Hinweis:
- Dieses Tutorial erfordert Zugriff auf Oracle Cloud. Informationen zum Anmelden für einen kostenlosen Account finden Sie unter Erste Schritte mit Oracle Cloud Infrastructure Free Tier.
- Es verwendet Beispielwerte für Oracle Cloud Infrastructure-Zugangsdaten, -Mandanten und -Compartments. Wenn Sie Ihre Übung abgeschlossen haben, ersetzen Sie diese Werte durch die Werte, die für Ihre Cloud-Umgebung spezifisch sind.
Verwenden Sie OCI Data Flow mit Apache Spark Streaming, um ein Kafka-Thema in einer skalierbaren und nahezu Echtzeitanwendung zu verarbeiten
Einführung
Oracle Cloud Infrastructure (OCI) Data Flow ist ein verwalteter Service für das Open-Source-Projekt mit dem Namen Apache Spark. Mit Spark können Sie es im Wesentlichen für umfangreiche Verarbeitungsdateien, Streaming- und Datenbankvorgänge verwenden. Sie können Anwendungen mit sehr hoch skalierbarer Verarbeitung erstellen. Spark kann geclusterte Rechner skalieren und verwenden, um Jobs mit minimaler Konfiguration zu paralellisieren.
Mit Spark als verwalteter Service (Data Flow) können Sie viele skalierbare Services hinzufügen, um die Leistungsfähigkeit der Cloud-Verarbeitung zu erhöhen. Data Flow kann Spark Streaming verarbeiten.
Streaming-Anwendungen erfordern eine kontinuierliche Ausführung für einen langen Zeitraum, der häufig über 24 Stunden hinausgeht und so lange wie Wochen oder sogar Monate dauern kann. Bei unerwarteten Fehlern müssen Streaminganwendungen vom Point of Failure neu gestartet werden, ohne falsche Berechnungsergebnisse zu erzeugen. Data Flow erfasst mit strukturiertem Spark-Streaming-Checkpointing den verarbeiteten Offset, der in Ihrem Object Storage-Bucket gespeichert werden kann.
Hinweis: Wenn Sie Daten als Batchstrategie verarbeiten müssen, können Sie den folgenden Artikel lesen: Große Dateien in Autonomous Database und Kafka mit Oracle Cloud Infrastructure Data Flow verarbeiten

In diesem Tutorial werden die häufigsten Aktivitäten zum Verarbeiten von Daten-Volume-Streaming angezeigt, Sie können Datenbanken abfragen und die Daten zusammenführen/verknüpfen, um eine andere Tabelle im Speicher zu bilden, oder Daten nahe an ein beliebiges Ziel senden. Sie können diese massiven Daten in Ihre Datenbank und in eine Kafka-Warteschlange mit sehr kostengünstiger und sehr effektiver Performance schreiben.
Ziele
- Erfahren Sie, wie Sie mit Data Flow große Datenmengen in einer skalierbaren und nahezu Echtzeitanwendung verarbeiten können.
Voraussetzungen
-
Ein betriebsbereiter Oracle Cloud-Mandant: Sie können einen kostenlosen Oracle Cloud-Account mit 300,00 USD pro Monat erstellen, um dieses Tutorial auszuprobieren. Siehe Kostenlosen Oracle Cloud-Account erstellen
-
OCI CLI (Oracle Cloud-Befehlszeilenschnittstelle) wird auf Ihrem lokalen Rechner installiert: Dies ist der Link zur Installation der OCI-CLI.
-
Eine auf Ihrem lokalen Rechner installierte Apache Spark-Anwendung. In Oracle Cloud Infrastructure Data Flow-Anwendungen lokal entwickeln und in der Cloud bereitstellen wird beschrieben, wie Sie lokal und in Data Flow entwickeln.
Hinweis: Dies ist die offizielle Seite für die Installation: Apache Spark. Es gibt alternative Verfahren zur Installation von Apache Spark für jede Art von Betriebssystem (Linux/Mac OS/Windows).
-
Spark Submit CLI ist installiert. Dies ist der Link zur Installation von Spark Submit CLI.
-
Maven ist auf Ihrem lokalen Rechner installiert.
-
Kenntnisse der OCI-Konzepte:
- Compartments
- IAM-Policys
- Mandant
- OCID Ihrer Ressourcen
Aufgabe 1: Object Storage-Struktur erstellen
Object Storage wird als Standarddatei-Repository verwendet. Sie können andere Typen von Datei-Repositorys verwenden. Object Storage ist jedoch eine einfache und kostengünstige Möglichkeit, Dateien mit Performance zu bearbeiten. In diesem Tutorial laden beide Anwendungen eine große CSV-Datei aus dem Objektspeicher und zeigen, wie Apache Spark schnell und intelligent ein hohes Datenvolumen verarbeiten kann.
-
Compartment erstellen: Compartments sind wichtig, um Ihre Cloud-Ressourcen zu organisieren und zu isolieren. Sie können Ihre Ressourcen nach IAM-Policys isolieren.
-
Mit diesem Link können Sie die Policys für Compartments verstehen und einrichten: Compartments verwalten
-
Erstellen Sie ein Compartment, in dem alle Ressourcen der 2 Anwendungen in diesem Tutorial gehostet werden. Erstellen Sie ein Compartment mit dem Namen Analytics.
-
Gehen Sie zum Hauptmenü von Oracle Cloud, und suchen Sie nach: Identität und Sicherheit, Compartments. Klicken Sie im Abschnitt "Compartments" auf Compartment erstellen, und geben Sie den Namen ein.

