Running and Troubleshooting Batch Processing
This section provides guidelines for running and troubleshooting batch processing with Oracle Utilities cloud services, including:
Introduction
Batch jobs are used for several key purposes in Oracle Utilities cloud services - to load data from files, to process new data that has been loaded/entered, to monitor status of various objects, etc. Batch jobs can be run individually on an ad hoc basis, or as part of a scheduled batch job stream with dependencies. The system produces logs during batch run execution, and it's important to understand how to view and interpret these logs.
Especially during implementation there are some common problems that may crop up during execution of jobs and streams. The following guide is designed to help you understand how to run batch and troubleshoot batch job problems, and describe important triage steps to perform before logging a Service Request (SR) for a batch problem.
Batch Basics
The system provides multi-threaded batch processing capability for many jobs. To support this, every cloud service environment has two Threadpool Workers (TPW) - Default and NOCACHE. Most jobs should be run with the Default TPW, but there are a few that need to use NOCACHE (Jobs related to CMA for configuration migration, jobs like K1-RIUSP or K1-ILMAD that are building database structures and require longer than normal time for single operations). You have the capability to specify how many threads from the TPW should be assigned to your job submission. There is a capability for a user to 'Restart TPWs' in case of a severe problem where jobs are not getting started - this can happen especially during implementation when data quality is variable.
Each time you run a particular batch, it gets a unique run number and has a status (Pending, In Progress, Complete, Error), and has one or more threads (each thread has a status as well, Pending, Complete, Error). A thread can have multiple instances if for instance the first instance errored out, and you restarted the job. Sometimes you will want to ensure that no more instances are created for a run, if for example you need to reset the parameters of the job. Details of each batch run are displayed on the Batch Run Tree.
The service also provides the capability to define batch job streams - a linked sequence of batch jobs to run either on a pre-set schedule or ad hoc, with ability to set dependencies - i.e. only start job C after both job A and job B have completed successfully. A stream may fail to complete if one of the jobs has a problem - so if that happens you need to investigate the outcome of the job.
Note that this guide assumes familiarity with the Oracle Utilities Application Framework batch framework. The online documentation can provide much more detail on all the online transactions related to batch processing.
Important Parameters
The system provides many batch jobs, and they are defined in the Batch Control table. There are common parameters applicable for all batch jobs, and most jobs also have unique parameters as well.
• Override Number of Records to Commit: We recommend not overriding to a number greater than 1 (i.e. don't override to a bigger number thinking that will help - the infrastructure works best to commit frequently)
• Thread Pool Name: Parameter used to define the name of the thread pool worker used with the batch process. Valid values are DEFAULT and NOCACHE. As stated above, be aware of the jobs that should be run with NOCACHE TPW.
• NOCACHE TPW should only be used with Conversion, Content Migration Assistant (CMA) and Information Lifecycle Management (ILM) related batch jobs such as K1-RIUSP, K1-ILMAD, F1-MGOAP, F1-MGTAP, and so on.
• NOCACHE TPW should not be used for batch jobs related to Generalized / Specialized Data Export or any other functional batch jobs.
Leave the Thread Pool Name parameter blank to use the DEFAULT TPW.
Batch Performance Factors
Batch performance is dependent on a number of factors, and these factors can be changing rapidly during implementation, so it's important to have a mental checklist to review as batch processing is being tested:
• State of data conversion - typically data conversion involves multiple iterations, and data quality will vary (hopefully increasing steadily!). We strongly recommend use of the validation batch programs to do statistical sampling of the loaded data, to help identify problems such as incorrect or missing foreign keys - you can review the results on the FK Validation Summary and Validation Error Summary portals If there are data quality issues, they will often result in errors during various types of batch processing. Be aware of what's happening with data conversion.
• State of indexes and the database - during implementation and data conversion iterations, frequently tables are being truncated and re-loaded, and indexes may be disabled then re-built. Problems will occur if any indexes get into 'unusable' state. Ensure the data conversion team always follows necessary steps, and gives official go-ahead before running your jobs in an environment where data conversion is active. To check for unusable indexes you can run this query: SELECT INDEX_NAME, TABLE_NAME FROM all_indexes where TABLE_OWNER = 'CISADM' and STATUS = 'UNUSABLE' ORDER BY TABLE_NAME
• Extensions - new scripts and algorithms may have unexpected impacts on batch processing if they have not been fully designed and tested for scalability. Best practice is to review the explain plans for all new SQL used in extensions, to ensure that new code will perform suitably.
• Other concurrent processing - during implementation often various teams are using one environment and trying various jobs. Be aware of what other activities may be happening concurrently - those activities may impact your job in some way.
• Multi-threading setup - while many jobs are designed to be run multi-threaded (to divide the workload into roughly equivalent groupings to process in parallel), the performance characteristics are not necessarily linear. By this we mean that doubling the number of threads for a job will not always cut the processing time in half. In general the best strategy is to start with small data volumes and fewer threads to establish a baseline of data quality and performance, then increase in incremental steps to tune performance.
Frequently Asked Questions for Common Batch Issues
Q1) Batch job results in error, what should I do?
First step is review the Batch Run Tree. The Batch Run Tree shows the details for the Run, Instance(s) and Threads, and is where you can access batch logs (stdout and stderr).
Review the status of the threads by expanding the tree fully. In some cases the thread details will show the error message that was thrown and that may be enough to understand the problem.
Example 1:

In the example above, the run is in error, the thread is in error, and the error message is shown clearly under the instance. In this case the problem was with a batch date parameter.
To get more details, download the log files by clicking on the links and search for terms such as 'error ' or 'ORA-' (for database error code).
Example 2:

Above is an example of an error in a batch log - in this case a problem during a CMA job. Note that here the key for a Migration Object is given, and is likely a good place to look for something anomalous.
To get more details, download the log files.
Example 3:

Here the run tree shows that the thread ended abnormally. Stderrr shows:
2021-08-04 11:39:10.267-0700 [83] ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper Exception occurred while getting connection: oracle.ucp.UniversalConnectionPoolException: Cannot get Connection from Datasource: java.sql.SQLRecoverableException: Listener refused the connection with the following error:
ORA-12514, TNS:listener does not currently know of service requested in connect descriptor
The above example illustrates a connectivity issue. In cases like this, please raise a SR and provide screenshots of batch job submission with parameters, batch run tree (expanded) and both logs (STDERR and STDOUT).
For Batch logs, Oracle maintains logs data for 14 days only, so we recommend that you download them promptly.
Please note that a batch run may complete successfully even though certain records may have encountered recoverable errors (and in certain cases may create ToDo entries for follow-up). So particularly in early batch testing it is important to examine the batch run tree for each job to verify the execution details - it's not necessarily enough to just see that the batch completed.
Important TIPS:
If the logs are not pointing towards the exact error, logs are emptied or logs don't guide , please follow the steps below:
• Make sure the past runs of batch are marked as DO NOT ATTEMPT RESTART on the Batch Run Tree, Run Control tab.
• Re-submit the batch job with single thread and check the following two boxes on the batch job submission

• Once the batch job results in error, go to batch run tree and download and review the logs.
• Make sure to populate MAX-ERRORS / maxErrors batch job parameter (where applicable) with the small number like 10. This parameter will abort the batch run after the batch encounters 10 errors. You may increase this number as per your need, if required.
• DO NOT run the CMA batch jobs with all traces ON, unless it is deemed necessary.
• If there is a need to raise a Service Request, please provide screenshots of the output from the Prepare Issue Details feature (see Prepare Issue Details in the Administrative User Guide), batch job submission with parameters, batch run tree (expanded), and both logs (STDERR and STDOUT).
Note: If the errored batch is custom-built, please contact the project implementation / support team.
Q2) After a batch results in error and after re-submission, why does the batch run tree shows the same batch number and batch run tree showing multiple batch instances?
By default, a re-submission of an errored job will cause the previously errored run to re-start. Sometimes that is not what you would like to have happen, so to prevent a restart and actually create a new batch run, you need to go to the Run Control tab page of last Batch Run Tree, and check the 'Do Not Attempt Re-Start' box (example below).

