Manage Datasets
Datasets provide the criteria for the data to be used in an algorithm (such as, a Calc). When an algorithm is running, either manually or in a scenario, it pulls the data defined by a dataset from the population defined by a filter.

Note: Datasets use procedures called "get methods" to pull data from the population.
On this page:
Dataset Fields
A dataset consists of one or more dataset field objects. Each dataset field object can be configured independently to access data from different time periods. Where time series data is queried, datasets allow dynamic aggregations to be done at runtime. The type of aggregation is decided by the method chosen and attached to the dataset field. Each dataset field generates metrics based on the type of method chosen.
Dataset Fields columns within a dataset record have the following basic characteristics:
- Enabled Flag: Allows fields to be disabled and their processing skipped. (Default: Enabled)
- Name: A user defined named for the field. Every reference to the dataset in a calc that it is bound to is done using the field name.
- Time Window Name: A reference to the time window configured in the time windows section that gets attached to a field. Each field has its own time window.
- Level: Each field is associated with a level, which is a point type code. Levels
allow a dataset to go up the relationship hierarchy and pull data from parent points and
make that available in the same dataset. Datasets require a level named
core, which must be set to the dataset's point type code. Additional levels may be added to get data from parent points. There is no limit on the number of levels, but performance may suffer if too many levels are added. - Get Method: A get method operates on the data for the time window attached to the field and aggregates it into several metrics.
Processing Basis
Processing Basis controls the level of aggregation as well as how the data set should evaluate the time period for which it will be processed. For example, if the processing basis is set to daily and the dataset is run for three days, it will apply the daily basis and run the dataset once per day. Additionally, all data will be aggregated up to the daily level so if the dataset is used to return interval level consumption, the dataset output will be aggregated up to the daily level.
Note: Processing mode is set in the Options section of the Dataset XML Editor, which corresponds to the options element in the dataset XML definition:
<options>
<option name="processing_basis" value="DAILY" ></option>
</options>
Valid processing basis include:
- DAILY
- WEEKLY
- MONTHLY
- YEARLY
- CUSTOM
- QUARTERLY
- INT_1: one second
- INT_60: one minute
- INT_300: five minutes
- INT_900: fifteen minutes
- INT_1800: thirty minutes
- INT_3600: one hour
Processing Basis Example
If you were to create a daily processing basis that started on January 1, and ended on January 31, the dataset would run 31 times in a loop with each slice being the day that the dataset is ran.
Resultant time slices: (1/1,1/1), (1/2,1/2), …, (1/31,1/31).
Manage Datasets Page
The Manage Datasets page provides fields and controls for filtering existing datasets and a data table that lists existing datasets. The Manage Datasets data table displays datasets based on the Type selected in the Search Pane.
Navigate to the Manage Datasets page by selecting Datasets from the Analytics section of the Manage menu. The datasets data table will load with the datasets that match the selected Type and Role or have no associated role.
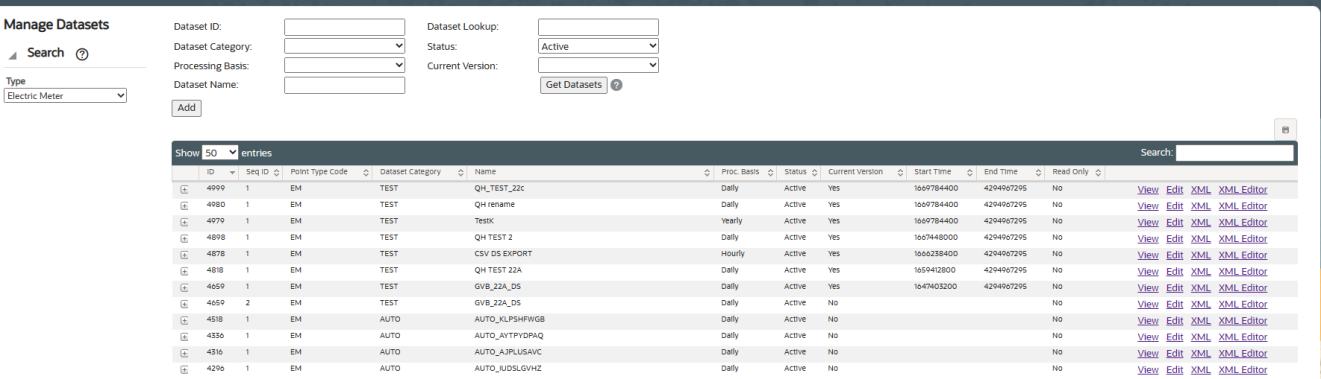
Datasets Fields and Buttons
The top section of the Manage Datasets page allows you to search for datasets matching criteria added to the fields:
- Dataset ID: System generated dataset ID.
