Integración de Data Flow con Data Science
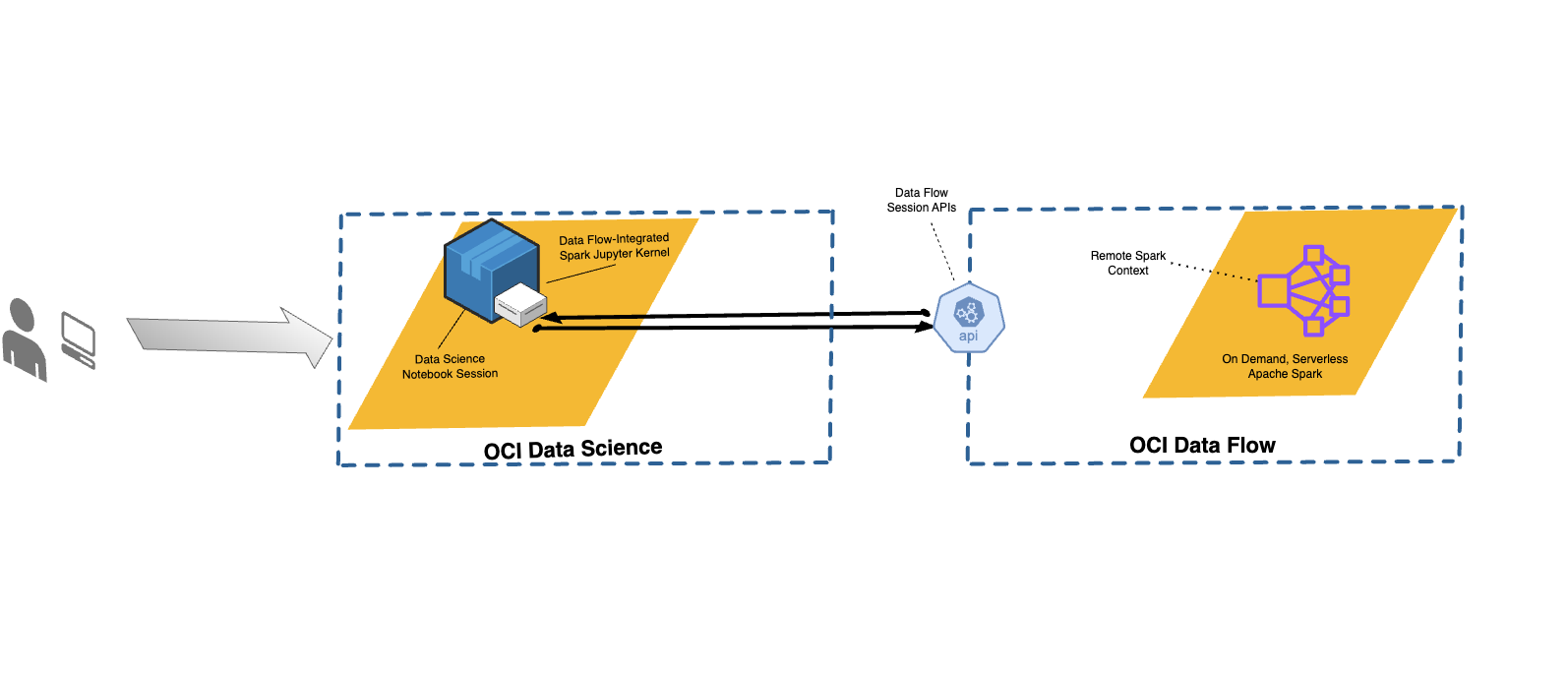
Con Data Flow, puede configurar Notebooks de Data Science para ejecutar aplicaciones de forma interactiva con Data Flow.
Data Flow utiliza blocs de nota de Jupyter totalmente gestionados para permitir a los científicos de dato e ingenieros de dato crear, visualizar, colaborar y depurar aplicaciones, de ingeniería de dato y ciencia de dato. Puede escribir estas aplicaciones en Python, Scala y PySpark. También puede conectar una sesión del bloc de notas de Data Science a Data Flow para ejecutar aplicaciones. Los núcleos y aplicaciones de Data Flow se ejecutan en Oracle Cloud Infrastructure Data Flow.
Apache Spark es un sistema informático distribuido diseñado para procesar datos a escala. Soporta SQL a gran escala, el procesamiento por lotes y de flujos, y tareas de Machine Learning. Spark SQL proporciona soporte similar a una base de datos. Para consultar datos estructurados, utilice Spark SQL. Se trata de una implantación de SQL estándar ANSI.
Las Sesiones de Data Flow soportan la escalabilidad automática de las capacidades del cluster de Data Flow. Para obtener más información, consulte Escala automática en la documentación de Data Flow.
Las sesiones de Data Flow soportan el uso de entornos conda como entornos de tiempo de ejecución de Spark personalizables.
- Limitaciones
-
-
Las sesiones de Data Flow duran hasta 7 días o 10 080 minutos (maxDurationInMinutes).
- Las sesiones de Data Flow tienen un valor de timeout de inactividad por defecto de 480 minutos (8 horas) (idleTimeoutInMinutes). Puede configurar un valor diferente.
