Terraform Basics for Architects
Introduction
Terraform is fast becoming the de facto standard for IaC, but it is still unfamiliar to many architects. This short guide covers the basic knowledge that architects need to design a secure and effective approach to managing medium to large cloud environments.
The learning curve can be steep for those coming to Terraform for the first time, especially those from a software development background. While Terraform superficially looks like a programming language and is often compared with Ansible or Python as suitable for IaC, it is not a programming language at all; it is, at its core, a metadata language. Terraform “scripts” describe the desired configuration of a specific set of cloud resources - a “deployment.” All the more complex constructs that Terraform uses (e.g., iterators, modules, variables, etc.) should be considered as shortcuts or abbreviations describing the cloud deployment.
It’s important to note that Terraform scripts are not “run”, but are “applied” to a target cloud environment. As this is quite different from what is expected in a programming language, it’s worth looking at the Terraform internal architecture and process in a little more detail.
If you are interested in a step-by-step tutorial of setting up and using Terraform on OCI, we have Terraform Tutorial.
Terraform Architecture
We should think about Terraform as having three key components :
- The Terraform “scripts”
- The State “file”
- The target cloud infrastructure
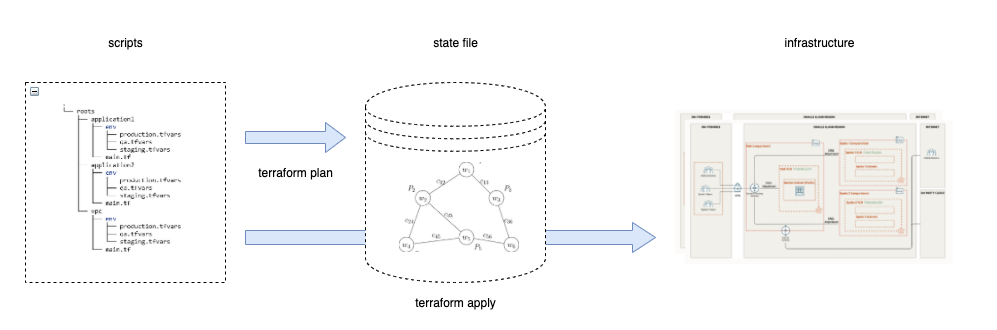
The “scripts” are simple human-readable text files that describe the desired deployment architecture. Each resource to be deployed will have a section, and each includes the configuration parameters needed to instantiate the resource. The deployment architecture can be split over many script files - all held in a single directory. Any Terraform command always runs in the context of your current directory - often called the Terraform ‘’root’. Remember that any Terraform will ignore any scripts not in the current directory - including subdirectories. You can name your scripts anything you like as long as they have a “.tf” suffix. Even main.tf is not mandatory, although a strong convention.
Here’s an example of a simple Terraform script to create a compartment :
resource "oci_identity_compartment" "tf-compartment" {
# Required
compartment_id = "<tenancy-ocid>"
description = "Compartment for Terraform resources."
name = "<your-compartment-name>"
}
We will come back to sub-directories and modules later, but we can safely ignore them for the moment.
Terraform Basic Commands
The first run of the scripts is via the Terraform plan command. It invokes the Terraform binary to parse the “scripts” and build an internal data model of the desired deployment. It then uses that data model to define the set of API calls that would need to be run to deploy the architecture - which it reports back to the user.
terraform plan
Internally, Terraform converts the “script” files into a graph model - this is key to determining the dependencies between resources. Terraform uses the graph model to navigate the dependencies and to define the correct order of API calls to deploy the resources.
If the user is happy with the reported plan, then the user can then apply that desired model to the target environment. At this point, Terraform will run the API commands against the target environment. If this succeeds, then Terraform stores the final metadata in the “state file”. Thus we then have a digital representation of the deployment.
terraform apply
Let’s say that after deployment, the user realizes that they missed a resource - perhaps a virtual machine. The user can then edit the original Terraform “scripts” and add the extra virtual machine. The user can then ask Terraform to “plan” again.
Terraform now again builds the desired architecture as a new graph model, but then critically, it compares that new desired state with the current state as saved in the “state” file and, in essence, calculated a “diff”. It then evaluates all the dependencies and creates a new series of API calls that, when applied, will transition the existing deployment to the new desired deployment (i.e., it will add the virtual server).
Of course, Terraform allows much more than just adding new resources, it manages additions, deletions, and amendments. At this point, we can introduce the term “Terraform provider”. The provider lists the types of resources that a specific cloud vendor cloud offers. It includes details of how resources may be configured, their dependencies, and their constraints. The “provider” is, as you might expect, cloud-vendor specific - Oracle’s is known as the OCI Provider
Terraform also offers the “destroy” command. This command will remove or destroy all the resources that have been deployed by a previous apply command. The list of resources to be destroyed is derived from the current state file.
Additional Terraform commands
Finally, we should mention two other commands - refresh and import. Both are designed to update the state file from the actual deployment. Import assumes a blank state file, and refresh assumes some resources have previously been deployed with Terraform. Neither updates the “script” files. However, both Terraform and Oracle’s advice at this time is these are not fully reliable and should not be used.
If you wish to bring a current deployment under control by Terraform then for OCI, Oracle recommends the resource discovery feature available in the OCI console. This will reverse engineer all the resources in a compartment into a set of Terraform scripts which can then be used to create a state file. You can find full instructions on how to use resource discovery in this resource discovery tutorial.
tf-oci -command=export -compartment_name=<your-compartment-name> -services=object_storage -output_path=$HOME/resource-discovery
One other option is to use one of the open-source tools available - Oracle supports one called OKit which you can download and try for yourself Okit on github.
Note, however, that all of these options generate scripts that are “naive”. They will, by necessity, hard-code values and are not a substitute for well-written Terraform.
Terraform State
So far, we have referred to the Terraform “state” and explained that it is a graph model, but we haven’t defined how it’s stored. The default is that the state is a file in the local file system under the same directory as your Terraform “scripts” - and this is fine if you are a single user managing a small deployment. Terraform calls the method used to store the state file a backend, and for a local filesystem store, the backend type is named local.
But this isn’t the only option.
The “state” is essentially a medium-sized binary object and can be stored in a single file, but it can also be stored in any data store that supports basic read and write operations.
Terraform a number of “backends” that can support the storage of the graph model beyond the local default. Terraform communicated with the backend via a standard set of simple APIs (basically, get and put). These have been implemented by both vendors and open source projects. Some use object storage, some database technology, and some on file storage. All are equivalent in their capabilities except for the “lock” feature that we will come back to later. The Terraform cloud also offers a remote option which we will also cover later.
Summary and the next challenge
So far, we have covered just the basics, and this all you need to understand how to manage a small Terraform managed cloud deployment yourself. Of course, we haven’t covered anything about the Terraform language itself - but there are lots of tutorials out there to help you get started.
In the next section, we take Terraform to the next level as we introduce multi-user configurations, multi-environments, separation of duties, permissions and governance, and code re-use.