Hinweis:
- Dieses Tutorial erfordert Zugriff auf Oracle Cloud. Informationen zur Registrierung für einen kostenlosen Account finden Sie unter Erste Schritte mit Oracle Cloud Infrastructure Free Tier.
- Es verwendet Beispielwerte für Oracle Cloud Infrastructure-Zugangsdaten, -Mandanten und -Compartments. In der Übung ersetzen Sie diese Werte durch die Werte, die für Ihre Cloud-Umgebung spezifisch sind.
Analysieren Sie PDF-Dokumente in natürlicher Sprache mit OCI Generative AI
Einführung
Oracle Cloud Infrastructure Generative AI (OCI Generative AI) ist eine fortschrittliche generative künstliche Intelligenzlösung, mit der Unternehmen und Entwickler intelligente Anwendungen mit hochmodernen Sprachmodellen erstellen können. Basierend auf leistungsstarken Technologien wie Large Language Models (LLMs) ermöglicht diese Lösung die Automatisierung komplexer Aufgaben, wodurch Prozesse schneller, effizienter und durch Interaktionen in natürlicher Sprache zugänglich werden.
Eine der wirkungsvollsten Anwendungen von OCI Generative AI ist die PDF-Dokumentanalyse. Unternehmen beschäftigen sich häufig mit großen Mengen an Dokumenten, wie Verträgen, Finanzberichten, technischen Handbüchern und Forschungsarbeiten. Die manuelle Suche nach Informationen in diesen Dateien kann zeitaufwendig und fehleranfällig sein.
Mit der Verwendung generativer künstlicher Intelligenz ist es möglich, Informationen sofort und genau zu extrahieren, sodass Benutzer komplexe Dokumente einfach abfragen können, indem sie Fragen in natürlicher Sprache formulieren. Das heißt, anstatt ganze Seiten zu lesen, um eine bestimmte Klausel in einem Vertrag oder einen relevanten Datenpunkt in einem Bericht zu finden, können Benutzer einfach das Modell fragen, das die Antwort basierend auf dem analysierten Inhalt schnell zurückgibt.
Neben dem Abrufen von Informationen kann OCI Generative AI auch verwendet werden, um langwierige Dokumente zusammenzufassen, Inhalte zu vergleichen, Informationen zu klassifizieren und sogar strategische Einblicke zu generieren. Diese Fähigkeiten machen die Technologie für verschiedene Bereiche wie Recht, Finanzen, Gesundheitswesen und Engineering unerlässlich, optimieren die Entscheidungsfindung und steigern die Produktivität.
Durch die Integration dieser Technologie in Tools wie Oracle AI-Services, OCI Data Science und APIs für die Dokumentenverarbeitung können Unternehmen intelligente Lösungen entwickeln, die ihre Interaktion mit ihren Daten vollständig verändern und den Informationsabruf schneller und effektiver machen.
Voraussetzungen
- Installieren Sie Python
version 3.10oder höher und die Oracle Cloud Infrastructure-Befehlszeilenschnittstelle (OCI-CLI).
Aufgabe 1: Python-Packages installieren
Der Python-Code erfordert bestimmte Librarys zur Verwendung von OCI Generative AI. Führen Sie den folgenden Befehl durch, um die erforderlichen Python-Packages zu installieren.
pip install -r requirements.txt
Aufgabe 2: Python-Code verstehen
Dies ist eine Demo von OCI Generative AI zum Abfragen von Funktionalitäten von Oracle SOA Suite und Oracle Integration. Beide Tools werden derzeit für hybride Integrationsstrategien verwendet, was bedeutet, dass sie sowohl in Cloud- als auch in On-Premises-Umgebungen arbeiten.
Da diese Tools Funktionalitäten und Prozesse gemeinsam nutzen, hilft dieser Code, zu verstehen, wie derselbe Integrationsansatz in jedem Tool implementiert wird. Darüber hinaus können Benutzer gemeinsame Merkmale und Unterschiede untersuchen.
Laden Sie den Python-Code hier herunter:
Die PDF-Dokumente finden Sie hier:
Erstellen Sie einen Ordner mit dem Namen Manuals, und verschieben Sie diese PDFs dorthin.
-
Librarys importieren:
Importiert die erforderlichen Bibliotheken für die Verarbeitung von PDFs, OCI Generative AI, Textvektorisierung und Speicherung in Vektordatenbanken (Facebook AI Similarity Search (FAISS) und ChromaDB).
