flujos de datos
Un flujo de datos es un programa visual que representa el flujo de datos desde los activos de datos de origen, como una base de datos o un archivo plano, hasta los activos de datos de destino, como un lago de datos o un almacén de datos.
En las siguientes páginas se describe cómo mostrar, crear y gestionar flujos de datos en Data Integration:
- Listado de flujos de datos
- Creación de un flujo de datos
- Uso de operadores de flujo de datos
- Uso de parámetros de flujo de datos
- Edición de un flujo de datos
- Refrescamiento de entidades en un flujo de datos
- Movimiento de un flujo de datos
- Duplicación de un flujo de datos
- Supresión de un flujo de datos
- Referencia de Functions (Data Flow)
El diseñador de interfaz de usuario intuitivo de Data Integration se abre al crear, ver o editar un flujo de datos.
Consulte Conceptos de diseño para obtener una visión general de alto nivel de los conceptos básicos del diseñador interactivo. También puede ver el video interactivo del diseñador de flujos de datos de Data Integration para obtener una introducción práctica a los flujos de datos.
En las siguientes páginas se describe cómo exportar e importar un flujo de datos:
Conceptos de diseño
Para utilizar el diseñador interactivo en Data Integration, resulta útil comprender los siguientes conceptos básicos.
Un esquema define la unidad de datos en un sistema de origen o de destino. Al trabajar en un flujo de datos en Data Integration, el cambio de esquema se produce cuando cambian las definiciones de datos.
Por ejemplo, se podría agregar o eliminar un atributo en el origen, o cambiar el nombre de un atributo en el destino. Si no maneja el cambio de esquema, es posible que los procesos de ETL fallen o que pierda la calidad de los datos.
Por defecto, Data Integration gestiona el cambio de esquema. Cuando configure un operador de origen en el diseñador en el flujo de datos, después de seleccionar una entidad, seleccione el separador Opciones avanzadas del panel Propiedades. La Casilla de Control Permitir Cambio de Esquema seleccionada indica que está activado el cambio del esquema.
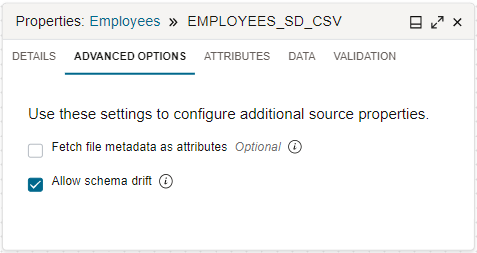
Cuando el cambio de esquema está activado, Data Integration puede detectar cambios de definición de esquema en las entidades de datos especificadas durante el diseño y el tiempo de ejecución del flujo de datos. Los cambios se seleccionan automáticamente y el esquema se adapta para acomodar nuevos atributos, atributos eliminados, nombres de atributos diferentes, tipos de datos cambiados, etc.
Si desactiva la casilla de control Allow Schema Drift, desactive el cambio de esquema para bloquear las definiciones de esquema cuando se defina el flujo de datos. Cuando el cambio de esquema está desactivado, Data Integration utiliza una unidad fija de la entidad de datos especificada incluso si la unidad subyacente ha cambiado.
Sin gestionar el cambio de esquema, los flujos de datos pueden volverse vulnerables a los cambios del origen de datos ascendente. Con la ayuda del cambio de esquema, los flujos de datos se vuelven más resilientes y se adaptan automáticamente a cualquier cambio. No es necesario rediseñar los flujos en los que se produzcan cambios en las definiciones del esquema.
Para un archivo JSON, el cambio de esquema está desactivado por defecto y no se puede activar si se utiliza un esquema personalizado para inferir la unidad de entidad. Si desea que el cambio de esquema esté disponible y activado, edite el origen de JSON en el flujo de datos o la tarea del cargador de datos y desmarque la casilla de control Usar esquema personalizado.
En Data Integration, una operación de datos en un flujo de datos se puede transferir a un sistema de datos de origen o destino para su procesamiento.
Por ejemplo, se puede realizar una operación de ordenación o filtro en el sistema de origen mientras se leen los datos. En el caso de que uno de los orígenes de una operación de unión esté en el mismo sistema que el destino, la operación de datos se puede transferir al sistema de destino.
