten im selben Shard gespeichert werden. Wenn es sich um keine Shard-Schlüssel handelt, könnten die am häufigsten abgefragten Spalten in einem beliebigen Shard gespeichert werden. Bei der Suche nach allen Zeilen für beide Felder muss in solch einem Fall der gesamte Datenspeicher anstatt nur ein einziges Shard gescannt werden.
Shard-Schlüssel legen die Speicherung im selben Shard fest, um effiziente Abfragen für Schlüsselwerte zu ermöglichen. Da Ihre Daten jedoch für eine optimale Performance auf die Shards verteilt werden sollen, müssen Sie Shard-Schlüssel vermeiden, die wenige eindeutige Werte aufweisen.
Hinweis: Wenn Sie beim Erstellen einer Tabelle keine Shard-Schlüssel angegeben haben, verwendet Oracle NoSQL Database Cloud Service die Primärschlüssel für die Shard-Organisation.
Wichtige Faktoren beim Auswählen eines Shard-Schlüssels
-
Kardinalität: Bei Feldern mit niedriger Kardinalität (z.B. Heimatland eines Benutzers) werden Datensätze in wenigen Shards gruppieren. Diese Shards erfordern ein häufiges Rebalancing der Daten, was die Wahrscheinlichkeit des Auftretens von Problemen aufgrund hochfrequentierter Shards erhöht. Stattdessen sollte jeder Shard-Schlüssel eine hohe Kardinalität haben, wobei der Shard-Schlüssel ein gleichmäßiges Segment von Datensätzen im Datensatz ausdrücken kann. Beispiel: ID-Nummern wie
customerID,userIDoderproductIDsind gute Kandidaten für einen Shard-Schlüssel. -
Atomizität: Nur Objekte, die den Shard-Schlüssel gemeinsam verwenden, können an einer Transaktion teilnehmen. Wenn Sie ACID-Transaktionen benötigen, die mehrere Datensätze umfassen, wählen Sie einen Shard-Schlüssel aus, mit dem Sie diese Anforderung erfüllen können.
Welche Best Practices sind zu befolgen?
-
Gleichmäßige Verteilung von Shard-Schlüsseln: Wenn Shard-Schlüssel gleichmäßig verteilt werden, wird die Kapazität des Systems nicht von einem einzelnen Shard begrenzt.
-
Abfrageisolation: Abfragen sollten auf ein bestimmtes Shard ausgerichtet werden, um die Effizienz und Performance zu maximieren. Wenn keine Isolation von Abfragen auf ein einzelnes Shard gegeben ist, wird die Abfrage auf alle Shards angewendet. Dies ist weniger effizient und erhöht die Abfragelatenz.
Unter Tabellen erstellen finden Sie Informationen zum Zuweisen von Primärschlüsseln und Shard-Schlüsseln mit dem TableRequest-Objekt.
Gültigkeitsdauer
Erfahren Sie, wie Sie Ablaufzeiten für Tabellen und Zeilen mithilfe des TTL-Features angeben.
In vielen Anwendungen werden Daten mit einer begrenzten Nutzungsdauer verwaltet. Die Gültigkeitsdauer (TTL) ist ein Verfahren, mit dem Sie einen Zeitrahmen für Tabellenzeilen festlegen können, nach welchem die Zeilen automatisch ablaufen und nicht mehr verfügbar sind. Sie gibt an, wie viel Zeit die Daten in Oracle NoSQL Database Cloud Service verbleiben dürfen. Daten mit erreichter Ablaufzeit können nicht mehr abgerufen werden und werden nicht mehr in Speicherstatistiken angezeigt.
Standardmäßig weist jede erstellte Tabelle einen TTL-Wert von null auf, das heißt, es wird keine Ablaufzeit angegeben. Sie können einen TTL-Wert beim Erstellen einer Tabelle deklarieren. Dabei geben Sie die Gültigkeitsdauer mit einer Zahl an, gefolgt von HOURS oder DAYS. Tabellenzeilen erben den TTL-Wert der Tabelle, in welcher sie enthalten sind, sofern Sie nicht explizit einen TTL-Wert für Tabellenzeilen festlegen. Wenn Sie den TTL-Wert einer Zeile festlegen, wird der TTL-Wert der Tabelle überschrieben. Wenn Sie den TTL-Wert der Tabelle ändern, nachdem für die Zeile ein TTL-Wert eingestellt wurde, wird der TTL-Wert der Zeile beibehalten.
Sie können den TTL-Wert für eine Tabellenzeile jederzeit aktualisieren, bevor die Ablaufzeit der Zeile erreicht wurde. Auf abgelaufene Daten kann nicht mehr zugegriffen werden. Das Verwenden von TTL-Werten ist somit effizienter als das manuelle Löschen von Zeilen, weil das Schreiben eines Datenbanklogeintrags für die Datenlöschung vermieden wird. Abgelaufene Daten werden nach dem Ablaufdatum vom Datenträger gelöscht.
