Hinweis:
- Dieses Tutorial erfordert Zugriff auf Oracle Cloud. Informationen zum Anmelden für einen kostenlosen Account finden Sie unter Erste Schritte mit Oracle Cloud Infrastructure Free Tier.
- Es verwendet Beispielwerte für Oracle Cloud Infrastructure-Zugangsdaten, -Mandanten und -Compartments. Wenn Sie Ihre Übung abgeschlossen haben, ersetzen Sie diese Werte durch die Werte, die für Ihre Cloud-Umgebung spezifisch sind.
Verbindung von Alteryx mit Oracle Big Data Service Hive mit ODBC und Kerberos herstellen
Einführung
Oracle Big Data Service ist ein cloud-basierter Service von Oracle, mit dem Benutzer Hadoop-Cluster, Spark-Cluster und andere Big Data-Services erstellen und verwalten können. Standardmäßig verwendet ein Oracle Big Data Service-Cluster einfache Authentifizierungsverfahren wie Benutzername und Kennwort zur Authentifizierung von Benutzern und Services. Dies reicht jedoch möglicherweise nicht für Unternehmen aus, die ein höheres Sicherheitsniveau benötigen.
Die Kerberos-Authentifizierung ist ein weit verbreitetes Verfahren zur Sicherung verteilter Computing-Systeme. Sie bietet eine sichere Möglichkeit zur Authentifizierung von Benutzern und Services, sodass sie sicher über ein Netzwerk kommunizieren können. In einer Kerberos-fähigen Umgebung werden Benutzer und Services mit kryptografischen Schlüsseln ausgegeben, mit denen ihre Identität geprüft und der Zugriff auf Ressourcen autorisiert wird.
Die Kerberos-Authentifizierung bietet zusätzliche Sicherheit für ein Oracle Big Data Service-Cluster, indem eine starke Authentifizierung und Verschlüsselung zwischen Knoten ermöglicht wird.
Ziele
Erfahren Sie, wie Sie eine nahtlose Verbindung zwischen Alteryx und Oracle Big Data Service Hive in einem kerberisierten Cluster herstellen. Durch die Implementierung der Kerberos-Authentifizierung können wir eine sichere Umgebung für die Datenverarbeitung und -analyse sicherstellen.
- Erfahren Sie, wie Sie das Oracle Big Data Service-Cluster kerberisieren
- Erfahren Sie, wie Sie Alteryx mit Oracle Big Data Service Hive verbinden
Voraussetzungen
Ein Oracle Big Data Service-Cluster, das auf Oracle Cloud Infrastructure (OCI) ausgeführt wird, wobei die erforderlichen Services konfiguriert sind und Ports geöffnet werden.
Hinweis: In einem hochverfügbaren (HA-)Oracle Big Data Service-Cluster ist Kerberos installiert. Wenn Sie ein Nicht-HA-Cluster verwenden möchten, benötigen Sie die folgende Liste der Voraussetzungen.
-
Ein Kerberos Key Distribution Center-(KDC-) und Kerberos-Admin-Server. Sie können das KDC und den Admin-Server auf einem separaten Server installieren und konfigurieren oder das von Ihrer Organisation bereitgestellte KDC und den Admin-Server verwenden.
-
Das Utility
kadmin, mit dem Kerberos-Principals und -Keytabs erstellt und verwaltet werden. -
Das Utility
kinit, mit dem ein Kerberos-Ticket-Ganting-Ticket (TGT) für einen Benutzer oder einen Service-Principal abgerufen wird. -
Das Utility
klist, mit dem die Tickets im Zugangsdatencache eines Benutzer- oder Service-Principals aufgelistet werden. -
Ein Windows-Rechner mit Alteryx installiert. Für die Implementierung in diesem Tutorial haben wir die Testversion von Alteryx verwendet.
-
MIT Kerberos.
-
Der auf Ihrem Rechner installierte ODBC-Treiber.
-
Die erforderlichen Kerberos-Principals und -Keytabs für Ihr Oracle Big Data Service-Cluster. Weitere Details dazu finden Sie in den folgenden Abschnitten.
-
Zugriff auf das ODBC-Datenquellenadministratortool auf Ihrem Rechner.
Hinweis: In diesem Tutorial wird ein Oracle Big Data Service-HA-Cluster verwendet. Außerdem sollten Sie sich mit folgenden Konzepten und Terminologien vertraut machen:
-
Kerberos-Principals: Eine Entity, die vom Kerberos-System authentifiziert wird. Principals können Benutzer oder Services sein.
-
Keytabs: Eine Datei, die den Secret Key eines Principals enthält. Keytabs werden von Services zur Authentifizierung beim KDC verwendet.
-
Realms: Eine Kerberos-Realm ist eine Sammlung von Kerberos-Principals, die eine gemeinsame KDC-Datenbank verwenden.
-
Authentifizierung: Der Prozess zur Prüfung der Identität eines Benutzer- oder Service-Principals.
-
Autorisierung: Der Prozess zur Bestimmung, auf welche Ressourcen ein Benutzer oder ein Service-Principal zugreifen darf.
Aufgabe 1: Oracle Big Data Service-Cluster kern
-
Melden Sie sich über einen
SSH-Befehl beim Masterknoten des Oracle Big Data Service-Clusters an, oder verwenden Sie putty mit der Dateippkmit den Benutzerzugangsdatenopc. Nachdem Sie sich angemeldet haben, heben Sie die Berechtigungen an den Benutzerroot. In diesem Tutorial haben wir Putty für die Anmeldung bei den Knoten verwendet. -
Stoppen Sie alle ausgeführten Hadoop- und Spark-Services mit Ambari.