- La sesión de Data Flow solo está disponible a través de una sesión de Data Science Notebook.
- Solo están soportadas las versiones 3.5.0 y 3.2.1 de Spark.
-
Vea el vídeo de tutorial sobre el uso de Data Science con Data Flow Studio. Consulte también la documentación del SDK de Oracle Accelerated Data Science para obtener más información sobre la integración de Data Science y Data Flow.
Instalación del entorno conda
Siga estos pasos para utilizar Data Flow con Data Flow Magic.
Uso de Data Flow con Data Science
Siga estos pasos para ejecutar una aplicación utilizando Data Flow con Data Science.
-
Asegúrese de tener las políticas configuradas para utilizar un bloc en el que se incluya Data Flow.
-
Asegúrese de que las políticas de Data Science están configuradas correctamente.
- Para obtener una lista de todos los comandos soportados, utilice el comando
%help. - Los comandos de los siguientes pasos se aplican tanto a Spark 3.5.0 como a Spark 3.2.1. En los ejemplos se utiliza Spark 3.5.0. Defina el valor de
sparkVersionsegún la versión de Spark utilizada.
Personalización de un entorno de Spark de Data Flow con un entorno conda
Puede utilizar un entorno conda publicado como entorno de tiempo de ejecución.
Ejecución de spark-nlp en Data Flow
Siga estos pasos para instalar Spark-nlp y ejecutarlo en Data Flow.
Debe haber completado los pasos 1 y 2 de Personalización de un entorno de Spark de Data Flow con un entorno conda. La biblioteca spark-nlp está preinstalada en el entorno conda pyspark32_p38_cpu_v2.
Ejemplos
Estos son algunos ejemplos de uso de datos FlowMagic.
PySpark
sc representa la Spark y esta disponible cuando se utiliza el comando mágico %%spark. La siguiente celda es un ejemplo simplificado de cómo utilizar sc en una celda de datos FlowMagic. La celda llama al método .parallelize() , que crea un RDD, numbers, a partir del número de una lista. Se imprime información sobre el RDD. El método .toDebugString() devuelve una descripción del RDD.%%spark
print(sc.version)
numbers = sc.parallelize([4, 3, 2, 1])
print(f"First element of numbers is {numbers.first()}")
print(f"The RDD, numbers, has the following description\n{numbers.toDebugString()}")Spark SQL
El uso de la opción -c sql permite ejecutar comandos Spark SQL en una celda. En esta sección, se utiliza el juego de datos de Citi Bike. La siguiente celda lee el juego de datos en un marco de datos de Spark y lo guarda como una tabla. Este ejemplo se utiliza para mostrar Spark SQL.
%%spark
df_bike_trips = spark.read.csv("oci://dmcherka-dev@ociodscdev/201306-citibike-tripdata.csv", header=False, inferSchema=True)
df_bike_trips.show()
df_bike_trips.createOrReplaceTempView("bike_trips")En el siguiente ejemplo, se utiliza la opción -c sql para indicar a los datos FlowMagic que el contenido de la celda es SparkSQL. La opción -o <variable> toma los resultados de la operación Spark SQL y los almacena en la variable definida. En este caso,
df_bike_trips es un marco de datos de Pandas que está disponible para su uso en el Notebook.%%spark -c sql -o df_bike_trips
SELECT _c0 AS Duration, _c4 AS Start_Station, _c8 AS End_Station, _c11 AS Bike_ID FROM bike_trips;df_bike_trips.head()sqlContext para consultar la tabla:%%spark
df_bike_trips_2 = sqlContext.sql("SELECT * FROM bike_trips")
df_bike_trips_2.show()%%spark -c sql
SHOW TABLESWidget de visualización automática
Los datos FlowMagic incluyen autovizwidget que permite la visualización de marcos de datos de Pandas. La función display_dataframe() toma un marco de datos de Pandas como parámetro y genera una interfaz gráfica de usuario interactiva en el bloc de notas. Tiene separadores que muestran la visualización de los datos de varias formas, como gráficos tabulares, gráficos circulares, trazos de dispersión, y gráficos de área y barras.
display_dataframe() con el marco de datos df_people creado en la sección Spark SQL del Bloc de notas:from autovizwidget.widget.utils import display_dataframe
display_dataframe(df_bike_trips)Matplotlib
Una tarea común que realizan los científicos de datos es visualizar sus datos. Con juegos de datos grandes, generalmente no es posible y casi siempre es preferible no extraer los datos del cluster de Spark de Data Flow a la sesión de Notebook. En este ejemplo se muestra cómo utilizar recursos del servidor para generar un diagrama e incluirlo en el bloc de notas.
%matplot plt para mostrar el gráfico en el Notebook, aunque se represente en el servidor:%%spark
import matplotlib.pyplot as plt
df_bike_trips.groupby("_c4").count().toPandas().plot.bar(x="_c4", y="count")
%matplot pltEjemplos adicionales
Hay más ejemplos disponibles de GitHub con muestras de Data Flow y muestras de Data Science.