Tabellenstatus und -lebenszyklen
Machen Sie sich mit den verschiedenen Tabellenstatus und deren Bedeutung vertraut (Tabellenlebenszyklusprozess).
Jede Tabelle durchläuft eine Reihe von unterschiedlichen Status von ihrer Erstellung bis zum Löschen. Beispiel: Eine Tabelle im Status DROPPING kann nicht in den Status ACTIVE versetzt werden. Eine Tabelle im Status ACTIVE hingegen kann in den Status UPDATING versetzt werden. Sie können die verschiedenen Tabellenstatus verfolgen, indem Sie den Tabellenlebenszyklus überwachen. In diesem Abschnitt werden die einzelnen Tabellenstatus beschrieben.
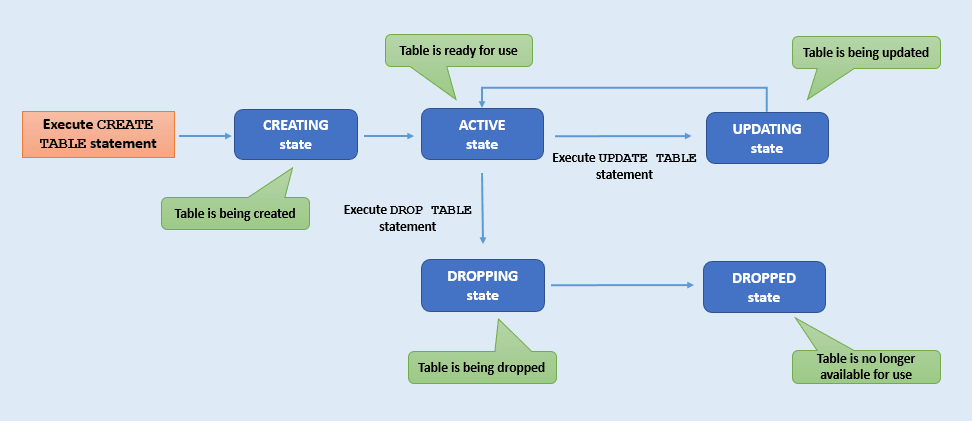
Beschreibung der Abbildung table-state.png
| Tabellenstatus | Beschreibung |
|---|---|
CREATING |
Die Tabelle wird gerade erstellt. Es ist nicht bereit zur Verwendung. |
UPDATING |
Die Tabelle wird gerade aktualisiert. Es sind keine weiteren Tabellenänderungen möglich, solange die Tabelle diesen Status aufweist. In folgenden Fällen befindet sich eine Tabelle im Status
|
ACTIVE |
Die Tabelle kann im aktuellen Status verwendet werden. Die Tabelle wurde möglicherweise vor Kurzem erstellt oder geändert, ihr Status ist jetzt jedoch stabil. |
DROPPING |
Die Tabelle wird gerade gelöscht und kann nicht aufgerufen werden (egal, zu welchem Zweck). |
DROPPED |
Die Tabelle wurde gelöscht und ist nicht mehr für Lese-, Schreib- oder Abfrageaktivitäten verfügbar. Hinweis: Nach dem Löschen können Sie eine neue Tabelle mit demselben Namen erneut erstellen. |
Tabellenhierarchien
Mit Oracle NoSQL Database können Tabellen in einer Parent-Child-Beziehung vorhanden sein. Dies wird als Tabellenhierarchien bezeichnet.
Mit der Anweisung zum Erstellen von Tabellen kann eine Tabelle als untergeordnetes Element einer anderen Tabelle erstellt werden, die dann zum übergeordneten Element der neuen Tabelle wird. Dazu wird ein zusammengesetzter Name (name_path) für die untergeordnete Tabelle verwendet. Ein zusammengesetzter Name besteht aus einer Zahl N (N > 1) von Bezeichnern, die durch Punkte getrennt sind. Der letzte Bezeichner ist der lokale Name der untergeordneten Tabelle, und die ersten N-1 Bezeichner verweisen auf den Namen des übergeordneten Bezeichners.
Eigenschaften von übergeordneten/untergeordneten Tabellen:
-
Eine untergeordnete Tabelle erbt die Primärschlüsselspalten der übergeordneten Tabelle.
-
Alle Tabellen in der Hierarchie haben dieselben Shard-Schlüsselspalten, die in der Anweisung create table der Root-Tabelle angegeben sind.
-
Eine übergeordnete Tabelle kann nicht gelöscht werden, bevor ihre untergeordneten Tabellen gelöscht werden.
-
Ein referenzielles Integritäts-Constraint wird in einer übergeordneten/untergeordneten Tabelle nicht durchgesetzt.
Sie sollten die Verwendung von untergeordneten Tabellen in Betracht ziehen, wenn eine Form der Datennormalisierung erforderlich ist. Untergeordnete Tabellen können auch bei der Modellierung von 1-zu-N-Beziehungen eine gute Wahl sein. Außerdem können sie eine ACID-Transaktionssemantik bereitstellen, wenn mehrere Datensätze in einer übergeordneten/untergeordneten Hierarchie geschrieben werden.