Hinweis: Sie müssen einer Benutzergruppe den Zugriff erteilen und Ihren Benutzer einschließen.
-
Klicken Sie auf Compartment erstellen, um das Compartment einzuschließen.
-
-
Erstellen Sie den Bucket in Object Storage: Buckets sind logische Container zum Speichern von Objekten. Daher werden alle für diese Demo verwendeten Dateien in diesem Bucket gespeichert.
-
Gehen Sie zum Hauptmenü von Oracle Cloud, und suchen Sie nach Speicher und Buckets. Wählen Sie im Abschnitt "Buckets" das zuvor erstellte Compartment (Analyse) aus.

-
Klicken Sie auf Bucket erstellen. Erstellen Sie 4 Buckets: Apps, Daten, Datenflusslogs, Wallet

-
Geben Sie die Informationen zum Bucket-Namen mit diesen 4 Buckets ein, und verwalten Sie die anderen Parameter mit der Standardauswahl.
-
Klicken Sie für jeden Bucket auf Erstellen. Die erstellten Buckets werden angezeigt.

-
Hinweis: Prüfen Sie die IAM-Policys für den Bucket. Sie müssen die Policys einrichten, wenn Sie diese Buckets in Ihren Demoanwendungen verwenden möchten. Die Konzepte und das Setup finden Sie hier: Überblick über Object Storage und IAM-Policys.
Aufgabe 2: Autonomous Database erstellen
Oracle Cloud Autonomous Database ist ein verwalteter Service für Oracle Database. In diesem Tutorial stellen die Anwendungen aus Sicherheitsgründen eine Verbindung zur Datenbank her.
-
Instanziieren Sie Autonomous Database wie hier beschrieben: Autonomous Database bereitstellen.
-
Wählen Sie im Hauptmenü von Oracle Cloud die Option Data Warehouse aus, wählen Sie Oracle Database und Autonomous Data Warehouse aus. Wählen Sie Ihre Compartment-Analyse aus, und folgen Sie dem Tutorial zum Erstellen der Datenbankinstanz.
-
Benennen Sie die Instanz mit verarbeiteten Logs, und wählen Sie Logs als Datenbanknamen aus. Sie müssen keinen Code in den Anwendungen ändern.
-
Geben Sie das ADMIN-Kennwort ein, und laden Sie die Wallet-ZIP-Datei herunter.

-
Nachdem Sie die Datenbank erstellt haben, können Sie das ADMIN-Benutzerkennwort einrichten und die ZIP-Datei Wallet herunterladen.



-
Speichern Sie die Wallet-ZIP-Datei (
Wallet_logs.zip), und annotieren Sie Ihr ADMIN-Kennwort. Sie müssen den Anwendungscode einrichten. -
Gehen Sie zu Speicher, Buckets. Wechseln Sie in das Compartment analytics, und der Bucket Wallet wird angezeigt. Klicken Sie darauf.
-
Um die Wallet-ZIP-Datei hochzuladen, klicken Sie einfach auf Hochladen, und hängen Sie die Datei Wallet_logs.zip an.