-
UnstructuredPDFLoaderwird zum Extrahieren von Text aus PDFs verwendet. -
Mit
ChatOCIGenAIkönnen Sie OCI Generative AI-Modelle verwenden, um Fragen zu beantworten. -
OCIGenAIEmbeddingserstellt Einbettungen (Vektordarstellungen) von Text für die semantische Suche.
-
-
PDFs laden und verarbeiten:
Listet die zu verarbeitenden PDF-Dateien auf.
-
UnstructuredPDFLoaderliest jedes Dokument und teilt es zur einfacheren Indizierung und Suche in Seiten auf. -
Dokumentkennungen werden für zukünftige Referenzzwecke gespeichert.

-
-
OCI Generative AI-Modell konfigurieren:
Konfiguriert das auf OCI gehostete
Llama-3.1-405b-Modell, um Antworten basierend auf den geladenen Dokumenten zu generieren.Definiert Parameter wie
temperature(Zufälligkeitssteuerung),top_p(Diversitätssteuerung) undmax_tokens(Tokengrenzwert).
Hinweis: Die verfügbare LLaMA-Version kann sich im Laufe der Zeit ändern. Prüfen Sie die aktuelle Version in Ihrem Mandanten, und aktualisieren Sie gegebenenfalls Ihren Code.
-
Erstellen Sie Einbettungen und Vektor-Indizierung:
Verwendet das Einbettungsmodell von Oracle, um Text in numerische Vektoren zu transformieren und semantische Suchen in Dokumenten zu erleichtern.

-
FAISS speichert die Einbettungen der PDF-Dokumente für schnelle Abfragen.
-
Mit
retrieverkönnen Sie die relevantesten Auszüge basierend auf der semantischen Ähnlichkeit der Abfrage des Benutzers abrufen.

-
-
Bei der ersten Verarbeitungsausführung werden die Vektordaten in einer FAISS-Datenbank gespeichert.

-
Definieren Sie den Prompt:
Erstellt eine intelligente Eingabeaufforderung für das generative Modell und führt dazu, dass nur relevante Dokumente für jede Abfrage berücksichtigt werden.
Dadurch wird die Genauigkeit der Antworten verbessert und unnötige Informationen vermieden.

-
Erstellen Sie die Verarbeitungskette (RAG - Retrieval-Augmented Generation):
Implementiert einen RAG-Flow, wobei:
retrieversucht nach den wichtigsten Dokumentauszügen.promptorganisiert die Abfrage für besseren Kontext.llmgeneriert eine Antwort basierend auf den abgerufenen Dokumenten.StrOutputParserformatiert die endgültige Ausgabe.

-
Frage-und-Antwort-Schleife:
Verwaltet eine Schleife, in der Benutzer Fragen zu den geladenen Dokumenten stellen können.
-
Die KI reagiert mit der aus den PDFs extrahierten Wissensdatenbank.
-
Wenn Sie
quiteingeben, wird das Programm beendet.

-
Jetzt können Sie 3 Optionen wählen, um die Dokumente zu verarbeiten. Sie können denken:
- Wie viel Leistung müssen Sie verarbeiten?
- Wie viel Zeit müssen Sie verarbeiten?
- Wie ist die Qualität Ihrer Antworten?
Sie haben also folgende Optionen:
Chunking mit fester Größe: Dies ist eine schnellere Alternative zur Verarbeitung Ihrer Dokumente. Es kann genug sein, um zu bekommen, was Sie wollen.
Semantisches Chunking: Dieser Prozess ist langsamer als Chunking mit fester Größe, bietet jedoch mehr Qualitäts-Chunking.
Semantisches Chunking mit GraphRAG: Es wird eine präzisere Methode bereitgestellt, da die Chunkingtexte und Wissensdiagramme organisiert werden.
Chunking mit fester Größe
Laden Sie den Code hier herunter: oci_genai_llm_context_fast.py.
-
Was ist Fixed Size Chunking?
Chunking mit fester Größe ist eine einfache und effiziente Text-Splitting-Strategie, bei der Dokumente basierend auf vordefinierten Größenbeschränkungen in Blöcke unterteilt werden, die in der Regel in Token, Zeichen oder Linien gemessen werden.
