Upgrading OCCNE
Following is the procedure to upgrade OCCNE.
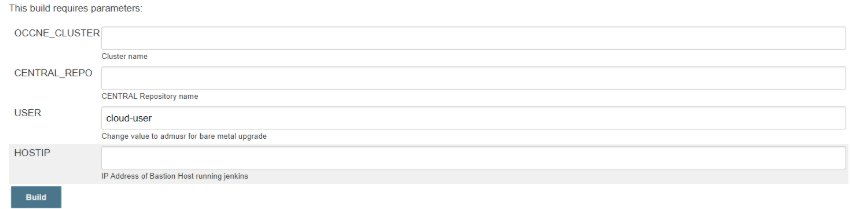
- Click the job name created in the previous step. Select the Build with Parameters option on the left top corner panel in the Jenkins GUI as shown below:
- On selecting the
Build with
Parameters option, there will be a list of parameters with a description
describing which values need to be used for the Bare-Metal upgrade vs the vCNE
upgrade.
Note: Change USER to admusr before upgrading bare-metal cluster
Figure 3-2 Jenkins UI: Build with Parameters
- After entering correct values for parameters, select Build to start upgrade.
- Once the build has started, go to the job home page to see the live console for upgrade. This can be done in two ways: Either select console output or Open Blue Ocean (Recommended is blue ocean as it will show each stage of upgrade)
- Check the job progress
from
Blue Ocean link
in the job to see each stage being executed, once upgrade is complete all the
stages will be in
Green.
Make sure before running next step that docker registry name and host name are same, if not run:
vi /var/occne/cluster/<cluster-name>/artifacts/upgrade_services.py and change hostname= os.environ['HOSTNAME'] in the script to hostname= '<bastion-registry-name>' -
After a successful upgrade, run following commands to upgrade the major version for the common services:
cd /var/occne/cluster/<cluster-name>/artifacts python -c "execfile('upgrade_services.py'); patch_random_named_pods_image()" // Wait for all the pods to be patched, run kubectl get pods to verify all the pods are running and ready flag is 1/1 python -c "execfile('upgrade_services.py'); patch_pods_image()" // Wait for all the pods to be patched, run kubectl get pods to verify all the pods are running and ready flag is 1/1 - To check if all the
elastic search data pods have restarted, run command below, sometimes it can
take time for a single pod to restart:
kubectl get pods -n occne-infra | grep data Sample output: NAME READY STATUS RESTARTS AGE occne-elastic-elasticsearch-data-0 1/1 Running 0 2d1h - Make sure that restarts value has changed to 1 from 0 after running the python command from code block above.
- Wait till data pods
restart is done, if not get information for node running the data pods and stop
elastic search data containers using the following command:
Verify all elasticsearch-data-<count> pods are with ready 1/1 , status = running and Restarts =1.$ sudo /usr/local/bin/crictl stop containerid - Once all the elastic
search data pods have restarted, run the command mentioned below:
$ python -c "execfile('upgrade_services.py'); patch_deployment_image_chart()"