Hinweis: Prüfen Sie IAM-Policys für den Zugriff auf Autonomous Database hier: IAM-Policy für Autonomous Database
Aufgabe 3: CSV-Beispieldateien hochladen
Um die Leistungsfähigkeit von Apache Spark zu demonstrieren, lesen die Anwendungen eine CSV-Datei mit 1.000.000 Zeilen. Diese Daten werden mit nur einer Befehlszeile in die Autonomous Data Warehouse-Datenbank eingefügt und auf einem Kafka-Streaming (Oracle Cloud Streaming) veröffentlicht. All diese Ressourcen sind skalierbar und perfekt für ein hohes Datenvolumen geeignet.
-
Laden Sie diese 2 Links herunter, und laden Sie sie in den Bucket Daten hoch:
-
Hinweis:
- organizations.csv hat nur 100 Zeilen, nur um die Anwendungen auf Ihrem lokalen Rechner zu testen.
- organizations1M.csv enthält 1.000.000 Zeilen und wird zur Ausführung in der Data Flow-Instanz verwendet.
-
Gehen Sie im Hauptmenü von Oracle Cloud zu Speicher und Buckets. Klicken Sie auf den Bucket Daten, und laden Sie die 2 Dateien aus dem vorherigen Schritt hoch.


-
Auxiliary-Tabelle in ADW-Datenbank hochladen
-
Laden Sie diese Datei herunter, um sie in die ADW-Datenbank hochzuladen: GDP PER CAPTA COUNTRY.csv
-
Wählen Sie im Oracle Cloud-Hauptmenü die Option Oracle Database und Autonomous Data Warehouse aus.
-
Klicken Sie auf die Instanz Verarbeitete Logs, um die Details anzuzeigen.
-
Klicken Sie auf Datenbankaktionen, um zu den Datenbank-Utilitys zu gehen.

-
Geben Sie Ihre Zugangsdaten für den ADMIN-Benutzer ein.

-
Klicken Sie auf die Option SQL, um zu den Abfrageutilitys zu navigieren.

-
Klicken Sie aufDataload.

-
Löschen Sie die Datei GDP PER CAPTA COUNTRY.csv in den Konsolenbereich, und importieren Sie die Daten in eine Tabelle.

-
Die neue Tabelle GDPPERCAPTA wurde erfolgreich importiert.

Aufgabe 4: Secret Vault für Ihr ADW-ADMIN-Kennwort erstellen
Aus Sicherheitsgründen wird das ADW ADMIN-Kennwort in einem Vault gespeichert. Oracle Cloud Vault kann dieses Kennwort mit Sicherheit hosten und mit OCI-Authentifizierung auf Ihre Anwendung zugreifen.
-
Erstellen Sie das Secret in einem Vault, wie in der folgenden Dokumentation beschrieben: Datenbank-Admin-Kennwort zu Vault hinzufügen
-
Erstellen Sie eine Variable mit dem Namen PASSWORD_SECRET_OCID in Ihren Anwendungen, und geben Sie die OCID ein.



Hinweis: Prüfen Sie die IAM-Policy für OCI Vault hier: OCI Vault-IAM-Policy.
Aufgabe 5: Kafka-Streaming erstellen (Oracle Cloud Streaming)
Oracle Cloud Streaming ist ein Kafka-ähnlicher verwalteter Streaming-Service. Sie können Anwendungen mit den Kafka-APIs und den gängigen SDKs entwickeln. In diesem Tutorial erstellen Sie eine Instanz von Streaming und konfigurieren diese für die Ausführung in beiden Anwendungen für die Veröffentlichung und Nutzung großer Datenmengen.
-
Gehen Sie im Hauptmenü von Oracle Cloud zu Analysen und KI, Streams.
-
Ändern Sie das Compartment in Analytics. Jede Ressource in dieser Demo wird in diesem Compartment erstellt. Dies ist sicherer und einfacher, IAM zu kontrollieren.
-
Klicken Sie auf Stream erstellen.

-
Geben Sie den Namen als kafka_like ein (Beispiel): Sie können alle anderen Parameter mit den Standardwerten verwalten.

-
Klicken Sie auf Erstellen, um die Instanz zu initialisieren.
-
Warten Sie auf den Status Active. Jetzt können Sie die Instanz verwenden.
Hinweis: Beim Erstellen des Streams können Sie die Option Standard-Streampool automatisch erstellen auswählen, um den Standardpool automatisch zu erstellen.
-
Klicken Sie auf den Link DefaultPool.

-
Zeigen Sie die Verbindungseinstellung an.