- Dataset Category: Assigned category for dataset.
- Processing Basis: Dataset processing basis is the type of data that the dataset is acting on (for example, Daily, Monthly, or Weekly data).
- Dataset Name: A dataset's "friendly" name.
- Dataset Lookup: Database lookup value. This is usually the dataset name without spaces in all caps.
- Status: Whether the dataset's status is set to Active or Inactive.
- Current Version: Whether the dataset is the current version in use.
- Get Datasets: Initiate the search for datasets matching the criteria set in the fields. Alternatively, you may press Enter when you finish adding content to a field and then click the Submit link when the system displays a message that the search criteria has changed.
- Add: Opens the Create Datasets dialog box from which you may create a new dataset.
Data Table
The data table contains information about the datasets. The table contains the following columns:
- ID: System generated dataset ID.
- Sequence ID: Dataset's sequence ID, which is its version number.
- Point Type Code: Code representing the object type (for example, EM for electric meter).
- Dataset Category: Category that a dataset is assigned to.
- Name: Dataset name.
- Processing Basis: Dataset processing basis is the type of data that the dataset is acting on (for example, Daily, Monthly, or Weekly data).
- Status: Whether the dataset's status is set to Active or Inactive.
- Current Version: Whether the dataset is the current version in use.
- Start Time: Date/time when the dataset was set to current.
- End Time: End date for the dataset. For active datasets, the end time is set to an arbitrary end date used in the system; when a new version of the dataset becomes current, the end time is updated to equal the start time of the new version.
- Read Only: Whether the dataset is read-only or may be edited.
- View link: Opens the View Datasets dialog box, which displays the same data as provided in the data table row as well as buttons and links that allow you to edit or configure the dataset.
- Edit link: Opens the Manage Datasets dialog box, which displays an editable view of the dataset information.
- XML link: Displays the Dataset Definition dialog box, which shows the configuration XML for the dataset.
- XML Editor link: Opens the Datasets XML Editor.
- Expand button: Reveals the data in the data table for each table row as well as the following:
- Dataset Role: Setting for a role that is applicable to the dataset.
- Dataset Description: Optional setting that describes the dataset purpose.
- Lock Status: The dataset is locked to editing.
- Minimize button: Hide extra information for each data row.
Note: The data table may be exported by clicking the export data icon located above the table's search field.
Add Datasets
To add a dataset:
- Click Add Dataset on the Manage Datasets page. The Create Datasets dialog box will open.
- Do the following:
- If the dataset should be applicable only to the selected Role, select the Dataset Role.
- In the Name field, enter a descriptive name. For example, Hourly Validation.
- In the Dataset Lookup field, enter a value for dataset lookup. The dataset lookup value can be any unique alphanumeric value with uppercase text and without spaces. A common practice is to use the dataset name without spaces. For example, HOURLY_VALIDATION.
- In the Processing Basis field, enter the data processing basis (for example, Daily, Monthly, Weekly).
- In the Dataset Description field, enter a short description of the dataset function. For example, This dataset performs validation on hourly data.
- From the Status drop-down list, select whether the filter is Active or Inactive.
Note: Datasets cannot be deleted through the user interface, but may be set to inactive.
- Leave the Dataset Definition blank. The Dataset Definition XML is typically defined with the Dataset XML Editor. However, if you wish to start with the Dataset Definition XML from another dataset, you may copy it and paste it in the Dataset Definition field.
- Click Save. The Create Datasets dialog box will close.