Diese Methode analysiert nicht die Bedeutung oder Struktur des Textes. Es schneidet den Inhalt einfach in festen Abständen ab, unabhängig davon, ob der Schnitt in der Mitte eines Satzes, Absatzes oder einer Idee erfolgt.
-
So funktioniert Chunking mit fester Größe:
-
Beispielregel: Teilen Sie das Dokument alle 1000 Token (oder alle 3000 Zeichen) auf.
-
Optionale Überschneidung: Um das Risiko der Aufteilung des relevanten context zu reduzieren, fügen einige Implementierungen eine Überschneidung zwischen aufeinanderfolgenden Chunks hinzu (z.B. 200-Token-Überschneidung), um sicherzustellen, dass wichtiger context an der Grenze nicht verloren geht.
-
-
Vorteile von Chunking mit fester Größe:
-
Schnelle Verarbeitung: Keine semantische Analyse, LLM-Inferenz oder Inhaltsverständnis erforderlich. Zählen und schneiden.
-
Niedriger Ressourcenverbrauch: Minimale CPU-/GPU- und Arbeitsspeicherauslastung, sodass sie für große Datasets skalierbar ist.
-
Einfach zu implementieren: Funktioniert mit einfachen Skripten oder Standard-Textverarbeitungsbibliotheken.
-
-
Einschränkungen von Chunking mit fester Größe:
-
Schlechte semantische Wahrnehmung: Chunks können Sätze, Absätze oder logische Abschnitte abschneiden, was zu unvollständigen oder fragmentierten Ideen führt.
-
Reduzierte Abrufgenauigkeit: In Anwendungen wie der semantischen Suche oder der Retrieval-Augmented Generation (RAG) können schlechte Chunk-Grenzen die Relevanz und Qualität der abgerufenen Antworten beeinflussen.
-
-
Wann wird Chunking mit fester Größe verwendet:
-
Verarbeitungsgeschwindigkeit und Skalierbarkeit stehen dabei an erster Stelle.
-
Bei groß angelegten Dokumentenaufnahmepipelines, bei denen die semantische Präzision nicht entscheidend ist.
-
Als erster Schritt in Szenarien, in denen spätere Verfeinerungen oder semantische Analysen nachgelagert stattfinden.
-
Dies ist eine sehr einfache Methode, um Text zu teilen.

-
Dies ist der Hauptprozess des festen Blocks.

Hinweis: Laden Sie diesen Code herunter, um das feste Chunking schneller zu verarbeiten:
oci_genai_llm_context_fast.py -
Semantisches Chunking
Laden Sie den Code hier herunter: oci_genai_llm_context.py.
-
Was ist Semantic Chunking?
Semantic Chunking ist eine Textvorverarbeitungstechnik, bei der große Dokumente (wie PDFs, Präsentationen oder Artikel) in kleinere Teile aufgeteilt werden, die als Chunks bezeichnet werden, wobei jeder Chunk einen semantisch kohärenten Textblock darstellt.
Im Gegensatz zum herkömmlichen Chunking mit fester Größe (z. B. alle 1000 Token oder alle X-Zeichen) verwendet Semantic Chunking künstliche Intelligenz (in der Regel Large Language Models - LLMs), um natürliche Inhaltsgrenzen zu erkennen und Themen, Abschnitte und context zu respektieren.
Anstatt Text willkürlich zu schneiden, versucht Semantic Chunking, die volle Bedeutung jedes Abschnitts zu erhalten und eigenständige, kontextbezogene Stücke zu erstellen.
-
Warum kann Semantic Chunking die Verarbeitung langsamer machen?
Ein traditioneller Chunking-Prozess, der auf einer festen Größe basiert, ist schnell. Das System zählt nur Token oder Zeichen und schneidet entsprechend ab. Mit Semantic Chunking sind mehrere zusätzliche Schritte der semantischen Analyse erforderlich:
- Volltext (oder große Blöcke) vor dem Splitten lesen und interpretieren: Das LLM muss den Inhalt verstehen, um die besten Chunk-Grenzen zu identifizieren.
- LLM-Prompts oder Lerneinheitenklassifizierungsmodelle ausführen: Das System fragt das LLM häufig mit Fragen ab, wie Ist dies das Ende einer Idee? oder Startet dieser Absatz einen neuen Abschnitt?.