Data Integration puede utilizar la ejecución en un flujo de datos cuando utiliza sistemas de datos relacionales que soportan la ejecución. La lista actual incluye bases de datos Oracle, Oracle Autonomous AI Lakehouse, Oracle Autonomous AI Transaction Processing y MySQL.
Por defecto, Data Integration utiliza la ejecución cuando corresponda. Cuando configure un operador de origen en el diseñador en el flujo de datos, después de seleccionar una entidad, seleccione el separador Opciones avanzadas del panel Propiedades. La Casilla de Control Permitir Ejecución seleccionada indica que la ejecución está activada.
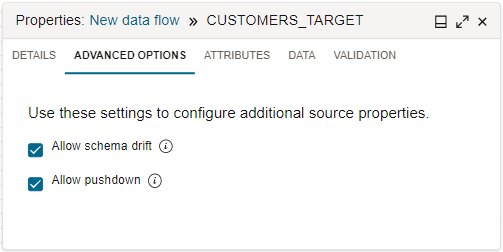
Cuando está activada la ejecución, Data Integration convierte la lógica de operación de datos aplicable en sentencias SQL que se ejecutan directamente en la base de datos relacional. Al ejecutar el procesamiento de datos en la base de datos, se extraen y cargan menos datos.
Si desactiva la casilla de control Permitir pushdown, desactiva pushdown. Cuando la ejecución está desactivada, Data Integration recupera todos los datos del sistema de origen y procesa los datos de los clusters de Apache Spark asignados al espacio de trabajo.
Al permitir que Data Integration utilice pushdown, el rendimiento se mejora porque:
- Se utiliza la potencia de procesamiento de la base de datos
- Se ingieren menos datos para su procesamiento.
Según la optimización, Data Integration puede utilizar la ejecución parcial o total en un flujo de datos. La ejecución parcial se realiza cuando se utiliza un sistema de datos relacional soportado en el origen o destino. La ejecución completa se realiza cuando están presentes las siguientes condiciones:
- Solo existe un destino en el flujo de datos.
- En un flujo de datos con un único origen, tanto el origen como el destino utilizan la misma conexión a un sistema de datos relacional soportado.
- En un flujo de datos con varios orígenes, todos los orígenes también deben utilizar la misma base de datos y conexión.
- Todos los operadores de transformación y las funciones del flujo de datos pueden generar un código SQL de ejecución válido.
La preparación de datos garantiza que los procesos de integración de datos ingieran datos precisos y significativos con menos errores para producir datos de calidad con el fin de obtener estadísticas más fiables.
La preparación de los datos incluye la limpieza y validación de los datos para reducir los errores, así como la transformación y el enriquecimiento de los datos antes de cargarlos en los sistemas de destino. Por ejemplo, los datos pueden provenir de diferentes orígenes con varios formatos e incluso de información duplicada. La preparación de datos puede implicar la eliminación de atributos y filas duplicados, la estandarización en un formato para todos los atributos de fecha y el enmascaramiento de datos de atributos confidenciales, como tarjetas de crédito y contraseñas.
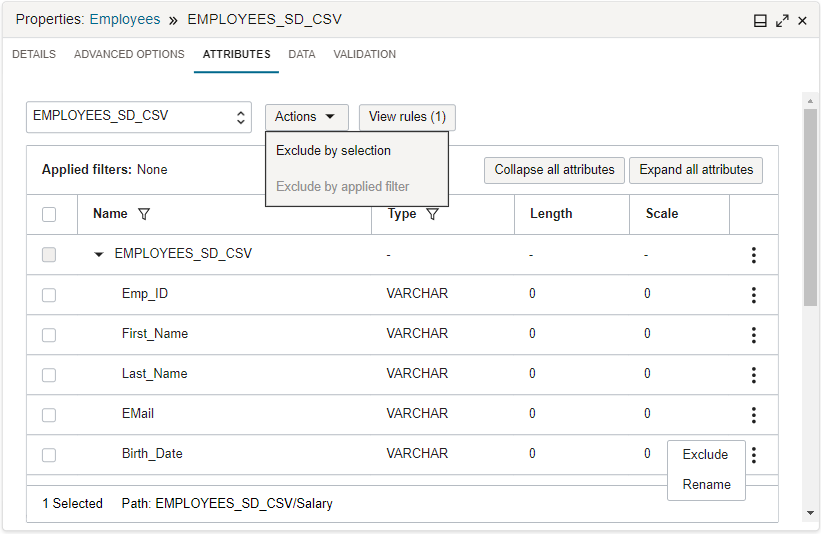
Data Integration proporciona operadores y funciones de conformación listas para usar y transformaciones que puede utilizar en herramientas interactivas para preparar los datos a medida que diseñe la lógica para los procesos ETL. Por ejemplo, el separador Atributos permite buscar atributos de entrada por un patrón y aplicar una regla de exclusión.