Note: Click Cancel to close the dialog box without saving the dataset; a dialog will open asking you to confirm that you want to close the Create Datasets dialog.
View Dataset Information
The View link in a dataset data table row launches the View Dataset dialog box, which displays the dataset information and allows you to view the dataset definition, edit the dataset information, create a new version of the dataset (clone), copy the dataset, or process the dataset.
Fields
- ID: System generated dataset ID.
- Sequence ID: Dataset's sequence ID, which is its version number.
- Dataset Role: Optional setting for a role that is applicable to the dataset.
- Point Type Code: Code representing the object type (e.g., EM for electric meter).
- Category: Assigned dataset category.
- Name: Dataset name.
- Dataset Lookup: Database lookup value; usually the dataset name without spaces in all caps.
- Processing Basis: Dataset processing basis is the type of data that the dataset is acting on (e.g., Daily, Monthly, or Weekly data).
- Dataset Description: Optional setting that describes the dataset purpose.
- Status: Dataset status (Active or Inactive).
- Lock Status: Whether the dataset is locked to editing.
- Start Time: Date and time when the dataset became active.
- End Time: End date for the dataset. For active datasets, the end time is set to an arbitrary end date used in the system; when a new version of the dataset becomes active, the end time is updated to equal the start time of the new version.
- Read Only: Whether the dataset is read-only or may be edited.
- Dataset Definition: Contains the XML link, which opens the Dataset Definition dialog box.
Buttons and Links
- Edit: Opens the Manage Datasets dialog box.
- Clone: Creates a new version of the dataset. The clone's Sequence ID is the original dataset's Sequence ID plus one; all other dataset information is the same. Cloning allows you to keep the initial dataset active while working on modifications to the dataset parameters.
- Copy: Creates a copy of the dataset having a unique ID.
- Set Current: Sets the Current Version flag to Yes.
- Cancel: Closes the dialog box.
- Execute Now: Processes the dataset.
Manage Dataset Information
The Manage Datasets dialog allows you to edit the variable information fields. To access the dialog, click the Edit link on the dataset data table row or the Edit button on the View Datasets dialog box.
Fields
- ID: System generated dataset ID.
- Sequence ID: Dataset's sequence ID, which is its version number.
- Dataset Role: Optional setting for a role that is applicable to the dataset.
- Point Type Code: Code representing the object type or entity (for example, EM for electric meter).
- Category: Assigned dataset category.
- Name: Dataset name.
- Dataset Lookup: Database lookup value; usually the dataset name without spaces in all caps.
- Processing Basis: Dataset's processing basis (for example, Daily, Monthly, Weekly).
- Dataset Description: Optional setting that describes the dataset purpose.
- Status: Dataset status (Active or Inactive).
- Lock Status: Whether the dataset is locked to editing.
- Start Time: Date and time when the dataset became active.
- End Time: End date for the dataset. For active datasets, the end time is set to an arbitrary end date used in the system; when a new version of the dataset becomes active, the end time is updated to equal the start time of the new version.
- Read Only: Whether the dataset is read-only or may be edited.
- Dataset Definition: Contains the XML link, which opens the Dataset Definition dialog box.
Buttons and Links
- Save: Saves any changes to the dataset information; the button is only active when a change has been made in one or more of the editable fields.
- Clone: Creates a new version of the dataset. The clone's Sequence ID is the original dataset's sequence ID plus one; all other dataset information is the same. Cloning allows you to keep the initial dataset active while working on modifications to the dataset parameters.
- Copy: Creates a copy of the dataset having a unique ID.
- Set Current: Sets the Current Version flag to Yes.
- Cancel: Closes the dialog box.
- Execute Now: Processes the dataset.
Manage Dataset Information
The Manage Datasets dialog allows you to edit the variable information fields. To access the dialog, click the Edit link on the dataset data table row or the Edit button on the View Datasets dialog box.
Fields
- ID: System generated dataset ID.
- Sequence ID: Dataset's sequence ID, which is its version number.
- Dataset Role: Optional setting for a role that is applicable to the dataset.
- Point Type Code: Code representing the object type (for example, EM for electric meter).
