
Generalized Data Export
The generalized data export method provides a file-based export of data in JSON format. Exporting the data of a maintenance object using this method involves an initial export of the entity’s entire data followed by an ongoing export of changes as they are made over time. These processes are illustrated in the following diagram:
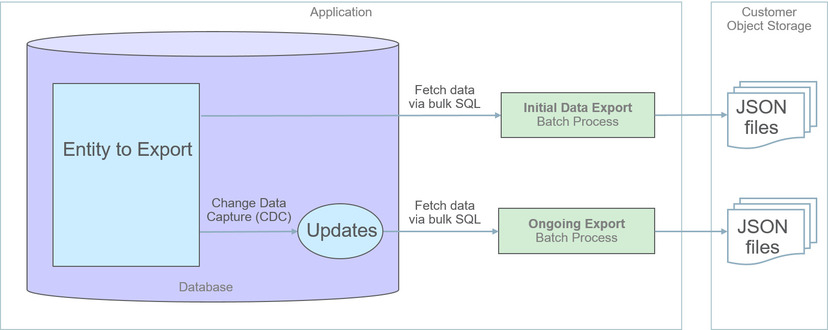
-
Enable entities for export in the Generalized Export Dashboard portal. You may enable many entities at once. This step also allows you to enable ongoing export of these entities.
-
Submit the Generalized Initial Export Initiator (F1-GEXPI ) batch process to export the current content of all enabled entities. This step submits a separate batch process for each entity you have enabled for export.
-
Schedule the Generalized Ongoing Export (F1-GEEXO ) batch process to run periodically.
The following sections further discusses concepts and guidelines related to the generalized data export method.
Eligibility
-
The entity manages extremely high volume of data. Tracking changes to such entity would double the volume of managed data and impact overall performance.
-
The entity is updated very frequently. Tracking these events may impact overall performance.
-
The entity is used by the product’s infrastructure and operational processes. These entities are maintained differently and cannot be subject to the generalized data export methods.
By default a maintenance object is eligible for the generalized data export method unless explicitly marked otherwise by the Data Export Class option. The option may be used to mark an entity as either not allowed for any type of export or allowed for a specialized export only. The lack of such explicit option means the maintenance object is eligible for the generalized export.
One Method Fits All
The generalized data export method is designed to accommodate many eligible maintenance objects in a generic way that must also takes performance considerations into account. For this reason this method does not support entity specific filtering options nor custom rules of any kind.
-
Entire data is exported.
-
All fields on all tables that belong to the maintenance object are exported except for “key” and “log” tables if any.
-
Maintenance object log tables typically do not contain useful business information and as such are omitted from export for performance and data volume reasons. However, there are entities for which log records provide analytical value. When applicable, use the Export Log Tables option to explicitly include log tables for a specific maintenance object.
-
-
Same data structure and format is used for all entities. Refer to the Record Format section for more information.
-
Data is exported to files only. Refer to the Export To Files Only section for more information.
-
All changes are captured. It is not possible to exclude some changes from being tracked for ongoing export based on custom business rules.
-
When data changes, a full snapshot of the data related to that entity is exported to avoid heavy data merging on the target side.
-
When the entity is deleted, only the primary key of the entity is exported along with an indication that it is deleted.
Export To Files Only
The immediate destination of both initial and ongoing export processes are files in a customer specified location. In a Cloud installation files are created in a customer owned Object Storage.
Based on your business requirements you may further consume these files by downstream applications such as data lakes etc.
Enabling Data Export
To enable data export for an eligible maintenance object a Data Export Control record needs to be created. The record keeps an indication of whether the initial export for the maintenance object has been completed or not and whether changes made to the entity should be tracked and exported on an ongoing basis. A designated portal allows you to enable the generalized data export for many maintenance objects at once as well as monitor their current export status at a glance. Refer to Generalized Export Dashboard portal for more information.
Ongoing export options are cached in various online and batch caches. In order for these options to take effect and track entity changes made by any online or batch process, the various caches must be properly flushed when these options are changed. Using the designated portals to enable entities for export triggers a 'global' flush of the caches. If the batch thread pool workers are configured to refresh their caches when a global flush is requested, then this is the only step required. If not, then the F1-FLUSH batch job should also be submitted to refresh the caches used in batch processing. Refer to Caching Overview for more information.
Initial Data Export
Each maintenance object that is eligible for the generalized data export method is associated with an initial data export batch control that is referenced on the maintenance object using the Export Batch Control option. The same common batch program is used by all these batch controls to export the entire data of an entity to files. The process is multi-threaded and produces one file per thread by default. An optional batch parameter allows for multiple smaller files to be generated per thread by setting a limit on the number of records written to each file. Refer to the File Size section for more information.
Instead of manually submitting the generalized initial export batch process for each maintenance object you have enabled for export, submit the F1-GEXPI Generalized Initial Export Initiator batch process to automatically submit them all at once.
The initial export process for each maintenance object updates the corresponding data export control record for the maintenance object to indicate that the process has started and updates it again upon completion. This allows you to view the overall status of the initial export across all enabled entities on the Generalized Export Dashboard portal.
Note that the initiator batch process only submits batch processes for enabled maintenance objects that according to their data export control record their initial export has not started yet. If you need to export one or more entities again, reset the initial export status indication on their data export control records and submit the initiator batch process again.
INIT_EXPORT[_file prefix(optional)]_[maintenance object]_[batch run]_[thread]_[thread count]_[timestamp][_file sequence].json.gz
Refer to any of the individual generalized initial export batch controls and the initiator batch control for more information.
Restricting Initial Export By Date
By default, the Initial Data Export batch process exports the entire data for an entity. In some situations, typically around high volume historical data, there may be a need to restrict the export to more recent data, for example the last few months of data.