- Höhere Speicher- und CPU-/GPU-Auslastung: Da das Modell größere Textblöcke verarbeitet, bevor Chunking-Entscheidungen getroffen werden, ist der Ressourcenverbrauch deutlich höher.
- Sequenzielle und inkrementelle Entscheidungsfindung: Semantisches Chunking funktioniert häufig in Schritten (z.B. Analyse von 10.000-Token-Blöcken und anschließende Verfeinerung von Chunk-Grenzen innerhalb dieses Blocks), was die Gesamtverarbeitungszeit erhöht.
Hinweis:
- Abhängig von Ihrer Maschinenverarbeitungsleistung warten Sie eine lange, lange Zeit, bis die erste Ausführung mit Semantic Chunking abgeschlossen ist.
- Mit diesem Algorithmus können Sie benutzerdefiniertes Chunking mit OCI Generative AI erstellen.
-
So funktioniert semantisches Chunking:
-
smart_split_text(): Tennt den Volltext in kleinen 10 KB-Teilen (Sie können konfigurieren, um andere Strategien einzuführen). Der Mechanismus nimmt den letzten Absatz wahr. Wenn ein Teil des Absatzes im nächsten Textteil enthalten ist, wird dieser Teil in der Verarbeitung ignoriert und an die nächste Verarbeitungstextgruppe angehängt. -
semantic_chunk(): Diese Methode verwendet den OCI-LLM-Mechanismus, um die Absätze zu trennen. Es enthält die Intelligenz, um die Titel, Komponenten einer Tabelle zu identifizieren, die Absätze, um einen Smart Chunk auszuführen. Die Strategie besteht darin, die Technik Semantischer Chunk zu verwenden. Es wird mehr Zeit brauchen, um die Mission abzuschließen, wenn man sie mit der gemeinsamen Verarbeitung vergleicht. Die erste Verarbeitung dauert also lange, aber die nächste lädt alle vorgespeicherten FAISS-Daten. -
split_llm_output_into_chapters(): Diese Methode schließt den Chunk ab und trennt die Kapitel.
Hinweis: Laden Sie diesen Code herunter, um das semantische Chunking zu verarbeiten:
oci_genai_llm_context.py -
Semantisches Chunking mit GraphRAG
Laden Sie den Code hier herunter: oci_genai_llm_graphrag.py.
GraphRAG (Graph-Augmented Retrieval-Augmented Generation) ist eine fortschrittliche KI-Architektur, die traditionellen vektorbasierten Abruf mit strukturierten Wissensdiagrammen kombiniert. In einer Standard-RAG-Pipeline ruft ein Sprachmodell relevante Dokument-Chunks mit semantischer Ähnlichkeit aus einer Vektordatenbank ab (wie FAISS). Der vektorbasierte Abruf funktioniert jedoch unstrukturiert und basiert ausschließlich auf Einbettungen und Entfernungsmetriken, die manchmal tiefere kontextbezogene oder relationale Bedeutungen verpassen.
GraphRAG verbessert diesen Prozess durch die Einführung einer Wissensdiagrammebene, in der Entitys, Konzepte, Komponenten und ihre Beziehungen explizit als Knoten und Kanten dargestellt werden. Dieser grafische context ermöglicht es dem Sprachmodell, Beziehungen, Hierarchien und Abhängigkeiten zu berücksichtigen, die Vektorähnlichkeit allein nicht erfassen kann.
-
Warum Semantic Chunking mit GraphRAG kombinieren?
Semantisches Chunking ist der Prozess der intelligenten Aufteilung großer Dokumente in sinnvolle Einheiten oder "Chunks", basierend auf der Struktur des Inhalts - wie Kapitel, Überschriften, Abschnitte oder logische Unterteilungen. Anstatt Dokumente rein durch Zeichenbeschränkungen oder naive Absatzteilung zu brechen, erzeugt semantisches Chunking qualitativ hochwertigere, context-bewusste Chunks, die besser mit dem menschlichen Verständnis übereinstimmen.
-
Semantisches Chunking mit GraphRAG Vorteile:
-
Erweiterte Wissensdarstellung:
- Semantische Blöcke behalten logische Grenzen im Inhalt bei.
- Knowledge-Diagramme, die aus diesen Blöcken extrahiert werden, pflegen genaue Beziehungen zwischen Entitys, Systemen, APIs, Prozessen oder Services.