- Category: Assigned dataset category.
- Name: Dataset name.
- Dataset Lookup: Database lookup value; usually the dataset name without spaces in all caps.
- Processing Basis: Dataset's processing basis (for example, Daily, Monthly, Weekly).
- Dataset Description: Optional setting that describes the dataset purpose.
- Status: Dataset status (Active or Inactive).
- Lock Status: Whether the dataset is locked to editing.
- Start Time: Date and time when the dataset became active.
- End Time: End date for the dataset. For active datasets, the end time is set to an arbitrary end date used in the system; when a new version of the dataset becomes active, the end time is updated to equal the start time of the new version.
- Read Only: Whether the dataset is read-only or may be edited.
- Dataset Definition: Contains the XML link, which opens the Dataset Definition dialog box.
Buttons and Links
- Save: Saves any changes to the dataset information; the button is only active when a change has been made in one or more of the editable fields.
- Clone: Creates a new version of the dataset. The clone's Sequence ID is the original dataset's sequence ID plus one; all other dataset information is the same. Cloning allows you to keep the initial dataset active while working on modifications to the dataset parameters.
- Copy: Creates a copy of the dataset having a unique ID.
- Set Current: Sets the Current Version flag to Yes.
- Cancel: Closes the dialog box.
- Execute Now link: Processes the dataset.
Define and Edit XML with the Datasets XML Editor
To configure a dataset, click the XML Editor link in the dataset's data table row. The Datasets XML Editor dialog box will open allowing you to define the dataset parameters. The Datasets XML Editor tree view allows you to define the dataset by Options, Time Windows, Levels, and Fields.
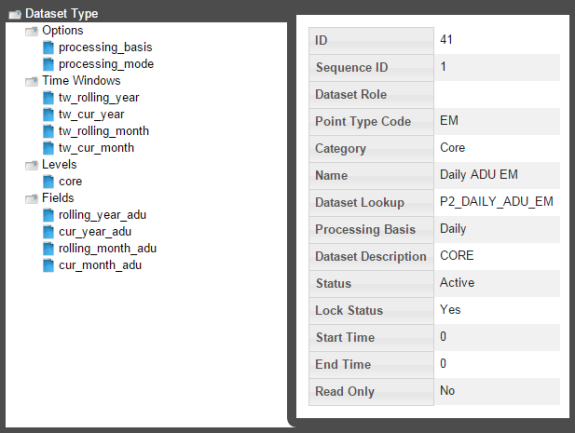
Buttons
- Save & Close: Saves the dataset in its current state and closes the Datasets XML Editor.
- Validate & Save: Validates the dataset syntax and displays any errors.
- Close: Closes the Datasets XML Editor without saving changes.
Add Options
When you select the Options heading in the tree-view, the editor will update with the Options Summary table, which lists existing options, and the Create New Options button.
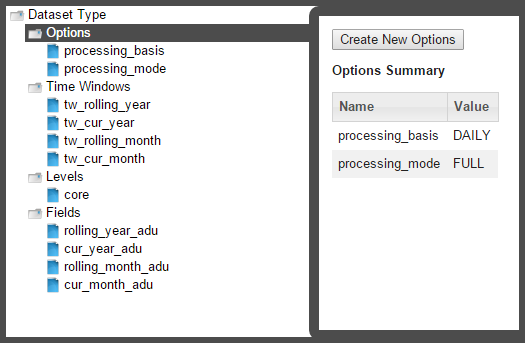
Processing Basis
The processing_basis is automatically populated with the selections chosen when creating the dataset.
Processing Mode
Processing mode is pre-defined as FULL, which is the only option currently available in the XML Editor. It allows dataset processing to be time based such that given a time period, the dataset processing will take place for all time slices of the time period being run.
Note: A processing mode of DATADRIVEN may be used via backend methods, but that is beyond the scope of this documentation.
Add Time Windows
Time Windows function much the same in datasets as in filters. However, in datasets, you have to note the dataset processing basis, which tells the dataset how to interpret the days you process the data for. In the example above, the time basis is DAILY, so it will slice/interpret the processing dates on a daily basis. However, if you were to use WEEKLY, it will interpret the processing dates as the entire week and the data start date and end date will not be on the days that you selected to process, but rather the week starting on Sunday and ending on Saturday.
