 Map Extended Item Data Set Into Learning Models for Product Classification
Map Extended Item Data Set Into Learning Models for Product Classification
This feature is a continuation of the embedded machine learning for product classification code proposal delivered in an earlier release. It enables you to define key-value pair mappings such as reference numbers, remarks, and flex-field attributes that are used to load data in the HDOWNER schema. This data is also used to train your machine learning models. If your items and/or item classifications have reference numbers, remarks, and attribute flex fields specified, you can tell GTM which data to load into the HDOWNER schema and the target field to use. When you run the Load Data into Analytics action, GTM loads the data into the HDOWNER schema based on the mappings you've defined. This data is also used when defining filters and include/exclude columns in your Machine Learning Scenario.
For example, if you have an Item Remark with a Qualifier of PRODUCT FAMILY, you'll want to ensure that this data is brought into the HDOWNER schema so that you can use it to predict potential product classification codes. You have the flexibility to create a Project Data Mapping record to use across multiple Machine Learning Projects. Or you can create a Project Data Mapping for a specific Machine Learning Project.
Project Data Mapping
The Project Data Mapping is used for loading data into the HDOWNER schema and is also used for training your machine learning models. Navigate to Logistics Machine Learning > Power Data > General > Machine Learning Data Mapping to create your project data mapping. The Objective Model Type = Product Classification Prediction.
NOTE: You can map the Source Attribute Type from item and/or item classification reference numbers, remarks, date flex fields, number flex fields, and string flex fields to the Target Attribute Type. The Target Attribute Type is always a string flex field. You can map up to 30 different Source Attribute Types to the Target Attribute Type in the HDOWNER schema.
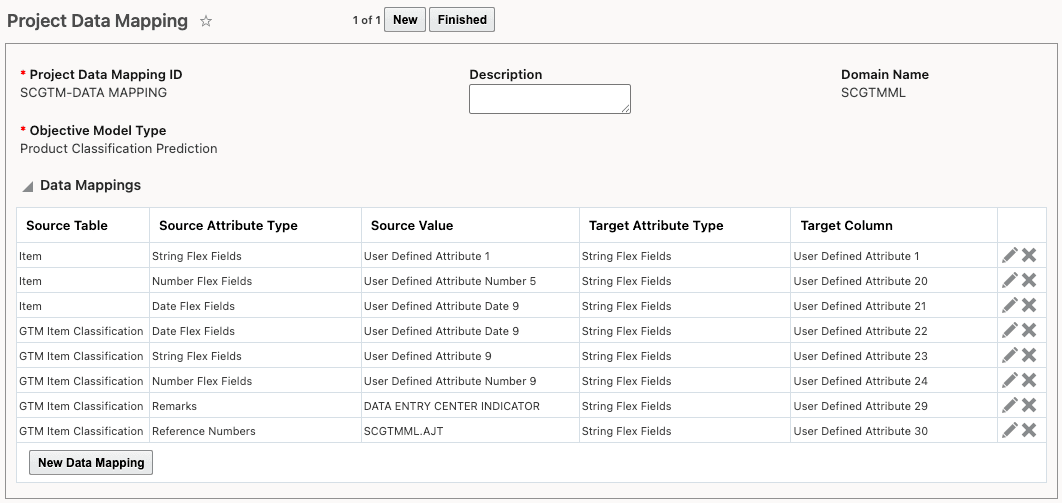
Project Data Mapping for Machine Learning Product Classification
Click New Data Mapping to add a line to the Data Mappings table. For each data mapping, select:
- Source Table - Select Item or GTM Item Classification.
- Source Attribute Type - You can map from references numbers, remarks, date flex fields, number flex fields or date flex fields. Depending on what is selected, GTM will display a drop-down list enabling you to specify a qualifier or flex field attribute field to be used. For example, if you are mapping from a remark, you need to enter the Remark Qualifier. If you are mapping from a String Flex Field, you need to select the appropriate User Defined Attribute field.
- Target Attribute Type - You can map to User Defined Attributes (30 string flex fields are available in the HDOWNER schema for mapping).
- Label ID - Specify the label you want to see on the training results screen and when specifying your filters and include/exclude columns on the Machine Learning Scenario. The label must be stored in the PUBLIC domain.
In this example, you are mapping from String Flex Field attribute 9 to a String Flex Field attribute 23. The label you want to used is Required Classification.

Project Data Mapping Details
Assigning a Project Data Mapping to a Machine Learning Project
Once you've defined your data mapping, you can assign it to a Machine Learning Project. When you train the model using the machine learning project, the Project Data Mapping defined is used to train the model.
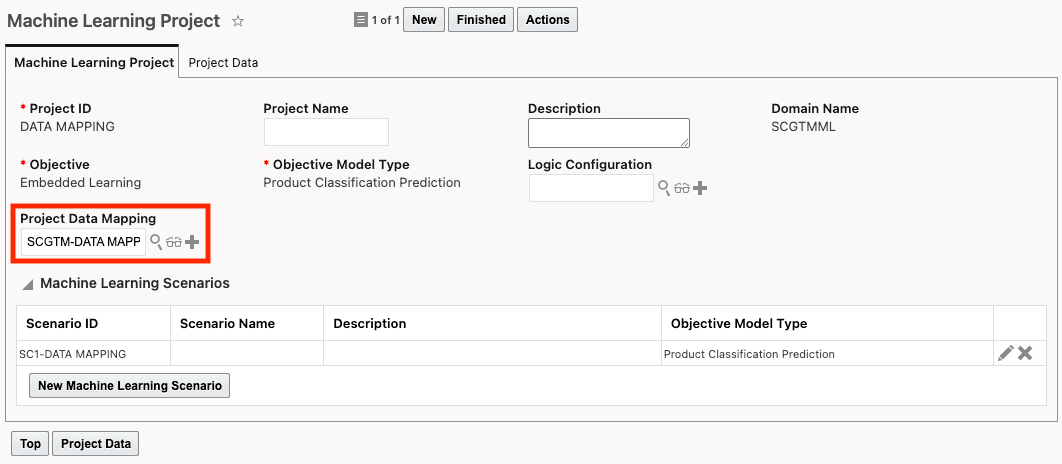
Machine Learning Project with Project Data Mapping Defined
For each Machine Learning Scenario in your project, you can define the filters and the columns to include and exclude. When you click New Machine Learning Scenario, select an Objective Model Type = Product Classification Prediction. You can also specify:
- Scenario Filters - Limits the data when training the model. For example, you may want to limit the training to a certain product family which you've defined in an item remark.