-
Notieren Sie diese Informationen, wie Sie sie im nächsten Schritt benötigen.
Hinweis: Prüfen Sie die IAM-Policys für das OCI-Streaming hier: IAM-Policy für OCI Streaming.
Aufgabe 6: AUTH TOKEN für den Zugriff auf Kafka generieren
Sie können auf OCI Streaming (Kafka-API) und andere Ressourcen in Oracle Cloud mit einem Authentifizierungstoken zugreifen, das Ihrem Benutzer in OCI IAM zugeordnet ist. In den Kafka-Verbindungseinstellungen enthalten die SASL-Verbindungszeichenfolgen einen Parameter namens password und einen AUTH_TOKEN-Wert, wie in der vorherigen Aufgabe beschrieben. Um den Zugriff auf OCI Streaming zu aktivieren, müssen Sie zu Ihrem Benutzer in der OCI-Konsole gehen und einen AUTH TOKEN erstellen.
-
Gehen Sie im Oracle Cloud-Hauptmenü zu Identität und Sicherheit, Benutzer.
Hinweis: Beachten Sie, dass der Benutzer, den Sie zum Erstellen von AUTH TOKEN benötigen, der mit Ihrer OCI CLI-Konfiguration und allen IAM-Policys-Konfiguration für die bisher erstellten Ressourcen konfiguriert ist. Die Ressourcen sind:
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloud-Streaming
- Oracle Object Storage
- Oracle-Datenfluss
-
Klicken Sie auf Ihren Benutzernamen, um die Details anzuzeigen.

-
Klicken Sie auf der linken Seite der Konsole auf die Option Authentifizierungstoken, und klicken Sie auf Token generieren.
Hinweis: Das Token wird nur in diesem Schritt generiert und wird nach Abschluss des Schritts nicht mehr angezeigt. Kopieren Sie den Wert, und speichern Sie ihn. Wenn Sie den Tokenwert verlieren, müssen Sie das Authentifizierungstoken erneut generieren.


Aufgabe 7: Demoanwendung einrichten
Dieses Tutorial enthält eine Demoanwendung, für die wir die erforderlichen Informationen einrichten.
- DataflowSparkStreamDemo: Diese Anwendung stellt eine Verbindung zum Kafka-Streaming her und verbraucht alle Daten und führt sie mit einer ADW-Tabelle namens GDPPERCAPTA zusammen. Die Streamdaten werden mit GDPPERCAPTA zusammengeführt und werden als CSV-Datei gespeichert, können aber einem anderen Kafka-Thema angezeigt werden.
-
Laden Sie die Anwendung mit dem folgenden Link herunter:
-
Suchen Sie die folgenden Details in Ihrer Oracle Cloud-Konsole:
-
Mandanten-Namespace