Add Levels
Note: Core is data on the most fundamental level to be analyzed and saved. If core is a meter, everything above it are considered levels. If you start an analysis for premise, then premise becomes the core and everything above it are levels.
To create a new level:
- Click Create New Levels and then complete the information fields.
Note: The Point Type Code field is the system code for a point type. System codes may be found using the Administer Facts page.
- Select Cache for improved performance.
Note: Data stored in a cache is data that is computed earlier and can be used later in a calculation, which otherwise would require it to be recalculated. The performance is only improved in cases where the points in a batch associated with a distinct parent points are > 10.
Add Fields
Fields allow you to select the type of fact to pull and how to pull it.
To add a field:
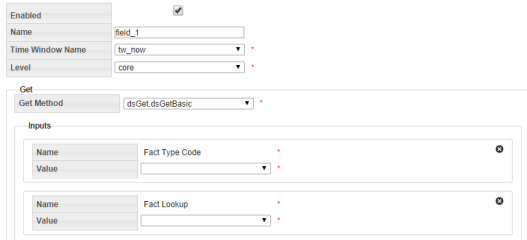
- Select Fields in the tree-view and click Create New Fields. If necessary, modify the name of the new field, then select the field to enable field criteria editing.
- Edit the field criteria:
- Enabled Flag: Allows fields to be disabled and their processing skipped. (Default: Enabled)
- Name: The field name.
- Time Window Name: Drop-down list that allows you to reference one of the time window configured in Adding Time Windows. Each field has its own time window.
- Level: Drop-down list that allows you to reference a level configured in the Addling Levels section.
- Get Method: Drop-down list allows you to select a get method to operate on the data.
Get Methods
Each Get Method accepts a list of inputs and generates a list of output or metrics. Every data point in can be uniquely identified by a 4 member
tuple: point, fact, time, value.
In the context of a dataset, the point is provided by the filter attached to the
dataset, the fact comes from the list of inputs to the Get Method,
time is provided by the time window attached to the field and passed on to the Get
Method, and value is the raw fact value(s) that would be aggregated into a metric.
Metrics then are the outputs of a Get Method.

Your choice of Get Method depends on what type of fact you want to pull and will define how the fact will be aggregated in your dataset output.
There are two major groupings of Get Methods: Basic Gets and Multi Gets.
- Basic Gets allow you to pull data for one selected fact.
- Multi Gets pull data based on a fact category. The Multi Gets will return the “best” fact from the category. Facts are grouped together by fact_categories and, within a fact category, each fact has a fact_sequence, which sets the priority of the fact; the best fact will always be the one with the lowest fact_sequence value (1 is the highest fact sequence). For example, with regard to an electric meter, Premise has a Fact Sequence of 5 and Account has a Fact Sequence of 6.]
Use Get Methods
Within the category daily kWh, for example, consumption may be derived, aggregated, interpolated, and so on. In order to account for all possible consumption types, you must use a dsGetBasic for each of the facts or use a dsGetMultiBasic on the entire fact_category and it will evaluate which of the facts has the highest fact_sequence priority.
Despite evaluating several facts in a dsGetMulti_, it will always return just one value (the best fact). If you want to return all of the facts, you will need to use dsGetValue and input a fact_category. Each dsGet_is equipped with its basic required fields; however, they all have additional panels that you can configure by clicking Add Inputs.
The following are descriptions of the Get Methods:
dsGetAttribute: Get attribute facts. Use the drop-down list to select the desired Fact Lookup. Aggregation mode is an additional field that allows you to select whether you want the first relation or the last relation found for that fact (if there happens to be more than one value within your selected time window).

dsGetNumAttr: Get numeric attribute facts. Similar to dsGetAttribute; choose the fact lookup and aggregation mode, if applicable.

dsGetRelation: Get the relation facts. Similar to dsGetAttribute; choose the fact lookup and aggregation mode, if applicable.