-
Multi-Modal Contextual Retrieval (das Sprachmodell ruft beide ab):
- Unstrukturiertes context aus der Vektordatenbank (semantische Ähnlichkeit).
- Strukturierter context aus dem Wissensdiagramm (Entitätsrelationstriples).
- Dieser hybride Ansatz führt zu vollständigeren und genaueren Antworten.
-
Verbesserte Logikfunktionen:
- Der grafische Abruf ermöglicht relationales Denken.
- Das LLM kann Fragen wie:
- Von welchen Services hängt die Auftrags-API ab?
- Welche Komponenten gehören zur SOA Suite?
- Diese relationalen Abfragen sind mit reinen Einbettungsansätzen oft nicht möglich.
-
Höhere Erklärbarkeit und Rückverfolgbarkeit:
- Diagrammbeziehungen sind menschenlesbar und transparent.
- Benutzer können prüfen, wie Antworten sowohl aus Text- als auch aus Strukturwissen abgeleitet werden.
-
Reduzierte Halluzination: Das Diagramm dient als Constraint für das LLM und verankert Antworten auf verifizierte Beziehungen und Faktenverbindungen, die aus den Quelldokumenten extrahiert werden.
-
Skalierbarkeit in komplexen Domains:
- In technischen Bereichen (z. B. APIs, Microservices, Rechtsverträge, Gesundheitsstandards) sind Beziehungen zwischen Komponenten genauso wichtig wie die Komponenten selbst.