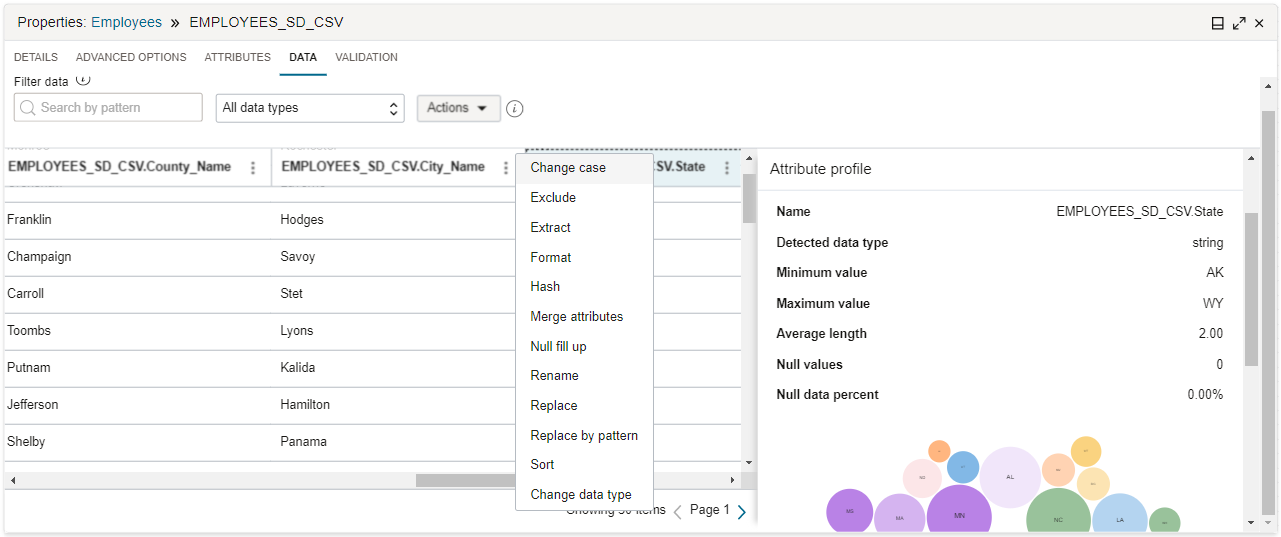
En el separador Datos, puede aplicar transformaciones en un solo atributo, o filtrar los atributos por un patrón de nombre o un tipo de datos y, a continuación, aplicar transformaciones en un grupo de atributos. También puede obtener una vista previa de los resultados de las transformaciones de datos en el separador Datos, sin tener que ejecutar todo el flujo de datos.
En Data Integration, utilice el separador Asignación para describir el flujo de datos de los atributos de origen a los atributos de destino.
Un destino puede ser una entidad de datos existente o una nueva. En un flujo de datos, el separador Asignación solo se aplica a un operador de destino para una entidad de datos existente. Para las entidades de datos de destino existentes, los atributos de origen y los atributos personalizados procedentes de operaciones ascendentes se asignan a los atributos del destino.