-
Erstellen Sie das Kerberos-Principal für den
bdsuser-Administrator, indem Sie die folgenden Schritte ausführen.-
Geben Sie die Eingabeaufforderung
Kadminmit dem BefehlKadmin.localein. -
Führen Sie an der Eingabeaufforderung
kadmin.localden Befehladdprincaus, um einen neuen Kerberos-Principal mit dem Namenbdsuserzu erstellen. Wenn Sie dazu aufgefordert werden, wählen Sie ein Kennwort für Ihre Voreinstellung aus, und bestätigen Sie es.
-
Geben Sie
exitein, um zur ursprünglichen Eingabeaufforderung zurückzukehren. Standardmäßig ist die hier verwendete Realm auskrb5.confausgewählt. Sie können die Realm jedoch anpassen, indem Sie die Konfiguration aktualisieren.
-
-
Erstellen Sie eine Gruppe
bdsusergroup, indem Sie den Befehldcli -C "groupadd bdsusergroupausführen. -
Geben Sie in der Eingabeaufforderung den Befehl
dcli -C "useradd -g bdsusergroup -G hdfs,hadoop,hive bdsuser"ein, um den Administratorbenutzerbdsuserzu erstellen und ihn den aufgelisteten Gruppen auf jedem Knoten im Cluster hinzuzufügen. -
Verwenden Sie den linux-Befehl
id, um die Erstellung vonbdsuserzu bestätigen und die Gruppenmitgliedschaft aufzulisten. -
Starten Sie alle Oracle Big Data Service-Services mit Ambari.

-
Testen Sie
bdsuser, indem Sie das Kerberos-Ticket mit dem Befehlkinit bdsusergenerieren und Dateien mit dem Befehlhadoop fs -ls /auflisten.
Aufgabe 2: Alteryx mit Oracle Big Data Service Hive verbinden
Wir haben die Kerberisierung des Oracle Big Data Service-Clusters untersucht. Jetzt lernen wir, Alteryx mit dem Kerberized Oracle Big Data Service Hive mit dem ODBC-Treiber zu verbinden.
Um das volle Potenzial Ihrer Oracle Big Data Service Hive-Daten auszuschöpfen, ist es wichtig, eine Verbindung zu Ihren bevorzugten Tools herzustellen. In diesem Abschnitt werden Sie durch den Prozess der Verbindung von Alteryx mit Oracle Big Data Service Hive geführt. Dazu konfigurieren wir eine ODBC-Verbindung, die Kerberos-Authentifizierung verwendet.
-
Konfigurieren Sie MIT Kerberos wie folgt:
-
Kopieren Sie die Datei
krb5.confundkrb5.keytabaus dem Masterknoten des Clusters inC:\Program Files\MIT\Kerberos. -
Ändern Sie die Dateierweiterung für die Windows-Kompatibilität von
.confin.ini. -
Erstellen Sie einen neuen Ordner
C:/temp(Ordner und Pfad können beliebig sein). -
Richten Sie die folgende Umgebungsvariable ein.