- GraphRAG wird in Kombination mit semantischen Chunking-Skalen effektiv in diesen Kontexten skaliert, wobei sowohl die Texttiefe als auch die relationale Struktur beibehalten werden.
Hinweis:
- Laden Sie den Code zur Verarbeitung des semantischen Chunkings mit graphRAG hier herunter:
oci_genai_llm_graphrag.py. - Sie benötigen:
- Ein docker, der installiert und aktiv ist, um die Open-Source-Graph-BS-Datenbank Neo4J zu testen.
- Installieren Sie die neo4j-Python-Library.
In diesem Code sind 2 Methoden vorhanden:
-
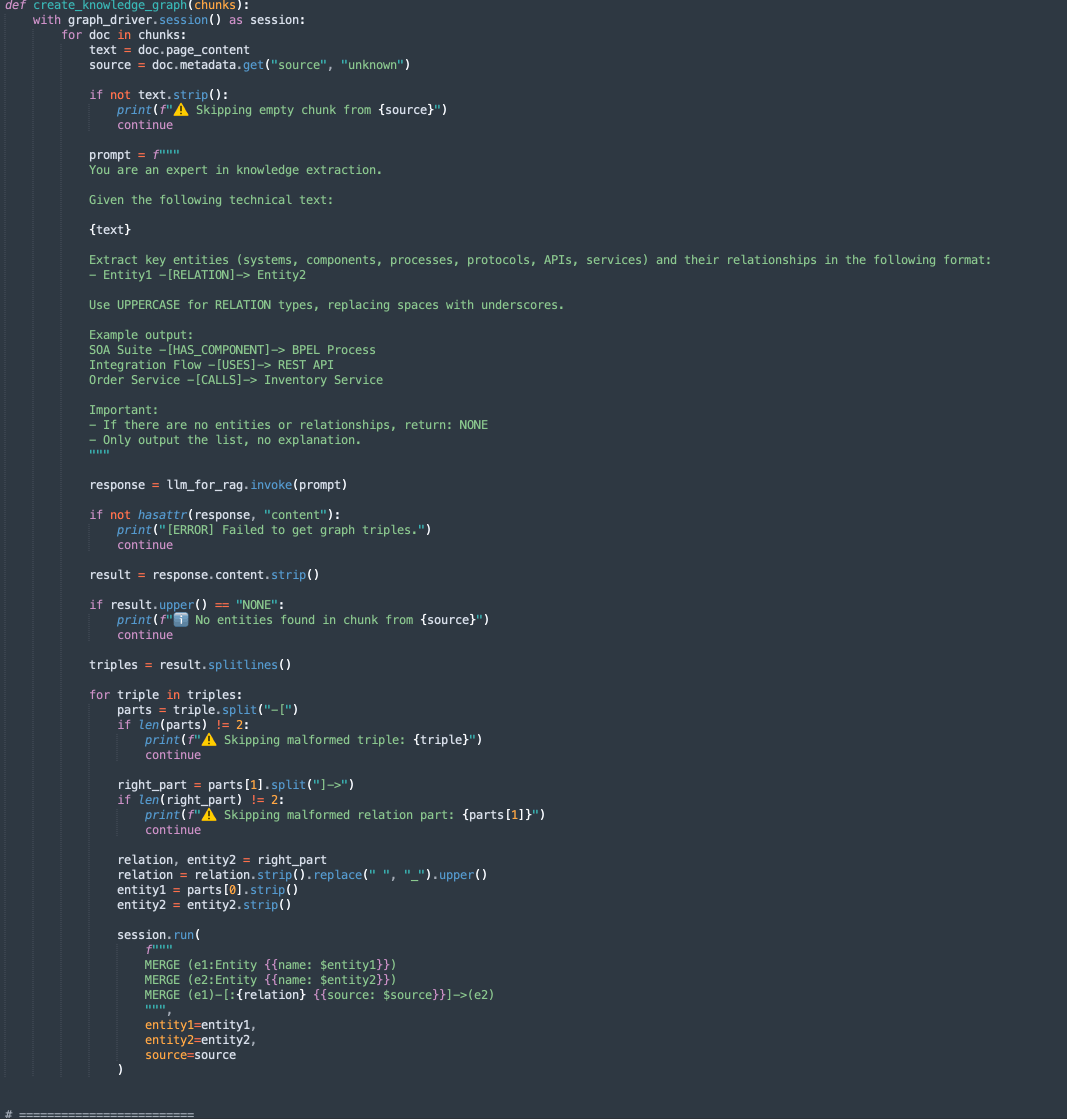
create_knowledge_graph:-
Mit dieser Methode werden Entitys und Beziehungen automatisch aus Textblöcken extrahiert und in einem Knowledge-Diagramm Neo4j gespeichert.
-
Für jeden Dokument-Chunk sendet er den Inhalt an ein LLM (Large Language Model) mit einer Aufforderung, Entitys (wie Systeme, Komponenten, Services, APIs) und ihre Beziehungen zu extrahieren.
-
Es parst jede Zeile, extrahiert Entity1, RELATION und Entity2.
-
Speichert diese Informationen als Knoten und Kanten in der Diagrammdatenbank Neo4j mit Cypher-Abfragen:
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
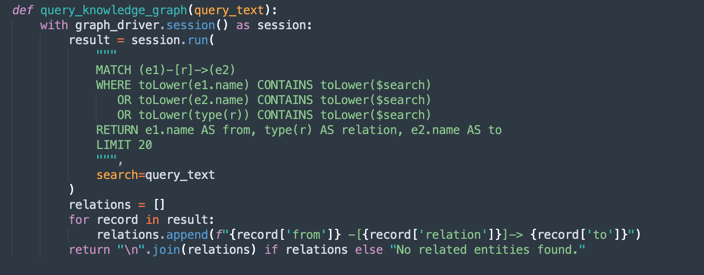
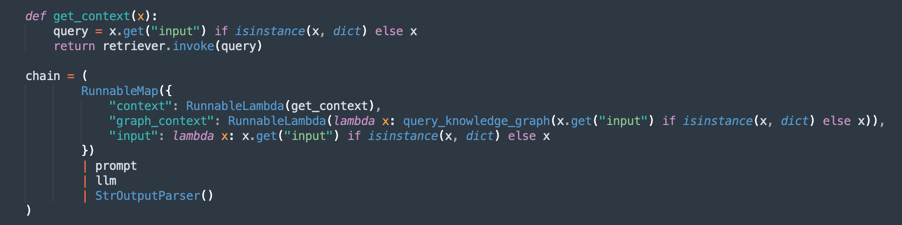
query_knowledge_graph:-
Diese Methode fragt das Knowledge-Diagramm Neo4j ab, um Beziehungen abzurufen, die sich auf ein bestimmtes Schlüsselwort oder Konzept beziehen.