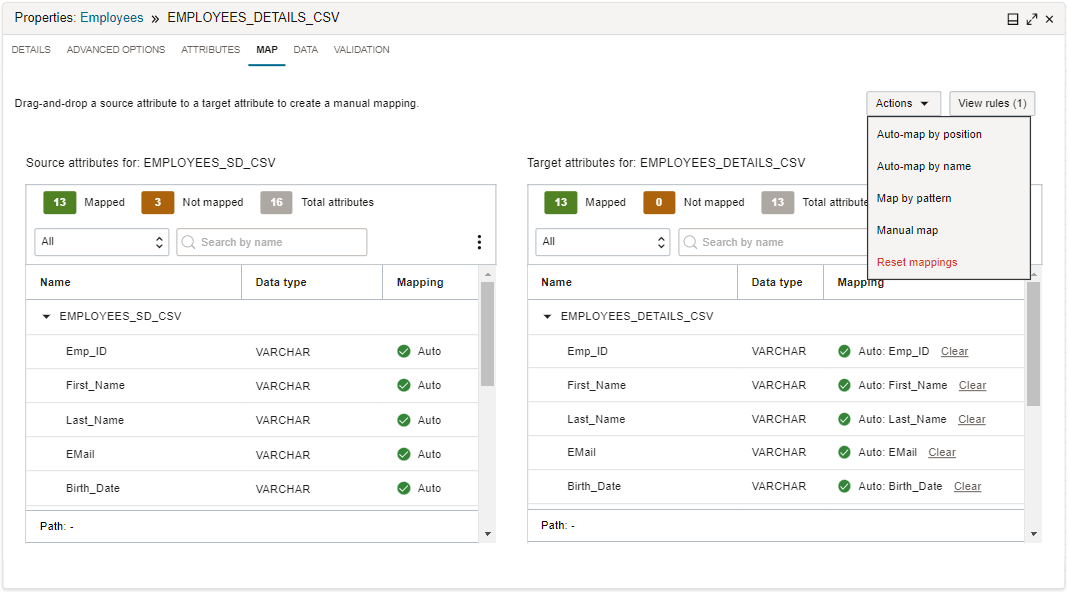
Puede optar por utilizar la asignación automática o la asignación manual. Para la asignación automática, Data Integration puede asignar atributos de entrada a atributos de destino con el mismo nombre o según su posición en las listas de atributos. En la asignación manual, arrastre un atributo de entrada de la lista de origen a un atributo de la lista de destino para crear una asignación. También puede utilizar el cuadro de diálogo Asignar atributo para crear una asignación seleccionando un atributo de origen y un atributo de destino. También puede utilizar un patrón de atributo de origen y un patrón de atributo de destino para crear la asignación.
Al seleccionar la casilla de control Crear nueva entidad de datos en un operador de destino, el separador Asignación no está disponible. Data Integration utiliza los atributos de origen de entrada para crear la tabla o estructura de archivos con una asignación de uno a uno.
Uso de la interfaz del diseñador
El diseñador de Data Integration permite utilizar una interfaz gráfica de usuario para crear un flujo de integración de datos.
También puede utilizar un diseñador similar para crear un pipeline.
Las áreas principales del diseñador son:

Las herramientas que le ayudarán a desplazarse por un flujo de datos o un pipeline en el lienzo son las siguientes:
- Ver: seleccione este menú para abrir o cerrar los paneles Propiedades, Operadores, Validación y Parámetros.
- Acercar: permite acercar el diseño.
- Salir: permite alejar para ver más del diseño.
- Reset Zoom: vuelve a la vista por defecto del diseño.
- Guía de cuadrícula: activa y desactiva las guías de cuadrícula.
- Diseño automático: organiza los operadores en el lienzo.
- Suprimir: elimina el operador seleccionado del lienzo.
- Deshacer: elimina la última acción realizada.
- Rehacer: realiza la última acción si ha seleccionado previamente Deshacer.
Puede deshacer y rehacer los siguientes tipos de acciones:
- Adición y supresión de un operador
- Adición y supresión de conexiones entre operadores
- Cambio de la posición de un operador en el lienzo
El lienzo es el área de trabajo principal, donde se diseña el flujo de datos o el pipeline.
Arrastre objetos del panel Operadores al lienzo para empezar.