The initial export batch process supports an optional batch parameter Restrict By Date that can be used to limit the scope of data to export. The parameter references a date field and a requested time frame in terms of number of days prior to business date. Refer to the F1-GEIXP Generalized Initial Export Template batch control for more information.
Ongoing Data Export
Data changes are tracked by the Capture Change for Ongoing Export (F1-MO-REGCHN) Maintenance Object Audit algorithm. The algorithm records the prime key of a changed entity in a designated Data Export Update table that serves as a queue of changed entities to export. The queue is later on consumed by the ongoing data export batch process.
The audit rule is added to a maintenance object when the ongoing data export option on its corresponding data export control record is enabled. In the same way the audit rule is removed from the maintenance object when the ongoing export option is disabled.
Unlike the initial export batch process that requires a batch control to be defined for each eligible maintenance object, a single batch process is used to export ongoing changes made to all entities.
-
All changes queued in the Data Export Update table are exported to a designated ongoing export file. Refer to the Managing a Large Backlog section for more information.
-
A full snapshot of the data related to the changed entity is exported to avoid heavy data merging on the target side.
-
Once exported, records are deleted from the Data Export Update table.
The process is multi-threaded and a separate file is produced for each thread by default. An optional batch parameter allows for multiple smaller files to be generated per thread by setting a limit on the number of records written to each file. Refer to the File Size section for more information.
INC_EXPORT_[batch run]_[thread]_[thread count]_[timestamp][_file sequence].json.gz Refer to Generalized Ongoing Export (F1-GEEXO) batch control for more information.
File Size
The initial export batch process produces a single file per thread by default. For some high volume entities this may result in files that are too large to manage. To produce multiple and smaller files for a specific entity, limit the number of records written to each file by setting the corresponding parameter on the initial export batch control defined for the entity. The same parameter may be provided when submitting the Initial Export Initiator batch process, in which case the initiator value is used only when a corresponding value has not been defined on the entity’s specific batch control record.
In the same way, the ongoing export batch process produces a single file per thread by default. To produce multiple and smaller files, limit the number of records written to each file by setting the corresponding parameter on the batch control.
To avoid the creation of too many files by a single batch run, the system sets a maximum limit of around 500 files per run. When the requested number of records per file is determined to cause the number of generated files to exceed the system limit, the actual value used is adjusted to meet the system limit.
Managing a Large Backlog
When a large backlog of changes accumulates in the ongoing export queue for some reason, the next batch takes longer to export which delays the downstream import step. A better option is for the backlog to be cleared in smaller "chunks", allowing the downstream process to import them as they are made available.
You may limit the number of records the batch process exports using the Thread Processing Limit batch parameter. When specified, the number of records exported by each thread is capped by the specified limit, leaving the remaining records to be consumed by subsequent batch runs. Instead of waiting for the next scheduled batch run, a new batch process may be automatically submitted, if explicitly requested to do so using the Automatic Backlog Clearance batch parameter.
It is important to ensure that the backlog clears gradually and that the queue resumes its normal size in a timely manner. The processing limit must therefore be set with an appropriate value that would promote proper clearance of the queue. To do so, at least 20% of the queue, and no less than 100,000 records, must be consumed by each batch run across all threads. If the specified limit does not meet the minimum clearance requirement then the processing limit is adjusted accordingly.
Record Format
Data is fetched and exported directly from the database in bulk read operations for performance reasons. For that reason, the structure used does not reflect the logical data model of the entity but rather its physical list of tables. Data for a given instance is organized by tables followed by rows in each table and for each row its list of fields in JSON format.
The following describes the format and structure used:
{
"OBJ": "<mo name>",
"TIMESTAMP": "<export time in ISO format for example 2019-07-25T11:06:04.740615Z>",
"PK1": "<mo pk1 value>",
"PK2": "<mo pk2 value if any>", ← PK2-5 should only be included when applicable
"PK3": "<mo pk3 value if any>",
"PK4": "<mo pk4 value if any>",
"PK5": "<mo pk5 value if any>",
"DELETED": true, ← should only be included when the entity is deleted
"DATA":
{
"<MO table name 1>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>},...
],
"<MO table name 2>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>}
],...
"<MO table name n>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>}
]
}
Notes about field values and formats:
-
All fields for a row are included even when the field is empty or null.
-
All string values are trimmed of excess trailing spaces but if a field is empty it exported as an empty string "" and not null.
-
An empty array is used for a table node when no records exists for the entity in the table.
-
Date/time information is converted to UTC time zone and exported in ISO format for example 2019-07-25T11:06:04.740615Z.
-
Deletes have an explicit indicator in the header.
Order of Consuming Files
It is important to apply all the initial export files for a maintenance object before applying ongoing change files to ensure data consistency.
-
Apply all initial data export files before ongoing export files.
-
Apply initial files for a maintenance object in run number order.
-
Apply ongoing export files in run number order.
-
If a new initial export is available the file consumption procedure should be changed temporarily as follows:
-
Stop consumption of ongoing export files.
-
Apply the new initial export files.
-
Resume consumption of ongoing export files.
-
Recover from a Lost Ongoing Export File
The ongoing export batch process keeps a backup of all entity keys, that were exported on a specific batch run, in a designated backup table. In rare situations where an ongoing export file is deleted or becomes corrupted before it gets processed, the backup table may be used to identify the missing changes and export them again.
Use the Restore Generalized Export Keys (F1-GERST) batch process to recover from this situation. The process identifies the entities that were exported during a specified batch run and adds them back to the ongoing changes queue from the backup table. The entities would then be exported again wen the next ongoing export runs. This method does not restore the exact content of the original file that was lost as it cannot be reproduced. Instead, the process ensures that the entities that were included in the lost file would be exported again.