-
Kennwort-Secret
-
Streaming-Verbindungseinstellungen
-
Authentifizierungstoken
-
-
Öffnen Sie die heruntergeladene ZIP-Datei (
Java-CSV-DB.zipundJavaConsumeKafka.zip). Gehen Sie zum Ordner /src/main/java/example, und suchen Sie den Code Example.java.
Dabei handelt es sich um die Variablen, die mit den Werten der Mandantenressourcen geändert werden müssen.
VARIABLENNAME RESSOURCENNAME INFORMATIONSTITEL bootstrapServers Streaming-Verbindungseinstellungen Bootstrap-Server streamPoolId Streaming-Verbindungseinstellungen Wert ocid1.streampool.oc1.iad..... in SASL-Verbindungszeichenfolge kafkaUsername Streaming-Verbindungseinstellungen Wert von usename in " " in SASL-Verbindungszeichenfolge kafkaPassword Authentifizierungstoken Der Wert wird nur im Erstellungsschritt angezeigt OBJECT_STORAGE_NAMESPACE MANDANTEN-NAMESPACE MANDANT NAMENSRAUM MANDANTEN-NAMESPACE MANDANT PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
Hinweis: Alle für diese Demo erstellten Ressourcen befinden sich in der Region "US-ASHBURN-1". Prüfen Sie, in welcher Region Sie arbeiten möchten. Wenn Sie die Region ändern, müssen Sie 2 Punkte in 2 Codedateien ändern:
Example.java: Ändern Sie die Variable bootstrapServers, und ersetzen Sie "us-ashburn-1" durch die neue Region
OboTokenClientConfigurator.java: Ändern Sie die Variable CANONICAL_REGION_NAME mit der neuen Region.
Aufgabe 8: Java-Code verstehen
Dieses Tutorial wurde in Java erstellt, und dieser Code kann auch in Python portiert werden. Um die Effizienz und Skalierbarkeit zu beweisen, wurde die Anwendung entwickelt, um einige Möglichkeiten in einem gemeinsamen Anwendungsfall eines Integrationsprozesses zu zeigen. Der Code für die Anwendung zeigt also die folgenden Beispiele an:
- Stellen Sie eine Verbindung zum Kafka-Stream her, und lesen Sie die Daten
- JOINS mit einer ADW-Tabelle verarbeiten, um nützliche Informationen zu erstellen
- Eine CSV-Datei mit allen nützlichen Informationen aus Kafka ausgeben
Diese Demo kann auf Ihrem lokalen Rechner ausgeführt und in der Data Flow-Instanz bereitgestellt werden, um sie als Jobausführung auszuführen.
Hinweis: Verwenden Sie für Data Flow-Jobs und Ihren lokalen Rechner die OCI-CLI-Konfiguration, um auf die OCI-Ressourcen zuzugreifen. Auf der Data Flow-Seite ist alles vorkonfiguriert, sodass die Parameter nicht geändert werden müssen. Auf der Seite Ihres lokalen Rechners müssen Sie die OCI-CLI installiert und den Mandanten-, Benutzer- und Private Key für den Zugriff auf Ihre OCI-Ressourcen konfiguriert haben.
Zeigen Sie den Example.java-Code in Abschnitten an:
-
Apache Spark-Initialisierung: Dieser Teil des Codes stellt die Spark-Initialisierung dar. Viele Parameter zur Ausführung von Ausführungsprozessen werden automatisch konfiguriert. Daher ist es sehr einfach, mit der Spark-Engine zu arbeiten. Die Initialisierung unterscheidet sich, wenn Sie innerhalb des Datenflusses oder auf dem lokalen Rechner ausgeführt werden. Wenn Sie sich in Data Flow befinden, müssen Sie die ADW-Wallet-ZIP-Datei nicht laden. Die Aufgabe zum Laden, Dekomprimieren und Lesen der Wallet-Dateien wird in der Data Flow-Umgebung automatisch ausgeführt. Auf dem lokalen Rechner müssen jedoch einige Befehle ausgeführt werden.

-
Lesen Sie das ADW Vault Secret: Dieser Teil des Codes greift auf Ihren Vault zu, um das Secret für Ihre Autonomous Data Warehouse-Instanz abzurufen.

-
ADW-Tabelle abfragen: In diesem Abschnitt wird gezeigt, wie eine Abfrage in einer Tabelle ausgeführt wird.

-
Kafka-Vorgänge: Dies ist die Vorbereitung für die Verbindung zu OCI Streaming mit der Kafka-API.
Hinweis: Oracle Cloud Streaming ist mit den meisten Kafka-APIs kompatibel.

Es gibt einen Prozess zum Parsen der JSON-Daten aus dem Thema Kafka in ein Dataset mit der richtigen Struktur (Organisations-ID, Name, Land).
-
Daten aus einem Kafka-Dataset und Autonomous Data Warehouse-Dataset zusammenführen: In diesem Abschnitt wird gezeigt, wie eine Abfrage mit 2 Datensets ausgeführt wird.

-
Ausgabe in einer CSV-Datei: So generiert die zusammengeführte Daten die Ausgabe in einer CSV-Datei.

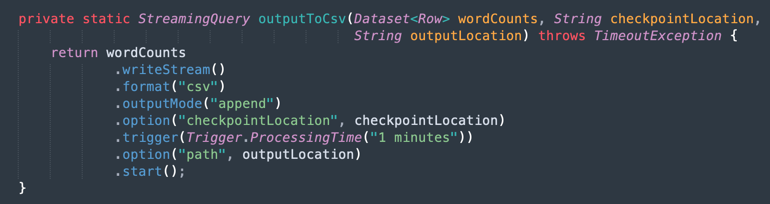
Aufgabe 9: Anwendung mit Maven verpacken
Bevor Sie den Job in Spark ausführen, müssen Sie Ihre Anwendung mit Maven verpacken.
-
Gehen Sie zum Ordner /DataflowSparkStreamDemo, und führen Sie den folgenden Befehl aus:
mvn package -
Maven wird beim Starten des Packages angezeigt.