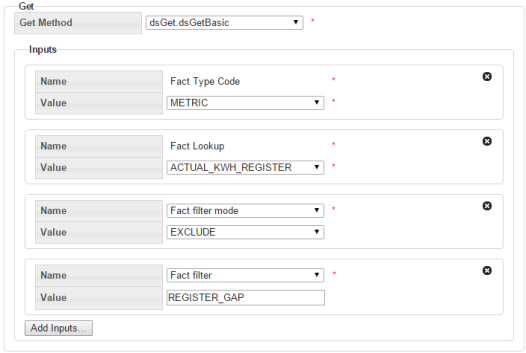
dsGetBasic: dsGetBasic is able to pull many different fact types. It is used for all fact types that do not fall in the relation, attribute, and numeric attribute categories (i.e., time series and interval facts; see ).

Note: You must specify the fact_type_code before choosing a fact_lookup.
For time series gets, there are inputs that help identify which fact’s time series data would be utilized. In dsGetBasic, fact type code (FTC) and Fact Lookup (FL) help uniquely identify a single fact. The third arrow labeled as behavioral input controls different behaviors as described below.
- Fact Filter: Fact filters allow you to exclude certain time periods from being included (or excluded) in the aggregation. Fact filter allows multiple facts to be specified using the following notation:
FactTypeCode:FactLookup,FactTypeCode,FactLookup.When multiple fact type codes are specified the implicit exclusion or inclusion
operation is OR.
Note: Behavior changing inputs are optional.
dsGetBasic also has many different additional inputs. The Fact filter and Fact filter mode input options are used in combination to selectively remove points from being evaluated. dsGetBasic has a mandatory primary fact input that you specified first; however fact filtering gives you the ability to exclude certain values of the mandatory fact.
For example, if your primary fact is kWh consumption, and you choose fact filter mode to exclude and the fact filter to be register validation gaps, then you will be excluding all kWh consumption values for days on which there was a gap.
Name filter options include:
- Hours to search backward/forward: For the most part, the system implies a midnight time-stamp for most data and the
dataset will search for midnight timestamps only. However, for facts such as register
reads, their reads may not necessarily come in at exactly midnight, so with these
functions you can expand the search to “hours before/after midnight”. Midnight timestamp mode:
Midnight timestamp mode allows reads that are within a specified threshold (typically +/-
1 hour of midnight) and treat it as midnight. For example, a read that comes in at 11:53
PM is considered to be a midnight read as is a read that came in at 12:53 AM. In both
cases, no interpolation is done and the register value is accepted without any adjustment.
However, if a read comes in at 10:55 PM or at 1:05 AM, it will not be considered a
midnight read since it would be outside of the +/- 1 hour threshold; reads outside of the
threshold will result in data interpolation to derive daily consumption.
Note: The threshold +/- n hour value is configurable.
-
Maximum ‘nth metric to compute’: This feature is to accommodate for facts that may not necessarily occur every day or on a regular basis. So in these situations, you can create a time window that is a wide enough net to grab a large number of occurrences/events of these facts. However, if your goal is to say, only aggregate the first five occurrences and ignore the rest, then you can specify that in this section.
- dsGetValue: The dsGetValue is used to get a value with no aggregation. You can use dsGetValue to specify
a fact_category or a specific fact_lookup. However, regardless of the time window, this
will only return the first value of each fact (no aggregations).