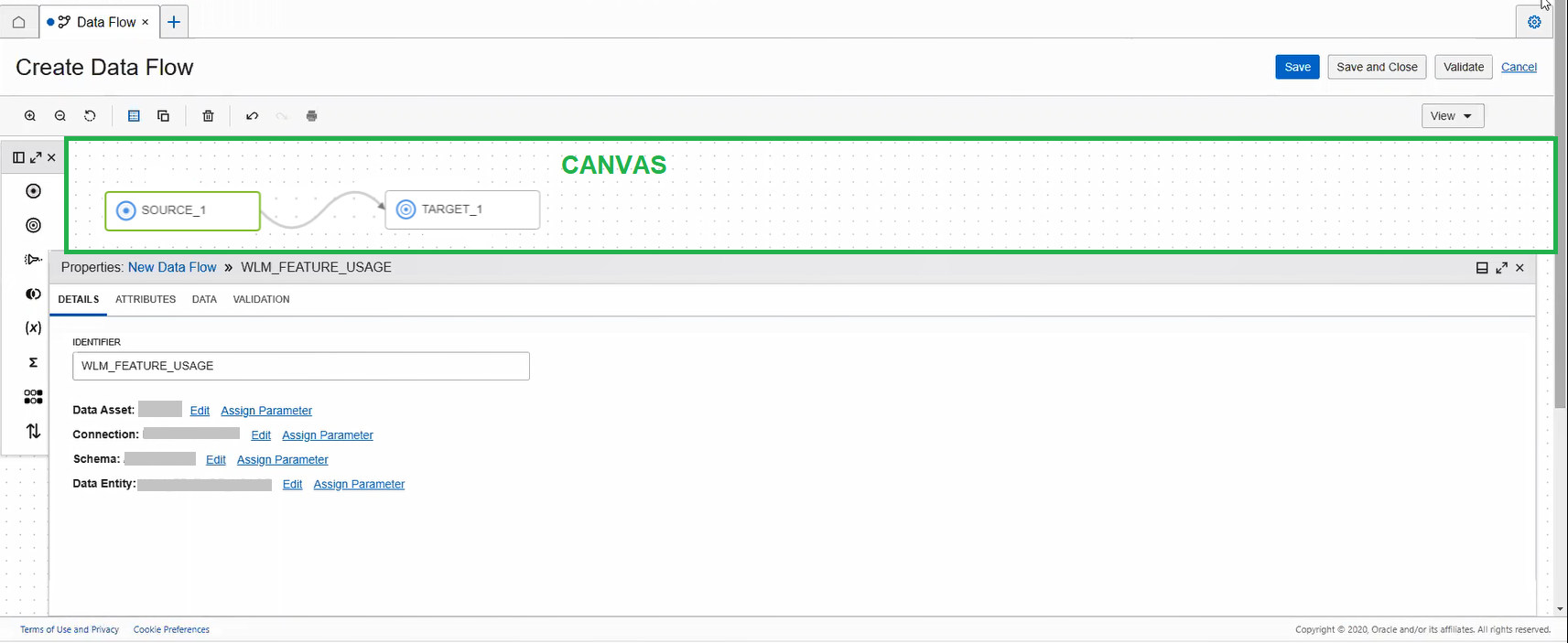
Se comienza con un lienzo en blanco para un flujo de datos. Para que un flujo de datos sea válido, debe tener al menos un origen y un destino definidos.
Para un pipeline, se comienza con un lienzo que tiene un operador de inicio y un operador de finalización. El diseño del pipeline debe incluir al menos un operador de tarea para que sea válido.
Para conectar dos operadores, pase el cursor sobre un operador hasta que vea el conector (un círculo pequeño) en el lado derecho del operador. A continuación, arrastre el conector al operador al que desea conectarse. La conexión es válida cuando una línea conecta los operadores después de soltar el conector.
Para insertar un operador entre dos operadores conectados, haga clic con el botón derecho en la línea de conexión y utilice el menú Insertar.
Para suprimir una conexión, puede hacer clic con el botón derecho en una línea y seleccionar Suprimir.
Para duplicar un operador de origen, destino o expresión, haga clic con el botón derecho en el icono de operador y seleccione Duplicar.
El panel Operadores muestra los operadores que puede agregar a un flujo de datos o pipeline.
Arrastre los operadores del panel Operadores al lienzo para diseñar el flujo de datos o el pipeline. Cada operador tiene un juego de propiedades diferente que puede configurar mediante el panel Propiedades.
Para un flujo de datos, puede agregar operadores de entrada, salida y conformación.

Para un pipeline, agregue operadores de entrada, salida y tarea para construir una secuencia.

Acerca de los operadores
Los siguientes operadores están disponibles para su uso en un flujo de datos:
- Entradas/salidas
-
- Origen: representa una entidad de origen de datos que sirve como entrada en un flujo de datos.