-
Führt eine Cypher-Abfrage aus, nach der gesucht wird:
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
Gibt bis zu 20 übereinstimmende Triples zurück, die wie folgt formatiert sind:
Entity1 -[RELATION]-> Entity2
-
Hinweis:
Neo4j Verwendung:
Bei dieser Implementierung wird Neo4j als eingebettete Knowledge Graph-Datenbank für Demonstrations- und Prototypingzwecke verwendet. Während Neo4j eine leistungsstarke und flexible Diagrammdatenbank ist, die für Entwicklungs-, Test- und kleine bis mittlere Workloads geeignet ist, erfüllt sie möglicherweise nicht die Anforderungen für unternehmensgerechte, geschäftskritische oder hochsichere Workloads, insbesondere in Umgebungen, die High Availability, Skalierbarkeit und erweiterte Sicherheitscompliance erfordern.
Für Produktionsumgebungen und Unternehmensszenarios wird empfohlen, Oracle Database mit Graph-Funktionen zu nutzen, die Folgendes bieten:
Zuverlässigkeit und Sicherheit der Unternehmensklasse.
Skalierbarkeit für geschäftskritische Workloads.
Native Graphmodelle (Property Graph und RDF), die in relationale Daten integriert sind.
Erweiterte Analyse-, Sicherheits-, Hochverfügbarkeits- und Disaster Recovery-Funktionen.
Vollständige Oracle Cloud Infrastructure-(OCI-)Integration.
Durch die Verwendung von Oracle Database für Diagramm-Workloads können Unternehmen strukturierte, halbstrukturierte und grafische Daten innerhalb einer einzigen, sicheren und skalierbaren Unternehmensplattform vereinheitlichen.
Aufgabe 3: Abfrage für den Inhalt von Oracle Integration und Oracle SOA Suite ausführen
Führen Sie den folgenden Befehl aus.
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
Hinweis: Die Parameter
--deviceund--gpu_namekönnen verwendet werden, um die Verarbeitung in Python zu beschleunigen. Verwenden Sie GPU, wenn Ihr Rechner einen hat. Beachten Sie, dass dieser Code auch mit lokalen Modellen verwendet werden kann.
Der angegebene Kontext unterscheidet Oracle SOA Suite und Oracle Integration. Sie können den Code unter Berücksichtigung der folgenden Punkte testen:
- Die Abfrage darf nur für Oracle SOA Suite erfolgen: Daher sollten nur Oracle SOA Suite-Dokumente berücksichtigt werden.
- Die Abfrage sollte nur für Oracle Integration durchgeführt werden: Daher sollten nur Oracle Integration-Dokumente berücksichtigt werden.
- Für die Abfrage ist ein Vergleich zwischen Oracle SOA Suite und Oracle Integration erforderlich: Daher müssen alle Dokumente berücksichtigt werden.
Wir können den folgenden Kontext definieren, was sehr hilft, die Dokumente richtig zu interpretieren.
Die folgende Abbildung zeigt ein Beispiel für einen Vergleich zwischen Oracle SOA Suite und Oracle Integration.

Nächste Schritte
Dieser Code demonstriert eine Anwendung von OCI Generative AI für die intelligente PDF-Analyse. Es ermöglicht Benutzern, große Mengen von Dokumenten effizient abzufragen, indem semantische Suchen und ein generatives KI-Modell verwendet werden, um genaue Antworten in natürlicher Sprache zu generieren.
Dieser Ansatz kann in verschiedenen Bereichen angewendet werden, wie Recht, Compliance, technische Unterstützung und akademische Forschung, wodurch das Abrufen von Informationen viel schneller und intelligenter wird.
Verwandte Links
-
Integration von Cloud- und Konversations-KI: LangChain und OCI Data Science-Plattform
-
Einführung in benutzerdefinierte und integrierte Python LangChain-Agents
-
Oracle Database Insider - Graph RAG: Die Vorteile von Diagrammen für generative KI nutzen
Bestätigungen
- Autor – Cristiano Hoshikawa (Oracle LAD A-Team Solution Engineer)
Weitere Lernressourcen
Sehen Sie sich weitere Übungen zu docs.oracle.com/learn an, oder greifen Sie auf weitere kostenlose Lerninhalte im Oracle Learning YouTube-Kanal zu. Besuchen Sie außerdem education.oracle.com/learning-explorer, um ein Oracle Learning Explorer zu werden.
Die Produktdokumentation finden Sie im Oracle Help Center.
Analyze PDF Documents in Natural Language with OCI Generative AI
G29536-05
Copyright ©2025, Oracle and/or its affiliates.