Non-Time Series Get Methods
| Get Method | Applicable fact_type (Input) | Primary Output |
|---|---|---|
| dsGetRelation | Relation | Parent point object with all point table columns available as metrics. |
| dsGetMultiRelation | ||
| dsGetNumAttr | Numeric Attribute | Numeric attribute value (float) |
| dsGetMultiNumAttr | ||
| dsGetAttribute | Attribute | Text attribute value (string) |
| dsGetMultiAttribute |
Time Series Get Methods
| Get Method | Applicable fact_type (Input) | Primary Output | Pre-Aggregation | Midnight Handling |
|---|---|---|---|---|
| dsGetBasic | Metric, Event, List, Interval, Count (MELIC) | Count, Sum, Average, Standard Deviation, Min, Max, Nth Max, Nth Max Date, Nth First Value, Nth Last Value, Nth First Date, Nth Last Date, Nth Cumulative Value | No. If multiple values are available for the same day (as in multiple registers for ACTUAL time basis) all values get included. | Yes, hours forward and hours backward allow looking within a configurable threshold of buffer around midnight; actual register timestamp can be retrieved using ACTUAL mode. |
| dsGetMultiBasic | Metric, Event, List, Interval, Count (MELIC) | Same as dsGetBasic. | Pre-aggregation support to choose a single value when multiple values exist. | Same as dsGetBasic. |
| dsGetMedian | Metric, Event | Value | ||
| dsGetMultiMedian | Metric, Event | Value | ||
| dsGetSegment | Segment | Segment | ||
| dsGetQuantile | Metric, Event | |||
| dsGetValue | Metric, Event, List, Interval, Count (MELIC) | Value; first value without aggregation. | N/A | Same as dsGetBasic. |
| dsGetMultiValue | Metric, Event, List, Interval, Count (MELIC) | Value, Date Found, Fact Lookup | Pre-aggregation or pre-selection allows a single value to be chosen when multiple exist. | Same as dsGetBasic. |
Clone a Dataset
The clone function, which is found in the View Datasets and Manage Datasets dialogs, creates a new version of the dataset; the Sequence ID will be incremented by one. The clone is unlocked, which allows it to be edited while the original is locked and ready to be processed. Once the new version is ready to be put in production, the previous version's End Time is set to the new version's Start Time.
To clone a dataset:
- In the View Datasets or Manage Datasets dialog, click Clone.
- Edit the clone.
- When the clone is ready to be deployed, open the Manage Datasets dialog and click Set Current. This will set the original dataset's Locked status to Unlocked and the clone's Locked status to Locked.
Copy a Dataset
The copy function, which is found in the View Datasets and Manage Datasets dialogs, creates a new dataset with a unique ID. Copying allows you to start a new dataset from an existing one. The copy has a Sequence ID of 1 since it is the first version of a new dataset.
View the Dataset Definition XML
From the Dataset Definition dialog box, you can view or edit the XML that is produced by the Database XML Editor. This allows you to quickly modify a parameter without needing to drill down in the editor.
Dataset XML
<?xml version="1.0" encoding="utf-8"?>
<dataset xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="dataset_type" xsi:noNamespaceSchemaLocation="dataset.xsd">
<options>
<option name="processing_basis" value="DAILY" />
<option name="processing_mode" value="FULL" />
</options>
<time_windows>
<tw xsi:type="time_window_offset_type" name="tw_now" desc="tw_offset">
<start_offset offset_of="data_start_date" unit="day">0</start_offset>
<end_offset offset_of="data_end_date" unit="day">0</end_offset>
</tw>
</time_windows>
<levels>
<level ptc="ACCNT" name="core" agg_method="first" />
</levels>
<fields>
<field xsi:type="field_type">
<name>rate</name>
<tw_name>tw_now</tw_name>
<level>core</level>
<get get_method="dsGet.dsGetRelation">
<inputs name="fl" value="RATE" desc="" />
</get>
</field>
</fields>
</dataset>Process Datasets
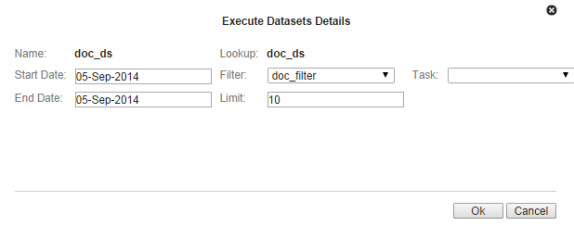
To process the datasets:
- Click View or Edit and then click Execute Now. The Execute Datasets Details dialog box will open:
- Select the process Start Date
and the process End Date, which are used as Data Start Date and
Data End Date in the time windows.
Note: You must select a filter to run your dataset on; the filter will decide which points for which to retrieve data.
-
Do one of the following:
- Click OK to process the dataset .
- Click Cancel to close the dialog box without processing the dataset.