- Destino: representa una entidad de datos de destino que sirve como entidad de salida para almacenar los datos transformados.
- Conformación
-
- Filtro: selecciona determinados atributos del puerto de entrada para continuar en sentido descendente hasta el puerto de salida.
- Unión: enlaza datos de varios orígenes. Los tipos de uniones soportados son Interna, Externa derecha, Externa izquierda y Externa completa.
- Expresión: realiza una transformación en una sola fila de datos.
- Agregación: realiza cálculos como una suma o un recuento en todas las filas o un grupo de filas.
- Distinto: devuelve filas de valores distintos con valores únicos.
- Ordenar: realiza la ordenación de datos en orden ascendente o descendente.
- Unión: realiza una operación de unión en hasta 10 operadores de origen.
- Resta: realiza una operación de resta en dos orígenes y devuelve las filas que están presentes en un origen pero no en el otro.
- Intersección: realiza una operación de intersección en dos o más orígenes y devuelve las filas que están presentes en los orígenes conectados.
- Dividir: realiza una operación de división para dividir un origen de datos de entrada entre dos o más puertos de salida en función de las condiciones de división.
- Girar: realiza una transformación mediante expresiones de función de agregado y valores de un atributo especificado como clave dinámica, lo que genera varios atributos nuevos en la salida.
- Consulta: realiza una consulta y, a continuación, una transformación utilizando un origen de entrada principal, un origen de entrada de consulta y una condición de consulta.
- Función: llama a una función de Oracle de Oracle Cloud Infrastructure desde un flujo a partir de Data Integration.
- Planificar: Realiza la anulación de anidación de una estructura de archivos compleja desde la raíz hasta el atributo de tipo de dato jerárquico seleccionado.
Obtenga más información sobre el uso de operadores de flujo de datos.
- Entradas/salidas
-
- Iniciar: representa el inicio de un pipeline. Solo hay un operador de inicio en un pipeline. El operador de inicio puede tener enlaces a más de una tarea.
- Finalizar: representa el final de un pipeline. Solo hay un operador de finalización en un pipeline. El operador de finalización puede tener enlaces de más de un nodo ascendente.
- Expresión: permite crear nuevos campos derivados en un pipeline, similares a un operador de expresión en un flujo de datos.
- Fusión: realiza una fusión de tareas que se ejecutan en paralelo. La condición de fusión especificada determina cómo proceder con las siguientes operaciones descendentes.
- Decisión: permite especificar un flujo de bifurcación de pipeline mediante una condición de decisión. En función de las salidas ascendentes, la expresión de condición especificada se debe evaluar como un valor booleano, que determina la bifurcación descendente posterior.
- Tareas
-
- Integración: enlaza a una tarea de integración.
- Cargador de datos: enlaza a una tarea del cargador de datos.
- Pipeline: enlaza a una tarea de pipeline.
- SQL: enlaza a una tarea de SQL.
- OCI Data Flow: enlaza a una aplicación en Oracle Cloud Infrastructure Data Flow.
- REST: enlaza a una tarea de REST.
Cómo trabajar con el panel Operadores
Para ayudarle a trabajar de manera más eficaz, puede acoplar el panel Operadores a la izquierda de la pantalla. Puede ampliar el panel o minimizarlo para mostrar solo los iconos mediante el icono de ampliación o reducción. También puede cerrar el panel. Si el panel está cerrado, puede abrirlo desde el menú Ver de la barra de herramientas del diseñador.
El panel Propiedades permite configurar el pipeline o el flujo de datos y sus operadores.
Utilice el separador Validación para validar todo el flujo de datos o el pipeline.
En el separador Parámetros, puede ver todos los parámetros definidos en el nivel de pipeline o flujo de datos, incluidos los parámetros generados por el sistema. Para los parámetros definidos por el usuario, puede suprimir parámetros y, si procede, editar los valores por defecto de los parámetros.
Para un flujo de datos, después de agregar un operador en el lienzo, seleccione el operador y utilice el panel Propiedades para configurar el operador. Puede:
- Especifique los detalles del operador, como el identificador, y configure los valores específicos del operador en el separador Detalles.
- Ver los atributos de entrada y salida del operador en el separador Atributos.