- Included and Excluded Columns - A set of columns are available by default in the Included Columns. You can also add columns from the Excluded Columns.
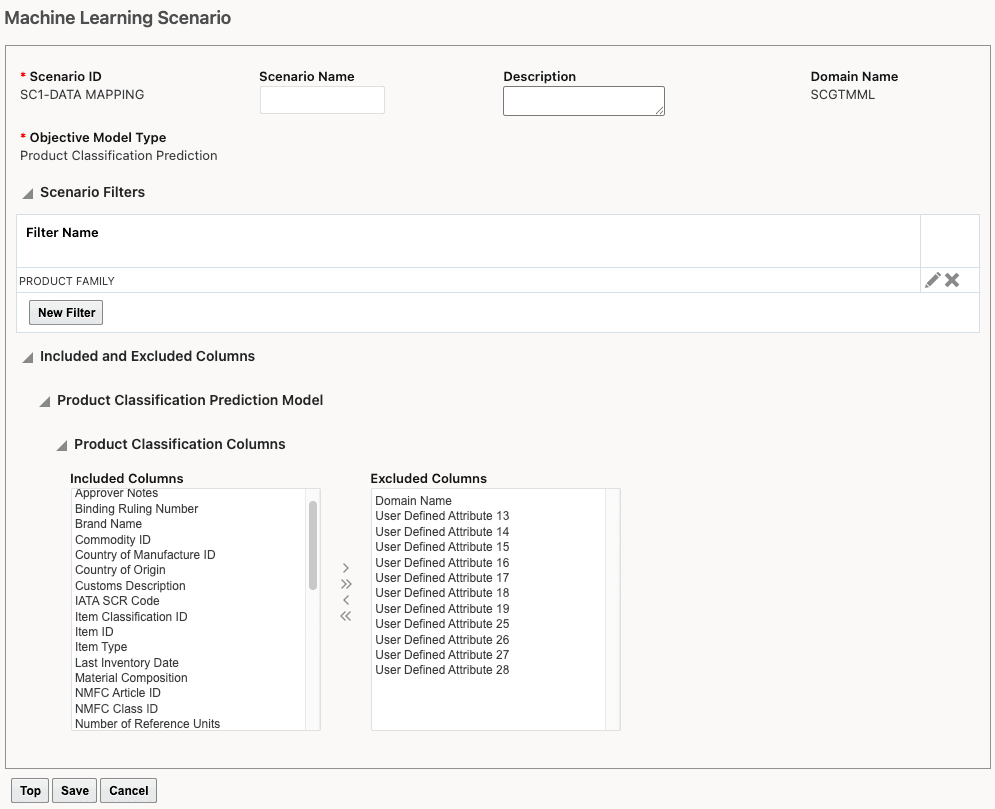
Machine Learning Scenario
Once configured, you can trigger the:
- Load Data into Analytics action on the Machine Learning Project to load the data to the HDOWNER table.
- Perform Training action on the Machine Learning Project to train the model.
- Propose Classification Code action on the Item to see the proposed codes based on machine learning.
- Utilizes historical product classification data on items to train AI/ML model(s) if desired.
- Considers user preferences and knowledge to propose classification data for items.
- Improves operational performance and reduces manual intervention.
Steps to Enable and Configure
To use embedded machine learning to propose product classification data, you must update each user who will use this capability. Navigate to Configuration and Administration > User Management > User Manager. For a user, add an Application ID = LML within the Business Intelligence Applications section.
To propose classification codes based on your data, you need to first configure and train the model:
- Data Setup - provide historical product classification data by creating machine learning projects and machine learning scenarios
- Data Export and Pre-Training Analytics - Load the data via the Load Data into Analytics action on the machine learning project and review it to see if you need to change the data setup
- Training and Post-Training Analytics - Train the model via the Perform Training action on the machine learning project review the results
- Prediction - Run the Propose Classification Code action on items to view the proposed codes, select a code and assign it to your item
Tips And Considerations
- This feature is only available to customers who are on ATP Database pods. If you are not on ATP yet, you will be shown a corresponding message when you try to use this feature.
- If you do not configure the Project Data Mapping, GTM will use the default mapping from the Source schema (GLOGOWNER) to the Target schema (HDOWNER):
- ITEM.ATTRIBUTE1-ATTRIBUTE20 is mapped to W_ML_GTM_ITEM_PC_F.ATTRIBUTE1-ATTRIBUTE20
- GTM_ITEM_CLASSIFICATION.ATTRIBUTE1-ATTRIBUTE20 is mapped to W_ML_GTM_ITEM_PC_F.ATTRIBUTE21-ATTRIBUTE30
Key Resources
- For more information on Embedded Machine Learning including training the model, refer to the help topic "Logistics Machine Learning".
- For more information on setting up and training the model for product classification, refer to the topic Embedded ML - Product Classification Code Proposal in the 25B What's New document.
- For more information on Enhancements to the Propose Classification Code action, refer to the topic in this What's New document.