-
Wenn alles korrekt ist, wird die Meldung Erfolgreich angezeigt.

Aufgabe 10: Ausführung prüfen
-
Testen Sie Ihre Anwendung auf dem lokalen Spark-Rechner, indem Sie den folgenden Befehl ausführen:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
Gehen Sie zu Ihrer Oracle Cloud Streaming-Kafka-Instanz, und klicken Sie auf Testnachricht erstellen, um einige Daten zu generieren, um Ihre Echtzeitanwendung zu testen.
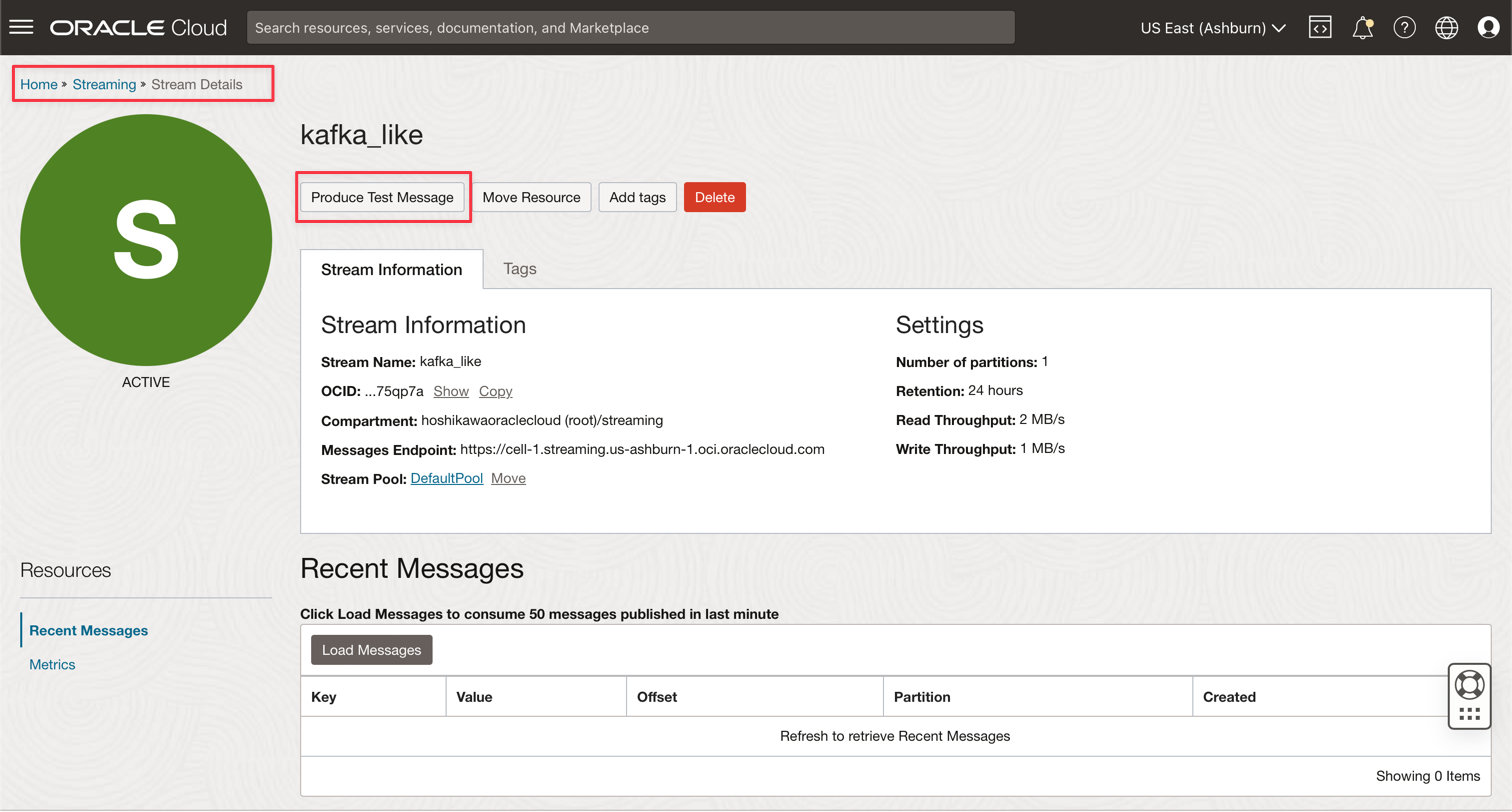
-
Sie können diese JSON-Nachricht in das Kafka-Thema einfügen.
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}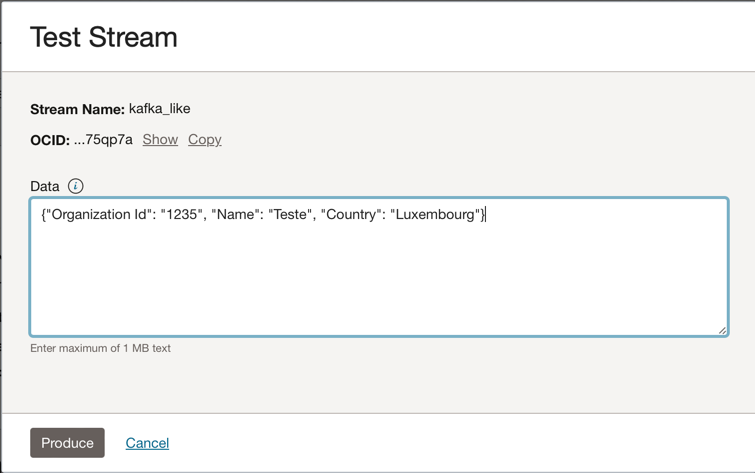
-
Jedes Mal, wenn Sie auf Erzeugen klicken, senden Sie eine Nachricht an die Anwendung. Das Ausgabelog der Anwendung sieht in etwa wie folgt aus:
-
Dies sind die Daten, die aus dem Kafka-Thema gelesen wurden.