Above is an example where the 'Do Not Attempt Restart' has been checked - this will ensure the next job submission will create a new Batch Number.
Q3) The batch run tree shows that there was a 'severe Java error' - how can I get further details?
In this case, even the Batch logs may not provide the detail - most often the underlying case is a data problem, such as a bad or missing foreign key that the job is trying to access, causing a null pointer exception. If so, you will need to log an SR and Dev Ops will need to review technical logs to find the underlying error.

Above is a sample Batch Run Tree with a Java error, please follow the 'Important TIPS' for troubleshooting shown under Q1.
Q4) I have submitted batch online and the batch job submission still shows batch status in Pending?
There could be several reasons for this situation:
• All available threads in the TPW are currently busy with another job. To check for this, go to the Batch Queues page and verify if any running jobs.
• The TPW may have been (or need to be) restarted because of a previous problem. If already Restarted, your job should start within minutes. Note that the Restart action takes a bit of time because it may need to interrupt running jobs, cleanly shut the batch server pods down, then start them up again. In order to restart, please run the application in debug mode where TPW restart option is available (as seen below)

• Check the desired execution date/time, it should not be in future.
Q5) I have cancelled the online batch submission but batch status still shows as Pending Cancel?
When you cancel the running batch job with multiple threads, the batch job tries to revert the work done or in progress after the last commit executed. In some cases, where batch job ran with many threads, it will take 4-5 minutes to complete the background process and change the status from pending cancel to canceled. During the process, it is recommended that implementation should not go immediately to restart the TPW. Even if the status don't change after TPW restart, please raise an SR for cloud operations help.
Q6) I want to submit a batch, but I don't know what batches are currently running?
To check this, go to the Admin → B → Batch Queue Portal page and verify if any running jobs. If you see batch jobs already showing in pending status that means you have consumed all the available threads allocated and no capacity available to submit any more batches.

Q7) How do I cancel jobs submitted by SaaS Batch Scheduler?
A Scheduler Batch Stream executes the batch controls in defined chronological order, and it creates batch job submissions with the submission method "Scheduled". Batch job submission with this status can not be canceled through the cancel option on batch job submission page. In order to cancel the Scheduler Batch Stream, you have to go to Scheduler Batch Stream Operations portal page, then select the running stream and perform cancel operation. This will result in canceling the overall stream including current running batches.
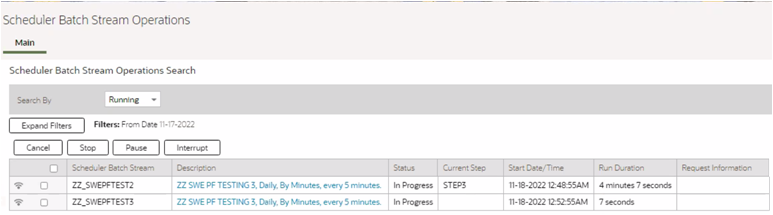
Q8) Why do I see multiple instances of F1-BTMON batch in batch job submission?
F1-BTMON is the batch probe - which is run automatically as part of the cloud service monitoring of each environment, to verify that batch is able to execute. This job does a small amount of transitory database access, and if it were to fail alerts would be created for the Cloud Operations team to investigate. It does not use any of the Default or NOCACHE threads so has no impact on your workloads.
Q9) I am getting batch completion emails from multiple environments, Can i get environment name inside the email contents?
Yes, from 21A onward, implementations can add a "Domain Name" Installation Message type (on the Messages tab of the Installation Options-Framework portal) and provide the description that identifies the environment. That description will be part of the email received as part of batch completion as well as on the application interface.

Above is the Installation Options - Framework list of Messages - add a unique value for "Domain Name" in each environment where batch is running.

Above is a sample batch notification email showing the Domain Name ("Oracle Internal Environment").
Q10) Can I run any job with many threads?
No, not all jobs support multi-threading. Most Batch Controls will indicate if they support it or not. If the work to be done can be cleanly divided, then multi-threading is available. There are some jobs that take a 'set-based' approach which need to run with a single thread.
If the batch control does not support multi-thread and related to upload / download and you submit the batch with more than one thread, only one thread will process, rest of the threads will start and complete immediately without process any record.
If the batch control does not support multi-thread and not related upload / download, you may see the following error in the log:

Q11) Batch job submission shows 'Started' but the batch run tree shows status as pending. What is wrong?
Typically this is a temporary situation. The reason for the delay is that in a multi-threaded submission the first thing that is done is the division of work across all the threads via an 'outer select' to get all eligible records - the threads can't get started until the 'work assignments' are complete.
Q12) I have a job that I'm running with many threads, and all threads show 'complete' except one which appears to be 'stuck' - what can I do?
We have seen a couple reasons for this situation - sometimes it really is not 'stuck' - but it is doing a large amount of work on a single record (for instance billing an Account with many Service Agreements). If the record count on the thread remains at the same number for more than 5 minutes, you may have to restart the TPW and or cancel the running batch. After restart, you may submit the batch job again without checking the 'do not attempt to restart' option on the last batch run tree, to restart against what's left to process.
Q13) The logs for my batch job are empty - what should I do?
There are a handful of jobs that will not produce logs - these are mostly related to ILM processing (K1-ILMAD, which others) that call stored procedures. But in general all jobs should have logs, and if logs are empty, first try to submit the batch job with single thread with trace on (please refer to 'Important TIPS' stated above), if you still don’t see the logs, please raise an SR for it, indicating the standard information around the environment, the job, the time it was run. Note that batch logs are only kept for 14 days.
Q14) The log says that the user requested cancellation - but we didn't do any cancel - what does it mean?
This error typically indicates that a timeout happened during the batch execution. This can happen if one of the jobs (Conversion and or ILM related) that should run in NOCACHE is run in Default by mistake. (For instance the re-build of an index on a large table can take some time, and under the Default TPW the operation might time out). Time out for Default TPW is 15 mins.

The above sample log entry typically indicates a timeout issue.
Q15) The record counts on the threads don't seem to match up with what I was expecting - what is being counted?
Many batch jobs do provide record counts, but typically what is being counted is the unit of work that is driving the process, not the new objects resulting from the processing.
So for example Billing job will count the number of eligible Accounts to bill, not the number of bills generated.
Q16) High volume processing - how to troubleshoot?
As mentioned in the batch performance factors, the recommended approach to batch is to start small, establish some baselines in terms of records per second or execution time, and then scale up. If you immediate jump to trying a job with hundreds of threads, you may actually be encountering multiple problems at the same time (data quality, threading, etc.) and it can be harder to untangle. If you do start having problems with a job that has successfully run with many threads, then the key is to do what you can to isolate the problem you are hitting by scaling back down again temporarily so you can fully track the variables and changes.
On a batch job submission there are four tracing options that you can turn on for a particular run during testing - these add much more detail to the batch logs, and should be used sparingly (i.e. if you turn on tracing for a job with hundreds of threads, the logging is so voluminous that the log files themselves become hard to manage). When needed, turn on the tracing for a small sample batch run with a single thread, in order to keep the output manageable.
Q17) While running plug-in driven batch for DML operations on Admin tables, i am getting "Illegal attempt to modify read-only entity" error. How to address it?
Run the batch in "NOCACHE" TPW and it will resolve the issue.
In general terms, ‘DEFAULT’ TPW caches a whole lot of ‘Admin’ data including meta-data. This makes jobs like billing run a lot faster, because you can safely assume that the Admin data won’t be changed during the run, and you can just access what’s in the cache and therefore, If your job does try to make changes to Admin data, you will get errors when running it in "DEFAULT" TPW.
The situation is different when running CMA batch jobs which actually try to add / update / delete Admin data which need "NOCACHE" (with L2 cache off) that will enable CMA batch to make changes to Admin data while running the batches.
The timeout of NOCACHE has been lifted to cater for longer-running processes (like indexing and partitioning). DEFAULT has a shorter timeout, because in normal jobs it’s a bad sign if particular operations are taking 15 minutes (or whatever the timeout is set to).
In the meantime, you can of course make changes to Admin data – but sometimes you have to do the ‘flush’ to empty and rebuild certain caches so that the new/changed values are accessible to everyone.
Q18) Where can I find information about handling SaaS Batch Scheduler exceptions?
Refer to Handling Exceptions in the Scheduler Batch Stream Operations section of the Oracle Utilities Cloud Service Foundation Administrative User Guide for guidelines related to handling exceptions using the SaaS Batch Scheduler.