-
Führen Sie den Befehl
Kinit bdsuseraus der Eingabeaufforderung aus, um das Kerberos-Setup zu prüfen und das Ticket zu generieren.
-
-
Installieren Sie den ODBC-Treiber auf Ihrem Windows-Rechner. Befolgen Sie die Anweisungen zur Installation des Treibers.
-
Konfigurieren Sie den ODBC-Treiber wie folgt:
-
Erstellen Sie DNS- und IP-Einträge in der Hostdatei
C:\Windows\System32\drivers\etcfür den Master- und Utilityknoten.
-
Testen Sie die Hosts-Dateieinträge mit dem Befehl
ping.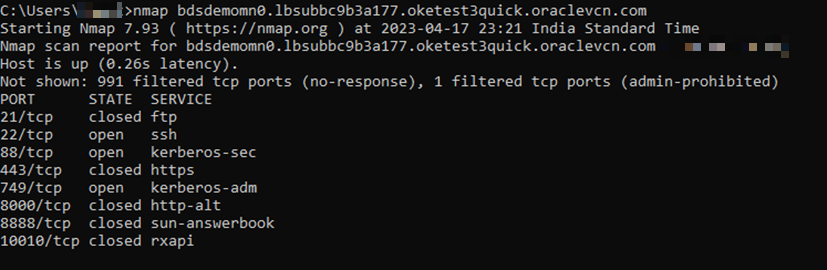
-
-
Öffnen Sie das ODBC-Datenquellenadministratortool auf Ihrem Rechner, und führen Sie die folgenden Schritte aus.
-
Wählen Sie die Registerkarte "System DSN". Klicken Sie auf Hinzufügen und auswählen für den Cloudera-ODBC-Treiber für Apache Hive, und klicken Sie dann auf Fertigstellen.

-
Folgen Sie dem folgenden Screenshot für die Hive-Verbindungskonfiguration.

-
Klicken Sie auf Testen, um die Konnektivität zu prüfen. Wenn alles korrekt eingerichtet ist, sollte eine Meldung angezeigt werden, dass der Test erfolgreich war. Klicken Sie auf OK, um die Einstellung zu speichern.

-
-
Öffnen Sie Alteryx, und führen Sie die folgenden Schritte aus.
-
Gehen Sie zu Datei, wählen Sie Verbindung verwalten aus, und klicken Sie auf Datenquelle hinzufügen. Wählen Sie unter den verfügbaren Technologieoptionen Hive aus.

-
Nachdem Sie die Technologieoption ausgewählt haben, werden Sie zum nächsten Bildschirm aufgefordert, auf dem Sie den DSN-Namen angeben müssen. Wählen Sie den ODBC-DSN aus, den Sie im vorherigen Schritt erstellt haben, und klicken Sie auf Speichern.

-
Die Verbindung wurde eingerichtet. Erstellen Sie jetzt einen Beispielworkflow, um die Daten aus Hive zu lesen. Um einen Beispielworkflow zu erstellen, klicken Sie auf Neuer Workflow, und verschieben Sie die Eingabedatenaufgabe per Drag-and-Drop.

-
Wählen Sie in der Verbindungsliste Hive ODBC aus.

-
Wählen Sie die Hive-Tabelle aus, um Daten abzurufen.

-
Führen Sie den Workflow aus. Sie können sehen, dass Alteryx erfolgreich Daten aus Oracle Big Data Service Hive abrufen kann.

-
Nächste Schritte
Die Kerberos-Authentifizierung ist eine wesentliche Komponente eines sicheren Hadoop-Clusters. Durch das Kerberisieren Ihres Oracle Big Data Service-Clusters können Sie Ihre sensiblen Daten und Anwendungen besser vor unberechtigten Zugriffen schützen. Während der Prozess der Kerberisierung Ihres Clusters eine Herausforderung sein kann, kann eine sorgfältige Planung und ausführliche Aufmerksamkeit dazu beitragen, eine erfolgreiche Implementierung sicherzustellen. Außerdem kann es schwierig sein, Alteryx mit Oracle Big Data Service Hive über die ODBC- und Kerberos-Authentifizierung zu verbinden. Sobald die Authentifizierung eingerichtet ist, verfügen Sie über Alteryx zum Analysieren und Visualisieren Ihrer Oracle Big Data Service-Daten. Wenn Sie die in diesem Tutorial beschriebenen Schritte befolgen, sollten Sie die Verbindung einfach einrichten können.
Bei Problemen können Sie Fehler beheben. Durch ein wenig Persistenz können Sie Alteryx mit Oracle Big Data Service Hive verbinden und das volle Potenzial Ihrer Daten erschließen.
Verwandte Links
Danksagungen
- Autoren - Pavan Upadhyay (Principal Cloud Engineer), Saket Bihari (Principal Cloud Engineer)
Weitere Lernressourcen
Sehen Sie sich andere Übungen zu docs.oracle.com/learn an, oder greifen Sie auf weitere kostenlose Lerninhalte im Oracle Learning YouTube-Kanal zu. Besuchen Sie außerdem die Website education.oracle.com/learning-explorer, um Oracle Learning Explorer zu werden.
Produktdokumentation finden Sie im Oracle Help Center.
Connect Alteryx to Oracle Big Data Service Hive Using ODBC and Kerberos
F85222-01
August 2023
Copyright © 2023, Oracle and/or its affiliates.