-
Dies sind die zusammengeführten Daten aus der ADW-Tabelle.

-
Aufgabe 11: Datenflussjob erstellen und ausführen
Wenn beide Anwendungen erfolgreich auf dem lokalen Spark-Rechner ausgeführt werden, können Sie sie jetzt im Oracle Cloud Data Flow in Ihrem Mandanten bereitstellen.
Hinweis: In der Spark Streaming-Dokumentation können Sie den Zugriff auf Ressourcen wie Oracle Object Storage und Oracle Streaming (Kafka) konfigurieren: Zugriff auf Data Flow aktivieren
-
Laden Sie die Packages in Object Storage hoch.
- Bevor Sie eine Datenflussanwendung erstellen, müssen Sie die Java-Artefaktanwendung (Ihre Datei ***-SNAPSHOT.jar) in den Object Storage-Bucket mit dem Namen Anwendungen hochladen.
-
Erstellen Sie eine Datenflussanwendung.
-
Wählen Sie das Hauptmenü von Oracle Cloud aus, und gehen Sie zu Analysen und KI und Datenfluss. Wählen Sie das Compartment Analytics aus, bevor Sie eine Datenflussanwendung erstellen.
-
Klicken Sie auf Anwendung erstellen.

-
Füllen Sie die Parameter wie folgt aus.

-
Klicken Sie auf Erstellen.
-
Klicken Sie nach der Erstellung auf den Link Demo skalieren, um Details anzuzeigen. Um einen Job auszuführen, klicken Sie auf RUN.
Hinweis: Klicken Sie auf Erweiterte Optionen anzeigen, um die OCI-Sicherheit für den Ausführungstyp Spark-Stream zu aktivieren.

-
-
Aktivieren Sie die folgenden Optionen.

-
Klicken Sie auf Run, um den Job auszuführen.
-
Bestätigen Sie die Parameter, und klicken Sie erneut auf Ausführen.

-
Sie können den Status des Jobs anzeigen.

-
Warten Sie, bis der Status auf Erfolgreich gesetzt ist, und die Ergebnisse werden angezeigt.

-
Verwandte Links
-
Große Dateien in Autonomous Database und Kafka mit Oracle Cloud Infrastructure Data Flow verarbeiten
Danksagungen
- Autor - Cristiano Hoshikawa (Oracle LAD A-Team Solution Engineer)
Weitere Lernressourcen
Sehen Sie sich andere Übungen zu docs.oracle.com/learn an, oder greifen Sie auf weitere kostenlose Lerninhalte im Oracle Learning YouTube-Kanal zu. Besuchen Sie außerdem die Website education.oracle.com/learning-explorer, um Oracle Learning Explorer zu werden.
Produktdokumentation finden Sie im Oracle Help Center.
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.