- Asignar atributos de entrada a atributos de la entidad de datos de destino para un operador de destino en el separador Asignación.
- Obtener una vista previa de un ejemplo de datos en el separador Datos.
- Validar la configuración del operador en el separador Validación.
Del mismo modo, para un pipeline, después de agregar un operador en el lienzo, seleccione el operador y utilice el panel Propiedades para configurar el operador. Puede:
- Especifique un nombre para el operador en el separador Detalles. Para un operador de fusión, especifique una condición de fusión. Para un operador de expresión, agregue una o más expresiones. Para los operadores de tareas, seleccione una tarea para enlazar al operador y especifique cuándo se ejecuta la tarea en función del estado de ejecución del operador ascendente.
Para todos los operadores de tareas, puede seleccionar tareas de tiempo de diseño de proyectos en el espacio de trabajo actual y tareas publicadas de cualquier aplicación en el espacio de trabajo actual. Con las tareas REST publicadas y las tareas de OCI Data Flow, también puede seleccionar una tarea de cualquier aplicación en otro espacio de trabajo del mismo compartimento u otro compartimento.
- Si corresponde, especifique las opciones de ejecución de tareas en el separador Configuración.
- Si corresponde, configure los parámetros entrantes en el separador Configuración.
- Ver las salidas del separador Salida, las cuales se pueden utilizar como entradas para el siguiente operador en el pipeline.
- Si corresponde, valide la configuración del operador en el separador Validación.
Cómo trabajar con el panel Propiedades
Para ayudarle a trabajar de forma más eficaz, puede atracar el panel Propiedades en la parte inferior de la pantalla. Puede ampliar el panel o minimizarlo mediante el icono de ampliación o reducción. También puede cerrar el panel. Si el panel está cerrado, puede abrirlo desde el menú Ver de la barra de herramientas del diseñador.
Más información sobre los separadores del panel Propiedades
Al hacer clic en el lienzo y no hay ningún operador seleccionado, el panel Propiedades muestra los detalles del flujo de datos o del pipeline .
Cuando selecciona diferentes operadores en el lienzo, el panel Propiedades muestra las propiedades del operador enfocado. Puede ver, configurar y transformar datos a medida que fluyen por el operador mediante los siguientes separadores del panel Propiedades:
- Detalles
-
Puede asignar un nombre a un operador mediante el campo Identificador del separador Detalles. Para los operadores de origen y de destino, también puede seleccionar el activo de datos, la conexión, el esquema y la entidad de datos. Si selecciona Autonomous AI Lakehouse o Autonomous AI Transaction Processing como activo de datos, se activa la opción para seleccionar la ubicación temporal. La ubicación temporal permite seleccionar el cubo de Object Storage para almacenar provisionalmente los datos antes que se muevan al destino.
Solo puede seleccionar el activo de datos, la conexión, el esquema y la entidad de datos en el orden en el que aparecen en el separador Detalles. Por ejemplo, puede seleccionar la conexión solo después de seleccionar el activo de datos. La opción de selección del esquema solo se activa una vez que se ha seleccionado la conexión, y así sucesivamente. Una selección solo se puede realizar en función de la relación principal-secundario heredada de la selección anterior. Después de realizar una selección, se activa la opción de edición.
Puede asignar parámetros a varios detalles de cada operador para que estos detalles no estén enlazados al código compilado cuando publique el flujo de integración de datos. Consulte Uso de parámetros en flujos de datos y Uso de parámetros en pipelines.
Para los operadores de conformación, puede crear las condiciones o las expresiones que se aplicarán a los datos a medida que pasan por el operador.
Para un pipeline, utilice el separador Detalles para proporcionar un nombre para el pipeline o el operador seleccionado. Para los operadores de tareas, también debe especificar la tarea que se va a utilizar.
- Atributos
-
El separador Atributos solo aparece para un flujo de datos.
En el menú, seleccione esta opción para ver los atributos de entrada enlazados al operador en el lado izquierdo del lienzo, o los atributos de salida que van al siguiente operador al que están enlazados en el lado derecho.
Al seleccionar el icono del filtro en la columna Nombre, se muestra el campo de filtro. Introduzca un patrón de expresión regular simple o los comodines (como
?y*) en el campo de filtro para filtrar los atributos por patrón de nombre. Este campo no es sensible a mayúsculas/minúsculas. Al seleccionar el icono del filtro de la columna Tipo, se muestra el menú de tipo. Utilice el menú para seleccionar el filtro de tipo. Solo puede aplicar un filtro de patrón de nombre a la vez, pero puede aplicar varios filtros de tipo. Por ejemplo, para filtrar por el patrón de nombre *_CODE y por el tipo numérico o varchar, aplique un filtro de patrón de nombre (*_CODE) y dos filtros de tipo (numérico, varchar).A continuación, puede seleccionar atributos para excluirlos o seleccionar atributos de filtros aplicados para excluirlos. Utilice el menú Acciones para elegir la exclusión por selección o la exclusión por filtros aplicados. Las reglas de exclusión seleccionadas se agregan al panel Reglas. Los filtros aplicados aparecerán en la parte superior de la lista de atributos. Utilice la opción Borrar todo para restablecer los filtros aplicados.
Seleccione Ver reglas para abrir el panel Reglas y ver todas las reglas aplicadas a la entidad de datos. También puede ver las reglas desde el mensaje de ejecución correcta que aparece en la esquina superior derecha después de aplicar las reglas. Por defecto, la primera regla del panel Reglas lo incluye todo. Puede aplicar acciones adicionales a cada regla, como reordenarla en la lista o suprimirla.
- Asignación
-
El separador Asignación solo aparece para un flujo de datos.
Este separador solo aparece para un operador de destino. Permite asignar los atributos de entrada a los atributos de la entidad de datos de destino, ya sea una asignación por posición, nombre o patrón, o una asignación directa. También puede utilizar la asignación automática, por nombre, o eliminar las asignaciones.
- Datos
-
El separador Datos solo aparece para un flujo de datos.
Acceda al separador Data para obtener una vista previa de un ejemplo de datos para ver cómo afecta una regla de transformación a los datos a medida que pasan por el operador.
Nota
Asegúrese de que tiene el activo de datos, la conexión, el esquema y la entidad de datos configurados antes de acceder al separador Datos.Puede filtrar datos por un patrón de nombre o un tipo de datos, y aplicar una regla de exclusión a los datos filtrados o realizar transformaciones de forma masiva mediante el menú Acciones. Para filtrar datos por un patrón de nombre, introduzca un patrón de expresión regular simple con caracteres comodín (como
?y*) en el campo Buscar por patrón. Para filtrar los datos por un tipo de datos, seleccione el tipo en el menú. No se pueden aplicar transformaciones a un operador de destino porque los datos son de solo lectura.A medida que agrega y elimina reglas y transformaciones, el muestreo de datos se actualiza para reflejar estos cambios. Obtenga más información sobre Transformaciones de datos.
- Configuración
-
El separador Configuración solo aparece para un pipeline. Si está disponible para una tarea, puede volver a configurar los valores de parámetros asociados con la tarea o el flujo de datos subyacente, si corresponde.
- Salida
-
El separador Salida solo aparece para un pipeline.
Puede ver la lista de salidas que pueden utilizarse como entradas a operadores conectados en el pipeline.
- Validación
- Utilice el separador Validation para comprobar que el operador está configurado correctamente a fin de evitar errores más tarde cuando ejecute el flujo de datos o el pipeline. Por ejemplo, si olvida asignar operadores de entrada o de salida, en el panel Validación aparecen mensajes de advertencia. Cuando selecciona un mensaje en el panel Validación, se pone el enfoque en el operador para que pueda solucionar el error o la advertencia.
El panel Parámetros muestra los parámetros utilizados en un flujo de datos o en un pipeline.
También puede suprimir un parámetro del panel Parámetros.
Puede ver todos los mensajes de error y de advertencia para un flujo de datos o un pipeline en el panel Validación global.
En la barra de herramientas del lienzo, seleccione Validar para comprobar y depurar el flujo de datos antes de utilizar el flujo de datos en una tarea de integración. Del mismo modo, compruebe y depure los pipelines antes de utilizarlos en una tarea de pipeline. El panel Validación global se abre y muestra mensajes de error y advertencia para que los solucione. La selección de un mensaje pone el enfoque en el operador que generó el mensaje de error o advertencia.